diff --git a/docs/source/_toctree.yml b/docs/source/_toctree.yml
index c6d7ef6826..f3d39ba445 100644
--- a/docs/source/_toctree.yml
+++ b/docs/source/_toctree.yml
@@ -42,8 +42,6 @@
title: ORPO
- local: ppo_trainer
title: PPO
- - local: ppov2_trainer
- title: PPOv2
- local: reward_trainer
title: Reward
- local: rloo_trainer
diff --git a/docs/source/customization.mdx b/docs/source/customization.mdx
index a576890734..7fc9211e11 100644
--- a/docs/source/customization.mdx
+++ b/docs/source/customization.mdx
@@ -1,6 +1,6 @@
# Training customization
-TRL is designed with modularity in mind so that users to be able to efficiently customize the training loop for their needs. Below are some examples on how you can apply and test different techniques.
+TRL is designed with modularity in mind so that users to be able to efficiently customize the training loop for their needs. Below are some examples on how you can apply and test different techniques. Note: Although these examples use the DPOTrainer, the customization applies to most (if not all) trainers.
## Train on multiple GPUs / nodes
@@ -46,171 +46,118 @@ else:
Consult the 🤗 Accelerate [documentation](https://huggingface.co/docs/accelerate/usage_guides/deepspeed) for more information about the DeepSpeed plugin.
-## Use different optimizers
+## Use different optimizers and schedulers
-By default, the `PPOTrainer` creates a `torch.optim.Adam` optimizer. You can create and define a different optimizer and pass it to `PPOTrainer`:
-```python
-import torch
-from transformers import GPT2Tokenizer
-from trl import PPOTrainer, PPOConfig, AutoModelForCausalLMWithValueHead
-
-# 1. load a pretrained model
-model = AutoModelForCausalLMWithValueHead.from_pretrained('gpt2')
-ref_model = AutoModelForCausalLMWithValueHead.from_pretrained('gpt2')
-tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
-
-# 2. define config
-ppo_config = {'batch_size': 1, 'learning_rate':1e-5}
-config = PPOConfig(**ppo_config)
-
-
-# 2. Create optimizer
-optimizer = torch.optim.SGD(model.parameters(), lr=config.learning_rate)
-
-
-# 3. initialize trainer
-ppo_trainer = PPOTrainer(config, model, ref_model, tokenizer, optimizer=optimizer)
-```
-
-For memory efficient fine-tuning, you can also pass `Adam8bit` optimizer from `bitsandbytes`:
-
-```python
-import torch
-import bitsandbytes as bnb
-
-from transformers import GPT2Tokenizer
-from trl import PPOTrainer, PPOConfig, AutoModelForCausalLMWithValueHead
-
-# 1. load a pretrained model
-model = AutoModelForCausalLMWithValueHead.from_pretrained('gpt2')
-ref_model = AutoModelForCausalLMWithValueHead.from_pretrained('gpt2')
-tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
-
-# 2. define config
-ppo_config = {'batch_size': 1, 'learning_rate':1e-5}
-config = PPOConfig(**ppo_config)
-
-
-# 2. Create optimizer
-optimizer = bnb.optim.Adam8bit(model.parameters(), lr=config.learning_rate)
-
-# 3. initialize trainer
-ppo_trainer = PPOTrainer(config, model, ref_model, tokenizer, optimizer=optimizer)
-```
-
-### Use LION optimizer
+By default, the `DPOTrainer` creates a `torch.optim.AdamW` optimizer. You can create and define a different optimizer and pass it to `DPOTrainer` as follows:
-You can use the new [LION optimizer from Google](https://huggingface.co/papers/2302.06675) as well, first take the source code of the optimizer definition [here](https://github.com/lucidrains/lion-pytorch/blob/main/lion_pytorch/lion_pytorch.py), and copy it so that you can import the optimizer. Make sure to initialize the optimizer by considering the trainable parameters only for a more memory efficient training:
```python
-optimizer = Lion(filter(lambda p: p.requires_grad, self.model.parameters()), lr=self.config.learning_rate)
-
-...
-ppo_trainer = PPOTrainer(config, model, ref_model, tokenizer, optimizer=optimizer)
+from datasets import load_dataset
+from transformers import AutoModelForCausalLM, AutoTokenizer
+from torch import optim
+from trl import DPOConfig, DPOTrainer
+
+model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen2.5-0.5B-Instruct")
+tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2.5-0.5B-Instruct")
+dataset = load_dataset("trl-lib/ultrafeedback_binarized", split="train")
+training_args = DPOConfig(output_dir="Qwen2.5-0.5B-DPO")
+
+optimizer = optim.SGD(model.parameters(), lr=training_args.learning_rate)
+
+trainer = DPOTrainer(
+ model=model,
+ args=training_args,
+ train_dataset=dataset,
+ tokenizer=tokenizer,
+ optimizers=(optimizer, None),
+)
+trainer.train()
```
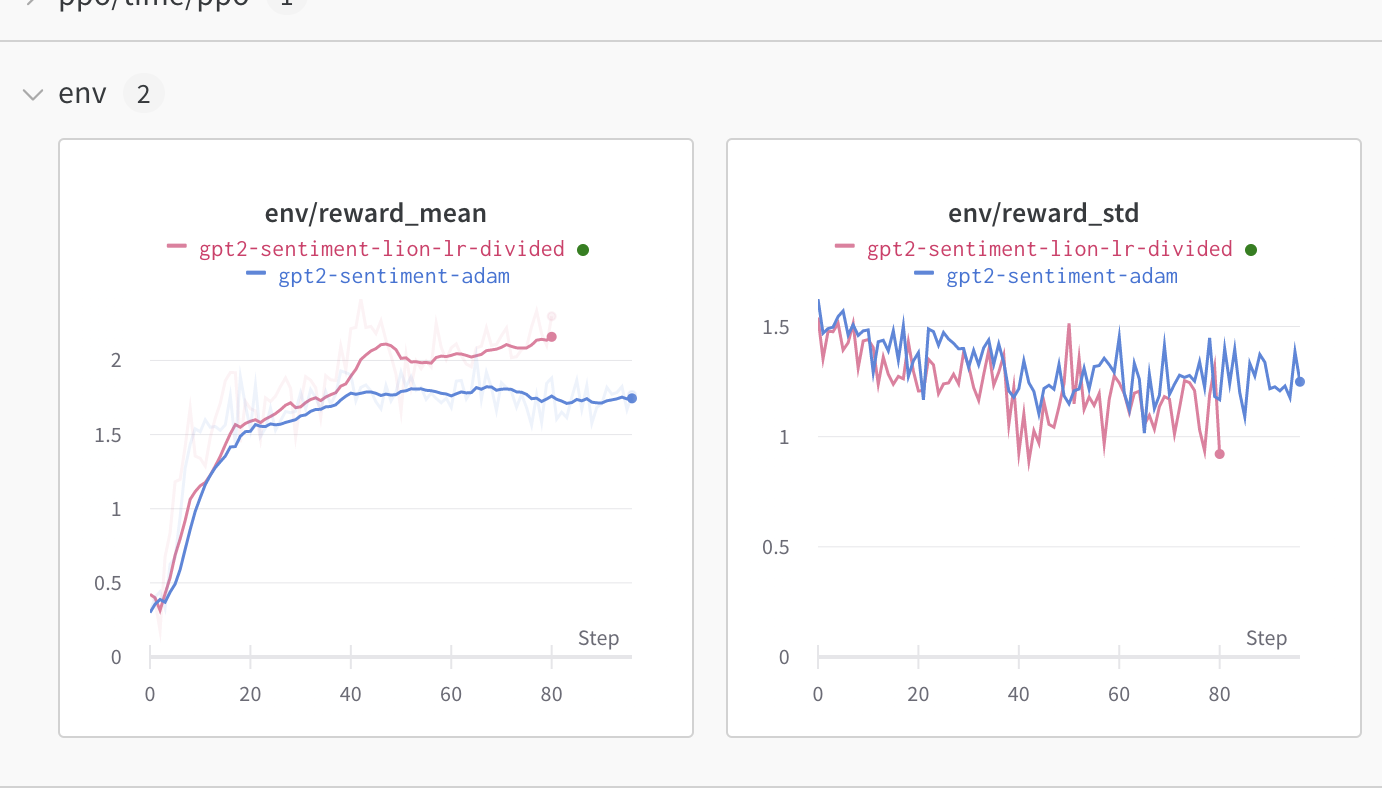
-We advise you to use the learning rate that you would use for `Adam` divided by 3 as pointed out [here](https://github.com/lucidrains/lion-pytorch#lion---pytorch). We observed an improvement when using this optimizer compared to classic Adam (check the full logs [here](https://wandb.ai/distill-bloom/trl/runs/lj4bheke?workspace=user-younesbelkada)):
-
-
-
-
-
-Since `trl` supports all key word arguments when loading a model from `transformers` using `from_pretrained`, you can also leverage `load_in_8bit` from `transformers` for more memory efficient fine-tuning.
+Since `trl` supports all keyword arguments when loading a model from `transformers` using `from_pretrained`, you can also leverage `load_in_8bit` from `transformers` for more memory efficient fine-tuning.
-Read more about 8-bit model loading in `transformers` [here](https://huggingface.co/docs/transformers/perf_infer_gpu_one#bitsandbytes-integration-for-int8-mixedprecision-matrix-decomposition).
-
-
+Read more about 8-bit model loading in `transformers` [here](https://huggingface.co/docs/transformers/en/peft#load-in-8bit-or-4bit).
```python
-# 0. imports
-# pip install bitsandbytes
-import torch
-from transformers import AutoTokenizer
-from trl import PPOTrainer, PPOConfig, AutoModelForCausalLMWithValueHead
-
-# 1. load a pretrained model
-model = AutoModelForCausalLMWithValueHead.from_pretrained('bigscience/bloom-560m')
-ref_model = AutoModelForCausalLMWithValueHead.from_pretrained('bigscience/bloom-560m', device_map="auto", load_in_8bit=True)
-tokenizer = AutoTokenizer.from_pretrained('bigscience/bloom-560m')
-
-# 2. initialize trainer
-ppo_config = {'batch_size': 1}
-config = PPOConfig(**ppo_config)
-ppo_trainer = PPOTrainer(config, model, ref_model, tokenizer)
+from datasets import load_dataset
+from transformers import AutoModelForCausalLM, AutoTokenizer
+from trl import DPOConfig, DPOTrainer
+
+model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen2.5-0.5B-Instruct")
+quantization_config = BitsAndBytesConfig(load_in_8bit=True)
+ref_model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen2.5-0.5B-Instruct", quantization_config= quantization_config)
+tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2.5-0.5B-Instruct")
+dataset = load_dataset("trl-lib/ultrafeedback_binarized", split="train")
+training_args = DPOConfig(output_dir="Qwen2.5-0.5B-DPO")
+
+trainer = DPOTrainer(
+ model=model,
+ ref_model=ref_model,
+ args=training_args,
+ train_dataset=dataset,
+ tokenizer=tokenizer,
+)
+trainer.train()
```
## Use the CUDA cache optimizer
-When training large models, you should better handle the CUDA cache by iteratively clearing it. Do do so, simply pass `optimize_cuda_cache=True` to `PPOConfig`:
+When training large models, you should better handle the CUDA cache by iteratively clearing it. To do so, simply pass `optimize_cuda_cache=True` to `DPOConfig`:
```python
-config = PPOConfig(..., optimize_cuda_cache=True)
-```
-
-
-
-## Use score scaling/normalization/clipping
-As suggested by [Secrets of RLHF in Large Language Models Part I: PPO](https://huggingface.co/papers/2307.04964), we support score (aka reward) scaling/normalization/clipping to improve training stability via `PPOConfig`:
-```python
-from trl import PPOConfig
-
-ppo_config = {
- use_score_scaling=True,
- use_score_norm=True,
- score_clip=0.5,
-}
-config = PPOConfig(**ppo_config)
-```
-
-To run `ppo.py`, you can use the following command:
-```
-python examples/scripts/ppo.py --log_with wandb --use_score_scaling --use_score_norm --score_clip 0.5
+training_args = DPOConfig(..., optimize_cuda_cache=True)
```
diff --git a/docs/source/dataset_formats.mdx b/docs/source/dataset_formats.mdx
index 6742d23123..fa69ff1e32 100644
--- a/docs/source/dataset_formats.mdx
+++ b/docs/source/dataset_formats.mdx
@@ -205,7 +205,7 @@ Choosing the right dataset format depends on the task you are working on and the
| [`NashMDTrainer`] | [Prompt-only](#prompt-only) |
| [`OnlineDPOTrainer`] | [Prompt-only](#prompt-only) |
| [`ORPOTrainer`] | [Preference (explicit prompt recommended)](#preference) |
-| [`PPOv2Trainer`] | Tokenized language modeling |
+| [`PPOTrainer`] | Tokenized language modeling |
| [`RewardTrainer`] | [Preference (implicit prompt recommended)](#preference) |
| [`SFTTrainer`] | [Language modeling](#language-modeling) |
| [`XPOTrainer`] | [Prompt-only](#prompt-only) |
diff --git a/docs/source/detoxifying_a_lm.mdx b/docs/source/detoxifying_a_lm.mdx
index e63fa4ebff..30c7d5a930 100644
--- a/docs/source/detoxifying_a_lm.mdx
+++ b/docs/source/detoxifying_a_lm.mdx
@@ -98,19 +98,15 @@ model = AutoModelForCausalLM.from_pretrained("EleutherAI/gpt-j-6B", torch_dtype=
and the optimizer will take care of computing the gradients in `bfloat16` precision. Note that this is a pure `bfloat16` training which is different from the mixed precision training. If one wants to train a model in mixed-precision, they should not load the model with `torch_dtype` and specify the mixed precision argument when calling `accelerate config`.
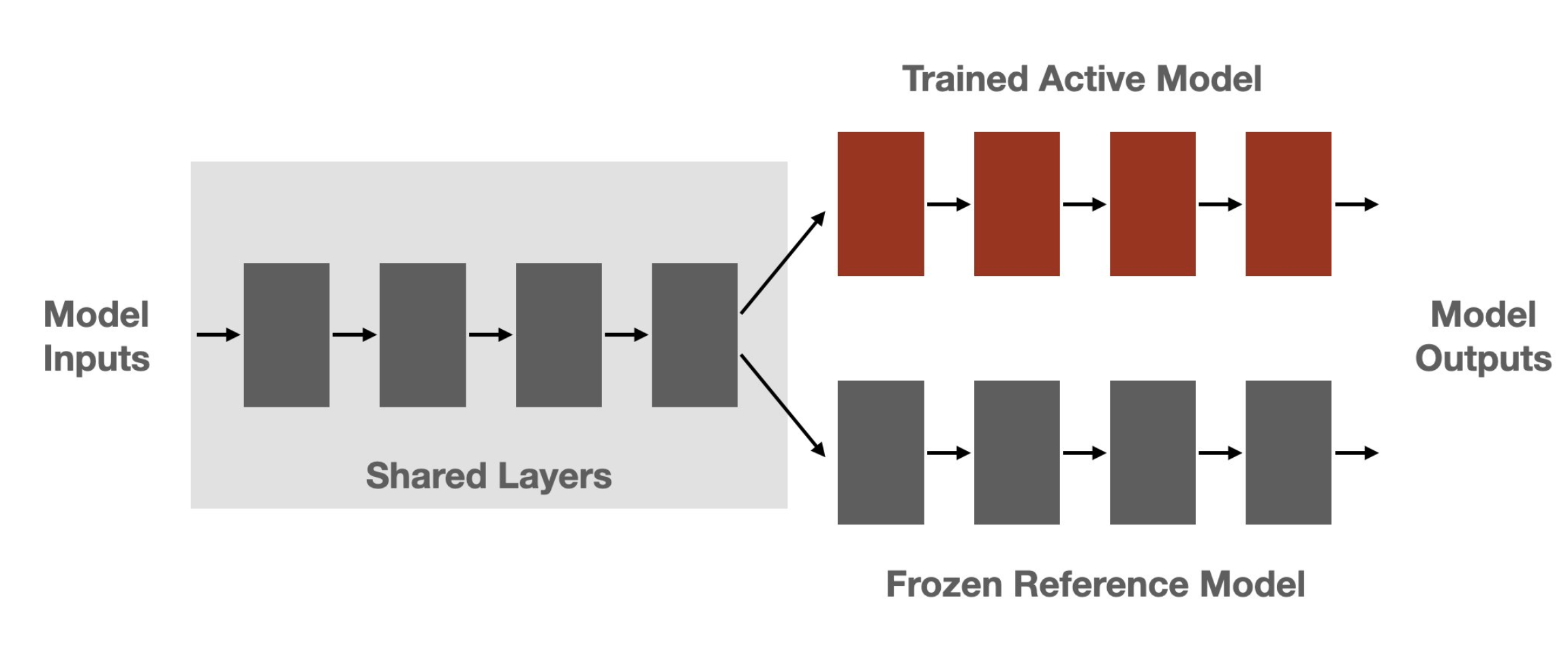
-- Use shared layers: Since PPO algorithm requires to have both the active and reference model to be on the same device, we have decided to use shared layers to reduce the memory footprint of the model. This can be achieved by just speifying `num_shared_layers` argument when creating a `PPOTrainer`:
+- Use shared layers: Since PPO algorithm requires to have both the active and reference model to be on the same device, we have decided to use shared layers to reduce the memory footprint of the model. This can be achieved by specifying `num_shared_layers` argument when calling the `create_reference_model()` function. For example, if you want to share the first 6 layers of the model, you can do it like this:
```python
-ppo_trainer = PPOTrainer(
- model=model,
- tokenizer=tokenizer,
- num_shared_layers=4,
- ...
-)
+ref_policy = create_reference_model(model, num_shared_layers=6)
+trainer = PPOTrainer(..., ref_policy=ref_policy)
```
In the example above this means that the model have the 4 first layers frozen (i.e. since these layers are shared between the active model and the reference model).
diff --git a/docs/source/dpo_trainer.mdx b/docs/source/dpo_trainer.mdx
index 66e55940c9..f9d01074ed 100644
--- a/docs/source/dpo_trainer.mdx
+++ b/docs/source/dpo_trainer.mdx
@@ -12,7 +12,7 @@ The abstract from the paper is the following:
The first step is to train an SFT model, to ensure the data we train on is in-distribution for the DPO algorithm.
-Then, fine-tuning a language model via DPO consists of two steps and is easier than [PPO](ppov2_trainer):
+Then, fine-tuning a language model via DPO consists of two steps and is easier than [PPO](ppo_trainer):
1. **Data collection**: Gather a [preference dataset](dataset_formats#preference) with positive and negative selected pairs of generation, given a prompt.
2. **Optimization**: Maximize the log-likelihood of the DPO loss directly.
diff --git a/docs/source/example_overview.md b/docs/source/example_overview.md
index 16686e5fe4..d239199810 100644
--- a/docs/source/example_overview.md
+++ b/docs/source/example_overview.md
@@ -44,8 +44,8 @@ Then, it is encouraged to launch jobs with `accelerate launch`!
| [`examples/scripts/dpo.py`](https://github.com/huggingface/trl/blob/main/examples/scripts/dpo.py) | This script shows how to use the [`DPOTrainer`] to fine-tune a stable to increase helpfulness and harmlessness using the [Anthropic/hh-rlhf](https://huggingface.co/datasets/Anthropic/hh-rlhf) dataset. |
| [`examples/scripts/kto.py`](https://github.com/huggingface/trl/blob/main/examples/scripts/kto.py) | This script shows how to use the [`KTOTrainer`] to fine-tune a model. |
| [`examples/scripts/orpo.py`](https://github.com/huggingface/trl/blob/main/examples/scripts/orpo.py) | This script shows how to use the [`ORPOTrainer`] to fine-tune a model to increase helpfulness and harmlessness using the [Anthropic/hh-rlhf](https://huggingface.co/datasets/Anthropic/hh-rlhf) dataset. |
-| [`examples/scripts/ppo_multi_adapter.py`](https://github.com/huggingface/trl/blob/main/examples/scripts/ppo_multi_adapter.py) | This script shows how to use the [`PPOTrainer`] to train a single base model with multiple adapters. Requires you to run the example script with the reward model training beforehand. |
-| [`examples/scripts/ppo.py`](https://github.com/huggingface/trl/blob/main/examples/scripts/ppo.py) | This script shows how to use the [`PPOTrainer`] to fine-tune a sentiment analysis model using [IMDB dataset](https://huggingface.co/datasets/stanfordnlp/imdb). |
+| [`examples/scripts/ppo/ppo.py`](https://github.com/huggingface/trl/blob/main/examples/scripts/ppo/ppo.py) | This script shows how to use the [`PPOTrainer`] to fine-tune a model to improve its ability to continue text with positive sentiment or physically descriptive language |
+| [`examples/scripts/ppo/ppo_tldr.py`](https://github.com/huggingface/trl/blob/main/examples/scripts/ppo/ppo_tldr.py) | This script shows how to use the [`PPOTrainer`] to fine-tune a model to improve its ability to generate TL;DR summaries. |
| [`examples/scripts/reward_modeling.py`](https://github.com/huggingface/trl/blob/main/examples/scripts/reward_modeling.py) | This script shows how to use the [`RewardTrainer`] to train a reward model on your own dataset. |
| [`examples/scripts/sft.py`](https://github.com/huggingface/trl/blob/main/examples/scripts/sft.py) | This script shows how to use the [`SFTTrainer`] to fine-tune a model or adapters into a target dataset. |
| [`examples/scripts/sft_vlm.py`](https://github.com/huggingface/trl/blob/main/examples/scripts/sft_vlm.py) | This script shows how to use the [`SFTTrainer`] to fine-tune a Vision Language Model in a chat setting. The script has only been tested with [LLaVA 1.5](https://huggingface.co/llava-hf/llava-1.5-7b-hf), [LLaVA 1.6](https://huggingface.co/llava-hf/llava-v1.6-mistral-7b-hf), and [Llama-3.2-11B-Vision-Instruct](https://huggingface.co/meta-llama/Llama-3.2-11B-Vision-Instruct) models so users may see unexpected behaviour in other model architectures. |
diff --git a/docs/source/logging.mdx b/docs/source/logging.mdx
index 71eb7c4137..4c60868dac 100644
--- a/docs/source/logging.mdx
+++ b/docs/source/logging.mdx
@@ -1,15 +1,14 @@
# Logging
As reinforcement learning algorithms are historically challenging to debug, it's important to pay careful attention to logging.
-By default, the TRL [`PPOTrainer`] saves a lot of relevant information to `wandb` or `tensorboard`.
+By default, the TRL [`PPOTrainer`] saves a lot of relevant information to wandb or tensorboard.
Upon initialization, pass one of these two options to the [`PPOConfig`]:
+
```
-config = PPOConfig(
- model_name=args.model_name,
- log_with=`wandb`, # or `tensorboard`
-)
+training_args = PPOConfig(..., report_to="wandb") # or "tensorboard"
```
+
If you want to log with tensorboard, add the kwarg `project_kwargs={"logging_dir": PATH_TO_LOGS}` to the PPOConfig.
## PPO Logging
diff --git a/docs/source/ppov2_trainer.md b/docs/source/ppo_trainer.md
similarity index 98%
rename from docs/source/ppov2_trainer.md
rename to docs/source/ppo_trainer.md
index 93adf0ffdc..414c051abc 100644
--- a/docs/source/ppov2_trainer.md
+++ b/docs/source/ppo_trainer.md
@@ -1,4 +1,4 @@
-# PPOv2 Trainer
+# PPO Trainer
[](https://huggingface.co/models?other=ppo,trl)
@@ -167,7 +167,7 @@ In the logs the sampled generations look like
## Implementation details
-This PPOv2 implementation is based on the [The N+ Implementation Details of RLHF with PPO: A Case Study on TL;DR Summarization](https://huggingface.co/papers/2403.17031).
+This PPO implementation is based on the [The N+ Implementation Details of RLHF with PPO: A Case Study on TL;DR Summarization](https://huggingface.co/papers/2403.17031).
## Benchmark experiments
@@ -222,14 +222,14 @@ python -m openrlbenchmark.rlops_multi_metrics \
--pc.ncols 4 \
--pc.ncols-legend 1 \
--pc.xlabel "Episode" \
- --output-filename benchmark/trl/pr-1540/ppov2 \
+ --output-filename benchmark/trl/pr-1540/ppo \
--scan-history
```
-## PPOv2Trainer
+## PPOTrainer
-[[autodoc]] PPOv2Trainer
+[[autodoc]] PPOTrainer
-## PPOv2Config
+## PPOConfig
-[[autodoc]] PPOv2Config
\ No newline at end of file
+[[autodoc]] PPOConfig
\ No newline at end of file
diff --git a/docs/source/ppo_trainer.mdx b/docs/source/ppo_trainer.mdx
deleted file mode 100644
index ebc97a9e28..0000000000
--- a/docs/source/ppo_trainer.mdx
+++ /dev/null
@@ -1,173 +0,0 @@
-# PPO Trainer
-
-[](https://huggingface.co/models?other=ppo,trl)
-
-TRL supports the [PPO](https://huggingface.co/papers/1707.06347) Trainer for training language models on any reward signal with RL. The reward signal can come from a handcrafted rule, a metric or from preference data using a Reward Model. For a full example have a look at [`examples/notebooks/gpt2-sentiment.ipynb`](https://github.com/lvwerra/trl/blob/main/examples/notebooks/gpt2-sentiment.ipynb). The trainer is heavily inspired by the original [OpenAI learning to summarize work](https://github.com/openai/summarize-from-feedback).
-
-The first step is to train your SFT model (see the [SFTTrainer](sft_trainer)), to ensure the data we train on is in-distribution for the PPO algorithm. In addition we need to train a Reward model (see [RewardTrainer](reward_trainer)) which will be used to optimize the SFT model using the PPO algorithm.
-
-## How PPO works
-
-Fine-tuning a language model via PPO consists of roughly three steps:
-
-1. **Rollout**: The language model generates a response or continuation based on query which could be the start of a sentence.
-2. **Evaluation**: The query and response are evaluated with a function, model, human feedback or some combination of them. The important thing is that this process should yield a scalar value for each query/response pair.
-3. **Optimization**: This is the most complex part. In the optimisation step the query/response pairs are used to calculate the log-probabilities of the tokens in the sequences. This is done with the model that is trained and a reference model, which is usually the pre-trained model before fine-tuning. The KL-divergence between the two outputs is used as an additional reward signal to make sure the generated responses don't deviate too far from the reference language model. The active language model is then trained with PPO.
-
-This process is illustrated in the sketch below:
-
-
-

-
Figure: Sketch of the workflow.
-