diff --git a/colossalai/shardformer/README.md b/colossalai/shardformer/README.md
index fca401562be6..c9650ce4f712 100644
--- a/colossalai/shardformer/README.md
+++ b/colossalai/shardformer/README.md
@@ -377,11 +377,49 @@ pytest tests/test_shardformer
### System Performance
-To be added.
+We conducted [benchmark tests](./examples/performance_benchmark.py) to evaluate the performance improvement of Shardformer. We compared the training time between the original model and the shard model.
+
+We set the batch size to 4, the number of attention heads to 8, and the head dimension to 64. 'N_CTX' refers to the sequence length.
+
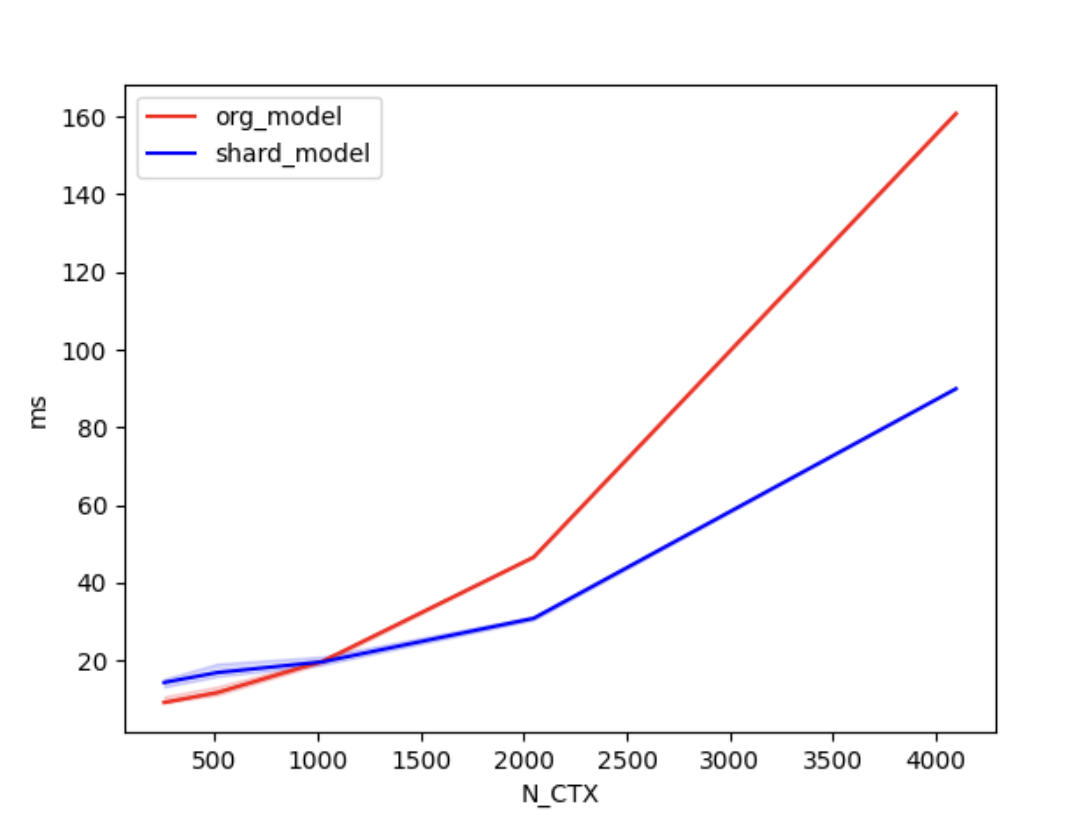
+In the case of using 2 GPUs, the training times are as follows.
+| N_CTX | org_model | shard_model |
+| :------: | :-----: | :-----: |
+| 256 | 11.2ms | 17.2ms |
+| 512 | 9.8ms | 19.5ms |
+| 1024 | 19.6ms | 18.9ms |
+| 2048 | 46.6ms | 30.8ms |
+| 4096 | 160.5ms | 90.4ms |
+
+
+
+  +
+
+
+
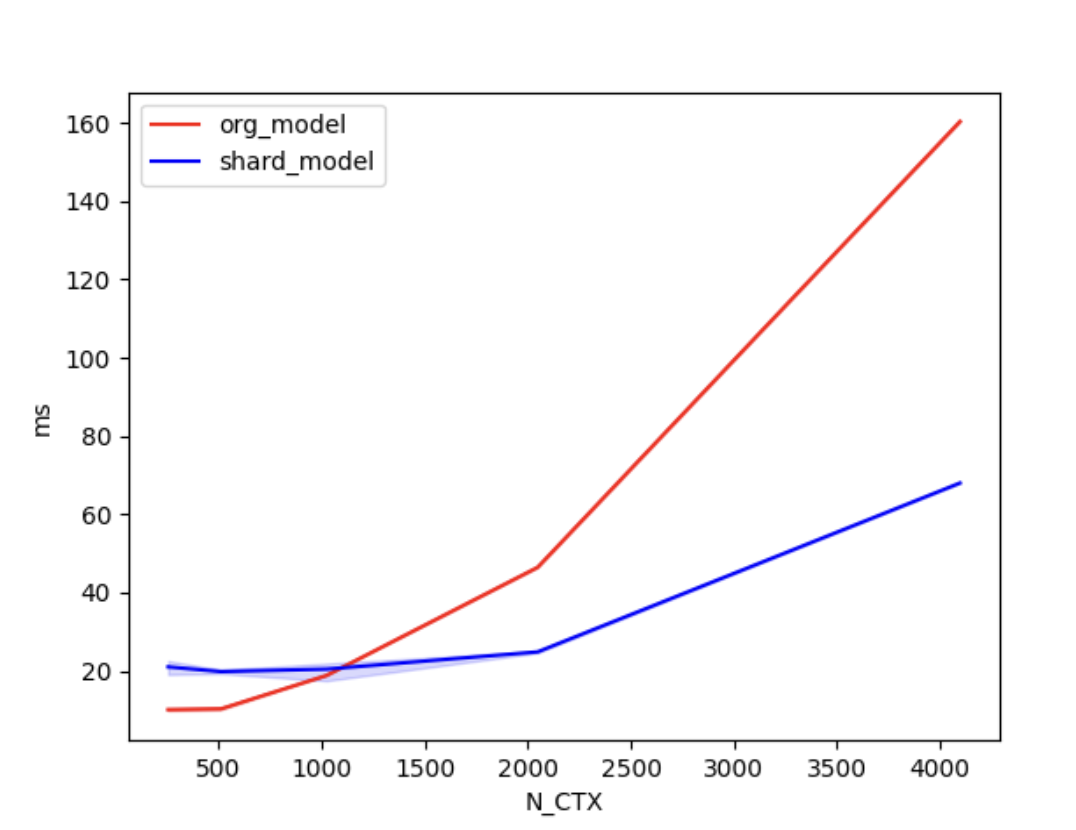
+In the case of using 4 GPUs, the training times are as follows.
+
+| N_CTX | org_model | shard_model |
+| :------: | :-----: | :-----: |
+| 256 | 10.0ms | 21.1ms |
+| 512 | 11.5ms | 20.2ms |
+| 1024 | 22.1ms | 20.6ms |
+| 2048 | 46.9ms | 24.8ms |
+| 4096 | 160.4ms | 68.0ms |
+
+
+
+
+  +
+
+
+
+
+As shown in the figures above, when the sequence length is around 1000 or greater, the parallel optimization of Shardformer for long sequences starts to become evident.
### Convergence
-To validate that training the model using shardformers does not impact its convergence. We [fine-tuned the BERT model](./examples/shardformer_benchmark.py) using both shardformer and non-shardformer approaches. We compared the accuracy, loss, F1 score of the training results.
+
+To validate that training the model using shardformers does not impact its convergence. We [fine-tuned the BERT model](./examples/convergence_benchmark.py) using both shardformer and non-shardformer approaches. We compared the accuracy, loss, F1 score of the training results.
| accuracy | f1 | loss | GPU number | model shard |
| :------: | :-----: | :-----: | :--------: | :---------: |
diff --git a/colossalai/shardformer/examples/shardformer_benchmark.py b/colossalai/shardformer/examples/convergence_benchmark.py
similarity index 100%
rename from colossalai/shardformer/examples/shardformer_benchmark.py
rename to colossalai/shardformer/examples/convergence_benchmark.py
diff --git a/colossalai/shardformer/examples/shardformer_benchmark.sh b/colossalai/shardformer/examples/convergence_benchmark.sh
similarity index 76%
rename from colossalai/shardformer/examples/shardformer_benchmark.sh
rename to colossalai/shardformer/examples/convergence_benchmark.sh
index f42b19a32d35..1c281abcda6d 100644
--- a/colossalai/shardformer/examples/shardformer_benchmark.sh
+++ b/colossalai/shardformer/examples/convergence_benchmark.sh
@@ -1,4 +1,4 @@
-torchrun --standalone --nproc_per_node=4 shardformer_benchmark.py \
+torchrun --standalone --nproc_per_node=4 convergence_benchmark.py \
--model "bert" \
--pretrain "bert-base-uncased" \
--max_epochs 1 \
diff --git a/colossalai/shardformer/examples/performance_benchmark.py b/colossalai/shardformer/examples/performance_benchmark.py
new file mode 100644
index 000000000000..9c7b76bcf0a6
--- /dev/null
+++ b/colossalai/shardformer/examples/performance_benchmark.py
@@ -0,0 +1,86 @@
+"""
+Shardformer Benchmark
+"""
+import torch
+import torch.distributed as dist
+import transformers
+import triton
+
+import colossalai
+from colossalai.shardformer import ShardConfig, ShardFormer
+
+
+def data_gen(batch_size, seq_length):
+ input_ids = torch.randint(0, seq_length, (batch_size, seq_length), dtype=torch.long)
+ attention_mask = torch.ones((batch_size, seq_length), dtype=torch.long)
+ return dict(input_ids=input_ids, attention_mask=attention_mask)
+
+
+def data_gen_for_sequence_classification(batch_size, seq_length):
+ # LM data gen
+ # the `labels` of LM is the token of the output, cause no padding, use `input_ids` as `labels`
+ data = data_gen(batch_size, seq_length)
+ data['labels'] = torch.ones((batch_size), dtype=torch.long)
+ return data
+
+
+MODEL_CONFIG = transformers.LlamaConfig(num_hidden_layers=4,
+ hidden_size=128,
+ intermediate_size=256,
+ num_attention_heads=4,
+ max_position_embeddings=128,
+ num_labels=16)
+BATCH, N_HEADS, N_CTX, D_HEAD = 4, 8, 4096, 64
+model_func = lambda: transformers.LlamaForSequenceClassification(MODEL_CONFIG)
+
+# vary seq length for fixed head and batch=4
+configs = [
+ triton.testing.Benchmark(x_names=['N_CTX'],
+ x_vals=[2**i for i in range(8, 13)],
+ line_arg='provider',
+ line_vals=['org_model', 'shard_model'],
+ line_names=['org_model', 'shard_model'],
+ styles=[('red', '-'), ('blue', '-')],
+ ylabel='ms',
+ plot_name=f'lama_for_sequence_classification-batch-{BATCH}',
+ args={
+ 'BATCH': BATCH,
+ 'dtype': torch.float16,
+ 'model_func': model_func
+ })
+]
+
+
+def train(model, data):
+ output = model(**data)
+ loss = output.logits.mean()
+ loss.backward()
+
+
+@triton.testing.perf_report(configs)
+def bench_shardformer(BATCH, N_CTX, provider, model_func, dtype=torch.float32, device="cuda"):
+ warmup = 10
+ rep = 100
+ # prepare data
+ data = data_gen_for_sequence_classification(BATCH, N_CTX)
+ data = {k: v.cuda() for k, v in data.items()}
+ model = model_func().to(device)
+ model.train()
+ if provider == "org_model":
+ fn = lambda: train(model, data)
+ ms = triton.testing.do_bench(fn, warmup=warmup, rep=rep)
+ return ms
+ if provider == "shard_model":
+ shard_config = ShardConfig(enable_fused_normalization=True, enable_tensor_parallelism=True)
+ shard_former = ShardFormer(shard_config=shard_config)
+ sharded_model = shard_former.optimize(model).cuda()
+ fn = lambda: train(sharded_model, data)
+ ms = triton.testing.do_bench(fn, warmup=warmup, rep=rep)
+ return ms
+
+
+# start benchmark, command:
+# torchrun --standalone --nproc_per_node=2 performance_benchmark.py
+if __name__ == "__main__":
+ colossalai.launch_from_torch({})
+ bench_shardformer.run(save_path='.', print_data=dist.get_rank() == 0)