আমরা আজকের অধ্যায়ে লিনিয়ার রিগ্রেশন মডেল স্ক্র্যাচ থেকে তৈরি করা শিখব। তবে এটা করার আগে আপনার অবশ্যই Numpy সম্পর্কে ধারণা থাকতে হবে। না থাকলে এই অধ্যায়টি পড়ে নিন। তাহলে শুরু করা যাক।
লিনিয়ার রিগ্রেশন মডেল বিল্ড করার জন্য আমি এখানে ব্যবহার করছি Andrew Ng এর Machine Learning কোর্সের লিনিয়ার রিগ্রেশন চ্যাপ্টারের ডেটাসেট। তবে সামান্য একটু পার্থক্য আছে। আমার দেওয়া ডেটাসেট কিছুটা পরিবর্তিত এবং পরিবর্তনটা হল প্রথম সারিতে শুধু দুইটা কলাম যোগ করে দিয়েছি। ডেটাসেট দেখতে বা ডাউনলোড করতে এখানে ক্লিক করুন
সর্বপ্রথম আমরা যে কাজটি করব, সেটা হল আমার সংগৃহীত ডেটাসেট এর একটি স্ক্যাটার প্লট ড্র করা। আমি এখানে Seaborn লাইব্রেরি ব্যবহার করব। Seaborn লাইব্রেরিটি matplotlib এর উপর ভিত্তি করে তৈরি করা। ডেটা ভিজুয়ালাইজেশন সহজ করার জন্য অনেক ফিচার এতে বিল্ট-ইন আছে।
কমান্ড উইন্ডো বা টার্মিনালে নিচের কমান্ডটি রান করুন,
pip install seaborn
import csv
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
import pandas as pd
import numpy as np
# Loading Dataset
with open('ex1data1.txt') as csvfile:
population, profit = zip(*[(float(row['Population']), float(row['Profit'])) for row in csv.DictReader(csvfile)])
# Creating DataFrame
df = pd.DataFrame()
df['Population'] = population
df['Profit'] = profit
# Plotting using Seaborn
sns.lmplot(x="Population", y="Profit", data=df, fit_reg=False, scatter_kws={'s':45})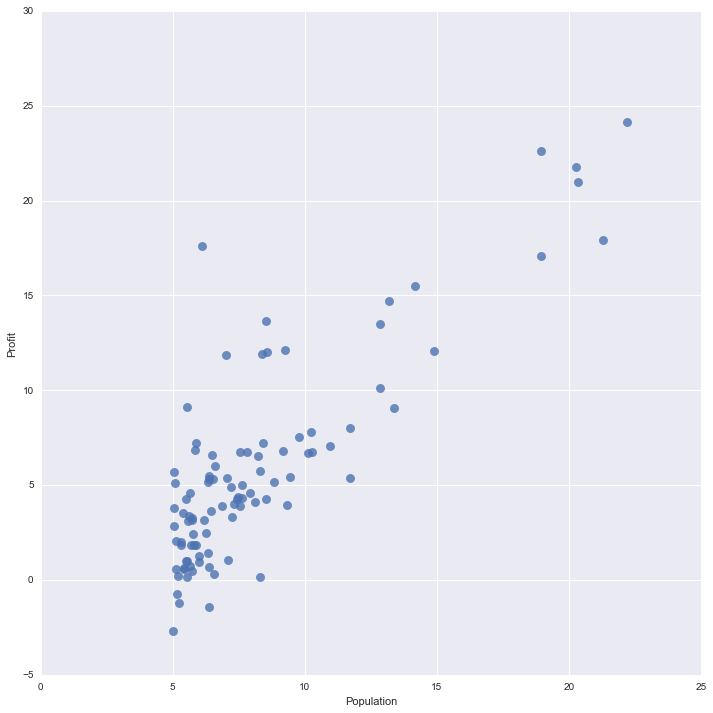
ব্যাখ্যা
ডেটাসেট লোড ও ডেটাফ্রেম তৈরি
প্রথমেই আমি ডেটাসেট লোড করে দুইটা পাইথন লিস্টে ইনপুট ডেটা Population ও আউটপুট ডেটা / টার্গেট / লেবেল নিলাম Profit লিস্টে। দুইটা লিস্ট দিয়ে একটা পান্ডাস ডেটাফ্রেম তৈরি করলাম।
প্লটিং
lmplot ফাংশন ব্যবহার করে স্ক্যাটারপ্লট তৈরি করলাম যেখানে x ও y দিয়ে যথাক্রমে X ও Y অক্ষে লেবেলিং করলাম এবং তৈরিকৃত ডেটাফ্রেমকে ডেটা হিসেবে পাস করলাম। fit_reg এর মান যদি True হত তাহলে গ্রাফটি দেখাত এমন, অর্থাৎ Seaborn একটা লিনিয়ার মডেলকে ফিট করে দেখাত। কিন্তু আমাদের মূল কাজটা সেটাই, গ্রেডিয়েন্ট ডিসেন্ট অ্যালগরিদম ব্যবহারের মাধ্যমে করতে হবে। scatter_kws={'s':45} দিয়ে আমি স্ক্যাটার ডট গুলোর আকার পরিবর্তন করলাম।
fit_reg=True হলে প্লট যেমন দেখাত
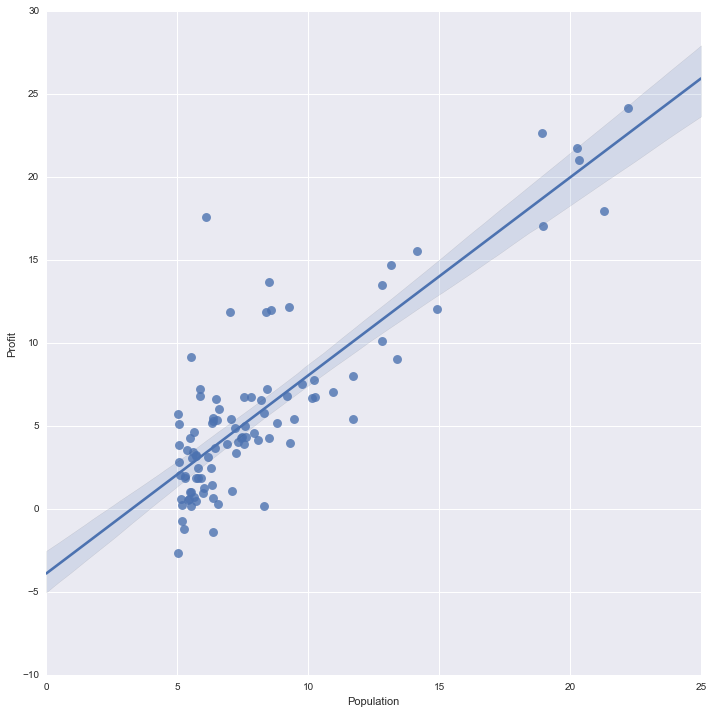
এই পর্যন্ত আমরা গ্রেডিয়েন্ট ডিসেন্ট ও কস্ট ক্যালকুলেশনের ব্যাপার স্যাপার দেখলাম। কিন্তু কোড এ হাত দেওয়ার আগে, থিওরি টা আরেকটু ভালভাবে ঝালাই দেওয়া দরকার। কোড লেখার চাইতে গুরুত্বপূর্ণ বিষয় হল ভিজুয়ালাইজেশন। চলুন আমরা একটু ভিজুয়ালাইজ করে গ্রেডিয়েন্ট ডিসেন্ট প্রয়োগ করি।
আমরা কস্ট ক্যালকুলেশনের সূত্রানুযায়ী জানি,
এই ফরমুলা অ্যাপ্লাই করতে গেলে বুঝতেই পারছেন, লুপের ব্যবহার লাগবে। কিন্তু না, আমরা কাজটা Numpy ব্যবহার করে খুব সহজেই করতে পারি ম্যাট্রিক্স অপারেশনের মাধ্যমে। কোন নোটেশনের মানে কী সেটা আগের অধ্যায়গুলোতে বলা আছে। তাও আমি একটা সাধারণ উদাহরণের মাধ্যমে আবার দেখাই।
ধরি আমার ডেটাসেট এইটা,
| আয় |
ব্যয় |
|
|---|---|---|
| 1 | 10 | 5 |
| 2 | 20 | 10 |
| 3 | 30 | 15 |
যেখানে,
লিনিয়ার রিগ্রেশন সূত্র,
$$h_{\theta}(X)=\theta \times X = \theta_{0} \times X^{0}{i} + \theta{1} \times X^{1}{i} = \theta{0} + \theta_{1} \times X$$
কিন্তু আমাদের থিটা এর ডাইমেনশন
এবং
তাহলে আমাদের হাইপোথিসিস হবে প্রতিটা কলামের জন্য,
ম্যাট্রিক্স আকারে লিখলে,
আউটপুট বা টার্গেট ম্যাট্রিক্স,
ম্যাট্রিক্স আকারে ক্যালকুলেটেড কস্ট সূত্র
$$
J(\theta_{0}, \theta_{1}) = \frac{1}{2\times3} \sum_{i=1}^{3} \left( \left[ \begin{array} {cc} 1&x_{1} \ 1& x_{2} \1& x_{3} \end{array} \right] \times \left[ \begin{array} {cc} \theta_{0} \ \theta_{1} \end{array} \right] - \left[ \begin{array} {cc} y_{1} \ y_{2} \ y_{3} \end{array} \right] \right)^{2}
\
=\frac{1}{6} \sum_{i=1}^{3} \left( \left[ \begin{array} {cc} \theta_{0} \times 1 + \theta_{1} \times x_{1} \ \theta_{0} \times 1 + \theta_{1} \times x_{2} \\theta_{0} \times 1 + \theta_{1} \times x_{3} \end{array} \right] - \left[ \begin{array} {cc} y_{1} \ y_{2} \ y_{3} \end{array} \right]
\right)^{2}
\
= \frac{1}{6} \sum_{i=1}^{3} \left( \left[ \begin{array} {cc} \theta_{0} + \theta_{1} \times x_{1} - y_{1} \ \theta_{0} + \theta_{1} \times x_{2} - y_{2}
\\theta_{0} + \theta_{1} \times x_{3} - y_{3} \end{array} \right] \right)^{2}
\
= \frac{1}{6} \left{ (\theta_{0}+\theta_{1}x_{1}-y_{1})^{2} + (\theta_{0}+\theta_{1}x_{2}-y_{2})^{2} + (\theta_{0}+\theta_{1}x_{3}-y_{3})^{2} \right} $$
বাড়ির কাজ
গ্রেডিয়েন্ট ডিসেন্ট ফরমুলা ম্যাট্রিক্স আকারে লিখুন।
এই ম্যাট্রিক্স ক্যালকুলেশনটাই আমরা পাইথনে লিখব। এসব কারণেই মেশিন লার্নিংয়ের ক্যালকুলশন দ্রুত বুঝতে ও করতে লিনিয়ার অ্যালজেব্রার সলিড ফাউন্ডেশন দরকার। যে ভাল লিনিয়ার অ্যালজেব্রা ও ক্যালকুলাস বোঝে তার জন্য মেশিন লার্নিংয়ের অ্যালগরিদম অ্যাপ্লাই করা খুবই সহজ।
এখন আমরা Numpy ব্যবহার করে 97 অবজারভেশনের ডেটাসেট এর কস্ট ক্যালকুলেশন ও গ্রেডিয়েন্ট ডিসেন্ট এর ফাংশন লিখব।
# Here, X, y and theta are 2D numpy array
def computeCost(X, y, theta):
# Getting number of observations
m = len(y)
# Getting hypothesis output
hypothesis = X.dot(theta)
# Computing loss
loss = hypothesis - y
# Computing cost
cost = sum(loss**2)
# Returning cost
return (cost / (2 * m))-
কতটা অবজারভেশন আছে সেটা একটা
mএ রাখলাম -
হাইপোথিসিস ভ্যালু বের করলাম
-
lossবের করলাম, যেটা কিনা আসল মান ও প্রেডিক্টেড মানের বিয়োগফল -
costবের করলাম, যেটাlossএর বর্গের যোগফল -
average costরিটার্ন করলামপাইথনে গ্রেডিয়েন্ট ডিসেন্ট ক্যালকুলেশন ফাংশন
def gradientDescent(X, y, theta, alpha, iterations):
cost = []
m = len(y)
for i in range(iterations):
# Calculating Loss
loss = X.dot(theta) - y
# Calculating gradient
gradient = X.T.dot(loss)
# Updating theta
theta = theta - (alpha / m) * gradient
# Recording the costs
cost.append(computeCost(X, y, theta))
# Printing out
print("Cost at iteration {0} : {1}".format(i, computeCost(X, y, theta)))
return (theta, cost)- আমরা একটা নির্দিষ্ট ইটারেশন রেঞ্জের মধ্যে প্যারামিটার আপডেট করব, অর্থাৎ, কস্ট একটা নির্দিষ্ট পরিমাণ কমে গেল সেটা আমাদের দেখার বিষয় না, একটা নির্দিষ্ট ইটারেশনে কতটুকু কস্ট কমে গেল। তাই আমরা ইটারেশন ফিক্স করলাম। আরেকটা উপায় হতে পারে, একটা নির্দিষ্ট কস্ট হওয়ার আগ পর্যন্ত ইটারেশন চালিয়েই যাবে। কিন্তু সেটা অনেক ক্ষেত্রে বিপদজনক হতে পারে যেটা আমরা একটু পরেই দেখতে পারব।
# Converting loaded dataset into numpy array
# Example:
# X = [[1, 10],
# [1, 20],
# [1, 30]]
#
X = np.concatenate((np.ones(len(population)).reshape(len(population), 1), population.reshape(len(population),1)), axis=1)
# Example
# y = [[1],
# [2],
# [3]]
y = np.array(profit).reshape(len(profit), 1)
# Creating theta matrix , theta = [[0], [0]]
theta = np.zeros((2, 1))
# Learning rate
alpha = 0.1
# Iterations to be taken
iterations = 1500
# Updated theta and calculated cost
theta, cost = gradientDescent(X, y, theta, alpha, iterations)Cost at iteration 0 : 5.4441412681185035
Cost at iteration 1 : 5.409587207509947
Cost at iteration 2 : 5.376267659177092
Cost at iteration 3 : 5.344138517723003
Cost at iteration 4 : 5.313157253503435
Cost at iteration 5 : 5.2832828563299445
Cost at iteration 6 : 5.254475781184327
......
......
......
Cost at iteration 23 : 177385094.9287188
Cost at iteration 24 : 9252868248.562147
Cost at iteration 25 : 482653703983.4108
Cost at iteration 26 : 25176474129882.656
Cost at iteration 27 : 1313270455375155.5
Cost at iteration 28 : 6.850360698103145e+16
Cost at iteration 29 : 3.573326537732157e+18
গ্রেডিয়েন্ট ডিসেন্ট অ্যালগরিদমের মূল কাজ কস্ট মিনিমাইজ করা, কিন্তু ইটারেশন 29 এই দেখুন কস্ট বেড়ে কত হয়েছে! এটা হওয়ার কারণ কী?
আমরা যদি লার্নিং রেট আরেকটু কমিয়ে কোড রান করি তাহলে,
# Creating theta matrix , theta = [[0], [0]]
theta = np.zeros((2, 1))
# Learning rate
alpha = 0.01
# Iterations to be taken
iterations = 1500
# Updated theta and calculated cost
theta, cost = gradientDescent(X, y, theta, alpha, iterations)আউটপুট
Cost at iteration 0 : 6.737190464870004
Cost at iteration 1 : 5.9315935686049555
Cost at iteration 2 : 5.901154707081388
Cost at iteration 3 : 5.895228586444221
Cost at iteration 4 : 5.8900949431173295
Cost at iteration 5 : 5.885004158443647
Cost at iteration 6 : 5.879932480491418
Cost at iteration 7 : 5.874879094762575
Cost at iteration 8 : 5.869843911806385
....
....
....
Cost at iteration 1497 : 4.483434734017543
Cost at iteration 1498 : 4.483411453374869
Cost at iteration 1499 : 4.483388256587726
এবার দেখুন কস্ট আসলেই কমছে। অর্থাৎ আমাদের গ্রেডিয়েন্ট ডিসেন্ট অ্যালগরিদম ঠিকঠাক কাজ করছে। লার্নিং রেট কমাতেই ওভারশুটিং হচ্ছে না এবং গ্রেডিয়েন্ট হিল বেয়েই সে নিচে নামছে!
আপনি যদি এই অধ্যায়টি পড়ে থাকেন তাহলে বুঝবেন লার্নিং রেট বেশি হওয়ার কারণে সে মিনিমাম পয়েন্টে কনভার্জ না করে ওভারশুট হওয়াতে শুধু উপরের দিকে যাচ্ছিল।

import matplotlib.pyplot as plt
plt.plot([i for i in range(1500)], cost, linewidth=1.9)
plt.xlabel("Iterations")
plt.ylabel('Cost')
plt.show()আমরা যদি ইটারেশন vs কস্ট এর গ্রাফ প্লট করি তাহলে এটা দেখাবে এইরকম,
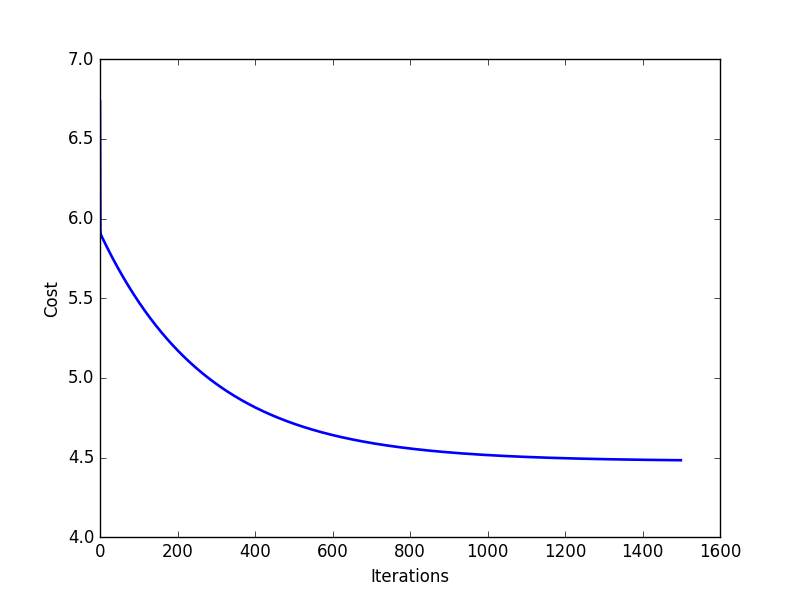
আমরা এতক্ষণ সিঙ্গেল ভ্যারিয়েবল লিনিয়ার রিগ্রেশন দেখলাম। মাল্টিভ্যারিয়েবলের ক্ষেত্রে কাজ পুরোপুরি একই, তবে কলাম সংখ্যা বেড়ে যাবে। তাতেও ম্যাট্রিক্স নোটেশন একই থাকবে।
পরবর্তী পর্বে গ্রেডিয়েন্ট ডিসেন্ট ম্যাট্রিক্স নোটেশনে প্রকাশ ও মাল্টিভ্যারিয়েবল লিনিয়ার রিগ্রেশনের জন্য মডেল তৈরি করব।