 +
+ + Multiple testing correction: q values +
+
+
+ var x = Enumerable.Range(1, 63).Select(x => x * 0.1);
-var y = x.Select(x => System.Math.Sin(x));
+var x = Enumerable.Range(1, 63).Select(x => x * 0.1);
+var y = x.Select(x => System.Math.Sin(x));
#r "nuget: Plotly.NET, 3.0.0"
-#r "nuget: Plotly.NET.Interactive, 3.0.0"
-#r "nuget: Plotly.NET.CSharp"
+#r "nuget: Plotly.NET, 3.0.0"
+#r "nuget: Plotly.NET.Interactive, 3.0.0"
+#r "nuget: Plotly.NET.CSharp"
using Plotly.NET.CSharp;
+using Plotly.NET.CSharp;
-Chart.Scatter<double,double,string>(
- x: x,
- y: y,
- mode: Plotly.NET.StyleParam.Mode.Markers
-)
+Chart.Scatter<double,double,string>(
+ x: x,
+ y: y,
+ mode: Plotly.NET.StyleParam.Mode.Markers
+)
Chart.Point<double, double, string>(
- x: x,
- y: y,
- Name: "y = sin(x)",
- ShowLegend: true
-)
- .WithXAxisStyle<string,string,string>(TitleText: "x")
- .WithYAxisStyle<string,string,string>(TitleText: "y")
+Chart.Point<double, double, string>(
+ x: x,
+ y: y,
+ Name: "y = sin(x)",
+ ShowLegend: true
+)
+ .WithXAxisStyle<string,string,string>(TitleText: "x")
+ .WithYAxisStyle<string,string,string>(TitleText: "y")
Chart.Line<double, double, string>(
- x: x,
- y: y
-)
- .WithXAxisStyle<string, string, string>(TitleText: "time [s]")
- .WithYAxisStyle<string, string, string>(TitleText: "some observation value")
+Chart.Line<double, double, string>(
+ x: x,
+ y: y
+)
+ .WithXAxisStyle<string, string, string>(TitleText: "time [s]")
+ .WithYAxisStyle<string, string, string>(TitleText: "some observation value")
var rnd = new System.Random(69);
-var rnd_x = Enumerable.Range(0,200).Select(x =>rnd.NextDouble());
-var rnd_y = Enumerable.Range(0,200).Select(x =>rnd.NextDouble());
-
-Chart.Grid(
- nRows: 1,
- nCols: 2,
- gCharts: new Plotly.NET.GenericChart.GenericChart [] {
- Chart.Point<double, double, string>(
- x: rnd_x,
- y: rnd_y,
- Name: "Point cloud"
- )
- .WithXAxisStyle<string, string, string>(TitleText: "x")
- .WithYAxisStyle<string, string, string>(TitleText: "y"),
-
- Chart.Line<double, double, string>(
- x: rnd_x,
- y: rnd_y,
- Name: "lines"
- )
- .WithXAxisStyle<string, string, string>(TitleText: "x")
- .WithYAxisStyle<string, string, string>(TitleText: "y")
- }
-)
- .WithSize(Width: 1000, Height: 600)
+var rnd = new System.Random(69);
+var rnd_x = Enumerable.Range(0,200).Select(x =>rnd.NextDouble());
+var rnd_y = Enumerable.Range(0,200).Select(x =>rnd.NextDouble());
+
+Chart.Grid(
+ nRows: 1,
+ nCols: 2,
+ gCharts: new Plotly.NET.GenericChart.GenericChart [] {
+ Chart.Point<double, double, string>(
+ x: rnd_x,
+ y: rnd_y,
+ Name: "Point cloud"
+ )
+ .WithXAxisStyle<string, string, string>(TitleText: "x")
+ .WithYAxisStyle<string, string, string>(TitleText: "y"),
+
+ Chart.Line<double, double, string>(
+ x: rnd_x,
+ y: rnd_y,
+ Name: "lines"
+ )
+ .WithXAxisStyle<string, string, string>(TitleText: "x")
+ .WithYAxisStyle<string, string, string>(TitleText: "y")
+ }
+)
+ .WithSize(Width: 1000, Height: 600)
// A Land
-var gdp_a = new int [] {20, 25, 35, 40, 50};
-var population_a = new int [] {500, 530, 520, 500, 510};
+var gdp_a = new int [] {20, 25, 35, 40, 50};
+var population_a = new int [] {500, 530, 520, 500, 510};
//B Land
-var gdp_b = new int [] {30, 30, 33, 31, 35};
-var population_b = new int [] {400, 500, 600, 700, 800};
-
-var times = new int [] {1900, 1910, 1920, 1930, 1940};
-
-Chart.Combine(
- gCharts: new Plotly.NET.GenericChart.GenericChart [] {
- Chart.Bubble<int, int, int>(
- x: times,
- y: population_a,
- sizes: gdp_a,
- Name: "ALand",
+var gdp_b = new int [] {30, 30, 33, 31, 35};
+var population_b = new int [] {400, 500, 600, 700, 800};
+
+var times = new int [] {1900, 1910, 1920, 1930, 1940};
+
+Chart.Combine(
+ gCharts: new Plotly.NET.GenericChart.GenericChart [] {
+ Chart.Bubble<int, int, int>(
+ x: times,
+ y: population_a,
+ sizes: gdp_a,
+ Name: "ALand",
MultiText: gdp_a, // show gdp values as text in addition to bubble size
TextPosition: Plotly.NET.StyleParam.TextPosition.Auto // set textposition to make gdp values visible
- ),
+ ),
- Chart.Bubble<int, int, int>(
- x: times,
- y: population_b,
- sizes: gdp_b,
- Name: "ALand",
+ Chart.Bubble<int, int, int>(
+ x: times,
+ y: population_b,
+ sizes: gdp_b,
+ Name: "ALand",
MultiText: gdp_b, // show gdp values as text in addition to bubble size
TextPosition: Plotly.NET.StyleParam.TextPosition.Auto // set textposition to make gdp values visible
- )
- }
-)
- .WithXAxisStyle<string, string, string>(TitleText: "Time [y]")
- .WithYAxisStyle<string, string, string>(TitleText: "Population [Million]")
+ )
+ }
+)
+ .WithXAxisStyle<string, string, string>(TitleText: "Time [y]")
+ .WithYAxisStyle<string, string, string>(TitleText: "Population [Million]")
using Plotly.NET.TraceObjects;
-
-Chart.Combine(
- gCharts: new Plotly.NET.GenericChart.GenericChart [] {
- Chart.Scatter<int, int, int>(
- x: times,
- y: population_a,
- mode: Plotly.NET.StyleParam.Mode.Lines_Markers_Text,
- Name: "ALand",
- MultiText: gdp_a,
+using Plotly.NET.TraceObjects;
+
+Chart.Combine(
+ gCharts: new Plotly.NET.GenericChart.GenericChart [] {
+ Chart.Scatter<int, int, int>(
+ x: times,
+ y: population_a,
+ mode: Plotly.NET.StyleParam.Mode.Lines_Markers_Text,
+ Name: "ALand",
+ MultiText: gdp_a,
TextPosition: Plotly.NET.StyleParam.TextPosition.Auto,
Marker: Marker.init(MultiSize:gdp_a) // the marker object controls the style of the individual points
- ),
-
- Chart.Scatter<int, int, int>(
- x: times,
- y: population_b,
- mode: Plotly.NET.StyleParam.Mode.Lines_Markers_Text,
- Name: "ALand",
- MultiText: gdp_b,
+ ),
+
+ Chart.Scatter<int, int, int>(
+ x: times,
+ y: population_b,
+ mode: Plotly.NET.StyleParam.Mode.Lines_Markers_Text,
+ Name: "ALand",
+ MultiText: gdp_b,
TextPosition: Plotly.NET.StyleParam.TextPosition.Auto,
Marker: Marker.init(MultiSize:gdp_b) // the marker object controls the style of the individual points
- )
- }
-)
- .WithXAxisStyle<string, string, string>(TitleText: "Time [y]")
- .WithYAxisStyle<string, string, string>(TitleText: "Population [Million]")
+ )
+ }
+)
+ .WithXAxisStyle<string, string, string>(TitleText: "Time [y]")
+ .WithYAxisStyle<string, string, string>(TitleText: "Population [Million]")
let x = [0. .. 0.1 .. (2.*System.Math.PI)]
-let y = x |> List.map sin
+let x = [0. .. 0.1 .. (2.*System.Math.PI)]
+let y = x |> List.map sin
#r "nuget: Plotly.NET.Interactive"
+#r "nuget: Plotly.NET.Interactive"
open Plotly.NET
+open Plotly.NET
-Chart.Scatter(
- x = x,
- y = y,
- mode = StyleParam.Mode.Markers
-)
+Chart.Scatter(
+ x = x,
+ y = y,
+ mode = StyleParam.Mode.Markers
+)
Chart.Point(
- x = x,
- y = y,
- Name = "y = sin(x)",
- ShowLegend = true
-)
-|> Chart.withXAxisStyle(TitleText = "x")
-|> Chart.withYAxisStyle(TitleText = "y")
-|> Chart.withTitle ("f(x) = sin(x)")
+Chart.Point(
+ x = x,
+ y = y,
+ Name = "y = sin(x)",
+ ShowLegend = true
+)
+|> Chart.withXAxisStyle(TitleText = "x")
+|> Chart.withYAxisStyle(TitleText = "y")
+|> Chart.withTitle ("f(x) = sin(x)")
Chart.Line(
- x = x,
- y = y
-)
-|> Chart.withXAxisStyle(TitleText = "time [s]")
-|> Chart.withYAxisStyle(TitleText = "some observation value")
-|> Chart.withTitle ("Our observations")
+Chart.Line(
+ x = x,
+ y = y
+)
+|> Chart.withXAxisStyle(TitleText = "time [s]")
+|> Chart.withYAxisStyle(TitleText = "some observation value")
+|> Chart.withTitle ("Our observations")
let rnd = new System.Random(69)
-let rnd_x = [for i in 0 .. 200 -> rnd.NextDouble()]
-let rnd_y = [for i in 0 .. 200 -> rnd.NextDouble()]
-
-[
- Chart.Point(
- x = rnd_x,
- y = rnd_y,
- Name = "Point cloud"
- )
- |> Chart.withXAxisStyle(TitleText = "x")
- |> Chart.withYAxisStyle(TitleText = "y")
- Chart.Line(
- x = rnd_x,
- y = rnd_y,
- Name = "lines"
- )
- |> Chart.withXAxisStyle(TitleText = "x")
- |> Chart.withYAxisStyle(TitleText = "y")
-]
-|> Chart.Grid(nRows = 1, nCols = 2)
-|> Chart.withSize(Width=1000,Height =600)
-|> Chart.withTitle "sometimes, lines do not make sense"
+let rnd = new System.Random(69)
+let rnd_x = [for i in 0 .. 200 -> rnd.NextDouble()]
+let rnd_y = [for i in 0 .. 200 -> rnd.NextDouble()]
+
+[
+ Chart.Point(
+ x = rnd_x,
+ y = rnd_y,
+ Name = "Point cloud"
+ )
+ |> Chart.withXAxisStyle(TitleText = "x")
+ |> Chart.withYAxisStyle(TitleText = "y")
+ Chart.Line(
+ x = rnd_x,
+ y = rnd_y,
+ Name = "lines"
+ )
+ |> Chart.withXAxisStyle(TitleText = "x")
+ |> Chart.withYAxisStyle(TitleText = "y")
+]
+|> Chart.Grid(nRows = 1, nCols = 2)
+|> Chart.withSize(Width=1000,Height =600)
+|> Chart.withTitle "sometimes, lines do not make sense"
// A Land
-let gdp_a = [20; 25; 35; 40; 50]
-let population_a = [500; 530; 520; 500; 510]
-
-//B Land
-let gdp_b = [30; 30; 33; 31; 35]
-let population_b = [400; 500; 600; 700; 800]
-
-let time = [1900; 1910; 1920; 1930; 1940]
-
-[
- Chart.Bubble(
- x = time,
- y = population_a,
- sizes = gdp_a,
- Name = "ALand",
- MultiText = gdp_a, // show gdp values as text in addition to bubble size
- TextPosition = StyleParam.TextPosition.Auto // set textposition to make gdp values visible
- )
-
- Chart.Bubble(
- x = time,
- y = population_b,
- sizes = gdp_b,
- Name = "BLand",
- MultiText = gdp_b, // show gdp values as text in addition to bubble size
- TextPosition = StyleParam.TextPosition.Auto // set textposition to make gdp values visible
- )
-]
-|> Chart.combine
-|> Chart.withXAxisStyle (TitleText = "Time [y]")
-|> Chart.withYAxisStyle (TitleText = "Population [Million]")
-|> Chart.withTitle "Comparison of ALand and BLand<br>regarding GDP and population growth over time"
+// A Land
+let gdp_a = [20; 25; 35; 40; 50]
+let population_a = [500; 530; 520; 500; 510]
+
+//B Land
+let gdp_b = [30; 30; 33; 31; 35]
+let population_b = [400; 500; 600; 700; 800]
+
+let time = [1900; 1910; 1920; 1930; 1940]
+
+[
+ Chart.Bubble(
+ x = time,
+ y = population_a,
+ sizes = gdp_a,
+ Name = "ALand",
+ MultiText = gdp_a, // show gdp values as text in addition to bubble size
+ TextPosition = StyleParam.TextPosition.Auto // set textposition to make gdp values visible
+ )
+
+ Chart.Bubble(
+ x = time,
+ y = population_b,
+ sizes = gdp_b,
+ Name = "BLand",
+ MultiText = gdp_b, // show gdp values as text in addition to bubble size
+ TextPosition = StyleParam.TextPosition.Auto // set textposition to make gdp values visible
+ )
+]
+|> Chart.combine
+|> Chart.withXAxisStyle (TitleText = "Time [y]")
+|> Chart.withYAxisStyle (TitleText = "Population [Million]")
+|> Chart.withTitle "Comparison of ALand and BLand<br>regarding GDP and population growth over time"
open Plotly.NET.TraceObjects
-
-[
- Chart.Scatter(
- x = time,
- y = population_a,
- mode = StyleParam.Mode.Lines_Markers_Text,
- Name = "ALand",
- MultiText = gdp_a,
- TextPosition = StyleParam.TextPosition.Auto,
- Marker = Marker.init(MultiSize = gdp_a) // the marker object controls the style of the individual points
- )
-
- Chart.Scatter(
- x = time,
- y = population_b,
- mode = StyleParam.Mode.Lines_Markers_Text,
- Name = "BLand",
- MultiText = gdp_b,
- TextPosition = StyleParam.TextPosition.Auto,
- Marker = Marker.init(MultiSize = gdp_b) // the marker object controls the style of the individual points
- )
-]
-|> Chart.combine
-|> Chart.withXAxisStyle (TitleText = "Time [y]")
-|> Chart.withYAxisStyle (TitleText = "Population [Million]")
-|> Chart.withTitle "Comparison of ALand and BLand<br>regarding GDP and population growth over time"
+open Plotly.NET.TraceObjects
+
+[
+ Chart.Scatter(
+ x = time,
+ y = population_a,
+ mode = StyleParam.Mode.Lines_Markers_Text,
+ Name = "ALand",
+ MultiText = gdp_a,
+ TextPosition = StyleParam.TextPosition.Auto,
+ Marker = Marker.init(MultiSize = gdp_a) // the marker object controls the style of the individual points
+ )
+
+ Chart.Scatter(
+ x = time,
+ y = population_b,
+ mode = StyleParam.Mode.Lines_Markers_Text,
+ Name = "BLand",
+ MultiText = gdp_b,
+ TextPosition = StyleParam.TextPosition.Auto,
+ Marker = Marker.init(MultiSize = gdp_b) // the marker object controls the style of the individual points
+ )
+]
+|> Chart.combine
+|> Chart.withXAxisStyle (TitleText = "Time [y]")
+|> Chart.withYAxisStyle (TitleText = "Population [Million]")
+|> Chart.withTitle "Comparison of ALand and BLand<br>regarding GDP and population growth over time"
@@ -193,7 +193,7 @@
+ 2022-3-20 +
+ +
+ #r "nuget: Deedle.Interactive, 3.0.0"
-#r "nuget: FSharp.Stats, 0.4.3"
-#r "nuget: Plotly.NET.Interactive, 4.0.0"
-#r "nuget: FSharp.Data, 4.2.7"
+#r "nuget: Deedle.Interactive, 3.0.0"
+#r "nuget: FSharp.Stats, 0.4.3"
+#r "nuget: Plotly.NET.Interactive, 4.0.0"
+#r "nuget: FSharp.Data, 4.2.7"
open FSharp.Data
-open FSharp.Stats
-open Deedle
+open FSharp.Data
+open FSharp.Stats
+open Deedle
-// Retrieve data using the FSharp.Data package and read it as dataframe using the Deedle package
-let rawData = Http.RequestString @"https://raw.githubusercontent.com/fslaborg/datasets/main/data/iris.csv"
-let df = Frame.ReadCsvString(rawData)
+// Retrieve data using the FSharp.Data package and read it as dataframe using the Deedle package
+let rawData = Http.RequestString @"https://raw.githubusercontent.com/fslaborg/datasets/main/data/iris.csv"
+let df = Frame.ReadCsvString(rawData)
-df
+df
open Plotly.NET
-open FSharp.Stats.ML.Unsupervised
+open Plotly.NET
+open FSharp.Stats.ML.Unsupervised
-let header2D = ["petal_length";"petal_width"]
-let header3D = ["sepal_length";"petal_length";"petal_width"]
+let header2D = ["petal_length";"petal_width"]
+let header3D = ["sepal_length";"petal_length";"petal_width"]
-//extract petal length and petal width
+//extract petal length and petal width
let data2D =
- Frame.sliceCols header2D df
- |> Frame.toJaggedArray
+ Frame.sliceCols header2D df
+ |> Frame.toJaggedArray
-//extract sepal length, petal length, and petal width
+//extract sepal length, petal length, and petal width
let data3D =
- Frame.sliceCols header3D df
- |> Frame.toJaggedArray
+ Frame.sliceCols header3D df
+ |> Frame.toJaggedArray
let labels =
- Frame.getCol "species" df
- |> Series.values
- |> Seq.mapi (fun i s -> sprintf "%s_%i" s i)
-
-let rawChart2D =
- let unzippedData =
- data2D
- |> Array.map (fun x -> x.[0],x.[1])
- Chart.Scatter(unzippedData,mode=StyleParam.Mode.Markers,MultiText=labels)
- |> Chart.withXAxisStyle header2D.[0]
- |> Chart.withYAxisStyle header2D.[1]
- |> Chart.withTitle "rawChart2D"
-
-let rawChart3D =
- let unzippedData =
- data3D
- |> Array.map (fun x -> x.[0],x.[1],x.[2])
- Chart.Scatter3D(unzippedData,mode=StyleParam.Mode.Markers,MultiText=labels)
- |> Chart.withXAxisStyle header3D.[0]
- |> Chart.withYAxisStyle header3D.[1]
- |> Chart.withZAxisStyle header3D.[2]
- |> Chart.withTitle "rawChart3D"
+ Frame.getCol "species" df
+ |> Series.values
+ |> Seq.mapi (fun i s -> sprintf "%s_%i" s i)
+
+let rawChart2D =
+ let unzippedData =
+ data2D
+ |> Array.map (fun x -> x.[0],x.[1])
+ Chart.Scatter(unzippedData,mode=StyleParam.Mode.Markers,MultiText=labels)
+ |> Chart.withXAxisStyle header2D.[0]
+ |> Chart.withYAxisStyle header2D.[1]
+ |> Chart.withTitle "rawChart2D"
+
+let rawChart3D =
+ let unzippedData =
+ data3D
+ |> Array.map (fun x -> x.[0],x.[1],x.[2])
+ Chart.Scatter3D(unzippedData,mode=StyleParam.Mode.Markers,MultiText=labels)
+ |> Chart.withXAxisStyle header3D.[0]
+ |> Chart.withYAxisStyle header3D.[1]
+ |> Chart.withZAxisStyle header3D.[2]
+ |> Chart.withTitle "rawChart3D"
rawChart2D
+rawChart2D
rawChart3D
+rawChart3D
open FSharp.Stats.ML
-open FSharp.Stats.ML.Unsupervised
+open FSharp.Stats.ML
+open FSharp.Stats.ML.Unsupervised
-let eps2D = 0.5
-let eps3D = 0.7
+let eps2D = 0.5
+let eps3D = 0.7
-let minPts = 20
+let minPts = 20
-let result2D = DbScan.compute DistanceMetrics.Array.euclidean minPts eps2D data2D
+let result2D = DbScan.compute DistanceMetrics.Array.euclidean minPts eps2D data2D
-result2D.ToString()
+result2D.ToString()
let result3D = DbScan.compute DistanceMetrics.Array.euclidean minPts eps3D data3D
+let result3D = DbScan.compute DistanceMetrics.Array.euclidean minPts eps3D data3D
-result3D.ToString()
+result3D.ToString()
let chartCluster2D =
- result2D.Clusterlist
- |> Seq.mapi (fun i l ->
- l
- |> Seq.map (fun x -> x.[0],x.[1])
- |> Seq.distinct //more efficient visualization; no difference in plot but in point numbers
- |> Chart.Point
- |> Chart.withTraceInfo (sprintf "Cluster %i" i))
- |> Chart.combine
+ result2D.Clusterlist
+ |> Seq.mapi (fun i l ->
+ l
+ |> Seq.map (fun x -> x.[0],x.[1])
+ |> Seq.distinct //more efficient visualization; no difference in plot but in point numbers
+ |> Chart.Point
+ |> Chart.withTraceInfo (sprintf "Cluster %i" i))
+ |> Chart.combine
let chartNoise2D =
- result2D.Noisepoints
+ result2D.Noisepoints
|> Seq.map (fun x -> x.[0],x.[1])
- |> Seq.distinct //more efficient visualization; no difference in plot but in point numbers
- |> Chart.Point
- |> Chart.withTraceInfo "Noise"
+ |> Seq.distinct //more efficient visualization; no difference in plot but in point numbers
+ |> Chart.Point
+ |> Chart.withTraceInfo "Noise"
let chartTitle2D =
- let noiseCount = result2D.Noisepoints |> Seq.length
- let clusterCount = result2D.Clusterlist |> Seq.length
- let clPtsCount = result2D.Clusterlist |> Seq.sumBy Seq.length
+ let noiseCount = result2D.Noisepoints |> Seq.length
+ let clusterCount = result2D.Clusterlist |> Seq.length
+ let clPtsCount = result2D.Clusterlist |> Seq.sumBy Seq.length
$"eps: %.1f{eps2D} minPts: %i{minPts} pts: %i{noiseCount + clPtsCount} cluster: %i{clusterCount} noisePts: %i{noiseCount}"
-[chartNoise2D;chartCluster2D]
-|> Chart.combine
-|> Chart.withTitle chartTitle2D
-|> Chart.withXAxisStyle header2D.[0]
-|> Chart.withYAxisStyle header2D.[1]
+[chartNoise2D;chartCluster2D]
+|> Chart.combine
+|> Chart.withTitle chartTitle2D
+|> Chart.withXAxisStyle header2D.[0]
+|> Chart.withYAxisStyle header2D.[1]
let chartCluster3D =
- result3D.Clusterlist
- |> Seq.mapi (fun i l ->
- l
- |> Seq.map (fun x -> x.[0],x.[1],x.[2])
- |> Seq.distinct //faster visualization; no difference in plot but in point number
- |> fun x -> Chart.Scatter3D (x,StyleParam.Mode.Markers)
- |> Chart.withTraceInfo (sprintf "Cluster_%i" i))
- |> Chart.combine
-
-let chartNoise3D =
- result3D.Noisepoints
+ result3D.Clusterlist
+ |> Seq.mapi (fun i l ->
+ l
+ |> Seq.map (fun x -> x.[0],x.[1],x.[2])
+ |> Seq.distinct //faster visualization; no difference in plot but in point number
+ |> fun x -> Chart.Scatter3D (x,StyleParam.Mode.Markers)
+ |> Chart.withTraceInfo (sprintf "Cluster_%i" i))
+ |> Chart.combine
+
+let chartNoise3D =
+ result3D.Noisepoints
|> Seq.map (fun x -> x.[0],x.[1],x.[2])
- |> Seq.distinct //faster visualization; no difference in plot but in point number
- |> fun x -> Chart.Scatter3D (x,StyleParam.Mode.Markers)
- |> Chart.withTraceInfo "Noise"
+ |> Seq.distinct //faster visualization; no difference in plot but in point number
+ |> fun x -> Chart.Scatter3D (x,StyleParam.Mode.Markers)
+ |> Chart.withTraceInfo "Noise"
let chartname3D =
- let noiseCount = result3D.Noisepoints |> Seq.length
- let clusterCount = result3D.Clusterlist |> Seq.length
- let clPtsCount = result3D.Clusterlist |> Seq.sumBy Seq.length
+ let noiseCount = result3D.Noisepoints |> Seq.length
+ let clusterCount = result3D.Clusterlist |> Seq.length
+ let clPtsCount = result3D.Clusterlist |> Seq.sumBy Seq.length
$"eps: %.1f{eps3D} minPts: %i{minPts} pts: %i{noiseCount + clPtsCount} cluster: %i{clusterCount} noisePts: %i{noiseCount}"
-[chartNoise3D;chartCluster3D]
-|> Chart.combine
-|> Chart.withTitle chartname3D
-|> Chart.withXAxisStyle header3D.[0]
-|> Chart.withYAxisStyle header3D.[1]
-|> Chart.withZAxisStyle header3D.[2]
+[chartNoise3D;chartCluster3D]
+|> Chart.combine
+|> Chart.withTitle chartname3D
+|> Chart.withXAxisStyle header3D.[0]
+|> Chart.withYAxisStyle header3D.[1]
+|> Chart.withZAxisStyle header3D.[2]
//for faster computation you can use the squaredEuclidean distance and set your eps to its square
-let clusteredChart3D() = DbScan.compute DistanceMetrics.Array.euclideanNaNSquared 20 (0.7**2.) data3D
+//for faster computation you can use the squaredEuclidean distance and set your eps to its square
+let clusteredChart3D() = DbScan.compute DistanceMetrics.Array.euclideanNaNSquared 20 (0.7**2.) data3D
#r "nuget: Deedle.Interactive, 3.0.0"
-#r "nuget: FSharp.Stats, 0.4.3"
-#r "nuget: Plotly.NET.Interactive, 4.0.0"
-#r "nuget: FSharp.Data, 4.2.7"
+#r "nuget: Deedle.Interactive, 3.0.0"
+#r "nuget: FSharp.Stats, 0.4.3"
+#r "nuget: Plotly.NET.Interactive, 4.0.0"
+#r "nuget: FSharp.Data, 4.2.7"
open FSharp.Data
-open Deedle
+open FSharp.Data
+open Deedle
-// Retrieve data using the FSharp.Data package and read it as dataframe using the Deedle package
-let rawData = Http.RequestString @"https://raw.githubusercontent.com/fslaborg/datasets/main/data/iris.csv"
-let df = Frame.ReadCsvString(rawData)
+// Retrieve data using the FSharp.Data package and read it as dataframe using the Deedle package
+let rawData = Http.RequestString @"https://raw.githubusercontent.com/fslaborg/datasets/main/data/iris.csv"
+let df = Frame.ReadCsvString(rawData)
-df
+df
open Plotly.NET
+open Plotly.NET
-let colNames = ["sepal_length";"sepal_width";"petal_length";"petal_width"]
+let colNames = ["sepal_length";"sepal_width";"petal_length";"petal_width"]
-// isolate data as float [] []
+// isolate data as float [] []
let data =
- Frame.dropCol "species" df
- |> Frame.toJaggedArray
+ Frame.dropCol "species" df
+ |> Frame.toJaggedArray
-// isolate labels as seq<string>
+// isolate labels as seq<string>
let labels =
- Frame.getCol "species" df
- |> Series.values
- |> Seq.mapi (fun i s -> sprintf "%s_%i" s i)
- |> Array.ofSeq
+ Frame.getCol "species" df
+ |> Series.values
+ |> Seq.mapi (fun i s -> sprintf "%s_%i" s i)
+ |> Array.ofSeq
-Chart.Heatmap(data,colNames=colNames,rowNames=labels)
-// required to fit the species identifier on the left side of the heatmap
-|> Chart.withMarginSize(Left=100.)
-|> Chart.withTitle "raw iris data"
+Chart.Heatmap(data,colNames=colNames,rowNames=labels)
+// required to fit the species identifier on the left side of the heatmap
+|> Chart.withMarginSize(Left=100.)
+|> Chart.withTitle "raw iris data"
open FSharp.Stats.ML
-open FSharp.Stats.ML.Unsupervised
+open FSharp.Stats.ML
+open FSharp.Stats.ML.Unsupervised
-let distanceMeasure = DistanceMetrics.euclideanNaNSquared
+let distanceMeasure = DistanceMetrics.euclideanNaNSquared
-let linker = HierarchicalClustering.Linker.centroidLwLinker
+let linker = HierarchicalClustering.Linker.centroidLwLinker
-// calculates the clustering and reports a single root cluster (node),
-// that may recursively contains further nodes
+// calculates the clustering and reports a single root cluster (node),
+// that may recursively contains further nodes
let clusterResultH =
- HierarchicalClustering.generate distanceMeasure linker data
+ HierarchicalClustering.generate distanceMeasure linker data
-// If a desired cluster number is specified, the following function cuts the cluster according
-// to the depth, that results in the respective number of clusters (here 3). Only leaves are reported.
-let threeClusters = HierarchicalClustering.cutHClust 3 clusterResultH
+// If a desired cluster number is specified, the following function cuts the cluster according
+// to the depth, that results in the respective number of clusters (here 3). Only leaves are reported.
+let threeClusters = HierarchicalClustering.cutHClust 3 clusterResultH
// Detailed information for 3 clusters are given
-let inspectThreeClusters =
- threeClusters
+// Detailed information for 3 clusters are given
+let inspectThreeClusters =
+ threeClusters
|> List.map (fun cluster ->
- cluster
+ cluster
|> List.map (fun leaf ->
- labels.[HierarchicalClustering.getClusterId leaf]
- )
- )
+ labels.[HierarchicalClustering.getClusterId leaf]
+ )
+ )
inspectThreeClusters
+inspectThreeClusters
|> List.mapi (fun i x ->
let truncCluster = x.[0..4] |> String.concat "; "
sprintf "Cluster%i: [%s ...]" i truncCluster
- )
-|> String.concat "\n"
+ )
+|> String.concat "\n"
// To recursevely flatten the cluster tree into leaves only, use flattenHClust.
-// A leaf list is reported, that does not contain any cluster membership,
-// but is sorted by the clustering result.
+// To recursevely flatten the cluster tree into leaves only, use flattenHClust.
+// A leaf list is reported, that does not contain any cluster membership,
+// but is sorted by the clustering result.
let hLeaves =
- clusterResultH
- |> HierarchicalClustering.flattenHClust
+ clusterResultH
+ |> HierarchicalClustering.flattenHClust
-// Takes the sorted cluster result and reports a tuple of label and data value.
+// Takes the sorted cluster result and reports a tuple of label and data value.
let dataSortedByClustering =
- hLeaves
+ hLeaves
|> Seq.choose (fun c ->
- let label = labels.[HierarchicalClustering.getClusterId c]
- let values = HierarchicalClustering.tryGetLeafValue c
- match values with
- | None -> None
- | Some x -> Some (label,x)
- )
+ let label = labels.[HierarchicalClustering.getClusterId c]
+ let values = HierarchicalClustering.tryGetLeafValue c
+ match values with
+ | None -> None
+ | Some x -> Some (label,x)
+ )
open FSharpAux
-
-let (hlable,hdata) =
- dataSortedByClustering
- |> Seq.unzip
-Chart.Heatmap(hdata,colNames=colNames,rowNames=hlable)
-// required to fit the species identifier on the left side of the heatmap
-|> Chart.withMarginSize(Left=100.)
-|> Chart.withTitle "Clustered iris data (hierarchical clustering)"
+open FSharpAux
+
+let (hlable,hdata) =
+ dataSortedByClustering
+ |> Seq.unzip
+Chart.Heatmap(hdata,colNames=colNames,rowNames=hlable)
+// required to fit the species identifier on the left side of the heatmap
+|> Chart.withMarginSize(Left=100.)
+|> Chart.withTitle "Clustered iris data (hierarchical clustering)"
#r "nuget: Deedle.Interactive, 3.0.0"
-#r "nuget: FSharp.Stats, 0.4.3"
-#r "nuget: Plotly.NET.Interactive, 4.0.0"
-#r "nuget: FSharp.Data, 4.2.7"
+#r "nuget: Deedle.Interactive, 3.0.0"
+#r "nuget: FSharp.Stats, 0.4.3"
+#r "nuget: Plotly.NET.Interactive, 4.0.0"
+#r "nuget: FSharp.Data, 4.2.7"
open FSharp.Data
-open Deedle
+open FSharp.Data
+open Deedle
-// Retrieve data using the FSharp.Data package and read it as dataframe using the Deedle package
-let rawData = Http.RequestString @"https://raw.githubusercontent.com/fslaborg/datasets/main/data/iris.csv"
-let df = Frame.ReadCsvString(rawData)
+// Retrieve data using the FSharp.Data package and read it as dataframe using the Deedle package
+let rawData = Http.RequestString @"https://raw.githubusercontent.com/fslaborg/datasets/main/data/iris.csv"
+let df = Frame.ReadCsvString(rawData)
-df
+df
open Plotly.NET
+open Plotly.NET
-let colNames = ["sepal_length";"sepal_width";"petal_length";"petal_width"]
+let colNames = ["sepal_length";"sepal_width";"petal_length";"petal_width"]
-// isolate data as float [] []
+// isolate data as float [] []
let data =
- Frame.dropCol "species" df
- |> Frame.toJaggedArray
+ Frame.dropCol "species" df
+ |> Frame.toJaggedArray
-//isolate labels as seq<string>
+//isolate labels as seq<string>
let labels =
- Frame.getCol "species" df
- |> Series.values
- |> Seq.mapi (fun i s -> sprintf "%s_%i" s i)
+ Frame.getCol "species" df
+ |> Series.values
+ |> Seq.mapi (fun i s -> sprintf "%s_%i" s i)
-Chart.Heatmap(data,colNames=colNames,rowNames=labels)
-// required to fit the species identifier on the left side of the heatmap
-|> Chart.withMarginSize(Left=100.)
-|> Chart.withTitle "raw iris data"
+Chart.Heatmap(data,colNames=colNames,rowNames=labels)
+// required to fit the species identifier on the left side of the heatmap
+|> Chart.withMarginSize(Left=100.)
+|> Chart.withTitle "raw iris data"
open FSharp.Stats
-open FSharp.Stats.ML
-open FSharp.Stats.ML.Unsupervised
+open FSharp.Stats
+open FSharp.Stats.ML
+open FSharp.Stats.ML.Unsupervised
-// For random cluster initiation use randomInitFactory:
-let rnd = System.Random()
+// For random cluster initiation use randomInitFactory:
+let rnd = System.Random()
let randomInitFactory : IterativeClustering.CentroidsFactory<float []> =
- IterativeClustering.randomCentroids<float []> rnd
+ IterativeClustering.randomCentroids<float []> rnd
-// For assisted cluster initiation use cvmaxFactory:
-//let cvmaxFactory : IterativeClustering.CentroidsFactory<float []> =
-// IterativeClustering.intitCVMAX
+// For assisted cluster initiation use cvmaxFactory:
+//let cvmaxFactory : IterativeClustering.CentroidsFactory<float []> =
+// IterativeClustering.intitCVMAX
-let distanceFunction = DistanceMetrics.euclideanNaNSquared
+let distanceFunction = DistanceMetrics.euclideanNaNSquared
let kmeansResult =
- IterativeClustering.kmeans distanceFunction randomInitFactory data 4
+ IterativeClustering.kmeans distanceFunction randomInitFactory data 4
let clusteredIrisData =
- Seq.zip labels data
+let clusteredIrisData =
+ Seq.zip labels data
|> Seq.map (fun (species,dataPoint) ->
- let clusterIndex,centroid = kmeansResult.Classifier dataPoint
- clusterIndex,species,dataPoint)
+ let clusterIndex,centroid = kmeansResult.Classifier dataPoint
+ clusterIndex,species,dataPoint)
-clusteredIrisData
-|> Seq.take 7
-|> Seq.map (fun (a,b,c) -> sprintf "%i, %A, %A" a b c)
-|> String.concat "\n"
-|> fun x -> x + "\n ... "
+clusteredIrisData
+|> Seq.take 7
+|> Seq.map (fun (a,b,c) -> sprintf "%i, %A, %A" a b c)
+|> String.concat "\n"
+|> fun x -> x + "\n ... "
open FSharpAux
+open FSharpAux
-clusteredIrisData
-//sort all data points according to their assigned cluster number
-|> Seq.sortBy (fun (clusterIndex,label,dataPoint) -> clusterIndex)
-|> Seq.unzip3
+clusteredIrisData
+//sort all data points according to their assigned cluster number
+|> Seq.sortBy (fun (clusterIndex,label,dataPoint) -> clusterIndex)
+|> Seq.unzip3
|> fun (_,labels,d) ->
- Chart.Heatmap(d,colNames=colNames,rowNames=labels)
- // required to fit the species identifier on the left side of the heatmap
- |> Chart.withMarginSize(Left=100.)
- |> Chart.withTitle "clustered iris data (k-means clustering)"
+ Chart.Heatmap(d,colNames=colNames,rowNames=labels)
+ // required to fit the species identifier on the left side of the heatmap
+ |> Chart.withMarginSize(Left=100.)
+ |> Chart.withTitle "clustered iris data (k-means clustering)"
//group clusters
-clusteredIrisData
-|> Seq.groupBy (fun (clusterIndex,label,dataPoint) -> clusterIndex)
-//for each cluster generate a scatter plot
+//group clusters
+clusteredIrisData
+|> Seq.groupBy (fun (clusterIndex,label,dataPoint) -> clusterIndex)
+//for each cluster generate a scatter plot
|> Seq.map (fun (clusterIndex,cluster) ->
- cluster
- |> Seq.unzip3
+ cluster
+ |> Seq.unzip3
|> fun (clusterIndex,label,data) ->
- let clusterName = sprintf "cluster %i" (Seq.head clusterIndex)
- //for 3 dimensional representation isolate sepal length, petal length, and petal width
+ let clusterName = sprintf "cluster %i" (Seq.head clusterIndex)
+ //for 3 dimensional representation isolate sepal length, petal length, and petal width
let truncData = data |> Seq.map (fun x -> x.[0],x.[2],x.[3])
- Chart.Scatter3D(truncData,mode=StyleParam.Mode.Markers,Name = clusterName,MultiText=label)
- )
-|> Chart.combine
-|> Chart.withTitle "isolated coordinates of clustered iris data (k-means clustering)"
-|> Chart.withXAxisStyle colNames.[0]
-|> Chart.withYAxisStyle colNames.[2]
-|> Chart.withZAxisStyle colNames.[3]
+ Chart.Scatter3D(truncData,mode=StyleParam.Mode.Markers,Name = clusterName,MultiText=label)
+ )
+|> Chart.combine
+|> Chart.withTitle "isolated coordinates of clustered iris data (k-means clustering)"
+|> Chart.withXAxisStyle colNames.[0]
+|> Chart.withYAxisStyle colNames.[2]
+|> Chart.withZAxisStyle colNames.[3]
let getBestkMeansClustering bootstraps k =
- let dispersions =
+let getBestkMeansClustering bootstraps k =
+ let dispersions =
Array.init bootstraps (fun _ ->
- IterativeClustering.kmeans distanceFunction randomInitFactory data k
- )
- |> Array.map (fun clusteringResult -> IterativeClustering.DispersionOfClusterResult clusteringResult)
- Seq.mean dispersions,Seq.stDev dispersions
+ IterativeClustering.kmeans distanceFunction randomInitFactory data k
+ )
+ |> Array.map (fun clusteringResult -> IterativeClustering.DispersionOfClusterResult clusteringResult)
+ Seq.mean dispersions,Seq.stDev dispersions
-let iterations = 10
+let iterations = 10
-let maximalK = 10
+let maximalK = 10
[2 .. maximalK]
|> List.map (fun k ->
- let mean,stdev = getBestkMeansClustering iterations k
- k,mean,stdev
- )
-|> List.unzip3
+ let mean,stdev = getBestkMeansClustering iterations k
+ k,mean,stdev
+ )
+|> List.unzip3
|> fun (ks,means,stdevs) ->
- Chart.Line(ks,means)
- |> Chart.withYErrorStyle(Array=stdevs)
- |> Chart.withXAxisStyle "k"
- |> Chart.withYAxisStyle "average dispersion"
- |> Chart.withTitle "iris data set average dispersion per k"
+ Chart.Line(ks,means)
+ |> Chart.withYErrorStyle(Array=stdevs)
+ |> Chart.withXAxisStyle "k"
+ |> Chart.withYAxisStyle "average dispersion"
+ |> Chart.withTitle "iris data set average dispersion per k"
#r "nuget: FSharp.Stats"
-// References a sepcific package version
-#r "nuget: Plotly.NET, 4.0.0"
-#r "nuget: Plotly.NET.Interactive, 4.0.0"
+#r "nuget: FSharp.Stats"
+// References a sepcific package version
+#r "nuget: Plotly.NET, 4.0.0"
+#r "nuget: Plotly.NET.Interactive, 4.0.0"
Alternatively, .dll files can be referenced directly with the following syntax:
-#r @"Your\Path\To\Package\PackageName.dll"
+#r @"Your\Path\To\Package\PackageName.dll"
// Packages hosted by the Fslab community
-#r "nuget: Deedle.Interactive, 3.0.0"
-#r "nuget: FSharp.Stats"
-// third party .net packages
-#r "nuget: Plotly.NET.Interactive, 4.0.0"
-#r "nuget: FSharpAux"
-#r "nuget: FSharp.Data, 5.0.2"
+// Packages hosted by the Fslab community
+#r "nuget: Deedle.Interactive, 3.0.0"
+#r "nuget: FSharp.Stats"
+// third party .net packages
+#r "nuget: Plotly.NET.Interactive, 4.0.0"
+#r "nuget: FSharpAux"
+#r "nuget: FSharp.Data, 5.0.2"
open FSharp.Stats
+open FSharp.Stats
-SpecialFunctions.Factorial.factorial 3
+SpecialFunctions.Factorial.factorial 3
open FSharp.Data
-open Deedle
+open FSharp.Data
+open Deedle
-// Retrieve data using the FSharp.Data package
-let rawData = Http.RequestString @"https://raw.githubusercontent.com/dotnet/machinelearning/master/test/data/housing.txt"
+// Retrieve data using the FSharp.Data package
+let rawData = Http.RequestString @"https://raw.githubusercontent.com/dotnet/machinelearning/master/test/data/housing.txt"
-// And create a data frame object using the ReadCsvString method provided by Deedle.
-// Note: Of course you can directly provide the path to a local source.
-let df = Frame.ReadCsvString(rawData,hasHeaders=true,separators="\t")
+// And create a data frame object using the ReadCsvString method provided by Deedle.
+// Note: Of course you can directly provide the path to a local source.
+let df = Frame.ReadCsvString(rawData,hasHeaders=true,separators="\t")
-df
+df
let housesNotAtRiver =
- df
- |> Frame.sliceCols ["RoomsPerDwelling";"MedianHomeValue";"CharlesRiver"]
+ df
+ |> Frame.sliceCols ["RoomsPerDwelling";"MedianHomeValue";"CharlesRiver"]
|> Frame.filterRowValues (fun s -> s.GetAs<bool>("CharlesRiver") |> not )
-housesNotAtRiver
+housesNotAtRiver
open Plotly.NET
+open Plotly.NET
-// Note that we explicitly specify that we want to work with the values as floats.
-// Since the row identity is not needed anymore when plotting the distribution we can
-// directly convert the collection to a FSharp Sequence.
+// Note that we explicitly specify that we want to work with the values as floats.
+// Since the row identity is not needed anymore when plotting the distribution we can
+// directly convert the collection to a FSharp Sequence.
let pricesNotAtRiver : seq<float> =
- housesNotAtRiver
- |> Frame.getCol "MedianHomeValue"
- |> Series.values
+ housesNotAtRiver
+ |> Frame.getCol "MedianHomeValue"
+ |> Series.values
-Chart.Histogram(pricesNotAtRiver)
-|> Chart.withYAxisStyle("median value of owner occupied homes in 1000s")
-|> Chart.withXAxisStyle("price distribution")
+Chart.Histogram(pricesNotAtRiver)
+|> Chart.withYAxisStyle("median value of owner occupied homes in 1000s")
+|> Chart.withXAxisStyle("price distribution")
let housesAtRiver =
- df
- |> Frame.sliceCols ["RoomsPerDwelling";"MedianHomeValue";"CharlesRiver"]
- |> Frame.filterRowValues (fun s -> s.GetAs<bool>("CharlesRiver"))
+ df
+ |> Frame.sliceCols ["RoomsPerDwelling";"MedianHomeValue";"CharlesRiver"]
+ |> Frame.filterRowValues (fun s -> s.GetAs<bool>("CharlesRiver"))
let pricesAtRiver : seq<float> =
- housesAtRiver
- |> Frame.getCol "MedianHomeValue"
- |> Series.values
-
-
-[
- Chart.Histogram(pricesNotAtRiver, Opacity = 0.66, OffsetGroup = "A")
- |> Chart.withTraceInfo "not at river"
- Chart.Histogram(pricesAtRiver, Opacity = 0.66, OffsetGroup = "A")
- |> Chart.withTraceInfo "at river"
-]
-|> Chart.combine
-|> Chart.withYAxisStyle("median value of owner occupied homes in 1000s")
-|> Chart.withXAxisStyle("Comparison of price distributions")
+ housesAtRiver
+ |> Frame.getCol "MedianHomeValue"
+ |> Series.values
+
+
+[
+ Chart.Histogram(pricesNotAtRiver, Opacity = 0.66, OffsetGroup = "A")
+ |> Chart.withTraceInfo "not at river"
+ Chart.Histogram(pricesAtRiver, Opacity = 0.66, OffsetGroup = "A")
+ |> Chart.withTraceInfo "at river"
+]
+|> Chart.combine
+|> Chart.withYAxisStyle("median value of owner occupied homes in 1000s")
+|> Chart.withXAxisStyle("Comparison of price distributions")
open FSharp.Stats
-open FSharpAux
-open FSharp.Stats.Correlation
+open FSharp.Stats
+open FSharpAux
+open FSharp.Stats.Correlation
let pricesAll :Series<int,float> =
- df
- |> Frame.getCol "MedianHomeValue"
+ df
+ |> Frame.getCol "MedianHomeValue"
let roomsPerDwellingAll :Series<int,float> =
- df
+ df
|> Frame.getCol "RoomsPerDwelling"
let correlation =
let tmpPrices, tmpRooms =
Series.zipInner pricesAll roomsPerDwellingAll
|> Series.values
- |> Seq.unzip
- Seq.pearson tmpPrices tmpRooms
+ |> Seq.unzip
+ Seq.pearson tmpPrices tmpRooms
-correlation
+correlation
open Fitting.LinearRegression.OrdinaryLeastSquares
+open Fitting.LinearRegression.OrdinaryLeastSquares
let predictPricesByRooms description data =
let pricesAll :Series<_,float> =
- data
- |> Frame.getCol "MedianHomeValue"
+ data
+ |> Frame.getCol "MedianHomeValue"
let roomsPerDwellingAll :Series<_,float> =
- data
+ data
|> Frame.getCol "RoomsPerDwelling"
let fit =
let tmpRooms, tmpPrices =
Series.zipInner roomsPerDwellingAll pricesAll
- |> Series.sortBy fst
+ |> Series.sortBy fst
|> Series.values
- |> Seq.unzip
- let coeffs = Linear.Univariable.coefficient (vector tmpRooms) (vector tmpPrices)
+ |> Seq.unzip
+ let coeffs = Linear.Univariable.coefficient (vector tmpRooms) (vector tmpPrices)
let model = Linear.Univariable.fit coeffs
- let predictedPrices = tmpRooms |> Seq.map model
- [
- Chart.Point(tmpRooms,tmpPrices)
- |> Chart.withTraceInfo (sprintf "%s: data" description )
- Chart.Line(tmpRooms,predictedPrices)
- |> Chart.withTraceInfo (sprintf "%s: coefficients: intercept:%f, slope:%f" description coeffs.[0] coeffs.[1])
+ let predictedPrices = tmpRooms |> Seq.map model
+ [
+ Chart.Point(tmpRooms,tmpPrices)
+ |> Chart.withTraceInfo (sprintf "%s: data" description )
+ Chart.Line(tmpRooms,predictedPrices)
+ |> Chart.withTraceInfo (sprintf "%s: coefficients: intercept:%f, slope:%f" description coeffs.[0] coeffs.[1])
]
- |> Chart.combine
- |> Chart.withXAxisStyle("rooms per dwelling")
- |> Chart.withYAxisStyle("median value")
- fit
+ |> Chart.combine
+ |> Chart.withXAxisStyle("rooms per dwelling")
+ |> Chart.withYAxisStyle("median value")
+ fit
[
- predictPricesByRooms "not at river" housesNotAtRiver
- predictPricesByRooms "at river" housesAtRiver
-]
-|> Chart.combine
-|> Chart.withSize(1200.,700.)
+[
+ predictPricesByRooms "not at river" housesNotAtRiver
+ predictPricesByRooms "at river" housesAtRiver
+]
+|> Chart.combine
+|> Chart.withSize(1200.,700.)
TLDR: A q value defines the proportion of false positives there are within all discoveries that were called significant up to the current item.
+High throughput techniques like microarrays with its successor RNA-Seq and mass spectrometry proteomics lead to an huge data amount. +Thousands of features (e.g. transcripts or proteins) are measured simultaneously. Differential expression analysis aims to identify features, that change significantly +between two conditions. A common experimental setup is the analysis of which genes are over- or underexpressed between e.g. a wild type and a mutant.
+Hypothesis tests aim to identify differences between two or more samples. The most common statistical test is the t test that tests a difference of means. Hypothesis tests report +a p value, that correspond the probability of obtaining results at least as extreme as the observed results, assuming that the null hypothesis is correct. In other words:
+// required for auxiliary functions
+#r "nuget: FSharpAux, 2.0.0"
+// required for all calculations
+#r "nuget: FSharp.Stats, 0.4.12-preview.3"
+// required to read the pvalue set
+#r "nuget: FSharp.Data, 4.2.7"
+// required for charting
+#r "nuget: Plotly.NET.Interactive, 4.1.0"
+
+open FSharpAux
+open FSharp.Stats
+open FSharp.Data
+open Plotly.NET
+open Plotly.NET.StyleParam
+open Plotly.NET.LayoutObjects
+Consider two population distributions that follow a normal distribution. Both have the same mean and standard deviation.
+ +let distributionA = Distributions.Continuous.Normal.Init 10.0 1.0
+let distributionB = Distributions.Continuous.Normal.Init 10.0 1.0
+
+let distributionChartAB =
+ [
+ Chart.Area(xy = ([5. .. 0.01 .. 15.] |> List.map (fun x -> x,distributionA.PDF x)), Name = "distA")
+ Chart.Area(xy = ([5. .. 0.01 .. 15.] |> List.map (fun x -> x,distributionB.PDF x)), Name = "distB")
+ ]
+ |> Chart.combine
+ |> Chart.withTemplate ChartTemplates.lightMirrored
+ |> Chart.withXAxisStyle "variable X"
+ |> Chart.withYAxisStyle "relative count"
+ |> Chart.withSize (900.,600.)
+ |> Chart.withTitle "null hypothesis"
+
+distributionChartAB
+Samples with sample size 5 are randomly drawn from both population distributions. +Both samples are tested if a mean difference exist using a two sample t test where equal variances of the underlying population distribution are assumed.
+ +let getSample n (dist: Distributions.ContinuousDistribution<float,float>) =
+ Vector.init n (fun _ -> dist.Sample())
+
+let sampleA = getSample 5 distributionA
+let sampleB = getSample 5 distributionB
+
+let pValue = (Testing.TTest.twoSample true sampleA sampleB).PValue
+
+pValue
+0.24680735077408789
10,000 tests are performed, each with new randomly drawn samples. This corresponds to an experiment in which none of the features changed. +Note, that the mean intensities are arbitrary and must not be the same for all features! In the presented case all feature intensities are in average 10. +The same simulation can be performed with pairwise comparisons from distributions that differ for each feature, but are the same within the feature. +The resulting p values are uniformly distributed between 0 and 1.
+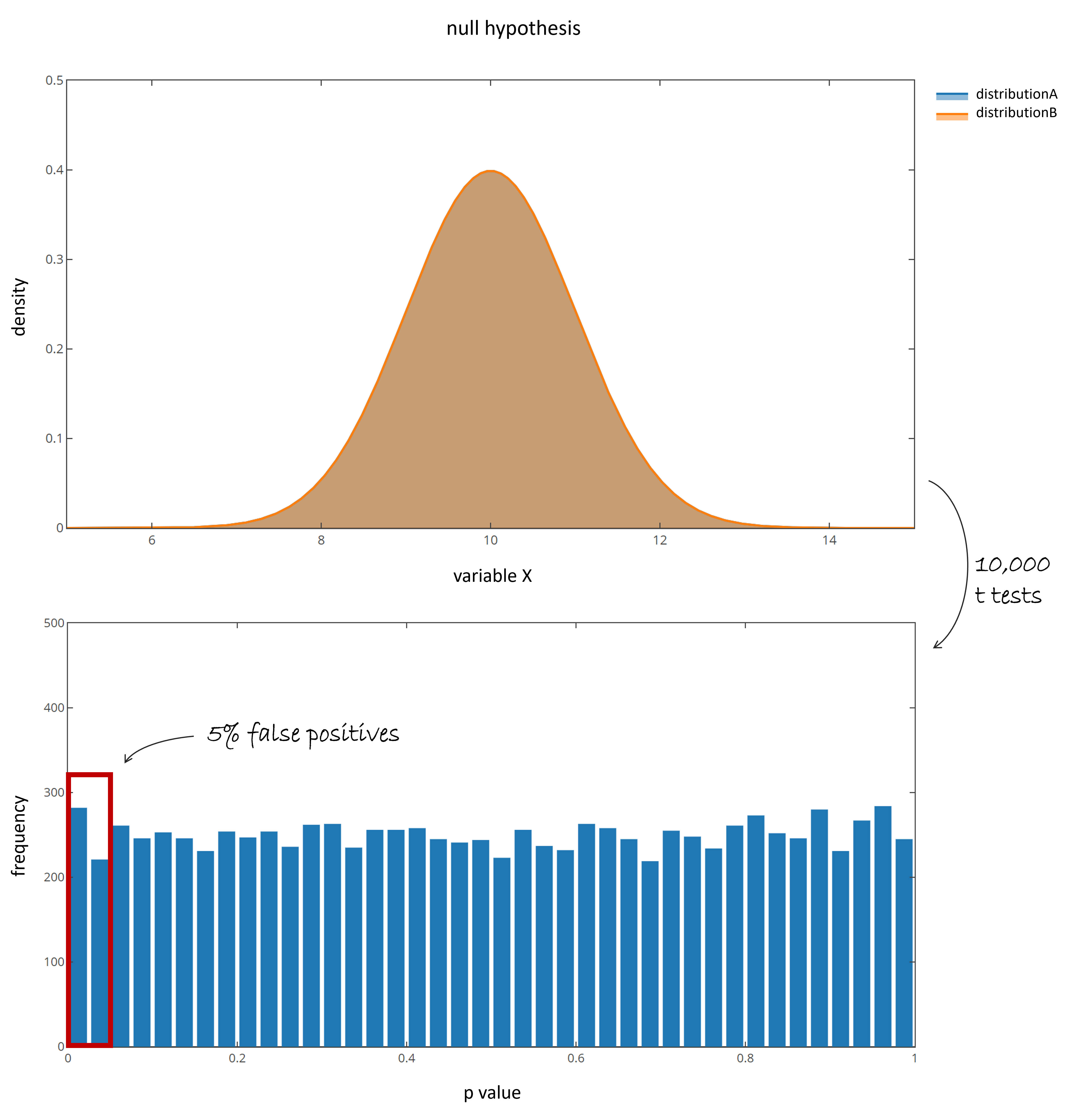
Fig 1: p value distribution of the null hypothesis.
+ +Samples are called significantly different, if their p value is below a certain significance threshold ($\alpha$ level). While "the lower the better", a common threshold +is a p value of 0.05 or 0.01. In the presented case in average $10,000 * 0.05 = 500$ tests are significant (red box), even though the populations do not differ. They are called false +positives (FP). Now lets repeat the same experiment, but this time sample 70% of the time from null features (no difference) and add 30% samples of truly +differing distributions. Therefore a third populations is generated, that differ in mean, but has an equal standard deviation:
+ +let distributionC = Distributions.Continuous.Normal.Init 11.5 1.0
+
+let distributionChartAC =
+ [
+ Chart.Area(xy = ([5. .. 0.01 .. 15.] |> List.map (fun x -> x,distributionA.PDF x)), Name = "distA")
+ Chart.Area(xy = ([5. .. 0.01 .. 15.] |> List.map (fun x -> x,distributionC.PDF x)), Name = "distC")
+ ]
+ |> Chart.combine
+ |> Chart.withTemplate ChartTemplates.lightMirrored
+ |> Chart.withXAxisStyle "variable X"
+ |> Chart.withYAxisStyle "relative count"
+ |> Chart.withSize (1000.,600.)
+ |> Chart.withTitle "alternative hypothesis"
+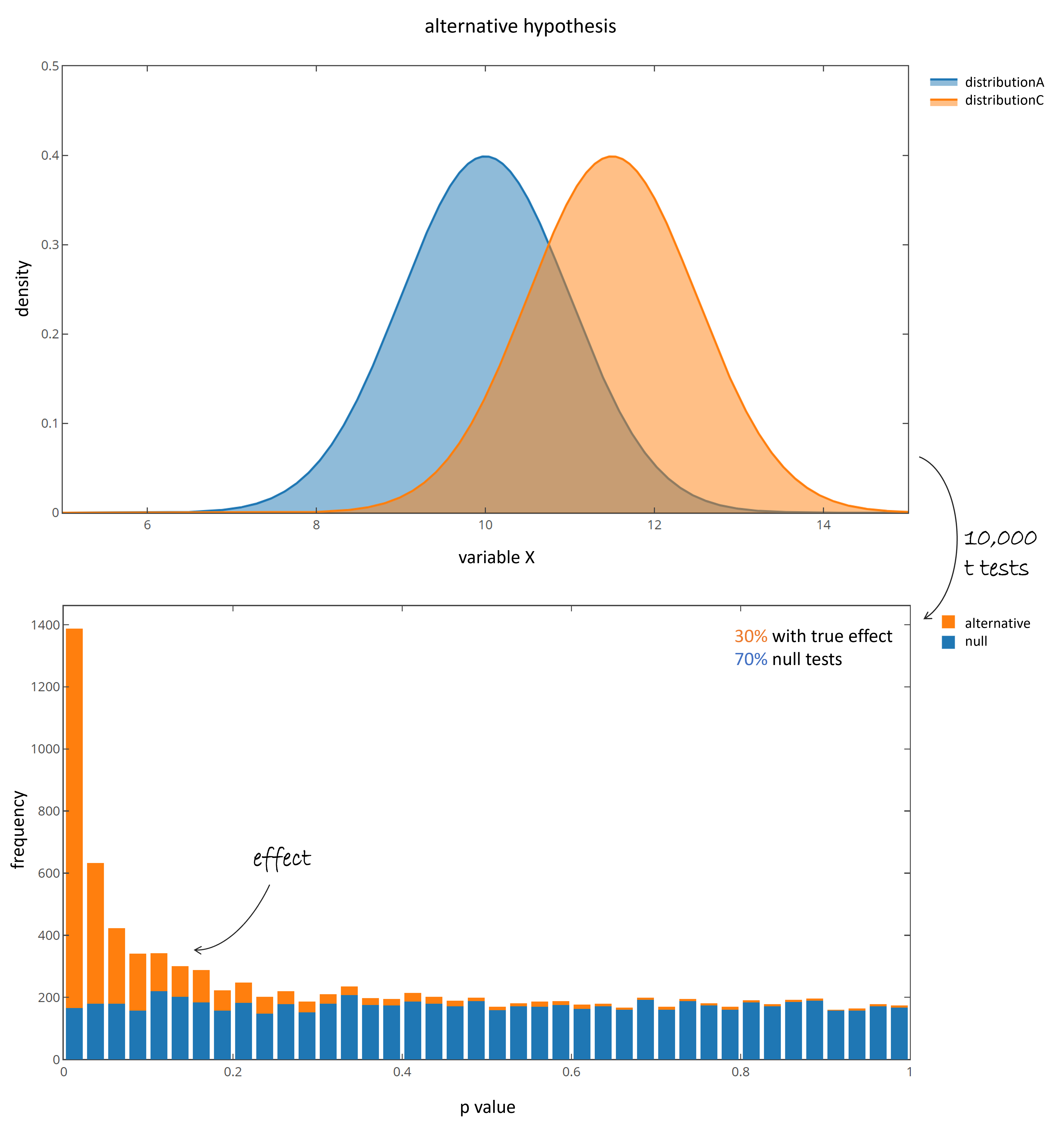
Fig 2: p value distribution of the alternative hypothesis. Blue coloring indicate p values deriving from distribution A and B (null). +Orange coloring indicate p values deriving from distribution A and C (truly differing).
+The pvalue distribution of the tests resulting from truly differing populations are right skewed, while the null tests again show a homogeneous distribution between 0 and 1. +Many, but not all of the tests that come from the truly differing populations are below 0.05, and therefore would be reported as significant. +In average 350 null features would be reported as significant even though they derive from null features (blue bars, 10,000 x 0.7 x 0.05 = 350).
+The hypothesis testing framework with the p value definition given above was developed for performing just one test. If many tests are performed, like in modern high throughput studies, the probability to obtain a +false positive result increases. The probability of at least one false positive is called Familywise error rate (FWER) and can be determined by $FWER=1-(1-\alpha)^m$ where +$\alpha$ corresponds to the significance threshold (here 0.05) and $m$ is the number of performed tests.
+ +let bonferroniLine =
+ Shape.init(ShapeType=ShapeType.Line,X0=0.,X1=35.,Y0=0.05,Y1=0.05,Line=Line.init(Dash=DrawingStyle.Dash))
+
+let fwer =
+ [1..35]
+ |> List.map (fun x ->
+ x,(1. - (1. - 0.05)**(float x))
+ )
+ |> Chart.Point
+ |> Chart.withTemplate ChartTemplates.lightMirrored
+ |> Chart.withXAxisStyle "#tests"
+ |> Chart.withYAxisStyle("p(at least one FP)",MinMax=(0.,1.))
+ |> Chart.withShape bonferroniLine
+ |> Chart.withTitle "FWER"
+
+fwer
+Fig 3: Family wise error rate depending on number of performed tests. The black dashed line indicates the Bonferroni corrected FWER by $p^* = \frac{\alpha}{m}$ .
+When 10,000 null features are tested with a p value threshold of 0.05, in average 500 tests are reported significant even if there is not a single comparisons in which the +population differ. If some of the features are in fact different, the number of false positives consequently decreases (remember, the p value is defined for tests of null features).
+Why the interpretation of high throughput data based on p values is difficult: The more features are measured, the more false positives you can expect. If 100 differentially +expressed genes are identified by p value thresholding, without further information about the magnitude of expected changes and the total number of measured transcripts, the +data is useless.
+The p value threshold has no straight-forward interpretation when many tests are performed. Of course you could restrict the family wise error rate to 0.05, regardless +how many tests are performed. This is realized by dividing the $\alpha$ significance threshold by the number of tests, which is known as Bonferroni correction: $p^* = \frac{\alpha}{m}$. +This correction drastically limit the false positive rate, but in an experiment with a huge count of expected changes, it additionally would result in many false negatives. The +FWER should be chosen if the costs of follow up studies to tests the candidates are dramatic or there is a huge waste of time to potentially study false positives.
+A more reasonable measure of significance with a simple interpretation is the so called false discovery rate (FDR). It describes the rate of expected false positives within the +overall reported significant features. The goal is to identify as many sig. features as possible while incurring a relatively low proportion of false positives. +Consequently a set of reported significant features together with the FDR describes the confidence of this set, without the requirement to +somehow incorporate the uncertainty that is introduced by the total number of tests performed. In the simulated case of 7,000 null tests and 3,000 tests resulting from truly +differing distributions above, the FDR can be calculated exactly. Therefore at e.g. a p value of 0.05 the number of false positives (blue in red box) are divided by the number +of significant reported tests (false positives + true positives).
+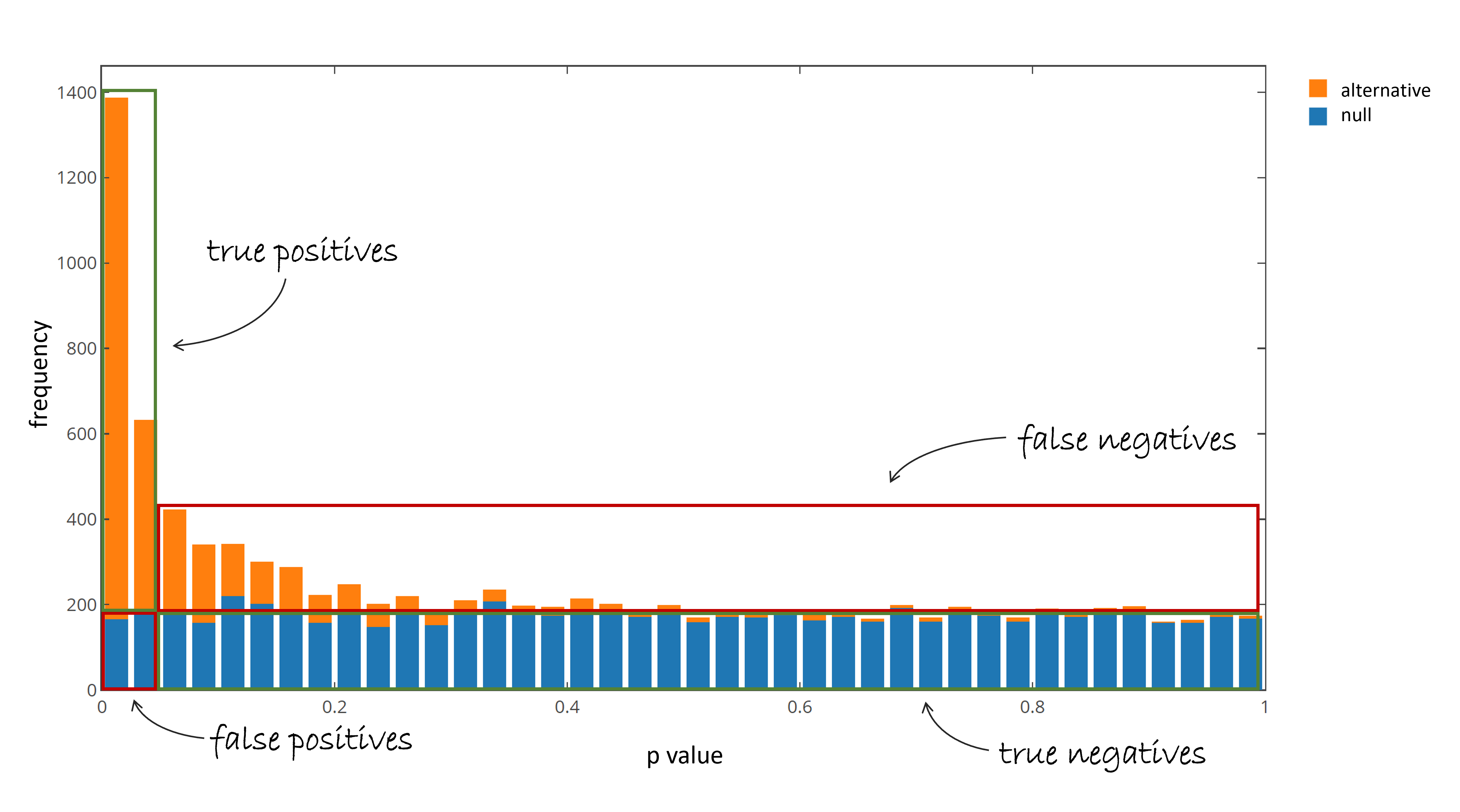
Fig 4: p value distribution of the alternative hypothesis.
+Given the conditions described in the first chapter, the FDR of this experiment with a p value threshold of 0.05 is 0.173. Out of the 2019 reported significant comparisons, in average 350 +are expected to be false positives, which gives an straight forward interpretation of the data confidence. In real-world experiments the proportion of null tests and tests +deriving from an actual difference is of course unknown. The proportion of null tests however tends to be distributed equally in the p value histogram. By identification of +the average null frequency, a proportion of FP and TP can be determined and the FDR can be defined. This frequency estimate is called $\pi_0$, which leads to an FDR definition of:
+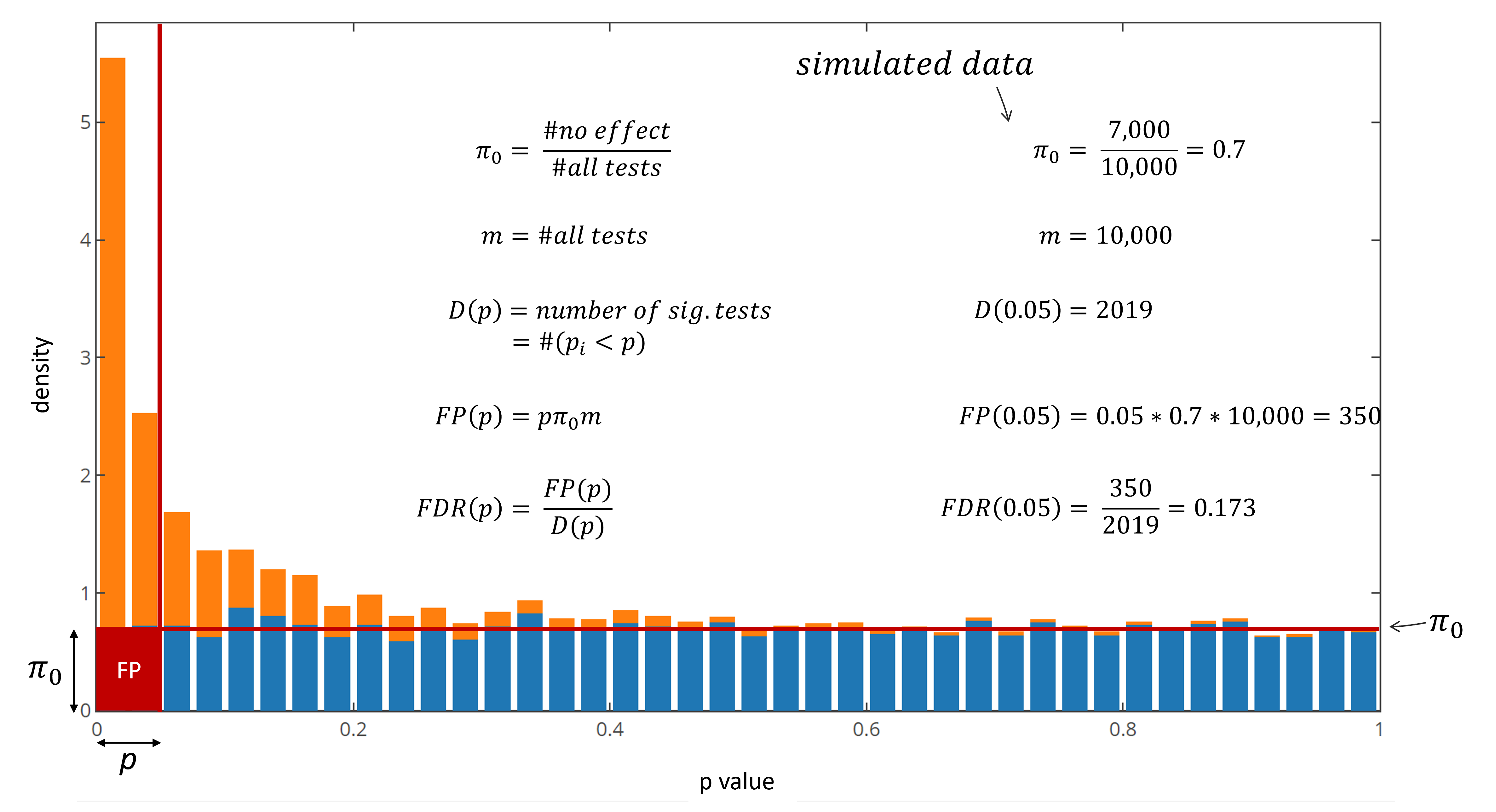
Fig 5: FDR calculation on simulated data.
+Consequently for each presented p value a corresponding FDR can be calculated. The minimum local FDR at each p value is called q value.
+$$\hat q(p_i) = min_{t \geq p_i} \hat{FDR}(p_i)$$Since the q value is not monotonically increasing, it is smoothed by assigning the lowest FDR of all p values, that are equal or higher the current one.
+By defining $\pi_0$, all other parameters can be calculated from the given p value distribution to determine the all q values. The most prominent +FDR-controlling method is known as Benjamini-Hochberg correction. It sets $\pi_0$ as 1, assuming that all features are null. In studies with an expected high proportion of true +positives, a $\pi_0$ of 1 is too conservative, since there definitely are true positives in the data.
+A better estimation of $\pi_0$ is given in the following:
+True positives are assumed to be right skewed while null tests are distributed equally between 0 and 1. Consequently the right flat region of the p value histogram tends to correspond +to the true frequency of null comparisons (Fig 5). As real world example 9856 genes were measured in triplicates under two conditions (control and treatment). The p value distribution of two +sample t tests looks as follows:
+ +let examplePVals =
+ let rawData = Http.RequestString @"https://raw.githubusercontent.com/fslaborg/datasets/main/data/pvalExample.txt"
+ rawData.Split '\n'
+ |> Array.tail
+ |> Array.map float
+
+//number of tests
+let m =
+ examplePVals
+ |> Array.length
+ |> float
+
+let nullLine =
+ Shape.init(ShapeType=ShapeType.Line,X0=0.,X1=1.,Y0=1.,Y1=1.,Line=Line.init(Dash=DrawingStyle.Dash))
+
+let empLine =
+ Shape.init(ShapeType=ShapeType.Line,X0=0.,X1=1.,Y0=0.4,Y1=0.4,Line=Line.init(Dash=DrawingStyle.DashDot,Color=Color.fromHex "#FC3E36"))
+
+let exampleDistribution =
+ [
+ [
+ examplePVals
+ |> Distributions.Frequency.create 0.025
+ |> Map.toArray
+ |> Array.map (fun (k,c) -> k,float c / (m * 0.025))
+ |> Chart.Column
+ |> Chart.withTraceInfo "density"
+ |> Chart.withTemplate ChartTemplates.lightMirrored
+ |> Chart.withXAxisStyle "p value"
+ |> Chart.withYAxisStyle "density"
+ |> Chart.withShapes [nullLine;empLine]
+
+ examplePVals
+ |> Distributions.Frequency.create 0.025
+ |> Map.toArray
+ |> Array.map (fun (k,c) -> k,float c)
+ |> Chart.Column
+ |> Chart.withTraceInfo "gene count"
+ |> Chart.withTemplate ChartTemplates.lightMirrored
+ |> Chart.withXAxisStyle "p value"
+ |> Chart.withYAxisStyle "gene count"
+ ]
+ ]
+ |> Chart.Grid()
+ |> Chart.withSize(1100.,550.)
+
+exampleDistribution
+Fig 6: p value distributions of real world example. The frequency is given on the right, its density on the left. The black dashed line indicates the distribution, if all features +were null. The red dash-dotted line indicates the visual estimated pi0.
+By performing t tests for all comparisons 3743 (38 %) of the genes lead to a pvalue lower than 0.05. +By eye, you would estimate $\pi_0$ as 0.4, indicating, only a small fraction of the genes are unaltered (null). After q value calculations, you would filter for a specific FDR (e.g. 0.05) and +end up with an p value threshold of 0.04613, indicating a FDR of max. 0.05 in the final reported 3642 genes.
+ +pi0 = 0.4
+m = 9856
+D(p) = number of sig. tests at given p
+FP(p) = p*0.4*9856
+FDR(p) = FP(p) / D(p)FDR(0.04613) = 0.4995
+Now let's compare p- to its corresponding q values with ensuring continuity
+ +let pi0 = 0.4
+
+let getD p =
+ examplePVals
+ |> Array.sumBy (fun x -> if x <= p then 1. else 0.)
+
+let getFP p = p * pi0 * m
+
+let getFDR p = (getFP p) / (getD p)
+
+let qvaluesNotSmoothed =
+ examplePVals
+ |> Array.sort
+ |> Array.map (fun x ->
+ x, getFDR x)
+ |> Chart.Line
+ |> Chart.withTraceInfo "not smoothed"
+
+let qvaluesSmoothed =
+ let pValsSorted =
+ examplePVals
+ |> Array.sortDescending
+ let rec loop i lowest acc =
+ if i = pValsSorted.Length then
+ acc |> List.rev
+ else
+ let p = pValsSorted.[i]
+ let q = getFDR p
+ if q > lowest then
+ loop (i+1) lowest ((p,lowest)::acc)
+ else loop (i+1) q ((p,q)::acc)
+ loop 0 1. []
+ |> Chart.Line
+ |> Chart.withTraceInfo "smoothed"
+
+let eXpos = examplePVals |> Array.filter (fun x -> x <= 0.046135) |> Array.length
+
+let p2qValeChart =
+ [qvaluesNotSmoothed;qvaluesSmoothed]
+ |> Chart.combine
+ |> Chart.withYAxisStyle("",MinMax=(0.,1.))
+ |> Chart.withTemplate ChartTemplates.lightMirrored
+ |> Chart.withXAxisStyle "p value"
+ |> Chart.withYAxisStyle "q value"
+ |> Chart.withShape empLine
+ |> Chart.withTitle (sprintf "#[genes with q value < 0.05] = %i" eXpos)
+
+p2qValeChart
+Fig 7: FDR calculation on experiment data. Please zoom into the very first part of the curve to inspect the monotonicity.
+For a range of $\lambda$ in e.g. $\{0.0 .. 0.05 .. 0.95\}$, calculate $\hat \pi_0 (\lambda) = \frac {\#[p_j > \lambda]}{m(1 - \lambda)}$
+ +let pi0Est =
+ [|0. .. 0.05 .. 0.95|]
+ |> Array.map (fun lambda ->
+ let num =
+ examplePVals
+ |> Array.sumBy (fun x -> if x > lambda then 1. else 0.)
+ let den = float examplePVals.Length * (1. - lambda)
+ lambda, num/den
+ )
+
+let pi0EstChart =
+ pi0Est
+ |> Chart.Point
+ |> Chart.withYAxisStyle("",MinMax=(0.,1.))
+ |> Chart.withXAxisStyle("",MinMax=(0.,1.))
+ |> Chart.withTemplate ChartTemplates.lightMirrored
+ |> Chart.withXAxisStyle "$\lambda$"
+ |> Chart.withYAxisStyle "$\hat \pi_0(\lambda)$"
+ |> Chart.withMathTex(true)
+ |> Chart.withConfig(
+ Config.init(
+ Responsive=true,
+ ModeBarButtonsToAdd=[
+ ModeBarButton.DrawLine
+ ModeBarButton.DrawOpenPath
+ ModeBarButton.EraseShape
+ ]
+ )
+ )
+
+pi0EstChart
+Fig 8: pi0 estimation.
+The resulting diagram shows, that with increasing $\lambda$ its function value $\hat \pi_0(\lambda)$ tends to $\pi_0$. The calculation relates the actual proportion of tests greater than $\lambda$ to the proportion of $\lambda$ range the corresponding p values are in. +In Storey & Tibshirani 2003 this curve is fitted with a cubic spline. A weighting of the knots by $(1 - \lambda)$ is recommended +but not specified in the final publication. Afterwards the function value at $\hat \pi_0(1)$ is defined as final estimator of $\pi_0$. This is often referred to as the smoother method.
+Another method (bootstrap method) (Storey et al., 2004), that does not depend on fitting is based on bootstrapping and was introduced in Storey et al. (2004). It is implemented in FSharp.Stats:
+Determine the minimal $\hat \pi_0 (\lambda)$ and call it $min \hat \pi_0$ .
+For each $\lambda$, bootstrap the p values (e.g. 100 times) and calculate the mean squared error (MSE) from the difference of resulting $\hat \pi_0^b$ to $min \hat \pi_0$. The minimal MSE indicates the best $\lambda$. With $\lambda$ +defined, $\pi_0$ can be determined. Note: When bootstrapping an data set of size n, n elements are drawn with replacement.
+let getpi0Bootstrap (lambda:float[]) (pValues:float[]) =
+ let rnd = System.Random()
+ let m = pValues.Length |> float
+ let getpi0hat lambda pVals=
+ let hits =
+ pVals
+ |> Array.sumBy (fun x -> if x > lambda then 1. else 0.)
+ hits / (m * (1. - lambda))
+
+ //calculate MSE for each lambda
+ let getMSE lambda =
+ let mse =
+ //generate 100 bootstrap samples of p values and calculate the MSE at given lambda
+ Array.init 100 (fun b ->
+ Array.sampleWithReplacement rnd pValues pValues.Length
+ |> getpi0hat lambda
+ )
+ mse
+ lambda
+ |> Array.map (fun l -> l,getMSE l)
+
+
+let minimalpihat =
+ //FSharp.Stats.Testing.MultipleTesting.Qvalues.pi0hats [|0. .. 0.05 .. 0.96|] examplePVals |> Array.minBy snd |> snd
+ 0.3686417749
+
+let minpiHatShape =
+ Shape.init(ShapeType=ShapeType.Line,X0=0.,X1=1.,Y0=minimalpihat,Y1=minimalpihat,Line=Line.init(Dash=DrawingStyle.Dash))
+
+let bootstrappedPi0 =
+ getpi0Bootstrap [|0. .. 0.05 .. 0.95|] examplePVals
+ |> Array.map (fun (l,x) ->
+ Chart.BoxPlot(data=x,orientation=Orientation.Vertical,FillColor=Color.fromHex"#1F77B4",MarkerColor=Color.fromHex"#1F77B4",Name=sprintf "%.2f" l))
+ |> Chart.combine
+ |> Chart.withShape minpiHatShape
+ |> Chart.withTemplate ChartTemplates.lightMirrored
+ |> Chart.withXAxisStyle "lambda"
+ |> Chart.withYAxisStyle "pi0 hat"
+
+bootstrappedPi0
+Fig 9: Bootstrapping for pi0 estimation. The dashed line indicates the minimal pi0 from Fig. 8. +The bootstrapped pi0 distribution that shows the least variation to the dashed line is the optimal. In the presented example it is either 0.8 or 0.85.
+For an $\lambda$, range of $\{0.0 .. 0.05 .. 0.95\}$ the bootstrapping method determines either 0.8 or 0.85 as optimal $\lambda$ and therefore $optimal \hat \pi_0$ is either $0.3703$ or $0.3686$.
+The automated estimation of $\pi_0$ based on bootstrapping is implemented in FSharp.Stats.Testing.MultipleTesting.Qvalues.
open Testing.MultipleTesting
+
+let pi0Stats = Qvalues.pi0BootstrapWithLambda [|0.0 .. 0.05 .. 0.95|] examplePVals
+
+pi0Stats
+0.3703327922077925
Subsequent to $\pi_0$ estimation the q values can be determined from a list of p values.
+ +let qValues = Qvalues.ofPValues pi0Stats examplePVals
+
+qValues
+[ 0.2690343536429767, 0.03451771894511998, 0.260005815044248, 0.2984261021835806, 0.08590835637088742, 0.3516354103053438, 0.14017753875059466, 0.3114779827361747, 0.25753341900121823, 0.028988378992537343, 0.3259266204071664, 0.031850238633144505, 0.2934858001322298, 0.13373258389042894, 0.010485759027169157, 0.16093162128197516, 0.02086019153225808, 0.3193118083488758, 0.0744394201633433, 0.06533030596475378 ... (9836 more) ]
A robust variant of q value determination exists, that is more conservative for small p values when +the total number of p values is low. Here the number of false positives is divided by the number of +total discoveries multiplied by the FWER at the current p value. The correction takes into account +the probability of a false positive being reported in the first place.
+Especially when the population distributions do not follow a perfect normal distribution or the p value distribution looks strange, +the usage of the robust version is recommended.
+let qvaluesRobust =
+ Testing.MultipleTesting.Qvalues.ofPValuesRobust pi0Stats examplePVals
+
+let qChart =
+ [
+ Chart.Line(Array.sortBy fst (Array.zip examplePVals qValues),Name="qValue")
+ Chart.Line(Array.sortBy fst (Array.zip examplePVals qvaluesRobust),Name="qValueRobust")
+ ]
+ |> Chart.combine
+ |> Chart.withTemplate ChartTemplates.lightMirrored
+ |> Chart.withXAxisStyle "p value"
+ |> Chart.withYAxisStyle "q value"
+Fig 10: Comparison of q values and robust q values, that is more conservative at low p values.
+let pi0Line =
+ Shape.init(ShapeType=ShapeType.Line,X0=0.,X1=1.,Y0=pi0Stats,Y1=pi0Stats,Line=Line.init(Dash=DrawingStyle.Dash))
+
+// relates the q value to each p value
+let p2q =
+ Array.zip examplePVals qValues
+ |> Array.sortBy fst
+ |> Chart.Line
+ |> Chart.withShape pi0Line
+ |> Chart.withTemplate ChartTemplates.lightMirrored
+ |> Chart.withXAxisStyle "p value"
+ |> Chart.withYAxisStyle "q value"
+
+// shows the p values distribution for an visual inspection of pi0 estimation
+let pValueDistribution =
+ let frequencyBins = 0.025
+ let m = examplePVals.Length |> float
+ examplePVals
+ |> Distributions.Frequency.create frequencyBins
+ |> Map.toArray
+ |> Array.map (fun (k,c) -> k,float c / frequencyBins / m)
+ |> Chart.StackedColumn
+ |> Chart.withTraceInfo "p values"
+ |> Chart.withTemplate ChartTemplates.lightMirrored
+ |> Chart.withXAxisStyle "p value"
+ |> Chart.withYAxisStyle "frequency density"
+ |> Chart.withShape pi0Line
+
+// shows pi0 estimation in relation to lambda
+let pi0Estimation =
+ //Testing.MultipleTesting.Qvalues.pi0hats [|0. .. 0.05 .. 0.96|] examplePVals
+ [|0. .. 0.05 .. 0.95|]
+ |> Array.map (fun lambda ->
+ let num =
+ examplePVals
+ |> Array.sumBy (fun x -> if x > lambda then 1. else 0.)
+ let den = float examplePVals.Length * (1. - lambda)
+ lambda, num/den
+ )
+ |> Chart.Point
+ |> Chart.withTemplate ChartTemplates.lightMirrored
+ |> Chart.withXAxisStyle "$\lambda$"
+ |> Chart.withYAxisStyle "$\hat \pi_0(\lambda)$"
+ |> Chart.withMathTex(true)
+
+p2q
+Fig 11: p value relation to q values. At a p value of 1 the q value is equal to pi0 (black dashed line).
+ +pValueDistribution
+Fig 12: p value density distribution. The dashed line indicates pi0 estimated by Storeys bootstrapping method.
+ +pi0Estimation
+Fig 13: Visual pi0 estimation.
+Why are q values lower than their associated p values?
+Which cut off should I use?
+In my study gene RBCM has an q value of 0.03. Does that indicate, there is a 3% chance, that it is an false positive?
+Should I use the default or robust version for my study?
+When should I use q values over BH correction, or other multiple testing variants?
+0.24680735077408789




0.3703327922077925
[ 0.2690343536429767, 0.03451771894511998, 0.260005815044248, 0.2984261021835806, 0.08590835637088742, 0.3516354103053438, 0.14017753875059466, 0.3114779827361747, 0.25753341900121823, 0.028988378992537343, 0.3259266204071664, 0.031850238633144505, 0.2934858001322298, 0.13373258389042894, 0.010485759027169157, 0.16093162128197516, 0.02086019153225808, 0.3193118083488758, 0.0744394201633433, 0.06533030596475378 ... (9836 more) ]
#r "nuget: Deedle.Interactive, 3.0.0"
-#r "nuget: FSharp.Stats, 0.4.3"
-#r "nuget: Plotly.NET.Interactive, 4.0.0"
-#r "nuget: FSharp.Data, 4.2.7"
-
-open FSharp.Data
-open Deedle
-open Plotly.NET
+#r "nuget: Deedle.Interactive, 3.0.0"
+#r "nuget: FSharp.Stats, 0.4.3"
+#r "nuget: Plotly.NET.Interactive, 4.0.0"
+#r "nuget: FSharp.Data, 4.2.7"
+
+open FSharp.Data
+open Deedle
+open Plotly.NET
// Get data from Deutscher Wetterdienst
-// Explanation for Abbreviations: https://www.dwd.de/DE/leistungen/klimadatendeutschland/beschreibung_tagesmonatswerte.html
-let rawData = FSharp.Data.Http.RequestString @"https://raw.githubusercontent.com/fslaborg/datasets/main/data/WeatherDataAachen-Orsbach_daily_1year.txt"
+// Get data from Deutscher Wetterdienst
+// Explanation for Abbreviations: https://www.dwd.de/DE/leistungen/klimadatendeutschland/beschreibung_tagesmonatswerte.html
+let rawData = FSharp.Data.Http.RequestString @"https://raw.githubusercontent.com/fslaborg/datasets/main/data/WeatherDataAachen-Orsbach_daily_1year.txt"
-// print first 1000 characters to console.
-rawData.[..1000]
+// print first 1000 characters to console.
+rawData.[..1000]
open System
-open System.Text.RegularExpressions
+open System
+open System.Text.RegularExpressions
-/// Tuple of 4 data arrays representing the measured temperature for over a year.
+/// Tuple of 4 data arrays representing the measured temperature for over a year.
let processedData =
- // First separate the huge string in lines
- rawData.Split([|'\n'|], StringSplitOptions.RemoveEmptyEntries)
- // Skip the first 5 rows until the real data starts, also skip the last row (length-2) to remove a "</pre>" at the end
- |> fun arr -> arr.[5..arr.Length-2]
+ // First separate the huge string in lines
+ rawData.Split([|'\n'|], StringSplitOptions.RemoveEmptyEntries)
+ // Skip the first 5 rows until the real data starts, also skip the last row (length-2) to remove a "</pre>" at the end
+ |> fun arr -> arr.[5..arr.Length-2]
|> Array.map (fun data ->
- // Regex pattern that will match groups of whitespace
- let whitespacePattern = @"\s+"
- // This is needed to tell regex to replace hits with a tabulator
- let matchEval = MatchEvaluator(fun _ -> @"\t" )
- // The original data columns are separated by different amounts of whitespace.
- // Therefore, we need a flexible string parsing option to replace any amount of whitespace with a single tabulator.
- // This is done with the regex pattern above and the fsharp core library "System.Text.RegularExpressions"
- let tabSeparated = Regex.Replace(data, whitespacePattern, matchEval)
- tabSeparated
- // Split each row by tabulator will return rows with an equal amount of values, which we can access.
- |> fun dataStr -> dataStr.Split([|@"\t"|], StringSplitOptions.RemoveEmptyEntries)
+ // Regex pattern that will match groups of whitespace
+ let whitespacePattern = @"\s+"
+ // This is needed to tell regex to replace hits with a tabulator
+ let matchEval = MatchEvaluator(fun _ -> @"\t" )
+ // The original data columns are separated by different amounts of whitespace.
+ // Therefore, we need a flexible string parsing option to replace any amount of whitespace with a single tabulator.
+ // This is done with the regex pattern above and the fsharp core library "System.Text.RegularExpressions"
+ let tabSeparated = Regex.Replace(data, whitespacePattern, matchEval)
+ tabSeparated
+ // Split each row by tabulator will return rows with an equal amount of values, which we can access.
+ |> fun dataStr -> dataStr.Split([|@"\t"|], StringSplitOptions.RemoveEmptyEntries)
|> fun dataArr ->
- // Second value is the date of measurement, which we will parse to the DateTime type
- DateTime.ParseExact(dataArr.[1], "yyyyMMdd", Globalization.CultureInfo.InvariantCulture),
- // 5th value is minimal temperature at that date.
- float dataArr.[4],
- // 6th value is average temperature over 24 timepoints at that date.
- float dataArr.[5],
- // 7th value is maximal temperature at that date.
- float dataArr.[6]
- )
- // Sort by date
- |> Array.sortBy (fun (day,tn,tm,tx) -> day)
- // Unzip the array of value tuples, to make the different values easier accessible
+ // Second value is the date of measurement, which we will parse to the DateTime type
+ DateTime.ParseExact(dataArr.[1], "yyyyMMdd", Globalization.CultureInfo.InvariantCulture),
+ // 5th value is minimal temperature at that date.
+ float dataArr.[4],
+ // 6th value is average temperature over 24 timepoints at that date.
+ float dataArr.[5],
+ // 7th value is maximal temperature at that date.
+ float dataArr.[6]
+ )
+ // Sort by date
+ |> Array.sortBy (fun (day,tn,tm,tx) -> day)
+ // Unzip the array of value tuples, to make the different values easier accessible
|> fun arr ->
- arr |> Array.map (fun (day,tn,tm,tx) -> day.ToShortDateString()),
- arr |> Array.map (fun (day,tn,tm,tx) -> tm),
- arr |> Array.map (fun (day,tn,tm,tx) -> tx),
- arr |> Array.map (fun (day,tn,tm,tx) -> tn)
+ arr |> Array.map (fun (day,tn,tm,tx) -> day.ToShortDateString()),
+ arr |> Array.map (fun (day,tn,tm,tx) -> tm),
+ arr |> Array.map (fun (day,tn,tm,tx) -> tx),
+ arr |> Array.map (fun (day,tn,tm,tx) -> tn)
-processedData
+processedData
open Plotly.NET
-open Plotly.NET.LayoutObjects
+open Plotly.NET
+open Plotly.NET.LayoutObjects
-// Because our data set is already rather wide we want to move the legend from the right side of the plot
-// to the right center.
+// Because our data set is already rather wide we want to move the legend from the right side of the plot
+// to the right center.
let legend =
- Legend.init(
- YAnchor = StyleParam.YAnchorPosition.Top,
- Y = 0.99,
- XAnchor = StyleParam.XAnchorPosition.Left,
- X = 0.5
- )
-
-/// This function will take 'processedData' as input and return a range chart with a line for the average temperature
-/// and a different colored area for the range between minimal and maximal temperature at that date.
-let createTempChart (days,tm,tmUpper,tmLower) =
- Chart.Range(
- // data arrays
+ Legend.init(
+ YAnchor = StyleParam.YAnchorPosition.Top,
+ Y = 0.99,
+ XAnchor = StyleParam.XAnchorPosition.Left,
+ X = 0.5
+ )
+
+/// This function will take 'processedData' as input and return a range chart with a line for the average temperature
+/// and a different colored area for the range between minimal and maximal temperature at that date.
+let createTempChart (days,tm,tmUpper,tmLower) =
+ Chart.Range(
+ // data arrays
x = days,
y = tm,
upper = tmUpper,
- lower = tmLower,
- mode = StyleParam.Mode.Lines,
- MarkerColor= Color.fromString "#3D1244",
- RangeColor= Color.fromString "#F99BDE",
- // Name for line in legend
- Name="Average temperature over 24 timepoints each day",
- // Name for lower point when hovering over chart
- LowerName="Min temp",
- // Name for upper point when hovering over chart
- UpperName="Max temp"
- )
- // Configure the chart with the legend from above
- |> Chart.withLegend legend
- // Add name to y axis
- |> Chart.withYAxisStyle("daily temperature [°C]")
- |> Chart.withSize (1000.,600.)
-
-/// Chart for original data set
+ lower = tmLower,
+ mode = StyleParam.Mode.Lines,
+ MarkerColor= Color.fromString "#3D1244",
+ RangeColor= Color.fromString "#F99BDE",
+ // Name for line in legend
+ Name="Average temperature over 24 timepoints each day",
+ // Name for lower point when hovering over chart
+ LowerName="Min temp",
+ // Name for upper point when hovering over chart
+ UpperName="Max temp"
+ )
+ // Configure the chart with the legend from above
+ |> Chart.withLegend legend
+ // Add name to y axis
+ |> Chart.withYAxisStyle("daily temperature [°C]")
+ |> Chart.withSize (1000.,600.)
+
+/// Chart for original data set
processedData
-|> createTempChart
+|> createTempChart
open FSharp.Stats
+open FSharp.Stats
-let smootheTemp ws order (days,tm,tmUpper,tmLower) =
- let tm' = Signal.Filtering.savitzkyGolay ws order 0 1 tm
- let tmUpper' = Signal.Filtering.savitzkyGolay ws order 0 1 tmUpper
- let tmLower' = Signal.Filtering.savitzkyGolay ws order 0 1 tmLower
- days,tm',tmUpper',tmLower'
+let smootheTemp ws order (days,tm,tmUpper,tmLower) =
+ let tm' = Signal.Filtering.savitzkyGolay ws order 0 1 tm
+ let tmUpper' = Signal.Filtering.savitzkyGolay ws order 0 1 tmUpper
+ let tmLower' = Signal.Filtering.savitzkyGolay ws order 0 1 tmLower
+ days,tm',tmUpper',tmLower'
-processedData
-|> smootheTemp 31 4
-|> createTempChart
+processedData
+|> smootheTemp 31 4
+|> createTempChart
#r "nuget: Deedle.Interactive, 3.0.0"
-#r "nuget: FSharp.Stats, 0.4.3"
-#r "nuget: Plotly.NET.Interactive, 4.0.0"
-#r "nuget: FSharp.Data, 4.2.7"
-
-open FSharp.Data
-open Deedle
-open Plotly.NET
+#r "nuget: Deedle.Interactive, 3.0.0"
+#r "nuget: FSharp.Stats, 0.4.3"
+#r "nuget: Plotly.NET.Interactive, 4.0.0"
+#r "nuget: FSharp.Data, 4.2.7"
+
+open FSharp.Data
+open Deedle
+open Plotly.NET
// We retrieve the dataset via FSharp.Data:
-let rawDataHousefly = Http.RequestString @"https://raw.githubusercontent.com/fslaborg/datasets/main/data/HouseflyWingLength.txt"
+// We retrieve the dataset via FSharp.Data:
+let rawDataHousefly = Http.RequestString @"https://raw.githubusercontent.com/fslaborg/datasets/main/data/HouseflyWingLength.txt"
let dataHousefly : seq<float> =
- Frame.ReadCsvString(rawDataHousefly, false, schema = "wing length (mm * 10^1)")
- |> Frame.getCol "wing length (mm * 10^1)"
- |> Series.values
- // We convert the values to mm
- |> Seq.map (fun x -> x / 10.)
+ Frame.ReadCsvString(rawDataHousefly, false, schema = "wing length (mm * 10^1)")
+ |> Frame.getCol "wing length (mm * 10^1)"
+ |> Series.values
+ // We convert the values to mm
+ |> Seq.map (fun x -> x / 10.)
Chart.BoxPlot(
+Chart.BoxPlot(
Y = dataHousefly,
Name = "housefly",
BoxPoints = StyleParam.BoxPoints.All,
- Jitter = 0.2
-)
-|> Chart.withYAxisStyle "wing length [mm]"
+ Jitter = 0.2
+)
+|> Chart.withYAxisStyle "wing length [mm]"
open FSharp.Stats
-open FSharp.Stats.Testing
+open FSharp.Stats
+open FSharp.Stats.Testing
-// The testing module in FSharp.Stats require vectors as input types, thus we transform our array into a vector:
-let vectorDataHousefly = vector dataHousefly
+// The testing module in FSharp.Stats require vectors as input types, thus we transform our array into a vector:
+let vectorDataHousefly = vector dataHousefly
-// The expected value of our population.
-let expectedValue = 4.5
+// The expected value of our population.
+let expectedValue = 4.5
-// Perform the one-sample t-test with our vectorized data and our exptected value as parameters.
-let oneSampleResult = TTest.oneSample vectorDataHousefly expectedValue
+// Perform the one-sample t-test with our vectorized data and our exptected value as parameters.
+let oneSampleResult = TTest.oneSample vectorDataHousefly expectedValue
-oneSampleResult
+oneSampleResult
open System.Text
+open System.Text
-let rawDataAthletes = Http.RequestString @"https://raw.githubusercontent.com/fslaborg/datasets/main/data/ConcussionsInMaleAndFemaleCollegeAthletes_adapted.tsv"
+let rawDataAthletes = Http.RequestString @"https://raw.githubusercontent.com/fslaborg/datasets/main/data/ConcussionsInMaleAndFemaleCollegeAthletes_adapted.tsv"
-let dataAthletesAsStream = new System.IO.MemoryStream(rawDataAthletes |> Encoding.UTF8.GetBytes)
+let dataAthletesAsStream = new System.IO.MemoryStream(rawDataAthletes |> Encoding.UTF8.GetBytes)
-// The schema helps us setting column keys.
-let dataAthletesAsFrame = Frame.ReadCsv(dataAthletesAsStream, hasHeaders = false, separators = "\t", schema = "Gender, Sports, Year, Concussion, Count")
+// The schema helps us setting column keys.
+let dataAthletesAsFrame = Frame.ReadCsv(dataAthletesAsStream, hasHeaders = false, separators = "\t", schema = "Gender, Sports, Year, Concussion, Count")
-dataAthletesAsFrame
+dataAthletesAsFrame
// We need to filter out the columns and rows we don't need. Thus, we filter out the rows where the athletes suffered no concussions
-// as well as filter out the columns without the number of concussions.
-let dataAthletesFemale, dataAthletesMale =
- let getAthleteGenderData gender =
- let dataAthletesOnlyConcussion =
- dataAthletesAsFrame
- |> Frame.filterRows (fun r objS -> objS.GetAs "Concussion")
- let dataAthletesGenderFrame =
- dataAthletesOnlyConcussion
- |> Frame.filterRows (fun r objS -> objS.GetAs "Gender" = gender)
- dataAthletesGenderFrame
+// We need to filter out the columns and rows we don't need. Thus, we filter out the rows where the athletes suffered no concussions
+// as well as filter out the columns without the number of concussions.
+let dataAthletesFemale, dataAthletesMale =
+ let getAthleteGenderData gender =
+ let dataAthletesOnlyConcussion =
+ dataAthletesAsFrame
+ |> Frame.filterRows (fun r objS -> objS.GetAs "Concussion")
+ let dataAthletesGenderFrame =
+ dataAthletesOnlyConcussion
+ |> Frame.filterRows (fun r objS -> objS.GetAs "Gender" = gender)
+ dataAthletesGenderFrame
|> Frame.getCol "Count"
- |> Series.values
- |> vector
- getAthleteGenderData "Female", getAthleteGenderData "Male"
+ |> Series.values
+ |> vector
+ getAthleteGenderData "Female", getAthleteGenderData "Male"
[
- Chart.BoxPlot(Y = dataAthletesFemale, Name = "female college athletes", BoxPoints = StyleParam.BoxPoints.All, Jitter = 0.2)
- Chart.BoxPlot(Y = dataAthletesMale, Name = "male college athletes", BoxPoints = StyleParam.BoxPoints.All, Jitter = 0.2)
-]
-|> Chart.combine
-|> Chart.withYAxisStyle "number of concussions over 3 years"
+[
+ Chart.BoxPlot(Y = dataAthletesFemale, Name = "female college athletes", BoxPoints = StyleParam.BoxPoints.All, Jitter = 0.2)
+ Chart.BoxPlot(Y = dataAthletesMale, Name = "male college athletes", BoxPoints = StyleParam.BoxPoints.All, Jitter = 0.2)
+]
+|> Chart.combine
+|> Chart.withYAxisStyle "number of concussions over 3 years"
// We test both samples against each other, assuming equal variances.
-let twoSampleResult = TTest.twoSample true dataAthletesFemale dataAthletesMale
+// We test both samples against each other, assuming equal variances.
+let twoSampleResult = TTest.twoSample true dataAthletesFemale dataAthletesMale
-twoSampleResult
+twoSampleResult
let rawDataCaffeine = Http.RequestString @"https://raw.githubusercontent.com/fslaborg/datasets/main/data/CaffeineAndEndurance(wide)_adapted.tsv"
+let rawDataCaffeine = Http.RequestString @"https://raw.githubusercontent.com/fslaborg/datasets/main/data/CaffeineAndEndurance(wide)_adapted.tsv"
-let dataCaffeineAsStream = new System.IO.MemoryStream(rawDataCaffeine |> Encoding.UTF8.GetBytes)
-let dataCaffeineAsFrame = Frame.ReadCsv(dataCaffeineAsStream, hasHeaders = false, separators = "\t", schema = "Subject ID, no Dose, 5 mg, 9 mg, 13 mg")
+let dataCaffeineAsStream = new System.IO.MemoryStream(rawDataCaffeine |> Encoding.UTF8.GetBytes)
+let dataCaffeineAsFrame = Frame.ReadCsv(dataCaffeineAsStream, hasHeaders = false, separators = "\t", schema = "Subject ID, no Dose, 5 mg, 9 mg, 13 mg")
-// We want to compare the subjects' performances under the influence of 13 mg caffeine and in the control situation.
-let dataCaffeineNoDose, dataCaffeine13mg =
+// We want to compare the subjects' performances under the influence of 13 mg caffeine and in the control situation.
+let dataCaffeineNoDose, dataCaffeine13mg =
let getVectorFromCol col =
- dataCaffeineAsFrame
- |> Frame.getCol col
- |> Series.values
- |> vector
- getVectorFromCol "no Dose", getVectorFromCol "13 mg"
+ dataCaffeineAsFrame
+ |> Frame.getCol col
+ |> Series.values
+ |> vector
+ getVectorFromCol "no Dose", getVectorFromCol "13 mg"
-// Transforming our data into a chart.
+// Transforming our data into a chart.
-Seq.zip dataCaffeineNoDose dataCaffeine13mg
+Seq.zip dataCaffeineNoDose dataCaffeine13mg
|> Seq.mapi (fun i (control,treatment) ->
let participant = "Person " + string i
- Chart.Line(["no dose", control; "13 mg", treatment], Name = participant)
- )
-|> Chart.combine
-|> Chart.withXAxisStyle ""
-|> Chart.withYAxisStyle("endurance performance", MinMax = (0.,100.))
+ Chart.Line(["no dose", control; "13 mg", treatment], Name = participant)
+ )
+|> Chart.combine
+|> Chart.withXAxisStyle ""
+|> Chart.withYAxisStyle("endurance performance", MinMax = (0.,100.))
let twoSamplePairedResult = TTest.twoSamplePaired dataCaffeineNoDose dataCaffeine13mg
-twoSamplePairedResult
+let twoSamplePairedResult = TTest.twoSamplePaired dataCaffeineNoDose dataCaffeine13mg
+twoSamplePairedResult