inDexDa - Natural Language Processing of academic papers for dataset identification and indexing.
An Initiative for human-centered Innovation in the Knowledge Sphere of the ETH Library Lab.
Three different networks were tested for the pipeline which determines whether an academic paper indicates a new dataset. The data used to train these networks were several hundred papers which did point towards a new dataset and 1500 which did not. The positive examples were taken from YACVID and reference computer vision datasets, and the negative examples were randomly sampled from arXiv over a range of subjects. The best performing network, BERT, was chosen as the network of choice for this project.
To train these networks, you can either use the dataset provided with inDexDa, or you can create your own dataset and use that. If you wish to do the latter, you must prepare it in the same way as the default inDexDa dataset.
Rules for Dataset Preparation:
- Positive training examples should in their own file (
inDexDa/data/positive_samples.json) and the format should be a list of strings where each string is a new paper abstract. - Do the same as above but with the negative training samples (file name should be
changed to
[...]/negative_samples.json)
BERT is the Bidirectional Encoder Representations from Transforms language model. It was recently published by researchers in Google's AI Learning division. The complexity of BERT cannot be explained here, but Google allows you to download the pre-trained network and then fine-tuning can be done for the user-specific task.
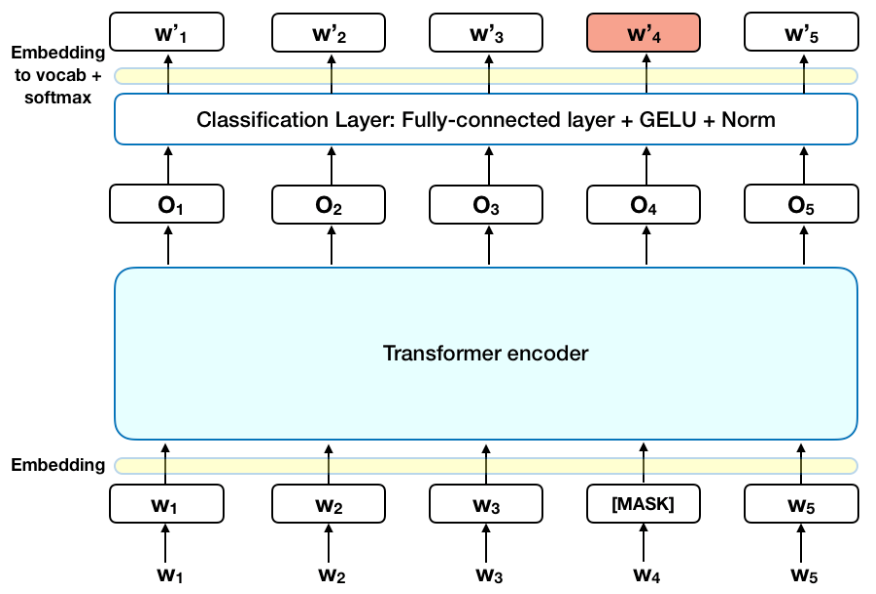
Our BERT network (using the ktrain front-end) takes as input a list of strings, where each string is a new academic paper abstract. The testing is taken care of by the main inDexDa run.py script in the main folder. When the --scrape flag is used, the pretrained network is used (pretrained on provided inDexDa dataset). By using the --train flag on the main script, the BERT network will be retrained using either the user provided dataset or, if none was give, the default inDexDa dataset.
The output of the network will be the results.json file located in inDexDa/data/. This file will only contain papers that the network predicts point towards a dataset and each entry in this file will contain the information about those papers (title, authors, abstrat, etc).