diff --git a/serverless/nav/serverless-devtools.docnav.json b/serverless/nav/serverless-devtools.docnav.json
deleted file mode 100644
index d474c5a8..00000000
--- a/serverless/nav/serverless-devtools.docnav.json
+++ /dev/null
@@ -1,29 +0,0 @@
-{
- "mission": "Dev tools",
- "id": "serverless-Devtools",
- "landingPageSlug": "/serverless/devtools/developer-tools",
- "icon": "logoElastic",
- "description": "Description to be written",
- "items": [
- {
- "slug": "/serverless/devtools/run-api-requests-in-the-console",
- "classic-sources": ["enKibanaConsoleKibana"]
- },
- {
- "slug": "/serverless/devtools/profile-queries-and-aggregations",
- "classic-sources": ["enKibanaXpackProfiler"]
- },
- {
- "slug": "/serverless/devtools/debug-grok-expressions",
- "classic-sources": ["enKibanaXpackGrokdebugger"]
- },
- {
- "slug": "/serverless/devtools/debug-painless-scripts",
- "classic-sources": ["enKibanaPainlesslab"]
- },
- {
- "slug": "/serverless/devtools/dev-tools-troubleshooting",
- "classic-sources": ["enElasticsearchReferenceTroubleshootingSearches"]
- }
- ]
- }
diff --git a/serverless/nav/serverless-elasticsearch.docnav.json b/serverless/nav/serverless-elasticsearch.docnav.json
deleted file mode 100644
index 403db5d8..00000000
--- a/serverless/nav/serverless-elasticsearch.docnav.json
+++ /dev/null
@@ -1,134 +0,0 @@
-{
- "mission": "Elasticsearch",
- "id": "serverless-elasticsearch",
- "landingPageSlug": "/serverless/elasticsearch/what-is-elasticsearch-serverless",
- "icon": "logoElasticsearch",
- "description": "Description to be written",
- "items": [
- {
- "slug": "/serverless/elasticsearch/what-is-elasticsearch-serverless"
- },
- {
- "slug": "/serverless/elasticsearch/elasticsearch-billing"
- },
- {
- "slug": "/serverless/elasticsearch/get-started"
- },
- {
- "slug": "/serverless/elasticsearch/clients",
- "items": [
- {
- "slug": "/serverless/elasticsearch/go-client-getting-started"
- },
- {
- "slug": "/serverless/elasticsearch/java-client-getting-started"
- },
- {
- "slug": "/serverless/elasticsearch/dot-net-client-getting-started"
- },
- {
- "slug": "/serverless/elasticsearch/nodejs-client-getting-started"
- },
- {
- "slug": "/serverless/elasticsearch/php-client-getting-started"
- },
- {
- "slug": "/serverless/elasticsearch/python-client-getting-started"
- },
- {
- "slug": "/serverless/elasticsearch/ruby-client-getting-started"
- }
- ]
- },
- {
- "slug": "/serverless/elasticsearch/http-apis",
- "items": [
- {
- "slug": "/serverless/elasticsearch/api-conventions",
- "classic-sources": [ "enElasticsearchReferenceApiConventions" ]
- },
- {
- "slug": "/serverless/elasticsearch/kibana-api-conventions",
- "classic-sources": [ "enKibanaApi" ]
- }
- ]
- },
- {
- "slug": "/serverless/elasticsearch/dev-tools"
- },
- {
- "slug": "/serverless/elasticsearch/ingest-your-data",
- "items": [
- {
- "slug": "/serverless/elasticsearch/ingest-data-through-api"
- },
- {
- "slug": "/serverless/elasticsearch/ingest-data-through-integrations-connector-client"
- },
- {
- "slug": "/serverless/elasticsearch/ingest-data-file-upload"
- },
- {
- "slug": "/serverless/elasticsearch/ingest-data-through-logstash"
- },
- {
- "slug": "/serverless/elasticsearch/ingest-data-through-beats",
- "classic-sources": [ "enFleetBeatsAgentComparison" ]
- }
- ]
- },
- {
- "slug": "/serverless/elasticsearch/search-your-data",
- "items": [
- {
- "slug": "/serverless/elasticsearch/search-your-data-the-search-api"
- },
- {
- "slug": "/serverless/elasticsearch/elasticsearch/reference/search-with-synonyms"
- },
- {
- "slug": "/serverless/elasticsearch/knn-search"
- },
- {
- "slug": "/serverless/elasticsearch/elasticsearch/reference/semantic-search",
- "items": [
- {
- "slug": "/serverless/elasticsearch/elasticsearch/reference/semantic-search-elser"
- }
- ]
- }
- ]
- },
- {
- "slug": "/serverless/elasticsearch/explore-your-data",
- "items": [
- {
- "slug": "/serverless/elasticsearch/explore-your-data-aggregations"
- },
- {
- "slug": "/serverless/elasticsearch/explore-your-data-discover-your-data",
- "classic-sources": [ "enKibanaDiscover" ]
- },
- {
- "slug": "/serverless/elasticsearch/explore-your-data-visualize-your-data",
- "classic-sources": [ "enKibanaDashboard" ]
- },
- {
- "slug": "/serverless/elasticsearch/explore-your-data-alerting",
- "classic-sources": [ "enKibanaCreateAndManageRules" ],
- "label": "Alerts"
- }
- ]
- },
- {
- "slug": "/serverless/elasticsearch/playground"
- },
- {
- "slug": "/serverless/elasticsearch/differences",
- "label": "Serverless differences"
- },
- {
- "slug": "/serverless/elasticsearch/technical-preview-limitations"
- }
- ]
-}
\ No newline at end of file
diff --git a/serverless/nav/serverless-general.docnav.json b/serverless/nav/serverless-general.docnav.json
deleted file mode 100644
index cfc371ca..00000000
--- a/serverless/nav/serverless-general.docnav.json
+++ /dev/null
@@ -1,68 +0,0 @@
-{
- "mission": "Welcome to Elastic serverless",
- "id": "serverless-general",
- "landingPageSlug": "/serverless",
- "icon": "logoElastic",
- "description": "Create and manage serverless projects on Elastic Cloud",
- "items": [
- {
- "slug": "/serverless/general/what-is-serverless-elastic"
- },
- {
- "slug": "/serverless/general/sign-up-trial"
- },
- {
- "slug": "/serverless/general/manage-organization",
- "items": [
- {
- "slug": "/serverless/general/manage-access-to-organization"
- },
- {
- "slug": "/serverless/general/assign-user-roles"
- },
- {
- "slug": "/serverless/general/join-organization-from-existing-cloud-account"
- }
- ]
- },
- {
- "label": "Manage your projects",
- "slug": "/serverless/elasticsearch/manage-project",
- "items": [
- {
- "slug": "/serverless/general/manage-project-with-api"
- }
- ]
- },
- {
- "label": "Manage billing",
- "slug": "/serverless/general/manage-billing",
- "items": [
- {
- "slug": "/serverless/general/check-subscription"
- },
- {
- "slug": "/serverless/general/monitor-usage"
- },
- {
- "slug": "/serverless/general/billing-history"
- },
- {
- "slug": "/serverless/general/serverless-billing"
- },
- {
- "slug": "/serverless/general/billing-stop-project"
- }
- ]
- },
- {
- "slug": "/serverless/general/serverless-status"
- },
- {
- "slug": "/serverless/general/user-profile"
- },
- {
- "slug": "/serverless/regions"
- }
- ]
-}
diff --git a/serverless/nav/serverless-project-settings.docnav.json b/serverless/nav/serverless-project-settings.docnav.json
deleted file mode 100644
index 63386f90..00000000
--- a/serverless/nav/serverless-project-settings.docnav.json
+++ /dev/null
@@ -1,82 +0,0 @@
-{
- "mission": "Project and management settings",
- "id": "serverless-project-settings",
- "landingPageSlug": "/serverless/project-and-management-settings",
- "icon": "logoElastic",
- "description": "Description to be written",
- "items": [
- {
- "slug": "/serverless/project-settings",
- "classic-sources": ["enKibanaManagement"],
- "label": "Management",
- "items": [
- {
- "slug": "/serverless/api-keys",
- "classic-sources": ["enKibanaApiKeys"]
- },
- {
- "slug": "/serverless/action-connectors",
- "classic-sources": ["enKibanaActionTypes"]
- },
- {
- "slug": "/serverless/custom-roles"
- },
- {
- "slug": "/serverless/data-views",
- "classic-sources": ["enKibanaDataViews"]
- },
- {
- "slug": "/serverless/files"
- },
- {
- "slug": "/serverless/index-management",
- "classic-sources": ["enElasticsearchReferenceIndexMgmt"]
- },
- {
- "slug": "/serverless/ingest-pipelines"
- },
- {
- "slug": "/serverless/logstash-pipelines"
- },
- {
- "slug": "/serverless/machine-learning"
- },
- {
- "slug": "/serverless/maintenance-windows",
- "classic-sources": ["enKibanaMaintenanceWindows"]
- },
- {
- "slug": "/serverless/maps"
- },
- {
- "slug": "/serverless/reports"
- },
- {
- "slug": "/serverless/rules",
- "classic-sources": [ "enKibanaAlertingGettingStarted" ]
- },
- {
- "slug": "/serverless/saved-objects",
- "classic-sources": ["enKibanaManagingSavedObjects"]
- },
- {
- "slug": "/serverless/spaces"
- },
- {
- "slug": "/serverless/tags",
- "classic-sources": ["enKibanaManagingTags"]
- },
- {
- "slug": "/serverless/transforms",
- "classic-sources": ["enElasticsearchReferenceTransforms"]
- }
- ]
- },
- {
- "slug": "/serverless/integrations"
- },
- {
- "slug": "/serverless/fleet-and-elastic-agent"
- }
- ]
-}
diff --git a/serverless/pages/action-connectors.mdx b/serverless/pages/action-connectors.mdx
deleted file mode 100644
index 98c109cc..00000000
--- a/serverless/pages/action-connectors.mdx
+++ /dev/null
@@ -1,317 +0,0 @@
----
-slug: /serverless/action-connectors
-title: ((connectors-app))
-description: Configure connections to third party systems for use in cases and rules.
-tags: [ 'serverless' ]
----
-
-
-This content applies to:
-
-The list of available connectors varies by project type.
-
-
-
-{/* Connectors provide a central place to store connection information for services and integrations with third party systems.
-Actions are instantiations of a connector that are linked to rules and run as background tasks on the ((kib)) server when rule conditions are met. */}
-{/* ((kib)) provides the following types of connectors for use with ((alert-features)) :
-
-- [D3 Security](((kibana-ref))/d3security-action-type.html)
-- [Email](((kibana-ref))/email-action-type.html)
-- [Generative AI](((kibana-ref))/gen-ai-action-type.html)
-- [IBM Resilient](((kibana-ref))/resilient-action-type.html)
-- [Index](((kibana-ref))/index-action-type.html)
-- [Jira](((kibana-ref))/jira-action-type.html)
-- [Microsoft Teams](((kibana-ref))/teams-action-type.html)
-- [Opsgenie](((kibana-ref))/opsgenie-action-type.html)
-- [PagerDuty](((kibana-ref))/pagerduty-action-type.html)
-- [ServerLog](((kibana-ref))/server-log-action-type.html)
-- [ServiceNow ITSM](((kibana-ref))/servicenow-action-type.html)
-- [ServiceNow SecOps](((kibana-ref))/servicenow-sir-action-type.html)
-- [ServiceNow ITOM](((kibana-ref))/servicenow-itom-action-type.html)
-- [Slack](((kibana-ref))/slack-action-type.html)
-- [Swimlane](((kibana-ref))/swimlane-action-type.html)
-- [Tines](((kibana-ref))/tines-action-type.html)
-- [Torq](((kibana-ref))/torq-action-type.html)
-- [Webhook](((kibana-ref))/webhook-action-type.html)
-- [Webhook - Case Management](((kibana-ref))/cases-webhook-action-type.html)
-- [xMatters](((kibana-ref))/xmatters-action-type.html) */}
-
-{/* [cols="2"] */}
-{/* | | |
-|---|---|
-| Email | Send email from your server. |
-| ((ibm-r)) | Create an incident in ((ibm-r)). |
-| Index | Index data into Elasticsearch. |
-| Jira | Create an incident in Jira. |
-| Microsoft Teams | Send a message to a Microsoft Teams channel. |
-| Opsgenie | Create or close an alert in Opsgenie. |
-| | Send an event in PagerDuty. |
-| ServerLog | Add a message to a Kibana log. |
-| ((sn-itsm)) | Create an incident in ((sn)). |
-| ((sn-sir)) | Create a security incident in ((sn)). |
-| ((sn-itom)) | Create an event in ((sn)). |
-| Slack | Send a message to a Slack channel or user. |
-| ((swimlane)) | Create an incident in ((swimlane)). |
-| Tines | Send events to a Tines Story. |
-| ((webhook)) | Send a request to a web service. |
-| ((webhook-cm)) | Send a request to a Case Management web service. |
-| xMatters | Send actionable alerts to on-call xMatters resources. |
-| Torq |
-| Generative AI |
-| D3 Security | */}
-
-{/*
-
-Some connector types are paid commercial features, while others are free.
-For a comparison of the Elastic subscription levels, go to
-[the subscription page](((subscriptions))).
-
- */}
-
-{/*
-## Managing connectors
-
-Rules use connectors to route actions to different destinations like log files, ticketing systems, and messaging tools. While each ((kib)) app can offer their own types of rules, they typically share connectors. **((stack-manage-app)) → ((connectors-ui))** offers a central place to view and manage all the connectors in the current space.
-
- */}
-{/* NOTE: This is an autogenerated screenshot. Do not edit it directly. */}
-{/*
-## Required permissions
-
-Access to connectors is granted based on your privileges to alerting-enabled
-features. For more information, go to Security.
-
-## Connector networking configuration
-
-Use the action configuration settings to customize connector networking configurations, such as proxies, certificates, or TLS settings. You can set configurations that apply to all your connectors or use `xpack.actions.customHostSettings` to set per-host configurations.
-
-## Connector list
-
-In **((stack-manage-app)) → ((connectors-ui))**, you can find a list of the connectors
-in the current space. You can use the search bar to find specific connectors by
-name and type. The **Type** dropdown also enables you to filter to a subset of
-connector types.
-
- */}
-{/* NOTE: This is an autogenerated screenshot. Do not edit it directly. */}
-{/*
-You can delete individual connectors using the trash icon. Alternatively, select
-multiple connectors and delete them in bulk using the **Delete** button.
-
- */}
-{/* NOTE: This is an autogenerated screenshot. Do not edit it directly. */}
-{/*
-
-
-You can delete a connector even if there are still actions referencing it.
-When this happens the action will fail to run and errors appear in the ((kib)) logs.
-
-
-
-## Creating a new connector
-
-New connectors can be created with the **Create connector** button, which guides
-you to select the type of connector and configure its properties.
-
-
-
-After you create a connector, it is available for use any time you set up an
-action in the current space.
-
-For out-of-the-box and standardized connectors, refer to
-preconfigured connectors.
-
-
-You can also manage connectors as resources with the [Elasticstack provider](https://registry.terraform.io/providers/elastic/elasticstack/latest) for Terraform.
-For more details, refer to the [elasticstack_kibana_action_connector](https://registry.terraform.io/providers/elastic/elasticstack/latest/docs/resources/kibana_action_connector) resource.
-
-
-## Importing and exporting connectors
-
-To import and export connectors, use the
-Saved Objects Management UI.
-
-
-
-If a connector is missing sensitive information after the import, a **Fix**
-button appears in **((connectors-ui))**.
-
-
-
-## Monitoring connectors
-
-The Task Manager health API helps you understand the performance of all tasks in your environment.
-However, if connectors fail to run, they will report as successful to Task Manager. The failure stats will not
-accurately depict the performance of connectors.
-
-For more information on connector successes and failures, refer to the Event log index.
-
-The include that was here is another page */}
diff --git a/serverless/pages/api-keys.mdx b/serverless/pages/api-keys.mdx
deleted file mode 100644
index cff7c614..00000000
--- a/serverless/pages/api-keys.mdx
+++ /dev/null
@@ -1,99 +0,0 @@
----
-slug: /serverless/api-keys
-title: ((api-keys-app))
-description: API keys allow access to the ((stack)) on behalf of a user.
-tags: ["serverless", "Elasticsearch", "Observability", "Security"]
----
-
-
-This content applies to:
-
-API keys are security mechanisms used to authenticate and authorize access to ((stack)) resources,
-and ensure that only authorized users or applications are able to interact with the ((stack)).
-
-For example, if you extract data from an ((es)) cluster on a daily basis, you might create an API key tied to your credentials, configure it with minimum access, and then put the API credentials into a cron job.
-Or, you might create API keys to automate ingestion of new data from remote sources, without a live user interaction.
-
-You can manage your keys in **((project-settings)) → ((manage-app)) → ((api-keys-app))**:
-
-
-{/* TBD: This image was refreshed but should be automated */}
-
-A _personal API key_ allows external services to access the ((stack)) on behalf of a user.
-{/* Cross-Cluster API key: allows remote clusters to connect to your local cluster. */}
-A _managed API key_ is created and managed by ((kib)) to correctly run background tasks.
-
-{/* TBD (accurate?) Secondary credentials have the same or lower access rights. */}
-
-{/* ## Security privileges
-
-You must have the `manage_security`, `manage_api_key`, or the `manage_own_api_key`
-cluster privileges to use API keys in Elastic. API keys can also be seen in a readonly view with access to the page and the `read_security` cluster privilege. To manage roles, open the main menu, then click
-**Management → Custom Roles**, or use the Role Management API. */}
-
-## Create an API key
-
-In **((api-keys-app))**, click **Create API key**:
-
-
-
-Once created, you can copy the encoded API key and use it to send requests to the ((es)) HTTP API. For example:
-
-```bash
-curl "${ES_URL}" \
--H "Authorization: ApiKey ${API_KEY}"
-```
-
-
- API keys are intended for programmatic access. Don't use API keys to
- authenticate access using a web browser.
-
-
-### Restrict privileges
-
-When you create or update an API key, use **Restrict privileges** to limit the permissions. Define the permissions using a JSON `role_descriptors` object, where you specify one or more roles and the associated privileges.
-
-For example, the following `role_descriptors` object defines a `books-read-only` role that limits the API key to `read` privileges on the `books` index.
-
-```json
-{
- "books-read-only": {
- "cluster": [],
- "indices": [
- {
- "names": ["books"],
- "privileges": ["read"]
- }
- ],
- "applications": [],
- "run_as": [],
- "metadata": {},
- "transient_metadata": {
- "enabled": true
- }
- }
-}
-```
-
-For the `role_descriptors` object schema, check out the [`/_security/api_key` endpoint](((ref))/security-api-create-api-key.html#security-api-create-api-key-request-body) docs. For supported privileges, check [Security privileges](((ref))/security-privileges.html#privileges-list-indices).
-
-## Update an API key
-
-In **((api-keys-app))**, click on the name of the key.
-You can update only **Restrict privileges** and **Include metadata**.
-
-{/* TBD: Refer to the update API key documentation to learn more about updating personal API keys. */}
-
-## View and delete API keys
-
-The **((api-keys-app))** app lists your API keys, including the name, date created, and status.
-When API keys expire, the status changes from `Active` to `Expired`.
-
-{/*
-TBD: RBAC requirements for serverless?
-If you have `manage_security` or `manage_api_key` permissions,
-you can view the API keys of all users, and see which API key was
-created by which user in which realm.
-If you have only the `manage_own_api_key` permission, you see only a list of your own keys. */}
-
-You can delete API keys individually or in bulk.
diff --git a/serverless/pages/apis-elasticsearch-conventions.mdx b/serverless/pages/apis-elasticsearch-conventions.mdx
deleted file mode 100644
index aa259caf..00000000
--- a/serverless/pages/apis-elasticsearch-conventions.mdx
+++ /dev/null
@@ -1,211 +0,0 @@
----
-slug: /serverless/elasticsearch/api-conventions
-title: Elasticsearch API conventions
-description: The ((es)) REST APIs have conventions for headers and request bodies.
-tags: [ 'serverless', 'elasticsearch', 'API', 'reference' ]
----
-
-
-You can run ((es)) API requests in **((dev-tools-app)) → Console**.
-For example:
-
-```shell
-GET _cat/indices?v=true
-```
-
-Check out .
-
-## Request headers
-
-When you call ((es)) APIs outside of the Console, you must provide a request header.
-The ((es)) APIs support the `Authorization`, `Content-Type`, and `X-Opaque-Id` headers.
-
-### Authorization
-
-((es)) APIs use key-based authentication.
-You must create an API key and use the encoded value in the request header.
-For example:
-
-```bash
-curl -X GET "${ES_URL}/_cat/indices?v=true" \
- -H "Authorization: ApiKey ${API_KEY}"
-```
-
-To get API keys or the Elasticsearch Endpoint (`${ES_URL}`) for a project, refer to .
-
-### Content-type
-
-The type of the content sent in a request body must be specified using the `Content-Type` header.
-For example:
-
-```bash
-curl -X GET "${ES_URL}/_search?pretty" \
- -H "Authorization: ApiKey ${API_KEY}" \
- -H "Content-Type: application/json" \
- -d '
- {
- "query": {
- "match_all": { "boost" : 1.2 }
- }
- }
-'
-```
-
-The value of this header must map to one of the formats that the API supports.
-Most APIs support JSON, YAML, CBOR, and SMILE.
-The bulk and multi-search APIs support NDJSON, JSON, and SMILE; other types will result in an error response.
-
-If you use the `source` query string parameter, you must specify the content type with the `source_content_type` query string parameter.
-
-((es)) APIs support only UTF-8-encoded JSON.
-Any other encoding headings sent with a request are ignored.
-Responses are also UTF-8 encoded.
-
-{/*
-TBD: Is this something you specify in the request header or find in the response header?
-### Traceparent
-
-((es)) APIs support a `traceparent` HTTP header using the [official W3C trace context spec](https://www.w3.org/TR/trace-context/#traceparent-header).
-You can use the `traceparent` header to trace requests across Elastic products and other services.
-Because it's used only for traces, you can safely generate a unique `traceparent` header for each request.
-
-((es)) APIs surface the header's `trace-id` value as `trace.id` in the:
-
-* JSON ((es)) server logs
-* Slow logs
-* Deprecation logs
-
-For example, a `traceparent` value of `00-0af7651916cd43dd8448eb211c80319c-b7ad6b7169203331-01` would produce the following
-`trace.id` value in the logs: `0af7651916cd43dd8448eb211c80319c`.
-*/}
-
-### X-Opaque-Id
-
-You can pass an `X-Opaque-Id` HTTP header to track the origin of a request in ((es)) logs and tasks.
-For example:
-
-```bash
-curl -X GET "${ES_URL}/_search?pretty" \
- -H "Authorization: ApiKey ${API_KEY}" \
- -H "Content-Type: application/json" \
- -H "X-Opaque-Id: 123456" \
- -d '
- {
- "query": {
- "match_all": { "boost" : 1.2 }
- }
- }
-'
-```
-
-((es)) surfaces the `X-Opaque-Id` value in the:
-
-* Response of any request that includes the header
-* Task management API response
-* Slow logs
-* Deprecation logs
-
-{/* MISSING LINKS
-* Response of any request that includes the header
-* \<\<_identifying_running_tasks,Task management API>> response
-* \<\<_identifying_search_slow_log_origin,Slow logs>>
-* missing link{/* Deprecation logs
-*/}
-For the deprecation logs, ((es)) also uses the `X-Opaque-Id` value to throttle and deduplicate deprecation warnings.
-{/* MISSING LINKS
-See \<\<_deprecation_logs_throttling>>.
-*/}
-
-The `X-Opaque-Id` header accepts any arbitrary value.
-However, it is recommended that you limit these values to a finite set, such as an ID per client.
-Don't generate a unique `X-Opaque-Id` header for every request.
-Too many unique `X-Opaque-Id` values can prevent ((es)) from deduplicating warnings in the deprecation logs.
-
-## Request bodies
-
-A number of ((es)) APIs with GET operations--most notably the search API--support a request body.
-While the GET operation makes sense in the context of retrieving information, GET requests with a body are not supported by all HTTP libraries.
-
-All ((es)) APIs with GET operations that require a body can also be submitted as POST requests.
-Alternatively, you can pass the request body as the `source` query string parameter when using GET.
-When you use this method, the `source_content_type` parameter should also be passed with a media type value that indicates the format of the source, such as `application/json`.
-
-{/*
-TBD: The examples in this section don't current seem to work.
-Error: no handler found for uri [.../_search?pretty=true] and method [GET]"
-
-## Date math
-
-Most ((es)) APIs that accept an index or index alias argument support date math.
-Date math name resolution enables you to search a range of time series indices or index aliases rather than searching all of your indices and filtering the results.
-Limiting the number of searched indices reduces cluster load and improves search performance.
-For example, if you are searching for errors in your daily logs, you can use a date math name template to restrict the search to the past two days.
-
-A date math name takes the following form:
-
-```txt
-
-```
-- `static_name` is static text.
-- `date_math_expr` is a dynamic date math expression that computes the date dynamically.
-- `date_format` is the optional format in which the computed date should be rendered. Defaults to `yyyy.MM.dd`. The format should be compatible with [java-time](https://docs.oracle.com/javase/8/docs/api/java/time/format/DateTimeFormatter.html).
-- `time_zone` is the optional time zone. Defaults to `UTC`.
-
-
-For example, `mm` denotes the minute of the hour, while `MM` denotes the month of the year.
-Similarly `hh` denotes the hour in the `1-12` range in combination with `AM/PM`, while `HH` denotes the hour in the `0-23` 24-hour range.
-
-
-Date math expressions are resolved independent of the locale.
-Consequently, you cannot use any calendars other than the Gregorian calendar.
-
-You must enclose date math names in angle brackets.
-If you use the name in a request path, special characters must be URI encoded.
-For example, `` is encoded as `%3Cmy-index-%7Bnow%2Fd%7D%3E`.
-
-The special characters used for date rounding must be URI encoded.
-For example:
-
-| | |
-|---|---|
-| `<` | `%3C` |
-| `>` | `%3E` |
-| `/` | `%2F` |
-| `{` | `%7B` |
-| `}` | `%7D` |
-| `\|` | `%7C` |
-| `+` | `%2B` |
-| `:` | `%3A` |
-| `,` | `%2C` |
-
-The following example shows different forms of date math names and the final names they resolve to given the current time is 22nd March 2024 noon UTC:
-
-| Expression | Resolves to |
-|---|---|
-| `` | `logstash-2024.03.22` |
-| `` | `logstash-2024.03.01` |
-| `` | `logstash-2024.03` |
-| `` | `logstash-2024.02` |
-| `` | `logstash-2024.03.23` |
-
-To use the characters `{` and `}` in the static part of a name template, escape them with a backslash `\`.
-For example, `` resolves to `elastic{ON}-2024.03.01`
-
-The following example shows a search request that searches the ((ls)) indices for the past three days, assuming the indices use the default ((ls)) index name format (`logstash-YYYY.MM.dd`):
-
-```console
-# ,,
-curl -X GET "${ES_URL}/%3Clogstash-%7Bnow%2Fd-2d%7D%3E%2C%3Clogstash-%7Bnow%2Fd-1d%7D%3E%2C%3Clogstash-%7Bnow%2Fd%7D%3E/_search" \
- -H "Authorization: ApiKey ${API_KEY}" \
- -H "Content-Type: application/json" \
- -d '
- {
- "query" : {
- "match": {
- "test": "data"
- }
- }
- }
-'
-```
-*/}
diff --git a/serverless/pages/apis-http-apis.mdx b/serverless/pages/apis-http-apis.mdx
deleted file mode 100644
index 83e764da..00000000
--- a/serverless/pages/apis-http-apis.mdx
+++ /dev/null
@@ -1,26 +0,0 @@
----
-slug: /serverless/elasticsearch/http-apis
-title: REST APIs
-description: ((es)) and ((kib)) expose REST APIs that can be called directly to configure and access ((stack)) features.
-tags: [ 'serverless', 'elasticsearch', 'http', 'rest', 'overview' ]
----
-
-
-
-
\ No newline at end of file
diff --git a/serverless/pages/apis-kibana-conventions.mdx b/serverless/pages/apis-kibana-conventions.mdx
deleted file mode 100644
index 6fdeebea..00000000
--- a/serverless/pages/apis-kibana-conventions.mdx
+++ /dev/null
@@ -1,80 +0,0 @@
----
-slug: /serverless/elasticsearch/kibana-api-conventions
-title: Management API conventions
-description: The Management APIs for ((serverless-short)) have request header conventions.
-tags: [ 'serverless', 'kibana', 'API', 'reference' ]
----
-
-
-
-The Management REST APIs for ((serverless-full)) let you manage resources that are available in multiple solutions.
-These resources include connectors, data views, and saved objects.
-If you've previously used the ((stack)), the Management APIs are similar to ((kib)) APIs.
-
-Management API calls are stateless.
-Each request that you make happens in isolation from other calls and must include all of the necessary information for ((kib)) to fulfill the request.
-API requests return JSON output, which is a format that is machine-readable and works well for automation.
-
-To interact with Management APIs, use the following operations:
-
-- GET: Fetches the information.
-- POST: Adds new information.
-- PUT: Updates the existing information.
-- DELETE: Removes the information.
-
-You can prepend any Management API endpoint with `kbn:` and run the request in **((dev-tools-app)) → Console**.
-For example:
-
-```shell
-GET kbn:/api/data_views
-```
-
-Check out .
-
-## Request headers
-
-When you call Management APIs outside of the Console, you must provide a request header.
-The Management APIs support the `Authorization`, `Content-Type`, and `kbn-xsrf` headers.
-
-`Authorization: ApiKey`
-
-: Management APIs use key-based authentication.
- You must create an API key and use the encoded value in the request header.
- To learn about creating keys, go to .
-
-`Content-Type: application/json`
-
-: You must use this header when you send a payload in the API request.
- Typically, if you include the `kbn-xsrf` header, you must also include the `Content-Type` header.
-
-`kbn-xsrf: true`
-
-: You must use this header for all API calls except `GET` or `HEAD` operations.
-
-{/*
-TBD: Are these settings accessible to users in serverless projects?
-
-This header is also not required when:
-* The path is allowed using the `server.xsrf.allowlist` setting
-* XSRF protections are disabled using the `server.xsrf.disableProtection` setting
-*/}
-
-For example:
-
-```bash
-curl -X POST \
- "${KIBANA_URL}/api/data_views/data_view" \
- -H "Authorization: ApiKey ${API_KEY}" \
- -H 'Content-Type: application/json' \
- -H 'kbn-xsrf: true' \
- -d '{
- "data_view": {
- "title": "books*",
- "name": "My Books Data View"
- }
- }
-'
-```
-{/*
-TBD: Add instructions for how to obtain the KIBANA_URL
- */}
\ No newline at end of file
diff --git a/serverless/pages/clients-dot-net-getting-started.mdx b/serverless/pages/clients-dot-net-getting-started.mdx
deleted file mode 100644
index 86c161ef..00000000
--- a/serverless/pages/clients-dot-net-getting-started.mdx
+++ /dev/null
@@ -1,126 +0,0 @@
----
-slug: /serverless/elasticsearch/dot-net-client-getting-started
-title: Get started with the serverless .NET client
-description: Set up and use the .NET client for ((es3)).
-tags: [ 'serverless', 'elasticsearch', '.net', 'how to' ]
----
-
-
-
-This page guides you through the installation process of the
-.NET client for ((es3)), shows you how to initialize the client, and how to perform basic
-((es)) operations with it.
-
-
-## Requirements
-
-* .NET Core, .NET 5+ or .NET Framework (4.6.1 and higher).
-
-
-## Installation
-
-You can install the .NET client with the following command:
-
-```bash
-dotnet add package Elastic.Clients.Elasticsearch.Serverless
-```
-
-
-## Initialize the client
-
-Initialize the client using your API key and Elasticsearch Endpoint:
-
-```net
-var client = new ElasticsearchClient("", new ApiKey(""));
-```
-
-To get API keys or the Elasticsearch Endpoint for a project, see .
-
-
-## Using the API
-
-After you've initialized the client, you can create an index and start ingesting
-documents.
-
-
-### Creating an index and ingesting documents
-
-The following is an example of creating a `my_index` index:
-
-```net
-var response = await client.Indices.CreateAsync("my_index");
-```
-
-This is a simple way of indexing a document into `my_index`:
-
-```net
-var doc = new MyDoc
-{
- Id = 1,
- User = "xyz_user",
- Message = "Trying out the client, so far so good?"
-};
-
-var response = await client.IndexAsync(doc, "my_index");
-```
-
-
-### Getting documents
-
-You can get documents by using the following code:
-
-```net
-var response = await client.GetAsync(id, idx => idx.Index("my_index"));
-
-if (response.IsValidResponse)
-{
- var doc = response.Source;
-}
-```
-
-
-### Searching
-
-This is how you can create a single match query with the .NET client:
-
-```net
-var response = await client.SearchAsync(s => s
- .Index("my_index")
- .From(0)
- .Size(10)
- .Query(q => q
- .Term(t => t.User, "flobernd")
- )
-);
-
-if (response.IsValidResponse)
-{
- var doc = response.Documents.FirstOrDefault();
-}
-```
-
-
-### Updating a document
-
-This is how you can update a document, for example to add a new field:
-
-```net
-doc.Message = "This is a new message";
-
-var response = await client.UpdateAsync("my_index", 1, u => u
- .Doc(doc));
-```
-
-### Deleting a document
-
-```net
-var response = await client.DeleteAsync("my_index", 1);
-```
-
-
-### Deleting an index
-
-
-```net
-var response = await client.Indices.DeleteAsync("my_index");
-```
\ No newline at end of file
diff --git a/serverless/pages/clients-go-getting-started.mdx b/serverless/pages/clients-go-getting-started.mdx
deleted file mode 100644
index f7c00985..00000000
--- a/serverless/pages/clients-go-getting-started.mdx
+++ /dev/null
@@ -1,214 +0,0 @@
----
-slug: /serverless/elasticsearch/go-client-getting-started
-title: Get started with the serverless Go Client
-description: Set up and use the Go client for ((es3)).
-tags: [ 'serverless', 'elasticsearch', 'go', 'how to' ]
----
-
-
-This page guides you through the installation process of the Go
-client for ((es3)), shows you how to initialize the client, and how to perform basic
-((es)) operations with it.
-
-
-## Requirements
-
-* Go 1.20 or higher installed on your system.
-
-
-## Installation
-
-
-### Using the command line
-
-You can install the Go client with the following
-commands:
-
-```bash
-go get -u github.com/elastic/elasticsearch-serverless-go@latest
-```
-
-
-## Imports
-
-The following snippets use these imports:
-
-```go
-import (
- "context"
- "encoding/json"
- "fmt"
- "log"
- "strconv"
-
- "github.com/elastic/elasticsearch-serverless-go"
- "github.com/elastic/elasticsearch-serverless-go/typedapi/types"
- "github.com/elastic/elasticsearch-serverless-go/typedapi/types/enums/result"
-)
-```
-
-
-## Initialize the client
-
-Initialize the client using your API key and Elasticsearch Endpoint:
-
-```go
-client, err := elasticsearch.NewClient(elasticsearch.Config{
- APIKey: "you_api_key",
- Address: "https://my-project-url",
-})
-if err != nil {
- log.Fatal(err)
-}
-```
-
-To get API keys or the Elasticsearch Endpoint for a project, see .
-
-
-## Using the API
-
-After you've initialized the client, you can start ingesting documents. You can
-use the `bulk` API for this. This API enables you to index, update, and delete
-several documents in one request.
-
-
-### Creating an index and ingesting documents
-
-You can call the `bulk` API with a body parameter, an array of hashes that
-define the action, and a document.
-
-The following is an example of indexing some classic books into the `books`
-index:
-
-```go
-type Book struct {
- Name string `json:"name"`
- Author string `json:"author"`
- ReleaseDate string `json:"release_date"`
- PageCount int `json:"page_count"`
-}
-
-books := []Book{
- {Name: "Snow Crash", Author: "Neal Stephenson", ReleaseDate: "1992-06-01", PageCount: 470},
- {Name: "Revelation Space", Author: "Alastair Reynolds", ReleaseDate: "2000-03-15", PageCount: 585},
- {Name: "1984", Author: "George Orwell", ReleaseDate: "1949-06-08", PageCount: 328},
- {Name: "Fahrenheit 451", Author: "Ray Bradbury", ReleaseDate: "1953-10-15", PageCount: 227},
- {Name: "Brave New World", Author: "Aldous Huxley", ReleaseDate: "1932-06-01", PageCount: 268},
- {Name: "The Handmaid's Tale", Author: "Margaret Atwood", ReleaseDate: "1985-06-01", PageCount: 311},
-}
-indexName := "books"
-
-bulk := client.Bulk()
-for i, book := range books {
- id := strconv.Itoa(i)
- err := bulk.CreateOp(types.CreateOperation{Index_: &indexName, Id_: &id}, book)
- if err != nil {
- log.Fatal(err)
- }
-}
-bulkRes, err := bulk.Do(context.TODO())
-if err != nil {
- log.Fatal(err)
-}
-
-fmt.Printf("Bulk: %#v\n", bulkRes.Items)
-```
-
-When you use the client to make a request to ((es)), it returns an API
-response object. You can access the body values directly as seen on
-the previous example with `bulkRes`.
-
-
-### Getting documents
-
-You can get documents by using the following code:
-
-```go
-getRes, err := client.Get(indexName, "5").Do(context.TODO())
-if err != nil {
- log.Fatal(err)
-}
-book := Book{}
-if err := json.Unmarshal(getRes.Source_, &book); err != nil {
- log.Fatal(err)
-}
-fmt.Printf("Get book: %#v\n", book)
-```
-
-
-### Searching
-
-Now that some data is available, you can search your documents using the
-`search` API:
-
-```go
-searchRes, err := client.Search().
- Index("books").
- Q("snow").
- Do(context.TODO())
-if err != nil {
- log.Fatal(err)
-}
-
-bookSearch := []Book{}
-for _, hit := range searchRes.Hits.Hits {
- book := Book{}
- if err := json.Unmarshal(hit.Source_, &book); err != nil {
- log.Fatal(err)
- }
- bookSearch = append(bookSearch, book)
-}
-fmt.Printf("Search books: %#v\n", bookSearch)
-```
-
-### Updating a document
-
-You can call the `Update` API to update a document, in this example updating the
-`page_count` for "The Handmaid's Tale" with id "5":
-
-```go
-updateRes, err := client.Update("books", "5").
- Doc(
- struct {
- PageCount int `json:"page_count"`
- }{PageCount: 312},
- ).
- Do(context.TODO())
-if err != nil {
- log.Fatal(err)
-}
-
-if updateRes.Result == result.Updated {
- fmt.Printf("Update book: %#v\n", updateRes)
-}
-```
-
-### Deleting a document
-
-You can call the `Delete` API to delete a document:
-
-```go
-deleteRes, err := client.Delete("books", "5").Do(context.TODO())
-if err != nil {
- log.Fatal(err)
-}
-
-if deleteRes.Result == result.Deleted {
- fmt.Printf("Delete book: %#v\n", deleteRes)
-}
-```
-
-
-### Deleting an index
-
-
-```go
-indexDeleteRes, err := client.Indices.Delete("books").Do(context.TODO())
-if err != nil {
- log.Fatal(err)
-}
-
-if indexDeleteRes.Acknowledged {
- fmt.Printf("Delete index: %#v\n", indexDeleteRes)
-}
-```
\ No newline at end of file
diff --git a/serverless/pages/clients-java-getting-started.mdx b/serverless/pages/clients-java-getting-started.mdx
deleted file mode 100644
index 016b4e6a..00000000
--- a/serverless/pages/clients-java-getting-started.mdx
+++ /dev/null
@@ -1,172 +0,0 @@
----
-slug: /serverless/elasticsearch/java-client-getting-started
-title: Get started with the serverless Java client
-description: Set up and use the Java client for ((es3)).
-tags: [ 'serverless', 'elasticsearch', 'java', 'how to' ]
----
-
-
-This page guides you through the installation process of the Java
-client for ((es3)), shows you how to initialize the client, and how to perform basic
-((es)) operations with it.
-
-## Requirements
-
-* Java 8 or later.
-* A JSON object mapping library to allow seamless integration of
-your application classes with the ((es)) API. The examples below
-show usage with Jackson.
-
-## Installation
-
-
-You can add the Java client to your Java project using
-either Gradle or Maven.
-
-### Using Gradle
-
-You can install the Java client as a Gradle dependency:
-
-```groovy
-dependencies {
- implementation 'co.elastic.clients:elasticsearch-java-serverless:1.0.0-20231031'
- implementation 'com.fasterxml.jackson.core:jackson-databind:2.17.0'
-}
-```
-
-### Using Maven
-
-You can install the Java client as a Maven dependency, add
-the following to the `pom.xml` of your project:
-
-```xml
-
-
-
-
- co.elastic.clients
- elasticsearch-java-serverless
- 1.0.0-20231031
-
-
-
- com.fasterxml.jackson.core
- jackson-databind
- 2.17.0
-
-
-
-
-```
-
-## Initialize the client
-
-Initialize the client using your API key and Elasticsearch Endpoint:
-
-```java
-// URL and API key
-String serverUrl = "https://...elastic.cloud";
-String apiKey = "VnVhQ2ZHY0JDZGJrU...";
-
-// Create the low-level client
-RestClient restClient = RestClient
- .builder(HttpHost.create(serverUrl))
- .setDefaultHeaders(new Header[]{
- new BasicHeader("Authorization", "ApiKey " + apiKey)
- })
- .build();
-
-// Create the transport with a Jackson mapper
-ElasticsearchTransport transport = new RestClientTransport(
- restClient, new JacksonJsonpMapper());
-
-// And create the API client
-ElasticsearchClient esClient = new ElasticsearchClient(transport);
-```
-
-To get API keys or the Elasticsearch Endpoint for a project, see .
-
-
-## Using the API
-
-After you initialized the client, you can start ingesting documents.
-
-
-### Creating an index and ingesting documents
-
-The following is an example of indexing a document, here a `Product` application
-object in the `products` index:
-
-```java
-Product product = new Product("bk-1", "City bike", 123.0);
-
-IndexResponse response = esClient.index(i -> i
- .index("products")
- .id(product.getSku())
- .document(product)
-);
-
-logger.info("Indexed with version " + response.version());
-```
-
-
-### Searching
-
-Now that some data is available, you can search your documents using the
-`search` API:
-
-```java
-String searchText = "bike";
-
-SearchResponse response = esClient.search(s -> s
- .index("products")
- .query(q -> q
- .match(t -> t
- .field("name")
- .query(searchText)
- )
- ),
- Product.class
-);
-```
-
-A few things to note in the above example:
-
-* The search query is built using a hierarchy of lambda expressions that closely
-follows the ((es)) HTTP API. Lambda expressions allows you to be guided
-by your IDE's autocompletion, without having to import (or even know!) the
-actual classes representing a query.
-* The last parameter `Product.class` instructs the client to return results as
-`Product` application objects instead of raw JSON.
-
-
-### Updating
-
-You can update your documents using the `update` API:
-
-```java
-Product product = new Product("bk-1", "City bike", 123.0);
-
-esClient.update(u -> u
- .index("products")
- .id("bk-1")
- .upsert(product),
- Product.class
-);
-```
-
-### Delete
-
-You can also delete documents:
-
-```java
-esClient.delete(d -> d.index("products").id("bk-1"));
-```
-
-
-### Deleting an index
-
-
-```java
-esClient.indices().delete(d -> d.index("products"));
-```
diff --git a/serverless/pages/clients-nodejs-getting-started.mdx b/serverless/pages/clients-nodejs-getting-started.mdx
deleted file mode 100644
index 51a95936..00000000
--- a/serverless/pages/clients-nodejs-getting-started.mdx
+++ /dev/null
@@ -1,151 +0,0 @@
----
-slug: /serverless/elasticsearch/nodejs-client-getting-started
-title: Get started with the serverless Node.js client
-description: Set up and use the Node.js client for ((es3)).
-tags: [ 'serverless', 'elasticsearch', 'nodejs', 'how to' ]
----
-
-
-This page guides you through the installation process of the Node.js
-client for ((es3)), shows you how to initialize the client, and how to perform basic
-((es)) operations with it.
-
-## Requirements
-
-* Node.js 16 or higher installed on your system.
-
-## Installation
-
-### Using the command line
-
-You can install the Node.js client with the following
-commands:
-
-```bash
-npm install @elastic/elasticsearch-serverless
-```
-
-## Initialize the client
-
-Initialize the client using your API key and Elasticsearch Endpoint:
-
-```js
-const { Client } = require('@elastic/elasticsearch-serverless')
-const client = new Client({
- node: 'https://', // serverless project URL
- auth: { apiKey: 'your_api_key' }, // project API key
-})
-```
-
-To get API keys or the URL for a project, see .
-
-## Using the API
-
-After you've initialized the client, you can start ingesting documents.
-You can use the `bulk` API for this.
-This API enables you to index, update, and delete several documents in one request.
-
-### Creating an index and ingesting documents
-
-You can call the `bulk` helper API with a list of documents and a handler for
-what action to perform on each document.
-
-The following is an example of bulk indexing some classic books into the `books`
-index:
-
-```js
-// First we build our data:
-const body = [
- {name: "Snow Crash", "author": "Neal Stephenson", "release_date": "1992-06-01", "page_count": 470},
- {name: "Revelation Space", "author": "Alastair Reynolds", "release_date": "2000-03-15", "page_count": 585},
- {name: "1984", "author": "George Orwell", "release_date": "1985-06-01", "page_count": 328},
- {name: "Fahrenheit 451", "author": "Ray Bradbury", "release_date": "1953-10-15", "page_count": 227},
- {name: "Brave New World", "author": "Aldous Huxley", "release_date": "1932-06-01", "page_count": 268},
- {name: "The Handmaid's Tale", "author": "Margaret Atwood", "release_date": "1985-06-01", "page_count": 311}
-]
-
-// Then we send the data using the bulk API helper:
-const result = await client.helpers.bulk({
- datasource: body,
- onDocument (doc) {
- // instructs the bulk indexer to add each item in `body` to the books index
- // you can optionally inspect each `doc` object to alter what action is performed per document
- return {
- index: { _index: 'books' }
- }
- }
-})
-```
-
-
-### Getting documents
-
-You can get documents by using the following code:
-
-```js
-await client.get({
- index: 'books',
- id: 'a_document_id',
-})
-```
-
-
-### Searching
-
-Now that some data is available, you can search your documents using the `search` API:
-
-```js
-const result = await client.search({
- index: 'books',
- query: {
- match: {
- author: 'ray bradbury'
- }
- }
-})
-console.log(result.hits.hits)
-```
-
-
-### Updating a document
-
-You can call the `update` API to update a document:
-
-```js
-await client.update({
- index: 'books',
- id: 'a_document_id',
- doc: {
- author: 'S.E. Hinton',
- new_field: 'new value'
- }
-})
-```
-
-### Deleting a document
-
-You can call the `delete` API to delete a document:
-
-```js
-await client.delete({
- index: 'books',
- id: 'a_document_id',
-})
-```
-
-
-### Deleting an index
-
-
-```js
-await client.indices.delete({ index: 'books' })
-```
-
-
-## TypeScript
-
-The Node.js client is implemented in TypeScript. IDEs that support
-TypeScript-based autocompletion should automatically find and load the
-appropriate declaration files in the package's `lib` directory.
-The source TypeScript can also be
-[viewed on GitHub](https://github.com/elastic/elasticsearch-serverless-js/tree/main/src).
diff --git a/serverless/pages/clients-php-getting-started.mdx b/serverless/pages/clients-php-getting-started.mdx
deleted file mode 100644
index 7fb3360c..00000000
--- a/serverless/pages/clients-php-getting-started.mdx
+++ /dev/null
@@ -1,177 +0,0 @@
----
-slug: /serverless/elasticsearch/php-client-getting-started
-title: Get started with the serverless PHP client
-description: Set up and use the PHP client for ((es3)).
-tags: ["serverless", "elasticsearch", "php", "how to"]
----
-
-
-This page guides you through the installation process of the
-PHP client for ((es3)), shows you how to initialize the client, and how to perform basic
-((es)) operations with it.
-
-## Requirements
-
-- PHP 8.0 or higher installed on your system.
-
-## Installation
-
-### Using the command line
-
-You can install the PHP client using
-[composer](https://getcomposer.org/) with the following commands:
-
-```bash
-composer require elastic/elasticsearch-serverless
-```
-
-## Initialize the client
-
-Initialize the client using your API key and Elasticsearch Endpoint:
-
-```php
-require 'vendor/autoload.php';
-
-use Elastic\Elasticsearch\Serverless\ClientBuilder;
-
-$client = ClientBuilder::create()
- ->setEndpoint('')
- ->setApiKey('')
- ->build();
-```
-
-To get API keys or the Elasticsearch Endpoint for a project, see .
-
-## Using the API
-
-After you've initialized the client, you can start ingesting documents. You can
-use the `bulk` API for this. This API enables you to index, update, and delete
-several documents in one request.
-
-### Creating an index and ingesting documents
-
-You can call the `bulk` API with a body parameter, an array of actions (index)
-and documents.
-
-The following is an example of indexing some classic books into the `books`
-index:
-
-```php
-$body = [
- [ "index" => [ "_index" => "books" ]],
- [ "name" => "Snow Crash", "author" => "Neal Stephenson", "release_date" => "1992-06-01", "page_count" => 470],
- [ "index" => [ "_index" => "books" ]],
- [ "name" => "Revelation Space", "author" => "Alastair Reynolds", "release_date" => "2000-03-15", "page_count" => 585],
- [ "index" => [ "_index" => "books" ]],
- [ "name" => "1984", "author" => "George Orwell", "release_date" => "1949-06-08", "page_count" => 328],
- [ "index" => [ "_index" => "books" ]],
- [ "name" => "Fahrenheit 451", "author" => "Ray Bradbury", "release_date" => "1953-10-15", "page_count" => 227],
- [ "index" => [ "_index" => "books" ]],
- [ "name" => "Brave New World", "author" => "Aldous Huxley", "release_date" => "1932-06-01", "page_count" => 268],
- [ "index" => [ "_index" => "books" ]],
- [ "name" => "The Handmaid's Tale", "author" => "Margaret Atwood", "release_date" => "1985-06-01", "page_count" => 311]
-];
-
-$response = $client->bulk(body: $body);
-# You can check the response if the items are indexed and have an ID
-print_r($response['items']);
-```
-
-When you use the client to make a request to ((es)), it returns an API response
-object. This object implements the [PSR-7](https://www.php-fig.org/psr/psr-7/)
-interface, that means you can check the for the HTTP status using the following
-method:
-
-```php
-print($response->getStatusCode());
-```
-
-or get the HTTP response headers using the following:
-
-```php
-print_r($response->getHeaders());
-```
-
-or reading the HTTP response body as follows:
-
-```php
-print($response->getBody()->getContents());
-# or using the asString() dedicated method
-print($response->asString());
-```
-
-The response body can be accessed as associative array or as object.
-
-```php
-var_dump($response['items']); # associative array
-var_dump($response->items); # object
-```
-
-There are also methods to render the response as array, object, string and
-boolean values.
-
-```php
-var_dump($response->asArray()); // response body content as array
-var_dump($response->asObject()); // response body content as object
-var_dump($response->asString()); // response body as string (JSON)
-var_dump($response->asBool()); // true if HTTP response code between 200 and 300
-```
-
-### Getting documents
-
-You can get documents by using the following code:
-
-```php
-$response = $client->get(index: "books", id: $id);
-```
-
-### Searching
-
-You can search your documents using the `search` API:
-
-```php
-# Search for all the books written by Ray Bradbury
-$query = [ 'query' => [ 'match' => [ 'author' => 'Ray Bradbury' ]]];
-$response = $client->search(index: "books", body: $query);
-
-printf("Documents found: %d\n", $response['hits']['total']['value']); # total documents found
-print_r($response['hits']['hits']); # list of books
-```
-
-For more information about the `search` API's query parameters and the response type,
-refer to the
-[Search API](https://www.elastic.co/docs/api/doc/elasticsearch-serverless/group/endpoint-search)
-docs.
-
-### Updating documents
-
-You can call the `update` API to update a document:
-
-```php
-$id = '';
-# update the "page_count" value to 300
-$body = [ "doc" => [ "page_count" => 300 ]];
-$response = $client->update(index: "books", id: $id, body: $body);
-printf("Operation result: %s\n", $response['result']); # You get 'updated' as a result.
-```
-
-### Deleting documents
-
-You can call the `delete` API to delete a document:
-
-```php
-$id = '';
-$response = $client->delete(index: "books", id: $id);
-printf("Operation result: %s\n", $response['result']); # You get "deleted" a as result.
-```
-
-### Deleting an index
-
-You can delete an entire index as follows:
-
-```php
-$response = $client->indices()->delete(index: "books");
-if ($response['acknowledged']) {
- print("Index successfully removed!");
-}
-```
diff --git a/serverless/pages/clients-python-getting-started.mdx b/serverless/pages/clients-python-getting-started.mdx
deleted file mode 100644
index 01e5d93f..00000000
--- a/serverless/pages/clients-python-getting-started.mdx
+++ /dev/null
@@ -1,131 +0,0 @@
----
-slug: /serverless/elasticsearch/python-client-getting-started
-title: Get started with the serverless Python client
-description: Set up and use the Python client for ((es3)).
-tags: [ 'serverless', 'elasticsearch', 'python', 'how to' ]
----
-
-
-This page guides you through the installation process of the Python
-client for ((es3)), shows you how to initialize the client, and how to perform basic
-((es)) operations with it.
-
-## Requirements
-
-* Python 3.7 or higher
-* [`pip`](https://pip.pypa.io/en/stable/)
-
-## Documentation
-
-Find the full documentation for the Python client on [readthedocs](https://elasticsearch-serverless-python.readthedocs.io/en/latest/).
-
-## Installation
-
-### Using the command line
-
-You can install the Python client with the following
-commands:
-
-```bash
-python -m pip install elasticsearch-serverless
-```
-
-
-## Initialize the client
-
-Initialize the client using your API key and Elasticsearch Endpoint:
-
-```python
-from elasticsearch_serverless import Elasticsearch
-
-client = Elasticsearch(
- "https://...", # Your project's Elasticsearch Endpoint
- api_key='api-key', # API key for your project
-)
-```
-
-To get API keys or the Elasticsearch Endpoint for a project, see .
-
-
-## Using the API
-
-After you've initialized the client, you can start ingesting documents. You can use
-the `bulk` API for this. This API enables you to index, update, and delete several
-documents in one request.
-
-
-### Creating an index and ingesting documents
-
-You can call the `bulk` API with a body parameter, an array of hashes that
-define the action, and a document.
-
-The following is an example of indexing some classic books into the `books`
-index:
-
-```python
-from datetime import datetime
-
-client.bulk(
- body=[
- {"index": {"_index": "books", "_id": "1"}},
- {"title": "Infinite Jest", "author": "David Foster Wallace", "published_on": datetime(1996, 2, 1)},
- {"index": {"_index": "books", "_id": "2"}},
- {"title": "Ulysses", "author": "James Joyce", "published_on": datetime(1922, 2, 2)},
- {"index": {"_index": "books", "_id": "3"}},
- {"title": "Just Kids", "author": "Patti Smith", "published_on": datetime(2010, 1, 19)},
- ],
-)
-```
-
-
-### Getting documents
-
-You can get documents by using the following code:
-
-```python
-response = client.get(index="books", id="1")
-print(response.body)
-```
-
-### Searching
-
-Now that some data is available, you can search your documents using the
-`search` API:
-
-```python
-response = client.search(index="books", query={
- "match": {
- "title": "infinite"
- }
-})
-
-for hit in response["hits"]["hits"]:
- print(hit["_source"])
-```
-
-### Updating a document
-
-You can call the `update` API to update a document:
-
-```python
-client.update(index="books", id="2", doc={
- "author": "James Augustine Aloysius Joyce",
- "pages": 732,
-})
-```
-
-### Deleting a document
-
-You can call the `delete` API to delete a document:
-
-```python
-client.delete(index="books", id="3")
-```
-
-
-### Deleting an index
-
-
-```python
-client.indices.delete(index="books")
-```
diff --git a/serverless/pages/clients-ruby-getting-started.mdx b/serverless/pages/clients-ruby-getting-started.mdx
deleted file mode 100644
index fc14b07d..00000000
--- a/serverless/pages/clients-ruby-getting-started.mdx
+++ /dev/null
@@ -1,185 +0,0 @@
----
-slug: /serverless/elasticsearch/ruby-client-getting-started
-title: Get started with the serverless Ruby client
-description: Set up and use the Ruby client for ((es3)).
-tags: [ 'serverless', 'elasticsearch', 'ruby', 'how to' ]
----
-
-
-This page guides you through the installation process Ruby
-client for ((es3)), shows you how to initialize the client, and how to perform basic
-((es)) operations with it.
-
-
-## Requirements
-
-* Ruby 3.0 or higher installed on your system.
-* To use the `elasticsearch-serverless` gem, you must have an API key and Elasticsearch Endpoint for an ((es3)) project.
-
-## Installation
-
-### From GitHub's releases
-
-You can install the Ruby Client from RubyGems:
-
-```bash
-gem install elasticsearch-serverless --pre
-```
-
-Check [releases](https://github.com/elastic/elasticsearch-serverless-ruby/releases)
-for the latest available versions.
-
-
-### From the source code
-
-You can install the Ruby client from the client's [source
-code](https://github.com/elastic/elasticsearch-serverless-ruby) with the
-following commands:
-
-```bash
-# From the project's root directory:
-gem build elasticsearch-serverless.gemspec
-gem install elasticsearch-serverless-x.x.x.gem
-```
-
-
-### Using the Gemfile
-
-Alternatively, you can include the client gem in your Ruby project's Gemfile:
-
-```ruby
-gem 'elasticsearch-serverless'
-```
-
-Once installed, require it in your code:
-
-```ruby
-require 'elasticsearch-serverless'
-```
-
-
-### Running a Ruby console
-
-You can also run the client from a Ruby console using the client's [source
-code](https://github.com/elastic/elasticsearch-serverless-ruby). To start the
-console, run the following commands:
-
-```bash
-# From the project's root directory:
-bundle install
-bundle exec rake console
-```
-
-
-## Initialize the client
-
-Initialize the client using your API key and Elasticsearch Endpoint:
-
-```ruby
-client = ElasticsearchServerless::Client.new(
- api_key: 'your_api_key',
- url: 'https://...'
-)
-```
-
-To get API keys or the Elasticsearch Endpoint for a project, see .
-
-
-## Using the API
-
-After you've initialized the client, you can start ingesting documents. You can use
-the `bulk` API for this. This API enables you to index, update, and delete several
-documents in one request.
-
-
-The code examples in this section use the Ruby console. To set up the console, .
-
-
-
-### Creating an index and ingesting documents
-
-You can call the `bulk` API with a body parameter, an array of hashes that
-define the action, and a document.
-
-The following is an example of indexing some classic books into the `books`
-index:
-
-```ruby
-# First, build your data:
-> body = [
- { index: { _index: 'books', data: {name: "Snow Crash", author: "Neal Stephenson", release_date: "1992-06-01", page_count: 470} } },
- { index: { _index: 'books', data: {name: "Revelation Space", author: "Alastair Reynolds", release_date: "2000-03-15", page_count: 585} } },
- { index: { _index: 'books', data: {name: "1984", author: "George Orwell", release_date: "1949-06-08", page_count: 328} } },
- { index: { _index: 'books', data: {name: "Fahrenheit 451", author: "Ray Bradbury", release_date: "1953-10-15", page_count: 227} } },
- { index: { _index: 'books', data: {name: "Brave New World", author: "Aldous Huxley", release_date: "1932-06-01", page_count: 268} } },
- { index: { _index: 'books', data: {name: "The Handmaid's Tale", author: "Margaret Atwood", release_date: "1985-06-01", page_count: 311} } }
-]
-# Then ingest the data via the bulk API:
-> response = client.bulk(body: body)
-# You can check the response if the items are indexed and have a document (doc) ID:
-> response['items']
-# Returns:
-# =>
-# [{"index"=>{"_index"=>"books", "_id"=>"Pdink4cBmDx329iqhzM2", "_version"=>1, "result"=>"created", "_shards"=>{"total"=>2, "successful"=>1, "failed"=>0}, "_seq_no"=>0, "_primary_term"=>1, "status"=>201}},
-# {"index"=>{"_index"=>"books", "_id"=>"Ptink4cBmDx329iqhzM2", "_version"=>1, "result"=>"created", "_shards"=>{"total"=>2, "successful"=>1, "failed"=>0}, "_seq_no"=>1, "_primary_term"=>1, "status"=>201}},
-# {"index"=>{"_index"=>"books", "_id"=>"P9ink4cBmDx329iqhzM2", "_version"=>1, "result"=>"created", "_shards"=>{"total"=>2, "successful"=>1, "failed"=>0}, "_seq_no"=>2, "_primary_term"=>1, "status"=>201}},
-# {"index"=>{"_index"=>"books", "_id"=>"QNink4cBmDx329iqhzM2", "_version"=>1, "result"=>"created", "_shards"=>{"total"=>2, "successful"=>1, "failed"=>0}, "_seq_no"=>3, "_primary_term"=>1, "status"=>201}},
-# {"index"=>{"_index"=>"books", "_id"=>"Qdink4cBmDx329iqhzM2", "_version"=>1, "result"=>"created", "_shards"=>{"total"=>2, "successful"=>1, "failed"=>0}, "_seq_no"=>4, "_primary_term"=>1, "status"=>201}},
-# {"index"=>{"_index"=>"books", "_id"=>"Qtink4cBmDx329iqhzM2", "_version"=>1, "result"=>"created", "_shards"=>{"total"=>2, "successful"=>1, "failed"=>0}, "_seq_no"=>5, "_primary_term"=>1, "status"=>201}}]
-```
-
-When you use the client to make a request to Elasticsearch, it returns an API
-response object. You can check the HTTP return code by calling `status` and the
-HTTP headers by calling `headers` on the response object. The response object
-also behaves as a Hash, so you can access the body values directly as seen on
-the previous example with `response['items']`.
-
-
-### Getting documents
-
-You can get documents by using the following code:
-
-```ruby
-> client.get(index: 'books', id: 'id') # Replace 'id' with a valid doc ID
-```
-
-
-### Searching
-
-Now that some data is available, you can search your documents using the
-`search` API:
-
-```ruby
-> response = client.search(index: 'books', q: 'snow')
-> response['hits']['hits']
-# Returns:
-# => [{"_index"=>"books", "_id"=>"Pdink4cBmDx329iqhzM2", "_score"=>1.5904956, "_source"=>{"name"=>"Snow Crash", "author"=>"Neal Stephenson", "release_date"=>"1992-06-01", "page_count"=>470}}]
-```
-
-### Updating a document
-
-You can call the `update` API to update a document:
-
-```ruby
-> response = client.update(
- index: 'books',
- id: 'id', # Replace 'id' with a valid doc ID
- body: { doc: { page_count: 312 } }
-)
-```
-
-### Deleting a document
-
-You can call the `delete` API to delete a document:
-
-```ruby
-> client.delete(index: 'books', id: 'id') # Replace 'id' with a valid doc ID
-```
-
-
-### Deleting an index
-
-
-```ruby
-> client.indices.delete(index: 'books')
-```
\ No newline at end of file
diff --git a/serverless/pages/clients.mdx b/serverless/pages/clients.mdx
deleted file mode 100644
index bc8483cf..00000000
--- a/serverless/pages/clients.mdx
+++ /dev/null
@@ -1,18 +0,0 @@
----
-slug: /serverless/elasticsearch/clients
-title: Client libraries
-description: Index, search, and manage ((es)) data in your preferred language.
-tags: ["serverless", "elasticsearch", "clients", "overview"]
----
-
-
-((es3)) provides official language clients to use ((es)) REST APIs.
-Currently, the following language clients are supported:
-
-- | [Repository](https://github.com/elastic/elasticsearch-serverless-go)
-- | [Repository](https://github.com/elastic/elasticsearch-java/tree/main/java-client-serverless)
-- | [Repository](https://github.com/elastic/elasticsearch-net)
-- | [Repository](https://github.com/elastic/elasticsearch-serverless-js)
-- | [Repository](https://github.com/elastic/elasticsearch-serverless-php)
-- | [Repository](https://github.com/elastic/elasticsearch-serverless-python)
-- | [Repository](https://github.com/elastic/elasticsearch-serverless-ruby)
diff --git a/serverless/pages/cloud-regions.mdx b/serverless/pages/cloud-regions.mdx
deleted file mode 100644
index a35d96bb..00000000
--- a/serverless/pages/cloud-regions.mdx
+++ /dev/null
@@ -1,26 +0,0 @@
----
-slug: /serverless/regions
-title: Serverless regions
-description: Index, search, and manage ((es)) data in your preferred language.
-tags: ["serverless", "regions", "aws", "cloud"]
----
-
-A region is the geographic area where the data center of the cloud provider that hosts your project is located. Review the available Elastic Cloud Serverless regions to decide which region to use. If you aren't sure which region to pick, choose one that is geographically close to you to reduce latency.
-
-Elastic Cloud Serverless handles all hosting details for you. You are unable to change the region after you create a project.
-
-
-Currently, a limited number of Amazon Web Services (AWS) regions are available. More regions for AWS, as well as Microsoft Azure and Google Cloud Platform (GCP), will be added in the future.
-
-
-## Amazon Web Services (AWS) regions
-
-The following AWS regions are currently available:
-
-| Region | Name |
-|--------|------|
-| ap-southeast-1 | Asia Pacific (Singapore) |
-| eu-west-1 | Europe (Ireland) |
-| us-east-1 | US East (N. Virginia) |
-| us-west-2 | US West (Oregon) |
-
diff --git a/serverless/pages/custom-roles.mdx b/serverless/pages/custom-roles.mdx
deleted file mode 100644
index e238385e..00000000
--- a/serverless/pages/custom-roles.mdx
+++ /dev/null
@@ -1,96 +0,0 @@
----
-slug: /serverless/custom-roles
-title: Custom roles
-description: Create and manage roles that grant privileges within your project.
-tags: [ 'serverless', 'Elasticsearch', 'Security' ]
----
-
-Coming soon
-
-
-
-
-This content applies to:
-
-The built-in organization-level roles and instance access roles are great for getting started with ((serverless-full)), and for system administrators who do not need more restrictive access.
-
-As an administrator, however, you have the ability to create your own roles to describe exactly the kind of access your users should have within a specific project.
-For example, you might create a marketing_user role, which you then assign to all users in your marketing department.
-This role would grant access to all of the necessary data and features for this team to be successful, without granting them access they don't require.
-{/* Derived from https://www.elastic.co/guide/en/kibana/current/tutorial-secure-access-to-kibana.html */}
-
-All custom roles grant the same access as the `Viewer` instance access role with regards to ((ecloud)) privileges.
-To grant more ((ecloud)) privileges, assign more roles.
-Users receive a union of all their roles' privileges.
-
-You can manage custom roles in **((project-settings)) → ((manage-app)) →((custom-roles-app))**.
-To create a new custom role, click the **Create role** button.
-To clone, delete, or edit a role, open the actions menu:
-
-
-{/* TO-DO: This screenshot needs to be refreshed and automated. */}
-
-Roles are a collection of privileges that enable users to access project features and data.
-For example, when you create a custom role, you can assign ((es)) cluster and index privileges and ((kib)) privileges.
-
-
- You cannot assign [run as privileges](((ref))/security-privileges.html#_run_as_privilege) in ((serverless-full)) custom roles.
-
-
-## ((es)) cluster privileges
-
-Cluster privileges grant access to monitoring and management features in ((es)).
-They also enable some ((stack-manage-app)) capabilities in your project.
-
-
-{/* TO-DO: This screenshot needs to be refreshed and automated. */}
-
-Refer to [cluster privileges](((ref))/security-privileges.html#privileges-list-cluster) for a complete description of available options.
-
-## ((es)) index privileges
-
-Each role can grant access to multiple data indices, and each index can have a different set of privileges.
-Typically, you will grant the `read` and `view_index_metadata` privileges to each index that you expect your users to work with.
-For example, grant access to indices that match an `acme-marketing-*` pattern:
-
-
-{/* TO-DO: This screenshot needs to be refreshed and automated. */}
-
-Refer to [index privileges](((ref))/security-privileges.html#privileges-list-indices) for a complete description of available options.
-
-Document-level and field-level security affords you even more granularity when it comes to granting access to your data.
-With document-level security (DLS), you can write an ((es)) query to describe which documents this role grants access to.
-With field-level security (FLS), you can instruct ((es)) to grant or deny access to specific fields within each document.
-{/* Derived from https://www.elastic.co/guide/en/kibana/current/kibana-role-management.html#adding_cluster_privileges */}
-
-## ((kib)) privileges
-
-When you create a custom role, click **Add Kibana privilege** to grant access to specific features.
-The features that are available vary depending on the project type.
-For example, in ((es-serverless)):
-
-
-{/* TO-DO: This screenshot needs to be refreshed and automated. */}
-
-Open the **Spaces** selection control to specify whether to grant the role access to all spaces or one or more individual spaces.
-When using the **Customize by feature** option, you can choose either **All**, **Read** or **None** for access to each feature.
-
-All
-: Grants full read-write access.
-
-Read
-: Grants read-only access.
-
-None
-: Does not grant any access.
-
-Some features have finer access control and you can optionally enable sub-feature privileges.
-
-
-As new features are added to ((serverless-full)), roles that use the custom option do not automatically get access to the new features. You must manually update the roles.
-
-
-After your roles are set up, the next step to securing access is to assign roles to your users.
-Click the **Assign roles** link to go to the **Members** tab of the **Organization** page.
-Learn more in .
-
\ No newline at end of file
diff --git a/serverless/pages/data-views.mdx b/serverless/pages/data-views.mdx
deleted file mode 100644
index 71005dff..00000000
--- a/serverless/pages/data-views.mdx
+++ /dev/null
@@ -1,164 +0,0 @@
----
-slug: /serverless/data-views
-title: ((data-sources-cap))
-description: Elastic requires a ((data-source)) to access the ((es)) data that you want to explore.
-tags: [ 'serverless', 'Elasticsearch', 'Observability', 'Security' ]
----
-
-
-This content applies to:
-
-A ((data-source)) can point to one or more indices, [data streams](((ref))/data-streams.html), or [index aliases](((ref))/alias.html).
-For example, a ((data-source)) can point to your log data from yesterday or all indices that contain your data.
-
-{/*
-
-## Required permissions
-
-* Access to **Data Views** requires the ((kib)) privilege
- `Data View Management`.
-
-* To create a ((data-source)), you must have the ((es)) privilege
- `view_index_metadata`.
-
-* If a read-only indicator appears, you have insufficient privileges
- to create or save ((data-sources)). In addition, the buttons to create ((data-sources)) or
- save existing ((data-sources)) are not visible. For more information,
- refer to Granting access to ((kib)).
-*/}
-
-## Create a data view
-
-After you've loaded your data, follow these steps to create a ((data-source)):
-
-{/* */}
-
- 1. Open {/***Lens** or*/}**Discover** then open the data view menu.
-
- Alternatively, go to **((project-settings)) → ((manage-app)) → ((data-views-app))**.
-
-1. Click **Create a ((data-source))**.
-
-1. Give your ((data-source)) a name.
-
-1. Start typing in the **Index pattern** field, and Elastic looks for the names of
- indices, data streams, and aliases that match your input. You can
- view all available sources or only the sources that the data view targets.
- 
-
- * To match multiple sources, use a wildcard (*). `filebeat-*` matches
- `filebeat-apache-a`, `filebeat-apache-b`, and so on.
-
- * To match multiple single sources, enter their names,
- separated by a comma. Do not include a space after the comma.
- `filebeat-a,filebeat-b` matches two indices.
-
- * To exclude a source, use a minus sign (-), for example, `-test3`.
-
-1. Open the **Timestamp field** dropdown,
- and then select the default field for filtering your data by time.
-
- * If you don't set a default time field, you can't use
- global time filters on your dashboards. This is useful if
- you have multiple time fields and want to create dashboards that combine visualizations
- based on different timestamps.
-
- * If your index doesn't have time-based data, choose **I don't want to use the time filter**.
-
-1. Click **Show advanced settings** to:
- * Display hidden and system indices.
- * Specify your own ((data-source)) name. For example, enter your ((es)) index alias name.
-
-1. Click **Save ((data-source)) to Elastic**.
-
-You can manage your data views in **((project-settings)) → ((manage-app)) → ((data-views-app))**.
-
-### Create a temporary ((data-source))
-
-Want to explore your data or create a visualization without saving it as a data view?
-Select **Use without saving** in the **Create ((data-source))** form in **Discover**.
-With a temporary ((data-source)), you can add fields and create an ((es)) query alert, just like you would a regular ((data-source)).
-Your work won't be visible to others in your space.
-
-A temporary ((data-source)) remains in your space until you change apps, or until you save it.
-
-{/* 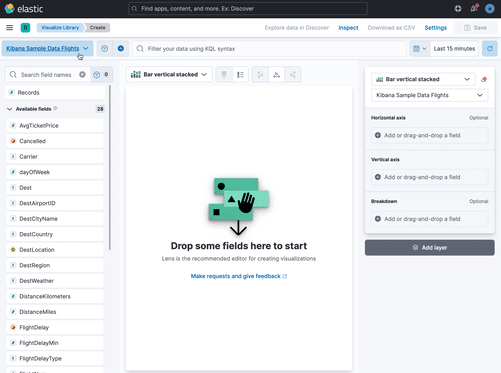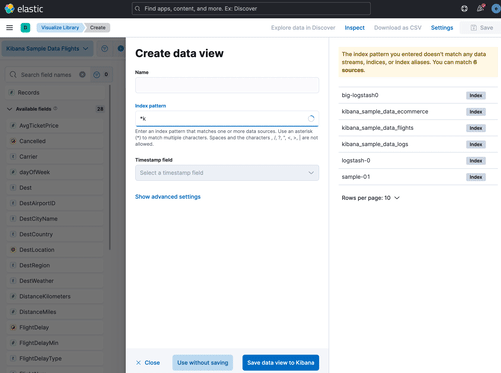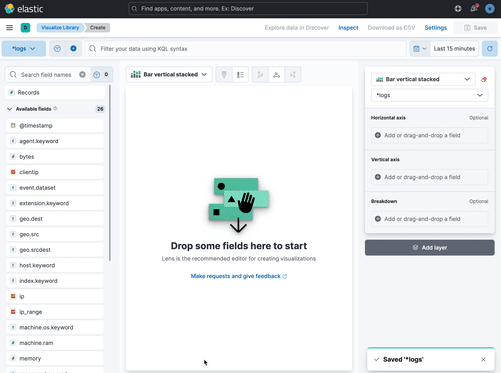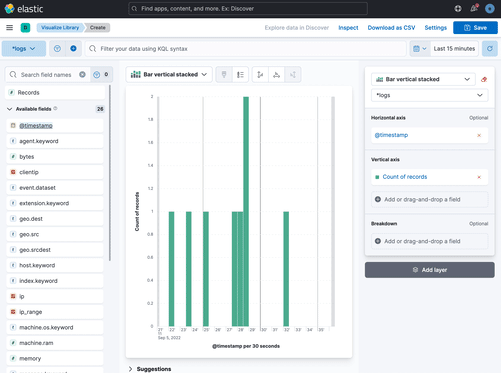 */}
-
-
-
-{/*
-
-### Use ((data-sources)) with rolled up data
-
-A ((data-source)) can match one rollup index. For a combination rollup
-((data-source)) with both raw and rolled up data, use the standard notation:
-
-```ts
-rollup_logstash,kibana_sample_data_logs
-```
-For an example, refer to Create and visualize rolled up data. */}
-
-{/*
-
-### Use ((data-sources)) with ((ccs))
-
-If your ((es)) clusters are configured for [((ccs))](((ref))/modules-cross-cluster-search.html),
-you can create a ((data-source)) to search across the clusters of your choosing.
-Specify data streams, indices, and aliases in a remote cluster using the
-following syntax:
-
-```ts
-:
-```
-
-To query ((ls)) indices across two ((es)) clusters
-that you set up for ((ccs)), named `cluster_one` and `cluster_two`:
-
-```ts
- cluster_one:logstash-*,cluster_two:logstash-*
-```
-
-Use wildcards in your cluster names
-to match any number of clusters. To search ((ls)) indices across
-clusters named `cluster_foo`, `cluster_bar`, and so on:
-
-```ts
-cluster_*:logstash-*
-```
-
-To query across all ((es)) clusters that have been configured for ((ccs)),
-use a standalone wildcard for your cluster name:
-
-```ts
-*:logstash-*
-```
-
-To match indices starting with `logstash-`, but exclude those starting with `logstash-old`, from
-all clusters having a name starting with `cluster_`:
-
-```ts
-`cluster_*:logstash-*,cluster_*:-logstash-old*`
-```
-
-To exclude a cluster having a name starting with `cluster_`:
-
-```ts
-`cluster_*:logstash-*,cluster_one:-*`
-```
-
-Once you configure a ((data-source)) to use the ((ccs)) syntax, all searches and
-aggregations using that ((data-source)) in Elastic take advantage of ((ccs)). */}
-
-## Delete a ((data-source))
-
-When you delete a ((data-source)), you cannot recover the associated field formatters, runtime fields, source filters,
-and field popularity data.
-Deleting a ((data-source)) does not remove any indices or data documents from ((es)).
-
-
-
-1. Go to **((project-settings)) → ((manage-app)) → ((data-views-app))**.
-
-1. Find the ((data-source)) that you want to delete, and then
- click in the **Actions** column.
-
diff --git a/serverless/pages/debug-grok-expressions.mdx b/serverless/pages/debug-grok-expressions.mdx
deleted file mode 100644
index 477522c1..00000000
--- a/serverless/pages/debug-grok-expressions.mdx
+++ /dev/null
@@ -1,113 +0,0 @@
----
-slug: /serverless/devtools/debug-grok-expressions
-title: Grok Debugger
-description: Build and debug grok patterns before you use them in your data processing pipelines.
-tags: [ 'serverless', 'dev tools', 'how-to' ]
----
-
-
-This content applies to:
-
-
-
-You can build and debug grok patterns in the **Grok Debugger** before you use them in your data processing pipelines.
-Grok is a pattern-matching syntax that you can use to parse and structure arbitrary text.
-Grok is good for parsing syslog, apache, and other webserver logs, mysql logs, and in general,
-any log format written for human consumption.
-
-Grok patterns are supported in ((es)) [runtime fields](((ref))/runtime.html),
-the ((es)) [grok ingest processor](((ref))/grok-processor.html),
-and the ((ls)) [grok filter](((logstash-ref))/plugins-filters-grok.html).
-For syntax, see [Grokking grok](((ref))/grok.html).
-
-Elastic ships with more than 120 reusable grok patterns.
-For a complete list of patterns, see
-[((es))
-grok patterns](https://github.com/elastic/elasticsearch/tree/master/libs/grok/src/main/resources/patterns)
-and [((ls))
-grok patterns](https://github.com/logstash-plugins/logstash-patterns-core/tree/master/patterns).
-
-{/* TODO: Figure out where to link to for grok patterns. Looks like the dir structure has changed. */}
-
-Because ((es)) and ((ls)) share the same grok implementation and pattern libraries,
-any grok pattern that you create in the **Grok Debugger** will work in both ((es)) and ((ls)).
-
-
-
-## Get started
-
-This example walks you through using the **Grok Debugger**.
-
-
-The **Admin** role is required to use the Grok Debugger.
-For more information, refer to
-
-
-1. From the main menu, click **Developer Tools**, then click **Grok Debugger**.
-1. In **Sample Data**, enter a message that is representative of the data you want to parse.
-For example:
-
- ```ruby
- 55.3.244.1 GET /index.html 15824 0.043
- ```
-
-1. In **Grok Pattern**, enter the grok pattern that you want to apply to the data.
-
- To parse the log line in this example, use:
-
- ```ruby
- %{IP:client} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration}
- ```
-
-1. Click **Simulate**.
-
- You'll see the simulated event that results from applying the grok
- pattern.
-
- 
-
-
-
-## Test custom patterns
-
-
-If the default grok pattern dictionary doesn't contain the patterns you need,
-you can define, test, and debug custom patterns using the **Grok Debugger**.
-
-Custom patterns that you enter in the **Grok Debugger** are not saved. Custom patterns
-are only available for the current debugging session and have no side effects.
-
-Follow this example to define a custom pattern.
-
-1. In **Sample Data**, enter the following sample message:
-
- ```ruby
- Jan 1 06:25:43 mailserver14 postfix/cleanup[21403]: BEF25A72965: message-id=<20130101142543.5828399CCAF@mailserver14.example.com>
- ```
-
-1. Enter this grok pattern:
-
- ```ruby
- %{SYSLOGBASE} %{POSTFIX_QUEUEID:queue_id}: %{MSG:syslog_message}
- ```
-
- Notice that the grok pattern references custom patterns called `POSTFIX_QUEUEID` and `MSG`.
-
-1. Expand **Custom Patterns** and enter pattern definitions for the custom patterns that you want to use in the grok expression.
-You must specify each pattern definition on its own line.
-
- For this example, you must specify pattern definitions
- for `POSTFIX_QUEUEID` and `MSG`:
-
- ```ruby
- POSTFIX_QUEUEID [0-9A-F]{10,11}
- MSG message-id=<%{GREEDYDATA}>
- ```
-
-1. Click **Simulate**.
-
- You'll see the simulated output event that results from applying the grok pattern that contains the custom pattern:
-
- 
-
- If an error occurs, you can continue iterating over the custom pattern until the output matches your expected event.
diff --git a/serverless/pages/debug-painless-scripts.mdx b/serverless/pages/debug-painless-scripts.mdx
deleted file mode 100644
index 8ec36fc3..00000000
--- a/serverless/pages/debug-painless-scripts.mdx
+++ /dev/null
@@ -1,20 +0,0 @@
----
-slug: /serverless/devtools/debug-painless-scripts
-title: Painless Lab
-description: Use our interactive code editor to test and debug Painless scripts in real-time.
-tags: [ 'serverless', 'dev tools', 'how-to' ]
----
-
-
-This content applies to:
-
-
-
-
-
-The **Painless Lab** is an interactive code editor that lets you test and debug [Painless scripts](((ref))/modules-scripting-painless.html) in real-time.
-You can use Painless to safely write inline and stored scripts anywhere scripts are supported.
-
-To get started, open the main menu, click **Developer Tools**, and then click **Painless Lab**.
-
-
diff --git a/serverless/pages/developer-tools-troubleshooting.mdx b/serverless/pages/developer-tools-troubleshooting.mdx
deleted file mode 100644
index a1f8273c..00000000
--- a/serverless/pages/developer-tools-troubleshooting.mdx
+++ /dev/null
@@ -1,263 +0,0 @@
----
-slug: /serverless/devtools/dev-tools-troubleshooting
-title: Troubleshooting
-description: Troubleshoot searches.
-tags: [ 'serverless', 'troubleshooting' ]
----
-
-
-When you query your data, Elasticsearch may return an error, no search results,
-or results in an unexpected order. This guide describes how to troubleshoot
-searches.
-
-## Ensure the data stream, index, or alias exists
-
-Elasticsearch returns an `index_not_found_exception` when the data stream, index
-or alias you try to query does not exist. This can happen when you misspell the
-name or when the data has been indexed to a different data stream or index.
-
-Use the [**Exists API**](https://www.elastic.co/docs/api/doc/elasticsearch-serverless/operation/operation-indices-exists-index-template) to check whether
-a data stream, index, or alias exists:
-
-```js
-HEAD my-index
-```
-
-Use the [**Get index API**](https://www.elastic.co/docs/api/doc/elasticsearch-serverless/operation/operation-indices-get)
-to list all indices and their aliases:
-
-```js
-GET /_all?filter_path=*.aliases
-```
-
-Instead of an error, it is possible to retrieve partial search results if some
-of the indices you're querying are unavailable.
-Set `ignore_unavailable` to `true`:
-
-```js
-GET /my-alias/_search?ignore_unavailable=true
-```
-
-## Ensure the data stream or index contains data
-
-When a search request returns no hits, the data stream or index may contain no
-data.
-This can happen when there is a data ingestion issue.
-For example, the data may have been indexed to a data stream or index with
-another name.
-
-Use the [**Count API**](https://www.elastic.co/docs/api/doc/elasticsearch-serverless/operation/operation-count-1)
-to retrieve the number of documents in a data
-stream or index.
-Check that `count` in the response is not 0.
-
-
-```js
-GET /my-index-000001/_count
-```
-
-
-
-If you aren't getting search results in the UI, check that you have selected the
-correct data view and a valid time range. Also, ensure the data view has been
-configured with the correct time field.
-
-
-## Check that the field exists and its capabilities
-
-Querying a field that does not exist will not return any results.
-Use the [**Field capabilities API**](https://www.elastic.co/docs/api/doc/elasticsearch-serverless/operation/operation-field-caps)
-to check whether a field exists:
-
-```js
-GET /my-index-000001/_field_caps?fields=my-field
-```
-
-If the field does not exist, check the data ingestion process.
-The field may have a different name.
-
-If the field exists, the request will return the field's type and whether it is
-searchable and aggregatable.
-
-```console-response
-{
- "indices": [
- "my-index-000001"
- ],
- "fields": {
- "my-field": {
- "keyword": {
- "type": "keyword", [^1]
- "metadata_field": false,
- "searchable": true, [^2]
- "aggregatable": true [^3]
- }
- }
- }
-}
-```
-[^1]: The field is of type `keyword` in this index.
-[^2]: The field is searchable in this index.
-[^3]: The field is aggregatable in this index.
-
-## Check the field's mappings
-
-A field's capabilities are determined by its [mapping](((ref))/mapping.html).
-To retrieve the mapping, use the [**Get mapping API**](https://www.elastic.co/docs/api/doc/elasticsearch-serverless/operation/operation-indices-get-mapping):
-
-```js
-GET /my-index-000001/_mappings
-```
-
-If you query a `text` field, pay attention to the analyzer that may have been
-configured.
-You can use the [**Analyze API**](https://www.elastic.co/docs/api/doc/elasticsearch-serverless/operation/operation-indices-analyze)
-to check how a field's analyzer processes values and query terms:
-
-```js
-GET /my-index-000001/_analyze
-{
- "field": "my-field",
- "text": "this is a test"
-}
-```
-
-To change the mapping of an existing field use the [**Update mapping API**](https://www.elastic.co/docs/api/doc/elasticsearch-serverless/operation/operation-indices-put-mapping-1).
-
-## Check the field's values
-
-Use the `exists` query to check whether there are
-documents that return a value for a field.
-Check that `count` in the response is
-not 0.
-
-```js
-GET /my-index-000001/_count
-{
- "query": {
- "exists": {
- "field": "my-field"
- }
- }
-}
-```
-
-If the field is aggregatable, you can use
-to check the field's values. For `keyword` fields, you can use a `terms`
-aggregation to retrieve the field's most common values:
-
-```js
-GET /my-index-000001/_search?filter_path=aggregations
-{
- "size": 0,
- "aggs": {
- "top_values": {
- "terms": {
- "field": "my-field",
- "size": 10
- }
- }
- }
-}
-```
-
-For numeric fields, you can use [stats aggregation](((ref))/search-aggregations-metrics-stats-aggregation.html) {/* stats aggregation */} to get an idea of the field's value distribution:
-
-```js
-GET /my-index-000001/_search?filter_path=aggregations
-{
- "aggs": {
- "my-num-field-stats": {
- "stats": {
- "field": "my-num-field"
- }
- }
- }
-}
-```
-
-If the field does not return any values, check the data ingestion process.
-The field may have a different name.
-
-## Check the latest value
-
-For time-series data, confirm there is non-filtered data within the attempted
-time range.
-For example, if you are trying to query the latest data for the
-`@timestamp` field, run the following to see if the max `@timestamp` falls
-within the attempted range:
-
-```js
-GET /my-index-000001/_search?sort=@timestamp:desc&size=1
-```
-
-## Validate, explain, and profile queries
-
-When a query returns unexpected results, Elasticsearch offers several tools to
-investigate why.
-
-The [**Validate API**](https://www.elastic.co/docs/api/doc/elasticsearch-serverless/operation/operation-indices-validate-query)
-enables you to validate a query.
-Use the `rewrite` parameter to return the Lucene query an Elasticsearch query is
-rewritten into:
-
-```js
-GET /my-index-000001/_validate/query?rewrite=true
-{
- "query": {
- "match": {
- "user.id": {
- "query": "kimchy",
- "fuzziness": "auto"
- }
- }
- }
-}
-```
-
-Use the [**Explain API**](((ref))/search-explain.html) to find out why a
-specific document matches or doesn’t match a query:
-
-```js
-GET /my-index-000001/_explain/0
-{
- "query" : {
- "match" : { "message" : "elasticsearch" }
- }
-}
-```
-
-The [**Profile API**](((ref))/search-profile.html)
-provides detailed timing information about a search request.
-For a visual representation of the results, use the
-.
-
-
-To troubleshoot queries, select **Inspect** in the toolbar.
-Next, select **Request**.
-You can now copy the query sent to ((es)) for further analysis in Console.
-
-
-## Check index settings
-
-Index settings {/* Index settings */}
-can influence search results.
-For example, the `index.query.default_field` setting, which determines the field
-that is queried when a query specifies no explicit field.
-Use the [**Get index settings API**](https://www.elastic.co/docs/api/doc/elasticsearch-serverless/operation/operation-indices-get-settings)
-to retrieve the settings for an index:
-
-```bash
-GET /my-index-000001/_settings
-```
-
-You can update dynamic index settings with the
-[**Update index settings API**](https://www.elastic.co/docs/api/doc/elasticsearch-serverless/operation/operation-indices-put-settings).
-Changing dynamic index settings for a data stream
-{/* Changing dynamic index settings for a data stream */}
-requires changing the index template used by the data stream.
-
-For static settings, you need to create a new index with the correct settings.
-Next, you can reindex the data into that index.
-{/*For data streams, refer to Change a static index setting
-for a data stream */}
diff --git a/serverless/pages/elasticsearch-developer-tools.mdx b/serverless/pages/elasticsearch-developer-tools.mdx
deleted file mode 100644
index 929e0dce..00000000
--- a/serverless/pages/elasticsearch-developer-tools.mdx
+++ /dev/null
@@ -1,19 +0,0 @@
----
-slug: /serverless/elasticsearch/dev-tools
-title: Developer tools
-description: Elastic tools for developers.
-tags: [ 'serverless', 'elasticsearch', 'overview' ]
----
-
-
-
-A number of developer tools are available in your project's UI under the **Dev Tools** section.
-
-- : Make API calls to your Elasticsearch instance using the Query DSL and view the responses.
-- : Inspect and analyze your search queries to identify performance bottlenecks.
-- : Build and debug grok patterns before you use them in your data processing pipelines.
-
-
-{/* ## Troubleshooting */}
-
-{/* - : Debug your searches using various Elasticsearch APIs. */}
diff --git a/serverless/pages/explore-your-data-alerting.mdx b/serverless/pages/explore-your-data-alerting.mdx
deleted file mode 100644
index 027e5041..00000000
--- a/serverless/pages/explore-your-data-alerting.mdx
+++ /dev/null
@@ -1,126 +0,0 @@
----
-slug: /serverless/elasticsearch/explore-your-data-alerting
-title: Manage alerting rules
-description: Define when to generate alerts and notifications with alerting rules.
-tags: [ 'serverless', 'elasticsearch', 'alerting', 'how-to' ]
----
-
-
-In **((alerts-app))** or **((project-settings)) → ((manage-app)) → ((rules-app))** you can:
-
-* Create and edit rules
-* Manage rules including enabling/disabling, muting/unmuting, and deleting
-* Drill down to rule details
-* Configure rule settings
-
-
-
-For an overview of alerting concepts, go to .
-
-{/* ## Required permissions
-
-Access to rules is granted based on your ((alert-features)) privileges. */}
-{/* MISSING LINK:
-For more information, go to missing linkSecuritys. */}
-
-## Create and edit rules
-
-When you click the **Create rule** button, it launches a flyout that guides you through selecting a rule type and configuring its conditions and actions.
-
-
-
-The rule types available in an ((es)) project are:
-
-* [((es)) query](((kibana-ref))/rule-type-es-query.html)
-* [Index threshold](((kibana-ref))/rule-type-index-threshold.html)
-* [Tracking containement](((kibana-ref))/geo-alerting.html)
-* [Transform health](((ref))/transform-alerts.html)
-
-After a rule is created, you can open the action menu (…) and select **Edit rule** to re-open the flyout and change the rule properties.
-
-You can also manage rules as resources with the [Elasticstack provider](https://registry.terraform.io/providers/elastic/elasticstack/latest) for Terraform.
-For more details, refer to the [elasticstack_kibana_alerting_rule](https://registry.terraform.io/providers/elastic/elasticstack/latest/docs/resources/kibana_alerting_rule) resource.
-
-{/* For details on what types of rules are available and how to configure them, refer to [Rule types](((kibana-ref))/rule-types.html). */}
-{/* missing link*/}
-
-## Snooze and disable rules
-
-The rule listing enables you to quickly snooze, disable, enable, or delete individual rules.
-For example, you can change the state of a rule:
-
-
-
-When you snooze a rule, the rule checks continue to run on a schedule but the alert will not trigger any actions.
-You can snooze for a specified period of time, indefinitely, or schedule single or recurring downtimes:
-
-
-
-When a rule is in a snoozed state, you can cancel or change the duration of this state.
-
-## Import and export rules
-
-To import and export rules, use .
-
-{/*
-TBD: Do stack monitoring rules exist in serverless?
-Stack monitoring rules are automatically created for you and therefore cannot be managed in **Saved Objects**.
-*/}
-
-Rules are disabled on export. You are prompted to re-enable the rule on successful import.
-
-
-
-## View rule details
-
-You can determine the health of a rule by looking at its **Last response**.
-A rule can have one of the following responses:
-
-`failed`
- : The rule ran with errors.
-
-`succeeded`
- : The rule ran without errors.
-
-`warning`
- : The rule ran with some non-critical errors.
-
-Click the rule name to access a rule details page:
-
-
-
-In this example, the rule detects when a site serves more than a threshold number of bytes in a 24 hour period. Four sites are above the threshold. These are called alerts - occurrences of the condition being detected - and the alert name, status, time of detection, and duration of the condition are shown in this view. Alerts come and go from the list depending on whether the rule conditions are met.
-
-When an alert is created, it generates actions. If the conditions that caused the alert persist, the actions run again according to the rule notification settings. There are three common alert statuses:
-
-`active`
- : The conditions for the rule are met and actions should be generated according to the notification settings.
-
-`flapping`
- : The alert is switching repeatedly between active and recovered states.
-
-`recovered`
- : The conditions for the rule are no longer met and recovery actions should be generated.
-
-
-The `flapping` state is possible only if you have enabled alert flapping detection in **((rules-ui))** → **Settings**. A look back window and threshold are used to determine whether alerts are flapping. For example, you can specify that the alert must change status at least 6 times in the last 10 runs. If the rule has actions that run when the alert status changes, those actions are suppressed while the alert is flapping.
-
-
-If there are rule actions that failed to run successfully, you can see the details on the **History** tab.
-In the **Message** column, click the warning or expand icon or click the number in the **Errored actions** column to open the **Errored Actions** panel.
-{/* */}
-
-{/*
-TBD: Is this setting still feasible in serverless?
-In this example, the action failed because the `xpack.actions.email.domain_allowlist` setting was updated and the action's email recipient is no longer included in the allowlist:
-
-
-*/}
-{/* If an alert was affected by a maintenance window, its identifier appears in the **Maintenance windows** column. */}
-
-You can suppress future actions for a specific alert by turning on the **Mute** toggle.
-If a muted alert no longer meets the rule conditions, it stays in the list to avoid generating actions if the conditions recur.
-You can also disable a rule, which stops it from running checks and clears any alerts it was tracking.
-You may want to disable rules that are not currently needed to reduce the load on your cluster.
-
-
diff --git a/serverless/pages/explore-your-data-discover-your-data.mdx b/serverless/pages/explore-your-data-discover-your-data.mdx
deleted file mode 100644
index 428051ca..00000000
--- a/serverless/pages/explore-your-data-discover-your-data.mdx
+++ /dev/null
@@ -1,209 +0,0 @@
----
-slug: /serverless/elasticsearch/explore-your-data-discover-your-data
-title: Discover your data
-description: Learn how to use Discover to gain insights into your data.
-tags: [ 'serverless', 'elasticsearch', 'discover data', 'how to' ]
----
-
-
-With **Discover**, you can quickly search and filter your data, get information
-about the structure of the fields, and display your findings in a visualization.
-You can also customize and save your searches and place them on a dashboard.
-
-## Explore and query your data
-
-This tutorial shows you how to use **Discover** to search large amounts of
-data and understand what’s going on at any given time. This tutorial uses the book sample data set from the Get started page.
-
-You’ll learn to:
-
-- **Select** data for your exploration, set a time range for that data,
-search it with the ((kib)) Query Language, and filter the results.
-- **Explore** the details of your data, view individual documents, and create tables
-that summarize the contents of the data.
-- **Present** your findings in a visualization.
-
-At the end of this tutorial, you’ll be ready to start exploring with your own
-data in **Discover**.
-
-## Find your data
-
-Tell ((kib)) where to find the data you want to explore, and then specify the time range in which to view that data.
-
-1. Once the book sample data has been ingested, navigate to **Explore → Discover** and click **Create data view**.
-
-1. Give your data view a name.
-
-
-
-1. Start typing in the **Index pattern** field, and the names of indices, data streams, and aliases that match your input will be displayed.
-
- - To match multiple sources, use a wildcard (*), for example, `b*` and any indices starting with the letter `b` display.
- - To match multiple sources, enter their names separated by a comma. Do not include a space after the comma. For example `books,magazines` would match two indices: `books` and `magazines`.
- - To exclude a source, use a minus sign (-), for example `-books`.
-
-1. In the **Timestamp** field dropdown, and then select `release_date`.
-
- - If you don't set a time field, you can't use global time filters on your dashboards. Leaving the time field unset might be useful if you have multiple time fields and want to create dashboards that combine visualizations based on different timestamps.
- - If your index doesn't have time-based data, choose **I don't want to use the time filter**.
-
-1. Click **Show advanced settings** to:
-
- - Display hidden and system indices.
- - Specify your own data view name. For example, enter your Elasticsearch index alias name.
-
-1. Click **Save data view to ((kib))**.
-
-1. Adjust the time range to view data for the **Last 40 years** to view all your book data.
-
-
-
-
-
-## Explore the fields in your data
-
-**Discover** includes a table that shows all the documents that match your search. By default, the document table includes a column for the time field and a column that lists all other fields in the document. You’ll modify the document table to display your fields of interest.
-
-1. In the sidebar, enter `au` in the search field to find the `author` field.
-
-1. In the **Available fields** list, click `author` to view its most popular values.
-
- **Discover** shows the top 10 values and the number of records used to calculate those values.
-
-1. Click to toggle the field into the document table. You can also drag the field from the **Available fields** list into the document table.
-
-## Add a field to your ((data-source))
-
-What happens if you forgot to define an important value as a separate field? Or, what if you
-want to combine two fields and treat them as one? This is where [runtime fields](((ref))/runtime.html) come into play.
-You can add a runtime field to your ((data-source)) from inside of **Discover**,
-and then use that field for analysis and visualizations,
-the same way you do with other fields.
-
-1. In the sidebar, click **Add a field**.
-
-1. In the **Create field** form, enter `hello` for the name.
-
-1. Turn on **Set value**.
-
-1. Define the script using the Painless scripting language. Runtime fields require an `emit()`.
-
- ```ts
- emit("Hello World!");
- ```
-
-1. Click **Save**.
-
-1. In the sidebar, search for the **hello** field, and then add it to the document table.
-
-1. Create a second field named `authorabbrev` that combines the authors last name and first initial.
-
- ```ts
- String str = doc['author.keyword'].value;
- char ch1 = str.charAt(0);
- emit(doc['author.keyword'].value + ", " + ch1);
- ```
-
-1. Add `authorabbrev` to the document table.
-
-
-
-
-
-## Search your data
-
-One of the unique capabilities of **Discover** is the ability to combine free text search with filtering based on structured data. To search all fields, enter a simple string in the query bar.
-
-To search particular fields and build more complex queries, use the ((kib)) Query language. As you type, KQL prompts you with the fields you can search and the operators you can use to build a structured query.
-
-Search the book data to find out which books have more than 500 pages:
-
-1. Enter `p`, and then select **page_count**.
-1. Select **>** for greater than and enter **500**, then click the refresh button or press the Enter key to see which books have more than 500 pages.
-
-
-
-## Filter your data
-
-Whereas the query defines the set of documents you are interested in,
-filters enable you to zero in on subsets of those documents.
-You can filter results to include or exclude specific fields, filter for a value in a range,
-and more.
-
-Exclude documents where the author is not Terry Pratchett:
-
-1. Click next to the query bar.
-1. In the **Add filter** pop-up, set the field to **author**, the operator to **is not**, and the value to **Terry Pratchett**.
-1. Click **Add filter**.
-1. Continue your exploration by adding more filters.
-1. To remove a filter, click the close icon (x) next to its name in the filter bar.
-
-
-
-## Look inside a document
-
-Dive into an individual document to view its fields and the documents that occurred before and after it.
-
-1. In the document table, click the expand icon to show document details.
-
-1. Scan through the fields and their values. If you find a field of interest, hover your mouse over the **Actions** column for filters and other options.
-
-1. To create a view of the document that you can bookmark and share, click **Single document**.
-
-1. To view documents that occurred before or after the event you are looking at, click **Surrounding documents**.
-
-
-
-## Save your search for later use
-
-Save your search so you can use it later to generate a CSV report, create visualizations and Dashboards. Saving a search saves the query text, filters, and current view of **Discover**, including the columns selected in the document table, the sort order, and the ((data-source)).
-
-1. In the upper right toolbar, click **Save**.
-
-1. Give your search a title.
-
-1. Optionally store tags and the time range with the search.
-
-1. Click **Save**.
-
-## Visualize your findings
-If a field can be [aggregated](((ref))/search-aggregations.html), you can quickly visualize it from **Discover**.
-
-1. In the sidebar, find and then click `release_date`.
-
-1. In the popup, click **Visualize**.
-
-
- ((kib)) creates a visualization best suited for this field.
-
-
-1. From the **Available fields** list, drag and drop `page_count` onto the workspace.
-
-1. Save your visualization for use on a dashboard.
-
-For geographical point fields, if you click **Visualize**, your data appears in a map.
-
-
-
-## Share your findings
-
-To share your findings with a larger audience, click **Share** in the upper right toolbar.
-
-
-
-## Generate alerts
-
-From **Discover**, you can create a rule to periodically check when data goes above or below a certain threshold within a given time interval.
-
-1. Ensure that your data view,
- query, and filters fetch the data for which you want an alert.
-
-1. In the toolbar, click **Alerts → Create search threshold rule**.
-
- The **Create rule** form is pre-filled with the latest query sent to ((es)).
-
-1. Configure your ((es)) query and select a connector type.
-
-1. Click **Save**.
-
-For more about this and other rules provided in ((alert-features)), go to Alerting.
diff --git a/serverless/pages/explore-your-data-ml-nlp-classify-text.mdx b/serverless/pages/explore-your-data-ml-nlp-classify-text.mdx
deleted file mode 100644
index 464bbb23..00000000
--- a/serverless/pages/explore-your-data-ml-nlp-classify-text.mdx
+++ /dev/null
@@ -1,120 +0,0 @@
----
-# slug: /serverless/elasticsearch/explore-your-data-ml-nlp/classify-text
-title: Classify text
-description: NLP tasks that classify input text or determine the language of text.
-tags: [ 'serverless', 'elasticsearch', 'tbd' ]
----
-
-
-These NLP tasks enable you to identify the language of text and classify or
-label unstructured input text:
-
-*
-* Text classification
-* Zero-shot text classification
-
-## Text classification
-
-Text classification assigns the input text to one of multiple classes that best
-describe the text. The classes used depend on the model and the data set that
-was used to train it. Based on the number of classes, two main types of
-classification exist: binary classification, where the number of classes is
-exactly two, and multi-class classification, where the number of classes is more
-than two.
-
-This task can help you analyze text for markers of positive or negative
-sentiment or classify text into various topics. For example, you might use a
-trained model to perform sentiment analysis and determine whether the following
-text is "POSITIVE" or "NEGATIVE":
-
-```js
-{
- docs: [{"text_field": "This was the best movie I’ve seen in the last decade!"}]
-}
-...
-```
-{/* NOTCONSOLE */}
-
-Likewise, you might use a trained model to perform multi-class classification
-and determine whether the following text is a news topic related to "SPORTS",
-"BUSINESS", "LOCAL", or "ENTERTAINMENT":
-
-```js
-{
- docs: [{"text_field": "The Blue Jays played their final game in Toronto last night and came out with a win over the Yankees, highlighting just how far the team has come this season."}]
-}
-...
-```
-{/* NOTCONSOLE */}
-
-
-## Zero-shot text classification
-
-The zero-shot classification task offers the ability to classify text without
-training a model on a specific set of classes. Instead, you provide the classes
-when you deploy the model or at ((infer)) time. It uses a model trained on a
-large data set that has gained a general language understanding and asks the
-model how well the labels you provided fit with your text.
-
-This task enables you to analyze and classify your input text even when you
-don't have sufficient training data to train a text classification model.
-
-For example, you might want to perform multi-class classification and determine
-whether a news topic is related to "SPORTS", "BUSINESS", "LOCAL", or
-"ENTERTAINMENT". However, in this case the model is not trained specifically for
-news classification; instead, the possible labels are provided together with the
-input text at ((infer)) time:
-
-```js
-{
- docs: [{"text_field": "The S&P 500 gained a meager 12 points in the day’s trading. Trade volumes remain consistent with those of the past week while investors await word from the Fed about possible rate increases."}],
- "inference_config": {
- "zero_shot_classification": {
- "labels": ["SPORTS", "BUSINESS", "LOCAL", "ENTERTAINMENT"]
- }
- }
-}
-```
-{/* NOTCONSOLE */}
-
-The task returns the following result:
-
-```js
-...
-{
- "predicted_value": "BUSINESS"
- ...
-}
-...
-```
-{/* NOTCONSOLE */}
-
-You can use the same model to perform ((infer)) with different classes, such as:
-
-```js
-{
- docs: [{"text_field": "Hello support team. I’m writing to inquire about the possibility of sending my broadband router in for repairs. The internet is really slow and the router keeps rebooting! It’s a big problem because I’m in the middle of binge-watching The Mandalorian!"}]
- "inference_config": {
- "zero_shot_classification": {
- "labels": ["urgent", "internet", "phone", "cable", "mobile", "tv"]
- }
- }
-}
-```
-{/* NOTCONSOLE */}
-
-The task returns the following result:
-
-```js
-...
-{
- "predicted_value": ["urgent", "internet", "tv"]
- ...
-}
-...
-```
-{/* NOTCONSOLE */}
-
-Since you can adjust the labels while you perform ((infer)), this type of task is
-exceptionally flexible. If you are consistently using the same labels, however,
-it might be better to use a fine-tuned text classification model.
\ No newline at end of file
diff --git a/serverless/pages/explore-your-data-ml-nlp-deploy-model.mdx b/serverless/pages/explore-your-data-ml-nlp-deploy-model.mdx
deleted file mode 100644
index a689e1dd..00000000
--- a/serverless/pages/explore-your-data-ml-nlp-deploy-model.mdx
+++ /dev/null
@@ -1,80 +0,0 @@
----
-# slug: /serverless/elasticsearch/explore-your-data-ml-nlp/deploy-trained-models/deploy-model
-title: Deploy the model in your cluster
-description: Description to be written
-tags: []
----
-
-
-After you import the model and vocabulary, you can use ((kib)) to view and
-manage their deployment across your cluster under **((ml-app))** →
-**Model Management**. Alternatively, you can use the
-[start trained model deployment API](((ref))/start-trained-model-deployment.html).
-
-You can deploy a model multiple times by assigning a unique deployment ID when
-starting the deployment. It enables you to have dedicated deployments for
-different purposes, such as search and ingest. By doing so, you ensure that the
-search speed remains unaffected by ingest workloads, and vice versa. Having
-separate deployments for search and ingest mitigates performance issues
-resulting from interactions between the two, which can be hard to diagnose.
-
-
-
-It is recommended to fine-tune each deployment based on its specific purpose. To
-improve ingest performance, increase throughput by adding more allocations to
-the deployment. For improved search speed, increase the number of threads per
-allocation.
-
-
-Since eland uses APIs to deploy the models, you cannot see the models in
-((kib)) until the saved objects are synchronized. You can follow the prompts in
-((kib)), wait for automatic synchronization, or use the
-[sync ((ml)) saved objects API](((kibana-ref))/machine-learning-api-sync.html).
-
-
-When you deploy the model, its allocations are distributed across available ((ml))
-nodes. Model allocations are independent units of work for NLP tasks. To
-influence model performance, you can configure the number of allocations and the
-number of threads used by each allocation of your deployment.
-
-Throughput can be scaled by adding more allocations to the deployment; it
-increases the number of ((infer)) requests that can be performed in parallel. All
-allocations assigned to a node share the same copy of the model in memory. The
-model is loaded into memory in a native process that encapsulates `libtorch`,
-which is the underlying ((ml)) library of PyTorch. The number of allocations
-setting affects the amount of model allocations across all the ((ml)) nodes. Model
-allocations are distributed in such a way that the total number of used threads
-does not exceed the allocated processors of a node.
-
-The threads per allocation setting affects the number of threads used by each
-model allocation during ((infer)). Increasing the number of threads generally
-increases the speed of ((infer)) requests. The value of this setting must not
-exceed the number of available allocated processors per node.
-
-You can view the allocation status in ((kib)) or by using the
-[get trained model stats API](((ref))/get-trained-models-stats.html). If you want to
-change the number of allocations, you can use the
-[update trained model stats API](((ref))/update-trained-model-deployment.html)
-after the allocation status is `started`.
-
-
-## Request queues and search priority
-
-Each allocation of a model deployment has a dedicated queue to buffer ((infer))
-requests. The size of this queue is determined by the `queue_capacity` parameter
-in the
-[start trained model deployment API](((ref))/start-trained-model-deployment.html).
-When the queue reaches its maximum capacity, new requests are declined until
-some of the queued requests are processed, creating available capacity once
-again. When multiple ingest pipelines reference the same deployment, the queue
-can fill up, resulting in rejected requests. Consider using dedicated
-deployments to prevent this situation.
-
-((infer-cap)) requests originating from search, such as the
-[`sparse_vector` query](((ref))/query-dsl-sparse-vector-query.html), have a higher
-priority compared to non-search requests. The ((infer)) ingest processor generates
-normal priority requests. If both a search query and an ingest processor use the
-same deployment, the search requests with higher priority skip ahead in the
-queue for processing before the lower priority ingest requests. This
-prioritization accelerates search responses while potentially slowing down
-ingest where response time is less critical.
diff --git a/serverless/pages/explore-your-data-ml-nlp-deploy-trained-models.mdx b/serverless/pages/explore-your-data-ml-nlp-deploy-trained-models.mdx
deleted file mode 100644
index a86e9a23..00000000
--- a/serverless/pages/explore-your-data-ml-nlp-deploy-trained-models.mdx
+++ /dev/null
@@ -1,17 +0,0 @@
----
-# slug: /serverless/elasticsearch/explore-your-data-ml-nlp/deploy-trained-models
-title: Deploy trained models
-description: You can import trained models into your cluster and configure them for specific NLP tasks.
-tags: [ 'serverless', 'elasticsearch', 'tbd' ]
----
-
-
-If you want to perform ((nlp)) tasks in your cluster, you must deploy an
-appropriate trained model. There is tooling support in
-[Eland](https://github.com/elastic/eland) and ((kib)) to help you prepare and
-manage models.
-
-1. Select a trained model.
-1. Import the trained model and vocabulary.
-1. Deploy the model in your cluster.
-1. Try it out.
\ No newline at end of file
diff --git a/serverless/pages/explore-your-data-ml-nlp-elser.mdx b/serverless/pages/explore-your-data-ml-nlp-elser.mdx
deleted file mode 100644
index 89c20f2f..00000000
--- a/serverless/pages/explore-your-data-ml-nlp-elser.mdx
+++ /dev/null
@@ -1,150 +0,0 @@
----
-# slug: /serverless/elasticsearch/explore-your-data-ml-nlp/elastic-models/elser
-title: ELSER – Elastic Learned Sparse EncodeR
-description: ELSER is a learned sparse ranking model trained by Elastic.
-tags: [ 'serverless', 'elasticsearch', 'tbd' ]
----
-
-
-Elastic Learned Sparse EncodeR - or ELSER - is a retrieval model trained by
-Elastic that enables you to perform
-[semantic search](((ref))/semantic-search-elser.html) to retrieve more relevant
-search results. This search type provides you search results based on contextual
-meaning and user intent, rather than exact keyword matches.
-
-ELSER is an out-of-domain model which means it does not require fine-tuning on
-your own data, making it adaptable for various use cases out of the box.
-
-ELSER expands the indexed and searched passages into collections of terms that
-are learned to co-occur frequently within a diverse set of training data. The
-terms that the text is expanded into by the model _are not_ synonyms for the
-search terms; they are learned associations. These expanded terms are weighted
-as some of them are more significant than others. Then the ((es))
-[rank-feature field type](((ref))/rank-feature.html) is used to store the terms
-and weights at index time, and to search against later.
-
-## Requirements
-
-To use ELSER, you must have the [appropriate subscription](((subscriptions))) level
-for semantic search or the trial period activated.
-
-## Benchmarks
-
-The following sections provide information about how ELSER performs on different
-hardwares and compares the model performance to ((es)) BM25 and other strong
-baselines such as Splade or OpenAI.
-
-### Hardware benchmarks
-
-Two data sets were utilized to evaluate the performance of ELSER in different
-hardware configurations: `msmarco-long-light` and `arguana`.
-
-| | | | |
-|---|---|---|---|
-| **Data set** | **Data set size** | **Average count of tokens / query** | **Average count of tokens / document** |
-| `msmarco-long-light` | 37367 documents | 9 | 1640 |
-| `arguana` | 8674 documents | 238 | 202 |
-
-The `msmarco-long-light` data set contains long documents with an average of
-over 512 tokens, which provides insights into the performance implications
-of indexing and ((infer)) time for long documents. This is a subset of the
-"msmarco" dataset specifically designed for document retrieval (it shouldn't be
-confused with the "msmarco" dataset used for passage retrieval, which primarily
-consists of shorter spans of text).
-
-The `arguana` data set is a [BEIR](https://github.com/beir-cellar/beir) data set.
-It consists of long queries with an average of 200 tokens per query. It can
-represent an upper limit for query slowness.
-
-The table below present benchmarking results for ELSER using various hardware
-configurations.
-
-
-### Qualitative benchmarks
-
-The metric that is used to evaluate ELSER's ranking ability is the Normalized
-Discounted Cumulative Gain (NDCG) which can handle multiple relevant documents
-and fine-grained document ratings. The metric is applied to a fixed-sized list
-of retrieved documents which, in this case, is the top 10 documents (NDCG@10).
-
-The table below shows the performance of ELSER compared to ((es)) BM25 with an
-English analyzer broken down by the 12 data sets used for the evaluation. ELSER
-has 10 wins, 1 draw, 1 loss and an average improvement in NDCG@10 of 17%.
-
-
-_NDCG@10 for BEIR data sets for BM25 and ELSER - higher values are better)_
-
-The following table compares the average performance of ELSER to some other
-strong baselines. The OpenAI results are separated out because they use a
-different subset of the BEIR suite.
-
-
-_Average NDCG@10 for BEIR data sets vs. various high quality baselines (higher_
-_is better). OpenAI chose a different subset, ELSER results on this set_
-_reported separately._
-
-To read more about the evaluation details, refer to
-[this blog post](https://www.elastic.co/blog/may-2023-launch-information-retrieval-elasticsearch-ai-model).
-
-
-## Download and deploy ELSER
-
-You can download and deploy ELSER either from **Trained Models** or by using the
-Dev Console.
-
-### Using the Trained Models page
-
-1. In ((kib)), navigate to **Trained Models**. ELSER can be found
- in the list of trained models.
-
-1. Click the **Download model** button under **Actions**. You can check the
- download status on the **Notifications** page.
-
-
-
-1. After the download is finished, start the deployment by clicking the
- **Start deployment** button.
-
-1. Provide a deployment ID, select the priority, and set the number of
- allocations and threads per allocation values.
-
-
-
-1. Click Start.
-
-
-### Using the Dev Console
-
-1. Navigate to the **Dev Console**.
-1. Create the ELSER model configuration by running the following API call:
-
- ```console
- PUT _ml/trained_models/.elser_model_1
- {
- "input": {
- "field_names": ["text_field"]
- }
-
- ```
-
- The API call automatically initiates the model download if the model is not
- downloaded yet.
-
-1. Deploy the model by using the
- [start trained model deployment API](((ref))/start-trained-model-deployment.html)
- with a delpoyment ID:
-
- ```console
- POST _ml/trained_models/.elser_model_1/deployment/_start?deployment_id=for_search
- ```
-
- You can deploy the model multiple times with different deployment IDs.
-
-After the deployment is complete, ELSER is ready to use either in an ingest
-pipeline or in a `sparse_vector` query to perform semantic search.
-
-
-## Further reading
-
-* [Perform semantic search with ELSER](((ref))/semantic-search-elser.html)
-* [Improving information retrieval in the Elastic Stack: Introducing Elastic Learned Sparse Encoder, our new retrieval model](https://www.elastic.co/blog/may-2023-launch-information-retrieval-elasticsearch-ai-model)
diff --git a/serverless/pages/explore-your-data-ml-nlp-examples.mdx b/serverless/pages/explore-your-data-ml-nlp-examples.mdx
deleted file mode 100644
index 4945d557..00000000
--- a/serverless/pages/explore-your-data-ml-nlp-examples.mdx
+++ /dev/null
@@ -1,13 +0,0 @@
----
-# slug: /serverless/elasticsearch/explore-your-data-ml-nlp/examples
-title: Examples
-description: Description to be written
-tags: []
----
-
-
-The following pages contain end-to-end examples of how to use the different
-((nlp)) tasks in the ((stack)).
-
-* How to deploy named entity recognition
-* How to deploy a text embedding model and use it for semantic search
\ No newline at end of file
diff --git a/serverless/pages/explore-your-data-ml-nlp-extract-info.mdx b/serverless/pages/explore-your-data-ml-nlp-extract-info.mdx
deleted file mode 100644
index b7274e09..00000000
--- a/serverless/pages/explore-your-data-ml-nlp-extract-info.mdx
+++ /dev/null
@@ -1,130 +0,0 @@
----
-# slug: /serverless/elasticsearch/explore-your-data-ml-nlp/extract-info
-title: Extract information
-description: NLP tasks that extract information from unstructured text.
-tags: [ 'serverless', 'elasticsearch', 'tbd' ]
----
-
-
-These NLP tasks enable you to extract information from your unstructured text:
-
-* Named entity recognition
-* Fill-mask
-* Question answering
-
-## Named entity recognition
-
-The named entity recognition (NER) task can identify and categorize certain
-entities - typically proper nouns - in your unstructured text. Named entities
-usually refer to objects in the real world such as persons, locations,
-organizations, and other miscellaneous entities that are consistently referenced
-by a proper name.
-
-NER is a useful tool to identify key information, add structure and gain
-insight into your content. It's particularly useful while processing and
-exploring large collections of text such as news articles, wiki pages or
-websites. It makes it easier to understand the subject of a text and group
-similar pieces of content together.
-
-In the following example, the short text is analyzed for any named entity and
-the model extracts not only the individual words that make up the entities, but
-also phrases, consisting of multiple words.
-
-```js
-{
- "docs": [{"text_field": "Elastic is headquartered in Mountain View, California."}]
-}
-...
-```
-{/* NOTCONSOLE */}
-
-The task returns the following result:
-
-```js
-{
- "inference_results": [{
- ...
- entities: [
- {
- "entity": "Elastic",
- "class": "organization"
- },
- {
- "entity": "Mountain View",
- "class": "location"
- },
- {
- "entity": "California",
- "class": "location"
- }
- ]
- }
- ]
-}
-...
-```
-{/* NOTCONSOLE */}
-
-
-## Fill-mask
-
-The objective of the fill-mask task is to predict a missing word from a text
-sequence. The model uses the context of the masked word to predict the most
-likely word to complete the text.
-
-The fill-mask task can be used to quickly and easily test your model.
-
-In the following example, the special word “[MASK]” is used as a placeholder to
-tell the model which word to predict.
-
-```js
-{
- docs: [{"text_field": "The capital city of France is [MASK]."}]
-}
-...
-```
-{/* NOTCONSOLE */}
-
-The task returns the following result:
-
-```js
-...
-{
- "predicted_value": "Paris"
- ...
-}
-...
-```
-{/* NOTCONSOLE */}
-
-
-## Question answering
-
-The question answering (or extractive question answering) task makes it possible
-to get answers to certain questions by extracting information from the provided
-text.
-
-The model tokenizes the string of – usually long – unstructured text, then it
-attempts to pull an answer for your question from the text. The logic is
-shown by the following examples:
-
-```js
-{
- "docs": [{"text_field": "The Amazon rainforest (Portuguese: Floresta Amazônica or Amazônia; Spanish: Selva Amazónica, Amazonía or usually Amazonia; French: Forêt amazonienne; Dutch: Amazoneregenwoud), also known in English as Amazonia or the Amazon Jungle, is a moist broadleaf forest that covers most of the Amazon basin of South America. This basin encompasses 7,000,000 square kilometres (2,700,000 sq mi), of which 5,500,000 square kilometres (2,100,000 sq mi) are covered by the rainforest. This region includes territory belonging to nine nations. The majority of the forest is contained within Brazil, with 60% of the rainforest, followed by Peru with 13%, Colombia with 10%, and with minor amounts in Venezuela, Ecuador, Bolivia, Guyana, Suriname and French Guiana. States or departments in four nations contain "Amazonas" in their names. The Amazon represents over half of the planet's remaining rainforests, and comprises the largest and most biodiverse tract of tropical rainforest in the world, with an estimated 390 billion individual trees divided into 16,000 species."}],
- "inference_config": {"question_answering": {"question": "Which name is also used to describe the Amazon rainforest in English?"}}
-}
-...
-```
-{/* NOTCONSOLE */}
-
-The answer is shown by the object below:
-
-```js
-...
-{
- "predicted_value": "Amazonia"
- ...
-}
-...
-```
-{/* NOTCONSOLE */}
\ No newline at end of file
diff --git a/serverless/pages/explore-your-data-ml-nlp-import-model.mdx b/serverless/pages/explore-your-data-ml-nlp-import-model.mdx
deleted file mode 100644
index 47bf8138..00000000
--- a/serverless/pages/explore-your-data-ml-nlp-import-model.mdx
+++ /dev/null
@@ -1,117 +0,0 @@
----
-# slug: /serverless/elasticsearch/explore-your-data-ml-nlp/deploy-trained-models/import-model
-title: Import the trained model and vocabulary
-# description: Description to be written
-tags: [ 'serverless', 'elasticsearch', 'tbd' ]
----
-
-
-
-If you want to install a trained model in a restricted or closed
-network, refer to
-[these instructions](((eland-docs))/machine-learning.html#ml-nlp-pytorch-air-gapped).
-
-
-After you choose a model, you must import it and its tokenizer vocabulary to
-your cluster. When you import the model, it must be chunked and imported one
-chunk at a time for storage in parts due to its size.
-
-
-Trained models must be in a TorchScript representation for use with
-((stack-ml-features)).
-
-
-[Eland](https://github.com/elastic/eland) is an ((es)) Python client that
-provides a simple script to perform the conversion of Hugging Face transformer
-models to their TorchScript representations, the chunking process, and upload to
-((es)); it is therefore the recommended import method. You can either install
-the Python Eland client on your machine or use a Docker image to build Eland and
-run the model import script.
-
-
-## Import with the Eland client installed
-
-1. Install the [Eland Python client](((eland-docs))/installation.html) with
- PyTorch extra dependencies.
-
- ```shell
- python -m pip install 'eland[pytorch]'
- ```
- {/* NOTCONSOLE */}
-
-1. Run the `eland_import_hub_model` script to download the model from Hugging
- Face, convert it to TorchScript format, and upload to the ((es)) cluster.
- For example:
-
- {/* NOTCONSOLE */}
- ```shell
- eland_import_hub_model
- -u -p \ [^2]
- ```
- [^1]: Specify the Elastic Cloud identifier. Alternatively, use `--url`.
- [^2]: Provide authentication details to access your cluster. Refer to
- Authentication methods to learn more.
- [^3]: Specify the identifier for the model in the Hugging Face model hub.
- [^4]: Specify the type of NLP task. Supported values are `fill_mask`, `ner`,
- `text_classification`, `text_embedding`, and `zero_shot_classification`.
-
-For more details, refer to
-https://www.elastic.co/guide/en/elasticsearch/client/eland/current/machine-learning.html#ml-nlp-pytorch.
-
-
-## Import with Docker
-
-
-To use the Docker container, you need to clone the Eland repository:
-https://github.com/elastic/eland
-
-
-If you want to use Eland without installing it, clone the Eland repository and
-from the root directory run the following to build the Docker image:
-
-```bash
-$ docker build -t elastic/eland .
-```
-
-You can now use the container interactively:
-
-```bash
-$ docker run -it --rm --network host elastic/eland
-```
-
-The `eland_import_hub_model` script can be run directly in the docker command:
-
-```bash
-docker run -it --rm elastic/eland \
- eland_import_hub_model \
- --url $ELASTICSEARCH_URL \
- --hub-model-id elastic/distilbert-base-uncased-finetuned-conll03-english \
- --start
-```
-
-Replace the `$ELASTICSEARCH_URL` with the URL for your ((es)) cluster. Refer to
-Authentication methods
-to learn more.
-
-
-## Authentication methods
-
-The following authentication options are available when using the import script:
-
-* username/password authentication (specified with the `-u` and `-p` options):
-
-```bash
-eland_import_hub_model --url https://: -u -p ...
-```
-
-* username/password authentication (embedded in the URL):
-
- ```bash
- eland_import_hub_model --url https://:@: ...
- ```
-
-* API key authentication:
-
- ```bash
- eland_import_hub_model --url https://: --es-api-key ...
- ```
\ No newline at end of file
diff --git a/serverless/pages/explore-your-data-ml-nlp-inference.mdx b/serverless/pages/explore-your-data-ml-nlp-inference.mdx
deleted file mode 100644
index 50d45cc2..00000000
--- a/serverless/pages/explore-your-data-ml-nlp-inference.mdx
+++ /dev/null
@@ -1,290 +0,0 @@
----
-# slug: /serverless/elasticsearch/explore-your-data-ml-nlp/inference
-title: Add NLP ((infer)) to ingest pipelines
-description: You can import trained models into your cluster and configure them for specific NLP tasks.
-tags: [ 'serverless', 'elasticsearch', 'tbd' ]
----
-
-
-After you deploy a trained model in your cluster,
-you can use it to perform ((nlp)) tasks in ingest pipelines.
-
-1. Verify that all of the
- [ingest pipeline prerequisites](((ref))/ingest.html#ingest-prerequisites)
- are met.
-
-1. Add an ((infer)) processor to an ingest pipeline.
-1. Ingest documents.
-1. View the results.
-
-
-## Add an ((infer)) processor to an ingest pipeline
-
-In ((kib)), you can create and edit pipelines under **Content** → **Pipelines**.
-
-
-
-1. Click **Create pipeline** or edit an existing pipeline.
-1. Add an [((infer)) processor](((ref))/inference-processor.html) to your pipeline:
- 1. Click **Add a processor** and select the **((infer-cap))** processor type.
- 1. Set **Model ID** to the name of your trained model, for example
- `elastic__distilbert-base-cased-finetuned-conll03-english` or
- `lang_ident_model_1`.
-
- 1. If you use the ((lang-ident)) model (`lang_ident_model_1`) that is provided in
- your cluster:
-
- 1. The input field name is assumed to be `text`. If you want to identify
- languages in a field with a different name, you must map your field name to
- `text` in the **Field map** section. For example:
-
- ```js
- {
- "message": "text"
- }
- ```
- {/* NOTCONSOLE */}
-
- 1. Click **Add** to save the processor.
-1. Optional: Add a [set processor](((ref))/set-processor.html) to index the ingest
- timestamp.
-
- 1. Click **Add a processor** and select the **Set** processor type.
- 1. Choose a name for the field (such as `event.ingested`) and set its value to
- `{{{_ingest.timestamp}}}`. For more details, refer to
- [Access ingest metadata in a processor](((ref))/ingest.html#access-ingest-metadata).
-
- 1. Click **Add** to save the processor.
-1. Optional: Add failure processors to handle exceptions. For example, in the
- **Failure processors** section:
-
- 1. Add a set processor to capture the
- pipeline error message. Choose a name for the field (such as
- `ml.inference_failure`) and set its value to the
- `{{_ingest.on_failure_message}}` document metadata field.
-
- 1. Add a set processor to reroute
- problematic documents to a different index for troubleshooting purposes. Use
- the `_index` metadata field and set its value to a new name (such as
- `failed-{{{ _index }}}`). For more details, refer
- to [Handling pipeline failures](((ref))/ingest.html#handling-pipeline-failures).
-
-1. To test the pipeline, click **Add documents**.
- 1. In the **Documents** tab, provide a sample document for testing.
-
- For example, to test a trained model that performs named entity recognition
- (NER):
-
- ```js
- [
- {
- "_source": {
- "text_field":"Hello, my name is Josh and I live in Berlin."
- }
- }
- ]
- ```
- {/* NOTCONSOLE */}
-
- To test a trained model that performs ((lang-ident)):
-
- ```js
- [
- {
- "_source":{
- "message":"Sziasztok! Ez egy rövid magyar szöveg. Nézzük, vajon sikerül-e azonosítania a language identification funkciónak? Annak ellenére is sikerülni fog, hogy a szöveg két angol szót is tartalmaz."
- }
- }
- ]
- ```
- {/* NOTCONSOLE */}
-
- 1. Click **Run the pipeline** and verify the pipeline worked as expected.
-
- In the ((lang-ident)) example, the predicted value is the ISO identifier of the
- language with the highest probability. In this case, it should be `hu` for
- Hungarian.
-
- 1. If everything looks correct, close the panel, and click **Create
- pipeline**. The pipeline is now ready for use.
-
-{/*
-
-
-
-```console
-POST _ingest/pipeline/my-ner-pipeline
-{
- "inference": {
- "model_id": "elastic__distilbert-base-cased-finetuned-conll03-english",
- "field_map": {
- "review": "text_field"
- },
- "on_failure": [
- {
- "set": {
- "description": "Set the error message",
- "field": "ml.inference_failure",
- "value": "{{_ingest.on_failure_message}}"
- }
- },
- {
- "set": {
- "description": "Index document to 'failed-'",
- "field": "_index",
- "value": "failed-{{{ _index }}}"
- }
- }
- ]
- }
-}
-```
-TEST[skip:TBD]
-
-
-
-*/}
-
-## Ingest documents
-
-You can now use your ingest pipeline to perform NLP tasks on your data.
-
-Before you add data, consider which mappings you want to use. For example, you
-can create explicit mappings with the create index API in the
-**((dev-tools-app))** → **Console**:
-
-```console
-PUT ner-test
-{
- "mappings": {
- "properties": {
- "ml.inference.predicted_value": {"type": "annotated_text"},
- "ml.inference.model_id": {"type": "keyword"},
- "text_field": {"type": "text"},
- "event.ingested": {"type": "date"}
- }
- }
-}
-```
-{/* TEST[skip:TBD] */}
-
-
-To use the `annotated_text` data type in this example, you must install the
-[mapper annotated text plugin](((plugins))/mapper-annotated-text.html). For more
-installation details, refer to
-[Add plugins provided with ((ess))](((cloud))/ec-adding-elastic-plugins.html).
-
-
-You can then use the new pipeline to index some documents. For example, use a
-bulk indexing request with the `pipeline` query parameter for your NER pipeline:
-
-```console
-POST /_bulk?pipeline=my-ner-pipeline
-{"create":{"_index":"ner-test","_id":"1"}}
-{"text_field":"Hello, my name is Josh and I live in Berlin."}
-{"create":{"_index":"ner-test","_id":"2"}}
-{"text_field":"I work for Elastic which was founded in Amsterdam."}
-{"create":{"_index":"ner-test","_id":"3"}}
-{"text_field":"Elastic has headquarters in Mountain View, California."}
-{"create":{"_index":"ner-test","_id":"4"}}
-{"text_field":"Elastic's founder, Shay Banon, created Elasticsearch to solve a simple need: finding recipes!"}
-{"create":{"_index":"ner-test","_id":"5"}}
-{"text_field":"Elasticsearch is built using Lucene, an open source search library."}
-```
-{/* TEST[skip:TBD] */}
-
-Or use an individual indexing request with the `pipeline` query parameter for
-your ((lang-ident)) pipeline:
-
-```console
-POST lang-test/_doc?pipeline=my-lang-pipeline
-{
- "message": "Mon pays ce n'est pas un pays, c'est l'hiver"
-}
-```
-{/* TEST[skip:TBD] */}
-
-You can also use NLP pipelines when you are reindexing documents to a new
-destination. For example, since the
-[sample web logs data set](((kibana-ref))/get-started.html#gs-get-data-into-kibana)
-contain a `message` text field, you can reindex it with your ((lang-ident))
-pipeline:
-
-```console
-POST _reindex
-{
- "source": {
- "index": "kibana_sample_data_logs",
- "size": 50
- },
- "dest": {
- "index": "lang-test",
- "pipeline": "my-lang-pipeline"
- }
-}
-```
-{/* TEST[skip:TBD] */}
-
-However, those web log messages are unlikely to contain enough words for the
-model to accurately identify the language.
-
-
-Set the reindex `size` option to a value smaller than the `queue_capacity`
-for the trained model deployment. Otherwise, requests might be rejected with a
-"too many requests" 429 error code.
-
-
-
-## View the results
-
-Before you can verify the results of the pipelines, you must
-[create ((data-sources))](((kibana-ref))/data-views.html). Then you can explore
-your data in **Discover**:
-
-
-
-The `ml.inference.predicted_value` field contains the output from the ((infer))
-processor. In this NER example, there are two documents that contain the
-`Elastic` organization entity.
-
-In this ((lang-ident)) example, the `ml.inference.predicted_value` contains the
-ISO identifier of the language with the highest probability and the
-`ml.inference.top_classes` fields contain the top five most probable languages
-and their scores:
-
-
-
-To learn more about ingest pipelines and all of the other processors that you
-can add, refer to [Ingest pipelines](((ref))/ingest.html).
-
-
-## Common problems
-
-If you encounter problems while using your trained model in an ingest pipeline,
-check the following possible causes:
-
-1. The trained model is not deployed in your cluster. You can view its status in
- **((ml-app))** → **Model Management** or use the
- [get trained models statistics API](((ref))/get-trained-models-stats.html).
- Unless you are using the built-in `lang_ident_model_1` model, you must
- ensure your model is successfully deployed. Refer to
- Deploy the model in your cluster.
-
-1. The default input field name expected by your trained model is not present in
- your source document. Use the **Field Map** option in your ((infer))
- processor to set the appropriate field name.
-
-1. There are too many requests. If you are using bulk ingest, reduce the number
- of documents in the bulk request. If you are reindexing, use the `size`
- parameter to decrease the number of documents processed in each batch.
-
-These common failure scenarios and others can be captured by adding failure
-processors to your pipeline. For more examples, refer to
-[Handling pipeline failures](((ref))/ingest.html#handling-pipeline-failures).
-
-
-## Further reading
-
-* [How to deploy NLP: Text Embeddings and Vector Search](((blog-ref))how-to-deploy-nlp-text-embeddings-and-vector-search)
-* [How to deploy NLP: Named entity recognition (NER) example](((blog-ref))how-to-deploy-nlp-named-entity-recognition-ner-example)
-* [How to deploy NLP: Sentiment Analysis Example](((blog-ref))how-to-deploy-nlp-sentiment-analysis-example)
\ No newline at end of file
diff --git a/serverless/pages/explore-your-data-ml-nlp-lang-ident.mdx b/serverless/pages/explore-your-data-ml-nlp-lang-ident.mdx
deleted file mode 100644
index 0c2c85ba..00000000
--- a/serverless/pages/explore-your-data-ml-nlp-lang-ident.mdx
+++ /dev/null
@@ -1,89 +0,0 @@
----
-# slug: /serverless/elasticsearch/explore-your-data-ml-nlp/ootb-models/lang-ident
-title: Language identification
-description: Language identification is an NLP task and a model that enables you to determine the language of text.
-tags: [ 'serverless', 'elasticsearch', 'tbd' ]
----
-
-
-((lang-ident-cap)) enables you to determine the language of text.
-
-A ((lang-ident)) model is provided in your cluster, which you can use in an
-((infer)) processor of an ingest pipeline by using its model ID
-(`lang_ident_model_1`). For an example, refer to
-Add NLP ((infer)) to ingest pipelines.
-
-The longer the text passed into the ((lang-ident)) model, the more accurately the
-model can identify the language. It is fairly accurate on short samples (for
-example, 50 character-long streams) in certain languages, but languages that are
-similar to each other are harder to identify based on a short character stream.
-If there is no valid text from which the identity can be inferred, the model
-returns the special language code `zxx`. If you prefer to use a different
-default value, you can adjust your ingest pipeline to replace `zxx` predictions
-with your preferred value.
-
-((lang-ident-cap)) takes into account Unicode boundaries when the feature set is
-built. If the text has diacritical marks, then the model uses that information
-for identifying the language of the text. In certain cases, the model can
-detect the source language even if it is not written in the script that the
-language traditionally uses. These languages are marked in the supported
-languages table (see below) with the `Latn` subtag. ((lang-ident-cap)) supports
-Unicode input.
-
-## Supported languages
-
-The table below contains the ISO codes and the English names of the languages
-that ((lang-ident)) supports. If a language has a 2-letter `ISO 639-1` code, the
-table contains that identifier. Otherwise, the 3-letter `ISO 639-2` code is
-used. The `Latn` subtag indicates that the language is transliterated into Latin
-script.
-
-{/* lint disable */}
-{/* [cols="\<,\<,\<,\<,\<,\<"] */}
-| | | | | | |
-|---|---|---|---|---|---|
-| Code | Language | Code | Language | Code | Language |
-| af | Afrikaans | hr | Croatian | pa | Punjabi |
-| am | Amharic | ht | Haitian | pl | Polish |
-| ar | Arabic | hu | Hungarian | ps | Pashto |
-| az | Azerbaijani | hy | Armenian | pt | Portuguese |
-| be | Belarusian | id | Indonesian | ro | Romanian |
-| bg | Bulgarian | ig | Igbo | ru | Russian |
-| bg-Latn | Bulgarian | is | Icelandic | ru-Latn | Russian |
-| bn | Bengali | it | Italian | sd | Sindhi |
-| bs | Bosnian | iw | Hebrew | si | Sinhala |
-| ca | Catalan | ja | Japanese | sk | Slovak |
-| ceb | Cebuano | ja-Latn | Japanese | sl | Slovenian |
-| co | Corsican | jv | Javanese | sm | Samoan |
-| cs | Czech | ka | Georgian | sn | Shona |
-| cy | Welsh | kk | Kazakh | so | Somali |
-| da | Danish | km | Central Khmer | sq | Albanian |
-| de | German | kn | Kannada | sr | Serbian |
-| el | Greek, modern | ko | Korean | st | Southern Sotho |
-| el-Latn | Greek, modern | ku | Kurdish | su | Sundanese |
-| en | English | ky | Kirghiz | sv | Swedish |
-| eo | Esperanto | la | Latin | sw | Swahili |
-| es | Spanish, Castilian | lb | Luxembourgish | ta | Tamil |
-| et | Estonian | lo | Lao | te | Telugu |
-| eu | Basque | lt | Lithuanian | tg | Tajik |
-| fa | Persian | lv | Latvian | th | Thai |
-| fi | Finnish | mg | Malagasy | tr | Turkish |
-| fil | Filipino | mi | Maori | uk | Ukrainian |
-| fr | French | mk | Macedonian | ur | Urdu |
-| fy | Western Frisian | ml | Malayalam | uz | Uzbek |
-| ga | Irish | mn | Mongolian | vi | Vietnamese |
-| gd | Gaelic | mr | Marathi | xh | Xhosa |
-| gl | Galician | ms | Malay | yi | Yiddish |
-| gu | Gujarati | mt | Maltese | yo | Yoruba |
-| ha | Hausa | my | Burmese | zh | Chinese |
-| haw | Hawaiian | ne | Nepali | zh-Latn | Chinese |
-| hi | Hindi | nl | Dutch, Flemish | zu | Zulu |
-| hi-Latn | Hindi | no | Norwegian | | |
-| hmn | Hmong | ny | Chichewa | | |
-
-{/* lint enable */}
-
-
-## Further reading
-
-* [Multilingual search using ((lang-ident)) in ((es))](((blog-ref))multilingual-search-using-language-identification-in-elasticsearch)
\ No newline at end of file
diff --git a/serverless/pages/explore-your-data-ml-nlp-model-ref.mdx b/serverless/pages/explore-your-data-ml-nlp-model-ref.mdx
deleted file mode 100644
index 78ae5208..00000000
--- a/serverless/pages/explore-your-data-ml-nlp-model-ref.mdx
+++ /dev/null
@@ -1,268 +0,0 @@
----
-# slug: /serverless/elasticsearch/explore-your-data-ml-nlp/model-reference
-title: Compatible third party NLP models
-description: The list of compatible third party NLP models.
-tags: ["ml","reference","analyze"]
----
-
-
-The ((stack-ml-features)) support transformer models that conform to the
-standard BERT model interface and use the WordPiece tokenization algorithm.
-
-The current list of supported architectures is:
-
-* BERT
-* BART
-* DPR bi-encoders
-* DistilBERT
-* ELECTRA
-* MobileBERT
-* RoBERTa
-* RetriBERT
-* MPNet
-* SentenceTransformers bi-encoders with the above transformer architectures
-* XLM-RoBERTa
-
-In general, any trained model that has a supported architecture is deployable in
-((es)) by using eland. However, it is not possible to test every third party
-model. The following lists are therefore provided for informational purposes
-only and may not be current. Elastic makes no warranty or assurance that the
-((ml-features)) will continue to interoperate with these third party models in
-the way described, or at all.
-
-These models are listed by NLP task; for more information about those tasks,
-refer to
-Overview.
-
-**Models highlighted in bold** in the list below are recommended for evaluation
-purposes and to get started with the Elastic ((nlp)) features.
-
-
-## Third party fill-mask models
-
-* [BERT base model](https://huggingface.co/bert-base-uncased)
-* [DistilRoBERTa base model](https://huggingface.co/distilroberta-base)
-* [MPNet base model](https://huggingface.co/microsoft/mpnet-base)
-* [RoBERTa large model](https://huggingface.co/roberta-large)
-
-
-## Third party named entity recognition models
-
-* [BERT base NER](https://huggingface.co/dslim/bert-base-NER)
-* [**DistilBERT base cased finetuned conll03 English**](https://huggingface.co/elastic/distilbert-base-cased-finetuned-conll03-english)
-* [DistilRoBERTa base NER conll2003](https://huggingface.co/philschmid/distilroberta-base-ner-conll2003)
-* [**DistilBERT base uncased finetuned conll03 English**](https://huggingface.co/elastic/distilbert-base-uncased-finetuned-conll03-english)
-* [DistilBERT fa zwnj base NER](https://huggingface.co/HooshvareLab/distilbert-fa-zwnj-base-ner)
-
-
-## Third party question answering models
-
-* [BERT large model (uncased) whole word masking finetuned on SQuAD](https://huggingface.co/bert-large-uncased-whole-word-masking-finetuned-squad)
-* [DistilBERT base cased distilled SQuAD](https://huggingface.co/distilbert-base-cased-distilled-squad)
-* [Electra base squad2](https://huggingface.co/deepset/electra-base-squad2)
-* [TinyRoBERTa squad2](https://huggingface.co/deepset/tinyroberta-squad2)
-
-
-## Third party text embedding models
-
-Text Embedding models are designed to work with specific scoring functions
-for calculating the similarity between the embeddings they produce.
-Examples of typical scoring functions are: `cosine`, `dot product` and
-`euclidean distance` (also known as `l2_norm`).
-
-The embeddings produced by these models should be indexed in ((es)) using the
-[dense vector field type](((ref))/dense-vector.html)
-with an appropriate
-[similarity function](((ref))/dense-vector.html#dense-vector-params) chosen for
-the model.
-
-To find similar embeddings in ((es)) use the efficient
-[Approximate k-nearest neighbor (kNN)](((ref))/knn-search.html#approximate-knn)
-search API with a text embedding as the query vector. Approximate kNN search
-uses the similarity function defined in the dense vector field mapping is used
-to calculate the relevance. For the best results the function must be one of
-the suitable similarity functions for the model.
-
-Using `SentenceTransformerWrapper`:
-
-* [All DistilRoBERTa v1](https://huggingface.co/sentence-transformers/all-distilroberta-v1)
- Suitable similarity functions: `dot_product`, `cosine`, `l2_norm`
-
-* [All MiniLM L12 v2](https://huggingface.co/sentence-transformers/all-MiniLM-L12-v2)
- Suitable similarity functions: `dot_product`, `cosine`, `l2_norm`
-
-* [**All MPNet base v2**](https://huggingface.co/sentence-transformers/all-mpnet-base-v2)
- Suitable similarity functions: `dot_product`, `cosine`, `l2_norm`
-
-* [Facebook dpr-ctx_encoder multiset base](https://huggingface.co/sentence-transformers/facebook-dpr-ctx_encoder-multiset-base)
- Suitable similarity functions: `dot_product`
-
-* [Facebook dpr-question_encoder single nq base](https://huggingface.co/sentence-transformers/facebook-dpr-question_encoder-single-nq-base)
- Suitable similarity functions: `dot_product`
-
-* [LaBSE](https://huggingface.co/sentence-transformers/LaBSE)
- Suitable similarity functions: `cosine`
-
-* [msmarco DistilBERT base tas b](https://huggingface.co/sentence-transformers/msmarco-distilbert-base-tas-b)
- Suitable similarity functions: `dot_product`
-
-* [msmarco MiniLM L12 v5](https://huggingface.co/sentence-transformers/msmarco-MiniLM-L12-cos-v5)
- Suitable similarity functions: `dot_product`, `cosine`, `l2_norm`
-
-* [paraphrase mpnet base v2](https://huggingface.co/sentence-transformers/paraphrase-mpnet-base-v2)
- Suitable similarity functions: `cosine`
-
-Using `DPREncoderWrapper`:
-
-* [ance dpr-context multi](https://huggingface.co/castorini/ance-dpr-context-multi)
-* [ance dpr-question multi](https://huggingface.co/castorini/ance-dpr-question-multi)
-* [bpr nq-ctx-encoder](https://huggingface.co/castorini/bpr-nq-ctx-encoder)
-* [bpr nq-question-encoder](https://huggingface.co/castorini/bpr-nq-question-encoder)
-* [dpr-ctx_encoder single nq base](https://huggingface.co/facebook/dpr-ctx_encoder-single-nq-base)
-* [dpr-ctx_encoder multiset base](https://huggingface.co/facebook/dpr-ctx_encoder-multiset-base)
-* [dpr-question_encoder single nq base](https://huggingface.co/facebook/dpr-question_encoder-single-nq-base)
-* [dpr-question_encoder multiset base](https://huggingface.co/facebook/dpr-question_encoder-multiset-base)
-
-
-## Third party text classification models
-
-* [BERT base uncased emotion](https://huggingface.co/nateraw/bert-base-uncased-emotion)
-* [DehateBERT mono english](https://huggingface.co/Hate-speech-CNERG/dehatebert-mono-english)
-* [DistilBERT base uncased emotion](https://huggingface.co/bhadresh-savani/distilbert-base-uncased-emotion)
-* [DistilBERT base uncased finetuned SST-2](https://huggingface.co/distilbert-base-uncased-finetuned-sst-2-english)
-* [FinBERT](https://huggingface.co/ProsusAI/finbert)
-* [Twitter roBERTa base for Sentiment Analysis](https://huggingface.co/cardiffnlp/twitter-roberta-base-sentiment)
-
-
-## Third party zero-shot text classification models
-
-* [BART large mnli](https://huggingface.co/facebook/bart-large-mnli)
-* [DistilBERT base model (uncased)](https://huggingface.co/typeform/distilbert-base-uncased-mnli)
-* [**DistilBart MNLI**](https://huggingface.co/valhalla/distilbart-mnli-12-6)
-* [MobileBERT: a Compact Task-Agnostic BERT for Resource-Limited Devices](https://huggingface.co/typeform/mobilebert-uncased-mnli)
-* [NLI DistilRoBERTa base](https://huggingface.co/cross-encoder/nli-distilroberta-base)
-* [NLI RoBERTa base](https://huggingface.co/cross-encoder/nli-roberta-base)
-* [SqueezeBERT](https://huggingface.co/typeform/squeezebert-mnli)
-
-## Expected model output
-
-Models used for each NLP task type must output tensors of a specific format to
-be used in the Elasticsearch NLP pipelines.
-
-Here are the expected outputs for each task type.
-
-### Fill mask expected model output
-
-Fill mask is a specific kind of token classification; it is the base training
-task of many transformer models.
-
-For the Elastic stack's fill mask NLP task to understand the model output, it
-must have a specific format. It needs to
-be a float tensor with
-`shape(, , )`.
-
-Here is an example with a single sequence `"The capital of [MASK] is Paris"` and
-with vocabulary `["The", "capital", "of", "is", "Paris", "France", "[MASK]"]`.
-
-Should output:
-
-```
- [
- [
- [ 0, 0, 0, 0, 0, 0, 0 ], // The
- [ 0, 0, 0, 0, 0, 0, 0 ], // capital
- [ 0, 0, 0, 0, 0, 0, 0 ], // of
- [ 0.01, 0.01, 0.3, 0.01, 0.2, 1.2, 0.1 ], // [MASK]
- [ 0, 0, 0, 0, 0, 0, 0 ], // is
- [ 0, 0, 0, 0, 0, 0, 0 ] // Paris
- ]
-]
-```
-
-The predicted value here for `[MASK]` is `"France"` with a score of 1.2.
-
-### Named entity recognition expected model output
-
-Named entity recognition is a specific token classification task. Each token in
-the sequence is scored related to a specific set of classification labels. For
-the Elastic Stack, we use Inside-Outside-Beginning (IOB) tagging. Elastic supports any NER entities
-as long as they are IOB tagged. The default values are:
-"O", "B_MISC", "I_MISC", "B_PER", "I_PER", "B_ORG", "I_ORG", "B_LOC", "I_LOC".
-
-The `"O"` entity label indicates that the current token is outside any entity.
-`"I"` indicates that the token is inside an entity.
-`"B"` indicates the beginning of an entity.
-`"MISC"` is a miscellaneous entity.
-`"LOC"` is a location.
-`"PER"` is a person.
-`"ORG"` is an organization.
-
-The response format must be a float tensor with
-`shape(, , )`.
-
-Here is an example with a single sequence `"Waldo is in Paris"`:
-
-```
- [
- [
-// "O", "B_MISC", "I_MISC", "B_PER", "I_PER", "B_ORG", "I_ORG", "B_LOC", "I_LOC"
- [ 0, 0, 0, 0.4, 0.5, 0, 0.1, 0, 0 ], // Waldo
- [ 1, 0, 0, 0, 0, 0, 0, 0, 0 ], // is
- [ 1, 0, 0, 0, 0, 0, 0, 0, 0 ], // in
- [ 0, 0, 0, 0, 0, 0, 0, 0, 1.0 ] // Paris
- ]
-]
-```
-
-### Text embedding expected model output
-
-Text embedding allows for semantic embedding of text for dense information
-retrieval.
-
-The output of the model must be the specific embedding directly without any
-additional pooling.
-
-Eland does this wrapping for the aforementioned models. But if supplying your
-own, the model must output the embedding for each inferred sequence.
-
-### Text classification expected model output
-
-With text classification (for example, in tasks like sentiment analysis), the
-entire sequence is classified. The output of the model must be a float tensor
-with `shape(, )`.
-
-Here is an example with two sequences for a binary classification model of
-"happy" and "sad":
-
-```
- [
- [
-// happy, sad
- [ 0, 1], // first sequence
- [ 1, 0] // second sequence
- ]
-]
-```
-
-### Zero-shot text classification expected model output
-
-Zero-shot text classification allows text to be classified for arbitrary labels
-not necessarily part of the original training. Each sequence is combined with
-the label given some hypothesis template. The model then scores each of these
-combinations according to `[entailment, neutral, contradiction]`. The output of
-the model must be a float tensor with
-`shape(, , 3)`.
-
-Here is an example with a single sequence classified against 4 labels:
-
-```
- [
- [
-// entailment, neutral, contradiction
- [ 0.5, 0.1, 0.4], // first label
- [ 0, 0, 1], // second label
- [ 1, 0, 0], // third label
- [ 0.7, 0.2, 0.1] // fourth label
- ]
-]
-```
\ No newline at end of file
diff --git a/serverless/pages/explore-your-data-ml-nlp-ner-example.mdx b/serverless/pages/explore-your-data-ml-nlp-ner-example.mdx
deleted file mode 100644
index bb994c51..00000000
--- a/serverless/pages/explore-your-data-ml-nlp-ner-example.mdx
+++ /dev/null
@@ -1,312 +0,0 @@
----
-# slug: /serverless/elasticsearch/explore-your-data-ml-nlp/examples/ner
-title: How to deploy named entity recognition
-description: Description to be written
-tags: []
----
-
-
-You can use these instructions to deploy a
-named entity recognition (NER)
-model in ((es)), test the model, and add it to an ((infer)) ingest pipeline. The
-model that is used in the example is publicly available on
-[HuggingFace](https://huggingface.co/).
-
-## Requirements
-
-To follow along the process on this page, you must have:
-
-* The [appropriate subscription](((subscriptions))) level or the free trial period
- activated.
-
-* [Docker](https://docs.docker.com/get-docker/) installed.
-
-## Deploy a NER model
-
-You can use the [Eland client](((eland-docs))) to install the ((nlp)) model.
-Eland commands can be run in Docker. First, you need to clone the Eland
-repository then create a Docker image of Eland:
-
-```shell
-git clone git@github.com:elastic/eland.git
-cd eland
-docker build -t elastic/eland .
-```
-
-After the script finishes, your Eland Docker client is ready to use.
-
-Select a NER model from the
-third-party model reference list
-This example uses an
-[uncased NER model](https://huggingface.co/elastic/distilbert-base-uncased-finetuned-conll03-english).
-
-Install the model by running the `eland_import_model_hub` command in the Docker
-image:
-
-```shell
-docker run -it --rm elastic/eland \
- eland_import_hub_model \
- --cloud-id $CLOUD_ID \
- -u -p \
- --hub-model-id elastic/distilbert-base-uncased-finetuned-conll03-english \
- --task-type ner \
- --start
-
-```
-
-You need to provide an administrator username and its password and replace the
-`$CLOUD_ID` with the ID of your Cloud deployment. This Cloud ID can be copied
-from the deployments page on your Cloud website.
-
-Since the `--start` option is used at the end of the Eland import command,
-((es)) deploys the model ready to use. If you have multiple models and want to
-select which model to deploy, you can use the **Model Management** page to
-manage the starting and stopping of models.
-
-Go to the **Trained Models** page and synchronize your trained models. A warning
-message is displayed at the top of the page that says
-_"ML job and trained model synchronization required"_. Follow the link to
-_"Synchronize your jobs and trained models."_ Then click **Synchronize**. You
-can also wait for the automatic synchronization that occurs in every hour, or
-use the [sync ((ml)) objects API](((kibana-ref))/ml-sync.html).
-
-## Test the NER model
-
-Deployed models can be evaluated on the **Trained Models** page by selecting the
-**Test model** action for the respective model.
-
-
-
-
-
-You can also evaluate your models by using the
-[_infer API](((ref))/infer-trained-model-deployment.html). In the following
-request, `text_field` is the field name where the model expects to find the
-input, as defined in the model configuration. By default, if the model was
-uploaded via Eland, the input field is `text_field`.
-
-```js
-POST _ml/trained_models/elastic__distilbert-base-uncased-finetuned-conll03-english/_infer
-{
- "docs": [
- {
- "text_field": "Elastic is headquartered in Mountain View, California."
- }
- ]
-}
-```
-
-The API returns a response similar to the following:
-
-```js
-{
- "inference_results": [
- {
- "predicted_value": "[Elastic](ORG&Elastic) is headquartered in [Mountain View](LOC&Mountain+View), [California](LOC&California).",
- "entities": [
- {
- "entity": "elastic",
- "class_name": "ORG",
- "class_probability": 0.9958921231805256,
- "start_pos": 0,
- "end_pos": 7
- },
- {
- "entity": "mountain view",
- "class_name": "LOC",
- "class_probability": 0.9844731508992688,
- "start_pos": 28,
- "end_pos": 41
- },
- {
- "entity": "california",
- "class_name": "LOC",
- "class_probability": 0.9972361009811214,
- "start_pos": 43,
- "end_pos": 53
- }
- ]
- }
- ]
-}
-```
-{/* NOTCONSOLE */}
-
-
-
-Using the example text "Elastic is headquartered in Mountain View, California.",
-the model finds three entities: an organization "Elastic", and two locations
-"Mountain View" and "California".
-
-
-## Add the NER model to an ((infer)) ingest pipeline
-
-You can perform bulk ((infer)) on documents as they are ingested by using an
-[((infer)) processor](((ref))/inference-processor.html) in your ingest pipeline.
-The novel _Les Misérables_ by Victor Hugo is used as an example for ((infer)) in
-the following example.
-[Download](https://github.com/elastic/stack-docs/blob/8.5/docs/en/stack/ml/nlp/data/les-miserables-nd.json)
-the novel text split by paragraph as a JSON file, then upload it by using the
-[Data Visualizer](((kibana-ref))/connect-to-elasticsearch.html#upload-data-kibana).
-Give the new index the name `les-miserables` when uploading the file.
-
-Now create an ingest pipeline either in the
-**Pipeline** page or by using the API:
-
-```js
-PUT _ingest/pipeline/ner
-{
- "description": "NER pipeline",
- "processors": [
- {
- "inference": {
- "model_id": "elastic__distilbert-base-uncased-finetuned-conll03-english",
- "target_field": "ml.ner",
- "field_map": {
- "paragraph": "text_field"
- }
- }
- },
- {
- "script": {
- "lang": "painless",
- "if": "return ctx['ml']['ner'].containsKey('entities')",
- "source": "Map tags = new HashMap(); for (item in ctx['ml']['ner']['entities']) { if (!tags.containsKey(item.class_name)) tags[item.class_name] = new HashSet(); tags[item.class_name].add(item.entity);} ctx['tags'] = tags;"
- }
- }
- ],
- "on_failure": [
- {
- "set": {
- "description": "Index document to 'failed-'",
- "field": "_index",
- "value": "failed-{{{ _index }}}"
- }
- },
- {
- "set": {
- "description": "Set error message",
- "field": "ingest.failure",
- "value": "{{_ingest.on_failure_message}}"
- }
- }
- ]
-}
-```
-
-The `field_map` object of the `inference` processor maps the `paragraph` field
-in the _Les Misérables_ documents to `text_field` (the name of the
-field the model is configured to use). The `target_field` is the name of the
-field to write the inference results to.
-
-The `script` processor pulls out the entities and groups them by type. The end
-result is lists of people, locations, and organizations detected in the input
-text. This painless script enables you to build visualizations from the fields
-that are created.
-
-The purpose of the `on_failure` clause is to record errors. It sets the `_index`
-meta field to a new value, and the document is now stored there. It also sets a
-new field `ingest.failure` and the error message is written to this field.
-((infer-cap)) can fail for a number of easily fixable reasons. Perhaps the model
-has not been deployed, or the input field is missing in some of the source
-documents. By redirecting the failed documents to another index and setting the
-error message, those failed inferences are not lost and can be reviewed later.
-When the errors are fixed, reindex from the failed index to recover the
-unsuccessful requests.
-
-Ingest the text of the novel - the index `les-miserables` - through the pipeline
-you created:
-
-```js
-POST _reindex
-{
- "source": {
- "index": "les-miserables",
- "size": 50 [^1]
- },
- "dest": {
- "index": "les-miserables-infer",
- "pipeline": "ner"
- }
-}
-```
-[^1]: The default batch size for reindexing is 1000. Reducing `size` to a
-smaller number makes the update of the reindexing process quicker which enables
-you to follow the progress closely and detect errors early.
-
-Take a random paragraph from the source document as an example:
-
-```js
-{
- "paragraph": "Father Gillenormand did not do it intentionally, but inattention to proper names was an aristocratic habit of his.",
- "line": 12700
-}
-```
-
-After the text is ingested through the NER pipeline, find the resulting document
-stored in ((es)):
-
-```js
-GET /les-miserables-infer/_search
-{
- "query": {
- "term": {
- "line": 12700
- }
- }
-}
-```
-
-The request returns the document marked up with one identified person:
-
-```js
-(...)
-"paragraph": "Father Gillenormand did not do it intentionally, but inattention to proper names was an aristocratic habit of his.",
- "@timestamp": "2020-01-01T17:38:25.000+01:00",
- "line": 12700,
- "ml": {
- "ner": {
- "predicted_value": "Father [Gillenormand](PER&Gillenormand) did not do it intentionally, but inattention to proper names was an aristocratic habit of his.",
- "entities": [
- {
- "entity": "gillenormand",
- "class_name": "PER",
- "class_probability": 0.9452480789333386,
- "start_pos": 7,
- "end_pos": 19
- }
- ],
- "model_id": "elastic__distilbert-base-uncased-finetuned-conll03-english"
- }
- },
- "tags": {
- "PER": [
- "gillenormand"
- ]
- }
-(...)
-```
-
-
-## Visualize results
-
-You can create a tag cloud to visualize your data processed by the ((infer))
-pipeline. A tag cloud is a visualization that scales words by the frequency at
-which they occur. It is a handy tool for viewing the entities found in the data.
-
-Open **Index management** → **((data-sources-cap))**, and create a new
-((data-source)) from the `les-miserables-infer` index pattern.
-
-Open **Dashboard** and create a new dashboard. Select the
-**Aggregation based-type → Tag cloud** visualization. Choose the new
-((data-source)) as the source.
-
-Add a new bucket with a term aggregation, select the `tags.PER.keyword` field,
-and increase the size to 20.
-
-Optionally, adjust the time selector to cover the data points in the
-((data-source)) if you selected a time field when creating it.
-
-Update and save the visualization.
-
-
\ No newline at end of file
diff --git a/serverless/pages/explore-your-data-ml-nlp-ootb-models.mdx b/serverless/pages/explore-your-data-ml-nlp-ootb-models.mdx
deleted file mode 100644
index 0485a3af..00000000
--- a/serverless/pages/explore-your-data-ml-nlp-ootb-models.mdx
+++ /dev/null
@@ -1,13 +0,0 @@
----
-# slug: /serverless/elasticsearch/explore-your-data-ml-nlp/elastic-models
-title: Elastic trained models
-description: Models trained and provided by Elastic
-tags: [ 'serverless', 'elasticsearch', 'tbd' ]
----
-
-
-You can use models that are trained and provided by Elastic that are available
-within the ((stack)) with a click of a button.
-
-* ELSER – Elastic Learned Sparse EncodeR
-* Language identification
\ No newline at end of file
diff --git a/serverless/pages/explore-your-data-ml-nlp-search-compare.mdx b/serverless/pages/explore-your-data-ml-nlp-search-compare.mdx
deleted file mode 100644
index f6b32e7e..00000000
--- a/serverless/pages/explore-your-data-ml-nlp-search-compare.mdx
+++ /dev/null
@@ -1,90 +0,0 @@
----
-# slug: /serverless/elasticsearch/explore-your-data-ml-nlp/search-compare-text
-title: Search and compare text
-description: NLP tasks for generate embeddings which can be used to search in text or compare different peieces of text.
-tags: [ 'serverless', 'elasticsearch', 'tbd' ]
----
-
-
-The ((stack-ml-features)) can generate embeddings, which you can use to search in
-unstructured text or compare different pieces of text.
-
-* Text embedding
-* Text similarity
-
-
-## Text embedding
-
-Text embedding is a task which produces a mathematical representation of text
-called an embedding. The ((ml)) model turns the text into an array of numerical
-values (also known as a _vector_). Pieces of content with similar meaning have
-similar representations. This means it is possible to determine whether
-different pieces of text are either semantically similar, different, or even
-opposite by using a mathematical similarity function.
-
-This task is responsible for producing only the embedding. When the
-embedding is created, it can be stored in a dense_vector field and used at
-search time. For example, you can use these vectors in a
-k-nearest neighbor (kNN) search to achieve semantic search capabilities.
-
-The following is an example of producing a text embedding:
-
-```js
-{
- docs: [{"text_field": "The quick brown fox jumps over the lazy dog."}]
-}
-...
-```
-{/* NOTCONSOLE */}
-
-The task returns the following result:
-
-```js
-...
-{
- "predicted_value": [0.293478, -0.23845, ..., 1.34589e2, 0.119376]
- ...
-}
-...
-```
-{/* NOTCONSOLE */}
-
-
-## Text similarity
-
-The text similarity task estimates how similar two pieces of text are to each
-other and expresses the similarity in a numeric value. This is commonly referred
-to as cross-encoding. This task is useful for ranking document text when
-comparing it to another provided text input.
-
-You can provide multiple strings of text to compare to another text input
-sequence. Each string is compared to the given text sequence at inference time
-and a prediction of similarity is calculated for every string of text.
-
-```js
-{
- "docs":[{ "text_field": "Berlin has a population of 3,520,031 registered inhabitants in an area of 891.82 square kilometers."}, {"text_field": "New York City is famous for the Metropolitan Museum of Art."}],
- "inference_config": {
- "text_similarity": {
- "text": "How many people live in Berlin?"
- }
- }
-}
-```
-{/* NOTCONSOLE */}
-
-In the example above, every string in the `docs` array is compared individually
-to the text provided in the `text_similarity`.`text` field and a predicted
-similarity is calculated for both as the API response shows:
-
-```js
-...
-{
- "predicted_value": 7.235751628875732
-},
-{
- "predicted_value": -11.562295913696289
-}
-...
-```
-{/* NOTCONSOLE */}
\ No newline at end of file
diff --git a/serverless/pages/explore-your-data-ml-nlp-select-model.mdx b/serverless/pages/explore-your-data-ml-nlp-select-model.mdx
deleted file mode 100644
index 03465460..00000000
--- a/serverless/pages/explore-your-data-ml-nlp-select-model.mdx
+++ /dev/null
@@ -1,26 +0,0 @@
----
-# slug: /serverless/elasticsearch/explore-your-data-ml-nlp/deploy-trained-models/select-model
-title: Select a trained model
-# description: Description to be written
-tags: [ 'serverless', 'elasticsearch', 'tbd' ]
----
-
-
-Per the
-Overview,
-there are multiple ways that you can use NLP features within the ((stack)).
-After you determine which type of NLP task you want to perform, you must choose
-an appropriate trained model.
-
-The simplest method is to use a model that has already been fine-tuned for the
-type of analysis that you want to perform. For example, there are models and
-data sets available for specific NLP tasks on
-[Hugging Face](https://huggingface.co/models). These instructions assume you're
-using one of those models and do not describe how to create new models. For the
-current list of supported model architectures, refer to
-Compatible third party NLP models.
-
-If you choose to perform ((lang-ident)) by using the `lang_ident_model_1` that is
-provided in the cluster, no further steps are required to import or deploy the
-model. You can skip to using the model in
-ingestion pipelines.
\ No newline at end of file
diff --git a/serverless/pages/explore-your-data-ml-nlp-test-inference.mdx b/serverless/pages/explore-your-data-ml-nlp-test-inference.mdx
deleted file mode 100644
index 2ce12862..00000000
--- a/serverless/pages/explore-your-data-ml-nlp-test-inference.mdx
+++ /dev/null
@@ -1,63 +0,0 @@
----
-# slug: /serverless/elasticsearch/explore-your-data-ml-nlp/deploy-trained-models/try-it-out
-title: Try it out
-description: You can import trained models into your cluster and configure them for specific NLP tasks.
-tags: [ 'serverless', 'elasticsearch', 'tbd' ]
----
-
-
-When the model is deployed on at least one node in the cluster, you can begin to
-perform inference. _((infer-cap))_ is a ((ml)) feature that enables you to use
-your trained models to perform NLP tasks (such as text extraction,
-classification, or embeddings) on incoming data.
-
-The simplest method to test your model against new data is to use the
-**Test model** action in ((kib)). You can either provide some input text or use a
-field of an existing index in your cluster to test the model:
-
-
-
-Alternatively, you can use the
-[infer trained model API](((ref))/infer-trained-model.html).
-For example, to try a named entity recognition task, provide some sample text:
-
-```console
-POST /_ml/trained_models/elastic__distilbert-base-cased-finetuned-conll03-english/_infer
-{
- "docs":[{"text_field": "Sasha bought 300 shares of Acme Corp in 2022."}]
-}
-```
-{/* TEST[skip:TBD] */}
-
-In this example, the response contains the annotated text output and the
-recognized entities:
-
-```console-result
-{
- "inference_results" : [
- {
- "predicted_value" : "[Sasha](PER&Sasha) bought 300 shares of [Acme Corp](ORG&Acme+Corp) in 2022.",
- "entities" : [
- {
- "entity" : "Sasha",
- "class_name" : "PER",
- "class_probability" : 0.9953193407987492,
- "start_pos" : 0,
- "end_pos" : 5
- },
- {
- "entity" : "Acme Corp",
- "class_name" : "ORG",
- "class_probability" : 0.9996392198381716,
- "start_pos" : 27,
- "end_pos" : 36
- }
- ]
- }
- ]
-}
-```
-{/* NOTCONSOLE */}
-
-If you are satisfied with the results, you can add these NLP tasks in your
-ingestion pipelines.
\ No newline at end of file
diff --git a/serverless/pages/explore-your-data-ml-nlp-text-embedding-example.mdx b/serverless/pages/explore-your-data-ml-nlp-text-embedding-example.mdx
deleted file mode 100644
index 40911a14..00000000
--- a/serverless/pages/explore-your-data-ml-nlp-text-embedding-example.mdx
+++ /dev/null
@@ -1,333 +0,0 @@
----
-# slug: /serverless/elasticsearch/explore-your-data-ml-nlp/examples/text-embedding-vector-search
-title: How to deploy a text embedding model and use it for semantic search
-description: Description to be written
-tags: []
----
-
-
-You can use these instructions to deploy a
-text embedding
-model in ((es)), test the model, and add it to an ((infer)) ingest pipeline. It
-enables you to generate vector representations of text and perform vector
-similarity search on the generated vectors. The model that is used in the
-example is publicly available on [HuggingFace](https://huggingface.co/).
-
-The example uses a public data set from the
-[MS MARCO Passage Ranking Task](https://microsoft.github.io/msmarco/#ranking). It
-consists of real questions from the Microsoft Bing search engine and human
-generated answers for them. The example works with a sample of this data set,
-uses a model to produce text embeddings, and then runs vector search on it.
-
-## Requirements
-
-To follow along the process on this page, you must have:
-
-* The [appropriate subscription](((subscriptions))) level or the free trial period
- activated.
-
-* [Docker](https://docs.docker.com/get-docker/) installed.
-
-## Deploy a text embedding model
-
-You can use the [Eland client](((eland-docs))) to install the ((nlp)) model.
-Eland commands can be run in Docker. First, you need to clone the Eland
-repository then create a Docker image of Eland:
-
-```shell
-git clone git@github.com:elastic/eland.git
-cd eland
-docker build -t elastic/eland .
-```
-
-After the script finishes, your Eland Docker client is ready to use.
-
-Select a text embedding model from the
-third-party model reference list
-This example uses the
-[msmarco-MiniLM-L-12-v3](https://huggingface.co/sentence-transformers/msmarco-MiniLM-L-12-v3)
-sentence-transformer model.
-
-Install the model by running the `eland_import_model_hub` command in the Docker
-image:
-
-```shell
-docker run -it --rm elastic/eland \
- eland_import_hub_model \
- --cloud-id $CLOUD_ID \
- -u -p \
- --hub-model-id sentence-transformers/msmarco-MiniLM-L-12-v3 \
- --task-type text_embedding \
- --start
-```
-
-You need to provide an administrator username and password and replace the
-`$CLOUD_ID` with the ID of your Cloud deployment. This Cloud ID can be copied
-from the deployments page on your Cloud website.
-
-Since the `--start` option is used at the end of the Eland import command,
-((es)) deploys the model ready to use. If you have multiple models and want to
-select which model to deploy, you can use the **Model Management** page to
-manage the starting and stopping of models.
-
-Go to the **Trained Models** page and synchronize your trained models. A warning
-message is displayed at the top of the page that says
-_"ML job and trained model synchronization required"_. Follow the link to
-_"Synchronize your jobs and trained models."_ Then click **Synchronize**. You
-can also wait for the automatic synchronization that occurs in every hour, or
-use the [sync ((ml)) objects API](((kibana-ref))/ml-sync.html).
-
-
-## Test the text embedding model
-
-Deployed models can be evaluated on the **Trained Models** page by selecting the
-**Test model** action for the respective model.
-
-
-
-
-
-You can also evaluate your models by using the
-[_infer API](((ref))/infer-trained-model-deployment.html). In the following
-request, `text_field` is the field name where the model expects to find the
-input, as defined in the model configuration. By default, if the model was
-uploaded via Eland, the input field is `text_field`.
-
-```js
-POST /_ml/trained_models/sentence-transformers__msmarco-minilm-l-12-v3/_infer
-{
- "docs": {
- "text_field": "How is the weather in Jamaica?"
- }
-}
-```
-
-The API returns a response similar to the following:
-
-```js
-{
- "inference_results": [
- {
- "predicted_value": [
- 0.39521875977516174,
- -0.3263707458972931,
- 0.26809820532798767,
- 0.30127981305122375,
- 0.502890408039093,
- ...
- ]
- }
- ]
-}
-```
-{/* NOTCONSOLE */}
-
-
-
-The result is the predicted dense vector transformed from the example text.
-
-
-## Load data
-
-In this step, you load the data that you later use in an ingest pipeline to get
-the embeddings.
-
-The data set `msmarco-passagetest2019-top1000` is a subset of the MS MARCO
-Passage Ranking data set used in the testing stage of the 2019 TREC Deep
-Learning Track. It contains 200 queries and for each query a list of relevant
-text passages extracted by a simple information retrieval (IR) system. From that
-data set, all unique passages with their IDs have been extracted and put into a
-[tsv file](https://github.com/elastic/stack-docs/blob/8.5/docs/en/stack/ml/nlp/data/msmarco-passagetest2019-unique.tsv),
-totaling 182469 passages. In the following, this file is used as the example
-data set.
-
-Upload the file by using the
-[Data Visualizer](((kibana-ref))/connect-to-elasticsearch.html#upload-data-kibana).
-Name the first column `id` and the second one `text`. The index name is
-`collection`. After the upload is done, you can see an index named `collection`
-with 182469 documents.
-
-
-
-
-## Add the text embedding model to an ((infer)) ingest pipeline
-
-Process the initial data with an
-[((infer)) processor](((ref))/inference-processor.html). It adds an embedding for each
-passage. For this, create a text embedding ingest pipeline and then reindex the
-initial data with this pipeline.
-
-Now create an ingest pipeline either in the
-[((stack-manage-app)) UI](((ml-docs))/ml-nlp-inference.html#ml-nlp-inference-processor)
-or by using the API:
-
-```js
-PUT _ingest/pipeline/text-embeddings
-{
- "description": "Text embedding pipeline",
- "processors": [
- {
- "inference": {
- "model_id": "sentence-transformers__msmarco-minilm-l-12-v3",
- "target_field": "text_embedding",
- "field_map": {
- "text": "text_field"
- }
- }
- }
- ],
- "on_failure": [
- {
- "set": {
- "description": "Index document to 'failed-'",
- "field": "_index",
- "value": "failed-{{{_index}}}"
- }
- },
- {
- "set": {
- "description": "Set error message",
- "field": "ingest.failure",
- "value": "{{_ingest.on_failure_message}}"
- }
- }
- ]
-}
-```
-
-The passages are in a field named `text`. The `field_map` maps the text to the
-field `text_field` that the model expects. The `on_failure` handler is set to
-index failures into a different index.
-
-Before ingesting the data through the pipeline, create the mappings of the
-destination index, in particular for the field `text_embedding.predicted_value`
-where the ingest processor stores the embeddings. The `dense_vector` field must
-be configured with the same number of dimensions (`dims`) as the text embedding
-produced by the model. That value can be found in the `embedding_size` option in
-the model configuration either under the Trained Models page or in the response
-body of the [Get trained models API](((ref))/get-trained-models.html) call. The
-msmarco-MiniLM-L-12-v3 model has embedding_size of 384, so `dims` is set to 384.
-
-```js
-PUT collection-with-embeddings
-{
- "mappings": {
- "properties": {
- "text_embedding.predicted_value": {
- "type": "dense_vector",
- "dims": 384,
- "index": true,
- "similarity": "cosine"
- },
- "text": {
- "type": "text"
- }
- }
- }
-}
-```
-
-Create the text embeddings by reindexing the data to the
-`collection-with-embeddings` index through the ((infer)) pipeline. The ((infer))
-ingest processor inserts the embedding vector into each document.
-
-```js
-POST _reindex?wait_for_completion=false
-{
- "source": {
- "index": "collection",
- "size": 50 [^1]
- },
- "dest": {
- "index": "collection-with-embeddings",
- "pipeline": "text-embeddings"
- }
-}
-```
-[^1]: The default batch size for reindexing is 1000. Reducing `size` to a
-smaller number makes the update of the reindexing process quicker which enables
-you to follow the progress closely and detect errors early.
-
-The API call returns a task ID that can be used to monitor the progress:
-
-```js
-GET _tasks/
-```
-
-You can also open the model stat UI to follow the progress.
-
-
-
-After the reindexing is finished, the documents in the new index contain the
-((infer)) results – the vector embeddings.
-
-
-## Semantic search
-
-After the dataset has been enriched with vector embeddings, you can query the
-data using [semantic search](((ref))/knn-search.html). Pass a
-`query_vector_builder` to the k-nearest neighbor (kNN) vector search API, and
-provide the query text and the model you have used to create vector embeddings.
-This example searches for "How is the weather in Jamaica?":
-
-```js
-GET collection-with-embeddings/_search
-{
- "knn": {
- "field": "text_embedding.predicted_value",
- "query_vector_builder": {
- "text_embedding": {
- "model_id": "sentence-transformers__msmarco-minilm-l-12-v3",
- "model_text": "How is the weather in Jamaica?"
- }
- },
- "k": 10,
- "num_candidates": 100
- },
- "_source": [
- "id",
- "text"
- ]
-}
-```
-
-As a result, you receive the top 10 documents that are closest in meaning to the
-query from the `collection-with-embedings` index sorted by their proximity to
-the query:
-
-```js
-"hits" : [
- {
- "_index" : "collection-with-embeddings",
- "_id" : "47TPtn8BjSkJO8zzKq_o",
- "_score" : 0.94591534,
- "_source" : {
- "id" : 434125,
- "text" : "The climate in Jamaica is tropical and humid with warm to hot temperatures all year round. The average temperature in Jamaica is between 80 and 90 degrees Fahrenheit. Jamaican nights are considerably cooler than the days, and the mountain areas are cooler than the lower land throughout the year. Continue Reading."
- }
- },
- {
- "_index" : "collection-with-embeddings",
- "_id" : "3LTPtn8BjSkJO8zzKJO1",
- "_score" : 0.94536424,
- "_source" : {
- "id" : 4498474,
- "text" : "The climate in Jamaica is tropical and humid with warm to hot temperatures all year round. The average temperature in Jamaica is between 80 and 90 degrees Fahrenheit. Jamaican nights are considerably cooler than the days, and the mountain areas are cooler than the lower land throughout the year"
- }
- },
- {
- "_index" : "collection-with-embeddings",
- "_id" : "KrXPtn8BjSkJO8zzPbDW",
- "_score" : 0.9432083,
- "_source" : {
- "id" : 190804,
- "text" : "Quick Answer. The climate in Jamaica is tropical and humid with warm to hot temperatures all year round. The average temperature in Jamaica is between 80 and 90 degrees Fahrenheit. Jamaican nights are considerably cooler than the days, and the mountain areas are cooler than the lower land throughout the year. Continue Reading"
- }
- },
- (...)
-]
-```
-
-If you want to do a quick verification of the results, follow the steps of the
-_Quick verification_ section of
-[this blog post](((blog-ref))how-to-deploy-nlp-text-embeddings-and-vector-search#).
\ No newline at end of file
diff --git a/serverless/pages/explore-your-data-ml-nlp.mdx b/serverless/pages/explore-your-data-ml-nlp.mdx
deleted file mode 100644
index 14ed216e..00000000
--- a/serverless/pages/explore-your-data-ml-nlp.mdx
+++ /dev/null
@@ -1,35 +0,0 @@
----
-# slug: /serverless/elasticsearch/explore-your-data-ml-nlp
-title: Machine Learning - Natural Language Processing
-# description: Description to be written
-tags: [ 'serverless', 'elasticsearch', 'tbd' ]
----
-
-
-((nlp-cap)) (NLP) refers to the way in which we can use software to understand
-natural language in spoken word or written text.
-
-Classically, NLP was performed using linguistic rules, dictionaries, regular
-expressions, and ((ml)) for specific tasks such as automatic categorization or
-summarization of text. In recent years, however, deep learning techniques have
-taken over much of the NLP landscape. Deep learning capitalizes on the
-availability of large scale data sets, cheap computation, and techniques for
-learning at scale with less human involvement. Pre-trained language models that
-use a transformer architecture have been particularly successful. For example,
-BERT is a pre-trained language model that was released by Google in 2018. Since
-that time, it has become the inspiration for most of today’s modern NLP
-techniques. The ((stack)) ((ml)) features are structured around BERT and
-transformer models. These features support BERT’s tokenization scheme (called
-WordPiece) and transformer models that conform to the standard BERT model
-interface. For the current list of supported architectures, refer to
-Compatible third party NLP models.
-
-To incorporate transformer models and make predictions, ((es)) uses libtorch,
-which is an underlying native library for PyTorch. Trained models must be in a
-TorchScript representation for use with ((stack)) ((ml)) features.
-
-You can perform the following NLP operations:
-
-* Extract information
-* Classify text
-* Search and compare text
\ No newline at end of file
diff --git a/serverless/pages/explore-your-data-the-aggregations-api.mdx b/serverless/pages/explore-your-data-the-aggregations-api.mdx
deleted file mode 100644
index 76678ad6..00000000
--- a/serverless/pages/explore-your-data-the-aggregations-api.mdx
+++ /dev/null
@@ -1,377 +0,0 @@
----
-slug: /serverless/elasticsearch/explore-your-data-aggregations
-title: Aggregations
-description: Aggregate and summarize your ((es)) data.
-tags: [ 'serverless', 'elasticsearch', 'aggregations', 'reference' ]
----
-
-
-An aggregation summarizes your data as metrics, statistics, or other analytics.
-Aggregations help you answer questions like:
-
-* What's the average load time for my website?
-* Who are my most valuable customers based on transaction volume?
-* What would be considered a large file on my network?
-* How many products are in each product category?
-
-((es)) organizes aggregations into three categories:
-
-* [Metric](((ref))/search-aggregations-metrics.html) aggregations that calculate metrics,
- such as a sum or an average, from field values. Note that
- [scripted metric aggregations](((ref))/search-aggregations-metrics-scripted-metric-aggregation.html)
- are not available in serverless ((es)).
-
-* [Bucket](((ref))/search-aggregations-bucket.html) aggregations that
- group documents into buckets, also called bins, based on field values, ranges,
- or other criteria.
-
-* [Pipeline](((ref))/search-aggregations-pipeline.html) aggregations that take input from
- other aggregations instead of documents or fields.
-
-## Run an aggregation
-
-You can run aggregations as part of a search by specifying the search API's `aggs` parameter. The
-following search runs a [terms aggregation](((ref))/search-aggregations-bucket-terms-aggregation.html) on
-`my-field`:
-
-```bash
-curl "${ES_URL}/my-index/_search?pretty" \
--H "Authorization: ApiKey ${API_KEY}" \
--H "Content-Type: application/json" \
--d'
-{
- "aggs": {
- "my-agg-name": {
- "terms": {
- "field": "my-field"
- }
- }
- }
-}
-'
-```
-{/* TEST[setup:my_index] */}
-{/* TEST[s/my-field/http.request.method/] */}
-
-Aggregation results are in the response's `aggregations` object:
-
-{/* TESTRESPONSE[s/"took": 78/"took": "$body.took"/] */}
-{/* TESTRESPONSE[s/\.\.\.$/"took": "$body.took", "timed_out": false, "_shards": "$body._shards", /] */}
-{/* TESTRESPONSE[s/"hits": \[\.\.\.\]/"hits": "$body.hits.hits"/] */}
-{/* TESTRESPONSE[s/"buckets": \[\]/"buckets":\[\{"key":"get","doc_count":5\}\]/] */}
-```json
-{
- "took": 78,
- "timed_out": false,
- "_shards": {...},
- "hits": {...},
- "aggregations": {
- "my-agg-name": { [^1]
- "doc_count_error_upper_bound": 0,
- "sum_other_doc_count": 0,
- "buckets": [...]
- }
- }
-}
-```
-[^1]: Results for the `my-agg-name` aggregation.
-
-## Change an aggregation's scope
-
-Use the `query` parameter to limit the documents on which an aggregation runs:
-
-```bash
-curl "${ES_URL}/my-index/_search?pretty" \
--H "Authorization: ApiKey ${API_KEY}" \
--H "Content-Type: application/json" \
--d'
-{
- "query": {
- "range": {
- "@timestamp": {
- "gte": "now-1d/d",
- "lt": "now/d"
- }
- }
- },
- "aggs": {
- "my-agg-name": {
- "terms": {
- "field": "my-field"
- }
- }
- }
-}
-'
-```
-{/* TEST[setup:my_index] */}
-{/* TEST[s/my-field/http.request.method/] */}
-
-## Return only aggregation results
-
-By default, searches containing an aggregation return both search hits and
-aggregation results. To return only aggregation results, set `size` to `0`:
-
-```bash
-curl "${ES_URL}/my-index/_search?pretty" \
--H "Authorization: ApiKey ${API_KEY}" \
--H "Content-Type: application/json" \
--d'
-{
- "size": 0,
- "aggs": {
- "my-agg-name": {
- "terms": {
- "field": "my-field"
- }
- }
- }
-}
-'
-```
-{/* TEST[setup:my_index] */}
-{/* TEST[s/my-field/http.request.method/] */}
-
-## Run multiple aggregations
-
-You can specify multiple aggregations in the same request:
-
-```bash
-curl "${ES_URL}/my-index/_search?pretty" \
--H "Authorization: ApiKey ${API_KEY}" \
--H "Content-Type: application/json" \
--d'
-{
- "aggs": {
- "my-first-agg-name": {
- "terms": {
- "field": "my-field"
- }
- },
- "my-second-agg-name": {
- "avg": {
- "field": "my-other-field"
- }
- }
- }
-}
-'
-```
-{/* TEST[setup:my_index] */}
-{/* TEST[s/my-field/http.request.method/] */}
-{/* TEST[s/my-other-field/http.response.bytes/] */}
-
-## Run sub-aggregations
-
-Bucket aggregations support bucket or metric sub-aggregations. For example, a
-terms aggregation with an [avg](((ref))/search-aggregations-metrics-avg-aggregation.html)
-sub-aggregation calculates an average value for each bucket of documents. There
-is no level or depth limit for nesting sub-aggregations.
-
-```bash
-curl "${ES_URL}/my-index/_search?pretty" \
--H "Authorization: ApiKey ${API_KEY}" \
--H "Content-Type: application/json" \
--d'
-{
- "aggs": {
- "my-agg-name": {
- "terms": {
- "field": "my-field"
- },
- "aggs": {
- "my-sub-agg-name": {
- "avg": {
- "field": "my-other-field"
- }
- }
- }
- }
- }
-}
-'
-```
-{/* TEST[setup:my_index] */}
-{/* TEST[s/_search/_search?size=0/] */}
-{/* TEST[s/my-field/http.request.method/] */}
-{/* TEST[s/my-other-field/http.response.bytes/] */}
-
-The response nests sub-aggregation results under their parent aggregation:
-
-{/* TESTRESPONSE[s/\.\.\./"took": "$body.took", "timed_out": false, "_shards": "$body._shards", "hits": "$body.hits",/] */}
-{/* TESTRESPONSE[s/"key": "foo"/"key": "get"/] */}
-{/* TESTRESPONSE[s/"value": 75.0/"value": $body.aggregations.my-agg-name.buckets.0.my-sub-agg-name.value/] */}
-```json
-{
- ...
- "aggregations": {
- "my-agg-name": { [^1]
- "doc_count_error_upper_bound": 0,
- "sum_other_doc_count": 0,
- "buckets": [
- {
- "key": "foo",
- "doc_count": 5,
- "my-sub-agg-name": { [^2]
- "value": 75.0
- }
- }
- ]
- }
- }
-}
-```
-[^1]: Results for the parent aggregation, `my-agg-name`.
-[^2]: Results for `my-agg-name`'s sub-aggregation, `my-sub-agg-name`.
-
-## Add custom metadata
-
-Use the `meta` object to associate custom metadata with an aggregation:
-
-```bash
-curl "${ES_URL}/my-index/_search?pretty" \
--H "Authorization: ApiKey ${API_KEY}" \
--H "Content-Type: application/json" \
--d'
-{
- "aggs": {
- "my-agg-name": {
- "terms": {
- "field": "my-field"
- },
- "meta": {
- "my-metadata-field": "foo"
- }
- }
- }
-}
-'
-```
-
-{/* TEST[setup:my_index] */}
-{/* TEST[s/_search/_search?size=0/] */}
-
-The response returns the `meta` object in place:
-
-```json
-{
- ...
- "aggregations": {
- "my-agg-name": {
- "meta": {
- "my-metadata-field": "foo"
- },
- "doc_count_error_upper_bound": 0,
- "sum_other_doc_count": 0,
- "buckets": []
- }
- }
-}
-```
-{/* TESTRESPONSE[s/\.\.\./"took": "$body.took", "timed_out": false, "_shards": "$body._shards", "hits": "$body.hits",/] */}
-
-## Return the aggregation type
-
-By default, aggregation results include the aggregation's name but not its type.
-To return the aggregation type, use the `typed_keys` query parameter.
-
-```bash
-curl "${ES_URL}/my-index/_search?typed_keys&pretty" \
--H "Authorization: ApiKey ${API_KEY}" \
--H "Content-Type: application/json" \
--d'
-{
- "aggs": {
- "my-agg-name": {
- "histogram": {
- "field": "my-field",
- "interval": 1000
- }
- }
- }
-}
-'
-
-```
-{/* TEST[setup:my_index] */}
-{/* TEST[s/typed_keys/typed_keys&size=0/] */}
-{/* TEST[s/my-field/http.response.bytes/] */}
-
-The response returns the aggregation type as a prefix to the aggregation's name.
-
-
-Some aggregations return a different aggregation type from the
-type in the request. For example, the terms, [significant terms](((ref))/search-aggregations-bucket-significantterms-aggregation.html),
-and [percentiles](((ref))/search-aggregations-metrics-percentile-aggregation.html)
-aggregations return different aggregations types depending on the data type of
-the aggregated field.
-
-
-{/* TESTRESPONSE[s/\.\.\./"took": "$body.took", "timed_out": false, "_shards": "$body._shards", "hits": "$body.hits",/] */}
-{/* TESTRESPONSE[s/"buckets": \[\]/"buckets":\[\{"key":1070000.0,"doc_count":5\}\]/] */}
-```json
-{
- ...
- "aggregations": {
- "histogram#my-agg-name": { [^1]
- "buckets": []
- }
- }
-}
-```
-[^1]: The aggregation type, `histogram`, followed by a `#` separator and the aggregation's name, `my-agg-name`.
-
-## Use scripts in an aggregation
-
-When a field doesn't exactly match the aggregation you need, you
-should aggregate on a [runtime field](((ref))/runtime.html):
-
-```bash
-curl "${ES_URL}/my-index/_search?pretty" \
--H "Authorization: ApiKey ${API_KEY}" \
--H "Content-Type: application/json" \
--d'
-{
- "size": 0,
- "runtime_mappings": {
- "message.length": {
- "type": "long",
- "script": "emit(doc[\u0027message.keyword\u0027].value.length())"
- }
- },
- "aggs": {
- "message_length": {
- "histogram": {
- "interval": 10,
- "field": "message.length"
- }
- }
- }
-}
-'
-```
-
-Scripts calculate field values dynamically, which adds a little
-overhead to the aggregation. In addition to the time spent calculating,
-some aggregations like [`terms`](((ref))/search-aggregations-bucket-terms-aggregation.html)
-and [`filters`](((ref))/search-aggregations-bucket-filters-aggregation.html) can't use
-some of their optimizations with runtime fields. In total, performance costs
-for using a runtime field varies from aggregation to aggregation.
-
-## Aggregation caches
-
-For faster responses, ((es)) caches the results of frequently run aggregations in
-the [shard request cache](((ref))/shard-request-cache.html). To get cached results, use the
-same [`preference` string](((ref))/search-shard-routing.html#shard-and-node-preference) for each search. If you
-don't need search hits, set `size` to `0` to avoid
-filling the cache.
-
-((es)) routes searches with the same preference string to the same shards. If the
-shards' data doesn't change between searches, the shards return cached
-aggregation results.
-
-## Limits for `long` values
-
-When running aggregations, ((es)) uses [`double`](((ref))/number.html) values to hold and
-represent numeric data. As a result, aggregations on `long` numbers
-greater than 2^53 are approximate.
diff --git a/serverless/pages/explore-your-data-visualize-your-data-create-dashboards.mdx b/serverless/pages/explore-your-data-visualize-your-data-create-dashboards.mdx
deleted file mode 100644
index 6ce9701d..00000000
--- a/serverless/pages/explore-your-data-visualize-your-data-create-dashboards.mdx
+++ /dev/null
@@ -1,97 +0,0 @@
----
-slug: /serverless/elasticsearch/explore-your-data-dashboards
-title: Create dashboards
-description: Create dashboards to visualize and monitor your ((es)) data.
-tags: [ 'serverless', 'elasticsearch', 'dashboards', 'how to' ]
----
-
-
-Learn the most common way to create a dashboard from your own data. The tutorial will use sample data from the perspective of an analyst looking at website logs, but this type of dashboard works on any type of data.
-
-
-
-## Open the dashboard
-
-Begin with an empty dashboard, or open an existing dashboard.
-
-1. Open the main menu, then click **Dashboard**.
-
-1. On the **Dashboards** page, choose one of the following options:
-
-* To start with an empty dashboard, click **Create dashboard**.
-
- When you create a dashboard, you are automatically in edit mode and can make changes.
-
-* To open an existing dashboard, click the dashboard **Title** you want to open.
-
- When you open an existing dashboard, you are in view mode. To make changes, click **Edit** in the toolbar.
-
-## Add data and create a dashboard
-
-Add the sample web logs data, and create and set up the dashboard.
-
-1. On the **Dashboard** page, click **Add some sample data**.
-
-2. Click **Other sample data sets**.
-
-3. On the **Sample web logs** card, click **Add data**.
-
-Create the dashboard where you'll display the visualization panels.
-
-1. Open the main menu, then click **Dashboard**.
-
-2. Click **[Logs] Web Traffic**.
-
-By default some visualization panels have been created for you using the sample data. Go to to learn about the different visualizations.
-
-
-
-## Reset the dashboard
-
-To remove any changes you've made, reset the dashboard to the last saved changes.
-
-1. In the toolbar, click **Reset**.
-
-1. Click **Reset dashboard**.
-
-## Save dashboards
-
-When you've finished making changes to the dashboard, save it.
-
-1. In the toolbar, click **Save**.
-
-1. To exit **Edit** mode, click **Switch to view mode**.
-
-## Add dashboard settings
-
-When creating a new dashboard you can add the title, tags, design options, and more to the dashboard.
-
-1. In the toolbar, click **Settings**.
-
-2. On the **Dashboard settings** flyout, enter the **Title** and an optional **Description**.
-
-3. Add any applicable **Tags**.
-
-4. Specify the following settings:
-
-* **Store time with dashboard** — Saves the specified time filter.
-
-* **Use margins between panels** — Adds a margin of space between each panel.
-
-* **Show panel titles** — Displays the titles in the panel headers.
-
-* **Sync color palettes across panels** — Applies the same color palette to all panels on the dashboard.
-
-* **Sync cursor across panels** — When you hover your cursor over a panel, the cursor on all other related dashboard charts automatically appears.
-
-* **Sync tooltips across panels** — When you hover your cursor over a panel, the tooltips on all other related dashboard charts automatically appears.
-
-5. Click **Apply**.
-
-## Share dashboards
-
-To share the dashboard with a larger audience, click **Share** in the toolbar. For detailed information about the sharing options, refer to [Reporting](((kibana-ref))/reporting-getting-started.html).
-
-## Export dashboards
-
-To automate ((kib)), you can export dashboards as JSON using the [Export objects API](((kibana-ref))/saved-objects-api-export.html). It is important to export dashboards with all necessary references.
diff --git a/serverless/pages/explore-your-data-visualize-your-data-create-visualizations.mdx b/serverless/pages/explore-your-data-visualize-your-data-create-visualizations.mdx
deleted file mode 100644
index 715305a9..00000000
--- a/serverless/pages/explore-your-data-visualize-your-data-create-visualizations.mdx
+++ /dev/null
@@ -1,446 +0,0 @@
----
-slug: /serverless/elasticsearch/explore-your-data-visualizations
-title: Create visualizations
-description: Create charts, graphs, maps, and more from your ((es)) data.
-tags: [ 'serverless', 'elasticsearch', 'visualize', 'how to' ]
----
-
-
-Learn how to create some visualization panels to add to your dashboard.
-This tutorial uses the same web logs sample data from .
-
-## Open the visualization editor and get familiar with the data
-
-Once you have loaded the web logs sample data into your dashboard lets open the visualization editor, to ensure the correct fields appear.
-
-1. On the dashboard, click **Create visualization**.
-
-2. Make sure the **((kib)) Sample Data Logs** ((data-source)) appears.
-
-To create the visualizations in this tutorial, you'll use the following fields:
-
-* **Records**
-
-* **timestamp**
-
-* **bytes**
-
-* **clientip**
-
-* **referer.keyword**
-
-To see the most frequent values in a field, hover over the field name, then click *i*.
-
-## Create your first visualization
-
-Pick a field you want to analyze, such as **clientip**. To analyze only the **clientip** field, use the **Metric** visualization to display the field as a number.
-
-The only number function that you can use with **clientip** is **Unique count**, also referred to as cardinality, which approximates the number of unique values.
-
-1. Open the **Visualization type** dropdown, then select **Metric**.
-
-2. From the **Available fields** list, drag **clientip** to the workspace or layer pane.
-
- In the layer pane, **Unique count of clientip** appears because the editor automatically applies the **Unique count** function to the **clientip** field. **Unique count** is the only numeric function that works with IP addresses.
-
-3. In the layer pane, click **Unique count of clientip**.
-
- a. In the **Name** field, enter `Unique visitors`.
-
- b. Click **Close**.
-
-4. Click **Save and return**.
-
- **[No Title]** appears in the visualization panel header. Since the visualization has its own `Unique visitors` label, you do not need to add a panel title.
-
-## View a metric over time
-
-There are two shortcuts you can use to view metrics over time.
-When you drag a numeric field to the workspace, the visualization editor adds the default
-time field from the ((data-source)). When you use the **Date histogram** function, you can
-replace the time field by dragging the field to the workspace.
-
-To visualize the **bytes** field over time:
-
-1. On the dashboard, click **Create visualization**.
-
-2. From the **Available fields** list, drag **bytes** to the workspace.
-
- The visualization editor creates a bar chart with the **timestamp** and **Median of bytes** fields.
-
-3. To zoom in on the data, click and drag your cursor across the bars.
-
-To emphasize the change in **Median of bytes** over time, change the visualization type to **Line** with one of the following options:
-
-* In the **Suggestions**, click the line chart.
-* In the editor toolbar, open the **Visualization type** dropdown, then select **Line**.
-
-To increase the minimum time interval:
-
-1. In the layer pane, click **timestamp**.
-
-2. Change the **Minimum interval** to **1d**, then click **Close**.
-
- You can increase and decrease the minimum interval, but you are unable to decrease the interval below the configured **Advanced Settings**.
-
-To save space on the dashboard, hide the axis labels.
-
-1. Open the **Left axis** menu, then select **None** from the **Axis title** dropdown.
-
-2. Open the **Bottom axis** menu, then select **None** from the **Axis title** dropdown.
-
-3. Click **Save and return**
-
-Since you removed the axis labels, add a panel title:
-
-1. Open the panel menu, then select **Panel settings**.
-
-2. In the **Title** field, enter `Median of bytes`, then click **Apply**.
-
-## View the top values of a field
-
-Create a visualization that displays the most frequent values of **request.keyword** on your website, ranked by the unique visitors. To create the visualization, use **Top values of request.keyword** ranked by **Unique count of clientip**, instead of being ranked by **Count of records**.
-
-The **Top values** function ranks the unique values of a field by another function.
-The values are the most frequent when ranked by a **Count** function, and the largest when ranked by the **Sum** function.
-
-1. On the dashboard, click **Create visualization**.
-
-2. From the **Available fields** list, drag **clientip** to the **Vertical axis** field in the layer pane.
-
- The visualization editor automatically applies the **Unique count** function. If you drag **clientip** to the workspace, the editor adds the field to the incorrect axis.
-
-3. Drag **request.keyword** to the workspace.
-
- When you drag a text or IP address field to the workspace, the editor adds the **Top values** function ranked by **Count of records** to show the most frequent values.
-
-The chart labels are unable to display because the **request.keyword** field contains long text fields. You could use one of the **Suggestions**, but the suggestions also have issues with long text. The best way to display long text fields is with the **Table** visualization.
-
-1. Open the **Visualization type** dropdown, then select **Table**.
-
-2. In the layer pane, click **Top 5 values of request.keyword**.
-
- a. In the **Number of values** field, enter `10`.
-
- b. In the **Name** field, enter `Page URL`.
-
- c. Click **Close**.
-
-3. Click **Save and return**.
-
- Since the table columns are labeled, you do not need to add a panel title.
-
-## Compare a subset of documents to all documents
-
-Create a proportional visualization that helps you determine if your users transfer more bytes from documents under 10KB versus documents over 10KB.
-
-1. On the dashboard, click **Create visualization**.
-
-2. From the **Available fields** list, drag **bytes** to the **Vertical axis** field in the layer pane.
-
-3. In the layer pane, click **Median of bytes**.
-
-4. Click the **Sum** quick function, then click **Close**.
-
-5. From the **Available fields** list, drag **bytes** to the **Break down by** field in the layer pane.
-
-To select documents based on the number range of a field, use the **Intervals** function.
-When the ranges are non numeric, or the query requires multiple clauses, you could use the **Filters** function.
-
-Specify the file size ranges:
-
-1. In the layer pane, click **bytes**.
-
-2. Click **Create custom ranges**, enter the following in the **Ranges** field, then press Return:
-
-* **Ranges** — `0` -> `10240`
-
-* **Label** — `Below 10KB`
-
-3. Click **Add range**, enter the following, then press Return:
-
-* **Ranges** — `10240` -> `+∞`
-
-* **Label** — `Above 10KB`
-
-4. From the **Value format** dropdown, select **Bytes (1024)**, then click **Close**.
-
-To display the values as a percentage of the sum of all values, use the **Pie** chart.
-
-1. Open the **Visualization Type** dropdown, then select **Pie**.
-
-2. Click **Save and return**.
-
-Add a panel title:
-
-1. Open the panel menu, then select **Panel settings**.
-
-2. In the **Title** field, enter `Sum of bytes from large requests`, then click **Apply**.
-
-## View the distribution of a number field
-
-The distribution of a number can help you find patterns. For example, you can analyze the website traffic per hour to find the best time for routine maintenance.
-
-1. On the dashboard, click **Create visualization**.
-
-2. From the **Available fields** list, drag **bytes** to **Vertical axis** field in the layer pane.
-
-3. In the layer pane, click **Median of bytes**.
-
- a. Click the **Sum** quick function.
-
- b. In the **Name** field, enter `Transferred bytes`.
-
- c. From the **Value format** dropdown, select **Bytes (1024)**, then click **Close**.
-
-4. From the **Available fields** list, drag **hour_of_day** to **Horizontal axis** field in the layer pane.
-
-5. In the layer pane, click **hour_of_day**, then slide the **Intervals granularity** slider until the horizontal axis displays hourly intervals.
-
-6. Click **Save and return**.
-
-Add a panel title:
-
-1. Open the panel menu, then select **Panel settings**.
-
-2. In the **Title** field, enter `Website traffic`, then click **Apply**.
-
-## Create a multi-level chart
-
-**Table** and **Proportion** visualizations support multiple functions. For example, to create visualizations that break down the data by website traffic sources and user geography, apply the **Filters** and **Top values** functions.
-
-1. On the dashboard, click **Create visualization**.
-
-2. Open the **Visualization type** dropdown, then select **Treemap**.
-
-3. From the **Available fields** list, drag **Records** to the **Metric** field in the layer pane.
-
-4. In the layer pane, click **Add or drag-and-drop a field** for **Group by**.
-
-Create a filter for each website traffic source:
-
-1. Click **Filters**.
-
-2. Click **All records**, enter the following in the query bar, then press Return:
-
-* **KQL** — `referer : **facebook.com**`
-
-* **Label** — `Facebook`
-
-3. Click **Add a filter**, enter the following in the query bar, then press Return:
-
-* **KQL** — `referer : **twitter.com**`
-
-* **Label** — `Twitter`
-
-4. Click **Add a filter**, enter the following in the query bar, then press Return:
-
-* **KQL** — `NOT referer : **twitter.com** OR NOT referer: **facebook.com**`
-
-* **Label** — `Other`
-
-5. Click **Close**.
-
-Add the user geography grouping:
-
-1. From the **Available fields** list, drag **geo.srcdest** to the workspace.
-
-2. To change the **Group by** order, drag **Top 3 values of geo.srcdest** in the layer pane so that appears first.
-
-Remove the documents that do not match the filter criteria:
-
-1. In the layer pane, click **Top 3 values of geo.srcdest**.
-
-2. Click **Advanced**, deselect **Group other values as "Other"**, then click **Close**.
-
-3. Click **Save and return**.
-
-Add a panel title:
-
-1. Open the panel menu, then select **Panel settings**.
-
-2. In the **Title** field, enter `Page views by location and referrer`, then click **Apply**.
-
-## Visualization panels
-
-Visualization panels are how you display visualizations of your data and what make Kibana such a useful tool. Panels are designed to build interactive dashboards.
-
-### Create and add panels
-
-Create new panels, which can be accessed from the dashboard toolbar or the **Visualize Library**, or add panels that are saved in the **Visualize Library**, or search results from **Discover**.
-
-Panels added to the **Visualize Library** are available to all dashboards.
-
-To create panels from the dashboard:
-
-1. From the main menu, click **Dashboard** and select **[Logs] Web Traffic**.
-
-1. Click **Edit** then click **Create visualization**.
-
-1. From the **Available fields** drag and drop the data you want to visualize.
-
-1. Click **Save and return**.
-
-1. Click **Save** to add the new panel to your dashboard.
-
-To create panels from the **Visualize Library**:
-
-1. From the main menu, click **Visualize Library**.
-
-1. Click **Create visualization**, then select an editor from the options.
-
-1. Click **Save** once you have created your new visualization.
-
-1. In the modal, enter a **Title**, **Description**, and decide if you want to save the new panel to an existing dashboard, a new dashboard, or to the **Visualize Library**.
-
-1. Save the panel.
-
-To add existing panels from the **Visualize Library**:
-
-1. From the main menu, click **Dashboard** and select **[Logs] Web Traffic**.
-
-1. Click **Edit** then in the dashboard toolbar, click **Add from library**.
-
-1. Click the panel you want to add to the dashboard, then click *X*.
-
-### Save panels
-
-Consider where you want to save and add the panel in ((kib)).
-
-#### Save to the Visualize Library
-
-To use the panel on other dashboards, save the panel to the **Visualize Library**. When panels are saved in the **Visualize Library**, appears in the panel header.
-
-If you created the panel from the dashboard:
-
-1. Open the panel menu and click **More → Save to library**.
-
-1. Enter the **Title** and click **Save**.
-
-If you created the panel from the **Visualize Library**:
-
-1. In the editor, click **Save**.
-
-1. Under **Save visualization** enter a **Title**, **Description**, and decide if you want to save the new panel to an existing dashboard, a new dashboard, or to the **Visualize Library**.
-
-1. Click **Save and go to Dashboard**.
-
-1. Click **Save**.
-
-#### Save to the dashboard
-
-Return to the dashboard and add the panel without specifying the save options or adding the panel to the **Visualize Library**.
-
-If you created the panel from the dashboard:
-
-1. In the editor, click **Save and return**.
-
-1. Click **Save**.
-
-If you created the panel from the **Visualize Library**:
-
-1. Click **Save**.
-
-1. Under **Save visualization** enter a **Title**, **Description**, and decide if you want to save the new panel to an existing dashboard, a new dashboard, or to the **Visualize Library**.
-
-1. Click **Save and go to Dashboard**.
-
-1. Click **Save**.
-
-To add unsaved panels to the **Visualize Library**:
-
-1. Open the panel menu, then select **More → Save to library**.
-
-1. Enter the panel title, then click **Save**.
-
-### Arrange panels
-
-Compare the data in your panels side-by-side, organize panels by priority, resize the panels so they all appear on the dashboard without scrolling down, and more.
-
-In the toolbar, click **Edit**, then use the following options:
-
-* To move, click and hold the panel header, then drag to the new location.
-
-* To resize, click the resize control, then drag to the new dimensions.
-
-* To maximize to fullscreen, open the panel menu, then click **More → Maximize panel**.
-
-### Add text panels
-
-Add **Text** panels to your dashboard that display important information, instructions, and more. You create **Text** panels using [GitHub-flavored Markdown](https://github.github.com/gfm/) text.
-
-1. On the dashboard, click **Edit**.
-
-1. Click **Add panel** and select ** Text**.
-
-1. Check the rendered text, then click **Save and return**.
-
-1. To save the new text panel to your dashboard click **Save**.
-
-### Add image panels
-
-To personalize your dashboards, add your own logos and graphics with the **Image** panel. You can upload images from your computer, or add images from an external link.
-
-1. On the dashboard, click **Edit**.
-
-1. Click **Add panel** and select ** Image**.
-
-1. Use the editor to add an image.
-
-1. Click **Save**.
-
-1. To save the new image panel to your dashboard click **Save**.
-
-To manage your uploaded image files, open the main menu, then click **Management → Files**.
-
-
-
-When you export a dashboard, the uploaded image files are not exported.
-When importing a dashboard with an image panel, and the image file is unavailable, the image panel displays a `not found` warning. Such panels have to be fixed manually by re-uploading the image using the panel's image editor.
-
-
-
-
-
-### Edit panels
-
-To make changes to the panel, use the panel menu options.
-
-1. In the toolbar, click **Edit**.
-
-1. Open the panel menu, then use the following options:
-
-* **Edit Lens** — Opens **Lens** so you can make changes to the visualization.
-
-* **Edit visualization** — Opens the editor so you can make changes to the panel.
-
-* **Edit map** — Opens the editor so you can make changes to the map panel.
-
- The above options display in accordance to the type of visualization the panel is made up of.
-
-* **Edit Lens** — Opens aggregation-based visualizations in **Lens**.
-
-* **Clone panel** — Opens a copy of the panel on your dashboard.
-
-* **Panel settings** — Opens the **Panel settings** window to change the **title**, **description**, and **time range**.
-
-* **More → Inspect** — Opens an editor so you can view the data and the requests that collect that data.
-
-* **More → Explore data in Discover** — Opens that panels data in **Discover**.
-
-* **More → Save to library** — Saves the panel to the **Visualize Library**.
-
-* **More → Maximize panel** — Maximizes the panel to full screen.
-
-* **More → Download as CSV** — Downloads the data as a CSV file.
-
-* **More → Replace panel** — Opens the **Visualize Library** so you can select a new panel to replace the existing panel.
-
-* **More → Copy to dashboard** — Copy the panel to a different dashboard.
-
-* **More → Delete from dashboard** — Removes the panel from the dashboard.
-
-
-
-
-
diff --git a/serverless/pages/explore-your-data-visualize-your-data.mdx b/serverless/pages/explore-your-data-visualize-your-data.mdx
deleted file mode 100644
index 3b9fd042..00000000
--- a/serverless/pages/explore-your-data-visualize-your-data.mdx
+++ /dev/null
@@ -1,35 +0,0 @@
----
-slug: /serverless/elasticsearch/explore-your-data-visualize-your-data
-title: Visualize your data
-description: Build dynamic dashboards and visualizations for your ((es)) data.
-tags: ["serverless", "elasticsearch", "visualize", "how to"]
----
-
-
-The best way to understand your data is to visualize it.
-
-Elastic provides a wide range of pre-built dashboards for visualizing data from a variety of sources.
-These dashboards are loaded automatically when you install [Elastic integrations](https://www.elastic.co/docs/current/integrations).
-
-You can also create new dashboards and visualizations based on your data views to get a full picture of your data.
-
-In your ((es)) project, go to **Dashboards** to see existing dashboards or create your own.
-
-Notice you can filter the list of dashboards:
-
-* Use the text search field to filter by name or description.
-* Use the **Tags** menu to filter by tag. To create a new tag or edit existing tags, click **Manage tags**.
-* Click a dashboard's tags to toggle filtering for each tag.
-
-## Create new dashboards
-
-To create a new dashboard, click **Create dashboard** and begin adding visualizations.
-You can create charts, graphs, maps, tables, and other types of visualizations from your data, or you can add visualizations from the library.
-
-You can also add other types of panels — such as filters, links, and text — and add controls like time sliders.
-
-For more information about creating dashboards, refer to the [((kib)) documentation](((kibana-ref))/dashboard.html).
-
-
- The ((kib)) documentation is written for ((kib)) users, but the steps for serverless are very similar.
-
diff --git a/serverless/pages/explore-your-data.mdx b/serverless/pages/explore-your-data.mdx
deleted file mode 100644
index fb9597be..00000000
--- a/serverless/pages/explore-your-data.mdx
+++ /dev/null
@@ -1,14 +0,0 @@
----
-slug: /serverless/elasticsearch/explore-your-data
-title: Explore your data
-description: Turn ((es)) data into actionable insights with aggregations, visualizations, and alerts
-tags: [ 'serverless', 'elasticsearch', 'explore', 'overview' ]
----
-
-
-In addition to search, ((es3)) offers several options for analyzing and visualizing your data.
-
-- : Use the ((es)) REST API to summarize your data as metrics, statistics, or other analytics.
-- : Use the **Discover** UI to filter your data or learn about its structure.
-- : Build dynamic dashboards that visualize your data as charts, gauges, graphs, maps, and more.
-- : Create rules that trigger notifications based on your data.
diff --git a/serverless/pages/files.mdx b/serverless/pages/files.mdx
deleted file mode 100644
index 37eed9ac..00000000
--- a/serverless/pages/files.mdx
+++ /dev/null
@@ -1,15 +0,0 @@
----
-slug: /serverless/files
-title: ((files-app))
-description: Manage files that are stored in Elastic.
-tags: ["serverless", "Elasticsearch", "Observability", "Security"]
----
-
-
-This content applies to:
-
-Several ((serverless-full)) features let you upload files. For example, you can add files to or upload a logo to an **Image** panel in a .
-
-You can access these uploaded files in **((project-settings)) → ((manage-app)) → ((files-app))**.
-
-
diff --git a/serverless/pages/fleet-and-elastic-agent.mdx b/serverless/pages/fleet-and-elastic-agent.mdx
deleted file mode 100644
index 35109b81..00000000
--- a/serverless/pages/fleet-and-elastic-agent.mdx
+++ /dev/null
@@ -1,19 +0,0 @@
----
-slug: /serverless/fleet-and-elastic-agent
-title: Fleet and Elastic Agent
-description: Centrally manage your Elastic Agents in Fleet
-tags: [ 'serverless', 'ingest', 'fleet', 'elastic agent' ]
----
-
-
-This content applies to:
-
-((agent)) is a single, unified way to add monitoring for logs, metrics, and other types of data to a host.
-It can also protect hosts from security threats, query data from operating systems, forward data from remote services or hardware, and more.
-A single agent makes it easier and faster to deploy monitoring across your infrastructure.
-Each agent has a single policy you can update to add integrations for new data sources, security protections, and more.
-
-((fleet)) provides a web-based UI to centrally manage your ((agents)) and their policies.
-
-To learn more, refer to the [Fleet and Elastic Agent documentation](((fleet-guide))).
-
diff --git a/serverless/pages/general-developer-tools.mdx b/serverless/pages/general-developer-tools.mdx
deleted file mode 100644
index 551c0876..00000000
--- a/serverless/pages/general-developer-tools.mdx
+++ /dev/null
@@ -1,60 +0,0 @@
----
-slug: /serverless/devtools/developer-tools
-title: Developer tools
-description: Use our developer tools to interact with your data.
-tags: [ 'serverless', 'dev tools', 'overview' ]
----
-
-
-
-
-
-
- Console
- Interact with Elastic REST APIs.
-
-
-
-
-
-
-
- ((searchprofiler))
- Inspect and analyze your search queries.
-
-
-
-
-
-
-
- Grok Debugger
- Build and debug grok patterns before you use them in your data processing pipelines.
-
-
-
-
-
-
-
- Painless Lab
- Use an interactive code editor to test and debug Painless scripts in real time.
-
-
-
-
-
-
\ No newline at end of file
diff --git a/serverless/pages/get-started.mdx b/serverless/pages/get-started.mdx
deleted file mode 100644
index e9ce283e..00000000
--- a/serverless/pages/get-started.mdx
+++ /dev/null
@@ -1,223 +0,0 @@
----
-slug: /serverless/elasticsearch/get-started
-title: Get started
-description: Get started with ((es3)) in a few steps
-tags: [ 'serverless', 'elasticsearch', 'getstarted', 'overview' ]
----
-
-import MinimumVcusDetail from '../partials/minimum-vcus-detail.mdx'
-
-
-Follow along to set up your ((es)) project and get started with some sample documents.
-Then, choose how to continue with your own data.
-
-## Create project
-
-Use your ((ecloud)) account to create a fully-managed ((es)) project:
-
-1. Navigate to [cloud.elastic.co](((ess-console))) and create a new account or log in to your existing account.
-1. Within **Serverless Projects**, choose **Create project**.
-1. Choose the ((es)) project type.
-1. Select a **configuration** for your project, based on your use case.
- - **General purpose**. For general search use cases across various data types.
- - **Optimized for Vectors**. For search use cases using vectors and near real-time retrieval.
-1. Provide a name for the project and optionally edit the project settings, such as the cloud platform .
- Select **Create project** to continue.
-1. Once the project is ready, select **Continue**.
-
-You should now see **Get started with ((es))**, and you're ready to continue.
-
-
-
-## Create API key
-
-Create an API key, which will enable you to access the ((es)) API to ingest and search data.
-
-1. Scroll to **Add an API Key** and select **New**.
-1. In **Create API Key**, enter a name for your key and (optionally) set an expiration date.
-1. (Optional) Under **Control Security privileges**, you can set specific access permissions for this API key. By default, it has full access to all APIs.
-1. (Optional) The **Add metadata** section allows you to add custom key-value pairs to help identify and organize your API keys.
-1. Select **Create API Key** to finish.
-
-After creation, you'll see your API key displayed as an encoded string.
-Store this encoded API key securely. It is displayed only once and cannot be retrieved later.
-You will use this encoded API key when sending API requests.
-
-
- You can't recover or retrieve a lost API key. Instead, you must delete the key and create a new one.
-
-
-## Copy URL
-
-Next, copy the URL of your API endpoint.
-You'll send all ((es)) API requests to this URL.
-
-1. Scroll to **Copy your connection details**.
-1. Find the value for **Elasticsearch Endpoint**.
-
-Store this value along with your `encoded` API key.
-You'll use both values in the next step.
-
-## Test connection
-
-We'll use the `curl` command to test your connection and make additional API requests.
-(See [Install curl](https://everything.curl.dev/get) if you need to install this program.)
-
-`curl` will need access to your Elasticsearch Endpoint and `encoded` API key.
-Within your terminal, assign these values to the `ES_URL` and `API_KEY` environment variables.
-
-For example:
-
-```bash
-export ES_URL="https://dda7de7f1d264286a8fc9741c7741690.es.us-east-1.aws.elastic.cloud:443"
-export API_KEY="ZFZRbF9Jb0JDMEoxaVhoR2pSa3Q6dExwdmJSaldRTHFXWEp4TFFlR19Hdw=="
-```
-
-Then run the following command to test your connection:
-
-```bash
-curl "${ES_URL}" \
- -H "Authorization: ApiKey ${API_KEY}" \
- -H "Content-Type: application/json"
-```
-
-You should receive a response similar to the following:
-
-```json
-{
- "name" : "serverless",
- "cluster_name" : "dda7de7f1d264286a8fc9741c7741690",
- "cluster_uuid" : "ws0IbTBUQfigmYAVMztkZQ",
- "version" : { ... },
- "tagline" : "You Know, for Search"
-}
-```
-
-Now you're ready to ingest and search some sample documents.
-
-## Ingest data
-
-
- This example uses ((es)) APIs to ingest data. If you'd prefer to upload a file using the UI, refer to .
-
-
-To ingest data, you must create an index and store some documents.
-This process is also called "indexing".
-
-You can index multiple documents using a single `POST` request to the `_bulk` API endpoint.
-The request body specifies the documents to store and the indices in which to store them.
-
-((es)) will automatically create the index and map each document value to one of its data types.
-Include the `?pretty` option to receive a human-readable response.
-
-Run the following command to index some sample documents into the `books` index:
-
-```bash
-curl -X POST "${ES_URL}/_bulk?pretty" \
- -H "Authorization: ApiKey ${API_KEY}" \
- -H "Content-Type: application/json" \
- -d '
-{ "index" : { "_index" : "books" } }
-{"name": "Snow Crash", "author": "Neal Stephenson", "release_date": "1992-06-01", "page_count": 470}
-{ "index" : { "_index" : "books" } }
-{"name": "Revelation Space", "author": "Alastair Reynolds", "release_date": "2000-03-15", "page_count": 585}
-{ "index" : { "_index" : "books" } }
-{"name": "1984", "author": "George Orwell", "release_date": "1985-06-01", "page_count": 328}
-{ "index" : { "_index" : "books" } }
-{"name": "Fahrenheit 451", "author": "Ray Bradbury", "release_date": "1953-10-15", "page_count": 227}
-{ "index" : { "_index" : "books" } }
-{"name": "Brave New World", "author": "Aldous Huxley", "release_date": "1932-06-01", "page_count": 268}
-{ "index" : { "_index" : "books" } }
-{"name": "The Handmaids Tale", "author": "Margaret Atwood", "release_date": "1985-06-01", "page_count": 311}
-'
-```
-
-You should receive a response indicating there were no errors:
-
-```json
-{
- "errors" : false,
- "took" : 1260,
- "items" : [ ... ]
-}
-```
-
-## Search data
-
-To search, send a `POST` request to the `_search` endpoint, specifying the index to search.
-Use the ((es)) query DSL to construct your request body.
-
-Run the following command to search the `books` index for documents containing `snow`:
-
-```bash
-curl -X POST "${ES_URL}/books/_search?pretty" \
- -H "Authorization: ApiKey ${API_KEY}" \
- -H "Content-Type: application/json" \
- -d '
-{
- "query": {
- "query_string": {
- "query": "snow"
- }
- }
-}
-'
-```
-
-You should receive a response with the results:
-
-```json
-{
- "took" : 24,
- "timed_out" : false,
- "_shards" : {
- "total" : 1,
- "successful" : 1,
- "skipped" : 0,
- "failed" : 0
- },
- "hits" : {
- "total" : {
- "value" : 1,
- "relation" : "eq"
- },
- "max_score" : 1.5904956,
- "hits" : [
- {
- "_index" : "books",
- "_id" : "Z3hf_IoBONQ5TXnpLdlY",
- "_score" : 1.5904956,
- "_source" : {
- "name" : "Snow Crash",
- "author" : "Neal Stephenson",
- "release_date" : "1992-06-01",
- "page_count" : 470
- }
- }
- ]
- }
-}
-```
-
-## Continue on your own
-
-Congratulations!
-You've set up an ((es)) project, and you've ingested and searched some sample data.
-Now you're ready to continue on your own.
-
-### Explore
-
-Want to explore the sample documents or your own data?
-
-By creating a data view, you can explore data using several UI tools, such as Discover or Dashboards. Or, use ((es)) aggregations to explore your data using the API. Find more information in .
-
-### Build
-
-Ready to build your own solution?
-
-To learn more about sending and syncing data to ((es)), or the search API and its query DSL, check and .
-{/*
--
--
-*/}
-
diff --git a/serverless/pages/index-management.mdx b/serverless/pages/index-management.mdx
deleted file mode 100644
index da554e69..00000000
--- a/serverless/pages/index-management.mdx
+++ /dev/null
@@ -1,254 +0,0 @@
----
-slug: /serverless/index-management
-title: Index management
-description: Perform CRUD operations on indices and data streams. View index settings, mappings, and statistics.
-tags: [ 'serverless', 'Elasticsearch', 'Observability', 'Security' ]
----
-
-
-This content applies to:
-
-Elastic's index management features are an easy, convenient way to manage your cluster's indices, data streams, index templates, and enrich policies.
-Practicing good index management ensures your data is stored correctly and in the most cost-effective way possible.
-{/* data streams , and index
-templates. */}
-
-{/*
-## What you'll learn
-
-You'll learn how to:
-
-* View and edit index settings.
-* View mappings and statistics for an index.
-* Perform index-level operations, such as refreshes.
-* View and manage data streams.
-* Create index templates to automatically configure new data streams and indices.
-
-TBD: Are these RBAC requirements valid for serverless?
-
-## Required permissions
-
-If you use ((es)) ((security-features)), the following security privileges are required:
-
-* The `monitor` cluster privilege to access Elastic's **((index-manage-app))** features.
-* The `view_index_metadata` and `manage` index privileges to view a data stream
- or index's data.
-
-* The `manage_index_templates` cluster privilege to manage index templates.
-
-To add these privileges, go to **Management → Custom Roles**.
-
-*/}
-
-## Manage indices
-
-Go to **((project-settings)) → ((manage-app)) → ((index-manage-app))**:
-
-
-{/* TO-DO: This screenshot needs to be refreshed since it doesn't show all of the pertinent tabs */}
-
-The **((index-manage-app))** page contains an overview of your indices.
-{/*
-TBD: Do these badges exist in serverless?
-Badges indicate if an index is a follower index, a
-rollup index, or frozen. Clicking a badge narrows the list to only indices of that type. */}
-* To show details or perform operations, such as delete, click the index name. To perform operations
-on multiple indices, select their checkboxes and then open the **Manage** menu.
-
-* To filter the list of indices, use the search bar.
-
-* To drill down into the index mappings, settings, and statistics, click an index name. From this view, you can navigate to **Discover** to further explore the documents in the index.
-{/* settings, mapping */}
-
-{/*  */}
-{/* TO-DO: This screenshot needs to be refreshed since it doesn't show the appropriate context */}
-
-## Manage data streams
-
-Investigate your data streams and address lifecycle management needs in the **Data Streams** view.
-
-The value in the **Indices** column indicates the number of backing indices. Click this number to drill down into details.
-
-A value in the data retention column indicates that the data stream is managed by a data stream lifecycle policy.
-
-This value is the time period for which your data is guaranteed to be stored. Data older than this period can be deleted by
-((es)) at a later time.
-
-
-
-To view information about the stream's backing indices, click the number in the **Indices** column.
-
-* To view more information about a data stream, such as its generation or its
-current index lifecycle policy, click the stream's name. From this view, you can navigate to **Discover** to
-further explore data within the data stream.
-
-* To edit the data retention value, open the **Manage** menu, and then click **Edit data retention**.
-
-{/*
-TO-DO: This screenshot is not accurate since it contains several toggles that don't exist in serverless.
-
-*/}
-
-## Manage index templates
-
-Create, edit, clone, and delete your index templates in the **Index Templates** view. Changes made to an index template do not affect existing indices.
-
-
-{/* TO-DO: This screenshot is missing some tabs that exist in serverless */}
-
-If you don't have any templates, you can create one using the **Create template** wizard.
-
-{/*
-TO-DO: This walkthrough needs to be tested and updated for serverless.
-### Try it: Create an index template
-
-In this tutorial, you'll create an index template and use it to configure two
-new indices.
-
-**Step 1. Add a name and index pattern**
-
-1. In the **Index Templates** view, open the **Create template** wizard.
-
- 
-
-1. In the **Name** field, enter `my-index-template`.
-
-1. Set **Index pattern** to `my-index-*` so the template matches any index
- with that index pattern.
-
-1. Leave **Data Stream**, **Priority**, **Version**, and **_meta field** blank or as-is.
-
-**Step 2. Add settings, mappings, and aliases**
-
-1. Add component templates to your index template.
-
- Component templates are pre-configured sets of mappings, index settings, and
- aliases you can reuse across multiple index templates. Badges indicate
- whether a component template contains mappings (*M*), index settings (*S*),
- aliases (*A*), or a combination of the three.
-
- Component templates are optional. For this tutorial, do not add any component
- templates.
-
- 
-
-1. Define index settings. These are optional. For this tutorial, leave this
- section blank.
-
-1. Define a mapping that contains an object field named `geo` with a
- child `geo_point` field named `coordinates`:
-
- 
-
- Alternatively, you can click the **Load JSON** link and define the mapping as JSON:
-
- ```js
- {
- "properties": {
- "geo": {
- "properties": {
- "coordinates": {
- "type": "geo_point"
- }
- }
- }
- }
-
- ```
- \\ NOTCONSOLE
-
- You can create additional mapping configurations in the **Dynamic templates** and
- **Advanced options** tabs. For this tutorial, do not create any additional
- mappings.
-
-1. Define an alias named `my-index`:
-
- ```js
- {
- "my-index": {}
- }
- ```
- \\ NOTCONSOLE
-
-1. On the review page, check the summary. If everything looks right, click
- **Create template**.
-
-**Step 3. Create new indices**
-
-You’re now ready to create new indices using your index template.
-
-1. Index the following documents to create two indices:
- `my-index-000001` and `my-index-000002`.
-
- ```console
- POST /my-index-000001/_doc
- {
- "@timestamp": "2019-05-18T15:57:27.541Z",
- "ip": "225.44.217.191",
- "extension": "jpg",
- "response": "200",
- "geo": {
- "coordinates": {
- "lat": 38.53146222,
- "lon": -121.7864906
- }
- },
- "url": "https://media-for-the-masses.theacademyofperformingartsandscience.org/uploads/charles-fullerton.jpg"
- }
-
- POST /my-index-000002/_doc
- {
- "@timestamp": "2019-05-20T03:44:20.844Z",
- "ip": "198.247.165.49",
- "extension": "php",
- "response": "200",
- "geo": {
- "coordinates": {
- "lat": 37.13189556,
- "lon": -76.4929875
- }
- },
- "memory": 241720,
- "url": "https://theacademyofperformingartsandscience.org/people/type:astronauts/name:laurel-b-clark/profile"
- }
- ```
-
-1. Use the get index API to view the configurations for the
- new indices. The indices were configured using the index template you created
- earlier.
-
- ```console
- GET /my-index-000001,my-index-000002
- ```
- \\ TEST[continued]
- */}
-
-
-{/*
-TO-DO:This page is missing information about the "Component templates" tab.
-*/}
-
-## Manage enrich policies
-
-Use the **Enrich Policies** view to add data from your existing indices to incoming documents during ingest.
-An [enrich policy](((ref))/ingest-enriching-data.html) contains:
-
-* The policy type that determines how the policy matches the enrich data to incoming documents
-* The source indices that store enrich data as documents
-* The fields from the source indices used to match incoming documents
-* The enrich fields containing enrich data from the source indices that you want to add to incoming documents
-* An optional query.
-
-
-
-When creating an enrich policy, the UI walks you through the configuration setup and selecting the fields.
-Before you can use the policy with an enrich processor, you must execute the policy.
-
-When executed, an enrich policy uses enrich data from the policy's source indices
-to create a streamlined system index called the enrich index. The policy uses this index to match and enrich incoming documents.
-
-Check out these examples:
-
-* [Example: Enrich your data based on geolocation](((ref))/geo-match-enrich-policy-type.html)
-* [Example: Enrich your data based on exact values](((ref))/match-enrich-policy-type.html)
-* [Example: Enrich your data by matching a value to a range](((ref))/range-enrich-policy-type.html)
diff --git a/serverless/pages/ingest-pipelines.mdx b/serverless/pages/ingest-pipelines.mdx
deleted file mode 100644
index fdde6738..00000000
--- a/serverless/pages/ingest-pipelines.mdx
+++ /dev/null
@@ -1,50 +0,0 @@
----
-slug: /serverless/ingest-pipelines
-title: ((ingest-pipelines-cap))
-description: Create and manage ((ingest-pipelines)) to perform common transformations and enrichments on your data.
-tags: [ 'serverless', 'Elasticsearch', 'Observability', 'Security' ]
----
-
-
-This content applies to:
-
-[((ingest-pipelines-cap))](((ref))/ingest.html) let you perform common transformations on your data before indexing.
-For example, you can use pipelines to remove fields, extract values from text, and enrich your data.
-
-A pipeline consists of a series of configurable tasks called processors.
-Each processor runs sequentially, making specific changes to incoming documents.
-After the processors have run, ((es)) adds the transformed documents to your data stream or index.
-
-{/*
-TBD: Do these requirements apply in serverless?
-## Prerequisites
-
-- Nodes with the ingest node role handle pipeline processing. To use ingest pipelines, your cluster must have at least one node with the ingest role. For heavy ingest loads, we recommend creating dedicated ingest nodes.
-- If the Elasticsearch security features are enabled, you must have the manage_pipeline cluster privilege to manage ingest pipelines. To use Kibana’s Ingest Pipelines feature, you also need the cluster:monitor/nodes/info cluster privileges.
-- Pipelines including the enrich processor require additional setup. See Enrich your data.
-*/}
-
-## Create and manage pipelines
-
-In **((project-settings)) → ((manage-app)) → ((ingest-pipelines-app))**, you can:
-
-- View a list of your pipelines and drill down into details
-- Edit or clone existing pipelines
-- Delete pipelines
-
-
-
-To create a pipeline, click **Create pipeline → New pipeline**.
-For an example tutorial, see [Example: Parse logs](((ref))/common-log-format-example.html).
-
-The **New pipeline from CSV** option lets you use a file with comma-separated values (CSV) to create an ingest pipeline that maps custom data to the Elastic Common Schema (ECS).
-Mapping your custom data to ECS makes the data easier to search and lets you reuse visualizations from other data sets.
-To get started, check [Map custom data to ECS](((ecs-ref))/ecs-converting.html).
-
-## Test pipelines
-
-Before you use a pipeline in production, you should test it using sample documents.
-When creating or editing a pipeline in **((ingest-pipelines-app))**, click **Add documents**.
-In the **Documents** tab, provide sample documents and click **Run the pipeline**:
-
-
diff --git a/serverless/pages/ingest-your-data-ingest-data-through-api.mdx b/serverless/pages/ingest-your-data-ingest-data-through-api.mdx
deleted file mode 100644
index 0106d539..00000000
--- a/serverless/pages/ingest-your-data-ingest-data-through-api.mdx
+++ /dev/null
@@ -1,129 +0,0 @@
----
-slug: /serverless/elasticsearch/ingest-data-through-api
-title: Ingest data through API
-description: Add data to ((es)) using HTTP APIs or a language client.
-tags: [ 'serverless', 'elasticsearch', 'ingest', 'api', 'how to' ]
----
-
-
-The ((es)) APIs enable you to ingest data through code.
-You can use the APIs of one of the
- or the
-((es)) HTTP APIs. The examples
-on this page use the HTTP APIs to demonstrate how ingesting works in
-((es)) through APIs.
-If you want to ingest timestamped data or have a
-more complex ingestion use case, check out
- or
-.
-{/* . */}
-{/* ^^^^Page temporarily removed */}
-
-## Using the bulk API
-
-You can index multiple JSON documents to an index and make it searchable using
-the bulk API.
-
-The following example uses the bulk API to ingest book-related data into an
-index called `books`. The API call creates the index if it doesn't exist already.
-
-```bash
-curl -X POST "${ES_URL}/_bulk?pretty" \
--H "Authorization: ApiKey ${API_KEY}" \
--H "Content-Type: application/json" \
--d'
-{ "index" : { "_index" : "books" } }
-{"title": "Snow Crash", "author": "Neal Stephenson", "release_date": "1992-06-01", "page_count": 470}
-{ "index" : { "_index" : "books" } }
-{"title": "Revelation Space", "author": "Alastair Reynolds", "release_date": "2000-03-15", "page_count": 585}
-{ "index" : { "_index" : "books" } }
-{"title": "1984", "author": "George Orwell", "release_date": "1985-06-01", "page_count": 328}
-{ "index" : { "_index" : "books" } }
-{"title": "Fahrenheit 451", "author": "Ray Bradbury", "release_date": "1953-10-15", "page_count": 227}
-{ "index" : { "_index" : "books" } }
-{"title": "Brave New World", "author": "Aldous Huxley", "release_date": "1932-06-01", "page_count": 268}
-{ "index" : { "_index" : "books" } }
-{"title": "The Blind Assassin", "author": "Margaret Atwood", "release_date": "2000-09-02", "page_count": 536}
-'
-```
-
-The API returns a response similar to this:
-
-```json
-{
- "errors": false,
- "took": 902,
- "items": [
- {
- "index": {
- "_index": "books",
- "_id": "MCYbQooByucZ6Gimx2BL",
- "_version": 1,
- "result": "created",
- "_shards": {
- "total": 1,
- "successful": 1,
- "failed": 0
- },
- "_seq_no": 0,
- "_primary_term": 1,
- "status": 201
- }
- },
- ...
- ]
-}
-```
-
-
-Under the hood, the bulk request creates a data schema, called "mappings" for the `books` index.
-To review the mappings and ensure the JSON body matches the index mappings, navigate to **Content** → **Index management**, select the index you want to ingest the data into, and click the **Mappings** tab.
-
-
-The API call creates an index called `books` and adds six documents to it. All
-those documents have the `title`, `author`, `release_date`, and `page_count`
-fields with associated values. This data is now searchable.
-
-You can check if a book is in the index by calling the search API and specifying
-either of the properties of the book in a `match` query, for example:
-
-```bash
-curl "${ES_URL}/books/_search?pretty" \
--H "Authorization: ApiKey ${API_KEY}" \
--H "Content-Type: application/json" \
--d'
-{
- "query": {
- "match": {
- "title": "Snow Crash"
- }
- }
-}
-'
-```
-
-The API response contains an array of hits. Each hit represents a document that
-matches the query. The response contains the whole document. Only one document
-matches this query.
-
-## Using the index API
-
-Use the index API to ingest a single document to an index. Following the
-previous example, a new document will be added to the `books` index.
-
-```bash
-curl -X POST "${ES_URL}/books/_doc/" \
--H "Authorization: ApiKey ${API_KEY}" \
--H "Content-Type: application/json" \
--d'
-{
- "title": "Neuromancer",
- "author": "William Gibson",
- "release_date": "1984-07-01",
- "page_count": "271"
-}
-'
-```
-
-The API call indexes the new document into the `books` index. Now you can search
-for it!
diff --git a/serverless/pages/ingest-your-data-ingest-data-through-integrations-beats.mdx b/serverless/pages/ingest-your-data-ingest-data-through-integrations-beats.mdx
deleted file mode 100644
index 38557408..00000000
--- a/serverless/pages/ingest-your-data-ingest-data-through-integrations-beats.mdx
+++ /dev/null
@@ -1,33 +0,0 @@
----
-slug: /serverless/elasticsearch/ingest-data-through-beats
-title: Beats
-description: Use ((beats)) to ship operational data to ((es)).
-tags: [ 'serverless', 'elasticsearch', 'ingest', 'beats', 'how to' ]
----
-
-
-((beats)) are lightweight data shippers that send operational data to ((es)).
-Elastic provides separate ((beats)) for different types of data, such as logs, metrics, and uptime.
-Depending on what data you want to collect, you may need to install multiple shippers on a single host.
-
-| Data | ((beats))|
-|---|---|
-| Audit data | [Auditbeat](https://www.elastic.co/products/beats/auditbeat) |
-| Log files and journals | [Filebeat](https://www.elastic.co/products/beats/filebeat)|
-| Cloud data | [Functionbeat](https://www.elastic.co/products/beats/functionbeat)|
-| Availability | [Heartbeat](https://www.elastic.co/products/beats/heartbeat)|
-| Metrics | [Metricbeat](https://www.elastic.co/products/beats/metricbeat)|
-| Network traffic | [Packetbeat](https://www.elastic.co/products/beats/packetbeat)|
-| Windows event logs | [Winlogbeat](https://www.elastic.co/products/beats/winlogbeat)|
-
-((beats)) can send data to ((es)) directly or through ((ls)), where you
-can further process and enhance the data before visualizing it in ((kib)).
-
-
-
-When you use ((beats)) to export data to an ((es)) project, the ((beats)) require an API key to authenticate with ((es)).
-Refer to for the steps to set up your API key,
-and to [Grant access using API keys](https://www.elastic.co/guide/en/beats/filebeat/current/beats-api-keys.html) in the Filebeat documentation for an example of how to configure your ((beats)) to use the key.
-
-
-Check out [Get started with Beats](((beats-ref))/getting-started.html) for some next steps.
diff --git a/serverless/pages/ingest-your-data-ingest-data-through-integrations-connector-client.mdx b/serverless/pages/ingest-your-data-ingest-data-through-integrations-connector-client.mdx
deleted file mode 100644
index 7f958dde..00000000
--- a/serverless/pages/ingest-your-data-ingest-data-through-integrations-connector-client.mdx
+++ /dev/null
@@ -1,265 +0,0 @@
----
-slug: /serverless/elasticsearch/ingest-data-through-integrations-connector-client
-title: Connector clients
-description: Set up and deploy self-managed connectors that run on your own infrastructure.
-tags: [ 'serverless', 'elasticsearch', 'ingest', 'connector', 'how to' ]
-status: in review
----
-
-
- This page contains high-level instructions about setting up connector clients in your project's UI.
- Because prerequisites and configuration details vary by data source, you'll need to refer to the individual connector documentation for specific details.
-
-
-A _connector_ is a type of [Elastic integration](https://www.elastic.co/integrations/data-integrations) that syncs data from an original data source to ((es)).
-Each connector extracts the original files, records, or objects; and transforms them into documents within ((es)).
-
-_Connector clients_ are **self-managed** connectors that you run on your own infrastructure.
-These connectors are written in Python and the source code is available in the [`elastic/connectors`](https://github.com/elastic/connectors/tree/main/connectors/sources) repo.
-
-## Available connectors
-
-Connector clients are available for the following third-party data sources:
-
-
-
-{/* TODO: Update links if these references move*/}
-- [Azure Blob Storage](https://www.elastic.co/guide/en/elasticsearch/reference/master/es-connectors-azure-blob.html)
-- [Box](https://www.elastic.co/guide/en/elasticsearch/reference/master/es-connectors-box.html)
-- [Confluence](https://www.elastic.co/guide/en/elasticsearch/reference/master/es-connectors-confluence.html)
-- [Dropbox](https://www.elastic.co/guide/en/elasticsearch/reference/master/es-connectors-dropbox.html)
-- [GitHub](https://www.elastic.co/guide/en/elasticsearch/reference/master/es-connectors-github.html)
-- [Gmail](https://www.elastic.co/guide/en/elasticsearch/reference/master/es-connectors-gmail.html)
-- [Google Cloud Storage](https://www.elastic.co/guide/en/elasticsearch/reference/master/es-connectors-google-cloud.html)
-- [Google Drive](https://www.elastic.co/guide/en/elasticsearch/reference/master/es-connectors-google-drive.html)
-- [GraphQL](https://www.elastic.co/guide/en/elasticsearch/reference/master/es-connectors-graphql.html)
-- [Jira](https://www.elastic.co/guide/en/elasticsearch/reference/master/es-connectors-jira.html)
-- [MicrosoftSQL](https://www.elastic.co/guide/en/elasticsearch/reference/master/es-connectors-ms-sql.html)
-- [MongoDB](https://www.elastic.co/guide/en/elasticsearch/reference/master/es-connectors-mongodb.html)
-- [MySQL](https://www.elastic.co/guide/en/elasticsearch/reference/master/es-connectors-mysql.html)
-- [Network drive](https://www.elastic.co/guide/en/elasticsearch/reference/master/es-connectors-network-drive.html)
-- [Notion](https://www.elastic.co/guide/en/elasticsearch/reference/master/es-connectors-notion.html)
-- [OneDrive](https://www.elastic.co/guide/en/elasticsearch/reference/master/es-connectors-onedrive.html)
-- [OpenText Documentum](https://www.elastic.co/guide/en/elasticsearch/reference/master/es-connectors-opentext.html)
-- [Oracle](https://www.elastic.co/guide/en/elasticsearch/reference/master/es-connectors-oracle.html)
-- [Outlook](https://www.elastic.co/guide/en/elasticsearch/reference/master/es-connectors-outlook.html)
-- [PostgreSQL](https://www.elastic.co/guide/en/elasticsearch/reference/master/es-connectors-postgresql.html)
-- [Redis](https://www.elastic.co/guide/en/elasticsearch/reference/master/es-connectors-redis.html)
-- [S3](https://www.elastic.co/guide/en/elasticsearch/reference/master/es-connectors-s3.html)
-- [Salesforce](https://www.elastic.co/guide/en/elasticsearch/reference/master/es-connectors-salesforce.html)
-- [ServiceNow](https://www.elastic.co/guide/en/elasticsearch/reference/master/es-connectors-servicenow.html)
-- [SharePoint Online](https://www.elastic.co/guide/en/elasticsearch/reference/master/es-connectors-sharepoint-online.html)
-- [SharePoint Server](https://www.elastic.co/guide/en/elasticsearch/reference/master/es-connectors-sharepoint.html)
-- [Slack](https://www.elastic.co/guide/en/elasticsearch/reference/master/es-connectors-slack.html)
-- [Teams](https://www.elastic.co/guide/en/elasticsearch/reference/master/es-connectors-teams.html)
-- [Zoom](https://www.elastic.co/guide/en/elasticsearch/reference/master/es-connectors-zoom.html)
-
-
-## Overview
-
-Because connector clients are self-managed on your own infrastructure, they run outside of your ((es)) serverless project.
-
-You can run them from source or in a Docker container.
-
-
- In order to set up, configure, and run a connector you'll be moving between your third-party service, the ((es)) Serverless UI, and your terminal.
- At a high-level, the workflow looks like this:
- 1. Satisfy any data source prerequisites (e.g., create an OAuth application).
- 2. Create a connector in the UI.
- 3. Deploy the connector service from source or with Docker.
- 4. Enter data source configuration details in the UI.
-
-
-### Data source prerequisites
-
-The first decision you need to make before deploying a connector is which third party service (data source) you want to sync to ((es)).
-See the list of [available connectors](#available-connectors).
-
-Note that each data source will have specific prerequisites you'll need to meet to authorize the connector to access its data.
-For example, certain data sources may require you to create an OAuth application, or create a service account.
-You'll need to check the [individual connector documentation](#available-connectors) for these details.
-
-## Step 1: Initial setup in UI
-
-In your project's UI, go to **((es)) → Connectors**.
-Follow these steps:
-
-1. Select **Create a connector**.
-2. Choose a third-party service from the list of connector types.
-3. Add a name and optional description to identify the connector.
-4. Copy the `connector_id`, `service_type`, and `elasticsearch.host` values printed to the screen.
-You'll need to update these values in your [`config.yml`](https://github.com/elastic/connectors/blob/main/config.yml) file.
-5. Navigate to **Elasticsearch → Home**, and make a note of your **((es)) endpoint** and **API key** values. You can create a new API key by clicking on **New** in the **API key** section.
-6. Run the connector code either from source or with Docker, following the instructions below.
-
-## Step 2: Deploy your self-managed connector
-
-To use connector clients, you must deploy the connector service so your connector can talk to your ((es)) instance.
-The source code is hosted in the `elastic/connectors` repository.
-
-You have two deployment options:
-- Run with [Docker](#run-with-docker) (recommended)
-- Run from [source](#run-from-source)
-
-
- You'll need the following values handy to update your `config.yml` file:
- - `elasticsearch.host`: Your ((es)) endpoint. Printed to the screen when you create a new connector.
- - `elasticsearch.api_key`: Your ((es)) API key. You can create API keys by navigating to **Home**, and clicking **New** in the **API key** section. Once your connector is running, you'll be able to create a new API key that is limited to only access the connector's index.
- - `connector_id`: Unique id for your connector. Printed to the screen when you create a new connector.
- - `service_type`: Original data source type. Printed to the screen when you create a new connector.
-
-
-### Run with Docker
-
-You can deploy connector clients using Docker.
-Follow these instructions.
-
-**Step 1: Download sample configuration file**
-
-You can either download the configuration file manually or run the following command:
-
-```shell
-curl https://raw.githubusercontent.com/elastic/connectors/main/config.yml.example --output /connectors-config/config.yml
-```
-
-Change the `--output` argument value to the path where you want to save the configuration file.
-
-**Step 2: Update the configuration file for your self-managed connector**
-
-- Update the following settings to match your environment:
-
-* `elasticsearch.host`
-* `elasticsearch.api_key`
-* `connector id`
-* `service_type`
-
-Your configuration file should look like this:
-
-```yaml
-elasticsearch.host:
-elasticsearch.api_key:
-
-connectors:
- -
- connector_id:
- service_type: # sharepoint_online (example)
- api_key: # Optional. If not provided, the connector will use the elasticsearch.api_key instead
-```
-
-**Step 3: Run the Docker image**
-
-Use the following command, substituting values where necessary:
-
-```shell
-docker run \
--v "/connectors-config:/config" \ # NOTE: change absolute path to match where config.yml is located on your machine
---tty \
---rm \
-docker.elastic.co/enterprise-search/elastic-connectors:{version}.0 \
-/app/bin/elastic-ingest \
--c /config/config.yml # Path to your configuration file in the container
-```
-
-Find all available Docker images in the [official Elastic Docker registry](https://www.docker.elastic.co/r/enterprise-search/elastic-connectors).
-
-
- Each individual connector client reference contain instructions for deploying specific connectors using Docker.
-
-
-### Run from source
-
-Running from source requires cloning the repository and running the code locally.
-Use this approach if you're actively customizing connectors.
-
-Follow these steps:
-
-- Clone or fork the repository locally with the following command:
- ```shell
- git clone https://github.com/elastic/connectors
- ```
-- Open the `config.yml.example` file in the `connectors` repository and rename it to `config.yml`.
-- Update the following settings to match your environment:
-
-* `elasticsearch.host`
-* `elasticsearch.api_key`
-* `connector id`
-* `service_type`
-
-Your configuration file should look like this:
-
-```yaml
-elasticsearch.host:
-elasticsearch.api_key:
-
-connectors:
- -
- connector_id:
- service_type: # sharepoint_online (example)
- api_key: # Optional. If not provided, the connector will use the elasticsearch.api_key instead
-```
-
-
- Learn more about the `config.yml` file in the [repo docs](https://github.com/elastic/connectors/blob/main/docs/CONFIG.md).
-
-
-**Run the connector service**
-
-Once you've configured the connector code, you can run the connector service.
-
-In your terminal or IDE:
-
-- `cd` into the root of your `elastic/connectors` clone/fork.
-- Run the following commands to compile and run the connector service:
-
- ```shell
- make install
- make run
- ```
-
-The connector service should now be running in your terminal. If the connection to your ((es)) instance was successful, the **Configure your connector** step will be activated in the project's UI.
-
-Here we're working locally. In a production setup, you'll deploy the connector service to your own infrastructure.
-
-## Step 3: Enter data source details in UI
-
-Once the connector service is running, it's time to head back to the UI to finalize the connector configuration.
-You should now see the **Configure your connector** step in your project's UI.
-
-In this step, you need to add the specific connection details about your data source instance, like URL, authorization credentials, etc.
-These **details will vary** based on the third-party data source you’re connecting to.
-
-For example, the Sharepoint Online connector requires the following details about your Sharepoint instance:
-- **Tenant ID**
-- **Tenant name**
-- **Client ID**
-- **Secret value**
-- **Comma-separated list of tables**
-
-## Step 4: Connect to an index
-
-Once you've entered the data source details, you need to connect to an index.
-This is the final step in your project's UI, before you can run a sync.
-
-You can choose to sync to an existing ((es)) index, or create a new index for your connector.
-You can also create an API key that is limited to only access your selected index.
-
-
- Due to a bug, you must prefix your index name with `search-`, otherwise you will hit an error.
- For example, `search-my-index` is a valid index name, but `my-index` is not.
-
-
-
- When choosing an existing index for the connector to sync to, please ensure mappings are defined and are appropriate for incoming data. Connectors will not successfully sync to existing indices without mappings. If you are unsure about managing index mappings, choose to have your connector create the new index.
-
-
-Once this step is completed, you're ready to run a sync.
-When a sync is launched you'll start to see documents being added to your ((es)) index.
-
-Learn [how syncing works](https://github.com/elastic/connectors/blob/main/docs/DEVELOPING.md#syncing) in the `elastic/connectors` repo docs.
-
-## Learn more
-
-- Read the main [Elastic connectors documentation](https://www.elastic.co/guide/en/elasticsearch/reference/master/es-connectors.html)
-- The [Elastic connector framework](https://github.com/elastic/connectors/tree/main#connector-framework) enables you to:
- - Customize existing connector clients.
- - Build your own connector clients.
diff --git a/serverless/pages/ingest-your-data-ingest-data-through-integrations-logstash.mdx b/serverless/pages/ingest-your-data-ingest-data-through-integrations-logstash.mdx
deleted file mode 100644
index 6dba9130..00000000
--- a/serverless/pages/ingest-your-data-ingest-data-through-integrations-logstash.mdx
+++ /dev/null
@@ -1,91 +0,0 @@
----
-slug: /serverless/elasticsearch/ingest-data-through-logstash
-title: Logstash
-description: Use ((ls)) to ship data to ((es)).
-tags: [ 'serverless', 'elasticsearch', 'ingest', 'logstash', 'how to' ]
----
-
-
-((ls)) is an open source data collection engine with real-time pipelining capabilities.
-It supports a wide variety of data sources, and can dynamically unify data from disparate sources and normalize the data into destinations of your choice.
-
-((ls)) can collect data using a variety of ((ls)) [input plugins](((logstash-ref))/input-plugins.html), enrich and transform the data with ((ls)) [filter plugins](((logstash-ref))/filter-plugins.html),
-and output the data to ((es)) using the ((ls)) [Elasticsearch output plugin](((logstash-ref))/plugins-outputs-elasticsearch.html).
-
-You can use ((ls)) to extend for advanced use cases,
-such as data routed to multiple destinations or when you need to make your data persistent.
-
-
-
-
-((ls)) is a powerful, versatile ETL (Extract, Transform, Load) engine that can play an important role in organizations of all sizes.
-Some capabilities and features for large, self-managed users aren't appropriate for ((serverless-short)).
-
-You'll use the ((ls)) [`((es)) output plugin`](((logstash-ref))/plugins-outputs-elasticsearch.html) to send data to ((es3)).
-Some differences to note between ((es3)) and self-managed ((es)):
-
-- Your logstash-output-elasticsearch configuration uses **API keys** to access ((es)) from ((ls)).
-User-based security settings are ignored and may cause errors.
-- ((es3)) uses **((dlm)) (((dlm-init)))** instead of ((ilm)) (((ilm-init))).
-If you add ((ilm-init)) settings to your ((es)) output configuration, they are ignored and may cause errors.
-- **((ls)) monitoring** for ((serverless-short)) is available through the [((ls)) Integration](https://github.com/elastic/integrations/blob/main/packages/logstash/_dev/build/docs/README.md) in .
-
-**Known issue**
-
-* The logstash-output-elasticsearch `hosts` setting defaults to port `:9200`.
-Set the value to port `:443` instead.
-
-
-
-## Requirements
-
-To use ((ls)) to send data to ((es3)), you must be using:
-- ((ls)) 8.10.1 or later
-- ((ls)) [((es)) output plugin](((logstash-ref))/plugins-outputs-elasticsearch.html) 11.18.0 or later
-- ((ls)) [((es)) input plugin](((logstash-ref))/plugins-inputs-elasticsearch.html) 4.18.0 or later
-- ((ls)) [((es)) filter plugin](((logstash-ref))/plugins-filters-elasticsearch.html) 3.16.0 or later
-
-
-## Secure connection
-Serverless Elasticsearch simplifies secure communication between ((ls)) and ((es)).
-Configure the [Elasticsearch output](((logstash-ref))/plugins-outputs-elasticsearch.html) plugin to use
-[`cloud_id`](((logstash-ref))/plugins-outputs-elasticsearch.html#plugins-outputs-elasticsearch-cloud_id) and
-[`api_key`](((logstash-ref))/plugins-outputs-elasticsearch.html#plugins-outputs-elasticsearch-api_key).
-No additional SSL configuration steps are needed.
-
-## API keys for connecting ((ls)) to ((es3))
-
-Use the **Security: API key** section in the UI to create an API key
-for securely connecting the ((ls)) ((es)) output to ((es3)).
-We recommend creating a unique API key per ((ls)) instance.
-You can create as many API keys as necessary.
-
-When you set up your API keys, use the metadata option to tag each API key with details that are meaningful to you.
-This step makes managing multiple API keys easier.
-
-After you generate an API key, add it to your ((ls)) [((es)) output plugin](((logstash-ref))/plugins-outputs-elasticsearch.html) config file's `api_key` setting.
-Here's an example:
-
-```bash
-output {
- elasticsearch {
- api_key => "TiNAGG4BaaMdaH1tRfuU:KnR6yE41RrSowb0kQ0HWoA"
- }
-}
-```
-
-## Migrating Elasticsearch data using ((ls))
-
-You can use ((ls)) to migrate data from self-managed ((es)) or ((ess)) to ((es3)), or to migrate data from one ((es3)) deployment to another.
-
-Create a [((ls)) pipeline](((logstash-ref))/configuration.html) that includes the ((es)) [input plugin](((logstash-ref))/plugins-inputs-elasticsearch.html) and [output plugin](((logstash-ref))/plugins-outputs-elasticsearch.html).
-
-Configure the ((es)) input to point to your source deployment or instance, and configure the ((es)) output with the `cloud_id` and `api_key` settings for your target ((es3)) instance.
-
-If your origin index is using settings that aren't supported in Serverless, then you might need to adjust your index settings.
-
-## Next steps
-
-Check out the [Logstash product page](https://www.elastic.co/logstash) to see what ((ls)) can do for you.
-When you're ready,
- dive into the [Logstash documentation](((logstash-ref))/index.html).
diff --git a/serverless/pages/ingest-your-data-upload-file.mdx b/serverless/pages/ingest-your-data-upload-file.mdx
deleted file mode 100644
index 4ec25a8e..00000000
--- a/serverless/pages/ingest-your-data-upload-file.mdx
+++ /dev/null
@@ -1,44 +0,0 @@
----
-slug: /serverless/elasticsearch/ingest-data-file-upload
-title: Upload a file
-description: Add data to ((es)) using the File Uploader.
-tags: [ 'serverless', 'elasticsearch', 'ingest', 'how to' ]
----
-
-
-
-You can upload files to ((es)) using the File Uploader.
-Use the visualizer to inspect the data before importing it.
-
-You can upload different file formats for analysis:
-
-File formats supported up to 500 MB:
-
-- CSV
-- TSV
-- NDJSON
-- Log files
-
-File formats supported up to 60 MB:
-
-- PDF
-- Microsoft Office files (Word, Excel, PowerPoint)
-- Plain Text (TXT)
-- Rich Text (RTF)
-- Open Document Format (ODF)
-
-## How to upload a file
-
-You'll find a link to the File Uploader on the ((es)) **Home** page.
-
-
-
-Clicking **Upload a file** opens the File Uploader UI.
-
-
-
-
- The upload feature is not intended for use as part of a repeated production
-process, but rather for the initial exploration of your data.
-
-
diff --git a/serverless/pages/ingest-your-data.mdx b/serverless/pages/ingest-your-data.mdx
deleted file mode 100644
index c3634af5..00000000
--- a/serverless/pages/ingest-your-data.mdx
+++ /dev/null
@@ -1,29 +0,0 @@
----
-slug: /serverless/elasticsearch/ingest-your-data
-title: Ingest your data
-description: Add data to your ((es)) project.
-tags: [ 'serverless', 'elasticsearch', 'ingest', 'overview' ]
----
-
-
-You have many options for ingesting, or indexing, data into ((es)):
-
-- ((es)) API
-- Connector clients
-- File Uploader
-- ((beats))
-- ((ls))
-
-The best ingest option(s) for your use case depends on whether you are indexing general content or time series (timestamped) data.
-
-**General content**
-
-General content includes HTML pages, catalogs, files, and other content that does not update continuously.
-This data can be updated, but the value of the content remains relatively constant over time.
-Use connector clients to sync data from a range of popular data sources to ((es)).
-You can also send data directly to ((es)) from your application using the API.
-
-**Times series (timestamped) data**
-
-Time series, or timestamped data, describes data that changes frequently and "flows" over time, such as stock quotes, system metrics, and network traffic data.
-Use ((beats)) or ((ls)) to collect time series data.
diff --git a/serverless/pages/integrations.mdx b/serverless/pages/integrations.mdx
deleted file mode 100644
index 19ff0a78..00000000
--- a/serverless/pages/integrations.mdx
+++ /dev/null
@@ -1,16 +0,0 @@
----
-slug: /serverless/integrations
-title: Integrations
-description: Use our pre-built integrations to connect your data to Elastic.
-tags: [ 'serverless', 'ingest', 'integration' ]
----
-
-
-This content applies to:
-
-Elastic integrations are a streamlined way to connect your data to Elastic.
-Integrations are available for popular services and platforms, like Nginx, AWS, and MongoDB,
-as well as many generic input types like log files.
-
-Integration documentation is available in the product when you install an integration,
-or you can explore our [Elastic integrations documentation](https://www.elastic.co/docs/current/integrations).
diff --git a/serverless/pages/knn-search.mdx b/serverless/pages/knn-search.mdx
deleted file mode 100644
index 8c699002..00000000
--- a/serverless/pages/knn-search.mdx
+++ /dev/null
@@ -1,1029 +0,0 @@
----
-slug: /serverless/elasticsearch/knn-search
-title: k-nearest neighbor (kNN) search
-description: Vector search with k-nearest neighbor (kNN).
-tags: ['serverless', 'elasticsearch', 'search', 'vector', 'knn', 'ann']
----
-
-
-
-A _k-nearest neighbor_ (kNN) search finds the _k_ nearest vectors to a query
-vector, as measured by a similarity metric.
-
-Common use cases for kNN include:
-
-* Relevance ranking based on natural language processing (NLP) algorithms
-* Product recommendations and recommendation engines
-* Similarity search for images or videos
-
-## Prerequisites
-
-* To run a kNN search, you must be able to convert your data into meaningful
- vector values. You can
- [create these vectors using
- a natural language processing (NLP) model in ((es))](((ml-docs))/ml-nlp-text-emb-vector-search-example.html), or generate them outside
- ((es)). Vectors can be added to documents as [`dense_vector`](((ref))/dense-vector.html) field
- values. Queries are represented as vectors with the same dimension.
-
- Design your vectors so that the closer a document's vector is to a query vector,
- based on a similarity metric, the better its match.
-
-* To complete the steps in this guide, you must have the following
- [index privileges](((ref))/security-privileges.html#privileges-list-indices):
-
- * `create_index` or `manage` to create an index with a `dense_vector` field
- * `create`, `index`, or `write` to add data to the index you created
- * `read` to search the index
-
-## kNN methods
-
-((es)) supports two methods for kNN search:
-
-* Approximate kNN using the `knn` search
- option
-
-* Exact, brute-force kNN using a `script_score` query with a
- vector function
-
-In most cases, you'll want to use approximate kNN. Approximate kNN offers lower
-latency at the cost of slower indexing and imperfect accuracy.
-
-Exact, brute-force kNN guarantees accurate results but doesn't scale well with
-large datasets. With this approach, a `script_score` query must scan each
-matching document to compute the vector function, which can result in slow
-search speeds. However, you can improve latency by using a [query](((ref))/query-dsl.html)
-to limit the number of matching documents passed to the function. If you
-filter your data to a small subset of documents, you can get good search
-performance using this approach.
-
-## Approximate kNN
-
-To run an approximate kNN search, use the [`knn` option](((ref))/knn-search.html#approximate-knn)
-to search one or more `dense_vector` fields with indexing enabled.
-
-1. Explicitly map one or more `dense_vector` fields. Approximate kNN search
- requires the following mapping options:
-
- * A `similarity` value. This value determines the similarity metric used to
- score documents based on similarity between the query and document vector. For a
- list of available metrics, see the [`similarity`](((ref))/dense-vector.html#dense-vector-similarity)
- parameter documentation. The `similarity` setting defaults to `cosine`.
-
- ```bash
- curl -X PUT "${ES_URL}/image-index" \
- -H "Authorization: ApiKey ${API_KEY}" \
- -H "Content-Type: application/json" \
- -d '
- {
- "mappings": {
- "properties": {
- "image-vector": {
- "type": "dense_vector",
- "dims": 3,
- "similarity": "l2_norm"
- },
- "title-vector": {
- "type": "dense_vector",
- "dims": 5,
- "similarity": "l2_norm"
- },
- "title": {
- "type": "text"
- },
- "file-type": {
- "type": "keyword"
- }
- }
- }
- }
- '
- ```
-
-1. Index your data.
-
- ```bash
- curl -X POST "${ES_URL}/image-index/_bulk?refresh=true" \
- -H "Authorization: ApiKey ${API_KEY}" \
- -H "Content-Type: application/json" \
- -d '
- { "index": { "_id": "1" } }
- { "image-vector": [1, 5, -20], "title-vector": [12, 50, -10, 0, 1], "title": "moose family", "file-type": "jpg" }
- { "index": { "_id": "2" } }
- { "image-vector": [42, 8, -15], "title-vector": [25, 1, 4, -12, 2], "title": "alpine lake", "file-type": "png" }
- { "index": { "_id": "3" } }
- { "image-vector": [15, 11, 23], "title-vector": [1, 5, 25, 50, 20], "title": "full moon", "file-type": "jpg" }
- ...
- '
- ```
- {/* TEST[continued] */}
- {/* TEST[s/\.\.\.//] */}
-
-1. Run the search using the [`knn` option](((ref))/knn-search.html#approximate-knn).
-
- ```bash
- curl -X POST "${ES_URL}/image-index/_search" \
- -H "Authorization: ApiKey ${API_KEY}" \
- -H "Content-Type: application/json" \
- -d '
- {
- "knn": {
- "field": "image-vector",
- "query_vector": [
- -5,
- 9,
- -12
- ],
- "k": 10,
- "num_candidates": 100
- },
- "fields": [
- "title",
- "file-type"
- ]
- }
- '
- ```
- {/* TEST[continued] */}
- {/* TEST[s/"k": 10/"k": 3/] */}
- {/* TEST[s/"num_candidates": 100/"num_candidates": 3/] */}
-
-The [document `_score`](((ref))/search-search.html#search-api-response-body-score) is determined by
-the similarity between the query and document vector. See
-[`similarity`](((ref))/dense-vector.html#dense-vector-similarity) for more information on how kNN
-search scores are computed.
-
-### Tune approximate kNN for speed or accuracy
-
-To gather results, the kNN search API finds a `num_candidates` number of
-approximate nearest neighbor candidates on each shard. The search computes the
-similarity of these candidate vectors to the query vector, selecting the `k`
-most similar results from each shard. The search then merges the results from
-each shard to return the global top `k` nearest neighbors.
-
-You can increase `num_candidates` for more accurate results at the cost of
-slower search speeds. A search with a high value for `num_candidates`
-considers more candidates from each shard. This takes more time, but the
-search has a higher probability of finding the true `k` top nearest neighbors.
-
-Similarly, you can decrease `num_candidates` for faster searches with
-potentially less accurate results.
-
-
-
-### Approximate kNN using byte vectors
-
-The approximate kNN search API supports `byte` value vectors in
-addition to `float` value vectors. Use the [`knn` option](((ref))/knn-search.html#approximate-knn)
-to search a `dense_vector` field with [`element_type`](((ref))/dense-vector.html#dense-vector-params) set to
-`byte` and indexing enabled.
-
-1. Explicitly map one or more `dense_vector` fields with
- [`element_type`](((ref))/dense-vector.html#dense-vector-params) set to `byte` and indexing enabled.
-
- ```bash
- curl -X PUT "${ES_URL}/byte-image-index" \
- -H "Authorization: ApiKey ${API_KEY}" \
- -H "Content-Type: application/json" \
- -d '
- {
- "mappings": {
- "properties": {
- "byte-image-vector": {
- "type": "dense_vector",
- "element_type": "byte",
- "dims": 2
- },
- "title": {
- "type": "text"
- }
- }
- }
- }
- '
- ```
- {/* TEST[continued] */}
-
-1. Index your data ensuring all vector values
- are integers within the range [-128, 127].
-
- ```bash
- curl -X POST "${ES_URL}/byte-image-index/_bulk?refresh=true" \
- -H "Authorization: ApiKey ${API_KEY}" \
- -H "Content-Type: application/json" \
- -d '
- { "index": { "_id": "1" } }
- { "byte-image-vector": [5, -20], "title": "moose family" }
- { "index": { "_id": "2" } }
- { "byte-image-vector": [8, -15], "title": "alpine lake" }
- { "index": { "_id": "3" } }
- { "byte-image-vector": [11, 23], "title": "full moon" }
- '
- ```
- {/* TEST[continued] */}
-
-1. Run the search using the [`knn` option](((ref))/knn-search.html#approximate-knn)
- ensuring the `query_vector` values are integers within the
- range [-128, 127].
-
- ```bash
- curl -X POST "${ES_URL}/byte-image-index/_search" \
- -H "Authorization: ApiKey ${API_KEY}" \
- -H "Content-Type: application/json" \
- -d '
- {
- "knn": {
- "field": "byte-image-vector",
- "query_vector": [
- -5,
- 9
- ],
- "k": 10,
- "num_candidates": 100
- },
- "fields": [
- "title"
- ]
- }
- '
- ```
- {/* TEST[continued] */}
- {/* TEST[s/"k": 10/"k": 3/] */}
- {/* TEST[s/"num_candidates": 100/"num_candidates": 3/] */}
-
-
-### Filtered kNN search
-
-The kNN search API supports restricting the search using a filter. The search
-will return the top `k` documents that also match the filter query.
-
-The following request performs an approximate kNN search filtered by the
-`file-type` field:
-
-```bash
-curl -X POST "${ES_URL}/image-index/_search" \
--H "Authorization: ApiKey ${API_KEY}" \
--H "Content-Type: application/json" \
--d '
-{
- "knn": {
- "field": "image-vector",
- "query_vector": [54, 10, -2],
- "k": 5,
- "num_candidates": 50,
- "filter": {
- "term": {
- "file-type": "png"
- }
- }
- },
- "fields": ["title"],
- "_source": false
-}
-'
-```
-{/* TEST[continued] */}
-
-
-The filter is applied **during** the approximate kNN search to ensure
-that `k` matching documents are returned. This contrasts with a
-post-filtering approach, where the filter is applied **after** the approximate
-kNN search completes. Post-filtering has the downside that it sometimes
-returns fewer than k results, even when there are enough matching documents.
-
-
-### Combine approximate kNN with other features
-
-You can perform 'hybrid retrieval' by providing both the
-[`knn` option](((ref))/knn-search.html#approximate-knn) and a [`query`](((ref))/search-search.html#request-body-search-query):
-
-```bash
-curl -X POST "${ES_URL}/image-index/_search" \
--H "Authorization: ApiKey ${API_KEY}" \
--H "Content-Type: application/json" \
--d '
-{
- "query": {
- "match": {
- "title": {
- "query": "mountain lake",
- "boost": 0.9
- }
- }
- },
- "knn": {
- "field": "image-vector",
- "query_vector": [54, 10, -2],
- "k": 5,
- "num_candidates": 50,
- "boost": 0.1
- },
- "size": 10
-}
-'
-```
-{/* TEST[continued] */}
-
-This search finds the global top `k = 5` vector matches, combines them with the matches from the `match` query, and
-finally returns the 10 top-scoring results. The `knn` and `query` matches are combined through a disjunction, as if you
-took a boolean 'or' between them. The top `k` vector results represent the global nearest neighbors across all index
-shards.
-
-The score of each hit is the sum of the `knn` and `query` scores. You can specify a `boost` value to give a weight to
-each score in the sum. In the example above, the scores will be calculated as
-
-```txt
-score = 0.9 * match_score + 0.1 * knn_score
-```
-
-The `knn` option can also be used with `aggregations`.
-In general, ((es)) computes aggregations over all documents that match the search.
-So for approximate kNN search, aggregations are calculated on the top `k`
-nearest documents. If the search also includes a `query`, then aggregations are
-calculated on the combined set of `knn` and `query` matches.
-
-### Perform semantic search
-
-kNN search enables you to perform semantic search by using a previously deployed
-[text embedding model](((ml-docs))/ml-nlp-search-compare.html#ml-nlp-text-embedding).
-Instead of literal matching on search terms, semantic search retrieves results
-based on the intent and the contextual meaning of a search query.
-
-Under the hood, the text embedding NLP model generates a dense vector from the
-input query string called `model_text` you provide. Then, it is searched
-against an index containing dense vectors created with the same text embedding
-((ml)) model. The search results are semantically similar as learned by the model.
-
-
-
-To perform semantic search:
-
-* you need an index that contains the dense vector representation of the input
- data to search against,
-
-* you must use the same text embedding model for search that you used to create
- the dense vectors from the input data,
-
-* the text embedding NLP model deployment must be started.
-
-
-
-Reference the deployed text embedding model or the model deployment in the
-`query_vector_builder` object and provide the search query as `model_text`:
-
-{/* NOTCONSOLE */}
-```js
-(...)
-{
- "knn": {
- "field": "dense-vector-field",
- "k": 10,
- "num_candidates": 100,
- "query_vector_builder": {
- "text_embedding": { [^1]
- "model_id": "my-text-embedding-model", [^2]
- "model_text": "The opposite of blue" [^3]
- }
- }
- }
-}
-(...)
-```
-[^1]: The ((nlp)) task to perform. It must be `text_embedding`.
-[^2]: The ID of the text embedding model to use to generate the dense vectors from
-the query string. Use the same model that generated the embeddings from the
-input text in the index you search against. You can use the value of the
-`deployment_id` instead in the `model_id` argument.
-[^3]: The query string from which the model generates the dense vector
-representation.
-
-For more information on how to deploy a trained model and use it to create text
-embeddings, refer to this
-[end-to-end example](((ml-docs))/ml-nlp-text-emb-vector-search-example.html).
-
-### Search multiple kNN fields
-
-In addition to 'hybrid retrieval', you can search more than one kNN vector field at a time:
-
-```bash
-curl -X POST "${ES_URL}/image-index/_search" \
--H "Authorization: ApiKey ${API_KEY}" \
--H "Content-Type: application/json" \
--d '
-{
- "query": {
- "match": {
- "title": {
- "query": "mountain lake",
- "boost": 0.9
- }
- }
- },
- "knn": [ {
- "field": "image-vector",
- "query_vector": [54, 10, -2],
- "k": 5,
- "num_candidates": 50,
- "boost": 0.1
- },
- {
- "field": "title-vector",
- "query_vector": [1, 20, -52, 23, 10],
- "k": 10,
- "num_candidates": 10,
- "boost": 0.5
- }],
- "size": 10
-}
-'
-```
-{/* TEST[continued] */}
-
-This search finds the global top `k = 5` vector matches for `image-vector` and the global `k = 10` for the `title-vector`.
-These top values are then combined with the matches from the `match` query and the top-10 documents are returned.
-The multiple `knn` entries and the `query` matches are combined through a disjunction,
-as if you took a boolean 'or' between them. The top `k` vector results represent the global nearest neighbors across
-all index shards.
-
-The scoring for a doc with the above configured boosts would be:
-
-```txt
-score = 0.9 * match_score + 0.1 * knn_score_image-vector + 0.5 * knn_score_title-vector
-```
-
-### Search kNN with expected similarity
-
-While kNN is a powerful tool, it always tries to return `k` nearest neighbors. Consequently, when using `knn` with
-a `filter`, you could filter out all relevant documents and only have irrelevant ones left to search. In that situation,
-`knn` will still do its best to return `k` nearest neighbors, even though those neighbors could be far away in the
-vector space.
-
-To alleviate this worry, there is a `similarity` parameter available in the `knn` clause. This value is the required
-minimum similarity for a vector to be considered a match. The `knn` search flow with this parameter is as follows:
-
-* Apply any user provided `filter` queries
-* Explore the vector space to get `k` vectors
-* Do not return any vectors that are further away than the configured `similarity`
-
-Here is an example. In this example we search for the given `query_vector` for `k` nearest neighbors. However, with
-`filter` applied and requiring that the found vectors have at least the provided `similarity` between them.
-
-```bash
-curl -X POST "${ES_URL}/image-index/_search" \
--H "Authorization: ApiKey ${API_KEY}" \
--H "Content-Type: application/json" \
--d '
-{
- "knn": {
- "field": "image-vector",
- "query_vector": [1, 5, -20],
- "k": 5,
- "num_candidates": 50,
- "similarity": 36,
- "filter": {
- "term": {
- "file-type": "png"
- }
- }
- },
- "fields": ["title"],
- "_source": false
-}
-'
-```
-{/* TEST[continued] */}
-
-In our data set, the only document with the file type of `png` has a vector of `[42, 8, -15]`. The `l2_norm` distance
-between `[42, 8, -15]` and `[1, 5, -20]` is `41.412`, which is greater than the configured similarity of `36`. Meaning,
-this search will return no hits.
-
-
-
-### Nested kNN Search
-
-It is common for text to exceed a particular model's token limit and requires chunking before building the embeddings
-for individual chunks. When using [`nested`](((ref))/nested.html) with [`dense_vector`](((ref))/dense-vector.html), you can achieve nearest
-passage retrieval without copying top-level document metadata.
-
-Here is a simple passage vectors index that stores vectors and some top-level metadata for filtering.
-
-```bash
-curl -X PUT "${ES_URL}/passage_vectors" \
--H "Authorization: ApiKey ${API_KEY}" \
--H "Content-Type: application/json" \
--d '
-{
- "mappings": {
- "properties": {
- "full_text": {
- "type": "text"
- },
- "creation_time": {
- "type": "date"
- },
- "paragraph": {
- "type": "nested",
- "properties": {
- "vector": {
- "type": "dense_vector",
- "dims": 2
- },
- "text": {
- "type": "text",
- "index": false
- }
- }
- }
- }
- }
-}
-'
-```
-{/* TEST[continued] */}
-
-With the above mapping, we can index multiple passage vectors along with storing the individual passage text.
-
-```bash
-curl -X POST "${ES_URL}/passage_vectors/_bulk?refresh=true" \
--H "Authorization: ApiKey ${API_KEY}" \
--H "Content-Type: application/json" \
--d '
-{ "index": { "_id": "1" } }
-{ "full_text": "first paragraph another paragraph", "creation_time": "2019-05-04", "paragraph": [ { "vector": [ 0.45, 45 ], "text": "first paragraph", "paragraph_id": "1" }, { "vector": [ 0.8, 0.6 ], "text": "another paragraph", "paragraph_id": "2" } ] }
-{ "index": { "_id": "2" } }
-{ "full_text": "number one paragraph number two paragraph", "creation_time": "2020-05-04", "paragraph": [ { "vector": [ 1.2, 4.5 ], "text": "number one paragraph", "paragraph_id": "1" }, { "vector": [ -1, 42 ], "text": "number two paragraph", "paragraph_id": "2" } ] }
-'
-```
-{/* TEST[continued] */}
-{/* TEST[s/\.\.\.//] */}
-
-The query will seem very similar to a typical kNN search:
-
-```bash
-curl -X POST "${ES_URL}/passage_vectors/_search" \
--H "Authorization: ApiKey ${API_KEY}" \
--H "Content-Type: application/json" \
--d '
-{
- "fields": ["full_text", "creation_time"],
- "_source": false,
- "knn": {
- "query_vector": [
- 0.45,
- 45
- ],
- "field": "paragraph.vector",
- "k": 2,
- "num_candidates": 2
- }
-}
-'
-```
-{/* TEST[continued] */}
-
-Note below that even though we have 4 total vectors, we still return two documents. kNN search over nested dense_vectors
-will always diversify the top results over the top-level document. Meaning, `"k"` top-level documents will be returned,
-scored by their nearest passage vector (e.g. `"paragraph.vector"`).
-
-```console-result
-{
- "took": 4,
- "timed_out": false,
- "_shards": {
- "total": 1,
- "successful": 1,
- "skipped": 0,
- "failed": 0
- },
- "hits": {
- "total": {
- "value": 2,
- "relation": "eq"
- },
- "max_score": 1.0,
- "hits": [
- {
- "_index": "passage_vectors",
- "_id": "1",
- "_score": 1.0,
- "fields": {
- "creation_time": [
- "2019-05-04T00:00:00.000Z"
- ],
- "full_text": [
- "first paragraph another paragraph"
- ]
- }
- },
- {
- "_index": "passage_vectors",
- "_id": "2",
- "_score": 0.9997144,
- "fields": {
- "creation_time": [
- "2020-05-04T00:00:00.000Z"
- ],
- "full_text": [
- "number one paragraph number two paragraph"
- ]
- }
- }
- ]
- }
-}
-```
-{/* TESTRESPONSE[s/"took": 4/"took" : "$body.took"/] */}
-
-What if you wanted to filter by some top-level document metadata? You can do this by adding `filter` to your
-`knn` clause.
-
-
-`filter` will always be over the top-level document metadata. This means you cannot filter based on `nested`
- field metadata.
-
-
-```bash
-curl -X POST "${ES_URL}/passage_vectors/_search" \
--H "Authorization: ApiKey ${API_KEY}" \
--H "Content-Type: application/json" \
--d '
-{
- "fields": [
- "creation_time",
- "full_text"
- ],
- "_source": false,
- "knn": {
- "query_vector": [
- 0.45,
- 45
- ],
- "field": "paragraph.vector",
- "k": 2,
- "num_candidates": 2,
- "filter": {
- "bool": {
- "filter": [
- {
- "range": {
- "creation_time": {
- "gte": "2019-05-01",
- "lte": "2019-05-05"
- }
- }
- }
- ]
- }
- }
- }
-}
-'
-```
-{/* TEST[continued] */}
-
-Now we have filtered based on the top level `"creation_time"` and only one document falls within that range.
-
-```console-result
-{
- "took": 4,
- "timed_out": false,
- "_shards": {
- "total": 1,
- "successful": 1,
- "skipped": 0,
- "failed": 0
- },
- "hits": {
- "total": {
- "value": 1,
- "relation": "eq"
- },
- "max_score": 1.0,
- "hits": [
- {
- "_index": "passage_vectors",
- "_id": "1",
- "_score": 1.0,
- "fields": {
- "creation_time": [
- "2019-05-04T00:00:00.000Z"
- ],
- "full_text": [
- "first paragraph another paragraph"
- ]
- }
- }
- ]
- }
-}
-```
-{/* TESTRESPONSE[s/"took": 4/"took" : "$body.took"/] */}
-
-Additionally, if you wanted to extract the nearest passage for a matched document, you can supply [inner_hits](((ref))/inner-hits.html)
-to the `knn` clause.
-
-
-`inner_hits` for kNN will only ever return a single hit, the nearest passage vector.
-Setting `"size"` to any value greater than `1` will have no effect on the results.
-
-
-```bash
-curl -X POST "${ES_URL}/passage_vectors/_search" \
--H "Authorization: ApiKey ${API_KEY}" \
--H "Content-Type: application/json" \
--d '
-{
- "fields": [
- "creation_time",
- "full_text"
- ],
- "_source": false,
- "knn": {
- "query_vector": [
- 0.45,
- 45
- ],
- "field": "paragraph.vector",
- "k": 2,
- "num_candidates": 2,
- "inner_hits": {
- "_source": false,
- "fields": [
- "paragraph.text"
- ]
- }
- }
-}
-'
-```
-{/* TEST[continued] */}
-
-Now the result will contain the nearest found paragraph when searching.
-
-```console-result
-{
- "took": 4,
- "timed_out": false,
- "_shards": {
- "total": 1,
- "successful": 1,
- "skipped": 0,
- "failed": 0
- },
- "hits": {
- "total": {
- "value": 2,
- "relation": "eq"
- },
- "max_score": 1.0,
- "hits": [
- {
- "_index": "passage_vectors",
- "_id": "1",
- "_score": 1.0,
- "fields": {
- "creation_time": [
- "2019-05-04T00:00:00.000Z"
- ],
- "full_text": [
- "first paragraph another paragraph"
- ]
- },
- "inner_hits": {
- "paragraph": {
- "hits": {
- "total": {
- "value": 1,
- "relation": "eq"
- },
- "max_score": 1.0,
- "hits": [
- {
- "_index": "passage_vectors",
- "_id": "1",
- "_nested": {
- "field": "paragraph",
- "offset": 0
- },
- "_score": 1.0,
- "fields": {
- "paragraph": [
- {
- "text": [
- "first paragraph"
- ]
- }
- ]
- }
- }
- ]
- }
- }
- }
- },
- {
- "_index": "passage_vectors",
- "_id": "2",
- "_score": 0.9997144,
- "fields": {
- "creation_time": [
- "2020-05-04T00:00:00.000Z"
- ],
- "full_text": [
- "number one paragraph number two paragraph"
- ]
- },
- "inner_hits": {
- "paragraph": {
- "hits": {
- "total": {
- "value": 1,
- "relation": "eq"
- },
- "max_score": 0.9997144,
- "hits": [
- {
- "_index": "passage_vectors",
- "_id": "2",
- "_nested": {
- "field": "paragraph",
- "offset": 1
- },
- "_score": 0.9997144,
- "fields": {
- "paragraph": [
- {
- "text": [
- "number two paragraph"
- ]
- }
- ]
- }
- }
- ]
- }
- }
- }
- }
- ]
- }
-}
-```
-{/* TESTRESPONSE[s/"took": 4/"took" : "$body.took"/] */}
-
-
-
-### Indexing considerations
-
-For approximate kNN search, ((es)) stores the dense vector values of each
-segment as an [HNSW graph](https://arxiv.org/abs/1603.09320). Indexing vectors for
-approximate kNN search can take substantial time because of how expensive it is
-to build these graphs. You may need to increase the client request timeout for
-index and bulk requests. The [approximate kNN tuning guide](((ref))/tune-knn-search.html)
-contains important guidance around indexing performance, and how the index
-configuration can affect search performance.
-
-In addition to its search-time tuning parameters, the HNSW algorithm has
-index-time parameters that trade off between the cost of building the graph,
-search speed, and accuracy. When setting up the `dense_vector` mapping, you
-can use the [`index_options`](((ref))/dense-vector.html#dense-vector-index-options) argument to adjust
-these parameters:
-
-```bash
-curl -X PUT "${ES_URL}/image-index" \
--H "Authorization: ApiKey ${API_KEY}" \
--H "Content-Type: application/json" \
--d '
-{
- "mappings": {
- "properties": {
- "image-vector": {
- "type": "dense_vector",
- "dims": 3,
- "index": true,
- "similarity": "l2_norm",
- "index_options": {
- "type": "hnsw",
- "m": 32,
- "ef_construction": 100
- }
- }
- }
- }
-}
-'
-```
-
-### Limitations for approximate kNN search
-
-((es)) uses the [HNSW algorithm](https://arxiv.org/abs/1603.09320) to support
-efficient kNN search. Like most kNN algorithms, HNSW is an approximate method
-that sacrifices result accuracy for improved search speed. This means the
-results returned are not always the true _k_ closest neighbors.
-
-
-Approximate kNN search always uses the
-[`dfs_query_then_fetch`](((ref))/search-search.html#dfs-query-then-fetch) search type in order to gather
-the global top `k` matches across shards. You cannot set the
-`search_type` explicitly when running kNN search.
-
-
-
-
-## Exact kNN
-
-To run an exact kNN search, use a `script_score` query with a vector function.
-
-1. Explicitly map one or more `dense_vector` fields. If you don't intend to use
- the field for approximate kNN, set the `index` mapping option to `false`.
- This can significantly improve indexing speed.
-
- ```bash
- curl -X PUT "${ES_URL}/product-index" \
- -H "Authorization: ApiKey ${API_KEY}" \
- -H "Content-Type: application/json" \
- -d '
- {
- "mappings": {
- "properties": {
- "product-vector": {
- "type": "dense_vector",
- "dims": 5,
- "index": false
- },
- "price": {
- "type": "long"
- }
- }
- }
- }
- '
- ```
-
-1. Index your data.
-
- ```bash
- curl -X POST "${ES_URL}/product-index/_bulk?refresh=true" \
- -H "Authorization: ApiKey ${API_KEY}" \
- -H "Content-Type: application/json" \
- -d '
- { "index": { "_id": "1" } }
- { "product-vector": [230.0, 300.33, -34.8988, 15.555, -200.0], "price": 1599 }
- { "index": { "_id": "2" } }
- { "product-vector": [-0.5, 100.0, -13.0, 14.8, -156.0], "price": 799 }
- { "index": { "_id": "3" } }
- { "product-vector": [0.5, 111.3, -13.0, 14.8, -156.0], "price": 1099 }
- ...
- '
- ```
- {/* TEST[continued] */}
- {/* TEST[s/\.\.\.//] */}
-
-1. Use the search API to run a `script_score` query containing
- a [vector function](((ref))/query-dsl-script-score-query.html#vector-functions).
-
-
-To limit the number of matched documents passed to the vector function, we
-recommend you specify a filter query in the `script_score.query` parameter. If
-needed, you can use a [`match_all` query](((ref))/query-dsl-match-all-query.html) in this
-parameter to match all documents. However, matching all documents can
-significantly increase search latency.
-
- ```bash
- curl -X POST "${ES_URL}/product-index/_search" \
- -H "Authorization: ApiKey ${API_KEY}" \
- -H "Content-Type: application/json" \
- -d '
- {
- "query": {
- "script_score": {
- "query": {
- "bool": {
- "filter": {
- "range": {
- "price": {
- "gte": 1000
- }
- }
- }
- }
- },
- "script": {
- "source": "cosineSimilarity(params.queryVector, 'product-vector') + 1.0",
- "params": {
- "queryVector": [
- -0.5,
- 90,
- -10,
- 14.8,
- -156
- ]
- }
- }
- }
- }
- }
- '
- ```
- {/* TEST[continued] */}
-
-
diff --git a/serverless/pages/logstash-pipelines.mdx b/serverless/pages/logstash-pipelines.mdx
deleted file mode 100644
index d563c305..00000000
--- a/serverless/pages/logstash-pipelines.mdx
+++ /dev/null
@@ -1,72 +0,0 @@
----
-slug: /serverless/logstash-pipelines
-title: ((ls-pipelines))
-description: Create, edit, and delete your ((ls)) pipeline configurations.
-tags: [ 'serverless', 'Elasticsearch', 'Observability', 'Security' ]
----
-
-
-This content applies to:
-
-In **((project-settings)) → ((manage-app)) → ((ls-pipelines-app))**, you can control multiple ((ls)) instances and pipeline configurations.
-
-
-
-On the ((ls)) side, you must enable configuration management and register ((ls)) to use the centrally managed pipeline configurations.
-
-
-After you configure ((ls)) to use centralized pipeline management, you can no longer specify local pipeline configurations.
-The `pipelines.yml` file and settings such as `path.config` and `config.string` are inactive when centralized pipeline management is enabled.
-
-
-## Manage pipelines
-
-{/*
-TBD: What is the appropriate RBAC for serverless?
-If ((kib)) is protected with basic authentication, make sure your ((kib)) user has
-the `logstash_admin` role as well as the `logstash_writer` role that you created
-when you configured Logstash to use basic authentication. Additionally,
-in order to view (as read-only) non-centrally-managed pipelines in the pipeline management
-UI, make sure your ((kib)) user has the `monitoring_user` role as well.
-*/}
-
-1. [Configure centralized pipeline management](((logstash-ref))/configuring-centralized-pipelines.html).
-1. To add a new pipeline, go to **((project-settings)) → ((manage-app)) → ((ls-pipelines-app))** and click **Create pipeline**. Provide the following details, then click **Create and deploy**.
-
-Pipeline ID
-: A name that uniquely identifies the pipeline.
- This is the ID that you used when you configured centralized pipeline management and specified a list of pipeline IDs in the `xpack.management.pipeline.id` setting.
-
-Description
-: A description of the pipeline configuration. This information is for your use.
-
-Pipeline
-: The pipeline configuration.
- You can treat the editor like any other editor.
- You don't have to worry about whitespace or indentation.
-
-Pipeline workers
-: The number of parallel workers used to run the filter and output stages of the pipeline.
-
-Pipeline batch size
-: The maximum number of events an individual worker thread collects before
-executing filters and outputs.
-
-Pipeline batch delay
-: Time in milliseconds to wait for each event before sending an undersized
-batch to pipeline workers.
-
-Queue type
-: The internal queueing model for event buffering.
- Options are `memory` for in-memory queueing and `persisted` for disk-based acknowledged queueing.
-
-Queue max bytes
-: The total capacity of the queue when persistent queues are enabled.
-
-Queue checkpoint writes
-: The maximum number of events written before a checkpoint is forced when
-persistent queues are enabled.
-
-To delete one or more pipelines, select their checkboxes then click **Delete**.
-
-For more information about pipeline behavior, go to [Centralized Pipeline Management](((logstash-ref))/logstash-centralized-pipeline-management.html#_pipeline_behavior).
diff --git a/serverless/pages/machine-learning.mdx b/serverless/pages/machine-learning.mdx
deleted file mode 100644
index dfaa5472..00000000
--- a/serverless/pages/machine-learning.mdx
+++ /dev/null
@@ -1,43 +0,0 @@
----
-slug: /serverless/machine-learning
-title: ((ml-cap))
-description: View, export, and import ((ml)) jobs and models.
-tags: [ 'serverless', 'Elasticsearch', 'Observability', 'Security' ]
----
-
-
-This content applies to:
-
-To view your ((ml)) resources, go to **((project-settings)) → ((manage-app)) → ((ml-app))**:
-
-
-{/* TO-DO: This screenshot should be automated. */}
-
-The ((ml-features)) that are available vary by project type:
-
-- ((es-serverless)) projects have trained models.
-- ((observability)) projects have ((anomaly-jobs)).
-- ((security)) projects have ((anomaly-jobs)), ((dfanalytics-jobs)), and trained models.
-
-For more information, go to [((anomaly-detect-cap))](((ml-docs))/ml-ad-overview.html), [((dfanalytics-cap))](((ml-docs))/ml-dfanalytics.html) and [Natural language processing](((ml-docs))/ml-nlp.html).
-
-## Synchronize saved objects
-
-Before you can view your ((ml)) ((dfeeds)), jobs, and trained models in ((kib)), they must have saved objects.
-For example, if you used APIs to create your jobs, wait for automatic synchronization or go to the **((ml-app))** page and click **Synchronize saved objects**.
-
-## Export and import jobs
-
-You can export and import your ((ml)) job and ((dfeed)) configuration details on the **((ml-app))** page.
-For example, you can export jobs from your test environment and import them in your production environment.
-
-The exported file contains configuration details; it does not contain the ((ml)) models.
-For ((anomaly-detect)), you must import and run the job to build a model that is accurate for the new environment.
-For ((dfanalytics)), trained models are portable; you can import the job then transfer the model to the new cluster.
-Refer to [Exporting and importing ((dfanalytics)) trained models](((ml-docs))/ml-trained-models.html#export-import).
-
-There are some additional actions that you must take before you can successfully import and run your jobs:
-
-- The ((data-sources)) that are used by ((anomaly-detect)) ((dfeeds)) and ((dfanalytics)) source indices must exist; otherwise, the import fails.
-- If your ((anomaly-jobs)) use custom rules with filter lists, the filter lists must exist; otherwise, the import fails.
-- If your ((anomaly-jobs)) were associated with calendars, you must create the calendar in the new environment and add your imported jobs to the calendar.
\ No newline at end of file
diff --git a/serverless/pages/maintenance-windows.mdx b/serverless/pages/maintenance-windows.mdx
deleted file mode 100644
index e215d362..00000000
--- a/serverless/pages/maintenance-windows.mdx
+++ /dev/null
@@ -1,62 +0,0 @@
----
-slug: /serverless/maintenance-windows
-title: ((maint-windows-cap))
-description: Suppress rule notifications for scheduled periods of time.
-tags: [ 'serverless', 'Observability', 'Security' ]
----
-
-
-This content applies to:
-
-
-You can schedule single or recurring ((maint-windows)) to temporarily reduce rule notifications.
-For example, a maintenance window prevents false alarms during planned outages.
-
-Alerts continue to be generated, however notifications are suppressed as follows:
-
-- When an alert occurs during a maintenance window, there are no notifications.
-When the alert recovers, there are no notifications--even if the recovery occurs after the maintenance window ends.
-- When an alert occurs before a maintenance window and recovers during or after the maintenance window, notifications are sent as usual.
-
-{/*
-TBD: What RBAC requirements exist in serverless?
-## Configure access to maintenance windows
-
-To use maintenance windows, you must have the appropriate [subscription](((subscriptions))) and ((kib)) feature privileges.
-
-- To have full access to maintenance windows, you must have `All` privileges for the **Management → Maintenance Windows*** feature.
-- To have view-only access to maintenance windows, you must have `Read` privileges for the **Management → Maintenance Windows* feature.
-
-For more details, refer to ((kib)) privileges.
-*/}
-
-## Create and manage ((maint-windows))
-
-In **((project-settings)) → ((manage-app)) → ((maint-windows-app))** you can create, edit, and archive ((maint-windows)).
-
-When you create a maintenance window, you must provide a name and a schedule.
-You can optionally configure it to repeat daily, monthly, yearly, or on a custom interval.
-
-
-{/* NOTE: This is an autogenerated screenshot. Do not edit it directly. */}
-
-If you turn on **Filter alerts**, you can use KQL to filter the alerts affected by the maintenance window.
-For example, you can suppress notifications for alerts from specific rules:
-
-
-{/* NOTE: This is an autogenerated screenshot. Do not edit it directly. */}
-
-
-- You can select only a single category when you turn on filters.
-- Some rules are not affected by maintenance window filters because their alerts do not contain requisite data.
-In particular, [((stack-monitor-app))](((kibana-ref))/kibana-alerts.html), [tracking containment](((kibana-ref))/geo-alerting.html), [((anomaly-jobs)) health](((ml-docs))/ml-configuring-alerts.html), and [transform health](((ref))/transform-alerts.html) rules are not affected by the filters.
-
-
-A maintenance window can have any one of the following statuses:
-
-- `Upcoming`: It will run at the scheduled date and time.
-- `Running`: It is running.
-- `Finished`: It ended and does not have a repeat schedule.
-- `Archived`: It is archived. In a future release, archived ((maint-windows)) will be queued for deletion.
-
-When you view alert details in ((kib)), each alert shows unique identifiers for ((maint-windows)) that affected it.
\ No newline at end of file
diff --git a/serverless/pages/manage-access-to-org-from-existing-account.mdx b/serverless/pages/manage-access-to-org-from-existing-account.mdx
deleted file mode 100644
index 34875101..00000000
--- a/serverless/pages/manage-access-to-org-from-existing-account.mdx
+++ /dev/null
@@ -1,18 +0,0 @@
----
-slug: /serverless/general/join-organization-from-existing-cloud-account
-title: Join an organization from an existing Elastic Cloud account
-description: Join a new organization and bring over your projects.
-tags: [ 'serverless', 'general', 'organization', 'join', 'how to' ]
----
-
-
-
-If you already belong to an organization, and you want to join a new one, it is currently not possible to bring your projects over to the new organization.
-
-If you want to join a new project, follow these steps:
-
-1. Make sure you do not have active projects before you leave your current organization.
-1. Delete your projects and clear any bills.
-1. Leave your current organization.
-1. Ask the administrator to invite you to the organization you want to join.
-1. Accept the invitation that you will get by email.
\ No newline at end of file
diff --git a/serverless/pages/manage-access-to-org-user-roles.mdx b/serverless/pages/manage-access-to-org-user-roles.mdx
deleted file mode 100644
index d264c407..00000000
--- a/serverless/pages/manage-access-to-org-user-roles.mdx
+++ /dev/null
@@ -1,83 +0,0 @@
----
-slug: /serverless/general/assign-user-roles
-title: Assign user roles and privileges
-description: Manage the predefined set of roles and privileges for all your projects.
-tags: [ 'serverless', 'general', 'organization', 'roles', 'how to' ]
----
-
-
-Within an organization, users can have one or more roles and each role grants specific privileges.
-
-You must assign user roles when you invite users to join your organization.
-To subsequently edit the roles assigned to a user:
-
-1. Go to the user icon on the header bar and select **Organization**.
-
-2. Find the user on the **Members** tab of the **Organization** page. Click the member name to view and edit its roles.
-
-## Organization-level roles
-
-- **Organization owner**. Can manage all roles under the organization and has full access to all serverless projects, organization-level details, billing details, and subscription levels. This role is assigned by default to the person who created the organization.
-
-- **Billing admin**. Has access to all invoices and payment methods. Can make subscription changes.
-
-## Instance access roles
-
-Each serverless project type has a set of predefined roles that you can assign to your organization members.
-You can assign the predefined roles:
-
-- globally, for all projects of the same type (((es-serverless)), ((observability)), or ((security))). In this case, the role will also apply to new projects created later.
-- individually, for specific projects only. To do that, you have to set the **Role for all** field of that specific project type to **None**.
-
-For example, you can assign a user the developer role for a specific ((es-serverless)) project:
-
-
-
-
-You can also optionally create custom roles in a project.
-To assign a custom role to users, go to "Instance access roles" and select it from the list under the specific project it was created in.
-
-
-### ((es))
-
-- **Admin**. Has full access to project management, properties, and security privileges. Admins log into projects with superuser role privileges.
-
-- **Developer**. Creates API keys, indices, data streams, adds connectors, and builds visualizations.
-
-- **Viewer**. Has read-only access to project details, data, and features.
-
-### ((observability))
-
-- **Admin**. Has full access to project management, properties, and security privileges. Admins log into projects with superuser role privileges.
-
-- **Editor**. Configures all Observability projects. Has read-only access to data indices. Has full access to all project features.
-
-- **Viewer**. Has read-only access to project details, data, and features.
-
-### ((security))
-
-- **Admin**. Has full access to project management, properties, and security privileges. Admins log into projects with superuser role privileges.
-
-- **Editor**. Configures all Security projects. Has read-only access to data indices. Has full access to all project features.
-
-- **Viewer**. Has read-only access to project details, data, and features.
-
-- **Tier 1 analyst**. Ideal for initial alert triage. General read access, can create dashboards and visualizations.
-
-- **Tier 2 analyst**. Ideal for alert triage and beginning the investigation process. Can create cases.
-
-- **Tier 3 analyst**. Deeper investigation capabilities. Access to rules, lists, cases, Osquery, and response actions.
-
-- **Threat intelligence analyst**. Access to alerts, investigation tools, and intelligence pages.
-
-- **Rule author**. Access to detection engineering and rule creation. Can create rules from available data sources and add exceptions to reduce false positives.
-
-- **SOC manager**. Access to alerts, cases, investigation tools, endpoint policy management, and response actions.
-
-- **Endpoint operations analyst**. Access to endpoint response actions. Can manage endpoint policies, ((fleet)), and integrations.
-
-- **Platform engineer**. Access to ((fleet)), integrations, endpoints, and detection content.
-
-- **Detections admin**. All available detection engine permissions to include creating rule actions, such as notifications to third-party systems.
-
-- **Endpoint policy manager**. Access to endpoint policy management and related artifacts. Can manage ((fleet)) and integrations.
diff --git a/serverless/pages/manage-access-to-org.mdx b/serverless/pages/manage-access-to-org.mdx
deleted file mode 100644
index d40a57e4..00000000
--- a/serverless/pages/manage-access-to-org.mdx
+++ /dev/null
@@ -1,33 +0,0 @@
----
-slug: /serverless/general/manage-access-to-organization
-title: Invite your team
-description: Add members to your organization and projects.
-tags: [ 'serverless', 'general', 'organization', 'overview' ]
----
-
-To allow other users to interact with your projects, you must invite them to join your organization and grant them access to your organization resources and instances.
-
-Alternatively, [configure ((ecloud)) SAML SSO](((cloud))/ec-saml-sso.html) to enable your organization members to join the ((ecloud)) organization automatically.
-
-1. Go to the user icon on the header bar and select **Organization**.
-
-2. Click **Invite members**.
-
- You can add multiple members by entering their email addresses separated by a space.
-
- You can grant access to all projects of the same type with a unique role, or select individual roles for specific projects.
- For more details about roles, refer to .
-
-3. Click **Send invites**.
-
- Invitations to join an organization are sent by email. Invited users have 72 hours to accept the invitation. If they do not join within that period, you will have to send a new invitation.
-
-On the **Members** tab of the **Organization** page, you can view the list of current members, their status and role.
-
-In the **Actions** column, click the three dots to edit a member’s role or revoke the invite.
-
-## Leave an organization
-
-On the **Organization** page, click **Leave organization**.
-
-If you're the only user in the organization, you can only leave if you have deleted all your projects and don't have any pending bills.
\ No newline at end of file
diff --git a/serverless/pages/manage-billing-check-subscription.mdx b/serverless/pages/manage-billing-check-subscription.mdx
deleted file mode 100644
index 934a8378..00000000
--- a/serverless/pages/manage-billing-check-subscription.mdx
+++ /dev/null
@@ -1,19 +0,0 @@
----
-slug: /serverless/general/check-subscription
-title: Check your subscription
-description: Manage your account details and subscription level.
-tags: [ 'serverless', 'general', 'billing', 'subscription' ]
----
-
-
-To find more details about your subscription:
-
-1. Navigate to [cloud.elastic.co](https://cloud.elastic.co/) and log in to your Elastic Cloud account.
-
-1. Go to the user icon on the header bar and select **Billing**.
-
-On the **Overview** page you can:
-
-- Update your subscription level
-- Check the date when your next bill will be issued and update the payment method
-- Check your account details and add Elastic Consumption Units (ECU) credits
diff --git a/serverless/pages/manage-billing-history.mdx b/serverless/pages/manage-billing-history.mdx
deleted file mode 100644
index ca227678..00000000
--- a/serverless/pages/manage-billing-history.mdx
+++ /dev/null
@@ -1,17 +0,0 @@
----
-slug: /serverless/general/billing-history
-title: Check your billing history
-description: Monitor payments and billing receipts.
-tags: [ 'serverless', 'general', 'billing', 'history' ]
----
-
-
-Information about outstanding payments and billing receipts is available from the [((ess-console-name))](((ess-console))).
-
-To check your billing history:
-
-1. Log in to the [((ess-console-name))](((ess-console))).
-
-2. Select the user icon on the header bar and choose **Billing** from the menu.
-
-3. Under the **History** tab, select the invoice number for a detailed PDF.
diff --git a/serverless/pages/manage-billing-monitor-usage.mdx b/serverless/pages/manage-billing-monitor-usage.mdx
deleted file mode 100644
index bedef158..00000000
--- a/serverless/pages/manage-billing-monitor-usage.mdx
+++ /dev/null
@@ -1,26 +0,0 @@
----
-slug: /serverless/general/monitor-usage
-title: Monitor your account usage
-description: Check the usage breakdown of your account.
-tags: [ 'serverless', 'general', 'billing', 'usage' ]
----
-
-
-To find more details about your account usage:
-
-1. Navigate to [cloud.elastic.co](https://cloud.elastic.co/) and log in to your ((ecloud)) account.
-
-2. Go to the user icon on the header bar and select **Billing**.
-
-On the **Usage** page you can:
-
-- Monitor the usage for the current month, including total hourly rate and month-to-date usage
-- Check the usage breakdown for a selected time range
-
-
-The usage breakdown information is an estimate. To get the exact amount you owe for a given month, check your invoices in the .
-
-
-
- When you create an Elasticsearch Serverless project, a minimum number of VCUs are always allocated to your project to maintain basic ingest and search capabilities. These VCUs incur a minimum cost even with no active usage. Learn more about [minimum VCUs on Elasticsearch Serverless](https://www.elastic.co/pricing/serverless-search#what-are-the-minimum-compute-resource-vcus-on-elasticsearch-serverless).
-
diff --git a/serverless/pages/manage-billing-pricing-model.mdx b/serverless/pages/manage-billing-pricing-model.mdx
deleted file mode 100644
index fc8cfd9e..00000000
--- a/serverless/pages/manage-billing-pricing-model.mdx
+++ /dev/null
@@ -1,43 +0,0 @@
----
-slug: /serverless/general/serverless-billing
-title: Serverless billing dimensions
-description: Understand how usage affects serverless pricing.
-tags: [ 'serverless', 'general', 'billing', 'pricing model' ]
----
-
-
-
-Elastic Cloud serverless billing is based on your usage across these dimensions:
-
-* Offerings
-* Add-ons
-
-
-
-## Offerings
-
-To learn about billing dimensions for specific offerings, refer to:
-
-*
-*
-*
-
-
-
-## Add-ons
-
-### Data out
-
-_Data out_ accounts for all of the traffic coming out of a serverless project.
-This includes search results, as well as monitoring data sent from the project.
-The same rate applies regardless of the destination of the data, whether to the internet,
-another region, or a cloud provider account in the same region.
-Data coming out of the project through AWS PrivateLink, GCP Private Service Connect,
-or Azure Private Link is also considered data out.
-
-
-### Support
-
-If your subscription level is Standard, there is no separate charge for Support reflected on your bill.
-If your subscription level is Gold, Platinum, or Enterprise, a charge is made for Support as a percentage (%) of the ECUs.
-To find out more about our support levels, go to https://www.elastic.co/support.
\ No newline at end of file
diff --git a/serverless/pages/manage-billing-stop-project.mdx b/serverless/pages/manage-billing-stop-project.mdx
deleted file mode 100644
index d257d03d..00000000
--- a/serverless/pages/manage-billing-stop-project.mdx
+++ /dev/null
@@ -1,18 +0,0 @@
----
-slug: /serverless/general/billing-stop-project
-title: Stop charges for a project
-description: How to stop charges for a project.
-tags: [ 'serverless', 'general', 'billing' ]
----
-
-
-Got a project you no longer need and don't want to be charged for? Simply delete it.
-
-Warning: All data is lost. Billing for usage is by the hour and any outstanding charges for usage before you deleted the project will still appear on your next bill.
-
-To stop being charged for a project:
-1. Log in to the [((ess-console-name))](((ess-console))).
-
-2. Find your project on the home page in the **Serverless Projects** card and select **Manage** to access it directly. Or, select **Serverless Projects** to go to the projects page to view all of your projects.
-
-3. Select **Actions**, then select **Delete project** and confirm the deletion.
\ No newline at end of file
diff --git a/serverless/pages/manage-billing.mdx b/serverless/pages/manage-billing.mdx
deleted file mode 100644
index 5990f55e..00000000
--- a/serverless/pages/manage-billing.mdx
+++ /dev/null
@@ -1,29 +0,0 @@
----
-slug: /serverless/general/manage-billing
-title: Manage billing of your organization
-description: Configure the billing details of your organization.
-tags: [ 'serverless', 'general', 'billing', 'overview' ]
----
-
-
-
-
- Until May 31, 2024, your serverless consumption will not incur any charges, but will be visible along with your total Elastic Cloud consumption on the [Billing Usage page](https://cloud.elastic.co/billing/usage). Unless you are in a trial period, usage on or after June 1, 2024 will be deducted from your existing Elastic Cloud credits or be billed to your active payment method.
-
-
-You can manage the billing details of your organization directly from the Elastic Cloud console.
-
-1. Navigate to [cloud.elastic.co](https://cloud.elastic.co/) and log in to your Elastic Cloud account.
-
-2. Go to the user icon on the header bar and select **Billing**.
-
-From the **Billing pages**, you can perform the following tasks:
-
--
--
--
-
-If you have a project that you're no longer using, refer to .
-
-To learn about the serverless pricing model, refer to and our [pricing page](https://www.elastic.co/pricing/serverless-search).
-
diff --git a/serverless/pages/manage-org.mdx b/serverless/pages/manage-org.mdx
deleted file mode 100644
index 24e146a9..00000000
--- a/serverless/pages/manage-org.mdx
+++ /dev/null
@@ -1,25 +0,0 @@
----
-slug: /serverless/general/manage-organization
-title: Manage your organization
-description: Manage your instances, users, and settings.
-tags: [ 'serverless', 'general', 'organization', 'overview' ]
----
-
-
-When you sign up to Elastic Cloud, you create an **organization**.
-
-This organization is the umbrella for all of your Elastic Cloud resources, users, and account settings. Every organization has a unique identifier. Bills are invoiced according to the billing contact and details that you set for your organization.
-
-
\ No newline at end of file
diff --git a/serverless/pages/manage-your-project-rest-api.mdx b/serverless/pages/manage-your-project-rest-api.mdx
deleted file mode 100644
index ab49dcf6..00000000
--- a/serverless/pages/manage-your-project-rest-api.mdx
+++ /dev/null
@@ -1,169 +0,0 @@
----
-slug: /serverless/general/manage-project-with-api
-title: Using the Project Management REST API
-description: Manage your organization's serverless projects using the REST API.
-tags: [ 'serverless', 'project', 'manage', 'rest', 'api']
----
-
-
-
-You can manage serverless projects using the [Elastic Cloud Serverless REST API](https://www.elastic.co/docs/api/doc/elastic-cloud-serverless). This API allows you to create, update, and delete projects, as well as manage project features and usage.
-
-
- More APIs let you interact with data, capabilities, and settings inside of specific projects. Refer to the [Serverless API reference page](https://www.elastic.co/docs/api).
-
-
-
-## API Principles
-
-- The Elastic Cloud REST API is built following REST principles:
- - Resources (such as projects) are represented as URIs.
- - Standard HTTP response codes and verbs are used (GET, POST, PUT, PATCH and DELETE).
- - API calls are stateless. Every request that you make happens in isolation from other calls and must include all the information necessary to fulfill the request.
-- JSON is the data interchange format.
-
-## Authentication
-
-API keys are used to authenticate requests to the Elastic Cloud REST API.
-Learn how to [create API keys](https://www.elastic.co/guide/en/cloud/current/ec-api-authentication.html).
-
-You must provide the API key for all API requests in the `Authorization` header as follows:
-
-```bash
-"Authorization: ApiKey $API_KEY"
-```
-
-For example, if you interact with the API using the `curl` command:
-
-```bash
-curl -H "Authorization: ApiKey essu_..." https://api.elastic-cloud.com/api/v1/serverless/projects/elasticsearch
-```
-
-## Open API Specification
-
-The Project Management API is documented using the [OpenAPI Specification](https://en.wikipedia.org/wiki/OpenAPI_Specification). The current supported version of the specification is `3.0`.
-
-For details, check the [API reference](https://www.elastic.co/docs/api/doc/elastic-cloud-serverless) or download the [OpenAPI Specification](https://www.elastic.co/docs/api/doc/elastic-cloud-serverless.yaml).
-
-This specification can be used to generate client SDKs, or on tools that support it, such as the [Swagger Editor](https://editor.swagger.io).
-
-
-## Examples
-
-To try the examples in this section:
-
-1. [Create an API key](https://www.elastic.co/guide/en/cloud/current/ec-api-authentication.html).
-
-2. Store the generated API key as an environment variable so that you don't need to specify it again for each request:
-
- ```bash
- export API_KEY="YOUR_GENERATED_API_KEY"
- ```
-
-### Create a serverless Elasticsearch project
-
-```bash
-curl -H "Authorization: ApiKey $API_KEY" \
- -H "Content-Type: application/json" \
- "https://api.elastic-cloud.com/api/v1/serverless/projects/elasticsearch" \
- -XPOST --data '{
- "name": "My project", [^1]
- "region_id": "aws-us-east-1" [^2]
- }'
-```
-[^1]: Replace **`My project`** with a more descriptive name in this call.
-[^2]: You can .
-
-The response from the create project request will include the created project details, such as the project ID,
-the credentials to access the project, and the endpoints to access different apps such as Elasticsearch and Kibana.
-
-Example of `Create project` response:
-
-```json
-{
- "id": "cace8e65457043698ed3d99da2f053f6",
- "endpoints": {
- "elasticsearch": "https://sample-project-c990cb.es.us-east-1.aws.elastic.cloud",
- "kibana": "https://sample-project-c990cb-c990cb.kb.us-east-1.aws.elastic.cloud"
- },
- "credentials": {
- "username": "admin",
- "password": "abcd12345"
- }
- (...)
-}
-```
-
-You can store the project ID as an environment variable for the next requests:
-
-```bash
-export PROJECT_ID=cace8e65457043698ed3d99da2f053f6
-```
-
-### Get project
-
-You can retrieve your project details through an API call:
-
-```bash
-curl -H "Authorization: ApiKey $API_KEY" \
- "https://api.elastic-cloud.com/api/v1/serverless/projects/elasticsearch/${PROJECT_ID}"
-```
-
-### Get project status
-
-The 'status' endpoint indicates whether the project is initialized and ready to be used. In the response, the project's `phase` will change from "initializing" to "initialized" when it is ready:
-
-```bash
-curl -H "Authorization: ApiKey $API_KEY" \
- "https://api.elastic-cloud.com/api/v1/serverless/projects/elasticsearch/${PROJECT_ID}/status"
-```
-
-Example response:
-
-```json
-{
- "phase":"initializing"
-}
-```
-
-### Reset Credentials
-
-If you lose the credentials provided at the time of the project creation, you can reset the credentials by using the following endpoint:
-
-```bash
-curl -H "Authorization: ApiKey $API_KEY" \
- -XPOST \
- "https://api.elastic-cloud.com/api/v1/serverless/projects/elasticsearch/${PROJECT_ID}/_reset-credentials"
-```
-
-### Delete Project
-
-You can delete your project via the API:
-
-```bash
-curl -XDELETE -H "Authorization: ApiKey $API_KEY" \
- "https://api.elastic-cloud.com/api/v1/serverless/projects/elasticsearch/${PROJECT_ID}"
-```
-
-### Update Project
-
-You can update your project using a PATCH request. Only the fields included in the body of the request will be updated.
-
-```bash
-curl -H "Authorization: ApiKey $API_KEY" \
- -H "Content-Type: application/json" \
- "https://api.elastic-cloud.com/api/v1/serverless/projects/elasticsearch/${PROJECT_ID}" \
- -XPATCH --data '{
- "name": "new name",
- "alias": "new-project-alias"
- }'
-```
-
-### List available regions
-
-You can obtain the list of regions where projects can be created using the API:
-
-```bash
-curl -H "Authorization: ApiKey $API_KEY" \
- "https://api.elastic-cloud.com/api/v1/serverless/regions"
-```
\ No newline at end of file
diff --git a/serverless/pages/manage-your-project.mdx b/serverless/pages/manage-your-project.mdx
deleted file mode 100644
index fb004da6..00000000
--- a/serverless/pages/manage-your-project.mdx
+++ /dev/null
@@ -1,192 +0,0 @@
----
-slug: /serverless/elasticsearch/manage-project
-title: Manage your projects
-description: Configure project-wide features and usage.
-tags: [ 'serverless', 'elasticsearch', 'project', 'manage' ]
----
-
-
-To manage a project:
-
-1. Navigate to [cloud.elastic.co](https://cloud.elastic.co/).
-
-2. Log in to your Elastic Cloud account.
-
-3. Select your project from the **Serverless projects** panel and click **Manage**.
-
-From the project page, you can:
-
-- **Rename your project**. In the **Overview** section, click **Edit** next to the project's name.
-
-- **Manage data and integrations**. Update your project data, including storage settings, indices, and data views, directly in your project.
-
-- **Manage API keys**. Access your project and interact with its data programmatically using Elasticsearch APIs.
-
-- **Manage members**. Add members and manage their access to this project or other resources of your organization.
-
-## Search AI Lake settings
-
-Once ingested, your data is stored in cost-efficient, general storage. A cache layer is available on top of the general storage for recent and frequently queried data that provides faster search speed. Data in this cache layer is considered **search-ready**.
-
-Together, these data storage layers form your project's **Search AI Lake**.
-
-The total volume of search-ready data is the sum of the following:
-1. The volume of non-time series project data
-2. The volume of time series project data included in the Search Boost Window
-
-Each project type offers different settings that let you adjust the performance and volume of search-ready data, as well as the features available in your projects.
-
-
-
-
- **Search Power**
-
-
- Search Power affects search speed by controlling the number of VCUs (Virtual Compute Units) allocated to search-ready data in the project. Additional VCUs provide more compute resources and result in performance gains.
-
- The **Cost-efficient** Search Power setting limits the available cache size, and generates cost savings by reducing search performance.
-
- The **Balanced** Search Power setting ensures that there is sufficient cache for all search-ready data, in order to respond quickly to queries.
-
- The **Performance** Search Power setting provides more computing resources in addition to the searchable data cache, in order to respond quickly to higher query volumes and more complex queries.
-
-
-
-
-
-
-
- **Search Boost Window**
-
-
- Non-time series data is always considered search-ready. The **Search Boost Window** determines the volume of time series project data that will be considered search-ready.
-
- Increasing the window results in a bigger portion of time series project data included in the total search-ready data volume.
-
-
-
-
-
-
-
- **Data Retention**
-
-
- Data retention policies determine how long your project data is retained.
-
- You can specify different retention periods for specific data streams in your project.
-
-
-
-
-
-
-
-
-
-
- **Maximum data retention period**
-
- When enabled, this setting determines the maximum length of time that data can be retained in any data streams of this project.
-
- Editing this setting replaces the data retention set for all data streams of the project that have a longer data retention defined. Data older than the new maximum retention period that you set is permanently deleted.
-
-
-
-
-
-
-
-
- **Default data retention period**
-
- When enabled, this setting determines the default retention period that is automatically applied to all data streams in your project that do not have a custom retention period already set.
-
-
-
-
-
-
-
- **Project features**
-
-
- Controls feature tiers and add-on options for your ((elastic-sec)) project.
-
-
-
-
-
-
-
-
-
-## Project features and add-ons
-
- For ((elastic-sec)) projects, edit the **Project features** to select a feature tier and enable add-on options for specific use cases.
-
-
-
- **Security Analytics Essentials**
-
- Standard security analytics, detections, investigations, and collaborations. Allows these add-ons:
- * **Endpoint Protection Essentials**: Endpoint protections with ((elastic-defend)).
- * **Cloud Protection Essentials**: Cloud native security features.
-
-
-
- **Security Analytics Complete**
-
- Everything in **Security Analytics Essentials** plus advanced features such as entity analytics, threat intelligence, and more. Allows these add-ons:
- * **Endpoint Protection Complete**: Everything in **Endpoint Protection Essentials** plus advanced endpoint detection and response features.
- * **Cloud Protection Complete**: Everything in **Cloud Protection Essentials** plus advanced cloud security features.
-
-
-
-
-### Downgrading the feature tier
-
-When you downgrade your Security project features selection from **Security Analytics Complete** to **Security Analytics Essentials**, the following features become unavailable:
-
-* All Entity Analytics features
-* The ability to use certain entity analytics-related integration packages, such as:
- * Data Exfiltration detection
- * Lateral Movement detection
- * Living off the Land Attack detection
-* Intelligence Indicators page
-* External rule action connectors
-* Case connectors
-* Endpoint response actions history
-* Endpoint host isolation exceptions
-* AI Assistant
-* Attack discovery
-
-And, the following data may be permanently deleted:
-* AI Assistant conversation history
-* AI Assistant settings
-* Entity Analytics user and host risk scores
-* Entity Analytics asset criticality information
-* Detection rule external connector settings
-* Detection rule response action settings
\ No newline at end of file
diff --git a/serverless/pages/maps.mdx b/serverless/pages/maps.mdx
deleted file mode 100644
index 42e01645..00000000
--- a/serverless/pages/maps.mdx
+++ /dev/null
@@ -1,81 +0,0 @@
----
-slug: /serverless/maps
-title: ((maps-app))
-description: Create maps from your geographical data.
-tags: [ 'serverless', 'Security' ]
----
-
-
-This content applies to:
-
-In **((project-settings)) → ((maps-app))** you can:
-
-- Build maps with multiple layers and indices.
-- Animate spatial temporal data.
-- Upload GeoJSON files and shapefiles.
-- Embed your map in dashboards.
-- Focus on only the data that's important to you.
-
-{/*
-- Symbolize features using data values.
- */}
-
-## Build maps with multiple layers and indices
-
-Use multiple layers and indices to show all your data in a single map.
-Show how data sits relative to physical features like weather patterns, human-made features like international borders, and business-specific features like sales regions.
-Plot individual documents or use aggregations to plot any data set, no matter how large.
-
-
-
-Go to **((project-settings)) → ((maps-app))** and click **Add layer**.
-To learn about specific types of layers, check out [Heat map layer](((kibana-ref))/heatmap-layer.html), [Tile layer](((kibana-ref))/tile-layer.html), and [Vector layer](((kibana-ref))/vector-layer.html).
-
-## Animate spatial temporal data
-
-Data comes to life with animation.
-Hard to detect patterns in static data pop out with movement.
-Use time slider to animate your data and gain deeper insights.
-
-This animated map uses the time slider to show Portland buses over a period of 15 minutes.
-The routes come alive as the bus locations update with time.
-
-
-
-To create this type of map, check out [Track, visualize, and alert assets in real time](((kibana-ref))/asset-tracking-tutorial.html).
-
-## Upload GeoJSON files and shapefiles
-
-Use **((maps-app))** to drag and drop your GeoJSON and shapefile data and then use them as layers in your map.
-Check out [Import geospatial data](((kibana-ref))/import-geospatial-data.html).
-
-## Embed your map in dashboards
-
-Viewing data from different angles provides better insights.
-Dimensions that are obscured in one visualization might be illuminated in another.
-Add your map to a and view your geospatial data alongside bar charts, pie charts, tag clouds, and more.
-
-This choropleth map shows the density of non-emergency service requests in San Diego by council district.
-The map is embedded in a dashboard, so users can better understand when services are requested and gain insight into the top requested services.
-
-
-
-For a detailed example, check out [Build a map to compare metrics by country or region](((kibana-ref))/maps-getting-started.html).
-
-{/*
-TBD: There doesn't seem to be content to link to for this section, so it's omitted for now.
-## Symbolize features using data values
-
-Customize each layer to highlight meaningful dimensions in your data.
-For example, use dark colors to symbolize areas with more web log traffic, and lighter colors to symbolize areas with less traffic.
-*/}
-
-## Focus on only the data that's important to you
-
-Search across the layers in your map to focus on just the data you want.
-Combine free text search with field-based search using the ((kib)) Query Language (KQL)
-Set the time filter to restrict layers by time.
-Draw a polygon on the map or use the shape from features to create spatial filters.
-Filter individual layers to compares facets.
-
-Check out [Search geographic data](((kibana-ref))/maps-search.html).
\ No newline at end of file
diff --git a/serverless/pages/pricing.mdx b/serverless/pages/pricing.mdx
deleted file mode 100644
index a356683f..00000000
--- a/serverless/pages/pricing.mdx
+++ /dev/null
@@ -1,53 +0,0 @@
----
-slug: /serverless/elasticsearch/elasticsearch-billing
-title: Elasticsearch billing dimensions
-description: Learn about how Elasticsearch usage affects pricing.
-tags: [ 'serverless', 'elasticsearch', 'overview' ]
----
-
-import MinimumVcusDetail from '../partials/minimum-vcus-detail.mdx'
-
-
-
-Elasticsearch is priced based on the consumption of the underlying
-infrastructure used to support your use case, with the performance
-characteristics you need. We measure by Virtual Compute Units (VCUs), which is a
-slice of RAM, CPU and local disk for caching. The number of VCUs required will
-depend on the amount and the rate of data sent to Elasticsearch and retained,
-and the number of searches and latency you require for searches. In addition, if
-you required ((ml)) for inference or NLP tasks, those VCUs are also
-metered and billed.
-
-
-
-## Information about the VCU types (Search, Ingest, and ML)
-
-There are three VCU types in Elasticsearch:
-
-* **Indexing** — The VCUs used to index the incoming documents to be
-stored in Elasticsearch.
-* **Search** — The VCUs used to return search results with the latency and
-Queries per Second (QPS) you require.
-* **Machine Learning** — The VCUs used to perform inference, NLP tasks, and other ML activities.
-
-## Information about the Search AI Lake dimension (GB)
-
-For Elasticsearch, the Search AI Lake is where data is stored and retained. This is
-charged in GBs for the size of data at rest. Depending on the enrichment,
-vectorization and other activities during ingest, this size may be different
-from the original size of the source data.
-
-## Managing Elasticsearch costs
-
-You can control costs in a number of ways. Firstly there is the amount of
-data that is retained. Elasticsearch will ensure that the most recent data is
-cached, allowing for fast retrieval. Reducing the amount of data means fewer
-Search VCUs may be required. If you need lower latency, then more Search VCUs
-can be added by adjusting the Search Power. A further refinement is for data streams that can be used to store
-time series data. For that type of data, you can further define the number of
-days of data you want cacheable, which will affect the number of Search VCUs and
-therefore the cost. Note that Elasticsearch Serverless maintains and bills for
-[minimum compute resource Ingest and Search VCUs](https://www.elastic.co/pricing/serverless-search#what-are-the-minimum-compute-resource-vcus-on-elasticsearch-serverless).
-
-For detailed Elasticsearch serverless project rates, check the
-[Elasticsearch Serverless pricing page](https://www.elastic.co/pricing/serverless-search).
\ No newline at end of file
diff --git a/serverless/pages/profile-queries-and-aggregations.mdx b/serverless/pages/profile-queries-and-aggregations.mdx
deleted file mode 100644
index 51a64edf..00000000
--- a/serverless/pages/profile-queries-and-aggregations.mdx
+++ /dev/null
@@ -1,320 +0,0 @@
----
-slug: /serverless/devtools/profile-queries-and-aggregations
-title: Search Profiler
-description: Diagnose and debug poorly performing search queries.
-tags: [ 'serverless', 'dev tools', 'how-to' ]
----
-
-
-This content applies to:
-
-{/* TODO: The following content was copied verbatim from the ES docs on Oct 5, 2023. It should be included through
-transclusion. */}
-
-((es)) has a powerful [Profile API](((ref))/search-profile.html) for debugging search queries.
-It provides detailed timing information about the execution of individual components in a search request.
-This allows users to optimize queries for better performance.
-
-However, Profile API responses can be hard to read, especially for complex queries.
-**((searchprofiler))** helps you visualize these responses in a graphical interface.
-
-
-
-## Get started
-
-Access **((searchprofiler))** under **Dev Tools**.
-
-**((searchprofiler))** displays the names of the indices searched and how long it took for the query to complete.
-Test it out by replacing the default `match_all` query with the query you want to profile, and then select **Profile**.
-
-The following example shows the results of profiling the `match_all` query.
-If you take a closer look at the information for the `.security_7` sample index, the
-**Cumulative time** field shows you that the query took 0.028ms to execute.
-
-
-
-{/*
-
-The cumulative time metric is the sum of individual shard times.
-It is not necessarily the actual time it took for the query to return (wall clock time).
-Because shards might be processed in parallel on multiple nodes, the wall clock time can
-be significantly less than the cumulative time.
-However, if shards are colocated on the same node and executed serially, the wall clock time is closer to the cumulative time.
-
-While the cumulative time metric is useful for comparing the performance of your
-indices and shards, it doesn't necessarily represent the actual physical query times.
-
- */}
-{/* Commenting out for moment, given shards and nodes are obfuscated concepts in serverless */}
-
-To see more profiling information, select **View details**.
-You'll find details about query components and the timing
-breakdown of low-level methods.
-For more information, refer to [Profiling queries](((ref))/search-profile.html#profiling-queries) in the ((es)) documentation.
-
-## Filter for an index or type
-
-By default, all queries executed by the **((searchprofiler))** are sent
-to `GET /_search`.
-It searches across your entire cluster (all indices, all types).
-
-To query a specific index or type, you can use the **Index** filter.
-
-In the following example, the query is executed against the indices `.security-7` and `kibana_sample_data_ecommerce`.
-This is equivalent to making a request to `GET /.security-7,kibana_sample_data_ecommerce/_search`.
-
-
-
-
-
-## Profile a more complicated query
-
-To understand how the query trees are displayed inside the **((searchprofiler))**,
-take a look at a more complicated query.
-
-1. Index the following data using **Console**:
-
- ```js
- POST test/_bulk
- {"index":{}}
- {"name":"aaron","age":23,"hair":"brown"}
- {"index":{}}
- {"name":"sue","age":19,"hair":"red"}
- {"index":{}}
- {"name":"sally","age":19,"hair":"blonde"}
- {"index":{}}
- {"name":"george","age":19,"hair":"blonde"}
- {"index":{}}
- {"name":"fred","age":69,"hair":"blonde"}
- ```
- {/* CONSOLE */}
-
-1. From the **((searchprofiler))**, enter **test** in the **Index** field to restrict profiled
- queries to the `test` index.
-
-1. Replace the default `match_all` query in the query editor with a query that has two sub-query
- components and includes a simple aggregation:
- ```js
- {
- "query": {
- "bool": {
- "should": [
- {
- "match": {
- "name": "fred"
- }
- },
- {
- "terms": {
- "name": [
- "sue",
- "sally"
- ]
- }
- }
- ]
- }
- },
- "aggs": {
- "stats": {
- "stats": {
- "field": "price"
- }
- }
- }
- }
- ```
- {/* NOTCONSOLE */}
-
-1. Select **Profile** to profile the query and visualize the results.
-
- 
-
- - The top `BooleanQuery` component corresponds to the `bool` in the query.
- - The second `BooleanQuery` corresponds to the `terms` query, which is internally
- converted to a `Boolean` of `should` clauses. It has two child queries that correspond
- to "sally" and "sue from the `terms` query.
- - The `TermQuery` that's labeled with "name:fred" corresponds to `match: fred` in the query.
-
-
- In the time columns, the **Self time** and **Total time** are no longer
- identical on all rows:
-
- - **Self time** represents how long the query component took to execute.
- - **Total time** is the time a query component and all its children took to execute.
-
- Therefore, queries like the Boolean queries often have a larger total time than self time.
-
-1. Select **Aggregation Profile** to view aggregation profiling statistics.
-
- This query includes a `stats` agg on the `"age"` field.
- The **Aggregation Profile** tab is only enabled when the query being profiled contains an aggregation.
-
-1. Select **View details** to view the timing breakdown.
-
- 
-
- For more information about how the **((searchprofiler))** works, how timings are calculated, and
- how to interpret various results, refer to
- [Profiling queries](((ref))/search-profile.html#profiling-queries) in the ((es)) documentation.
-
-
-
-## Render pre-captured profiler JSON
-
-Sometimes you might want to investigate performance problems that are temporal in nature.
-For example, a query might only be slow at certain time of day when many customers are using your system.
-You can set up a process to automatically profile slow queries when they occur and then
-save those profile responses for later analysis.
-
-The **((searchprofiler))** supports this workflow by allowing you to paste the
-pre-captured JSON in the query editor.
-The **((searchprofiler))** will detect that you
-have entered a JSON response (rather than a query) and will render just the visualization,
-rather than querying the cluster.
-
-To see how this works, copy and paste the following profile response into the
-query editor and select **Profile**.
-
-```js
-{
- "took": 3,
- "timed_out": false,
- "_shards": {
- "total": 1,
- "successful": 1,
- "failed": 0
- },
- "hits": {
- "total": 1,
- "max_score": 1.3862944,
- "hits": [
- {
- "_index": "test",
- "_type": "test",
- "_id": "AVi3aRDmGKWpaS38wV57",
- "_score": 1.3862944,
- "_source": {
- "name": "fred",
- "age": 69,
- "hair": "blonde"
- }
- }
- ]
- },
- "profile": {
- "shards": [
- {
- "id": "[O-l25nM4QN6Z68UA5rUYqQ][test][0]",
- "searches": [
- {
- "query": [
- {
- "type": "BooleanQuery",
- "description": "+name:fred #(ConstantScore(*:*))^0.0",
- "time": "0.5884370000ms",
- "breakdown": {
- "score": 7243,
- "build_scorer_count": 1,
- "match_count": 0,
- "create_weight": 196239,
- "next_doc": 9851,
- "match": 0,
- "create_weight_count": 1,
- "next_doc_count": 2,
- "score_count": 1,
- "build_scorer": 375099,
- "advance": 0,
- "advance_count": 0
- },
- "children": [
- {
- "type": "TermQuery",
- "description": "name:fred",
- "time": "0.3016880000ms",
- "breakdown": {
- "score": 4218,
- "build_scorer_count": 1,
- "match_count": 0,
- "create_weight": 132425,
- "next_doc": 2196,
- "match": 0,
- "create_weight_count": 1,
- "next_doc_count": 2,
- "score_count": 1,
- "build_scorer": 162844,
- "advance": 0,
- "advance_count": 0
- }
- },
- {
- "type": "BoostQuery",
- "description": "(ConstantScore(*:*))^0.0",
- "time": "0.1223030000ms",
- "breakdown": {
- "score": 0,
- "build_scorer_count": 1,
- "match_count": 0,
- "create_weight": 17366,
- "next_doc": 0,
- "match": 0,
- "create_weight_count": 1,
- "next_doc_count": 0,
- "score_count": 0,
- "build_scorer": 102329,
- "advance": 2604,
- "advance_count": 2
- },
- "children": [
- {
- "type": "MatchAllDocsQuery",
- "description": "*:*",
- "time": "0.03307600000ms",
- "breakdown": {
- "score": 0,
- "build_scorer_count": 1,
- "match_count": 0,
- "create_weight": 6068,
- "next_doc": 0,
- "match": 0,
- "create_weight_count": 1,
- "next_doc_count": 0,
- "score_count": 0,
- "build_scorer": 25615,
- "advance": 1389,
- "advance_count": 2
- }
- }
- ]
- }
- ]
- }
- ],
- "rewrite_time": 168640,
- "collector": [
- {
- "name": "CancellableCollector",
- "reason": "search_cancelled",
- "time": "0.02952900000ms",
- "children": [
- {
- "name": "SimpleTopScoreDocCollector",
- "reason": "search_top_hits",
- "time": "0.01931700000ms"
- }
- ]
- }
- ]
- }
- ],
- "aggregations": []
- }
- ]
- }
-}
-```
-{/* NOTCONSOLE */}
-
-Your output should look similar to this:
-
-
diff --git a/serverless/pages/project-and-management-settings.mdx b/serverless/pages/project-and-management-settings.mdx
deleted file mode 100644
index 0f111855..00000000
--- a/serverless/pages/project-and-management-settings.mdx
+++ /dev/null
@@ -1,24 +0,0 @@
----
-slug: /serverless/project-and-management-settings
-title: Project and management settings
-description: Learn about capabilities available in multiple serverless solutions.
-tags: [ 'serverless', 'observability', 'security', 'elasticsearch', 'overview' ]
----
-
-
-The documentation in this section describes shared capabilities that are available in multiple solutions.
-Look for the doc badge on each page to see if the page is valid for your solution:
-
-* for the ((es)) solution
-* for the ((observability)) solution
-* for the ((security)) solution
-
-
-Some solutions provide versions of these capabilities tailored to your use case.
-Read the main solution docs to learn how to use those capabilities:
-
-*
-*
-*
-
-
diff --git a/serverless/pages/project-settings.mdx b/serverless/pages/project-settings.mdx
deleted file mode 100644
index c3080f64..00000000
--- a/serverless/pages/project-settings.mdx
+++ /dev/null
@@ -1,264 +0,0 @@
----
-slug: /serverless/project-settings
-title: Management settings
-description: Manage your indices, data views, saved objects, settings, and more from a central location in Elastic.
-tags: [ 'serverless', 'management', 'overview' ]
----
-
-
-Go to **Project Settings** to manage your indices, data views, saved objects, settings, and more.
-
-Access to individual features is governed by Elastic user roles.
-Consult your administrator if you do not have the appropriate access.
-To learn more about roles, refer to .
-
-
-
-
- API keys
-
-
- Create and manage keys that can send requests on behalf of users.
-
-
-
-
-
-
-
-
-
- Asset criticality
-
-
- Bulk assign asset criticality to multiple entities by importing a text file.
-
-
-
-
-
-
-
-
-
-
- Create and manage reusable connectors for triggering actions.
-
-
-
-
-
-
-
-
-
- Create and manage roles that grant privileges within your project.
-
-
-
-
-
-
-
-
-
-
-
- Manage the fields in the data views that retrieve your data from ((es)).
-
-
-
-
-
-
-
-
-
- Entity Risk Score
-
-
- Manage entity risk scoring, and preview risky entities.
-
-
-
-
-
-
-
-
-
-
- Manage files that are stored in ((kib)).
-
-
-
-
-
-
-
-
-
-
-
-
- View index settings, mappings, and statistics and perform operations on indices.
-
-
-
-
-
-
-
-
-
-
-
-
- Create and manage ingest pipelines that parse, transform, and enrich your data.
-
-
-
-
-
-
-
-
-
-
-
-
- Create and manage ((ls)) pipelines that parse, transform, and enrich your data.
-
-
-
-
-
-
-
-
-
-
-
-
- View, export, and import your ((anomaly-detect)) and ((dfanalytics)) jobs and trained models.
-
-
-
-
-
-
-
-
-
-
-
-
- Suppress rule notifications for scheduled periods of time.
-
-
-
-
-
-
-
-
-
-
-
- Create maps from your geographical data.
-
-
-
-
-
-
-
-
-
-
- Manage and download reports such as CSV files generated from saved searches.
-
-
-
-
-
-
-
-
-
-
-
-
- Create and manage rules that generate alerts.
-
-
-
-
-
-
-
-
-
-
- Copy, edit, delete, import, and export your saved objects.
- These include dashboards, visualizations, maps, ((data-sources)), and more.
-
-
-
-
-
-
-
-
-
-
-
-
- Organize your project and objects into multiple spaces.
-
-
-
-
-
-
-
-
-
-
-
-
- Create, manage, and assign tags to your saved objects.
-
-
-
-
-
-
-
-
-
-
-
-
- Use transforms to pivot existing ((es)) indices into summarized or entity-centric indices.
-
-
-
-
-
-
-
-
diff --git a/serverless/pages/reports.mdx b/serverless/pages/reports.mdx
deleted file mode 100644
index 2159c896..00000000
--- a/serverless/pages/reports.mdx
+++ /dev/null
@@ -1,24 +0,0 @@
----
-slug: /serverless/reports
-title: ((reports-app))
-description: View and manage generated reports.
-tags: [ 'serverless', 'Elasticsearch', 'Observability', 'Security' ]
-related: ['serverlessElasticsearchExploreYourDataDiscoverYourData']
----
-
-
-This content applies to:
-
-((kib)) provides you with several options to share saved searches, dashboards, and visualizations.
-
-For example, in **Discover**, you can create and download comma-separated values (CSV) files for saved searches.
-
-To view and manage reports, go to **((project-settings)) → ((manage-app)) → ((reports-app))**.
-
-
-{/* TBD: This image was refreshed but should be automated */}
-
-You can download or view details about the report by clicking the icons in the actions menu.
-
-To delete one or more reports, select their checkboxes then click **Delete reports**.
-
diff --git a/serverless/pages/rules.mdx b/serverless/pages/rules.mdx
deleted file mode 100644
index e3086bae..00000000
--- a/serverless/pages/rules.mdx
+++ /dev/null
@@ -1,152 +0,0 @@
----
-slug: /serverless/rules
-title: ((rules-app))
-description: Alerting works by running checks on a schedule to detect conditions defined by a rule.
-tags: [ 'serverless', 'Elasticsearch', 'alerting', 'learn' ]
-related: ['serverlessActionConnectors', 'serverlessElasticsearchExploreYourDataAlertings']
----
-
-
-This content applies to:
-
-In general, a rule consists of three parts:
-
-* _Conditions_: what needs to be detected?
-* _Schedule_: when/how often should detection checks run?
-* _Actions_: what happens when a condition is detected?
-
-For example, when monitoring a set of servers, a rule might:
-
-* Check for average CPU usage > 0.9 on each server for the last two minutes (condition).
-* Check every minute (schedule).
-* Send a warning email message via SMTP with subject `CPU on {{server}} is high` (action).
-
-{/* 
-
-The following sections describe each part of the rule in more detail. */}
-
-## Conditions
-
-Each project type supports a specific set of rule types.
-Each _rule type_ provides its own way of defining the conditions to detect, but an expression formed by a series of clauses is a common pattern.
-For example, in an ((es)) query rule, you specify an index, a query, and a threshold, which uses a metric aggregation operation (`count`, `average`, `max`, `min`, or `sum`):
-
-
-{/* NOTE: This is an autogenerated screenshot. Do not edit it directly. */}
-
-## Schedule
-
-{/* Rule schedules are defined as an interval between subsequent checks, and can range from a few seconds to months. */}
-
-All rules must have a check interval, which defines how often to evaluate the rule conditions.
-Checks are queued; they run as close to the defined value as capacity allows.
-
-
-
-The intervals of rule checks in ((kib)) are approximate. Their timing is affected by factors such as the frequency at which tasks are claimed and the task load on the system. Refer to [Alerting production considerations](((kibana-ref))/alerting-production-considerations.html)
-{/* missing linkAlerting production considerations */}
-
-
-
-## Actions
-
-You can add one or more actions to your rule to generate notifications when its conditions are met.
-Recovery actions likewise run when rule conditions are no longer met.
-
-When defining actions in a rule, you specify:
-
-* A connector
-* An action frequency
-* A mapping of rule values to properties exposed for that type of action
-
-Each action uses a connector, which provides connection information for a ((kib)) service or third party integration, depending on where you want to send the notifications.
-The specific list of connectors that you can use in your rule vary by project type.
-Refer to .
-{/* If no connectors exist, click **Add connector** to create one. */}
-
-After you select a connector, set the _action frequency_.
-If you want to reduce the number of notifications you receive without affecting their timeliness, some rule types support alert summaries.
-For example, if you create an ((es)) query rule, you can set the action frequency such that you receive summaries of the new, ongoing, and recovered alerts on a custom interval:
-
-
-
-{/* */}
-
-Alternatively, you can set the action frequency such that the action runs for each alert.
-If the rule type does not support alert summaries, this is your only available option.
-You must choose when the action runs (for example, at each check interval, only when the alert status changes, or at a custom action interval).
-You must also choose an action group, which affects whether the action runs.
-Each rule type has a specific set of valid action groups.
-For example, you can set *Run when* to `Query matched` or `Recovered` for the ((es)) query rule:
-
-
-{/* NOTE: This is an autogenerated screenshot. Do not edit it directly. */}
-
-Each connector supports a specific set of actions for each action group and enables different action properties.
-For example, you can have actions that create an ((opsgenie)) alert when rule conditions are met and recovery actions that close the ((opsgenie)) alert.
-
-Some types of rules enable you to further refine the conditions under which actions run.
-For example, you can specify that actions run only when an alert occurs within a specific time frame or when it matches a KQL query.
-
-
-
-If you are not using alert summaries, actions are triggered per alert and a rule can end up generating a large number of actions. Take the following example where a rule is monitoring three servers every minute for CPU usage > 0.9, and the action frequency is `On check intervals`:
-
-* Minute 1: server X123 > 0.9. _One email_ is sent for server X123.
-* Minute 2: X123 and Y456 > 0.9. _Two emails_ are sent, one for X123 and one for Y456.
-* Minute 3: X123, Y456, Z789 > 0.9. _Three emails_ are sent, one for each of X123, Y456, Z789.
-
-In this example, three emails are sent for server X123 in the span of 3 minutes for the same rule. Often, it's desirable to suppress these re-notifications. If
-you set the action frequency to `On custom action intervals` with an interval of 5 minutes, you reduce noise by getting emails only every 5 minutes for
-servers that continue to exceed the threshold:
-
-* Minute 1: server X123 > 0.9. _One email_ will be sent for server X123.
-* Minute 2: X123 and Y456 > 0.9. _One email_ will be sent for Y456.
-* Minute 3: X123, Y456, Z789 > 0.9. _One email_ will be sent for Z789.
-
-To get notified only once when a server exceeds the threshold, you can set the action frequency to `On status changes`. Alternatively, if the rule type supports alert summaries, consider using them to reduce the volume of notifications.
-
-
-
-{/*
-Each action definition is therefore a template: all the parameters needed to invoke a service are supplied except for specific values that are only known at the time the rule condition is detected.
-
-In the server monitoring example, the `email` connector type is used, and `server` is mapped to the body of the email, using the template string `CPU on {{server}} is high`.
-
-When the rule detects the condition, it creates an alert containing the details of the condition. */}
-
-### Action variables
-
-You can pass rule values to an action at the time a condition is detected.
-To view the list of variables available for your rule, click the "add rule variable" button:
-
-
-{/* NOTE: This is an autogenerated screenshot. Do not edit it directly. */}
-
-For more information about common action variables, refer to [Rule actions variables](((kibana-ref))/rule-action-variables.html)
-{/* missing link */}
-
-## Alerts
-
-When checking for a condition, a rule might identify multiple occurrences of the condition.
-((kib)) tracks each of these alerts separately.
-Depending on the action frequency, an action occurs per alert or at the specified alert summary interval.
-
-Using the server monitoring example, each server with average CPU > 0.9 is tracked as an alert.
-This means a separate email is sent for each server that exceeds the threshold whenever the alert status changes.
-
-{/*  */}
-
-## Putting it all together
-
-A rule consists of conditions, actions, and a schedule.
-When conditions are met, alerts are created that render actions and invoke them.
-To make action setup and update easier, actions use connectors that centralize the information used to connect with ((kib)) services and third-party integrations.
-The following example ties these concepts together:
-
-
-
-1. Any time a rule's conditions are met, an alert is created. This example checks for servers with average CPU \> 0.9. Three servers meet the condition, so three alerts are created.
-1. Alerts create actions according to the action frequency, as long as they are not muted or throttled. When actions are created, its properties are filled with actual values. In this example, three actions are created when the threshold is met, and the template string `{{server}}` is replaced with the appropriate server name for each alert.
-1. ((kib)) runs the actions, sending notifications by using a third party integration like an email service.
-1. If the third party integration has connection parameters or credentials, ((kib)) fetches these from the appropriate connector.
diff --git a/serverless/pages/run-api-requests-in-the-console.mdx b/serverless/pages/run-api-requests-in-the-console.mdx
deleted file mode 100644
index 59c93d9e..00000000
--- a/serverless/pages/run-api-requests-in-the-console.mdx
+++ /dev/null
@@ -1,187 +0,0 @@
----
-slug: /serverless/devtools/run-api-requests-in-the-console
-title: Console
-description: Use the Console to interact with Elastic REST APIs.
-tags: [ 'serverless', 'dev tools', 'how-to' ]
----
-
-
-This content applies to:
-
-**Console** lets you interact with [Elasticsearch and Kibana serverless APIs](https://www.elastic.co/docs/api) from your project.
-
-Requests are made in the left pane, and responses are displayed in the right pane.
-
-
-
-To go to **Console**, find **Dev Tools** in the navigation menu or use the global search bar.
-
-You can also find Console directly on your Elasticsearch serverless project pages, where you can expand it from the footer. This Console, called **Persistent Console**, has the same capabilities and shares the same history as the Console in **Dev Tools**.
-
-
-## Write requests
-
-**Console** understands commands in a cURL-like syntax.
-For example, the following is a `GET` request to the ((es)) `_search` API.
-
-```js
-GET /_search
-{
- "query": {
- "match_all": {}
- }
-}
-```
-
-Here is the equivalent command in cURL:
-
-```bash
-curl "${ES_URL}/_search" \
--H "Authorization: ApiKey ${API_KEY}" \
--H "Content-Type: application/json" \
--d'
-{
- "query": {
- "match_all": {}
- }
-}'
-```
-
-### Autocomplete
-
-When you're typing a command, **Console** makes context-sensitive suggestions.
-These suggestions show you the parameters for each API and speed up your typing.
-
-You can configure your preferences for autocomplete in the [Console settings](#configure-console-settings).
-
-### Comments
-
-You can write comments or temporarily disable parts of a request by using double forward slashes (`//`) or pound (`#`) signs to create single-line comments.
-
-```js
-# This request searches all of your indices.
-GET /_search
-{
- // The query parameter indicates query context.
- "query": {
- "match_all": {} // Matches all documents.
- }
-}
-```
-
-You can also use a forward slash followed by an asterisk (`/*`) to mark the beginning of multi-line
-comments.
-An asterisk followed by a forward slash (`*/`) marks the end.
-
-```js
-GET /_search
-{
- "query": {
- /*"match_all": {
- "boost": 1.2
- }*/
- "match_none": {}
- }
-}
-```
-### Variables
-
-Select **Variables** to create, edit, and delete variables.
-
-
-
-You can refer to these variables in the paths and bodies of your requests.
-Each variable can be referenced multiple times.
-
-```js
-GET ${pathVariable}
-{
- "query": {
- "match": {
- "${bodyNameVariable}": "${bodyValueVariable}"
- }
- }
-}
-```
-
-By default, variables in the body may be substituted as a boolean, number, array, or
-object by removing nearby quotes instead of a string with surrounding quotes. Triple
-quotes overwrite this default behavior and enforce simple replacement as a string.
-
-### Auto-formatting
-
-The auto-formatting
-capability can help you format requests to be more readable. Select one or more requests that you
-want to format, open the contextual menu, and then select **Auto indent**.
-
-### Keyboard shortcuts
-
-**Go to line number**: `Ctrl/Cmd` + `L`
-
-**Auto-indent current request**: `Ctrl/Cmd` + `I`
-
-**Jump to next request end**: `Ctrl/Cmd` + `↓`
-
-**Jump to previous request end**: `Ctrl/Cmd` + `↑`
-
-**Open documentation for current request**: `Ctrl/Cmd` + `/`
-
-**Run current request**: `Ctrl/Cmd` + `Enter`
-
-**Apply current or topmost term in autocomplete menu**: `Enter` or `Tab`
-
-**Close autocomplete menu**: `Esc`
-
-**Navigate items in autocomplete menu**: `↓` + `↑`
-
-
-### View API docs
-
-To view the documentation for an API endpoint, select the request, then open the contextual menu and select
-*Open API reference*.
-
-## Run requests
-
-When you're ready to submit the request, select the play button.
-
-The result of the request execution is displayed in the response panel, where you can see:
-
-- the JSON response
-- the HTTP status code corresponding to the request
-- The execution time, in ms.
-
-
-You can select multiple requests and submit them together.
-**Console** executes the requests one by one. Submitting multiple requests is helpful
-when you're debugging an issue or trying query
-combinations in multiple scenarios.
-
-
-## Import and export requests
-
-You can export requests:
-
-- **to a TXT file**, by using the **Export requests** button. When using this method, all content of the input panel is copied, including comments, requests, and payloads. All of the formatting is preserved and allows you to re-import the file later, or to a different environment, using the **Import requests** button.
-
-
- When importing a TXT file containing Console requests, the current content of the input panel is replaced. Export it first if you don't want to lose it, or find it in the **History** tab if you already ran the requests.
-
-
-- by copying them individually as **curl**, **JavaScript**, or **Python**. To do this, select a request, then open the contextual menu and select **Copy as**. When using this action, requests are copied individually to your clipboard. You can save your favorite language to make the copy action faster the next time you use it.
-
- When running copied requests from an external environment, you'll need to add [authentication information](https://www.elastic.co/docs/api/doc/serverless/authentication) to the request.
-
-## Get your request history
-
-*Console* maintains a list of the last 500 requests that you tried to execute.
-To view them, open the *History* tab.
-
-You can run a request from your history again by selecting the request and clicking **Add and run**. If you want to add it back to the Console input panel without running it yet, click **Add** instead. It is added to the editor at the current cursor position.
-
-## Configure Console settings
-
-Go to the **Config** tab of **Console** to customize its display, autocomplete, and accessibility settings.
-
-## Disable Console
-
-You can disable the persistent console that shows in the footer of your ((es)) project pages. To do that, go to **Management** > **Advanced Settings**, and turn off the `devTools:enablePersistentConsole` setting.
diff --git a/serverless/pages/saved-objects.mdx b/serverless/pages/saved-objects.mdx
deleted file mode 100644
index f5b99568..00000000
--- a/serverless/pages/saved-objects.mdx
+++ /dev/null
@@ -1,99 +0,0 @@
----
-slug: /serverless/saved-objects
-title: Saved objects
-description: Manage your saved objects, including dashboards, visualizations, maps, ((data-sources)), and more.
-tags: [ 'serverless', 'Elasticsearch', 'Observability', 'Security' ]
----
-
-
-This content applies to:
-
-To get started, go to **((project-settings)) → ((manage-app)) → ((saved-objects-app))**:
-
-
-{/* TO-DO: This screenshot needs to be refreshed and automated. */}
-
-{/*
-TBD: Need serverless-specific RBAC requirements
-## Required permissions
-
-To access **Saved Objects**, you must have the required `Saved Objects Management` ((kib)) privilege.
-
-To add the privilege, open the main menu, and then click **Management → Roles**.
-
-
-Granting access to `Saved Objects Management` authorizes users to
-manage all saved objects in ((kib)), including objects that are managed by
-applications they may not otherwise be authorized to access.
- */}
-
-## View and delete
-
-* To view and edit a saved object in its associated application, click the object title.
-
-* To show objects that use this object, so you know the impact of deleting it, click the actions icon and then select **Relationships**.
-
-* To delete one or more objects, select their checkboxes, and then click **Delete**.
-
-## Import and export
-
-Use import and export to move objects between different ((kib)) instances.
-These actions are useful when you have multiple environments for development and production.
-Import and export also work well when you have a large number of objects to update and want to batch the process.
-
-{/*
-TBD: Do these APIs exist for serverless?
-((kib)) also provides import and
-export APIs to automate this process.
-*/}
-
-### Import
-
-Import multiple objects in a single operation.
-
-1. In the toolbar, click **Import**.
-1. Select the NDJSON file that includes the objects you want to import.
-
-1. Select the import options. By default, saved objects already in ((kib)) are overwritten.
-
-1. Click **Import**.
-
-{/*
-TBD: Are these settings configurable in serverless?
-
-The `savedObjects.maxImportExportSize` configuration setting
-limits the number of saved objects to include in the file. The
-`savedObjects.maxImportPayloadBytes` setting limits the overall
-size of the file that you can import.
-
-*/}
-
-### Export
-
-Export objects by selection or type.
-
-* To export specific objects, select them in the table, and then click **Export**.
-* To export objects by type, click **Export objects** in the toolbar.
-
-((kib)) creates an NDJSON with all your saved objects.
-By default, the NDJSON includes child objects related to the saved objects.
-Exported dashboards include their associated ((data-sources)).
-
-{/*
-TBD: Are these settings configurable in serverless?
-
-The `savedObjects.maxImportExportSize` configuration setting limits the number of saved objects that you can export.
- */}
-
-## Copy to other spaces
-
-Copy saved objects and their related objects between spaces.
-
-1. Click the actions icon .
-1. Click **Copy to spaces**.
-1. Specify whether to automatically overwrite any objects that already exist
-in the target spaces, or resolve them on a per-object basis.
-1. Select the spaces in which to copy the object.
-
-The copy operation automatically includes child objects that are related to
-the saved object.
\ No newline at end of file
diff --git a/serverless/pages/search-playground.mdx b/serverless/pages/search-playground.mdx
deleted file mode 100644
index 11ce5a07..00000000
--- a/serverless/pages/search-playground.mdx
+++ /dev/null
@@ -1,18 +0,0 @@
----
-slug: /serverless/elasticsearch/playground
-title: Playground
-description: Test and edit Elasticsearch queries and chat with your data using LLMs.
-tags: ['serverless', 'elasticsearch', 'search', 'playground', 'GenAI', 'LLMs']
----
-
-
-
-Use the Search Playground to test and edit ((es)) queries visually in the UI. Then use the Chat Playground to combine your ((es)) data with large language models (LLMs) for retrieval augmented generation (RAG).
-You can also view the underlying Python code that powers the chat interface, and use it in your own application.
-
-Find Playground in the ((es)) serverless UI under **((es)) > Build > Playground**.
-
-
- ℹ️ The Playground documentation currently lives in the [((kib)) docs](https://www.elastic.co/guide/en/kibana/master/playground.html).
-
-
diff --git a/serverless/pages/search-with-synonyms.mdx b/serverless/pages/search-with-synonyms.mdx
deleted file mode 100644
index 9f3c1a87..00000000
--- a/serverless/pages/search-with-synonyms.mdx
+++ /dev/null
@@ -1,113 +0,0 @@
----
-slug: /serverless/elasticsearch/elasticsearch/reference/search-with-synonyms
-title: Full-text search with synonyms
-description: Use synonyms to search for words or phrases that have the same or similar meaning.
-tags: [ 'serverless', 'elasticsearch', 'search', 'synonyms' ]
----
-
-
-
-Synonyms are words or phrases that have the same or similar meaning.
-They are an important aspect of search, as they can improve the search experience and increase the scope of search results.
-
-Synonyms allow you to:
-
-* **Improve search relevance** by finding relevant documents that use different terms to express the same concept.
-* Make **domain-specific vocabulary** more user-friendly, allowing users to use search terms they are more familiar with.
-* **Define common misspellings and typos** to transparently handle common mistakes.
-
-Synonyms are grouped together using **synonyms sets**.
-You can have as many synonyms sets as you need.
-
-In order to use synonyms sets in ((es)), you need to:
-
-* Store your synonyms set
-* Configure synonyms token filters and analyzers
-
-## Store your synonyms set
-
-Your synonyms sets need to be stored in ((es)) so your analyzers can refer to them.
-There are two ways to store your synonyms sets:
-
-### Synonyms API
-
-You can use the [synonyms APIs](((ref))/synonyms-apis.html) to manage synonyms sets.
-This is the most flexible approach, as it allows to dynamically define and modify synonyms sets.
-
-Changes in your synonyms sets will automatically reload the associated analyzers.
-
-### Inline
-
-You can test your synonyms by adding them directly inline in your token filter definition.
-
-
-
-Inline synonyms are not recommended for production usage.
-A large number of inline synonyms increases cluster size unnecessarily and can lead to performance issues.
-
-
-
-
-
-### Configure synonyms token filters and analyzers
-
-Once your synonyms sets are created, you can start configuring your token filters and analyzers to use them.
-
-((es)) uses synonyms as part of the [analysis process](((ref))/analysis-overview.html).
-You can use two types of [token filter](((ref))/analysis-tokenfilters.html):
-
-* [Synonym graph token filter](((ref))/analysis-synonym-graph-tokenfilter.html): It is recommended to use it, as it can correctly handle multi-word synonyms ("hurriedly", "in a hurry").
-* [Synonym token filter](((ref))/analysis-synonym-tokenfilter.html): Not recommended if you need to use multi-word synonyms.
-
-Check each synonym token filter documentation for configuration details and instructions on adding it to an analyzer.
-
-### Test your analyzer
-
-You can test an analyzer configuration without modifying your index settings.
-Use the [analyze API](((ref))/indices-analyze.html) to test your analyzer chain:
-
-```bash
-curl "${ES_URL}/my-index/_analyze?pretty" \
--H "Authorization: ApiKey ${API_KEY}" \
--H "Content-Type: application/json" \
--d'
-{
- "tokenizer": "standard",
- "filter" : [
- "lowercase",
- {
- "type": "synonym_graph",
- "synonyms": ["pc => personal computer", "computer, pc, laptop"]
- }
- ],
- "text" : "Check how PC synonyms work"
-}
-```
-
-### Apply synonyms at index or search time
-
-Analyzers can be applied at [index time or search time](((ref))/analysis-index-search-time.html).
-
-You need to decide when to apply your synonyms:
-
-* Index time: Synonyms are applied when the documents are indexed into ((es)). This is a less flexible alternative, as changes to your synonyms require [reindexing](((ref))/docs-reindex.html).
-* Search time: Synonyms are applied when a search is executed. This is a more flexible approach, which doesn't require reindexing. If token filters are configured with `"updateable": true`, search analyzers can be [reloaded](((ref))/indices-reload-analyzers.html) when you make changes to your synonyms.
-
-Synonyms sets created using the synonyms API can only be used at search time.
-
-You can specify the analyzer that contains your synonyms set as a [search time analyzer](((ref))/specify-analyzer.html#specify-search-analyzer) or as an [index time analyzer](((ref))/specify-analyzer.html#specify-index-time-analyzer).
-
-The following example adds `my_analyzer` as a search analyzer to the `title` field in an index mapping:
-
-```JSON
- "mappings": {
- "properties": {
- "title": {
- "type": "text",
- "search_analyzer": "my_analyzer",
- "updateable": true
- }
- }
- }
-```
-
diff --git a/serverless/pages/search-your-data-semantic-search-elser.mdx b/serverless/pages/search-your-data-semantic-search-elser.mdx
deleted file mode 100644
index b2e95859..00000000
--- a/serverless/pages/search-your-data-semantic-search-elser.mdx
+++ /dev/null
@@ -1,374 +0,0 @@
----
-slug: /serverless/elasticsearch/elasticsearch/reference/semantic-search-elser
-title: "Tutorial: Semantic search with ELSER"
-description: Perform semantic search using ELSER, an NLP model trained by Elastic.
-tags: ['elasticsearch', 'elser', 'semantic search']
----
-
-
-
-
-
-Elastic Learned Sparse EncodeR - or ELSER - is an NLP model trained by Elastic
-that enables you to perform semantic search by using sparse vector
-representation. Instead of literal matching on search terms, semantic search
-retrieves results based on the intent and the contextual meaning of a search
-query.
-
-The instructions in this tutorial shows you how to use ELSER to perform semantic
-search on your data.
-
-
-Only the first 512 extracted tokens per field are considered during
-semantic search with ELSER. Refer to
-[this page](((ml-docs))/ml-nlp-limitations.html#ml-nlp-elser-v1-limit-512) for more
-information.
-
-
-
-
-## Requirements
-
-To perform semantic search by using ELSER, you must have the NLP model deployed
-in your cluster. Refer to the
-[ELSER documentation](((ml-docs))/ml-nlp-elser.html) to learn how to download and
-deploy the model.
-
-
-The minimum dedicated ML node size for deploying and using the ELSER model
-is 4 GB in Elasticsearch Service if
-[deployment autoscaling](((cloud))/ec-autoscaling.html) is turned off. Turning on
-autoscaling is recommended because it allows your deployment to dynamically
-adjust resources based on demand. Better performance can be achieved by using
-more allocations or more threads per allocation, which requires bigger ML nodes.
-Autoscaling provides bigger nodes when required. If autoscaling is turned off,
-you must provide suitably sized nodes yourself.
-
-
-
-
-## Create the index mapping
-
-First, the mapping of the destination index - the index that contains the tokens
-that the model created based on your text - must be created. The destination
-index must have a field with the
-[`sparse_vector`](((ref))/sparse-vector.html) or [`rank_features`](((ref))/rank-features.html) field
-type to index the ELSER output.
-
-
-ELSER output must be ingested into a field with the `sparse_vector` or
-`rank_features` field type. Otherwise, ((es)) interprets the token-weight pairs as
-a massive amount of fields in a document. If you get an error similar to this
-`"Limit of total fields [1000] has been exceeded while adding new fields"` then
-the ELSER output field is not mapped properly and it has a field type different
-than `sparse_vector` or `rank_features`.
-
-
-```bash
-curl -X PUT "${ES_URL}/my-index" \
--H "Authorization: ApiKey ${API_KEY}" \
--H "Content-Type: application/json" \
--d'
-{
- "mappings": {
- "properties": {
- "content_embedding": { [^1]
- "type": "sparse_vector" [^2]
- },
- "content": { [^3]
- "type": "text" [^4]
- }
- }
- }
-}
-'
-```
-[^1]: The name of the field to contain the generated tokens. It must be refrenced
-in the ((infer)) pipeline configuration in the next step.
-[^2]: The field to contain the tokens is a `sparse_vector` field.
-[^3]: The name of the field from which to create the sparse vector representation.
-In this example, the name of the field is `content`. It must be referenced in the
-((infer)) pipeline configuration in the next step.
-[^4]: The field type which is text in this example.
-
-To learn how to optimize space, refer to the Saving disk space by excluding the ELSER tokens from document source section.
-
-
-
-## Create an ingest pipeline with an inference processor
-
-Create an [ingest pipeline](((ref))/ingest.html) with an
-[inference processor](((ref))/inference-processor.html) to use ELSER to infer against the data
-that is being ingested in the pipeline.
-
-```bash
-curl -X PUT "${ES_URL}/_ingest/pipeline/elser-v2-test" \
--H "Authorization: ApiKey ${API_KEY}" \
--H "Content-Type: application/json" \
--d'
-{
- "processors": [
- {
- "inference": {
- "model_id": ".elser_model_2",
- "input_output": [ <1>
- {
- "input_field": "content",
- "output_field": "content_embedding"
- }
- ]
- }
- }
- ]
-}
-'
-```
-
-
-
-## Load data
-
-In this step, you load the data that you later use in the ((infer)) ingest
-pipeline to extract tokens from it.
-
-Use the `msmarco-passagetest2019-top1000` data set, which is a subset of the MS
-MARCO Passage Ranking data set. It consists of 200 queries, each accompanied by
-a list of relevant text passages. All unique passages, along with their IDs,
-have been extracted from that data set and compiled into a
-[tsv file](https://github.com/elastic/stack-docs/blob/main/docs/en/stack/ml/nlp/data/msmarco-passagetest2019-unique.tsv).
-
-Download the file and upload it to your cluster using the
-[Data Visualizer](((kibana-ref))/connect-to-elasticsearch.html#upload-data-kibana)
-in the ((ml-app)) UI. Assign the name `id` to the first column and `content` to
-the second column. The index name is `test-data`. Once the upload is complete,
-you can see an index named `test-data` with 182469 documents.
-
-
-
-## Ingest the data through the ((infer)) ingest pipeline
-
-Create the tokens from the text by reindexing the data throught the ((infer))
-pipeline that uses ELSER as the inference model.
-
-```bash
-curl -X POST "${ES_URL}/_reindex?wait_for_completion=false" \
--H "Authorization: ApiKey ${API_KEY}" \
--H "Content-Type: application/json" \
--d'
-{
- "source": {
- "index": "test-data",
- "size": 50 [^1]
- },
- "dest": {
- "index": "my-index",
- "pipeline": "elser-v2-test"
- }
-}
-'
-```
-[^1]: The default batch size for reindexing is 1000. Reducing `size` to a smaller
-number makes the update of the reindexing process quicker which enables you to
-follow the progress closely and detect errors early.
-
-The call returns a task ID to monitor the progress:
-
-```bash
-curl -X GET "${ES_URL}/_tasks/" \
--H "Authorization: ApiKey ${API_KEY}" \
-```
-
-You can also open the Trained Models UI, select the Pipelines tab under ELSER to
-follow the progress.
-
-
-
-## Semantic search by using the `sparse_vector` query
-
-To perform semantic search, use the `sparse_vector` query, and provide the
-query text and the inference ID associated with the ELSER model service. The example below uses the query text "How to
-avoid muscle soreness after running?", the `content_embedding` field contains
-the generated ELSER output:
-
-```bash
-curl -X GET "${ES_URL}/my-index/_search" \
--H "Authorization: ApiKey ${API_KEY}" \
--H "Content-Type: application/json" \
--d'
-{
- "query":{
- "sparse_vector":{
- "field": "content_embedding",
- "inference_id": "my-elser-endpoint",
- "query": "How to avoid muscle soreness after running?"
- }
- }
-}
-'
-```
-
-The result is the top 10 documents that are closest in meaning to your query
-text from the `my-index` index sorted by their relevancy. The result also
-contains the extracted tokens for each of the relevant search results with their
-weights.
-
-```consol-result
-"hits": {
- "total": {
- "value": 10000,
- "relation": "gte"
- },
- "max_score": 26.199875,
- "hits": [
- {
- "_index": "my-index",
- "_id": "FPr9HYsBag9jXmT8lEpI",
- "_score": 26.199875,
- "_source": {
- "content_embedding": {
- "muscular": 0.2821541,
- "bleeding": 0.37929374,
- "foods": 1.1718726,
- "delayed": 1.2112266,
- "cure": 0.6848574,
- "during": 0.5886185,
- "fighting": 0.35022718,
- "rid": 0.2752442,
- "soon": 0.2967024,
- "leg": 0.37649947,
- "preparation": 0.32974035,
- "advance": 0.09652356,
- (...)
- },
- "id": 1713868,
- "model_id": ".elser_model_2",
- "content": "For example, if you go for a run, you will mostly use the muscles in your lower body. Give yourself 2 days to rest those muscles so they have a chance to heal before you exercise them again. Not giving your muscles enough time to rest can cause muscle damage, rather than muscle development."
- }
- },
- (...)
- ]
-}
-```
-
-
-
-## Combining semantic search with other queries
-
-You can combine `sparse_vector` with other queries in a
-[compound query](((ref))/compound-queries.html). For example using a filter clause in a
-[Boolean query](((ref))/query-dsl-bool-query.html) or a full text query which may or may not use the same
-query text as the `sparse_vector` query. This enables you to combine the search
-results from both queries.
-
-The search hits from the `sparse_vector` query tend to score higher than other
-((es)) queries. Those scores can be regularized by increasing or decreasing the
-relevance scores of each query by using the `boost` parameter. Recall on the
-`sparse_vector` query can be high where there is a long tail of less relevant
-results. Use the `min_score` parameter to prune those less relevant documents.
-
-```bash
-curl -X GET "${ES_URL}/my-index/_search" \
--H "Authorization: ApiKey ${API_KEY}" \
--H "Content-Type: application/json" \
--d'
-{
- "query": {
- "bool": { [^1]
- "should": [
- {
- "sparse_vector": {
- "field": "content_embedding",
- "query": "How to avoid muscle soreness after running?",
- "inference_id": "my-elser-endpoint",
- "boost": 1 [^2]
- }
- }
- },
- {
- "query_string": {
- "query": "toxins",
- "boost": 4 [^3]
- }
- }
- ]
- }
- },
- "min_score": 10 [^4]
-}
-'
-```
-[^1]: Both the `sparse_vector` and the `query_string` queries are in a `should`
-clause of a `bool` query.
-[^2]: The `boost` value is `1` for the `sparse_vector` query which is the default
-value. This means that the relevance score of the results of this query are not
-boosted.
-[^3]: The `boost` value is `4` for the `query_string` query. The relevance score
-of the results of this query is increased causing them to rank higher in the
-search results.
-[^4]: Only the results with a score equal to or higher than `10` are displayed.
-
-
-
-## Optimizing performance
-
-
-
-### Saving disk space by excluding the ELSER tokens from document source
-
-The tokens generated by ELSER must be indexed for use in the
-[sparse_vector query](((ref))/query-dsl-sparse-vector-query.html). However, it is not
-necessary to retain those terms in the document source. You can save disk space
-by using the [source exclude](((ref))/mapping-source-field.html#include-exclude) mapping to remove the ELSER
-terms from the document source.
-
-
-Reindex uses the document source to populate the destination index.
-Once the ELSER terms have been excluded from the source, they cannot be
-recovered through reindexing. Excluding the tokens from the source is a
-space-saving optimsation that should only be applied if you are certain that
-reindexing will not be required in the future! It's important to carefully
-consider this trade-off and make sure that excluding the ELSER terms from the
-source aligns with your specific requirements and use case.
-
-
-The mapping that excludes `content_embedding` from the `_source` field can be
-created by the following API call:
-
-```bash
-curl -X PUT "${ES_URL}/my-index" \
--H "Authorization: ApiKey ${API_KEY}" \
--H "Content-Type: application/json" \
--d'
-{
- "mappings": {
- "_source": {
- "excludes": [
- "content_embedding"
- ]
- },
- "properties": {
- "content_embedding": {
- "type": "sparse_vector"
- },
- "content": {
- "type": "text"
- }
- }
- }
-}
-'
-```
-
-
-
-## Further reading
-
-* [How to download and deploy ELSER](((ml-docs))/ml-nlp-elser.html)
-* [ELSER limitation](((ml-docs))/ml-nlp-limitations.html#ml-nlp-elser-v1-limit-512)
-* [Improving information retrieval in the Elastic Stack: Introducing Elastic Learned Sparse Encoder, our new retrieval model](https://www.elastic.co/blog/may-2023-launch-information-retrieval-elasticsearch-ai-model)
-
-
-
-## Interactive example
-
-* The `elasticsearch-labs` repo has an interactive example of running [ELSER-powered semantic search](https://github.com/elastic/elasticsearch-labs/blob/main/notebooks/search/03-ELSER.ipynb) using the ((es)) Python client.
diff --git a/serverless/pages/search-your-data-semantic-search.mdx b/serverless/pages/search-your-data-semantic-search.mdx
deleted file mode 100644
index 8119fced..00000000
--- a/serverless/pages/search-your-data-semantic-search.mdx
+++ /dev/null
@@ -1,151 +0,0 @@
----
-slug: /serverless/elasticsearch/elasticsearch/reference/semantic-search
-title: Semantic search
-description: Find data based on the intent and contextual meaning of a search query with semantic search
-tags: ['elasticsearch', 'elser', 'semantic search']
----
-
-
-
-import DeployNlpModelWidget from '../partials/deploy-nlp-model-widget.mdx'
-import FieldMappingsWidget from '../partials/field-mappings-widget.mdx'
-import GenerateEmbeddingsWidget from '../partials/generate-embeddings-widget.mdx'
-import SearchWidget from '../partials/search-widget.mdx'
-import HybridSearchWidget from '../partials/hybrid-search-widget.mdx'
-
-
-
-Semantic search is a search method that helps you find data based on the intent
-and contextual meaning of a search query, instead of a match on query terms
-(lexical search).
-
-((es)) provides semantic search capabilities using [natural
-language processing (NLP)](((ml-docs))/ml-nlp.html) and vector search. Deploying an NLP model to ((es))
-enables it to extract text embeddings out of text. Embeddings are vectors that
-provide a numeric representation of a text. Pieces of content with similar
-meaning have similar representations.
-
-
-
-
-_A simplified representation of encoding textual concepts as vectors_
-
-At query time, ((es)) can use the same NLP model to convert a query into
-embeddings, enabling you to find documents with similar text embeddings.
-
-This guide shows you how to implement semantic search with ((es)), from selecting
-an NLP model, to writing queries.
-
-
-
-## Select an NLP model
-
-((es)) offers the usage of a
-[wide range of NLP models](((ml-docs))/ml-nlp-model-ref.html#ml-nlp-model-ref-text-embedding),
-including both dense and sparse vector models. Your choice of the language model
-is critical for implementing semantic search successfully.
-
-While it is possible to bring your own text embedding model, achieving good
-search results through model tuning is challenging. Selecting an appropriate
-model from our third-party model list is the first step. Training the model on
-your own data is essential to ensure better search results than using only BM25.
-However, the model training process requires a team of data scientists and ML
-experts, making it expensive and time-consuming.
-
-To address this issue, Elastic provides a pre-trained representational model
-called [Elastic Learned Sparse EncodeR (ELSER)](((ml-docs))/ml-nlp-elser.html).
-ELSER, currently available only for English, is an out-of-domain sparse vector
-model that does not require fine-tuning. This adaptability makes it suitable for
-various NLP use cases out of the box. Unless you have a team of ML specialists,
-it is highly recommended to use the ELSER model.
-
-In the case of sparse vector representation, the vectors mostly consist of zero
-values, with only a small subset containing non-zero values. This representation
-is commonly used for textual data. In the case of ELSER, each document in an
-index and the query text itself are represented by high-dimensional sparse
-vectors. Each non-zero element of the vector corresponds to a term in the model
-vocabulary. The ELSER vocabulary contains around 30000 terms, so the sparse
-vectors created by ELSER contain about 30000 values, the majority of which are
-zero. Effectively the ELSER model is replacing the terms in the original query
-with other terms that have been learnt to exist in the documents that best match
-the original search terms in a training dataset, and weights to control how
-important each is.
-
-
-
-## Deploy the model
-
-After you decide which model you want to use for implementing semantic search,
-you need to deploy the model in ((es)).
-
-
-
-
-
-## Map a field for the text embeddings
-
-Before you start using the deployed model to generate embeddings based on your
-input text, you need to prepare your index mapping first. The mapping of the
-index depends on the type of model.
-
-
-
-
-
-## Generate text embeddings
-
-Once you have created the mappings for the index, you can generate text
-embeddings from your input text. This can be done by using an
-[ingest pipeline](((ref))/ingest.html) with an [inference processor](((ref))/inference-processor.html).
-The ingest pipeline processes the input data and indexes it into the destination
-index. At index time, the inference ingest processor uses the trained model to
-infer against the data ingested through the pipeline. After you created the
-ingest pipeline with the inference processor, you can ingest your data through
-it to generate the model output.
-
-
-
-Now it is time to perform semantic search!
-
-
-
-## Search the data
-
-Depending on the type of model you have deployed, you can query sparse vectors
-with a sparse vector query, or dense vectors with a kNN search.
-
-
-
-
-
-## Beyond semantic search with hybrid search
-
-In some situations, lexical search may perform better than semantic search. For
-example, when searching for single words or IDs, like product numbers.
-
-Combining semantic and lexical search into one hybrid search request using
-[reciprocal rank fusion](((ref))/rrf.html) provides the best of both worlds. Not only that,
-but hybrid search using reciprocal rank fusion [has been shown to perform better
-in general](((blog-ref))improving-information-retrieval-elastic-stack-hybrid).
-
-
-
-
-
-## Read more
-
-* Tutorials:
- * Semantic search with ELSER
- * [Semantic search with the msmarco-MiniLM-L-12-v3 sentence-transformer model](((ml-docs))/ml-nlp-text-emb-vector-search-example.html)
-* Blogs:
- * [Introducing Elastic Learned Sparse Encoder: Elastic's AI model for semantic search](((blog-ref))may-2023-launch-sparse-encoder-ai-model)
- * [How to get the best of lexical and AI-powered search with Elastic's vector database](((blog-ref))lexical-ai-powered-search-elastic-vector-database)
- * Information retrieval blog series:
- * [Part 1: Steps to improve search relevance](((blog-ref))improving-information-retrieval-elastic-stack-search-relevance)
- * [Part 2: Benchmarking passage retrieval](((blog-ref))improving-information-retrieval-elastic-stack-benchmarking-passage-retrieval)
- * [Part 3: Introducing Elastic Learned Sparse Encoder, our new retrieval model](((blog-ref))may-2023-launch-information-retrieval-elasticsearch-ai-model)
- * [Part 4: Hybrid retrieval](((blog-ref))improving-information-retrieval-elastic-stack-hybrid)
-* Interactive examples:
- * The [`elasticsearch-labs`](https://github.com/elastic/elasticsearch-labs) repo contains a number of interactive semantic search examples in the form of executable Python notebooks, using the ((es)) Python client.
-
-{/* The include that was here is another page */}
diff --git a/serverless/pages/search-your-data-the-search-api.mdx b/serverless/pages/search-your-data-the-search-api.mdx
deleted file mode 100644
index 122c39d5..00000000
--- a/serverless/pages/search-your-data-the-search-api.mdx
+++ /dev/null
@@ -1,23 +0,0 @@
----
-slug: /serverless/elasticsearch/search-your-data-the-search-api
-title: The search API
-description: Run queries and aggregations with the search API.
-tags: [ 'serverless', 'elasticsearch', 'API' ]
----
-
-
-
-A _search_ consists of one or more queries that are combined and sent to ((es)).
-Documents that match a search's queries are returned in the _hits_, or
-_search results_, of the response.
-
-A search may also contain additional information used to better process its
-queries. For example, a search may be limited to a specific index or only return
-a specific number of results.
-
-You can use the [search API](https://www.elastic.co/docs/api/doc/elasticsearch-serverless/group/endpoint-search) to search and
-aggregate data stored in ((es)) data streams or indices.
-The API's `query` request body parameter accepts queries written in
-[Query DSL](((ref))/query-dsl.html).
-
-For more information, refer to [the search API overview](((ref))/search-your-data.html) in the classic ((es)) docs.
diff --git a/serverless/pages/search-your-data.mdx b/serverless/pages/search-your-data.mdx
deleted file mode 100644
index b1f7e885..00000000
--- a/serverless/pages/search-your-data.mdx
+++ /dev/null
@@ -1,28 +0,0 @@
----
-slug: /serverless/elasticsearch/search-your-data
-title: Search your data
-description: Use the search API to run queries on your data.
-tags: [ 'serverless', 'elasticsearch', 'search' ]
----
-
-
-A search query, or query, is a request for information about data in ((es)) data streams or indices.
-
-You can think of a query as a question, written in a way ((es)) understands. Depending on your data, you can use a query to get answers to questions like:
-
-- What processes on my server take longer than 500 milliseconds to respond?
-- What users on my network ran regsvr32.exe within the last week?
-- What pages on my website contain a specific word or phrase?
-
-You run search queries using the search API. The API supports several query types and search methods:
-
-**Search for exact values.**
-Use [term-level queries](((ref))/term-level-queries.html) to filter numbers, dates, IPs, or strings based on exact values or ranges.
-
-**Full-text search.**
-Use [full-text queries](((ref))/full-text-queries.html) to query [unstructured text](((ref))/analysis.html#analysis) and find documents that best match query terms. Use to search for words or phrases that have the same or similar meaning.
-
-**Vector search.**
-Store dense vectors in ((es)) and use approximate nearest neighbor (ANN) or k-nearest neighbor (kNN) search to find similar vectors.
-
-You can also use Elastic's natural language processing (NLP) model to encode text as sparse or dense vectors. Then use to find data based on the intent and contextual meaning rather than matching keywords.
diff --git a/serverless/pages/serverless-differences.mdx b/serverless/pages/serverless-differences.mdx
deleted file mode 100644
index 99c9bb80..00000000
--- a/serverless/pages/serverless-differences.mdx
+++ /dev/null
@@ -1,40 +0,0 @@
----
-slug: /serverless/elasticsearch/differences
-title: Differences from other Elasticsearch offerings
-description: Understand how serverless Elasticsearch differs from Elastic Cloud Hosted and self-managed offerings.
-tags: [ 'serverless', 'elasticsearch']
----
-
-
-
-Some features that are available in Elastic Cloud Hosted and self-managed offerings are not available in serverless ((es)).
-These features have either been replaced by a new feature, or are not applicable in the new Serverless architecture:
-
-- **Index lifecycle management (((ilm-init)))** is not available, in favor of ****.
-
- In an Elastic Cloud Hosted or self-managed environment, ((ilm-init)) lets you automatically transition indices through data tiers according to your
- performance needs and retention requirements. This allows you to balance hardware costs with performance. Serverless Elasticsearch eliminates this
- complexity by optimizing your cluster performance for you.
-
- Data stream lifecycle is an optimized lifecycle tool that lets you focus on the most common lifecycle management needs, without unnecessary
- hardware-centric concepts like data tiers.
-
-- **Watcher** is not available, in favor of ****.
-
- Kibana Alerts allows rich integrations across use cases like APM, metrics, security, and uptime. Prepackaged rule types simplify setup and
- hide the details of complex, domain-specific detections, while providing a consistent interface across Kibana.
-
-- Certain APIs, API parameters, index, cluster and node level settings are not available. Refer to our
- for a list of available APIs.
-
- Serverless Elasticsearch manages the underlying Elastic cluster for you, optimizing nodes, shards, and replicas for your use case.
- Because of this, various management and monitoring APIs, API parameters and settings are not available on Serverless.
-
-- [Scripted metric aggregations](((ref))/search-aggregations-metrics-scripted-metric-aggregation.html) are not available.
-
-
-
-For serverless technical preview limitations, refer to .
-
-
diff --git a/serverless/pages/service-status.mdx b/serverless/pages/service-status.mdx
deleted file mode 100644
index a61c481c..00000000
--- a/serverless/pages/service-status.mdx
+++ /dev/null
@@ -1,25 +0,0 @@
----
-slug: /serverless/general/serverless-status
-title: Monitor serverless status
-tags: ['serverless']
----
-
-Serverless projects run on cloud platforms, which may undergo changes in availability.
-When availability changes, Elastic makes sure to provide you with a current service status.
-
-To check current and past service availability, go to the Elastic serverless [service status](https://serverless-preview-status.statuspage.io/) page.
-
-## Subscribe to updates
-
-You can be notified about changes to the service status automatically.
-
-To receive service status updates:
-
-1. Go to the Elastic serverless [service status](https://serverless-preview-status.statuspage.io/) page.
-2. Select **SUBSCRIBE TO UPDATES**.
-3. You can be notified in the following ways:
- - Email
- - Slack
- - Atom or RSS feeds
-
-After you subscribe, you'll be notified whenever a service status update is posted.
diff --git a/serverless/pages/sign-up.mdx b/serverless/pages/sign-up.mdx
deleted file mode 100644
index eb4aa29e..00000000
--- a/serverless/pages/sign-up.mdx
+++ /dev/null
@@ -1,85 +0,0 @@
----
-slug: /serverless/general/sign-up-trial
-title: Get started with serverless
-description: Information about signing up for a serverless Elastic Cloud trial
-tags: [ 'serverless', 'general', 'signup' ]
----
-
-There are two options to create serverless projects:
-
-- If you are an existing customer, [log in to Elastic Cloud](https://cloud.elastic.co/login). On the home page, you will see a new option to create serverless projects. Note that if you are already subscribed to Elastic Cloud, there is no specific trial for serverless projects.
-
-- If you are a new user, you can [sign up for a free 14-day trial](https://cloud.elastic.co/serverless-registration), and you will be able to launch a serverless project.
-
-## What is included in my trial?
-
-Your free 14-day trial includes:
-
-**One hosted deployment**
-
- A deployment lets you explore Elastic solutions for Search, Observability, and Security. Trial deployments run on the latest version of the Elastic Stack. They includes 8 GB of RAM spread out over two availability zones, and enough storage space to get you started. If you’re looking to evaluate a smaller workload, you can scale down your trial deployment.
-Each deployment includes Elastic features such as Maps, SIEM, machine learning, advanced security, and much more. You have some sample data sets to play with and tutorials that describe how to add your own data.
-
-**One serverless project**
-
- Serverless projects package Elastic Stack features by type of solution:
-
-- [Elasticsearch](https://www.elastic.co/docs/current/serverless/elasticsearch/what-is-elasticsearch-serverless)
-- [Observability](https://www.elastic.co/docs/current/serverless/observability/what-is-observability-serverless)
-- [Security](https://www.elastic.co/docs/current/serverless/security/what-is-security-serverless)
-
-When you create a project, you select the project type applicable to your use case, so only the relevant and impactful applications and features are easily accessible to you.
-
-
- During the trial period, you are limited to one active hosted deployment and one active serverless project at a time. When you subscribe, you can create additional deployments and projects.
-
-
-## What limits are in place during a trial?
-
-During the free 14 day trial, Elastic provides access to one hosted deployment and one serverless project. If all you want to do is try out Elastic, the trial includes more than enough to get you started. During the trial period, some limitations apply.
-
-**Hosted deployments**
-
-- You can have one active deployment at a time
-- The deployment size is limited to 8GB RAM and approximately 360GB of storage, depending on the specified hardware profile
-- Machine learning nodes are available up to 4GB RAM
-- Custom Elasticsearch plugins are not enabled
-
-**Serverless projects**
-
-- You can have one active serverless project at a time.
-- Search Power is limited to 100. This setting only exists in Elasticsearch projects
-- Search Boost Window is limited to 7 days. This setting only exists in Elasticsearch projects
-
-**How to remove restrictions?**
-
-To remove limitations, subscribe to [Elastic Cloud](https://www.elastic.co/guide/en/cloud/current/ec-billing-details.html). Elastic Cloud subscriptions include the following benefits:
-
-- Increased memory or storage for deployment components, such as Elasticsearch clusters, machine learning nodes, and APM server.
-- As many deployments and projects as you need.
-- Third availability zone for your deployments.
-- Access to additional features, such as cross-cluster search and cross-cluster replication.
-
-You can subscribe to Elastic Cloud at any time during your trial. Billing starts when you subscribe. To maximize the benefits of your trial, subscribe at the end of the free period. To monitor charges, anticipate future costs, and adjust your usage, check your [account usage](https://www.elastic.co/guide/en/cloud/current/ec-account-usage.html) and [billing history](https://www.elastic.co/guide/en/cloud/current/ec-billing-history.html).
-
-## How do I get started with my trial?
-
-Start by checking out some common approaches for [moving data into Elastic Cloud](https://www.elastic.co/guide/en/cloud/current/ec-cloud-ingest-data.html#ec-ingest-methods).
-
-## What happens at the end of the trial?
-
-When your trial expires, the deployment and project that you created during the trial period are suspended until you subscribe to [Elastic Cloud](https://www.elastic.co/guide/en/cloud/current/ec-billing-details.html). When you subscribe, you are able to resume your deployment and serverless project, and regain access to the ingested data. After your trial expires, you have 30 days to subscribe. After 30 days, your deployment, serverless project, and ingested data are permanently deleted.
-
-If you’re interested in learning more ways to subscribe to Elastic Cloud, don’t hesitate to [contact us](https://www.elastic.co/contact).
-
-## How do I sign up through a marketplace?
-
-If you’re interested in consolidated billing, subscribe from the AWS Marketplace, which allows you to skip the trial period and connect your AWS Marketplace email to your unique Elastic account.
-
-
- Serverless projects are only available for AWS Marketplace. Support for GCP Marketplace and Azure Marketplace will be added in the near future.
-
-
-## How do I get help?
-
-We’re here to help. If you have any questions, reach out to [Support](https://cloud.elastic.co/support).
diff --git a/serverless/pages/spaces.mdx b/serverless/pages/spaces.mdx
deleted file mode 100644
index 6af2ea12..00000000
--- a/serverless/pages/spaces.mdx
+++ /dev/null
@@ -1,60 +0,0 @@
----
-slug: /serverless/spaces
-title: Spaces
-description: Organize your project and objects into multiple spaces.
----
-
-This content applies to:
-
-
-Spaces enable you to organize your dashboards and other saved
-objects into meaningful categories. Once inside a space, you see only
-the dashboards and saved objects that belong to that space.
-
-When you create and enter a new project, you're using the default space of that project.
-
-You can identify the space you're in or switch to a different space from the header.
-
-
-
-You can view and manage the spaces of a project from the **Spaces** page in **Management**.
-
-## Required permissions
-
-You must have an admin role on the project to manage its **Spaces**.
-
-## Create or edit a space
-
-You can have up to 100 spaces in a project.
-
-1. Click **Create space** or select the space you want to edit.
-
-2. Provide:
- - A meaningful name and description for the space.
- - A URL identifier. The URL identifier is a short text string that becomes part of the ((kib)) URL. ((kib)) suggests a URL identifier based on the name of your space, but you can customize the identifier to your liking. You cannot change the space identifier later.
-
-3. Customize the avatar of the space to your liking.
-
-4. Save the space.
-
-((kib)) also has an [API](https://www.elastic.co/docs/api/doc/serverless/group/endpoint-spaces)
-if you prefer to create spaces programmatically.
-
-
-## Customize access to space
-
-Customizing access to a space is available for the following project types only:
-
-As an administrator, you can define custom roles with specific access to certain spaces and features in a project. Refer to .
-
-
-## Delete a space
-
-Deleting a space permanently removes the space and all of its contents.
-Find the space on the *Spaces* page and click the trash icon in the Actions column.
-
-You can't delete the default space, but you can customize it to your liking.
-
-## Move saved objects between spaces
-
-To move saved objects between spaces, you can copy objects or export and import objects.
diff --git a/serverless/pages/tags.mdx b/serverless/pages/tags.mdx
deleted file mode 100644
index 465c7a02..00000000
--- a/serverless/pages/tags.mdx
+++ /dev/null
@@ -1,71 +0,0 @@
----
-slug: /serverless/tags
-title: ((tags-app))
-description: Use tags to categorize your saved objects, then filter for related objects based on shared tags.
-tags: [ 'serverless', 'Elasticsearch', 'Observability', 'Security' ]
----
-
-
-This content applies to:
-
-To get started, go to **((project-settings)) → ((manage-app)) → ((tags-app))**:
-
-
-
-{/*
-TBD: What are the serverless RBAC requirements?
-## Required permissions
-
-To create tags, you must meet the minimum requirements.
-
-* Access to **Tags** requires the `Tag Management` Kibana privilege. To add the privilege, open the main menu,
- and then click **Management → Custom Roles**.
-
-* The `read` privilege allows you to assign tags to the saved objects for which you have write permission.
-* The `write` privilege enables you to create, edit, and delete tags.
-
-
-Having the `Tag Management` ((kib)) privilege is not required to
-view tags assigned on objects you have `read` access to, or to filter objects by tags
-from the global search.
-
-*/}
-
-## Create a tag
-
-Create a tag to assign to your saved objects.
-
-1. Click **Create tag**.
-
-1. Enter a name and select a color for the new tag.
-
- The name cannot be longer than 50 characters.
-
-1. Click **Create tag**.
-
-## Assign a tag to an object
-
-{/*
-TBD: Do these RBAC requirements exist in serverless?
-To assign and remove tags, you must have `write` permission on the objects to which you assign the tags.
-*/}
-
-1. Find the tag you want to assign.
-
-1. Click the actions icon and then select **Manage assignments**.
-
-1. Select the objects to which you want to assign or remove tags.
-
- 
-
-1. Click **Save tag assignments**.
-
-## Delete a tag
-
-When you delete a tag, you remove it from all saved objects that use it.
-
-1. Click the actions icon, and then select **Delete**.
-
-1. Click **Delete tag**.
-
-To assign, delete, or clear multiple tags, select them in the **Tags** view, and then select the action from the **selected tags** menu.
diff --git a/serverless/pages/technical-preview-limitations.mdx b/serverless/pages/technical-preview-limitations.mdx
deleted file mode 100644
index 54848cde..00000000
--- a/serverless/pages/technical-preview-limitations.mdx
+++ /dev/null
@@ -1,26 +0,0 @@
----
-slug: /serverless/elasticsearch/technical-preview-limitations
-title: Technical preview limitations
-description: Review the limitations that apply to Elasticsearch projects.
-tags: [ 'serverless', 'elasticsearch']
----
-
-
-
-The following are currently not available:
-
-- Custom plugins and custom bundles
-- Reindexing from remote clusters
-- Cross-cluster search and cross-cluster replication
-- Snapshot and restore
-- Clone index API
-- Migrations from non-serverless ((es)) deployments. In the interim, you can use Logstash to move data to and from serverless projects.
-- Custom roles
-- Audit logging
-- Elasticsearch for Apache Hadoop
-
-Currently, workloads outside of the following ranges may experience higher latencies (greater than sub-second):
-
-- Search queries on indices greater than 150GB
-- Index queries per second (QPS) greater than 1000
-- Search queries per second (QPS) greater than 1800
\ No newline at end of file
diff --git a/serverless/pages/transforms.mdx b/serverless/pages/transforms.mdx
deleted file mode 100644
index 6316ad33..00000000
--- a/serverless/pages/transforms.mdx
+++ /dev/null
@@ -1,41 +0,0 @@
----
-slug: /serverless/transforms
-title: ((transforms-app))
-description: Use transforms to pivot existing indices into summarized or entity-centric indices.
-tags: [ 'serverless', 'Elasticsearch', 'Observability', 'Security' ]
----
-
-
-This content applies to:
-
-((transforms-cap)) enable you to convert existing ((es)) indices into summarized
-indices, which provide opportunities for new insights and analytics.
-
-For example, you can use ((transforms)) to pivot your data into entity-centric
-indices that summarize the behavior of users or sessions or other entities in
-your data. Or you can use ((transforms)) to find the latest document among all the
-documents that have a certain unique key.
-
-For more information, check out:
-
-* [When to use transforms](((ref))/transform-usage.html)
-* [Generating alerts for transforms](((ref))/transform-alerts.html)
-* [Transforms at scale](((ref))/transform-scale.html)
-* [How checkpoints work](((ref))/transform-checkpoints.html)
-* [Examples](((ref))/transform-examples.html)
-* [Painless examples](((ref))/transform-painless-examples.html)
-* [Troubleshooting transforms](((ref))/transform-troubleshooting.html)
-* [Limitations](((ref))/transform-limitations.html)
-
-## Create and manage ((transforms))
-
-In **((project-settings)) → ((manage-app)) → ((transforms-app))**, you can
-create, edit, stop, start, reset, and delete ((transforms)):
-
-
-
-When you create a ((transform)), you must choose between two types: _pivot_ and _latest_.
-You must also decide whether you want the ((transform)) to run once or continuously.
-For more information, go to [((transforms-cap)) overview](((ref))/transform-overview.html).
-
-{/* To stop, start, or delete multiple ((transforms)), select their checkboxes then click.... */}
\ No newline at end of file
diff --git a/serverless/pages/user-profile.mdx b/serverless/pages/user-profile.mdx
deleted file mode 100644
index bd6b10d0..00000000
--- a/serverless/pages/user-profile.mdx
+++ /dev/null
@@ -1,53 +0,0 @@
----
-slug: /serverless/general/user-profile
-title: Update your user profile
-description: Manage your profile settings.
-tags: [ 'serverless', 'general', 'profile', 'update' ]
----
-
-
-To edit your user profile, go to the user icon on the header bar and select **Profile**.
-
-## Update your email address
-
-Your email address is used to sign in. If needed, you can change this email address.
-1. In the **Profile** section, by **Email address**, select **Edit**.
-
-1. Enter a new email address and your current password.
-
- An email is sent to the new address with a link to confirm the change. If you don't get the email after a few minutes, check your spam folder.
-
-## Change your password
-
-When you signed up with your email address, you selected a password that you use to log in to the Elastic Cloud console. If needed, you can change this password.
-
-If you know your current password:
-
-1. Navigate to the **Password** section and select **Change password**.
-
-1. Enter the current password and provide the new password that you want to use.
-
-If you don't know your current password:
-
-1. At the login screen for the Elastic Cloud console, select the link **Forgot password?**
-
-1. Enter the email address for your account and select **Reset password**.
-
- An email is sent to the address you specified with a link to reset the password. If you don't get the email after a few minutes, check your spam folder.
-
-## Enable multi-factor authentication
-
-To add an extra layer of security, you can either set up Google authenticator or text messaging on a mobile device.
-
-
-Before you start using multi-factor authentication, verify that your device has SMS capabilities or download the Google Authenticator application onto your device.
-
-
-To enable multi-factor authentication, you must enroll your device.
-
-1. Navigate to the **Multi-factor authentication** section.
-
-1. Select **Configure** to enable the Authenticator app or **Add a phone number** to enable the Text message.
-
-If the device you want to remove is your only enrolled device, you must disable multi-factor authentication first. If your device is lost or stolen, contact [support](https://support.elastic.co/).
-
diff --git a/serverless/pages/visualize-library.mdx b/serverless/pages/visualize-library.mdx
deleted file mode 100644
index eee26773..00000000
--- a/serverless/pages/visualize-library.mdx
+++ /dev/null
@@ -1,24 +0,0 @@
----
-slug: /serverless/visualize-library
-title: Visualize Library
-#description: Add description here.
-tags: [ 'serverless', 'Elasticsearch', 'Observability', 'Security' ]
----
-
-{/* TODO: Figure out best way to deal with inconsistent location of these capabilities in different solutions.
-This content has been removed from the navigation for now because it's not useful in its current state.*/}
-
-This content applies to:
-
-The **Visualize Library** is a space where you can save visualization panels that you may want to use across multiple dashboards. The **Visualize Library** consists of two pages:
-
-* **Visualizations**
-* **Annotation groups**
-
-## Visualizations
-
-By default the **Visualizations** page opens first. Here you can create new visualizations, or select from a list of previously created visualizations. To learn more, refer to save to the Visualize Library.
-
-## Annotation groups
-
-**Annotation groups** give you the option to mark points on a visualization panel with events, such as a deployment, to help track performance. These annotations can be reused across multiple visualization panels.
\ No newline at end of file
diff --git a/serverless/pages/welcome-to-serverless.mdx b/serverless/pages/welcome-to-serverless.mdx
deleted file mode 100644
index 71202d54..00000000
--- a/serverless/pages/welcome-to-serverless.mdx
+++ /dev/null
@@ -1,86 +0,0 @@
----
-slug: /serverless
-title: Welcome to Elastic Cloud Serverless
-tags: ['serverless']
-layout: landing
----
-
-# Elastic Cloud Serverless
-
-Elastic Cloud Serverless products allow you to deploy and use Elastic for your use cases without managing the underlying Elastic cluster,
-such as nodes, data tiers, and scaling. Serverless instances are fully-managed, autoscaled, and automatically upgraded by Elastic so you can
-focus more on gaining value and insight from your data.
-
-Elastic provides three serverless solutions available on ((ecloud)):
-
-- **((es))** — Build powerful applications and search experiences using a rich ecosystem of vector search capabilities, APIs, and libraries.
-- **((observability))** — Monitor your own platforms and services using powerful machine learning and analytics tools with your logs, metrics, traces, and APM data.
-- **((security))** — Detect, investigate, and respond to threats, with SIEM, endpoint protection, and AI-powered analytics capabilities.
-
-Serverless instances of the Elastic Stack that you create in ((ecloud)) are called **serverless projects**.
-
-Elastic Cloud Serverless products are currently in preview. [Learn more about serverless in our blog](https://www.elastic.co/blog/elastic-serverless-architecture).
-
-
-
-## Get started
-
-Choose the type of project that matches your needs and we’ll help you get started with our solution guides.
-
-
-
-
-
-
-
-
diff --git a/serverless/pages/what-is-elasticsearch-serverless.mdx b/serverless/pages/what-is-elasticsearch-serverless.mdx
deleted file mode 100644
index 5560e366..00000000
--- a/serverless/pages/what-is-elasticsearch-serverless.mdx
+++ /dev/null
@@ -1,74 +0,0 @@
----
-slug: /serverless/elasticsearch/what-is-elasticsearch-serverless
-title: What is Elasticsearch on serverless?
-description: Build search solutions and applications with ((es)).
-tags: [ 'serverless', 'elasticsearch', 'overview' ]
-layout: landing
----
-
-
-
-
-
-
-
-Refer to and for important details, including features and limitations specific to ((es)) on serverless.
-
-
-
-
-
-
diff --git a/serverless/pages/what-is-serverless.mdx b/serverless/pages/what-is-serverless.mdx
deleted file mode 100644
index ca804e52..00000000
--- a/serverless/pages/what-is-serverless.mdx
+++ /dev/null
@@ -1,95 +0,0 @@
----
-slug: /serverless/general/what-is-serverless-elastic
-title: What is serverless Elastic?
-tags: ['serverless']
----
-
-Serverless projects use the core components of the ((stack)), such as ((es)) and ((kib)), and are based on [an architecture that
-decouples compute and storage](https://www.elastic.co/blog/elastic-serverless-architecture). Search and indexing operations are separated, which offers high flexibility for scaling your workloads while ensuring
-a high level of performance.
-
-**Management free.** Elastic manages the underlying Elastic cluster, so you can focus on your data. With serverless projects, Elastic is responsible for automatic upgrades, data backups,
-and business continuity.
-
-**Autoscaled.** To meet your performance requirements, the system automatically adjusts to your workloads. For example, when you have a short time spike on the
-data you ingest, more resources are allocated for that period of time. When the spike is over, the system uses less resources, without any action
-on your end.
-
-**Optimized data storage.** Your data is stored in cost-efficient, general storage. A cache layer is available on top of the general storage for recent and frequently queried data that provides faster search speed.
-The size of the cache layer and the volume of data it holds depend on that you can configure for each project.
-
-**Dedicated experiences.** All serverless solutions are built on the Elastic Search Platform and include the core capabilities of the Elastic Stack. They also each offer a distinct experience and specific capabilities that help you focus on your data, goals, and use cases.
-
-**Pay per usage.** Each serverless project type includes product-specific and usage-based pricing.
-
-
- Until May 31, 2024, your serverless consumption will not incur any charges, but will be visible along with your total Elastic Cloud consumption on the [Billing Usage page](https://cloud.elastic.co/billing/usage). Unless you are in a trial period, usage on or after June 1, 2024 will be deducted from your existing Elastic Cloud credits or be billed to your active payment method.
-
-
-## Control your data and performance
-
-Control your project data and query performance against your project data.
-
-**Data.** Choose the data you want to ingest, and the method to ingest it. By default, data is stored indefinitely in your project,
-and you define the retention settings for your data streams.
-
-**Performance.** For granular control over costs and query performance against your project data, serverless projects come with a set of predefined that you can edit.
-
-
-
-## Differences between serverless projects and hosted deployments on ((ecloud))
-
-You can run [hosted deployments](https://www.elastic.co/guide/en/cloud/current/ec-getting-started.html) of the ((stack)) on ((ecloud)). These hosted deployments provide more provisioning and advanced configuration options.
-
-| Option | Serverless | Hosted |
-|------------------------|:----------------------------------------------------------|:----------------------------------------------------------------------------------|
-| **Cluster management** | Fully managed by Elastic. | You provision and manage your hosted clusters. Shared responsibility with Elastic.|
-| **Scaling** | Autoscales out of the box. | Manual scaling or autoscaling available for you to enable. |
-| **Upgrades** | Automatically performed by Elastic. | You choose when to upgrade. |
-| **Pricing** | Individual per project type and based on your usage. | Based on deployment size and subscription level. |
-| **Performance** | Autoscales based on your usage. | Manual scaling. |
-| **Solutions** | Single solution per project. | Full Elastic Stack per deployment. |
-| **User management** | Elastic Cloud-managed users. | Elastic Cloud-managed users and native Kibana users. |
-| **API support** | Subset of [APIs](https://www.elastic.co/docs/api). | All Elastic APIs. |
-| **Backups** | Projects automatically backed up by Elastic. | Your responsibility with Snapshot & Restore. |
-| **Data retention** | Editable on data streams. | Index Lifecycle Management. |
-
-## Answers to common serverless questions
-
-**What Support is available for the serverless preview?**
-
-There is no official SLA for Support in Serverless until General Availability (GA). We’ll do our best to service customers and inquiries as we would any pre-GA product - at a Platinum/Enterprise Severity 3 (1 business day) SLA target.
-
-**Is there migration support between hosted deployments and serverless projects?**
-
-Migration paths between hosted deployments and serverless projects are currently unsupported.
-
-**How can I move data to or from serverless projects?**
-
-We are working on data migration tools! In the interim, you can use Logstash with Elasticsearch input and output plugins to move data to and from serverless projects.
-
-**How does serverless ensure compatibility between software versions?**
-
-Connections and configurations are unaffected by upgrades. To ensure compatibility between software versions, quality testing and API versioning are used.
-
-**Can I convert a serverless project into a hosted deployment, or a hosted deployment into a serverless project?**
-
-Projects and deployments are based on different architectures, and you are unable to convert.
-
-**Can I convert a serverless project into a project of a different type?**
-
-You are unable to convert projects into different project types, but you can create as many projects as you’d like. You will be charged only for your usage.
-
-**How can I create serverless service accounts?**
-
-Create API keys for service accounts in your serverless projects. Options to automate the creation of API keys with tools such as Terraform will be available in the future.
-
-To raise a Support case with Elastic, raise a case for your subscription the same way you do today. In the body of the case, make sure to mention you are working in serverless to ensure we can provide the appropriate support.
-
-**Where can I learn about pricing for serverless?**
-
-See serverless pricing information for [Search](https://www.elastic.co/pricing/serverless-search), [Observability](https://www.elastic.co/pricing/serverless-observability), and [Security](https://www.elastic.co/pricing/serverless-security).
-
-**Can I request backups or restores for my projects?**
-
-It is not currently possible to request backups or restores for projects, but we are working on data migration tools to better support this.
diff --git a/serverless/partials/deploy-nlp-model-dense-vector.mdx b/serverless/partials/deploy-nlp-model-dense-vector.mdx
deleted file mode 100644
index 938fa80e..00000000
--- a/serverless/partials/deploy-nlp-model-dense-vector.mdx
+++ /dev/null
@@ -1,5 +0,0 @@
-
-
-
-To deploy a third-party text embedding model, refer to
-[Deploy a text embedding model](((ml-docs))/ml-nlp-text-emb-vector-search-example.html#ex-te-vs-deploy).
diff --git a/serverless/partials/deploy-nlp-model-elser.mdx b/serverless/partials/deploy-nlp-model-elser.mdx
deleted file mode 100644
index 635146c9..00000000
--- a/serverless/partials/deploy-nlp-model-elser.mdx
+++ /dev/null
@@ -1,5 +0,0 @@
-
-
-
-To deploy ELSER, refer to
-[Download and deploy ELSER](((ml-docs))/ml-nlp-elser.html#download-deploy-elser).
diff --git a/serverless/partials/deploy-nlp-model-widget.mdx b/serverless/partials/deploy-nlp-model-widget.mdx
deleted file mode 100644
index 5d008b2a..00000000
--- a/serverless/partials/deploy-nlp-model-widget.mdx
+++ /dev/null
@@ -1,12 +0,0 @@
-
-import Elser from './deploy-nlp-model-elser.mdx'
-import DenseVector from './deploy-nlp-model-dense-vector.mdx'
-
-
-
-
-
-
-
-
-
\ No newline at end of file
diff --git a/serverless/partials/field-mappings-dense-vector.mdx b/serverless/partials/field-mappings-dense-vector.mdx
deleted file mode 100644
index d7223577..00000000
--- a/serverless/partials/field-mappings-dense-vector.mdx
+++ /dev/null
@@ -1,51 +0,0 @@
-
-
-
-The models compatible with ((es)) NLP generate dense vectors as output. The
-[`dense_vector`](((ref))/dense-vector.html) field type is suitable for storing dense vectors
-of numeric values. The index must have a field with the `dense_vector` field
-type to index the embeddings that the supported third-party model that you
-selected generates. Keep in mind that the model produces embeddings with a
-certain number of dimensions. The `dense_vector` field must be configured with
-the same number of dimensions using the `dims` option. Refer to the respective
-model documentation to get information about the number of dimensions of the
-embeddings.
-
-To review a mapping of an index for an NLP model, refer to the mapping code
-snippet in the
-[Add the text embedding model to an ingest inference pipeline](((ml-docs))/ml-nlp-text-emb-vector-search-example.html#ex-text-emb-ingest)
-section of the tutorial. The example shows how to create an index mapping that
-defines the `my_embeddings.predicted_value` field - which will contain the model
-output - as a `dense_vector` field.
-
-```bash
-curl -X PUT "${ES_URL}/my-index" \
--H "Authorization: ApiKey ${API_KEY}" \
--H "Content-Type: application/json" \
--d'
-{
- "mappings": {
- "properties": {
- "my_embeddings.predicted_value": { [^1]
- "type": "dense_vector", [^2]
- "dims": 384 [^3]
- },
- "my_text_field": { [^4]
- "type": "text" [^5]
- }
- }
- }
-}
-'
-```
-[^1]: The name of the field that will contain the embeddings generated by the
-model.
-[^2]: The field that contains the embeddings must be a `dense_vector` field.
-[^3]: The model produces embeddings with a certain number of dimensions. The
-`dense_vector` field must be configured with the same number of dimensions by
-the `dims` option. Refer to the respective model documentation to get
-information about the number of dimensions of the embeddings.
-[^4]: The name of the field from which to create the dense vector representation.
-In this example, the name of the field is `my_text_field`.
-[^5]: The field type is `text` in this example.
-
diff --git a/serverless/partials/field-mappings-elser.mdx b/serverless/partials/field-mappings-elser.mdx
deleted file mode 100644
index 1de0b5b8..00000000
--- a/serverless/partials/field-mappings-elser.mdx
+++ /dev/null
@@ -1,38 +0,0 @@
-
-
-
-ELSER produces token-weight pairs as output from the input text and the query.
-The ((es)) [`sparse_vector`](((ref))/sparse-vector.html) field type can store these
-token-weight pairs as numeric feature vectors. The index must have a field with
-the `sparse_vector` field type to index the tokens that ELSER generates.
-
-To create a mapping for your ELSER index, refer to the
-of the tutorial. The example
-shows how to create an index mapping for `my-index` that defines the
-`my_embeddings.tokens` field - which will contain the ELSER output - as a
-`sparse_vector` field.
-
-```bash
-curl -X PUT "${ES_URL}/my-index" \
--H "Authorization: ApiKey ${API_KEY}" \
--H "Content-Type: application/json" \
--d'
-{
- "mappings": {
- "properties": {
- "my_tokens": { [^1]
- "type": "sparse_vector" [^2]
- },
- "my_text_field": { [^3]
- "type": "text" [^4]
- }
- }
- }
-}
-'
-```
-[^1]: The name of the field that will contain the tokens generated by ELSER.
-[^2]: The field that contains the tokens must be a `sparse_vector` field.
-[^3]: The name of the field from which to create the sparse vector representation.
-In this example, the name of the field is `my_text_field`.
-[^4]: The field type is `text` in this example.
diff --git a/serverless/partials/field-mappings-widget.mdx b/serverless/partials/field-mappings-widget.mdx
deleted file mode 100644
index 35fdce60..00000000
--- a/serverless/partials/field-mappings-widget.mdx
+++ /dev/null
@@ -1,12 +0,0 @@
-
-import Elser from './field-mappings-elser.mdx'
-import DenseVector from './field-mappings-dense-vector.mdx'
-
-
-
-
-
-
-
-
-
\ No newline at end of file
diff --git a/serverless/partials/generate-embeddings-dense-vector.mdx b/serverless/partials/generate-embeddings-dense-vector.mdx
deleted file mode 100644
index 0964acfe..00000000
--- a/serverless/partials/generate-embeddings-dense-vector.mdx
+++ /dev/null
@@ -1,38 +0,0 @@
-
-
-
-This is how an ingest pipeline that uses a text embedding model is created:
-
-```bash
-curl -X PUT "${ES_URL}/_ingest/pipeline/my-text-embeddings-pipeline" \
--H "Authorization: ApiKey ${API_KEY}" \
--H "Content-Type: application/json" \
--d'
-{
- "description": "Text embedding pipeline",
- "processors": [
- {
- "inference": {
- "model_id": "sentence-transformers__msmarco-minilm-l-12-v3", [^1]
- "target_field": "my_embeddings",
- "field_map": { [^2]
- "my_text_field": "text_field"
- }
- }
- }
- ]
-}
-'
-```
-[^1]: The model ID of the text embedding model you want to use.
-[^2]: The `field_map` object maps the input document field name (which is
-`my_text_field` in this example) to the name of the field that the model expects
-(which is always `text_field`).
-
-To ingest data through the pipeline to generate text embeddings with your chosen
-model, refer to the
-[Add the text embedding model to an inference ingest pipeline](((ml-docs))/ml-nlp-text-emb-vector-search-example.html#ex-text-emb-ingest)
-section. The example shows how to create the pipeline with the inference
-processor and reindex your data through the pipeline. After you successfully
-ingested documents by using the pipeline, your index will contain the text
-embeddings generated by the model.
diff --git a/serverless/partials/generate-embeddings-elser.mdx b/serverless/partials/generate-embeddings-elser.mdx
deleted file mode 100644
index 74b558f2..00000000
--- a/serverless/partials/generate-embeddings-elser.mdx
+++ /dev/null
@@ -1,33 +0,0 @@
-
-
-
-This is how an ingest pipeline that uses the ELSER model is created:
-
-```bash
-curl -X PUT "${ES_URL}/_ingest/pipeline/my-text-embeddings-pipeline" \
--H "Authorization: ApiKey ${API_KEY}" \
--H "Content-Type: application/json" \
--d'
-{
- "description": "Text embedding pipeline",
- "processors": [
- {
- "inference": {
- "model_id": ".elser_model_2",
- "input_output": [
- {
- "input_field": "my_text_field",
- "output_field": "my_tokens"
- }
- ]
- }
- }
- ]
-}
-'
-```
-
-To ingest data through the pipeline to generate tokens with ELSER, refer to the
-Ingest the data through the ((infer)) ingest pipeline section of the tutorial. After you successfully
-ingested documents by using the pipeline, your index will contain the tokens
-generated by ELSER.
diff --git a/serverless/partials/generate-embeddings-widget.mdx b/serverless/partials/generate-embeddings-widget.mdx
deleted file mode 100644
index 2420e7c4..00000000
--- a/serverless/partials/generate-embeddings-widget.mdx
+++ /dev/null
@@ -1,12 +0,0 @@
-
-import Elser from './generate-embeddings-elser.mdx'
-import DenseVector from './generate-embeddings-dense-vector.mdx'
-
-
-
-
-
-
-
-
-
\ No newline at end of file
diff --git a/serverless/partials/hybrid-search-dense-vector.mdx b/serverless/partials/hybrid-search-dense-vector.mdx
deleted file mode 100644
index e261ebf2..00000000
--- a/serverless/partials/hybrid-search-dense-vector.mdx
+++ /dev/null
@@ -1,38 +0,0 @@
-
-
-
-Hybrid search between a semantic and lexical query can be achieved by providing:
-
-* a `query` clause for the full-text query;
-* a `knn` clause with the kNN search that queries the dense vector field;
-* and a `rank` clause with the `rrf` parameter to rank documents using
- reciprocal rank fusion.
-
-```bash
-curl -X GET "${ES_URL}/my-index/_search" \
--H "Authorization: ApiKey ${API_KEY}" \
--H "Content-Type: application/json" \
--d'
-{
- "query": {
- "match": {
- "my_text_field": "the query string"
- }
- },
- "knn": {
- "field": "text_embedding.predicted_value",
- "k": 10,
- "num_candidates": 100,
- "query_vector_builder": {
- "text_embedding": {
- "model_id": "sentence-transformers__msmarco-minilm-l-12-v3",
- "model_text": "the query string"
- }
- }
- },
- "rank": {
- "rrf": {}
- }
-}
-'
-```
diff --git a/serverless/partials/hybrid-search-elser.mdx b/serverless/partials/hybrid-search-elser.mdx
deleted file mode 100644
index ce795c92..00000000
--- a/serverless/partials/hybrid-search-elser.mdx
+++ /dev/null
@@ -1,43 +0,0 @@
-
-
-
-Hybrid search between a semantic and lexical query can be achieved by using retrievers in your search request.
-The following example uses retrievers to perform a match query and a sparse vector query, and rank them using RRF.
-
-```bash
-curl -X GET "${ES_URL}/my-index/_search" \
--H "Authorization: ApiKey ${API_KEY}" \
--H "Content-Type: application/json" \
--d'
-{
- "retriever": {
- "rrf": {
- "retrievers": [
- {
- "standard": {
- "query": {
- "match": {
- "my_text_field": "the query string"
- }
- }
- }
- },
- {
- "standard": {
- "query": {
- "sparse_vector": {
- "field": "my_tokens",
- "inference_id": "my-elser-endpoint",
- "query": "the query string"
- }
- }
- }
- }
- ],
- "window_size": 50,
- "rank_constant": 20
- }
- }
-}
-'
-```
diff --git a/serverless/partials/hybrid-search-widget.mdx b/serverless/partials/hybrid-search-widget.mdx
deleted file mode 100644
index 9fa8781e..00000000
--- a/serverless/partials/hybrid-search-widget.mdx
+++ /dev/null
@@ -1,12 +0,0 @@
-
-import Elser from './hybrid-search-elser.mdx'
-import DenseVector from './hybrid-search-dense-vector.mdx'
-
-
-
-
-
-
-
-
-
\ No newline at end of file
diff --git a/serverless/partials/minimum-vcus-detail.mdx b/serverless/partials/minimum-vcus-detail.mdx
deleted file mode 100644
index b6cdf3cc..00000000
--- a/serverless/partials/minimum-vcus-detail.mdx
+++ /dev/null
@@ -1,9 +0,0 @@
-
- When you create an Elasticsearch Serverless project, a minimum number of VCUs are always allocated to your project to maintain basic capabilities. These VCUs are used for the following purposes:
-
- - **Ingest**: Ensure constant availability for ingesting data into your project (4 VCUs).
- - **Search**: Maintain a data cache and support low latency searches (8 VCUs).
-
- These minimum VCUs are billed at the standard rate per VCU hour, incurring a minimum cost even when you're not actively using your project.
- Learn more about [minimum VCUs on Elasticsearch Serverless](https://www.elastic.co/pricing/serverless-search#what-are-the-minimum-compute-resource-vcus-on-elasticsearch-serverless).
-
\ No newline at end of file
diff --git a/serverless/partials/search-dense-vector.mdx b/serverless/partials/search-dense-vector.mdx
deleted file mode 100644
index 53a36609..00000000
--- a/serverless/partials/search-dense-vector.mdx
+++ /dev/null
@@ -1,30 +0,0 @@
-
-
-
-Text embeddings produced by dense vector models can be queried using a
-.
-In the `knn` clause, provide the name of the
-dense vector field, and a `query_vector_builder` clause with the model ID and
-the query text.
-
-```bash
-curl -X GET "${ES_URL}/my-index/_search" \
--H "Authorization: ApiKey ${API_KEY}" \
--H "Content-Type: application/json" \
--d'
-{
- "knn": {
- "field": "my_embeddings.predicted_value",
- "k": 10,
- "num_candidates": 100,
- "query_vector_builder": {
- "text_embedding": {
- "model_id": "sentence-transformers__msmarco-minilm-l-12-v3",
- "model_text": "the query string"
- }
- }
- }
-}
-'
-```
-{/* TEST[skip:TBD] */}
diff --git a/serverless/partials/search-elser.mdx b/serverless/partials/search-elser.mdx
deleted file mode 100644
index b7119013..00000000
--- a/serverless/partials/search-elser.mdx
+++ /dev/null
@@ -1,25 +0,0 @@
-
-
-
-ELSER text embeddings can be queried using a
-[sparse vector query](((ref))/query-dsl-sparse-vector-query.html). The sparse vector
-query enables you to query a sparse vector field, by providing an inference ID, and the query text:
-
-```bash
-curl -X GET "${ES_URL}/my-index/_search" \
--H "Authorization: ApiKey ${API_KEY}" \
--H "Content-Type: application/json" \
--d'
-{
- "query":{
- "sparse_vector":{
- "field": "my_tokens", [^1]
- "inference_id": "my-elser-endpoint",
- "query": "the query string"
- }
- }
- }
-}
-'
-```
-[^1]: The field of type `sparse_vector`.
diff --git a/serverless/partials/search-widget.mdx b/serverless/partials/search-widget.mdx
deleted file mode 100644
index d34259bf..00000000
--- a/serverless/partials/search-widget.mdx
+++ /dev/null
@@ -1,12 +0,0 @@
-
-import Elser from './search-elser.mdx'
-import DenseVector from './search-dense-vector.mdx'
-
-
-
-
-
-
-
-
-
\ No newline at end of file