diff --git a/.github/CODEOWNERS b/.github/CODEOWNERS
new file mode 100644
index 00000000..1b350484
--- /dev/null
+++ b/.github/CODEOWNERS
@@ -0,0 +1,2 @@
+* @elastic/docs
+/.github/workflows/ @elastic/docs-engineering
diff --git a/.github/workflows/docs-elastic-staging-publish.yml b/.github/workflows/docs-elastic-staging-publish.yml
new file mode 100644
index 00000000..6dfe8e71
--- /dev/null
+++ b/.github/workflows/docs-elastic-staging-publish.yml
@@ -0,0 +1,25 @@
+name: Staging Docs
+
+on:
+ pull_request_target:
+ paths:
+ - '**.mdx'
+ - '**.docnav.json'
+ - '**.docapi.json'
+ - '**.devdocs.json'
+ - '**.jpg'
+ - '**.jpeg'
+ - '**.png'
+ - '**.svg'
+ - '**.gif'
+ types: [opened, closed, synchronize]
+
+jobs:
+ publish:
+ name: Vercel Build Check
+ uses: elastic/workflows/.github/workflows/docs-elastic-co-publish.yml@main
+ secrets:
+ VERCEL_GITHUB_TOKEN: ${{ secrets.VERCEL_GITHUB_TOKEN }}
+ VERCEL_TOKEN: ${{ secrets.VERCEL_TOKEN }}
+ VERCEL_ORG_ID: ${{ secrets.VERCEL_ORG_ID }}
+ VERCEL_PROJECT_ID_DOCS_CO: ${{ secrets.VERCEL_PROJECT_ID_DOCS_CO }}
diff --git a/.gitignore b/.gitignore
new file mode 100644
index 00000000..f578ed08
--- /dev/null
+++ b/.gitignore
@@ -0,0 +1,8 @@
+# vscode stuff
+.vscode/
+
+# vs stuff
+.vs/
+
+# osx stuff
+.DS_Store
diff --git a/serverless/images/api-key-management.png b/serverless/images/api-key-management.png
new file mode 100644
index 00000000..0b8b1102
Binary files /dev/null and b/serverless/images/api-key-management.png differ
diff --git a/serverless/images/console-formatted-request.png b/serverless/images/console-formatted-request.png
new file mode 100644
index 00000000..c95b54dc
Binary files /dev/null and b/serverless/images/console-formatted-request.png differ
diff --git a/serverless/images/console-request-response.png b/serverless/images/console-request-response.png
new file mode 100644
index 00000000..c7602db5
Binary files /dev/null and b/serverless/images/console-request-response.png differ
diff --git a/serverless/images/console-settings.png b/serverless/images/console-settings.png
new file mode 100644
index 00000000..9b653169
Binary files /dev/null and b/serverless/images/console-settings.png differ
diff --git a/serverless/images/console-unformatted-request.png b/serverless/images/console-unformatted-request.png
new file mode 100644
index 00000000..a6fb9cd1
Binary files /dev/null and b/serverless/images/console-unformatted-request.png differ
diff --git a/serverless/images/console-variables.png b/serverless/images/console-variables.png
new file mode 100644
index 00000000..74074518
Binary files /dev/null and b/serverless/images/console-variables.png differ
diff --git a/serverless/images/create-maintenance-window-filter.png b/serverless/images/create-maintenance-window-filter.png
new file mode 100644
index 00000000..d524795c
Binary files /dev/null and b/serverless/images/create-maintenance-window-filter.png differ
diff --git a/serverless/images/create-maintenance-window.png b/serverless/images/create-maintenance-window.png
new file mode 100644
index 00000000..6938b0b9
Binary files /dev/null and b/serverless/images/create-maintenance-window.png differ
diff --git a/serverless/images/create-personal-api-key.png b/serverless/images/create-personal-api-key.png
new file mode 100644
index 00000000..1eba110e
Binary files /dev/null and b/serverless/images/create-personal-api-key.png differ
diff --git a/serverless/images/discover-create-data-view.png b/serverless/images/discover-create-data-view.png
new file mode 100644
index 00000000..b099995d
Binary files /dev/null and b/serverless/images/discover-create-data-view.png differ
diff --git a/serverless/images/discover-find-data-view.png b/serverless/images/discover-find-data-view.png
new file mode 100644
index 00000000..869fc9b9
Binary files /dev/null and b/serverless/images/discover-find-data-view.png differ
diff --git a/serverless/images/edit-search-power.png b/serverless/images/edit-search-power.png
new file mode 100644
index 00000000..5fd06b4b
Binary files /dev/null and b/serverless/images/edit-search-power.png differ
diff --git a/serverless/images/embed_dashboard_map.jpeg b/serverless/images/embed_dashboard_map.jpeg
new file mode 100644
index 00000000..7be233e7
Binary files /dev/null and b/serverless/images/embed_dashboard_map.jpeg differ
diff --git a/serverless/images/es-query-rule-action-summary.png b/serverless/images/es-query-rule-action-summary.png
new file mode 100644
index 00000000..1e098d77
Binary files /dev/null and b/serverless/images/es-query-rule-action-summary.png differ
diff --git a/serverless/images/es-query-rule-action-variables.png b/serverless/images/es-query-rule-action-variables.png
new file mode 100644
index 00000000..685f455b
Binary files /dev/null and b/serverless/images/es-query-rule-action-variables.png differ
diff --git a/serverless/images/es-query-rule-conditions.png b/serverless/images/es-query-rule-conditions.png
new file mode 100644
index 00000000..c9572afc
Binary files /dev/null and b/serverless/images/es-query-rule-conditions.png differ
diff --git a/serverless/images/es-query-rule-recovery-action.png b/serverless/images/es-query-rule-recovery-action.png
new file mode 100644
index 00000000..a7c1243c
Binary files /dev/null and b/serverless/images/es-query-rule-recovery-action.png differ
diff --git a/serverless/images/file-management.png b/serverless/images/file-management.png
new file mode 100644
index 00000000..522fa08f
Binary files /dev/null and b/serverless/images/file-management.png differ
diff --git a/serverless/images/grok-debugger-custom-pattern.png b/serverless/images/grok-debugger-custom-pattern.png
new file mode 100644
index 00000000..2a1660c8
Binary files /dev/null and b/serverless/images/grok-debugger-custom-pattern.png differ
diff --git a/serverless/images/grok-debugger-overview.png b/serverless/images/grok-debugger-overview.png
new file mode 100644
index 00000000..4692c7a8
Binary files /dev/null and b/serverless/images/grok-debugger-overview.png differ
diff --git a/serverless/images/index-management-data-stream-stats.png b/serverless/images/index-management-data-stream-stats.png
new file mode 100644
index 00000000..a474839f
Binary files /dev/null and b/serverless/images/index-management-data-stream-stats.png differ
diff --git a/serverless/images/index-management-index-templates.png b/serverless/images/index-management-index-templates.png
new file mode 100644
index 00000000..9188aa85
Binary files /dev/null and b/serverless/images/index-management-index-templates.png differ
diff --git a/serverless/images/index-management-indices.png b/serverless/images/index-management-indices.png
new file mode 100644
index 00000000..18698c85
Binary files /dev/null and b/serverless/images/index-management-indices.png differ
diff --git a/serverless/images/individual-role.png b/serverless/images/individual-role.png
new file mode 100644
index 00000000..810be3a3
Binary files /dev/null and b/serverless/images/individual-role.png differ
diff --git a/serverless/images/ingest-pipelines-management.png b/serverless/images/ingest-pipelines-management.png
new file mode 100644
index 00000000..735e8a75
Binary files /dev/null and b/serverless/images/ingest-pipelines-management.png differ
diff --git a/serverless/images/ingest-pipelines-test.png b/serverless/images/ingest-pipelines-test.png
new file mode 100644
index 00000000..65ee2815
Binary files /dev/null and b/serverless/images/ingest-pipelines-test.png differ
diff --git a/serverless/images/logstash-pipelines-management.png b/serverless/images/logstash-pipelines-management.png
new file mode 100644
index 00000000..27e79225
Binary files /dev/null and b/serverless/images/logstash-pipelines-management.png differ
diff --git a/serverless/images/management-data-stream.png b/serverless/images/management-data-stream.png
new file mode 100644
index 00000000..01534fde
Binary files /dev/null and b/serverless/images/management-data-stream.png differ
diff --git a/serverless/images/management-enrich-policies.png b/serverless/images/management-enrich-policies.png
new file mode 100644
index 00000000..d2c9b944
Binary files /dev/null and b/serverless/images/management-enrich-policies.png differ
diff --git a/serverless/images/ml-security-management.png b/serverless/images/ml-security-management.png
new file mode 100644
index 00000000..a7828b7f
Binary files /dev/null and b/serverless/images/ml-security-management.png differ
diff --git a/serverless/images/org-grant-access.png b/serverless/images/org-grant-access.png
new file mode 100644
index 00000000..8dc8db52
Binary files /dev/null and b/serverless/images/org-grant-access.png differ
diff --git a/serverless/images/org-invite-members.png b/serverless/images/org-invite-members.png
new file mode 100644
index 00000000..002cb7e0
Binary files /dev/null and b/serverless/images/org-invite-members.png differ
diff --git a/serverless/images/painless-lab.png b/serverless/images/painless-lab.png
new file mode 100644
index 00000000..65b4141e
Binary files /dev/null and b/serverless/images/painless-lab.png differ
diff --git a/serverless/images/profiler-filter.png b/serverless/images/profiler-filter.png
new file mode 100644
index 00000000..0bcfd7ca
Binary files /dev/null and b/serverless/images/profiler-filter.png differ
diff --git a/serverless/images/profiler-gs10.png b/serverless/images/profiler-gs10.png
new file mode 100644
index 00000000..19c3c1a5
Binary files /dev/null and b/serverless/images/profiler-gs10.png differ
diff --git a/serverless/images/profiler-gs8.png b/serverless/images/profiler-gs8.png
new file mode 100644
index 00000000..75b93d4d
Binary files /dev/null and b/serverless/images/profiler-gs8.png differ
diff --git a/serverless/images/profiler-json.png b/serverless/images/profiler-json.png
new file mode 100644
index 00000000..25d83e8e
Binary files /dev/null and b/serverless/images/profiler-json.png differ
diff --git a/serverless/images/profiler-overview.png b/serverless/images/profiler-overview.png
new file mode 100644
index 00000000..2669adc1
Binary files /dev/null and b/serverless/images/profiler-overview.png differ
diff --git a/serverless/images/reports-management.png b/serverless/images/reports-management.png
new file mode 100644
index 00000000..9249f137
Binary files /dev/null and b/serverless/images/reports-management.png differ
diff --git a/serverless/images/rule-concepts-summary.svg b/serverless/images/rule-concepts-summary.svg
new file mode 100644
index 00000000..d7fd2c58
--- /dev/null
+++ b/serverless/images/rule-concepts-summary.svg
@@ -0,0 +1,109 @@
+
diff --git a/serverless/images/sample_data_ecommerce_map.png b/serverless/images/sample_data_ecommerce_map.png
new file mode 100644
index 00000000..7fba3da6
Binary files /dev/null and b/serverless/images/sample_data_ecommerce_map.png differ
diff --git a/serverless/images/saved-object-management.png b/serverless/images/saved-object-management.png
new file mode 100644
index 00000000..fc61b928
Binary files /dev/null and b/serverless/images/saved-object-management.png differ
diff --git a/serverless/images/tag-assignment.png b/serverless/images/tag-assignment.png
new file mode 100644
index 00000000..92a78be5
Binary files /dev/null and b/serverless/images/tag-assignment.png differ
diff --git a/serverless/images/tag-management.png b/serverless/images/tag-management.png
new file mode 100644
index 00000000..34addfe4
Binary files /dev/null and b/serverless/images/tag-management.png differ
diff --git a/serverless/images/timeslider_map.gif b/serverless/images/timeslider_map.gif
new file mode 100644
index 00000000..463adf9a
Binary files /dev/null and b/serverless/images/timeslider_map.gif differ
diff --git a/serverless/images/transform-management.png b/serverless/images/transform-management.png
new file mode 100644
index 00000000..3b944ae5
Binary files /dev/null and b/serverless/images/transform-management.png differ
diff --git a/serverless/nav/serverless-devtools.docnav.json b/serverless/nav/serverless-devtools.docnav.json
new file mode 100644
index 00000000..ae0a741f
--- /dev/null
+++ b/serverless/nav/serverless-devtools.docnav.json
@@ -0,0 +1,29 @@
+{
+ "mission": "Dev tools",
+ "id": "serverless-Devtools",
+ "landingPageId": "serverlessDevtoolsDeveloperTools",
+ "icon": "logoElastic",
+ "description": "Description to be written",
+ "items": [
+ {
+ "pageId": "serverlessDevtoolsRunApiRequestsInTheConsole",
+ "classic-sources": ["enKibanaConsoleKibana"]
+ },
+ {
+ "pageId": "serverlessDevtoolsProfileQueriesAndAggregations",
+ "classic-sources": ["enKibanaXpackProfiler"]
+ },
+ {
+ "pageId": "serverlessDevtoolsDebugGrokExpressions",
+ "classic-sources": ["enKibanaXpackGrokdebugger"]
+ },
+ {
+ "pageId": "serverlessDevtoolsDebugPainlessScripts",
+ "classic-sources": ["enKibanaPainlesslab"]
+ },
+ {
+ "pageId": "serverlessDevtoolsTroubleshooting",
+ "classic-sources": ["enElasticsearchReferenceTroubleshootingSearches"]
+ }
+ ]
+ }
diff --git a/serverless/nav/serverless-general.docnav.json b/serverless/nav/serverless-general.docnav.json
new file mode 100644
index 00000000..75f5f747
--- /dev/null
+++ b/serverless/nav/serverless-general.docnav.json
@@ -0,0 +1,47 @@
+{
+ "mission": "Welcome to Elastic serverless",
+ "id": "serverless-general",
+ "landingPageId": "serverlessGeneralWelcomeToServerless",
+ "icon": "logoElastic",
+ "description": "Create and manage serverless projects on Elastic Cloud",
+ "items": [
+ {
+ "pageId": "whatIsServerlessElastic"
+ },
+ {
+ "pageId": "serverlessGeneralManageOrganization",
+ "items": [
+ {
+ "id": "serverlessGeneralManageAccessToOrganization"
+ },
+ {
+ "id": "serverlessGeneralAssignUserRoles"
+ },
+ {
+ "id": "serverlessGeneralJoinOrganizationFromExistingCloudAccount"
+ }
+ ]
+ },
+ {
+ "pageId": "serverlessGeneralManageProject"
+ },
+ {
+ "label": "Manage billing",
+ "pageId": "serverlessGeneralManageBilling",
+ "items": [
+ {
+ "id": "serverlessGeneralCheckSubscription"
+ },
+ {
+ "id": "serverlessGeneralMonitorUsage"
+ },
+ {
+ "id": "serverlessGeneralBillingHistory"
+ }
+ ]
+ },
+ {
+ "pageId": "serverlessGeneralUserProfile"
+ }
+ ]
+}
diff --git a/serverless/nav/serverless-project-settings.docnav.json b/serverless/nav/serverless-project-settings.docnav.json
new file mode 100644
index 00000000..7f08af1d
--- /dev/null
+++ b/serverless/nav/serverless-project-settings.docnav.json
@@ -0,0 +1,76 @@
+{
+ "mission": "Project and management settings",
+ "id": "serverless-project-settings",
+ "landingPageId": "serverlessProjectAndManagementSettings",
+ "icon": "logoElastic",
+ "description": "Description to be written",
+ "items": [
+ {
+ "pageId": "serverlessProjectSettings",
+ "classic-sources": ["enKibanaManagement"],
+ "label": "Management",
+ "items": [
+ {
+ "id": "serverlessApiKeys",
+ "classic-sources": ["enKibanaApiKeys"]
+ },
+ {
+ "id": "serverlessActionConnectors",
+ "classic-sources": ["enKibanaActionTypes"]
+ },
+ {
+ "id": "serverlessDataViews",
+ "classic-sources": ["enKibanaDataViews"]
+ },
+ {
+ "id": "serverlessFiles"
+ },
+ {
+ "id": "serverlessIndexManagement",
+ "classic-sources": ["enElasticsearchReferenceIndexMgmt"]
+ },
+ {
+ "id": "serverlessIngestPipelines"
+ },
+ {
+ "id": "serverlessLogstashPipelines"
+ },
+ {
+ "id": "serverlessMachineLearning"
+ },
+ {
+ "id": "serverlessMaintenanceWindows",
+ "classic-sources": ["enKibanaMaintenanceWindows"]
+ },
+ {
+ "id": "serverlessMaps"
+ },
+ {
+ "id": "serverlessReports"
+ },
+ {
+ "id": "serverlessRules",
+ "classic-sources": [ "enKibanaAlertingGettingStarted" ]
+ },
+ {
+ "id": "serverlessSavedObjects",
+ "classic-sources": ["enKibanaManagingSavedObjects"]
+ },
+ {
+ "id": "serverlessTags",
+ "classic-sources": ["enKibanaManagingTags"]
+ },
+ {
+ "id": "serverlessTransforms",
+ "classic-sources": ["enElasticsearchReferenceTransforms"]
+ }
+ ]
+ },
+ {
+ "pageId": "serverlessIntegrations"
+ },
+ {
+ "pageId": "serverlessFleetAndElasticAgent"
+ }
+ ]
+}
diff --git a/serverless/pages/action-connectors.mdx b/serverless/pages/action-connectors.mdx
new file mode 100644
index 00000000..0df4cdeb
--- /dev/null
+++ b/serverless/pages/action-connectors.mdx
@@ -0,0 +1,288 @@
+---
+id: serverlessActionConnectors
+slug: /serverless/action-connectors
+title: ((connectors-app))
+description: Configure connections to third party systems for use in cases and rules.
+tags: [ 'serverless' ]
+---
+
+
+This content applies to:
+
+The list of available connectors varies by project type.
+
+
+
+{/* Connectors provide a central place to store connection information for services and integrations with third party systems.
+Actions are instantiations of a connector that are linked to rules and run as background tasks on the ((kib)) server when rule conditions are met. */}
+{/* ((kib)) provides the following types of connectors for use with ((alert-features)) :
+
+- [D3 Security](((kibana-ref))/d3security-action-type.html)
+- [Email](((kibana-ref))/email-action-type.html)
+- [Generative AI](((kibana-ref))/gen-ai-action-type.html)
+- [IBM Resilient](((kibana-ref))/resilient-action-type.html)
+- [Index](((kibana-ref))/index-action-type.html)
+- [Jira](((kibana-ref))/jira-action-type.html)
+- [Microsoft Teams](((kibana-ref))/teams-action-type.html)
+- [Opsgenie](((kibana-ref))/opsgenie-action-type.html)
+- [PagerDuty](((kibana-ref))/pagerduty-action-type.html)
+- [ServerLog](((kibana-ref))/server-log-action-type.html)
+- [ServiceNow ITSM](((kibana-ref))/servicenow-action-type.html)
+- [ServiceNow SecOps](((kibana-ref))/servicenow-sir-action-type.html)
+- [ServiceNow ITOM](((kibana-ref))/servicenow-itom-action-type.html)
+- [Slack](((kibana-ref))/slack-action-type.html)
+- [Swimlane](((kibana-ref))/swimlane-action-type.html)
+- [Tines](((kibana-ref))/tines-action-type.html)
+- [Torq](((kibana-ref))/torq-action-type.html)
+- [Webhook](((kibana-ref))/webhook-action-type.html)
+- [Webhook - Case Management](((kibana-ref))/cases-webhook-action-type.html)
+- [xMatters](((kibana-ref))/xmatters-action-type.html) */}
+
+{/* [cols="2"] */}
+{/* | | |
+|---|---|
+| Email | Send email from your server. |
+| ((ibm-r)) | Create an incident in ((ibm-r)). |
+| Index | Index data into Elasticsearch. |
+| Jira | Create an incident in Jira. |
+| Microsoft Teams | Send a message to a Microsoft Teams channel. |
+| Opsgenie | Create or close an alert in Opsgenie. |
+| | Send an event in PagerDuty. |
+| ServerLog | Add a message to a Kibana log. |
+| ((sn-itsm)) | Create an incident in ((sn)). |
+| ((sn-sir)) | Create a security incident in ((sn)). |
+| ((sn-itom)) | Create an event in ((sn)). |
+| Slack | Send a message to a Slack channel or user. |
+| ((swimlane)) | Create an incident in ((swimlane)). |
+| Tines | Send events to a Tines Story. |
+| ((webhook)) | Send a request to a web service. |
+| ((webhook-cm)) | Send a request to a Case Management web service. |
+| xMatters | Send actionable alerts to on-call xMatters resources. |
+| Torq |
+| Generative AI |
+| D3 Security | */}
+
+{/*
+
+Some connector types are paid commercial features, while others are free.
+For a comparison of the Elastic subscription levels, go to
+[the subscription page](((subscriptions))).
+
+ */}
+
+{/*
+## Managing connectors
+
+Rules use connectors to route actions to different destinations like log files, ticketing systems, and messaging tools. While each ((kib)) app can offer their own types of rules, they typically share connectors. **((stack-manage-app)) → ((connectors-ui))** offers a central place to view and manage all the connectors in the current space.
+
+ */}
+{/* NOTE: This is an autogenerated screenshot. Do not edit it directly. */}
+{/*
+## Required permissions
+
+Access to connectors is granted based on your privileges to alerting-enabled
+features. For more information, go to Security.
+
+## Connector networking configuration
+
+Use the action configuration settings to customize connector networking configurations, such as proxies, certificates, or TLS settings. You can set configurations that apply to all your connectors or use `xpack.actions.customHostSettings` to set per-host configurations.
+
+## Connector list
+
+In **((stack-manage-app)) → ((connectors-ui))**, you can find a list of the connectors
+in the current space. You can use the search bar to find specific connectors by
+name and type. The **Type** dropdown also enables you to filter to a subset of
+connector types.
+
+ */}
+{/* NOTE: This is an autogenerated screenshot. Do not edit it directly. */}
+{/*
+You can delete individual connectors using the trash icon. Alternatively, select
+multiple connectors and delete them in bulk using the **Delete** button.
+
+ */}
+{/* NOTE: This is an autogenerated screenshot. Do not edit it directly. */}
+{/*
+
+
+You can delete a connector even if there are still actions referencing it.
+When this happens the action will fail to run and errors appear in the ((kib)) logs.
+
+
+
+## Creating a new connector
+
+New connectors can be created with the **Create connector** button, which guides
+you to select the type of connector and configure its properties.
+
+
+
+After you create a connector, it is available for use any time you set up an
+action in the current space.
+
+For out-of-the-box and standardized connectors, refer to
+preconfigured connectors.
+
+
+You can also manage connectors as resources with the [Elasticstack provider](https://registry.terraform.io/providers/elastic/elasticstack/latest) for Terraform.
+For more details, refer to the [elasticstack_kibana_action_connector](https://registry.terraform.io/providers/elastic/elasticstack/latest/docs/resources/kibana_action_connector) resource.
+
+
+## Importing and exporting connectors
+
+To import and export connectors, use the
+Saved Objects Management UI.
+
+
+
+If a connector is missing sensitive information after the import, a **Fix**
+button appears in **((connectors-ui))**.
+
+
+
+## Monitoring connectors
+
+The Task Manager health API helps you understand the performance of all tasks in your environment.
+However, if connectors fail to run, they will report as successful to Task Manager. The failure stats will not
+accurately depict the performance of connectors.
+
+For more information on connector successes and failures, refer to the Event log index.
+
+The include that was here is another page */}
diff --git a/serverless/pages/api-keys.mdx b/serverless/pages/api-keys.mdx
new file mode 100644
index 00000000..ae2a2de3
--- /dev/null
+++ b/serverless/pages/api-keys.mdx
@@ -0,0 +1,100 @@
+---
+id: serverlessApiKeys
+slug: /serverless/api-keys
+title: ((api-keys-app))
+description: API keys allow access to the ((stack)) on behalf of a user.
+tags: ["serverless", "Elasticsearch", "Observability", "Security"]
+---
+
+
+This content applies to:
+
+API keys are security mechanisms used to authenticate and authorize access to ((stack)) resources,
+and ensure that only authorized users or applications are able to interact with the ((stack)).
+
+For example, if you extract data from an ((es)) cluster on a daily basis, you might create an API key tied to your credentials, configure it with minimum access, and then put the API credentials into a cron job.
+Or, you might create API keys to automate ingestion of new data from remote sources, without a live user interaction.
+
+You can manage your keys in **((project-settings)) → ((manage-app)) → ((api-keys-app))**:
+
+
+{/* TBD: This image was refreshed but should be automated */}
+
+A _personal API key_ allows external services to access the ((stack)) on behalf of a user.
+{/* Cross-Cluster API key: allows remote clusters to connect to your local cluster. */}
+A _managed API key_ is created and managed by ((kib)) to correctly run background tasks.
+
+{/* TBD (accurate?) Secondary credentials have the same or lower access rights. */}
+
+{/* ## Security privileges
+
+You must have the `manage_security`, `manage_api_key`, or the `manage_own_api_key`
+cluster privileges to use API keys in Elastic. API keys can also be seen in a readonly view with access to the page and the `read_security` cluster privilege. To manage roles, open the main menu, then click
+**Stack Management → Roles**, or use the Role Management API. */}
+
+## Create an API key
+
+In **((api-keys-app))**, click **Create API key**:
+
+
+
+Once created, you can copy the encoded API key and use it to send requests to the ((es)) HTTP API. For example:
+
+```bash
+curl "${ES_URL}" \
+-H "Authorization: ApiKey ${API_KEY}"
+```
+
+
+ API keys are intended for programmatic access. Don't use API keys to
+ authenticate access using a web browser.
+
+
+### Restrict privileges
+
+When you create or update an API key, use **Restrict privileges** to limit the permissions. Define the permissions using a JSON `role_descriptors` object, where you specify one or more roles and the associated privileges.
+
+For example, the following `role_descriptors` object defines a `books-read-only` role that limits the API key to `read` privileges on the `books` index.
+
+```json
+{
+ "books-read-only": {
+ "cluster": [],
+ "indices": [
+ {
+ "names": ["books"],
+ "privileges": ["read"]
+ }
+ ],
+ "applications": [],
+ "run_as": [],
+ "metadata": {},
+ "transient_metadata": {
+ "enabled": true
+ }
+ }
+}
+```
+
+For the `role_descriptors` object schema, check out the [`/_security/api_key` endpoint](((ref))/security-api-create-api-key.html#security-api-create-api-key-request-body) docs. For supported privileges, check [Security privileges](((ref))/security-privileges.html#privileges-list-indices).
+
+## Update an API key
+
+In **((api-keys-app))**, click on the name of the key.
+You can update only **Restrict privileges** and **Include metadata**.
+
+{/* TBD: Refer to the update API key documentation to learn more about updating personal API keys. */}
+
+## View and delete API keys
+
+The **((api-keys-app))** app lists your API keys, including the name, date created, and status.
+When API keys expire, the status changes from `Active` to `Expired`.
+
+{/*
+TBD: RBAC requirements for serverless?
+If you have `manage_security` or `manage_api_key` permissions,
+you can view the API keys of all users, and see which API key was
+created by which user in which realm.
+If you have only the `manage_own_api_key` permission, you see only a list of your own keys. */}
+
+You can delete API keys individually or in bulk.
diff --git a/serverless/pages/data-views.mdx b/serverless/pages/data-views.mdx
new file mode 100644
index 00000000..a172063d
--- /dev/null
+++ b/serverless/pages/data-views.mdx
@@ -0,0 +1,165 @@
+---
+id: serverlessDataViews
+slug: /serverless/data-views
+title: ((data-views-app))
+description: Elastic requires a ((data-source)) to access the ((es)) data that you want to explore.
+tags: [ 'serverless', 'Elasticsearch', 'Observability', 'Security' ]
+---
+
+
+This content applies to:
+
+A ((data-source)) can point to one or more indices, [data streams](((ref))/data-streams.html), or [index aliases](((ref))/alias.html).
+For example, a ((data-source)) can point to your log data from yesterday or all indices that contain your data.
+
+{/*
+
+## Required permissions
+
+* Access to **Data Views** requires the ((kib)) privilege
+ `Data View Management`.
+
+* To create a ((data-source)), you must have the ((es)) privilege
+ `view_index_metadata`.
+
+* If a read-only indicator appears, you have insufficient privileges
+ to create or save ((data-sources)). In addition, the buttons to create ((data-sources)) or
+ save existing ((data-sources)) are not visible. For more information,
+ refer to Granting access to ((kib)).
+*/}
+
+## Create a data view
+
+After you've loaded your data, follow these steps to create a ((data-source)):
+
+{/* */}
+
+ 1. Open {/***Lens** or*/}**Discover** then open the data view menu.
+
+ Alternatively, go to **((project-settings)) → ((manage-app)) → ((data-views-app))**.
+
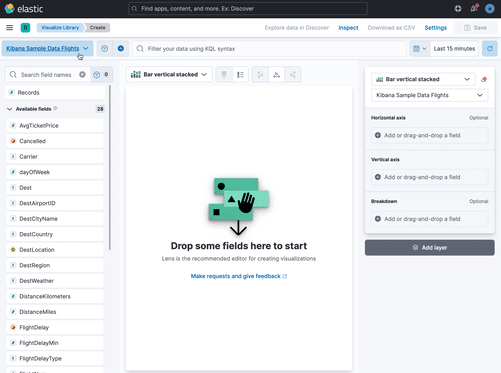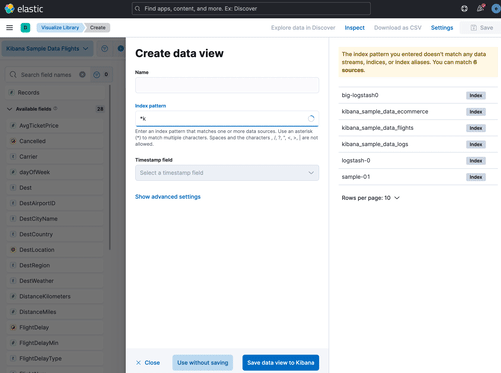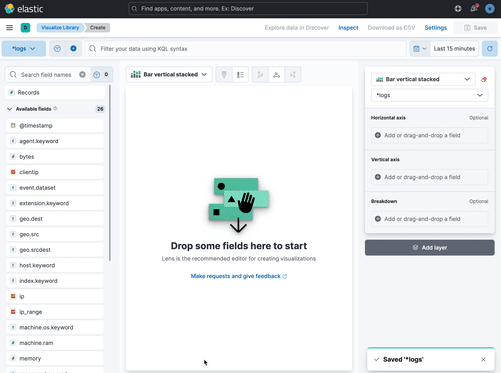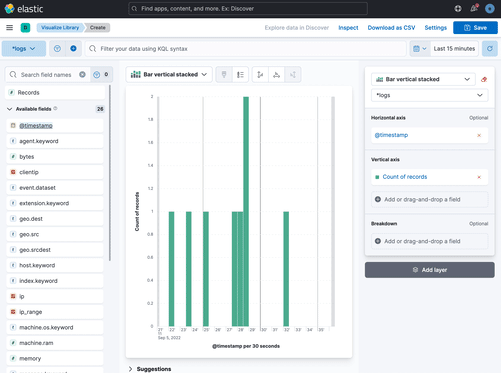
+1. Click **Create a ((data-source))**.
+
+1. Give your ((data-source)) a name.
+
+1. Start typing in the **Index pattern** field, and Elastic looks for the names of
+ indices, data streams, and aliases that match your input. You can
+ view all available sources or only the sources that the data view targets.
+ 
+
+ * To match multiple sources, use a wildcard (*). `filebeat-*` matches
+ `filebeat-apache-a`, `filebeat-apache-b`, and so on.
+
+ * To match multiple single sources, enter their names,
+ separated by a comma. Do not include a space after the comma.
+ `filebeat-a,filebeat-b` matches two indices.
+
+ * To exclude a source, use a minus sign (-), for example, `-test3`.
+
+1. Open the **Timestamp field** dropdown,
+ and then select the default field for filtering your data by time.
+
+ * If you don't set a default time field, you can't use
+ global time filters on your dashboards. This is useful if
+ you have multiple time fields and want to create dashboards that combine visualizations
+ based on different timestamps.
+
+ * If your index doesn't have time-based data, choose **I don't want to use the time filter**.
+
+1. Click **Show advanced settings** to:
+ * Display hidden and system indices.
+ * Specify your own ((data-source)) name. For example, enter your ((es)) index alias name.
+
+1. Click **Save ((data-source)) to Elastic**.
+
+You can manage your data views in **((project-settings)) → ((manage-app)) → ((data-views-app))**.
+
+### Create a temporary ((data-source))
+
+Want to explore your data or create a visualization without saving it as a data view?
+Select **Use without saving** in the **Create ((data-source))** form in **Discover**.
+With a temporary ((data-source)), you can add fields and create an ((es)) query alert, just like you would a regular ((data-source)).
+Your work won't be visible to others in your space.
+
+A temporary ((data-source)) remains in your space until you change apps, or until you save it.
+
+{/*  */}
+
+
+
+{/*
+
+### Use ((data-sources)) with rolled up data
+
+A ((data-source)) can match one rollup index. For a combination rollup
+((data-source)) with both raw and rolled up data, use the standard notation:
+
+```ts
+rollup_logstash,kibana_sample_data_logs
+```
+For an example, refer to Create and visualize rolled up data. */}
+
+{/*
+
+### Use ((data-sources)) with ((ccs))
+
+If your ((es)) clusters are configured for [((ccs))](((ref))/modules-cross-cluster-search.html),
+you can create a ((data-source)) to search across the clusters of your choosing.
+Specify data streams, indices, and aliases in a remote cluster using the
+following syntax:
+
+```ts
+:
+```
+
+To query ((ls)) indices across two ((es)) clusters
+that you set up for ((ccs)), named `cluster_one` and `cluster_two`:
+
+```ts
+ cluster_one:logstash-*,cluster_two:logstash-*
+```
+
+Use wildcards in your cluster names
+to match any number of clusters. To search ((ls)) indices across
+clusters named `cluster_foo`, `cluster_bar`, and so on:
+
+```ts
+cluster_*:logstash-*
+```
+
+To query across all ((es)) clusters that have been configured for ((ccs)),
+use a standalone wildcard for your cluster name:
+
+```ts
+*:logstash-*
+```
+
+To match indices starting with `logstash-`, but exclude those starting with `logstash-old`, from
+all clusters having a name starting with `cluster_`:
+
+```ts
+`cluster_*:logstash-*,cluster_*:-logstash-old*`
+```
+
+To exclude a cluster having a name starting with `cluster_`:
+
+```ts
+`cluster_*:logstash-*,cluster_one:-*`
+```
+
+Once you configure a ((data-source)) to use the ((ccs)) syntax, all searches and
+aggregations using that ((data-source)) in Elastic take advantage of ((ccs)). */}
+
+## Delete a ((data-source))
+
+When you delete a ((data-source)), you cannot recover the associated field formatters, runtime fields, source filters,
+and field popularity data.
+Deleting a ((data-source)) does not remove any indices or data documents from ((es)).
+
+
+
+1. Go to **((project-settings)) → ((manage-app)) → ((data-views-app))**.
+
+1. Find the ((data-source)) that you want to delete, and then
+ click in the **Actions** column.
+
diff --git a/serverless/pages/debug-grok-expressions.mdx b/serverless/pages/debug-grok-expressions.mdx
new file mode 100644
index 00000000..325dc8c1
--- /dev/null
+++ b/serverless/pages/debug-grok-expressions.mdx
@@ -0,0 +1,114 @@
+---
+id: serverlessDevtoolsDebugGrokExpressions
+slug: /serverless/devtools/debug-grok-expressions
+title: Grok Debugger
+description: Build and debug grok patterns before you use them in your data processing pipelines.
+tags: [ 'serverless', 'dev tools', 'how-to' ]
+---
+
+
+This content applies to:
+
+
+
+You can build and debug grok patterns in the **Grok Debugger** before you use them in your data processing pipelines.
+Grok is a pattern-matching syntax that you can use to parse and structure arbitrary text.
+Grok is good for parsing syslog, apache, and other webserver logs, mysql logs, and in general,
+any log format written for human consumption.
+
+Grok patterns are supported in ((es)) [runtime fields](((ref))/runtime.html),
+the ((es)) [grok ingest processor](((ref))/grok-processor.html),
+and the ((ls)) [grok filter](((logstash-ref))/plugins-filters-grok.html).
+For syntax, see [Grokking grok](((ref))/grok.html).
+
+Elastic ships with more than 120 reusable grok patterns.
+For a complete list of patterns, see
+[((es))
+grok patterns](https://github.com/elastic/elasticsearch/tree/master/libs/grok/src/main/resources/patterns)
+and [((ls))
+grok patterns](https://github.com/logstash-plugins/logstash-patterns-core/tree/master/patterns).
+
+{/* TODO: Figure out where to link to for grok patterns. Looks like the dir structure has changed. */}
+
+Because ((es)) and ((ls)) share the same grok implementation and pattern libraries,
+any grok pattern that you create in the **Grok Debugger** will work in both ((es)) and ((ls)).
+
+
+
+## Get started
+
+This example walks you through using the **Grok Debugger**.
+
+
+The **Admin** role is required to use the Grok Debugger.
+For more information, refer to
+
+
+1. From the main menu, click **Developer Tools**, then click **Grok Debugger**.
+1. In **Sample Data**, enter a message that is representative of the data you want to parse.
+For example:
+
+ ```ruby
+ 55.3.244.1 GET /index.html 15824 0.043
+ ```
+
+1. In **Grok Pattern**, enter the grok pattern that you want to apply to the data.
+
+ To parse the log line in this example, use:
+
+ ```ruby
+ %{IP:client} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration}
+ ```
+
+1. Click **Simulate**.
+
+ You'll see the simulated event that results from applying the grok
+ pattern.
+
+ 
+
+
+
+## Test custom patterns
+
+
+If the default grok pattern dictionary doesn't contain the patterns you need,
+you can define, test, and debug custom patterns using the **Grok Debugger**.
+
+Custom patterns that you enter in the **Grok Debugger** are not saved. Custom patterns
+are only available for the current debugging session and have no side effects.
+
+Follow this example to define a custom pattern.
+
+1. In **Sample Data**, enter the following sample message:
+
+ ```ruby
+ Jan 1 06:25:43 mailserver14 postfix/cleanup[21403]: BEF25A72965: message-id=<20130101142543.5828399CCAF@mailserver14.example.com>
+ ```
+
+1. Enter this grok pattern:
+
+ ```ruby
+ %{SYSLOGBASE} %{POSTFIX_QUEUEID:queue_id}: %{MSG:syslog_message}
+ ```
+
+ Notice that the grok pattern references custom patterns called `POSTFIX_QUEUEID` and `MSG`.
+
+1. Expand **Custom Patterns** and enter pattern definitions for the custom patterns that you want to use in the grok expression.
+You must specify each pattern definition on its own line.
+
+ For this example, you must specify pattern definitions
+ for `POSTFIX_QUEUEID` and `MSG`:
+
+ ```ruby
+ POSTFIX_QUEUEID [0-9A-F]{10,11}
+ MSG message-id=<%{GREEDYDATA}>
+ ```
+
+1. Click **Simulate**.
+
+ You'll see the simulated output event that results from applying the grok pattern that contains the custom pattern:
+
+ 
+
+ If an error occurs, you can continue iterating over the custom pattern until the output matches your expected event.
diff --git a/serverless/pages/debug-painless-scripts.mdx b/serverless/pages/debug-painless-scripts.mdx
new file mode 100644
index 00000000..0ad964e1
--- /dev/null
+++ b/serverless/pages/debug-painless-scripts.mdx
@@ -0,0 +1,21 @@
+---
+id: serverlessDevtoolsDebugPainlessScripts
+slug: /serverless/devtools/debug-painless-scripts
+title: Painless Lab
+description: Use our interactive code editor to test and debug Painless scripts in real-time.
+tags: [ 'serverless', 'dev tools', 'how-to' ]
+---
+
+
+This content applies to:
+
+
+
+
+
+The **Painless Lab** is an interactive code editor that lets you test and debug [Painless scripts](((ref))/modules-scripting-painless.html) in real-time.
+You can use Painless to safely write inline and stored scripts anywhere scripts are supported.
+
+To get started, open the main menu, click **Developer Tools**, and then click **Painless Lab**.
+
+
diff --git a/serverless/pages/developer-tools-troubleshooting.mdx b/serverless/pages/developer-tools-troubleshooting.mdx
new file mode 100644
index 00000000..73d133cd
--- /dev/null
+++ b/serverless/pages/developer-tools-troubleshooting.mdx
@@ -0,0 +1,270 @@
+---
+id: serverlessDevtoolsTroubleshooting
+slug: /serverless/devtools/dev-tools-troubleshooting
+title: Troubleshooting
+description: Troubleshoot searches.
+tags: [ 'serverless', 'troubleshooting' ]
+---
+
+
+When you query your data, Elasticsearch may return an error, no search results,
+or results in an unexpected order. This guide describes how to troubleshoot
+searches.
+
+## Ensure the data stream, index, or alias exists
+
+Elasticsearch returns an `index_not_found_exception` when the data stream, index
+or alias you try to query does not exist. This can happen when you misspell the
+name or when the data has been indexed to a different data stream or index.
+
+Use the [**Exists API**](/api-reference/search/indices-exists) to check whether
+a data stream, index, or alias exists:
+
+```js
+HEAD my-data-stream
+```
+
+Use the [**Data stream stats API**](/api-reference/search/indices-data-streams-stats)
+to list all data streams:
+
+```js
+GET /_data_stream/_stats
+```
+
+Use the [**Get index API**](/api-reference/search/indices-get)
+to list all indices and their aliases:
+
+```js
+GET /_all?filter_path=*.aliases
+```
+
+Instead of an error, it is possible to retrieve partial search results if some
+of the indices you're querying are unavailable.
+Set `ignore_unavailable` to `true`:
+
+```js
+GET /my-alias/_search?ignore_unavailable=true
+```
+
+## Ensure the data stream or index contains data
+
+When a search request returns no hits, the data stream or index may contain no
+data.
+This can happen when there is a data ingestion issue.
+For example, the data may have been indexed to a data stream or index with
+another name.
+
+Use the [**Count API**](/api-reference/search/count-3)
+to retrieve the number of documents in a data
+stream or index.
+Check that `count` in the response is not 0.
+
+
+```js
+GET /my-index-000001/_count
+```
+
+
+
+If you aren't getting search results in the UI, check that you have selected the
+correct data view and a valid time range. Also, ensure the data view has been
+configured with the correct time field.
+
+
+## Check that the field exists and its capabilities
+
+Querying a field that does not exist will not return any results.
+Use the [**Field capabilities API**](/api-reference/search/field-caps)
+to check whether a field exists:
+
+```js
+GET /my-index-000001/_field_caps?fields=my-field
+```
+
+If the field does not exist, check the data ingestion process.
+The field may have a different name.
+
+If the field exists, the request will return the field's type and whether it is
+searchable and aggregatable.
+
+```console-response
+{
+ "indices": [
+ "my-index-000001"
+ ],
+ "fields": {
+ "my-field": {
+ "keyword": {
+ "type": "keyword", [^1]
+ "metadata_field": false,
+ "searchable": true, [^2]
+ "aggregatable": true [^3]
+ }
+ }
+ }
+}
+```
+[^1]: The field is of type `keyword` in this index.
+[^2]: The field is searchable in this index.
+[^3]: The field is aggregatable in this index.
+
+## Check the field's mappings
+
+A field's capabilities are determined by its [mapping](((ref))/mapping.html).
+To retrieve the mapping, use the [**Get mapping API**](/api-reference/search/indices-get-mapping-1):
+
+```js
+GET /my-index-000001/_mappings
+```
+
+If you query a `text` field, pay attention to the analyzer that may have been
+configured.
+You can use the [**Analyze API**](/api-reference/search/indices-analyze)
+to check how a field's analyzer processes values and query terms:
+
+```js
+GET /my-index-000001/_analyze
+{
+ "field": "my-field",
+ "text": "this is a test"
+}
+```
+
+To change the mapping of an existing field use the [**Update mapping API**](/api-reference/search/indices-put-mapping).
+
+## Check the field's values
+
+Use the `exists` query to check whether there are
+documents that return a value for a field.
+Check that `count` in the response is
+not 0.
+
+```js
+GET /my-index-000001/_count
+{
+ "query": {
+ "exists": {
+ "field": "my-field"
+ }
+ }
+}
+```
+
+If the field is aggregatable, you can use
+to check the field's values. For `keyword` fields, you can use a `terms`
+aggregation to retrieve the field's most common values:
+
+```js
+GET /my-index-000001/_search?filter_path=aggregations
+{
+ "size": 0,
+ "aggs": {
+ "top_values": {
+ "terms": {
+ "field": "my-field",
+ "size": 10
+ }
+ }
+ }
+}
+```
+
+For numeric fields, you can use [stats aggregation](((ref))/search-aggregations-metrics-stats-aggregation.html) {/* stats aggregation */} to get an idea of the field's value distribution:
+
+```js
+GET /my-index-000001/_search?filter_path=aggregations
+{
+ "aggs": {
+ "my-num-field-stats": {
+ "stats": {
+ "field": "my-num-field"
+ }
+ }
+ }
+}
+```
+
+If the field does not return any values, check the data ingestion process.
+The field may have a different name.
+
+## Check the latest value
+
+For time-series data, confirm there is non-filtered data within the attempted
+time range.
+For example, if you are trying to query the latest data for the
+`@timestamp` field, run the following to see if the max `@timestamp` falls
+within the attempted range:
+
+```js
+GET /my-index-000001/_search?sort=@timestamp:desc&size=1
+```
+
+## Validate, explain, and profile queries
+
+When a query returns unexpected results, Elasticsearch offers several tools to
+investigate why.
+
+The [**Validate API**](/api-reference/search/indices-validate-query-2)
+enables you to validate a query.
+Use the `rewrite` parameter to return the Lucene query an Elasticsearch query is
+rewritten into:
+
+```js
+GET /my-index-000001/_validate/query?rewrite=true
+{
+ "query": {
+ "match": {
+ "user.id": {
+ "query": "kimchy",
+ "fuzziness": "auto"
+ }
+ }
+ }
+}
+```
+
+Use the [**Explain API**](((ref))/search-explain.html) to find out why a
+specific document matches or doesn’t match a query:
+
+```js
+GET /my-index-000001/_explain/0
+{
+ "query" : {
+ "match" : { "message" : "elasticsearch" }
+ }
+}
+```
+
+The [**Profile API**](((ref))/search-profile.html)
+provides detailed timing information about a search request.
+For a visual representation of the results, use the
+.
+
+
+To troubleshoot queries, select **Inspect** in the toolbar.
+Next, select **Request**.
+You can now copy the query sent to ((es)) for further analysis in Console.
+
+
+## Check index settings
+
+Index settings {/* Index settings */}
+can influence search results.
+For example, the `index.query.default_field` setting, which determines the field
+that is queried when a query specifies no explicit field.
+Use the [**Get index settings API**](/api-reference/search/indices-get-settings-1)
+to retrieve the settings for an index:
+
+```bash
+GET /my-index-000001/_settings
+```
+
+You can update dynamic index settings with the
+[**Update index settings API**](/api-reference/search/indices-put-settings-1).
+Changing dynamic index settings for a data stream
+{/* Changing dynamic index settings for a data stream */} requires changing the index template used by the data stream.
+
+For static settings, you need to create a new index with the correct settings.
+Next, you can reindex the data into that index.
+{/*For data streams, refer to Change a static index setting
+for a data stream */}
diff --git a/serverless/pages/developer-tools.mdx b/serverless/pages/developer-tools.mdx
new file mode 100644
index 00000000..3318a4d7
--- /dev/null
+++ b/serverless/pages/developer-tools.mdx
@@ -0,0 +1,61 @@
+---
+id: serverlessDevtoolsDeveloperTools
+slug: /serverless/devtools/developer-tools
+title: Developer tools
+description: Use our developer tools to interact with your data.
+tags: [ 'serverless', 'dev tools', 'overview' ]
+---
+
+
+
+
+
+
+ Console
+ Interact with Elastic REST APIs.
+
+
+
+
+
+
+
+ ((searchprofiler))
+ Inspect and analyze your search queries.
+
+
+
+
+
+
+
+ Grok Debugger
+ Build and debug grok patterns before you use them in your data processing pipelines.
+
+
+
+
+
+
+
+ Painless Lab
+ Use an interactive code editor to test and debug Painless scripts in real time.
+
+
+
+
+
+
\ No newline at end of file
diff --git a/serverless/pages/files.mdx b/serverless/pages/files.mdx
new file mode 100644
index 00000000..e46658bf
--- /dev/null
+++ b/serverless/pages/files.mdx
@@ -0,0 +1,16 @@
+---
+id: serverlessFiles
+slug: /serverless/files
+title: ((files-app))
+description: Manage files that are stored in Elastic.
+tags: ["serverless", "Elasticsearch", "Observability", "Security"]
+---
+
+
+This content applies to:
+
+Several ((serverless-full)) features let you upload files. For example, you can add files to or upload a logo to an **Image** panel in a .
+
+You can access these uploaded files in **((project-settings)) → ((manage-app)) → ((files-app))**.
+
+
diff --git a/serverless/pages/fleet-and-elastic-agent.mdx b/serverless/pages/fleet-and-elastic-agent.mdx
new file mode 100644
index 00000000..75279170
--- /dev/null
+++ b/serverless/pages/fleet-and-elastic-agent.mdx
@@ -0,0 +1,20 @@
+---
+id: serverlessFleetAndElasticAgent
+slug: /serverless/fleet-and-elastic-agent
+title: Fleet and Elastic Agent
+description: Centrally manage your Elastic Agents in Fleet
+tags: [ 'serverless', 'ingest', 'fleet', 'elastic agent' ]
+---
+
+
+This content applies to:
+
+((agent)) is a single, unified way to add monitoring for logs, metrics, and other types of data to a host.
+It can also protect hosts from security threats, query data from operating systems, forward data from remote services or hardware, and more.
+A single agent makes it easier and faster to deploy monitoring across your infrastructure.
+Each agent has a single policy you can update to add integrations for new data sources, security protections, and more.
+
+((fleet)) provides a web-based UI to centrally manage your ((agents)) and their policies.
+
+To learn more, refer to the [Fleet and Elastic Agent documentation](((fleet-guide))).
+
diff --git a/serverless/pages/index-management.mdx b/serverless/pages/index-management.mdx
new file mode 100644
index 00000000..cdf79029
--- /dev/null
+++ b/serverless/pages/index-management.mdx
@@ -0,0 +1,256 @@
+---
+id: serverlessIndexManagement
+slug: /serverless/index-management
+title: ((index-manage-app))
+description: Perform CRUD operations on indices and data streams. View index settings, mappings, and statistics.
+tags: [ 'serverless', 'Elasticsearch', 'Observability', 'Security' ]
+---
+
+
+This content applies to:
+
+Elastic's index management features are an easy, convenient way to manage your cluster's indices, data streams, index templates, and enrich policies.
+Practicing good index management ensures your data is stored correctly and in the most cost-effective way possible.
+{/* data streams , and index
+templates. */}
+
+{/*
+## What you'll learn
+
+You'll learn how to:
+
+* View and edit index settings.
+* View mappings and statistics for an index.
+* Perform index-level operations, such as refreshes.
+* View and manage data streams.
+* Create index templates to automatically configure new data streams and indices.
+
+TBD: Are these RBAC requirements valid for serverless?
+
+## Required permissions
+
+If you use ((es)) ((security-features)), the following security privileges are required:
+
+* The `monitor` cluster privilege to access Elastic's **((index-manage-app))** features.
+* The `view_index_metadata` and `manage` index privileges to view a data stream
+ or index's data.
+
+* The `manage_index_templates` cluster privilege to manage index templates.
+
+To add these privileges, go to **Stack Management → Security → Roles**.
+
+*/}
+
+## Manage indices
+
+Go to **((project-settings)) → ((manage-app)) → ((index-manage-app))**:
+
+
+{/* TO-DO: This screenshot needs to be refreshed since it doesn't show all of the pertinent tabs */}
+
+The **((index-manage-app))** page contains an overview of your indices.
+{/*
+TBD: Do these badges exist in serverless?
+Badges indicate if an index is a follower index, a
+rollup index, or frozen. Clicking a badge narrows the list to only indices of that type. */}
+* To show details or perform operations, such as delete, click the index name. To perform operations
+on multiple indices, select their checkboxes and then open the **Manage** menu.
+
+* To filter the list of indices, use the search bar.
+
+* To drill down into the index mappings, settings, and statistics, click an index name. From this view, you can navigate to **Discover** to further explore the documents in the index.
+{/* settings, mapping */}
+
+{/*  */}
+{/* TO-DO: This screenshot needs to be refreshed since it doesn't show the appropriate context */}
+
+## Manage data streams
+
+Investigate your data streams and address lifecycle management needs in the **Data Streams** view.
+
+The value in the **Indices** column indicates the number of backing indices. Click this number to drill down into details.
+
+A value in the data retention column indicates that the data stream is managed by a data stream lifecycle policy.
+
+This value is the time period for which your data is guaranteed to be stored. Data older than this period can be deleted by
+((es)) at a later time.
+
+
+
+To view information about the stream's backing indices, click the number in the **Indices** column.
+
+* To view more information about a data stream, such as its generation or its
+current index lifecycle policy, click the stream's name. From this view, you can navigate to **Discover** to
+further explore data within the data stream.
+
+* To edit the data retention value, open the **Manage** menu, and then click **Edit data retention**.
+This action is only available if your data stream is not managed by an ILM policy.
+
+{/*
+TO-DO: This screenshot is not accurate since it contains several toggles that don't exist in serverless.
+
+*/}
+
+## Manage index templates
+
+Create, edit, clone, and delete your index templates in the **Index Templates** view. Changes made to an index template do not affect existing indices.
+
+
+{/* TO-DO: This screenshot is missing some tabs that exist in serverless */}
+
+If you don't have any templates, you can create one using the **Create template** wizard.
+
+{/*
+TO-DO: This walkthrough needs to be tested and updated for serverless.
+### Try it: Create an index template
+
+In this tutorial, you'll create an index template and use it to configure two
+new indices.
+
+**Step 1. Add a name and index pattern**
+
+1. In the **Index Templates** view, open the **Create template** wizard.
+
+ 
+
+1. In the **Name** field, enter `my-index-template`.
+
+1. Set **Index pattern** to `my-index-*` so the template matches any index
+ with that index pattern.
+
+1. Leave **Data Stream**, **Priority**, **Version**, and **_meta field** blank or as-is.
+
+**Step 2. Add settings, mappings, and aliases**
+
+1. Add component templates to your index template.
+
+ Component templates are pre-configured sets of mappings, index settings, and
+ aliases you can reuse across multiple index templates. Badges indicate
+ whether a component template contains mappings (*M*), index settings (*S*),
+ aliases (*A*), or a combination of the three.
+
+ Component templates are optional. For this tutorial, do not add any component
+ templates.
+
+ 
+
+1. Define index settings. These are optional. For this tutorial, leave this
+ section blank.
+
+1. Define a mapping that contains an object field named `geo` with a
+ child `geo_point` field named `coordinates`:
+
+ 
+
+ Alternatively, you can click the **Load JSON** link and define the mapping as JSON:
+
+ ```js
+ {
+ "properties": {
+ "geo": {
+ "properties": {
+ "coordinates": {
+ "type": "geo_point"
+ }
+ }
+ }
+ }
+
+ ```
+ \\ NOTCONSOLE
+
+ You can create additional mapping configurations in the **Dynamic templates** and
+ **Advanced options** tabs. For this tutorial, do not create any additional
+ mappings.
+
+1. Define an alias named `my-index`:
+
+ ```js
+ {
+ "my-index": {}
+ }
+ ```
+ \\ NOTCONSOLE
+
+1. On the review page, check the summary. If everything looks right, click
+ **Create template**.
+
+**Step 3. Create new indices**
+
+You’re now ready to create new indices using your index template.
+
+1. Index the following documents to create two indices:
+ `my-index-000001` and `my-index-000002`.
+
+ ```console
+ POST /my-index-000001/_doc
+ {
+ "@timestamp": "2019-05-18T15:57:27.541Z",
+ "ip": "225.44.217.191",
+ "extension": "jpg",
+ "response": "200",
+ "geo": {
+ "coordinates": {
+ "lat": 38.53146222,
+ "lon": -121.7864906
+ }
+ },
+ "url": "https://media-for-the-masses.theacademyofperformingartsandscience.org/uploads/charles-fullerton.jpg"
+ }
+
+ POST /my-index-000002/_doc
+ {
+ "@timestamp": "2019-05-20T03:44:20.844Z",
+ "ip": "198.247.165.49",
+ "extension": "php",
+ "response": "200",
+ "geo": {
+ "coordinates": {
+ "lat": 37.13189556,
+ "lon": -76.4929875
+ }
+ },
+ "memory": 241720,
+ "url": "https://theacademyofperformingartsandscience.org/people/type:astronauts/name:laurel-b-clark/profile"
+ }
+ ```
+
+1. Use the get index API to view the configurations for the
+ new indices. The indices were configured using the index template you created
+ earlier.
+
+ ```console
+ GET /my-index-000001,my-index-000002
+ ```
+ \\ TEST[continued]
+ */}
+
+
+{/*
+TO-DO:This page is missing information about the "Component templates" tab.
+*/}
+
+## Manage enrich policies
+
+Use the **Enrich Policies** view to add data from your existing indices to incoming documents during ingest.
+An [enrich policy](((ref))/ingest-enriching-data.html) contains:
+
+* The policy type that determines how the policy matches the enrich data to incoming documents
+* The source indices that store enrich data as documents
+* The fields from the source indices used to match incoming documents
+* The enrich fields containing enrich data from the source indices that you want to add to incoming documents
+* An optional query.
+
+
+
+When creating an enrich policy, the UI walks you through the configuration setup and selecting the fields.
+Before you can use the policy with an enrich processor, you must execute the policy.
+
+When executed, an enrich policy uses enrich data from the policy's source indices
+to create a streamlined system index called the enrich index. The policy uses this index to match and enrich incoming documents.
+
+Check out these examples:
+
+* [Example: Enrich your data based on geolocation](((ref))/geo-match-enrich-policy-type.html)
+* [Example: Enrich your data based on exact values](((ref))/match-enrich-policy-type.html)
+* [Example: Enrich your data by matching a value to a range](((ref))/range-enrich-policy-type.html)
diff --git a/serverless/pages/ingest-pipelines.mdx b/serverless/pages/ingest-pipelines.mdx
new file mode 100644
index 00000000..2459907c
--- /dev/null
+++ b/serverless/pages/ingest-pipelines.mdx
@@ -0,0 +1,51 @@
+---
+id: serverlessIngestPipelines
+slug: /serverless/ingest-pipelines
+title: ((ingest-pipelines-app))
+description: Create and manage ingest pipelines to perform common transformations and enrichments on your data.
+tags: [ 'serverless', 'Elasticsearch', 'Observability', 'Security' ]
+---
+
+
+This content applies to:
+
+[Ingest pipelines](((ref))/ingest.html) let you perform common transformations on your data before indexing.
+For example, you can use pipelines to remove fields, extract values from text, and enrich your data.
+
+A pipeline consists of a series of configurable tasks called processors.
+Each processor runs sequentially, making specific changes to incoming documents.
+After the processors have run, ((es)) adds the transformed documents to your data stream or index.
+
+{/*
+TBD: Do these requirements apply in serverless?
+## Prerequisites
+
+- Nodes with the ingest node role handle pipeline processing. To use ingest pipelines, your cluster must have at least one node with the ingest role. For heavy ingest loads, we recommend creating dedicated ingest nodes.
+- If the Elasticsearch security features are enabled, you must have the manage_pipeline cluster privilege to manage ingest pipelines. To use Kibana’s Ingest Pipelines feature, you also need the cluster:monitor/nodes/info cluster privileges.
+- Pipelines including the enrich processor require additional setup. See Enrich your data.
+*/}
+
+## Create and manage pipelines
+
+In **((project-settings)) → ((manage-app)) → ((ingest-pipelines-app))**, you can:
+
+- View a list of your pipelines and drill down into details
+- Edit or clone existing pipelines
+- Delete pipelines
+
+
+
+To create a pipeline, click **Create pipeline → New pipeline**.
+For an example tutorial, see [Example: Parse logs](((ref))/common-log-format-example.html).
+
+The **New pipeline from CSV** option lets you use a file with comma-separated values (CSV) to create an ingest pipeline that maps custom data to the Elastic Common Schema (ECS).
+Mapping your custom data to ECS makes the data easier to search and lets you reuse visualizations from other data sets.
+To get started, check [Map custom data to ECS](((ecs-ref))/ecs-converting.html).
+
+## Test pipelines
+
+Before you use a pipeline in production, you should test it using sample documents.
+When creating or editing a pipeline in **((ingest-pipelines-app))**, click **Add documents**.
+In the **Documents** tab, provide sample documents and click **Run the pipeline**:
+
+
diff --git a/serverless/pages/integrations.mdx b/serverless/pages/integrations.mdx
new file mode 100644
index 00000000..008f4ce4
--- /dev/null
+++ b/serverless/pages/integrations.mdx
@@ -0,0 +1,17 @@
+---
+id: serverlessIntegrations
+slug: /serverless/integrations
+title: Integrations
+description: Use our pre-built integrations to connect your data to Elastic.
+tags: [ 'serverless', 'ingest', 'integration' ]
+---
+
+
+This content applies to:
+
+Elastic integrations are a streamlined way to connect your data to Elastic.
+Integrations are available for popular services and platforms, like Nginx, AWS, and MongoDB,
+as well as many generic input types like log files.
+
+Integration documentation is available in the product when you install an integration,
+or you can explore our [Elastic integrations documentation](https://docs.elastic.co/integrations).
diff --git a/serverless/pages/logstash-pipelines.mdx b/serverless/pages/logstash-pipelines.mdx
new file mode 100644
index 00000000..77931be6
--- /dev/null
+++ b/serverless/pages/logstash-pipelines.mdx
@@ -0,0 +1,73 @@
+---
+id: serverlessLogstashPipelines
+slug: /serverless/logstash-pipelines
+title: ((ls-pipelines-app))
+description: Create, edit, and delete your ((ls)) pipeline configurations.
+tags: [ 'serverless', 'Elasticsearch', 'Observability', 'Security' ]
+---
+
+
+This content applies to:
+
+In **((project-settings)) → ((manage-app)) → ((ls-pipelines-app))**, you can control multiple ((ls)) instances and pipeline configurations.
+
+
+
+On the ((ls)) side, you must enable configuration management and register ((ls)) to use the centrally managed pipeline configurations.
+
+
+After you configure ((ls)) to use centralized pipeline management, you can no longer specify local pipeline configurations.
+The `pipelines.yml` file and settings such as `path.config` and `config.string` are inactive when centralized pipeline management is enabled.
+
+
+## Manage pipelines
+
+{/*
+TBD: What is the appropriate RBAC for serverless?
+If ((kib)) is protected with basic authentication, make sure your ((kib)) user has
+the `logstash_admin` role as well as the `logstash_writer` role that you created
+when you configured Logstash to use basic authentication. Additionally,
+in order to view (as read-only) non-centrally-managed pipelines in the pipeline management
+UI, make sure your ((kib)) user has the `monitoring_user` role as well.
+*/}
+
+1. [Configure centralized pipeline management](((logstash-ref))/configuring-centralized-pipelines.html).
+1. To add a new pipeline, go to **((project-settings)) → ((manage-app)) → ((ls-pipelines-app))** and click **Create pipeline**. Provide the following details, then click **Create and deploy**.
+
+Pipeline ID
+: A name that uniquely identifies the pipeline.
+ This is the ID that you used when you configured centralized pipeline management and specified a list of pipeline IDs in the `xpack.management.pipeline.id` setting.
+
+Description
+: A description of the pipeline configuration. This information is for your use.
+
+Pipeline
+: The pipeline configuration.
+ You can treat the editor like any other editor.
+ You don't have to worry about whitespace or indentation.
+
+Pipeline workers
+: The number of parallel workers used to run the filter and output stages of the pipeline.
+
+Pipeline batch size
+: The maximum number of events an individual worker thread collects before
+executing filters and outputs.
+
+Pipeline batch delay
+: Time in milliseconds to wait for each event before sending an undersized
+batch to pipeline workers.
+
+Queue type
+: The internal queueing model for event buffering.
+ Options are `memory` for in-memory queueing and `persisted` for disk-based acknowledged queueing.
+
+Queue max bytes
+: The total capacity of the queue when persistent queues are enabled.
+
+Queue checkpoint writes
+: The maximum number of events written before a checkpoint is forced when
+persistent queues are enabled.
+
+To delete one or more pipelines, select their checkboxes then click **Delete**.
+
+For more information about pipeline behavior, go to [Centralized Pipeline Management](((logstash-ref))/logstash-centralized-pipeline-management.html#_pipeline_behavior).
diff --git a/serverless/pages/machine-learning.mdx b/serverless/pages/machine-learning.mdx
new file mode 100644
index 00000000..e4e58610
--- /dev/null
+++ b/serverless/pages/machine-learning.mdx
@@ -0,0 +1,44 @@
+---
+id: serverlessMachineLearning
+slug: /serverless/machine-learning
+title: ((ml-app))
+description: View, export, and import ((ml)) jobs and models.
+tags: [ 'serverless', 'Elasticsearch', 'Observability', 'Security' ]
+---
+
+
+This content applies to:
+
+To view your ((ml)) resources, go to **((project-settings)) → ((manage-app)) → ((ml-app))**:
+
+
+{/* TO-DO: This screenshot should be automated. */}
+
+The ((ml-features)) that are available vary by project type:
+
+- ((es-serverless)) projects have trained models.
+- ((observability)) projects have ((anomaly-jobs)).
+- ((security)) projects have ((anomaly-jobs)), ((dfanalytics-jobs)), and trained models.
+
+For more information, go to [((anomaly-detect-cap))](((ml-docs))/ml-ad-overview.html), [((dfanalytics-cap))](((ml-docs))/ml-dfanalytics.html) and [Natural language processing](((ml-docs))/ml-nlp.html).
+
+## Synchronize saved objects
+
+Before you can view your ((ml)) ((dfeeds)), jobs, and trained models in ((kib)), they must have saved objects.
+For example, if you used APIs to create your jobs, wait for automatic synchronization or go to the **((ml-app))** page and click **Synchronize saved objects**.
+
+## Export and import jobs
+
+You can export and import your ((ml)) job and ((dfeed)) configuration details on the **((ml-app))** page.
+For example, you can export jobs from your test environment and import them in your production environment.
+
+The exported file contains configuration details; it does not contain the ((ml)) models.
+For ((anomaly-detect)), you must import and run the job to build a model that is accurate for the new environment.
+For ((dfanalytics)), trained models are portable; you can import the job then transfer the model to the new cluster.
+Refer to [Exporting and importing ((dfanalytics)) trained models](((ml-docs))/ml-trained-models.html#export-import).
+
+There are some additional actions that you must take before you can successfully import and run your jobs:
+
+- The ((data-sources)) that are used by ((anomaly-detect)) ((dfeeds)) and ((dfanalytics)) source indices must exist; otherwise, the import fails.
+- If your ((anomaly-jobs)) use custom rules with filter lists, the filter lists must exist; otherwise, the import fails.
+- If your ((anomaly-jobs)) were associated with calendars, you must create the calendar in the new environment and add your imported jobs to the calendar.
\ No newline at end of file
diff --git a/serverless/pages/maintenance-windows.mdx b/serverless/pages/maintenance-windows.mdx
new file mode 100644
index 00000000..0020d0dc
--- /dev/null
+++ b/serverless/pages/maintenance-windows.mdx
@@ -0,0 +1,63 @@
+---
+id: serverlessMaintenanceWindows
+slug: /serverless/maintenance-windows
+title: ((maint-windows-app))
+description: Suppress rule notifications for scheduled periods of time.
+tags: [ 'serverless', 'Observability', 'Security' ]
+---
+
+
+This content applies to:
+
+
+You can schedule single or recurring maintenance windows to temporarily reduce rule notifications.
+For example, a maintenance window prevents false alarms during planned outages.
+
+Alerts continue to be generated, however notifications are suppressed as follows:
+
+- When an alert occurs during a maintenance window, there are no notifications.
+When the alert recovers, there are no notifications--even if the recovery occurs after the maintenance window ends.
+- When an alert occurs before a maintenance window and recovers during or after the maintenance window, notifications are sent as usual.
+
+{/*
+TBD: What RBAC requirements exist in serverless?
+## Configure access to maintenance windows
+
+To use maintenance windows, you must have the appropriate [subscription](((subscriptions))) and ((kib)) feature privileges.
+
+- To have full access to maintenance windows, you must have `All` privileges for the **Management → Maintenance Windows*** feature.
+- To have view-only access to maintenance windows, you must have `Read` privileges for the **Management → Maintenance Windows* feature.
+
+For more details, refer to ((kib)) privileges.
+*/}
+
+## Create and manage maintenance windows
+
+In **((project-settings)) → ((manage-app)) → ((maint-windows-app))** you can create, edit, and archive maintenance windows.
+
+When you create a maintenance window, you must provide a name and a schedule.
+You can optionally configure it to repeat daily, monthly, yearly, or on a custom interval.
+
+
+{/* NOTE: This is an autogenerated screenshot. Do not edit it directly. */}
+
+If you turn on **Filter alerts**, you can use KQL to filter the alerts affected by the maintenance window.
+For example, you can suppress notifications for alerts from specific rules:
+
+
+{/* NOTE: This is an autogenerated screenshot. Do not edit it directly. */}
+
+
+- You can select only a single category when you turn on filters.
+- Some rules are not affected by maintenance window filters because their alerts do not contain requisite data.
+In particular, [((stack-monitor-app))](((kibana-ref))/kibana-alerts.html), [tracking containment](((kibana-ref))geo-alerting.html), [((anomaly-jobs)) health](((ml-docs))/ml-configuring-alerts.html), and [transform health](((ref))/transform-alerts.html) rules are not affected by the filters.
+
+
+A maintenance window can have any one of the following statuses:
+
+- `Upcoming`: It will run at the scheduled date and time.
+- `Running`: It is running.
+- `Finished`: It ended and does not have a repeat schedule.
+- `Archived`: It is archived. In a future release, archived maintenance windows will be queued for deletion.
+
+When you view alert details in ((kib)), each alert shows unique identifiers for maintenance windows that affected it.
\ No newline at end of file
diff --git a/serverless/pages/manage-access-to-org-from-existing-account.mdx b/serverless/pages/manage-access-to-org-from-existing-account.mdx
new file mode 100644
index 00000000..1cdb0437
--- /dev/null
+++ b/serverless/pages/manage-access-to-org-from-existing-account.mdx
@@ -0,0 +1,19 @@
+---
+id: serverlessGeneralJoinOrganizationFromExistingCloudAccount
+slug: /serverless/general/join-organization-from-existing-cloud-account
+title: Join an organization from an existing Elastic Cloud account
+description: Join a new organization and bring over your projects.
+tags: [ 'serverless', 'general', 'organization', 'join', 'how to' ]
+---
+
+
+
+If you already belong to an organization, and you want to join a new one, it is currently not possible to bring your projects over to the new organization.
+
+If you want to join a new project, follow these steps:
+
+1. Make sure you do not have active projects before you leave your current organization.
+1. Delete your projects and clear any bills.
+1. Leave your current organization.
+1. Ask the administrator to invite you to the organization you want to join.
+1. Accept the invitation that you will get by email.
\ No newline at end of file
diff --git a/serverless/pages/manage-access-to-org-user-roles.mdx b/serverless/pages/manage-access-to-org-user-roles.mdx
new file mode 100644
index 00000000..dfdb63a1
--- /dev/null
+++ b/serverless/pages/manage-access-to-org-user-roles.mdx
@@ -0,0 +1,71 @@
+---
+id: serverlessGeneralAssignUserRoles
+slug: /serverless/general/assign-user-roles
+title: Assign user roles and privileges
+description: Manage the predefined set of roles and privileges for all your projects.
+tags: [ 'serverless', 'general', 'organization', 'roles', 'how to' ]
+---
+
+
+Within an organization, users can have one or more roles and each role grants specific privileges.
+
+You can set a role:
+
+- globally, for all projects of the same type (Elasticsearch, Observability, or Security). In this case, the role will also apply to new projects created later.
+- individually, for specific projects only. To do that, you have to set the **Role for all instances** field of that specific project type to **None**.
+
+
+
+## Organization-level roles
+
+- **Organization owner**. Can manage all roles under the organization and has full access to all serverless projects, organization-level details, billing details, and subscription levels. This role is assigned by default to the person who created the organization.
+
+- **Billing admin**. Has access to all invoices and payment methods. Can make subscription changes.
+
+## Instance access roles
+
+Each serverless project type has a set of predefined roles that you can assign to your organization members.
+
+### Elasticsearch
+
+- **Admin**. Has full access to project management, properties, and security privileges. Admins log into projects with superuser role privileges.
+
+- **Developer**. Creates API keys, indices, data streams, adds connectors, and builds visualizations.
+
+- **Viewer**. Has read-only access to project details, data, and features.
+
+### Observability
+
+- **Admin**. Has full access to project management, properties, and security privileges. Admins log into projects with superuser role privileges.
+
+- **Editor**. Configures all Observability projects. Has read-only access to data indices. Has full access to all project features.
+
+- **Viewer**. Has read-only access to project details, data, and features.
+
+### Security
+
+- **Admin**. Has full access to project management, properties, and security privileges. Admins log into projects with superuser role privileges.
+
+- **Editor**. Configures all Security projects. Has read-only access to data indices. Has full access to all project features.
+
+- **Viewer**. Has read-only access to project details, data, and features.
+
+- **Tier 1 analyst**. Ideal for initial alert triage. General read access, can create dashboards and visualizations.
+
+- **Tier 2 analyst**. Ideal for alert triage and beginning the investigation process. Can create cases.
+
+- **Tier 3 analyst**. Deeper investigation capabilities. Access to rules, lists, cases, Osquery, and response actions.
+
+- **Threat intelligence analyst**. Access to alerts, investigation tools, and intelligence pages.
+
+- **Rule author**. Access to detection engineering and rule creation. Can create rules from available data sources and add exceptions to reduce false positives.
+
+- **SOC manager**. Access to alerts, cases, investigation tools, endpoint policy management, and response actions.
+
+- **Endpoint operations analyst**. Access to endpoint response actions. Can manage endpoint policies, ((fleet)), and integrations.
+
+- **Platform engineer**. Access to ((fleet)), integrations, endpoints, and detection content.
+
+- **Detections admin**. All available detection engine permissions to include creating rule actions, such as notifications to third-party systems.
+
+- **Endpoint policy manager**. Access to endpoint policy management and related artifacts. Can manage ((fleet)) and integrations.
diff --git a/serverless/pages/manage-access-to-org.mdx b/serverless/pages/manage-access-to-org.mdx
new file mode 100644
index 00000000..eb463f09
--- /dev/null
+++ b/serverless/pages/manage-access-to-org.mdx
@@ -0,0 +1,37 @@
+---
+id: serverlessGeneralManageAccessToOrganization
+slug: /serverless/general/manage-access-to-organization
+title: Invite your team
+description: Add members to your organization and projects.
+tags: [ 'serverless', 'general', 'organization', 'overview' ]
+---
+
+To allow other users to interact with your projects, you must invite them to join your organization.
+
+When inviting them, you also to define their access to your organization resources and instances.
+
+1. Go to the user icon on the header bar and select **Organization**.
+
+2. Click **Invite members**.
+
+ You can add multiple members by entering their email addresses separated by a space.
+
+ You can grant access to all projects of the same type with a unique role, or select individual roles for specific projects only.
+
+
+ In **Instance access**, The **Deployment** tab correspond to [hosted deployments](https://www.elastic.co/guide/en/cloud/current/ec-getting-started.html), while **Elasticsearch**, **Observability**, and **Security** correspond to serverless projects.
+
+
+3. Click **Send invites**.
+
+ Invitations to join an organization are sent by email. Invited users have 72 hours to accept the invitation. If they do not join within that period, you will have to send a new invitation.
+
+On the **Members** tab of the **Organization** page, you can view the list of current members, their status and role.
+
+In the **Actions** column, click the three dots to edit a member’s role or revoke the invite.
+
+## Leave an organization
+
+On the **Organization** page, click **Leave organization**.
+
+If you're the only user in the organization, you can only leave if you have deleted all your projects and don't have any pending bills.
\ No newline at end of file
diff --git a/serverless/pages/manage-billing-check-subscription.mdx b/serverless/pages/manage-billing-check-subscription.mdx
new file mode 100644
index 00000000..74a428d2
--- /dev/null
+++ b/serverless/pages/manage-billing-check-subscription.mdx
@@ -0,0 +1,20 @@
+---
+id: serverlessGeneralCheckSubscription
+slug: /serverless/general/check-subscription
+title: Check your subscription
+description: Manage your account details and subscription level.
+tags: [ 'serverless', 'general', 'billing', 'subscription' ]
+---
+
+
+To find more details about your subscription:
+
+1. Navigate to [cloud.elastic.co](https://cloud.elastic.co/) and log in to your Elastic Cloud account.
+
+1. Go to the user icon on the header bar and select **Billing**.
+
+On the **Overview** page you can:
+
+- Update your subscription level
+- Check the date when your next bill will be issued and update the payment method
+- Check your account details and add Elastic Consumption Units (ECU) credits
diff --git a/serverless/pages/manage-billing-history.mdx b/serverless/pages/manage-billing-history.mdx
new file mode 100644
index 00000000..8147741b
--- /dev/null
+++ b/serverless/pages/manage-billing-history.mdx
@@ -0,0 +1,18 @@
+---
+id: serverlessGeneralBillingHistory
+slug: /serverless/general/billing-history
+title: Check your billing history
+description: Monitor payments and billing receipts.
+tags: [ 'serverless', 'general', 'billing', 'history' ]
+---
+
+
+Information about outstanding payments and billing receipts is available from the [((ess-console-name))](((ess-console))).
+
+To check your billing history:
+
+1. Log in to the [((ess-console-name))](((ess-console))).
+
+2. Select the user icon on the header bar and choose **Billing** from the menu.
+
+3. Under the **History** tab, select the invoice number for a detailed PDF.
diff --git a/serverless/pages/manage-billing-monitor-usage.mdx b/serverless/pages/manage-billing-monitor-usage.mdx
new file mode 100644
index 00000000..70da356f
--- /dev/null
+++ b/serverless/pages/manage-billing-monitor-usage.mdx
@@ -0,0 +1,24 @@
+---
+id: serverlessGeneralMonitorUsage
+slug: /serverless/general/monitor-usage
+title: Monitor your account usage
+description: Check the usage breakdown of your account.
+tags: [ 'serverless', 'general', 'billing', 'usage' ]
+---
+
+
+To find more details about your account usage:
+
+1. Navigate to [cloud.elastic.co](https://cloud.elastic.co/) and log in to your ((ecloud)) account.
+
+2. Go to the user icon on the header bar and select **Billing**.
+
+On the **Usage** page you can:
+
+- Monitor the usage for the current month, including total hourly rate and month-to-date usage
+- Check the usage breakdown for a selected time range
+
+
+The usage breakdown information is an estimate. To get the exact amount you owe for a given month, check your invoices in the .
+
+
diff --git a/serverless/pages/manage-billing.mdx b/serverless/pages/manage-billing.mdx
new file mode 100644
index 00000000..9fac8706
--- /dev/null
+++ b/serverless/pages/manage-billing.mdx
@@ -0,0 +1,23 @@
+---
+id: serverlessGeneralManageBilling
+slug: /serverless/general/manage-billing
+title: Manage billing of your organization
+description: Configure the billing details of your organization.
+tags: [ 'serverless', 'general', 'billing', 'overview' ]
+---
+
+
+
+
+
+You can manage the billing details of your organization directly from the Elastic Cloud console.
+
+1. Navigate to [cloud.elastic.co](https://cloud.elastic.co/) and log in to your Elastic Cloud account.
+
+2. Go to the user icon on the header bar and select **Billing**.
+
+From the **Billing pages**, you can perform the following tasks:
+
+-
+-
+-
diff --git a/serverless/pages/manage-org.mdx b/serverless/pages/manage-org.mdx
new file mode 100644
index 00000000..a9e54e0f
--- /dev/null
+++ b/serverless/pages/manage-org.mdx
@@ -0,0 +1,26 @@
+---
+id: serverlessGeneralManageOrganization
+slug: /serverless/general/manage-organization
+title: Manage your organization
+description: Manage your instances, users, and settings.
+tags: [ 'serverless', 'general', 'organization', 'overview' ]
+---
+
+
+When you sign up to Elastic Cloud, you create an **organization**.
+
+This organization is the umbrella for all of your Elastic Cloud resources, users, and account settings. Every organization has a unique identifier. Bills are invoiced according to the billing contact and details that you set for your organization.
+
+
\ No newline at end of file
diff --git a/serverless/pages/manage-your-project.mdx b/serverless/pages/manage-your-project.mdx
new file mode 100644
index 00000000..acdaf8e5
--- /dev/null
+++ b/serverless/pages/manage-your-project.mdx
@@ -0,0 +1,131 @@
+---
+id: serverlessGeneralManageProject
+slug: /serverless/elasticsearch/manage-project
+title: Manage your projects
+description: Configure project-wide features and usage.
+tags: [ 'serverless', 'elasticsearch', 'project', 'manage' ]
+---
+
+
+To manage a project:
+
+1. Navigate to [cloud.elastic.co](https://cloud.elastic.co/).
+
+2. Log in to your Elastic Cloud account.
+
+3. Select your project from the **Serverless projects** panel and click **Manage**.
+
+From the project page, you can:
+
+- **Rename your project**. In the **Overview** section, click **Edit** next to the project's name.
+
+- **Manage data and integrations**. Update your project data, including storage settings, indices, and data views, directly in your project.
+
+- **Manage API keys**. Access your project and interact with its data programmatically using Elasticsearch APIs.
+
+- **Manage members**. Add members and manage their access to this project or other resources of your organization.
+
+## Features and usage
+
+You can also edit the features and usage for your project. Available features vary by project type.
+
+
+
+
+ **Search Power**
+
+
+ Controls the number of VCUs (Virtual Compute Units) allocated per GB of data to your project.
+
+ Each VCU adds a combination of CPU, RAM, and data storage to your project, resulting in performance gains.
+
+
+
+
+
+
+
+ **Project features**
+
+
+ Controls feature tiers and add-on options for your ((elastic-sec)) project.
+
+
+
+
+
+
+ **Search Data Lake**
+
+
+ Provides cost-optimized storage for your data. By default, all data is stored indefinitely in the Search Data Lake and remains searchable.
+
+ You can specify different retention periods for each data source configured in your project.
+
+
+
+
+
+
+
+
+
+ **Search Boost Window**
+
+
+ Provides accelerated query speed for data residing on data streams. Increasing the boost window results in improved search and analytics performance for more data.
+
+ The default Search Boost window size is 7 days.
+
+
+
+
+
+
+
+
+
+### Project features and add-ons
+
+ For ((elastic-sec)) projects, edit the **Project features** to select a feature tier and enable add-on options for specific use cases.
+
+
+
+ **Security Analytics Essentials**
+
+ Standard security analytics, detections, investigations, and collaborations. Allows these add-ons:
+ * **Endpoint Protection Essentials**: Endpoint protections with ((elastic-defend)).
+ * **Cloud Protection Essentials**: Cloud native security features.
+
+
+
+ **Security Analytics Complete**
+
+ Everything in **Security Analytics Essentials** plus advanced features such as entity analytics, threat intelligence, and more. Allows these add-ons:
+ * **Endpoint Protection Complete**: Everything in **Endpoint Protection Essentials** plus advanced endpoint detection and response features.
+ * **Cloud Protection Complete**: Everything in **Cloud Protection Essentials** plus advanced cloud security features.
+
+
+
diff --git a/serverless/pages/maps.mdx b/serverless/pages/maps.mdx
new file mode 100644
index 00000000..963a3028
--- /dev/null
+++ b/serverless/pages/maps.mdx
@@ -0,0 +1,82 @@
+---
+id: serverlessMaps
+slug: /serverless/maps
+title: ((maps-app))
+description: Create maps from your geographical data.
+tags: [ 'serverless', 'Security' ]
+---
+
+
+This content applies to:
+
+In **((project-settings)) → ((maps-app))** you can:
+
+- Build maps with multiple layers and indices.
+- Animate spatial temporal data.
+- Upload GeoJSON files and shapefiles.
+- Embed your map in dashboards.
+- Focus on only the data that's important to you.
+
+{/*
+- Symbolize features using data values.
+ */}
+
+## Build maps with multiple layers and indices
+
+Use multiple layers and indices to show all your data in a single map.
+Show how data sits relative to physical features like weather patterns, human-made features like international borders, and business-specific features like sales regions.
+Plot individual documents or use aggregations to plot any data set, no matter how large.
+
+
+
+Go to **((project-settings)) → ((maps-app))** and click **Add layer**.
+To learn about specific types of layers, check out [Heat map layer](((kibana-ref))/heatmap-layer.html), [Tile layer](((kibana-ref))/tile-layer.html), and [Vector layer](((kibana-ref))/vector-layer.html).
+
+## Animate spatial temporal data
+
+Data comes to life with animation.
+Hard to detect patterns in static data pop out with movement.
+Use time slider to animate your data and gain deeper insights.
+
+This animated map uses the time slider to show Portland buses over a period of 15 minutes.
+The routes come alive as the bus locations update with time.
+
+
+
+To create this type of map, check out [Track, visualize, and alert assets in real time](((kibana-ref))/asset-tracking-tutorial.html).
+
+## Upload GeoJSON files and shapefiles
+
+Use **((maps-app))** to drag and drop your GeoJSON and shapefile data and then use them as layers in your map.
+Check out [Import geospatial data](((kibana-ref))/import-geospatial-data.html).
+
+## Embed your map in dashboards
+
+Viewing data from different angles provides better insights.
+Dimensions that are obscured in one visualization might be illuminated in another.
+Add your map to a and view your geospatial data alongside bar charts, pie charts, tag clouds, and more.
+
+This choropleth map shows the density of non-emergency service requests in San Diego by council district.
+The map is embedded in a dashboard, so users can better understand when services are requested and gain insight into the top requested services.
+
+
+
+For a detailed example, check out [Build a map to compare metrics by country or region](((kibana-ref))/maps-getting-started.html).
+
+{/*
+TBD: There doesn't seem to be content to link to for this section, so it's omitted for now.
+## Symbolize features using data values
+
+Customize each layer to highlight meaningful dimensions in your data.
+For example, use dark colors to symbolize areas with more web log traffic, and lighter colors to symbolize areas with less traffic.
+*/}
+
+## Focus on only the data that's important to you
+
+Search across the layers in your map to focus on just the data you want.
+Combine free text search with field-based search using the ((kib)) Query Language (KQL)
+Set the time filter to restrict layers by time.
+Draw a polygon on the map or use the shape from features to create spatial filters.
+Filter individual layers to compares facets.
+
+Check out [Search geographic data](((kibana-ref))/maps-search.html).
\ No newline at end of file
diff --git a/serverless/pages/profile-queries-and-aggregations.mdx b/serverless/pages/profile-queries-and-aggregations.mdx
new file mode 100644
index 00000000..98247b89
--- /dev/null
+++ b/serverless/pages/profile-queries-and-aggregations.mdx
@@ -0,0 +1,321 @@
+---
+id: serverlessDevtoolsProfileQueriesAndAggregations
+slug: /serverless/devtools/profile-queries-and-aggregations
+title: Search Profiler
+description: Diagnose and debug poorly performing search queries.
+tags: [ 'serverless', 'dev tools', 'how-to' ]
+---
+
+
+This content applies to:
+
+{/* TODO: The following content was copied verbatim from the ES docs on Oct 5, 2023. It should be included through
+transclusion. */}
+
+((es)) has a powerful [Profile API](((ref))/search-profile.html) for debugging search queries.
+It provides detailed timing information about the execution of individual components in a search request.
+This allows users to optimize queries for better performance.
+
+However, Profile API responses can be hard to read, especially for complex queries.
+**((searchprofiler))** helps you visualize these responses in a graphical interface.
+
+
+
+## Get started
+
+Access **((searchprofiler))** under **Dev Tools**.
+
+**((searchprofiler))** displays the names of the indices searched and how long it took for the query to complete.
+Test it out by replacing the default `match_all` query with the query you want to profile, and then select **Profile**.
+
+The following example shows the results of profiling the `match_all` query.
+If you take a closer look at the information for the `.security_7` sample index, the
+**Cumulative time** field shows you that the query took 0.028ms to execute.
+
+
+
+{/*
+
+The cumulative time metric is the sum of individual shard times.
+It is not necessarily the actual time it took for the query to return (wall clock time).
+Because shards might be processed in parallel on multiple nodes, the wall clock time can
+be significantly less than the cumulative time.
+However, if shards are colocated on the same node and executed serially, the wall clock time is closer to the cumulative time.
+
+While the cumulative time metric is useful for comparing the performance of your
+indices and shards, it doesn't necessarily represent the actual physical query times.
+
+ */}
+{/* Commenting out for moment, given shards and nodes are obfuscated concepts in serverless */}
+
+To see more profiling information, select **View details**.
+You'll find details about query components and the timing
+breakdown of low-level methods.
+For more information, refer to [Profiling queries](((ref))/search-profile.html#profiling-queries) in the ((es)) documentation.
+
+## Filter for an index or type
+
+By default, all queries executed by the **((searchprofiler))** are sent
+to `GET /_search`.
+It searches across your entire cluster (all indices, all types).
+
+To query a specific index or type, you can use the **Index** filter.
+
+In the following example, the query is executed against the indices `.security-7` and `kibana_sample_data_ecommerce`.
+This is equivalent to making a request to `GET /.security-7,kibana_sample_data_ecommerce/_search`.
+
+
+
+
+
+## Profile a more complicated query
+
+To understand how the query trees are displayed inside the **((searchprofiler))**,
+take a look at a more complicated query.
+
+1. Index the following data using **Console**:
+
+ ```js
+ POST test/_bulk
+ {"index":{}}
+ {"name":"aaron","age":23,"hair":"brown"}
+ {"index":{}}
+ {"name":"sue","age":19,"hair":"red"}
+ {"index":{}}
+ {"name":"sally","age":19,"hair":"blonde"}
+ {"index":{}}
+ {"name":"george","age":19,"hair":"blonde"}
+ {"index":{}}
+ {"name":"fred","age":69,"hair":"blonde"}
+ ```
+ {/* CONSOLE */}
+
+1. From the **((searchprofiler))**, enter **test** in the **Index** field to restrict profiled
+ queries to the `test` index.
+
+1. Replace the default `match_all` query in the query editor with a query that has two sub-query
+ components and includes a simple aggregation:
+ ```js
+ {
+ "query": {
+ "bool": {
+ "should": [
+ {
+ "match": {
+ "name": "fred"
+ }
+ },
+ {
+ "terms": {
+ "name": [
+ "sue",
+ "sally"
+ ]
+ }
+ }
+ ]
+ }
+ },
+ "aggs": {
+ "stats": {
+ "stats": {
+ "field": "price"
+ }
+ }
+ }
+ }
+ ```
+ {/* NOTCONSOLE */}
+
+1. Select **Profile** to profile the query and visualize the results.
+
+ 
+
+ - The top `BooleanQuery` component corresponds to the `bool` in the query.
+ - The second `BooleanQuery` corresponds to the `terms` query, which is internally
+ converted to a `Boolean` of `should` clauses. It has two child queries that correspond
+ to "sally" and "sue from the `terms` query.
+ - The `TermQuery` that's labeled with "name:fred" corresponds to `match: fred` in the query.
+
+
+ In the time columns, the **Self time** and **Total time** are no longer
+ identical on all rows:
+
+ - **Self time** represents how long the query component took to execute.
+ - **Total time** is the time a query component and all its children took to execute.
+
+ Therefore, queries like the Boolean queries often have a larger total time than self time.
+
+1. Select **Aggregation Profile** to view aggregation profiling statistics.
+
+ This query includes a `stats` agg on the `"age"` field.
+ The **Aggregation Profile** tab is only enabled when the query being profiled contains an aggregation.
+
+1. Select **View details** to view the timing breakdown.
+
+ 
+
+ For more information about how the **((searchprofiler))** works, how timings are calculated, and
+ how to interpret various results, refer to
+ [Profiling queries](((ref))/search-profile.html#profiling-queries) in the ((es)) documentation.
+
+
+
+## Render pre-captured profiler JSON
+
+Sometimes you might want to investigate performance problems that are temporal in nature.
+For example, a query might only be slow at certain time of day when many customers are using your system.
+You can set up a process to automatically profile slow queries when they occur and then
+save those profile responses for later analysis.
+
+The **((searchprofiler))** supports this workflow by allowing you to paste the
+pre-captured JSON in the query editor.
+The **((searchprofiler))** will detect that you
+have entered a JSON response (rather than a query) and will render just the visualization,
+rather than querying the cluster.
+
+To see how this works, copy and paste the following profile response into the
+query editor and select **Profile**.
+
+```js
+{
+ "took": 3,
+ "timed_out": false,
+ "_shards": {
+ "total": 1,
+ "successful": 1,
+ "failed": 0
+ },
+ "hits": {
+ "total": 1,
+ "max_score": 1.3862944,
+ "hits": [
+ {
+ "_index": "test",
+ "_type": "test",
+ "_id": "AVi3aRDmGKWpaS38wV57",
+ "_score": 1.3862944,
+ "_source": {
+ "name": "fred",
+ "age": 69,
+ "hair": "blonde"
+ }
+ }
+ ]
+ },
+ "profile": {
+ "shards": [
+ {
+ "id": "[O-l25nM4QN6Z68UA5rUYqQ][test][0]",
+ "searches": [
+ {
+ "query": [
+ {
+ "type": "BooleanQuery",
+ "description": "+name:fred #(ConstantScore(*:*))^0.0",
+ "time": "0.5884370000ms",
+ "breakdown": {
+ "score": 7243,
+ "build_scorer_count": 1,
+ "match_count": 0,
+ "create_weight": 196239,
+ "next_doc": 9851,
+ "match": 0,
+ "create_weight_count": 1,
+ "next_doc_count": 2,
+ "score_count": 1,
+ "build_scorer": 375099,
+ "advance": 0,
+ "advance_count": 0
+ },
+ "children": [
+ {
+ "type": "TermQuery",
+ "description": "name:fred",
+ "time": "0.3016880000ms",
+ "breakdown": {
+ "score": 4218,
+ "build_scorer_count": 1,
+ "match_count": 0,
+ "create_weight": 132425,
+ "next_doc": 2196,
+ "match": 0,
+ "create_weight_count": 1,
+ "next_doc_count": 2,
+ "score_count": 1,
+ "build_scorer": 162844,
+ "advance": 0,
+ "advance_count": 0
+ }
+ },
+ {
+ "type": "BoostQuery",
+ "description": "(ConstantScore(*:*))^0.0",
+ "time": "0.1223030000ms",
+ "breakdown": {
+ "score": 0,
+ "build_scorer_count": 1,
+ "match_count": 0,
+ "create_weight": 17366,
+ "next_doc": 0,
+ "match": 0,
+ "create_weight_count": 1,
+ "next_doc_count": 0,
+ "score_count": 0,
+ "build_scorer": 102329,
+ "advance": 2604,
+ "advance_count": 2
+ },
+ "children": [
+ {
+ "type": "MatchAllDocsQuery",
+ "description": "*:*",
+ "time": "0.03307600000ms",
+ "breakdown": {
+ "score": 0,
+ "build_scorer_count": 1,
+ "match_count": 0,
+ "create_weight": 6068,
+ "next_doc": 0,
+ "match": 0,
+ "create_weight_count": 1,
+ "next_doc_count": 0,
+ "score_count": 0,
+ "build_scorer": 25615,
+ "advance": 1389,
+ "advance_count": 2
+ }
+ }
+ ]
+ }
+ ]
+ }
+ ],
+ "rewrite_time": 168640,
+ "collector": [
+ {
+ "name": "CancellableCollector",
+ "reason": "search_cancelled",
+ "time": "0.02952900000ms",
+ "children": [
+ {
+ "name": "SimpleTopScoreDocCollector",
+ "reason": "search_top_hits",
+ "time": "0.01931700000ms"
+ }
+ ]
+ }
+ ]
+ }
+ ],
+ "aggregations": []
+ }
+ ]
+ }
+}
+```
+{/* NOTCONSOLE */}
+
+Your output should look similar to this:
+
+
diff --git a/serverless/pages/project-and-management-settings.mdx b/serverless/pages/project-and-management-settings.mdx
new file mode 100644
index 00000000..961a7f6a
--- /dev/null
+++ b/serverless/pages/project-and-management-settings.mdx
@@ -0,0 +1,25 @@
+---
+id: serverlessProjectAndManagementSettings
+slug: /serverless/project-and-management-settings
+title: Project and management settings
+description: Learn about capabilities available in multiple serverless solutions.
+tags: [ 'serverless', 'observability', 'security', 'elasticsearch', 'overview' ]
+---
+
+
+The documentation in this section describes shared capabilities that are available in multiple solutions.
+Look for the doc badge on each page to see if the page is valid for your solution:
+
+* for the ((es)) solution
+* for the ((observability)) solution
+* for the ((security)) solution
+
+
+Some solutions provide versions of these capabilities tailored to your use case.
+Read the main solution docs to learn how to use those capabilities:
+
+*
+*
+*
+
+
diff --git a/serverless/pages/project-settings.mdx b/serverless/pages/project-settings.mdx
new file mode 100644
index 00000000..f56a8c3d
--- /dev/null
+++ b/serverless/pages/project-settings.mdx
@@ -0,0 +1,232 @@
+---
+id: serverlessProjectSettings
+slug: /serverless/project-settings
+title: Management settings
+description: Manage your indices, data views, saved objects, settings, and more from a central location in Elastic.
+tags: [ 'serverless', 'management', 'overview' ]
+---
+
+
+Go to **Project Settings** to manage your indices, data views, saved objects, settings, and more.
+
+Access to individual features is governed by Elastic user roles.
+Consult your administrator if you do not have the appropriate access.
+To learn more about roles, refer to .
+
+
+
+
+ API keys
+
+
+ Create and manage keys that can send requests on behalf of users.
+
+
+
+
+
+
+
+
+
+
+
+
+ Create and manage reusable connectors for triggering actions.
+
+
+
+
+
+
+
+
+
+
+
+
+ Manage the fields in the data views that retrieve your data from ((es)).
+
+
+
+
+
+
+
+
+
+ Entity Risk Score
+
+
+ Manage entity risk scoring, and preview risky entities.
+
+
+
+
+
+
+
+
+
+
+ Manage files that are stored in ((kib)).
+
+
+
+
+
+
+
+
+
+
+
+
+ View index settings, mappings, and statistics and perform operations on indices.
+
+
+
+
+
+
+
+
+
+
+
+
+ Create and manage ingest pipelines that parse, transform, and enrich your data.
+
+
+
+
+
+
+
+
+
+
+
+
+ Create and manage ((ls)) pipelines that parse, transform, and enrich your data.
+
+
+
+
+
+
+
+
+
+
+
+
+ View, export, and import your ((anomaly-detect)) and ((dfanalytics)) jobs and trained models.
+
+
+
+
+
+
+
+
+
+
+
+
+ Suppress rule notifications for scheduled periods of time.
+
+
+
+
+
+
+
+
+
+
+
+ Create maps from your geographical data.
+
+
+
+
+
+
+
+
+
+
+ Manage and download reports such as CSV files generated from saved searches.
+
+
+
+
+
+
+
+
+
+
+
+
+ Create and manage rules that generate alerts.
+
+
+
+
+
+
+
+
+
+
+ Copy, edit, delete, import, and export your saved objects.
+ These include dashboards, visualizations, maps, ((data-sources)), and more.
+
+
+
+
+
+
+
+
+
+
+
+
+ Create, manage, and assign tags to your saved objects.
+
+
+
+
+
+
+
+
+
+
+
+
+ Use transforms to pivot existing ((es)) indices into summarized or entity-centric indices.
+
+
+
+
+
+
+
+
diff --git a/serverless/pages/reports.mdx b/serverless/pages/reports.mdx
new file mode 100644
index 00000000..851b96a2
--- /dev/null
+++ b/serverless/pages/reports.mdx
@@ -0,0 +1,25 @@
+---
+id: serverlessReports
+slug: /serverless/reports
+title: ((reports-app))
+description: View and manage generated reports.
+tags: [ 'serverless', 'Elasticsearch', 'Observability', 'Security' ]
+related: ['serverlessElasticsearchExploreYourDataDiscoverYourData']
+---
+
+
+This content applies to:
+
+((kib)) provides you with several options to share saved searches, dashboards, and visualizations.
+
+For example, in **Discover**, you can create and download comma-separated values (CSV) files for saved searches.
+
+To view and manage reports, go to **((project-settings)) → ((manage-app)) → ((reports-app))**.
+
+
+{/* TBD: This image was refreshed but should be automated */}
+
+You can download or view details about the report by clicking the icons in the actions menu.
+
+To delete one or more reports, select their checkboxes then click **Delete reports**.
+
diff --git a/serverless/pages/rules.mdx b/serverless/pages/rules.mdx
new file mode 100644
index 00000000..ea4ee72a
--- /dev/null
+++ b/serverless/pages/rules.mdx
@@ -0,0 +1,153 @@
+---
+id: serverlessRules
+slug: /serverless/rules
+title: ((rules-app))
+description: Alerting works by running checks on a schedule to detect conditions defined by a rule.
+tags: [ 'serverless', 'Elasticsearch', 'alerting', 'learn' ]
+related: ['serverlessActionConnectors', 'serverlessElasticsearchExploreYourDataAlertings']
+---
+
+
+This content applies to:
+
+In general, a rule consists of three parts:
+
+* _Conditions_: what needs to be detected?
+* _Schedule_: when/how often should detection checks run?
+* _Actions_: what happens when a condition is detected?
+
+For example, when monitoring a set of servers, a rule might:
+
+* Check for average CPU usage > 0.9 on each server for the last two minutes (condition).
+* Check every minute (schedule).
+* Send a warning email message via SMTP with subject `CPU on {{server}} is high` (action).
+
+{/* 
+
+The following sections describe each part of the rule in more detail. */}
+
+## Conditions
+
+Each project type supports a specific set of rule types.
+Each _rule type_ provides its own way of defining the conditions to detect, but an expression formed by a series of clauses is a common pattern.
+For example, in an ((es)) query rule, you specify an index, a query, and a threshold, which uses a metric aggregation operation (`count`, `average`, `max`, `min`, or `sum`):
+
+
+{/* NOTE: This is an autogenerated screenshot. Do not edit it directly. */}
+
+## Schedule
+
+{/* Rule schedules are defined as an interval between subsequent checks, and can range from a few seconds to months. */}
+
+All rules must have a check interval, which defines how often to evaluate the rule conditions.
+Checks are queued; they run as close to the defined value as capacity allows.
+
+
+
+The intervals of rule checks in ((kib)) are approximate. Their timing is affected by factors such as the frequency at which tasks are claimed and the task load on the system. Refer to [Alerting production considerations](((kibana-ref))/alerting-production-considerations.html)
+{/* missing linkAlerting production considerations */}
+
+
+
+## Actions
+
+You can add one or more actions to your rule to generate notifications when its conditions are met.
+Recovery actions likewise run when rule conditions are no longer met.
+
+When defining actions in a rule, you specify:
+
+* A connector
+* An action frequency
+* A mapping of rule values to properties exposed for that type of action
+
+Each action uses a connector, which provides connection information for a ((kib)) service or third party integration, depending on where you want to send the notifications.
+The specific list of connectors that you can use in your rule vary by project type.
+Refer to .
+{/* If no connectors exist, click **Add connector** to create one. */}
+
+After you select a connector, set the _action frequency_.
+If you want to reduce the number of notifications you receive without affecting their timeliness, some rule types support alert summaries.
+For example, if you create an ((es)) query rule, you can set the action frequency such that you receive summaries of the new, ongoing, and recovered alerts on a custom interval:
+
+
+
+{/* */}
+
+Alternatively, you can set the action frequency such that the action runs for each alert.
+If the rule type does not support alert summaries, this is your only available option.
+You must choose when the action runs (for example, at each check interval, only when the alert status changes, or at a custom action interval).
+You must also choose an action group, which affects whether the action runs.
+Each rule type has a specific set of valid action groups.
+For example, you can set *Run when* to `Query matched` or `Recovered` for the ((es)) query rule:
+
+
+{/* NOTE: This is an autogenerated screenshot. Do not edit it directly. */}
+
+Each connector supports a specific set of actions for each action group and enables different action properties.
+For example, you can have actions that create an ((opsgenie)) alert when rule conditions are met and recovery actions that close the ((opsgenie)) alert.
+
+Some types of rules enable you to further refine the conditions under which actions run.
+For example, you can specify that actions run only when an alert occurs within a specific time frame or when it matches a KQL query.
+
+
+
+If you are not using alert summaries, actions are triggered per alert and a rule can end up generating a large number of actions. Take the following example where a rule is monitoring three servers every minute for CPU usage > 0.9, and the action frequency is `On check intervals`:
+
+* Minute 1: server X123 > 0.9. _One email_ is sent for server X123.
+* Minute 2: X123 and Y456 > 0.9. _Two emails_ are sent, one for X123 and one for Y456.
+* Minute 3: X123, Y456, Z789 > 0.9. _Three emails_ are sent, one for each of X123, Y456, Z789.
+
+In this example, three emails are sent for server X123 in the span of 3 minutes for the same rule. Often, it's desirable to suppress these re-notifications. If
+you set the action frequency to `On custom action intervals` with an interval of 5 minutes, you reduce noise by getting emails only every 5 minutes for
+servers that continue to exceed the threshold:
+
+* Minute 1: server X123 > 0.9. _One email_ will be sent for server X123.
+* Minute 2: X123 and Y456 > 0.9. _One email_ will be sent for Y456.
+* Minute 3: X123, Y456, Z789 > 0.9. _One email_ will be sent for Z789.
+
+To get notified only once when a server exceeds the threshold, you can set the action frequency to `On status changes`. Alternatively, if the rule type supports alert summaries, consider using them to reduce the volume of notifications.
+
+
+
+{/*
+Each action definition is therefore a template: all the parameters needed to invoke a service are supplied except for specific values that are only known at the time the rule condition is detected.
+
+In the server monitoring example, the `email` connector type is used, and `server` is mapped to the body of the email, using the template string `CPU on {{server}} is high`.
+
+When the rule detects the condition, it creates an alert containing the details of the condition. */}
+
+### Action variables
+
+You can pass rule values to an action at the time a condition is detected.
+To view the list of variables available for your rule, click the "add rule variable" button:
+
+
+{/* NOTE: This is an autogenerated screenshot. Do not edit it directly. */}
+
+For more information about common action variables, refer to [Rule actions variables](((kibana-ref))/rule-action-variables.html)
+{/* missing link */}
+
+## Alerts
+
+When checking for a condition, a rule might identify multiple occurrences of the condition.
+((kib)) tracks each of these alerts separately.
+Depending on the action frequency, an action occurs per alert or at the specified alert summary interval.
+
+Using the server monitoring example, each server with average CPU > 0.9 is tracked as an alert.
+This means a separate email is sent for each server that exceeds the threshold whenever the alert status changes.
+
+{/*  */}
+
+## Putting it all together
+
+A rule consists of conditions, actions, and a schedule.
+When conditions are met, alerts are created that render actions and invoke them.
+To make action setup and update easier, actions use connectors that centralize the information used to connect with ((kib)) services and third-party integrations.
+The following example ties these concepts together:
+
+
+
+1. Any time a rule's conditions are met, an alert is created. This example checks for servers with average CPU \> 0.9. Three servers meet the condition, so three alerts are created.
+1. Alerts create actions according to the action frequency, as long as they are not muted or throttled. When actions are created, its properties are filled with actual values. In this example, three actions are created when the threshold is met, and the template string `{{server}}` is replaced with the appropriate server name for each alert.
+1. ((kib)) runs the actions, sending notifications by using a third party integration like an email service.
+1. If the third party integration has connection parameters or credentials, ((kib)) fetches these from the appropriate connector.
diff --git a/serverless/pages/run-api-requests-in-the-console.mdx b/serverless/pages/run-api-requests-in-the-console.mdx
new file mode 100644
index 00000000..04425c26
--- /dev/null
+++ b/serverless/pages/run-api-requests-in-the-console.mdx
@@ -0,0 +1,162 @@
+---
+id: serverlessDevtoolsRunApiRequestsInTheConsole
+slug: /serverless/devtools/run-api-requests-in-the-console
+title: Console
+description: Use the Console to interact with Elastic REST APIs.
+tags: [ 'serverless', 'dev tools', 'how-to' ]
+---
+
+
+This content applies to:
+
+{/* TODO: This content is copied verbatim from the serverless ES docs. We need to decide whether to
+transclude this content so that we don't have to maintain to copies of identical content. */}
+
+Use **Console** to run API requests against ((es)), and view the responses.
+Console is available in your Elastic UI under **Dev Tools**.
+
+Requests are made in the left pane, and responses are displayed in the right pane.
+
+
+
+Console keeps a request history, making it easy to find and repeat requests.
+It also provides links to API documentation.
+
+## Write requests
+
+**Console** understands commands in a cURL-like syntax.
+For example, the following is a `GET` request to the ((es)) `_search` API.
+
+```js
+GET /_search
+{
+ "query": {
+ "match_all": {}
+ }
+}
+```
+
+Here is the equivalent command in cURL:
+
+```bash
+curl "${ES_URL}/_search" \
+-H "Authorization: ApiKey ${API_KEY}" \
+-H "Content-Type: application/json" \
+-d'
+{
+ "query": {
+ "match_all": {}
+ }
+}'
+```
+
+When you paste a cURL command into **Console**, it is automatically converted to **Console** syntax.
+To convert **Console** syntax into cURL syntax, select the action icon () and choose **Copy as cURL**.
+Once copied, an API key will need to be provided for the calls to work from external environments.
+
+### Autocomplete
+
+When you're typing a command, **Console** makes context-sensitive suggestions.
+These suggestions show you the parameters for each API and speed up your typing.
+To configure your preferences for autocomplete, go to [Settings](#configure-console-settings).
+
+### Comments
+
+You can write comments or temporarily disable parts of a request by using double forward slashes (`//`) or pound (`#`) signs to create single-line comments.
+
+```js
+# This request searches all of your indices.
+GET /_search
+{
+ // The query parameter indicates query context.
+ "query": {
+ "match_all": {} // Matches all documents.
+ }
+}
+```
+
+You can also use a forward slash followed by an asterisk (`/*`) to mark the beginning of multi-line
+comments.
+An asterisk followed by a forward slash (`*/`) marks the end.
+
+```js
+GET /_search
+{
+ "query": {
+ /*"match_all": {
+ "boost": 1.2
+ }*/
+ "match_none": {}
+ }
+}
+```
+### Variables
+
+Select **Variables** to create, edit, and delete variables.
+
+
+
+You can refer to these variables in the paths and bodies of your requests.
+Each variable can be referenced multiple times.
+
+```js
+GET ${pathVariable}
+{
+ "query": {
+ "match": {
+ "${bodyNameVariable}": "${bodyValueVariable}"
+ }
+ }
+}
+```
+
+### Auto-formatting
+
+The auto-formatting
+capability can help you format requests. Select one or more requests that you
+want to format, select the action icon (),
+and then select **Auto indent**.
+
+For example, you might have a request formatted like this:
+
+
+
+**Console** adjusts the JSON body of the request to apply the indents.
+
+
+
+If you select **Auto indent** on a request that is already well formatted,
+**Console** collapses the request body to a single line per document.
+This is helpful when working with the ((es)) [bulk APIs](((ref))/docs-bulk.html).
+
+## Submit requests
+
+When you're ready to submit the request to ((es)), select the green triangle.
+
+You can select multiple requests and submit them together.
+**Console** sends the requests to ((es)) one by one and shows the output
+in the response pane. Submitting multiple requests is helpful
+when you're debugging an issue or trying query
+combinations in multiple scenarios.
+
+## View API docs
+
+To view the documentation for an API endpoint, select
+the action icon () and select
+**Open documentation**.
+
+## Get your request history
+
+**Console** maintains a list of the last 500 requests that ((es)) successfully executed.
+To view your most recent requests, select **History**.
+If you select a request and select **Apply**, it is added to the editor at the current cursor position.
+
+## Configure Console settings
+
+You can configure the **Console** font size, JSON syntax, and autocomplete suggestions in **Settings**.
+
+
+
+## Get keyboard shortcuts
+
+For a list of available keyboard shortcuts, select **Help**.
diff --git a/serverless/pages/saved-objects.mdx b/serverless/pages/saved-objects.mdx
new file mode 100644
index 00000000..f1728e86
--- /dev/null
+++ b/serverless/pages/saved-objects.mdx
@@ -0,0 +1,88 @@
+---
+id: serverlessSavedObjects
+slug: /serverless/saved-objects
+title: ((saved-objects-app))
+description: Manage your saved objects, including dashboards, visualizations, maps, ((data-sources)), and more.
+tags: [ 'serverless', 'Elasticsearch', 'Observability', 'Security' ]
+---
+
+
+This content applies to:
+
+To get started, go to **((project-settings)) → ((manage-app)) → ((saved-objects-app))**:
+
+
+{/* TO-DO: This screenshot needs to be refreshed and automated. */}
+
+{/*
+TBD: Need serverless-specific RBAC requirements
+## Required permissions
+
+To access **Saved Objects**, you must have the required `Saved Objects Management` ((kib)) privilege.
+
+To add the privilege, open the main menu, and then click **Stack Management → Roles**.
+
+
+Granting access to `Saved Objects Management` authorizes users to
+manage all saved objects in ((kib)), including objects that are managed by
+applications they may not otherwise be authorized to access.
+ */}
+
+## View and delete
+
+* To view and edit a saved object in its associated application, click the object title.
+
+* To show objects that use this object, so you know the impact of deleting it, click the actions icon and then select **Relationships**.
+
+* To delete one or more objects, select their checkboxes, and then click **Delete**.
+
+## Import and export
+
+Use import and export to move objects between different ((kib)) instances.
+These actions are useful when you have multiple environments for development and production.
+Import and export also work well when you have a large number of objects to update and want to batch the process.
+
+{/*
+TBD: Do these APIs exist for serverless?
+((kib)) also provides import and
+export APIs to automate this process.
+*/}
+
+### Import
+
+Import multiple objects in a single operation.
+
+1. In the toolbar, click **Import**.
+1. Select the NDJSON file that includes the objects you want to import.
+
+1. Select the import options. By default, saved objects already in ((kib)) are overwritten.
+
+1. Click **Import**.
+
+{/*
+TBD: Are these settings configurable in serverless?
+
+The `savedObjects.maxImportExportSize` configuration setting
+limits the number of saved objects to include in the file. The
+`savedObjects.maxImportPayloadBytes` setting limits the overall
+size of the file that you can import.
+
+*/}
+
+### Export
+
+Export objects by selection or type.
+
+* To export specific objects, select them in the table, and then click **Export**.
+* To export objects by type, click **Export objects** in the toolbar.
+
+((kib)) creates an NDJSON with all your saved objects.
+By default, the NDJSON includes child objects related to the saved objects.
+Exported dashboards include their associated ((data-sources)).
+
+{/*
+TBD: Are these settings configurable in serverless?
+
+The `savedObjects.maxImportExportSize` configuration setting limits the number of saved objects that you can export.
+ */}
+
diff --git a/serverless/pages/sign-up.mdx b/serverless/pages/sign-up.mdx
new file mode 100644
index 00000000..9abc3710
--- /dev/null
+++ b/serverless/pages/sign-up.mdx
@@ -0,0 +1,23 @@
+---
+id: serverlessGeneralSignUp
+# slug: /serverless/general/sign-up
+title: Sign up
+# description: Description to be written
+tags: [ 'serverless', 'general', 'signup' ]
+---
+
+## Join Elastic Cloud
+
+ ### Add your billing details
+
+ ### Choose a tier
+
+## Subscribe from a marketplace
+
+ ### AWS Marketplace
+
+ ### Azure Marketplace
+
+ ### Azure Native ISV Service
+
+ ### GCP Marketplace
diff --git a/serverless/pages/tags.mdx b/serverless/pages/tags.mdx
new file mode 100644
index 00000000..20a23400
--- /dev/null
+++ b/serverless/pages/tags.mdx
@@ -0,0 +1,71 @@
+---
+id: serverlessTags
+slug: /serverless/tags
+title: ((tags-app))
+description: Use tags to categorize your saved objects, then filter for related objects based on shared tags.
+tags: [ 'serverless', 'Elasticsearch', 'Observability', 'Security' ]
+---
+
+
+This content applies to:
+
+To get started, go to **((project-settings)) → ((manage-app)) → ((tags-app))**:
+
+
+
+{/*
+TBD: What are the serverless RBAC requirements?
+## Required permissions
+
+To create tags, you must meet the minimum requirements.
+
+* Access to **Tags** requires the `Tag Management` Kibana privilege. To add the privilege, open the main menu,
+ and then click **Stack Management → Roles**.
+
+* The `read` privilege allows you to assign tags to the saved objects for which you have write permission.
+* The `write` privilege enables you to create, edit, and delete tags.
+
+
+Having the `Tag Management` ((kib)) privilege is not required to
+view tags assigned on objects you have `read` access to, or to filter objects by tags
+from the global search.
+
+*/}
+
+## Create a tag
+
+Create a tag to assign to your saved objects.
+
+1. Click **Create tag**.
+
+1. Enter a name and select a color for the new tag.
+
+ The name cannot be longer than 50 characters.
+
+1. Click **Create tag**.
+
+## Assign a tag to an object
+
+{/*
+TBD: Do these RBAC requirements exist in serverless?
+To assign and remove tags, you must have `write` permission on the objects to which you assign the tags.
+*/}
+
+1. Find the tag you want to assign.
+
+1. Click the actions icon and then select **Manage assignments**.
+
+1. Select the objects to which you want to assign or remove tags.
+ 
+
+1. Click **Save tag assignments**.
+
+## Delete a tag
+
+When you delete a tag, you remove it from all saved objects that use it.
+
+1. Click the actions icon, and then select **Delete**.
+
+1. Click **Delete tag**.
+
+To assign, delete, or clear multiple tags, select them in the **Tags** view, and then select the action from the **selected tags** menu.
diff --git a/serverless/pages/transforms.mdx b/serverless/pages/transforms.mdx
new file mode 100644
index 00000000..b91e93ab
--- /dev/null
+++ b/serverless/pages/transforms.mdx
@@ -0,0 +1,42 @@
+---
+id: serverlessTransforms
+slug: /serverless/transforms
+title: ((transforms-app))
+description: Use transforms to pivot existing indices into summarized or entity-centric indices.
+tags: [ 'serverless', 'Elasticsearch', 'Observability', 'Security' ]
+---
+
+
+This content applies to:
+
+((transforms-cap)) enable you to convert existing ((es)) indices into summarized
+indices, which provide opportunities for new insights and analytics.
+
+For example, you can use ((transforms)) to pivot your data into entity-centric
+indices that summarize the behavior of users or sessions or other entities in
+your data. Or you can use ((transforms)) to find the latest document among all the
+documents that have a certain unique key.
+
+For more information, check out:
+
+* [When to use transforms](((ref))/transform-usage.html)
+* [Generating alerts for transforms](((ref))/transform-alerts.html)
+* [Transforms at scale](((ref))/transform-scale.html)
+* [How checkpoints work](((ref))/transform-checkpoints.html)
+* [Examples](((ref))/transform-examples.html)
+* [Painless examples](((ref))/transform-painless-examples.html)
+* [Troubleshooting transforms](((ref))/transform-troubleshooting.html)
+* [Limitations](((ref))/transform-limitations.html)
+
+## Create and manage ((transforms))
+
+In **((project-settings)) → ((manage-app)) → ((transforms-app))**, you can
+create, edit, stop, start, reset, and delete ((transforms)):
+
+
+
+When you create a ((transform)), you must choose between two types: _pivot_ and _latest_.
+You must also decide whether you want the ((transform)) to run once or continuously.
+For more information, go to [((transforms-cap)) overview](((ref))/transform-overview.html).
+
+{/* To stop, start, or delete multiple ((transforms)), select their checkboxes then click.... */}
\ No newline at end of file
diff --git a/serverless/pages/user-profile.mdx b/serverless/pages/user-profile.mdx
new file mode 100644
index 00000000..2cc777c1
--- /dev/null
+++ b/serverless/pages/user-profile.mdx
@@ -0,0 +1,54 @@
+---
+id: serverlessGeneralUserProfile
+slug: /serverless/general/user-profile
+title: Update your user profile
+description: Manage your profile settings.
+tags: [ 'serverless', 'general', 'profile', 'update' ]
+---
+
+
+To edit your user profile, go to the user icon on the header bar and select **Profile**.
+
+## Update your email address
+
+Your email address is used to sign in. If needed, you can change this email address.
+1. In the **Profile** section, by **Email address**, select **Edit**.
+
+1. Enter a new email address and your current password.
+
+ An email is sent to the new address with a link to confirm the change. If you don't get the email after a few minutes, check your spam folder.
+
+## Change your password
+
+When you signed up with your email address, you selected a password that you use to log in to the Elastic Cloud console. If needed, you can change this password.
+
+If you know your current password:
+
+1. Navigate to the **Password** section and select **Change password**.
+
+1. Enter the current password and provide the new password that you want to use.
+
+If you don't know your current password:
+
+1. At the login screen for the Elastic Cloud console, select the link **Forgot password?**
+
+1. Enter the email address for your account and select **Reset password**.
+
+ An email is sent to the address you specified with a link to reset the password. If you don't get the email after a few minutes, check your spam folder.
+
+## Enable multi-factor authentication
+
+To add an extra layer of security, you can either set up Google authenticator or text messaging on a mobile device.
+
+
+Before you start using multi-factor authentication, verify that your device has SMS capabilities or download the Google Authenticator application onto your device.
+
+
+To enable multi-factor authentication, you must enroll your device.
+
+1. Navigate to the **Multi-factor authentication** section.
+
+1. Select **Configure** to enable the Authenticator app or **Add a phone number** to enable the Text message.
+
+If the device you want to remove is your only enrolled device, you must disable multi-factor authentication first. If your device is lost or stolen, contact [support](https://support.elastic.co/).
+
diff --git a/serverless/pages/visualize-library.mdx b/serverless/pages/visualize-library.mdx
new file mode 100644
index 00000000..2d93f525
--- /dev/null
+++ b/serverless/pages/visualize-library.mdx
@@ -0,0 +1,25 @@
+---
+id: serverlessVisualizeLibrary
+slug: /serverless/visualize-library
+title: Visualize Library
+#description: Add description here.
+tags: [ 'serverless', 'Elasticsearch', 'Observability', 'Security' ]
+---
+
+{/* TODO: Figure out best way to deal with inconsistent location of these capabilities in different solutions.
+This content has been removed from the navigation for now because it's not useful in its current state.*/}
+
+This content applies to:
+
+The **Visualize Library** is a space where you can save visualization panels that you may want to use across multiple dashboards. The **Visualize Library** consists of two pages:
+
+* **Visualizations**
+* **Annotation groups**
+
+## Visualizations
+
+By default the **Visualizations** page opens first. Here you can create new visualizations, or select from a list of previously created visualizations. To learn more, refer to save to the Visualize Library.
+
+## Annotation groups
+
+**Annotation groups** give you the option to mark points on a visualization panel with events, such as a deployment, to help track performance. These annotations can be reused across multiple visualization panels.
\ No newline at end of file
diff --git a/serverless/pages/welcome-to-serverless.mdx b/serverless/pages/welcome-to-serverless.mdx
new file mode 100644
index 00000000..2ce163bc
--- /dev/null
+++ b/serverless/pages/welcome-to-serverless.mdx
@@ -0,0 +1,83 @@
+---
+id: serverlessGeneralWelcomeToServerless
+slug: /serverless
+title: Welcome to Elastic serverless
+tags: ['serverless']
+layout: landing
+---
+
+# Elastic serverless documentation
+
+Elastic serverless products allow you to deploy and use Elastic for your use cases without managing the underlying Elastic cluster,
+such as nodes, data tiers, and scaling. Serverless instances are fully-managed, autoscaled, and automatically upgraded by Elastic so you can
+focus more on gaining value and insight from your data.
+
+Elastic provides three serverless solutions available on ((ecloud)):
+
+- **((es))** — Build powerful applications and search experiences using a rich ecosystem of vector search capabilities, APIs, and libraries.
+- **Elastic ((observability))** — Monitor your own platforms and services using powerful machine learning and analytics tools with your logs, metrics, traces, and APM data.
+- **Elastic ((security))** — Detect, investigate, and respond to threats, with SIEM, endpoint protection, and AI-powered analytics capabilities.
+
+Serverless instances of the Elastic Stack that you create in ((ecloud)) are called **serverless projects**.
+
+Elastic serverless products are currently in preview. [Learn more about serverless in our blog](https://www.elastic.co/blog/elastic-serverless-architecture).
+
+
+
+## Get started
+
+Choose the type of project that matches your needs and we’ll help you get started with our solution guides.
+
+
+
+
diff --git a/serverless/pages/what-is-serverless.mdx b/serverless/pages/what-is-serverless.mdx
new file mode 100644
index 00000000..effdf351
--- /dev/null
+++ b/serverless/pages/what-is-serverless.mdx
@@ -0,0 +1,94 @@
+---
+id: whatIsServerlessElastic
+slug: /serverless/general/what-is-serverless-elastic
+title: What is serverless Elastic?
+tags: ['serverless']
+---
+
+Serverless projects use the core components of the ((stack)), such as ((es)) and ((kib)), and are based on [an architecture that
+decouples compute and storage](https://www.elastic.co/blog/elastic-serverless-architecture). Search and indexing operations are separated, which offers high flexibility for scaling your workloads while ensuring
+a high level of performance.
+
+**Management free.** Elastic manages the underlying Elastic cluster, so you can focus on your data. With serverless projects, Elastic is responsible for automatic upgrades, data backups,
+and business continuity.
+
+**Autoscaled.** To meet your performance requirements, the system automatically adjusts to your workloads. For example, when you have a short time spike on the
+data you ingest, more resources are allocated for that period of time. When the spike is over, the system uses less resources, without any action
+on your end.
+
+**Optimized data storage.** Your data is stored in the Search Data Lake of your project, which serves as a cost-efficient and performant storage.
+A high performance cache layer is available on top of the Search Data Lake for your most queried data. The size of the cache depends on performance settings
+that you configure for each project.
+
+**Dedicated experiences.** Each serverless solution includes navigation and functionality that helps you focus on your data, goals, and use cases.
+
+**Pay per usage.** Each serverless project type includes product-specific and usage-based pricing.
+
+
+
+# Control your data and performance
+
+Control your project data and query performance against your project data.
+
+**Data.** Choose the data you want to ingest, and the method to ingest it. By default, data is stored indefinitely in your project,
+and you define the retention settings for your data streams.
+
+**Performance.** For granular control over query performance against your project data, serverless projects include the following settings:
+
+
+
+ - **Search Power** — Control the search speed for your project data.
+ When ingested, a certain amount of data is loaded into a cache to increase query performance.
+ With Search Power, you can add replicas or reduce the amount of cached data by a static factor to increase search performance.
+
+ - **Search Boost Window** — Determine the amount of data that benefits from faster search.
+ The system dynamically adjusts the cache allocated to your project based on how much data you ingest during a specified period of time.
+
+# Differences between serverless projects and hosted deployments on ((ecloud))
+
+You can run [hosted deployments](https://www.elastic.co/guide/en/cloud/current/ec-getting-started.html) of the ((stack)) on ((ecloud)). These hosted deployments provide more provisioning and advanced configuration options.
+
+| Option | Serverless | Hosted |
+|------------------------|:----------------------------------------------------------|:----------------------------------------------------------------------------------|
+| **Cluster management** | Fully managed by Elastic. | You provision and manage your hosted clusters. Shared responsibility with Elastic.|
+| **Scaling** | Autoscales out of the box. | Manual scaling or autoscaling available for you to enable. |
+| **Upgrades** | Automatically performed by Elastic. | You choose when to upgrade. |
+| **Pricing** | Individual per project type and based on your usage. | Based on deployment size and subscription level. |
+| **Performance** | Autoscales based on your usage. | Manual scaling. |
+| **Solutions** | Single solution per project. | Full Elastic Stack per deployment. |
+| **User management** | Elastic Cloud-managed users. | Elastic Cloud-managed users and native Kibana users. |
+| **API support** | Subset of [APIs](https://docs.elastic.co/api-reference). | All Elastic APIs. |
+| **Backups** | Projects automatically backed up by Elastic. | Your responsibility with Snapshot & Restore. |
+| **Data retention** | | Index Lifecycle Management. |
+
+# Answers to common serverless questions
+
+**What Support is available for the serverless preview?**
+
+There is no official SLA for Support in Serverless until General Availability (GA). We’ll do our best to service customers and inquiries as we would any pre-GA product - at a Platinum/Enterprise Severity 3 (1 business day) SLA target.
+
+**Is there migration support between ESS and serverless, and serverless and ESS?**
+
+Migration paths between ESS and serverless, and serverless and ESS are currently unsupported.
+
+**How does serverless ensure compatibility between software versions?**
+
+Connections and configurations are unaffected by upgrades. To ensure compatibility between software versions, quality testing and API versioning are used.
+
+**Can I convert a serverless project into a hosted deployment, or a hosted deployment into a serverless project?**
+
+Projects and deployments are based on different architectures, and you are unable to convert.
+
+**Can I convert a serverless project into a project of a different type?**
+
+You are unable to convert projects into different project types, but you can create as many projects as you’d like. You will be charged only for your usage.
+
+**How can I create serverless service accounts?**
+
+Create API keys for service accounts in your serverless projects. Options to automate the creation of API keys with tools such as Terraform will be available in the future.
+
+To raise a Support case with Elastic, raise a case for your subscription the same way you do today. In the body of the case, make sure to mention you are working in serverless to ensure we can provide the appropriate support.
+
+**When will pricing information be available for serverless?**
+
+Pricing will be available through account representatives and published at a later date.