模型分为两类:概念模型,逻辑模型和物理模型
唯一标识实体的的属性集称为码
数据库的三级模式:外模式,模式,内模式
模式:逻辑模式是数据库中全体数据的逻辑结构和特征的描述
外模式:子模式或用户模式,数据库用户能够看见和使用的局部数据的逻辑结构和特征的描述,是数据库用户的数据视图与某一应用有关的数据的逻辑表示。
内模式:储存模式,一个数据库只有一个内模式。它是数据物理结构和存储方式的描述,是数据在数据库内部的组织方式。
逻辑模型:层次模型,网状模型,关系模型,面对对象数据模型,对象关系数据模型,半结构化数据模型。
元组是关系数据库中的基本概念,关系是一张表,表中的每行(即数据库中的每条记录)就是一个元组,每列就是一个属性。 在二维表里,元组也称为记录。
定义:
- 域:是一组具有相同数据类型的值的集合。
- 笛卡尔积
- 关系
- 主码,非主属性,非码属性
基本关系的六条性质:
- 列是同质的。
- 不同的列可出自同一个域,称其中的每一个列为一个属性,不同的属性要给予不同的属性名。
- 列的顺序无所谓,即列的次序可以任意交换。
- 任意两个元组的候选码不能取相同的值。
- 行的顺序无所谓,即行关系的次序可以任意交换。
- 分量必须取原子值,即每一个分量都必须是不可分的数据项。
关系完整性:实体完整性,参照完整性。
实体完整性:若A是基本关系R的主属性,则A不可以取空值。
关系运算:选择,投影,连接,除运算等。
选择:从表中某个属性之中选择出特定的部分或者个体(行)
投影:从属性列中罗列出不重复的选项(列)
连接:将表连接起来,就是高级版的笛卡儿积,等值连接就是把有共同属性且相等的拉出来,自然连接就是在自然连接的基础上把其中重复的属性再去掉,非等值连接就是按照其中的规定连接起来(行,列)
除:类似做成两个字典,一个字典的值对应另一个字典的键值,如果能够在第一个字典中找到相应的键值,那么就把第一个字典的键值罗列出来(行,列)
模式分为三级模式结构。外模式包括若干视图和部分基本表,数据库模式包括若干基本表,内模式包括若干存储文件。
schema可以理解为命名空间,与database处于同一级别。 create schema 模式名字 authorization 用户名字 (定义) drop schema 模式名字
create table 表名字(表的具体定义)
drop table 表名字
alter table 表名字
add column 数据类型 完整性约束
add 表级完整性约束
drop column 列名
drop constraint 完整性约束名 restrict|cascade
alter column 列名 数据类型mysql改变表的结构: alter table 名字 change 列 列 属性
删除基本表
drop table 表名 restrict|cascade前者有限制条件,不能有视图,触发器,不能有存储过程或函数,有则不能删除 后者没有限制条件,如果有,则全部删除。
建立索引可以加快查询速度。B+树索引,散列索引,位图索引
create unique cluster index 索引名 on 表名(列名 次序……)次序指的是desc降序,asc升序
删除索引 drop index on tableName
修改索引 alter index rename to 表名经测试在mysql貌似不支持对索引的修改,索引应该及时地repaire或者删除重新建立
数据库查询
select all|distinct 目标列(目标列表达式)
from 表名或者视图名 (select 语句 as 别名)
where 条件表达式
group by 列名 having 条件表达式
order by 列名 asc|desc字符匹配 谓词like’匹配串‘ 通配符 _ 代表单个任意字符 % 代表任意长度(可以为0)的字符串 当选择为空的时候,必须使用is而不能使用=
聚集函数 count(*) count(列名) sum,avg,max,min 注意:where子句中是不能用聚集函数作为条件表达式的,聚集函数只能用于select 子句和group by中的having子句中。
连接查询 等值连接查询,自然连接查询,非等值连接查询,自身连接查询,外连接查询,复合条件连接查询 那目标列中的重复的属性去掉为自然连接 将一个表取别名,则为自身连接 外连接则为,将两者相同的属性进行连接,没有的属性用NULL补全。左连接则保留左边关系,右连接保留右边关系。 查询可加入exist 和 not exist进行限制,只关心内层查询是否有返回值
集合查询 并,交,差 union将查询结果进行合并的时候,自动去掉重复元素。如果保留重复元素,使用union all。 Intersect:对两个结果集进行交集操作,不包括重复行,同时进行默认规则的排序; Minus:对两个结果集进行差操作,不包括重复行,同时进行默认规则的排序。
插入子查询
insert into 表名 属性 子查询
修改数据
update 表名
set 列名 = 表达式名
where 条件表达式删除数据
delete
from 表名
where 条件表达式视图
create view 视图名 (列名……){这里的列名可以选择,起不起别名}
as
子查询
with check option
检查表示对视图进行update,insert,delete操作的时候要保证更新、插入或者删除
视图在msql显示在table中,但是删除的时候必须删除view而不可以删除table
删除视图 drop view 视图名 (cascade) 级联删除可以将该视图和它导出的视图都删除
更新视图 由于视图是不存在的虚表,所以对视图的更新最终都会转化为对基本表的更新。
规定:
- 若视图是由两个以上的基本表导出的,则此视图不允许更新
- 若视图的字段来自字段表达式或常熟,则不允许对此视图进行insert和update操作,但允许进行delete操作
- 若视图的字段来自聚集函数,则此视图不允许更新
- 若视图定义中含有group by子句,则此视图不允许更新
- 若视图定义中含有distinct短语,则此视图不允许更新
- 若视图定义中有嵌套查询,并且内层查询的from子句中涉及的表也是导出该视图的基本表,则此视图不允许更新。
- 一个不允许更新的视图上定义的视图也不允许更新 视图的作用
- 视图可以简化用户的操作
- 视图使用户能以多种角度看待同一数据
- 视图对重构数据库提供了一定程度的逻辑独立性
- 视图能够对机密数据提供安全保护
- 适当利用视图可以更清晰地表达查询
授权
grant 权限
on 对象类型 对象名
to 用户
【with grant option】 如果指定了最后一句,则获得该权限的用户还可以把这种权限再授予其他用户。
不允许循环授予权限
收回权限
revoke 权限
on 对象类型 对象名
from 用户创建用户 create user ’名字‘@’主机‘ identified by '密码' 删除用户 drop user ’名字‘@’主机‘
定义实体完整性:即定义主码,分为列级定义主码,表级定义主码
定义参照完整性:即定义外码
约束条件:1. 不允许取空值 2. 列值唯一 3. 用check短语指定列值应该满足的条件
断言:
create assertion 断言名 check子句
断言创建以后,任何对断言中所涉及关系的操作都会触发关系数据库管理系统对断言的检查,任何使断言不为真值的操作都会被拒绝执行。
创建存储过程
CREATE PROCEDURE sp_name ([ proc_parameter ]) [ characteristics..] routine_body
proc_parameter指定存储过程的参数列表,列表形式如下:
[IN|OUT|INOUT] param_name type其中in表示输入参数,out表示输出参数,inout表示既可以输入也可以输出;param_name表示参数名称;type表示参数的类型
该类型可以是MYSQL数据库中的任意类型
触发器
CREATE TRIGGER trigger_name trigger_time trigger_event
ON tbl_name FOR EACH ROW trigger_stmt
begin
…………
end其中after指动作发生之后在进行操作,而before指的是动作发生之前进行的操作。
before失败,不会触发触发器的效果,after失败的话,会进行事务回滚。
分为行级和语句级触发器,语句级为for each statement(MYSQL不允许语句级的触发器)
数据依赖是一个关系内部属性与属性之间的一种约束关系。是通过属性之间的值的相等与否体现出来的数据间的相关联系。最重要的为函数依赖和多值依赖
平凡的函数依赖是必然成立的。
x称为决定因素。
如果$X \rightarrow Y$,并且对于x的任何一个真子集x',都有$X'\nrightarrow Y$,则y对x完全函数依赖,记做 $ X\stackrel{F}{\longrightarrow} Y$
如果$X\rightarrow Y$ ,但Y不完全函数依赖于X,则称Y对于X部分函数依赖,记做$X\stackrel{P}{\longrightarrow} Y$
传递函数依赖中,$X\nrightarrow Y$是为了不要变成直接函数依赖。
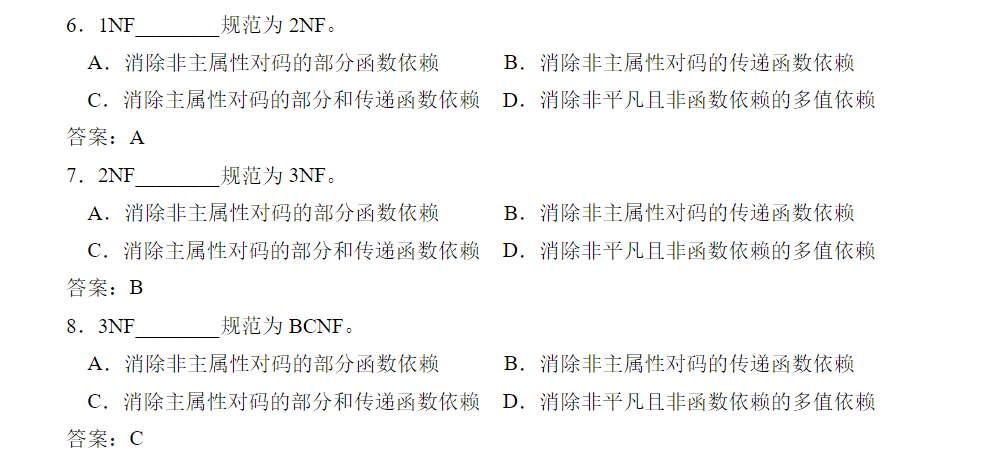
范式 :关系数据库中的关系是要满足一定要求的,满足不同程度要求的为不同范式。
2NF: 若$R\in 1NF$ ,且每一个非主属性完全函数依赖于任何一个候选码,则$R\in 2NF$
3NF: 每一个非主属性既不传递依赖于码,也不部分依赖于码。
BCNF:每一个决定因素都包含码。
所有非主属性对每一个码都是完全函数依赖
所有主属性对每一个不包含它的码也是完全函数依赖
没有任何属性完全函数依赖于非码的任何一组属性
注意: 这里指的都是非主属性
3NF——只消除非主属性对主属性的传递依赖; BCNF——消除所有属性对主属性的传递依赖。
函数依赖就像是函数一样,自变量唯一确定值;多值依赖则不一样,自变量可能决定多个值。
多值依赖的性质:
- 多值依赖具有对称性
- 多值依赖具有传递性
- 函数依赖可以看作是多值依赖的特殊情况
- 若$X\rightarrow \rightarrow Y$ ,$X\rightarrow \rightarrow Z$ ,则$X\rightarrow \rightarrow YZ$
- 若$X\rightarrow \rightarrow Y$,$X\rightarrow \rightarrow Y$,则$X\rightarrow \rightarrow Y\cap Z$
- 若$X\rightarrow \rightarrow Y$,$X\rightarrow \rightarrow Z$,则$X\rightarrow \rightarrow Y-Z$,$X\rightarrow \rightarrow Z-Y$
函数依赖与多值依赖的区别:
- 多值依赖是元组产生依赖,函数依赖是相等产生依赖。
- 多值依赖的有效性与属性集的范围有关,而函数依赖的有效性则与属性集的范围无关。
若X$\rightarrow$Y在R(U)上成立,则对于$\forall$Y′$\subseteq$Y,X$\rightarrow$Y′均成立。而若X$\rightarrow$$\rightarrow$Y在R(U)上成立,则不能断言对于Y′$\subseteq$Y,有X$\rightarrow$$\rightarrow$Y ′成立。(即函数依赖是相等依赖,多值依赖是元组产生依赖)
在多值依赖的范围内,属于4NF的关系模式已达到了最高的规范化程度
(!!!前提为简单的二元分解)R2<U2 , F2>是具有无损连接性的分解的充分必要条件是:(U1∩U2$\rightarrow$U1-U2)$\in F^+$或者(U1∩U2$\rightarrow$U2-U1)$\in F^+$,除此以外还可以使用表格法来判断是否是无损连接。
模式分解的若干结论:
- 分解具有无损连接性和分解保持函数依赖是两个互相独立的标准。具有无损连接性的分解不一定保持函数依赖,保持函数依赖的分解不一定具有无损连接性。一个关系模式的分解可能有三种情况
- 若要求分解具有无损连接性,那么分解后的模式一定能达到BCNF
- 若要求分解保持函数依赖,那么分解后的模式总可以达到3NF,但不一定能达到BCNF
- 若要求分解既具有无损连接性,又保持函数依赖,则分解后的模式可以达到3NF,但不一定能达到BCNF
求解最小函数依赖集分三步:
- 将F中的所有依赖右边化为单一元素
- 去掉F中的所有依赖左边的冗余属性.
- 去掉F中所有冗余依赖关系.
闭包的运算过程:
- 设最终将成为闭包的属性集是Y,把Y初始化为X
- 检查F中的每一个函数依赖A→B,如果属性集A中所有属性均在Y中,而B中有的属性不在Y中,则将其加入到Y中
- 重复第二步,直到没有属性可以添加到属性集Y中为止。 最后得到的Y就是X+
ER图规定:
- 实体型用矩形表示
- 属性用椭圆形表示
- 联系用菱形表示
ER图转化为关系模型:
- 一个1:1联系可以转化为一个独立的关系模型,也可以与任意一端对应的关系模型合并
- 一个1:n联系可以转化为一个独立的关系模型,也可以与n端对应的关系模型合并
- 一个m:n联系转换为一个关系模型,与该联系相连的各实体的码以及联系本身的属性均转换为关系的属性,各实体的码组成关系的码或关系码的一部分
- 三个或三个以上实体间的一个多元联系可以转换为一个关系模式
- 具有相同码的关系模式可以合并
疑问:
- 大前提为多个表,如果触发器定义完之后,往里面插入信息的时候,会破坏触发器,怎么办?