本文属于新闻推荐实战—数据层—构建物料池之MongoDB。MongoDB数据库在该项目中会用来存储画像数据(用户画像、新闻画像),使用MongoDB存储画像的一个主要原因就是方便扩展,因为画像内容可能会随着产品的不断发展而不断的更新。作为算法工程师需要了解常用的MongoDB语法(比如增删改查,排序等),因为在实际的工作可能会从MongoDB中获取用户、新闻画像来构造相关特征。本着这个目的,本文对MongoDB常见的语法及Python操作MongoDB进行了总结,方便大家快速了解。
MongoDB 是由C++语言编写的,是一个基于分布式文件存储的开源数据库系统。在高负载的情况下,添加更多的节点,可以保证服务器性能。MongoDB 旨在为WEB应用提供可扩展的高性能数据存储解决方案。
MongoDB 将数据存储为一个文档,数据结构由键值(key=>value)对组成。MongoDB 文档类似于 JSON 对象。字段值可以包含其他文档,数组及文档数组。
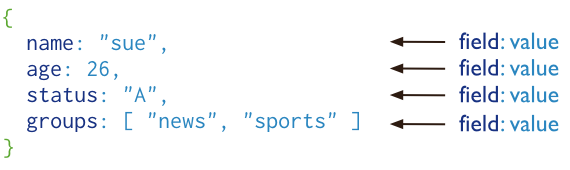
- MongoDB 是一个面向文档存储的数据库,操作起来比较简单和容易。
- 你可以在MongoDB记录中设置任何属性的索引 (如:FirstName="Sameer",Address="8 Gandhi Road")来实现更快的排序。
- 你可以通过本地或者网络创建数据镜像,这使得MongoDB有更强的扩展性。
- 如果负载的增加(需要更多的存储空间和更强的处理能力) ,它可以分布在计算机网络中的其他节点上这就是所谓的分片。
- Mongo支持丰富的查询表达式。查询指令使用JSON形式的标记,可轻易查询文档中内嵌的对象及数组。
- MongoDb 使用update()命令可以实现替换完成的文档(数据)或者一些指定的数据字段 。
- Mongodb中的Map/reduce主要是用来对数据进行批量处理和聚合操作。
- Map和Reduce。Map函数调用emit(key,value)遍历集合中所有的记录,将key与value传给Reduce函数进行处理。
- Map函数和Reduce函数是使用Javascript编写的,并可以通过db.runCommand或mapreduce命令来执行MapReduce操作。
- GridFS是MongoDB中的一个内置功能,可以用于存放大量小文件。
- MongoDB允许在服务端执行脚本,可以用Javascript编写某个函数,直接在服务端执行,也可以把函数的定义存储在服务端,下次直接调用即可。
- MongoDB支持各种编程语言:RUBY,PYTHON,JAVA,C++,PHP,C#等多种语言。
- MongoDB安装简单
MongoDB 提供了 linux 各个发行版本 64 位的安装包,你可以在官网下载安装包。
MongoDB 源码下载地址:https://www.mongodb.com/download-center#community
安装前我们需要安装各个 Linux 平台依赖包。
Red Hat/CentOS:
sudo yum install libcurl opensslUbuntu 18.04 LTS ("Bionic")/Debian 10 "Buster":
sudo apt-get install libcurl4 opensslUbuntu 16.04 LTS ("Xenial")/Debian 9 "Stretch":
sudo apt-get install libcurl3 openssl查看ubuntu的版本
lsb_release -a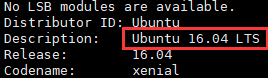
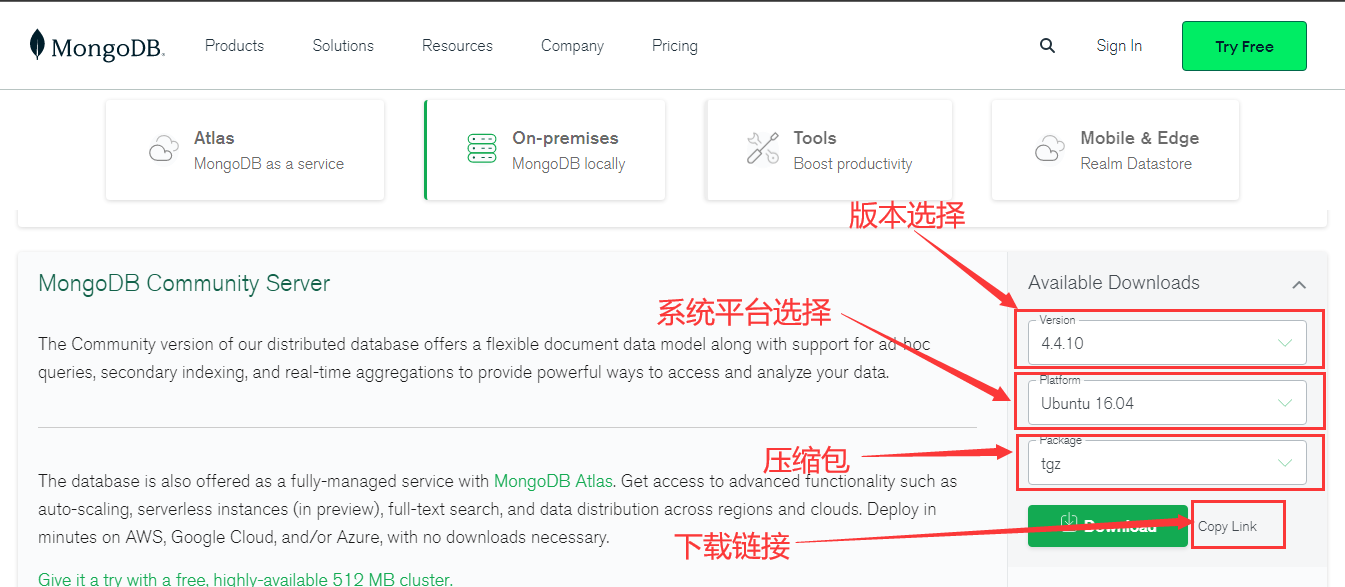
这里我们选择 tgz 下载,下载完安装包,并解压 tgz(以下演示的是 64 位 Linux上的安装) 。
wget https://fastdl.mongodb.org/linux/mongodb-linux-x86_64-ubuntu1604-4.4.10.tgz #下载
tar -zxvf mongodb-linux-x86_64-ubuntu1604-4.4.10.tgz #解压MongoDB 的可执行文件位于 bin 目录下,所以可以将其添加到 PATH 路径中
export PATH=<mongodb-install-directory>/bin:$PATH****为你 MongoDB 的安装路径。
默认情况下 MongoDB 启动后会初始化以下两个目录:
- 数据存储目录:/var/lib/mongodb
- 日志文件目录:/var/log/mongodb
我们在启动前可以先创建这两个目录:
sudo mkdir -p /var/lib/mongo
sudo mkdir -p /var/log/mongodb接下来启动 Mongodb 服务:
mongod --dbpath /var/lib/mongo --logpath /var/log/mongodb/mongod.log --fork如果你需要进入 mongodb 后台管理,由于已经将MongoDB可执行文件添加到PATH路径,所以可以直接执行 mongo 命令文件。
MongoDB Shell 是 MongoDB 自带的交互式 Javascript shell,用来对 MongoDB 进行操作和管理的交互式环境。
当你进入 mongoDB 后台后,它默认会链接到 test 文档(数据库):

在mongodb中基本的概念是文档、集合、数据库。下表将帮助您更容易理解Mongo中的一些概念:
| SQL术语/概念 | MongoDB术语/概念 | 解释/说明 |
|---|---|---|
| database | database | 数据库 |
| table | collection | 数据库表/集合 |
| row | document | 数据记录行/文档 |
| column | field | 数据字段/域 |
| index | index | 索引 |
| table joins | 表连接,MongoDB不支持 | |
| primary key | primary key | 主键,MongoDB自动将_id字段设置为主键 |
一个mongodb中可以建立多个数据库。
MongoDB的默认数据库为"db",该数据库存储在data目录中。
MongoDB的单个实例可以容纳多个独立的数据库,每一个都有自己的集合和权限,不同的数据库也放置在不同的文件中。
"show dbs" 命令可以显示所有数据的列表。
toby@recsys:~$ mongo
MongoDB shell version: 2.6.10
connecting to: test
> show dbs
admin (empty)
local 0.078GB执行 "db" 命令可以显示当前数据库对象或集合。
toby@recsys:~$ mongo
MongoDB shell version: 2.6.10
connecting to: test
> db
test运行"use"命令,可以连接到一个指定的数据库。
toby@recsys:~$ mongo
MongoDB shell version: 2.6.10
connecting to: test
> use admin
switched to db admin
> db
admin
> MongoDB 创建数据库的语法格式如下:
use DATABASE_NAME如果数据库不存在,则创建数据库,否则切换到指定数据库。
以下实例我们创建了数据库 tobytest:
toby@recsys:~$ mongo
MongoDB shell version: 2.6.10
connecting to: test
> use tobytest
switched to db tobytest
> db
tobytest
> 如果你想查看所有数据库,可以使用 show dbs 命令:
> show dbs
admin (empty)
local 0.078GB
> 可以看到,我们刚创建的数据库 tobytest并不在数据库的列表中, 要显示它,我们需要向 tobytest数据库插入一些数据。
> db.tobytest.insert({"name":"Toby"})
WriteResult({ "nInserted" : 1 })
> show dbs
admin (empty)
local 0.078GB
tobytest 0.078GB
> MongoDB 中默认的数据库为 test,如果你没有创建新的数据库,集合将存放在 test 数据库中。
注意: 在 MongoDB 中,集合只有在内容插入后才会创建! 就是说,创建集合(数据表)后要再插入一个文档(记录),集合才会真正创建。
MongoDB 中使用 createCollection() 方法来创建集合。
语法格式:
db.createCollection(name, options)参数说明:
- name: 要创建的集合名称
- options: 可选参数, 指定有关内存大小及索引的选项
options 可以是如下参数:
| 字段 | 类型 | 描述 |
|---|---|---|
| capped | 布尔 | (可选)如果为 true,则创建固定集合。固定集合是指有着固定大小的集合,当达到最大值时,它会自动覆盖最早的文档。 当该值为 true 时,必须指定 size 参数。 |
| autoIndexId | 布尔 | 3.2 之后不再支持该参数。(可选)如为 true,自动在 _id 字段创建索引。默认为 false。 |
| size | 数值 | (可选)为固定集合指定一个最大值,即字节数。 如果 capped 为 true,也需要指定该字段。 |
| max | 数值 | (可选)指定固定集合中包含文档的最大数量。 |
在插入文档时,MongoDB 首先检查固定集合的 size 字段,然后检查 max 字段。
在 tobytest 数据库中创建 runoob 集合:
> use tobytest
switched to db tobytest
> db.createCollection("tobycollection")
{ "ok" : 1 }
> 如果要查看已有集合,可以使用 show collections 或 show tables 命令:
> show tables
system.indexes
tobycollection
tobytest
> MongoDB 中使用 drop() 方法来删除集合。
语法格式:
db.collection.drop()参数说明:
- 无
返回值
如果成功删除选定集合,则 drop() 方法返回 true,否则返回 false。
在数据库 tobytest中,我们可以先通过 show collections 命令查看已存在的集合:
> use tobytest
switched to db tobytest
> show collections
system.indexes
tobycollection
tobytest
> 接着删除集合 tobycollection:
> db.tobycollection.drop()
true
> 通过 show collections 再次查看数据库 tobytest中的集合:
> show collections
system.indexes
tobytest
> 从结果中可以看出 tobycollection集合已被删除。
文档的数据结构和 JSON 基本一样。
所有存储在集合中的数据都是 BSON 格式。
BSON 是一种类似 JSON 的二进制形式的存储格式,是 Binary JSON 的简称。
MongoDB 使用 insert() 或 save() 方法向集合中插入文档,语法如下:
db.COLLECTION_NAME.insert(document)
或
db.COLLECTION_NAME.save(document)- save():如果 _id 主键存在则更新数据,如果不存在就插入数据。该方法新版本中已废弃,可以使用 db.collection.insertOne() 或 db.collection.replaceOne() 来代替。
- insert(): 若插入的数据主键已经存在,则会抛 org.springframework.dao.DuplicateKeyException 异常,提示主键重复,不保存当前数据。
以下文档可以存储在 MongoDB 的 tobytest 数据库 的 col 集合中:
> db.col.insert({title:'Toby MongoDB',
... description:'this is MongoDB',
... tags:['mongodb','database','NoSQL'],
... likes:1
... })
WriteResult({ "nInserted" : 1 })
> 以上实例中 col 是我们的集合名,如果该集合不在该数据库中, MongoDB 会自动创建该集合并插入文档。
查看已插入文档:
> db.col.find()
{ "_id" : ObjectId("617970fc286e9ff2b1250d70"), "title" : "Toby MongoDB", "description" : "this is MongoDB", "tags" : [ "mongodb", "database", "NoSQL" ], "likes" : 1 }
> 我们也可以将数据定义为一个变量,如下所示:
> document=({title:'Toby another MongoDB',
... description:'this is another MongoDB',
... tags:['mongodb','database','NoSQL'],
... likes:2
... })执行后显示结果如下:
{
"title" : "Toby another MongoDB",
"description" : "this is another MongoDB",
"tags" : [
"mongodb",
"database",
"NoSQL"
],
"likes" : 2
}执行插入操作:
> db.col.insert(document)
WriteResult({ "nInserted" : 1 })
> db.col.find()
{ "_id" : ObjectId("617970fc286e9ff2b1250d70"), "title" : "Toby MongoDB", "description" : "this is MongoDB", "tags" : [ "mongodb", "database", "NoSQL" ], "likes" : 1 }
{ "_id" : ObjectId("61797229286e9ff2b1250d71"), "title" : "Toby another MongoDB", "description" : "this is another MongoDB", "tags" : [ "mongodb", "database", "NoSQL" ], "likes" : 2 }
> MongoDB 使用 update() 和 save() 方法来更新集合中的文档。接下来让我们详细来看下两个函数的应用及其区别。
update() 方法用于更新已存在的文档。语法格式如下:
db.collection.update(
<query>,
<update>,
{
upsert: <boolean>,
multi: <boolean>,
writeConcern: <document>
}
)参数说明:
- query : update的查询条件,类似sql update查询内where后面的。
- update : update的对象和一些更新的操作符(如$,$inc...)等,也可以理解为sql update查询内set后面的
- upsert : 可选,这个参数的意思是,如果不存在update的记录,是否插入objNew,true为插入,默认是false,不插入。
- multi : 可选,mongodb 默认是false,只更新找到的第一条记录,如果这个参数为true,就把按条件查出来多条记录全部更新。
- writeConcern :可选,抛出异常的级别。
我们在集合 col 中插入如下数据:
> db.col.insert({title:'Toby MongoDB',
... description:'this is MongoDB',
... tags:['mongodb','database','NoSQL'],
... likes:1
... })
WriteResult({ "nInserted" : 1 })
> 接着我们通过 update() 方法来更新标题(title):
> db.col.update({'title':'Toby MongoDB'},{$set:{'title':'MongoDB'}})
WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
> db.col.find().pretty()
{
"_id" : ObjectId("617970fc286e9ff2b1250d70"),
"title" : "MongoDB",
"description" : "this is MongoDB",
"tags" : [
"mongodb",
"database",
"NoSQL"
],
"likes" : 1
}
{
"_id" : ObjectId("61797229286e9ff2b1250d71"),
"title" : "Toby another MongoDB",
"description" : "this is another MongoDB",
"tags" : [
"mongodb",
"database",
"NoSQL"
],
"likes" : 2
}
> 可以看到标题(title)由原来的 "Toby MongoDB" 更新为了 "MongoDB"。
MongoDB remove() 函数是用来移除集合中的数据。
MongoDB 数据更新可以使用 update() 函数。在执行 remove() 函数前先执行 find() 命令来判断执行的条件是否正确,这是一个比较好的习惯。
remove() 方法的基本语法格式如下所示:
db.collection.remove(
<query>,
<justOne>
)如果你的 MongoDB 是 2.6 版本以后的,语法格式如下:
db.collection.remove(
<query>,
{
justOne: <boolean>,
writeConcern: <document>
}
)参数说明:
- query :(可选)删除的文档的条件。
- justOne : (可选)如果设为 true 或 1,则只删除一个文档,如果不设置该参数,或使用默认值 false,则删除所有匹配条件的文档。
- writeConcern :(可选)抛出异常的级别。
以下文档我们执行两次插入操作:
> db.col.insert({title:'Toby MongoDB', description:'this is MongoDB', tags:['mongodb','database','NoSQL'], likes:1 })
WriteResult({ "nInserted" : 1 })
> db.col.insert({title:'Toby MongoDB', description:'this is MongoDB', tags:['mongodb','database','NoSQL'], likes:1 })
WriteResult({ "nInserted" : 1 })
> 使用 find() 函数查询数据:
> db.col.find()
{ "_id" : ObjectId("617970fc286e9ff2b1250d70"), "title" : "MongoDB", "description" : "this is MongoDB", "tags" : [ "mongodb", "database", "NoSQL" ], "likes" : 1 }
{ "_id" : ObjectId("61797229286e9ff2b1250d71"), "title" : "Toby another MongoDB", "description" : "this is another MongoDB", "tags" : [ "mongodb", "database", "NoSQL" ], "likes" : 2 }
{ "_id" : ObjectId("6179747d286e9ff2b1250d72"), "title" : "Toby MongoDB", "description" : "this is MongoDB", "tags" : [ "mongodb", "database", "NoSQL" ], "likes" : 1 }
{ "_id" : ObjectId("61797481286e9ff2b1250d73"), "title" : "Toby MongoDB", "description" : "this is MongoDB", "tags" : [ "mongodb", "database", "NoSQL" ], "likes" : 1 }
> 接下来我们移除 title 为 'Toby MongoDB' 的文档:
> db.col.remove({'title':'Toby MongoDB'})
WriteResult({ "nRemoved" : 2 }) # 删除了两个
> db.col.find()
{ "_id" : ObjectId("617970fc286e9ff2b1250d70"), "title" : "MongoDB", "description" : "this is MongoDB", "tags" : [ "mongodb", "database", "NoSQL" ], "likes" : 1 }
{ "_id" : ObjectId("61797229286e9ff2b1250d71"), "title" : "Toby another MongoDB", "description" : "this is another MongoDB", "tags" : [ "mongodb", "database", "NoSQL" ], "likes" : 2 }
> 如果你只想删除第一条找到的记录可以设置 justOne 为 1,如下所示:
>db.COLLECTION_NAME.remove(DELETION_CRITERIA,1)如果你想删除所有数据,可以使用以下方式(类似常规 SQL 的 truncate 命令):
> db.col.remove({})
WriteResult({ "nRemoved" : 2 })
> db.col.find()
> MongoDB 查询文档使用 find() 方法。
find() 方法以非结构化的方式来显示所有文档。
MongoDB 查询数据的语法格式如下:
db.collection.find(query, projection)- query :可选,使用查询操作符指定查询条件
- projection :可选,使用投影操作符指定返回的键。查询时返回文档中所有键值, 只需省略该参数即可(默认省略)。
如果你需要以易读的方式来读取数据,可以使用 pretty() 方法,语法格式如下:
>db.col.find().pretty()pretty() 方法以格式化的方式来显示所有文档。
以下实例我们查询了集合 col 中的数据:
> db.col.insert({title:'Toby MongoDB', description:'this is MongoDB',by:'Toby', tags:['mongodb','database','NoSQL'], likes:100 })
WriteResult({ "nInserted" : 1 })
> db.col.find().pretty()
{
"_id" : ObjectId("6179772f286e9ff2b1250d75"),
"title" : "Toby MongoDB",
"description" : "this is MongoDB",
"by" : "Toby",
"tags" : [
"mongodb",
"database",
"NoSQL"
],
"likes" : 100
}
> 除了 find() 方法之外,还有一个 findOne() 方法,它只返回一个文档。
MongoDB 的 find() 方法可以传入多个键(key),每个键(key)以逗号隔开,即常规 SQL 的 AND 条件。
语法格式如下:
>db.col.find({key1:value1, key2:value2}).pretty()以下实例通过 by 和 title 键来查询 Toby 中 Toby MongoDB 的数据
> db.col.find({'by':'Toby','title':'Toby MongoDB'}).prettydb.col.find({'by':'Toby','title':'Toby MongoDB'}).pretty()
{
"_id" : ObjectId("6179772f286e9ff2b1250d75"),
"title" : "Toby MongoDB",
"description" : "this is MongoDB",
"by" : "Toby",
"tags" : [
"mongodb",
"database",
"NoSQL"
],
"likes" : 100
}
> 以上实例中类似于 WHERE 语句:WHERE by='Toby' AND title='Toby MongoDB'
MongoDB OR 条件语句使用了关键字 $or,语法格式如下:
>db.col.find(
{
$or: [
{key1: value1}, {key2:value2}
]
}
).pretty()以下实例中,我们演示了查询键 by 值为 Toby或键 title 值为 Toby MongoDB 的文档。
> db.col.find({$or:[{"by":"Toby"},{"title":"Toby MongoDB"}]}).pretty()
{
"_id" : ObjectId("6179772f286e9ff2b1250d75"),
"title" : "Toby MongoDB",
"description" : "this is MongoDB",
"by" : "Toby",
"tags" : [
"mongodb",
"database",
"NoSQL"
],
"likes" : 100
}
> 以下实例演示了 AND 和 OR 联合使用,类似常规 SQL 语句为: 'where likes>50 AND (by = 'Toby' OR title = 'Toby MongoDB')'
> db.col.find({"likes":{$gt:50},$or:[{"by":"Toby"},{"title":"Toby MongoDB"}]}).pretty()
{
"_id" : ObjectId("6179772f286e9ff2b1250d75"),
"title" : "Toby MongoDB",
"description" : "this is MongoDB",
"by" : "Toby",
"tags" : [
"mongodb",
"database",
"NoSQL"
],
"likes" : 100
}
> 在 MongoDB 中使用 sort() 方法对数据进行排序,sort() 方法可以通过参数指定排序的字段,并使用 1 和 -1 来指定排序的方式,其中 1 为升序排列,而 -1 是用于降序排列。
sort()方法基本语法如下所示:
>db.COLLECTION_NAME.find().sort({KEY:1})col 集合中的数据如下:
> db.col.find().pretty()
{
"_id" : ObjectId("61797a56286e9ff2b1250d78"),
"title" : "Toby PHP",
"description" : "this is PHP",
"by" : "Toby",
"tags" : [
"PHP",
"Language"
],
"likes" : 100
}
{
"_id" : ObjectId("61797a62286e9ff2b1250d79"),
"title" : "Toby JAVA",
"description" : "this is JAVA",
"by" : "Toby",
"tags" : [
"JAVA",
"Language"
],
"likes" : 50
}
{
"_id" : ObjectId("61797a83286e9ff2b1250d7a"),
"title" : "Toby Python",
"description" : "this is Python",
"by" : "Toby",
"tags" : [
"Python",
"Language"
],
"likes" : 20
}
> 以下实例演示了 col 集合中的数据按字段 likes 的降序排列:
> db.col.find({},{'title':1,_id:0}).sort({"likes":-1})
{ "title" : "Toby PHP" }
{ "title" : "Toby JAVA" }
{ "title" : "Toby Python" }
> Python 要连接 MongoDB 需要 MongoDB 驱动,这里我们使用 PyMongo 驱动来连接。
pip 是一个通用的 Python 包管理工具,提供了对 Python 包的查找、下载、安装、卸载的功能。
安装 pymongo:
$ python3 -m pip install pymongo接下来我们可以创建一个测试文件 demo_test_mongodb.py,代码如下:
import pymongo执行以上代码文件,如果没有出现错误,表示安装成功。
创建数据库需要使用 MongoClient 对象,并且指定连接的 URL 地址和要创建的数据库名。
如下实例中,我们创建的数据库 pydb:
import pymongo
myclient=pymongo.MongoClient("mongodb://localhost:27017/")
mydb=myclient["pydb"]注意: 在 MongoDB 中,数据库只有在内容插入后才会创建! 就是说,数据库创建后要创建集合(数据表)并插入一个文档(记录),数据库才会真正创建。
我们可以读取 MongoDB 中的所有数据库,并判断指定的数据库是否存在:
import pymongo
myclient=pymongo.MongoClient("mongodb://localhost:27017/")
mydb=myclient["pydb"]
dblist = myclient.list_database_names()
# dblist = myclient.database_names()
if "pydb" in dblist:
print("数据库已存在!")
else:
print('数据库不存在')**注意:**database_names 在最新版本的 Python 中已废弃,Python3.7+ 之后的版本改为了 list_database_names()。
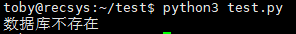
MongoDB 中的集合类似 SQL 的表。
MongoDB 使用数据库对象来创建集合,实例如下:
import pymongo
myclient=pymongo.MongoClient("mongodb://localhost:27017/")
mydb=myclient["pydb"]
mycol=myclient["col_set"]注意: 在 MongoDB 中,集合只有在内容插入后才会创建! 就是说,创建集合(数据表)后要再插入一个文档(记录),集合才会真正创建。
我们可以读取 MongoDB 数据库中的所有集合,并判断指定的集合是否存在:
import pymongo
myclient=pymongo.MongoClient("mongodb://localhost:27017/")
mydb=myclient["pydb"]
mycol=myclient["col_set"]
collist = mydb. list_collection_names()
if "col_set" in collist: # 判断 sites 集合是否存在
print("集合已存在!")
else:
print('集合不存在')
MongoDB 中的一个文档类似 SQL 表中的一条记录。
集合中插入文档使用 insert_one() 方法,该方法的第一参数是字典 name => value 对。
以下实例向 col_set 集合中插入文档:
import pymongo
myclient = pymongo.MongoClient("mongodb://localhost:27017/")
mydb = myclient["pydb"]
mycol = mydb["col_set"]
mydict = { "name": "Toby", "age": "23", "url": "https://juejin.cn/user/3403743731649863" }
x = mycol.insert_one(mydict)
print(x)
在命令行看一下是否插入成功
> use pydb
switched to db pydb
> db.col_set.find()
{ "_id" : ObjectId("617ce42cbc6011eaf1529012"), "name" : "Toby", "url" : "https://juejin.cn/user/3403743731649863", "age" : "23" }
> 集合中插入多个文档使用 insert_many() 方法,该方法的第一参数是字典列表。
import pymongo
myclient = pymongo.MongoClient("mongodb://localhost:27017/")
mydb = myclient["pydb"]
mycol = mydb["col_set"]
mylist = [
{ "name": "Tom", "age": "100", "url": "https://juejin.cn/user/3403743731649863" },
{ "name": "Mary", "age": "101", "url": "https://juejin.cn/user/3403743731649863" },
{ "name": "Timi", "age": "10", "url": "https://juejin.cn/user/3403743731649863" },
]
x = mycol.insert_many(mylist)
# 输出插入的所有文档对应的 _id 值
print(x.inserted_ids)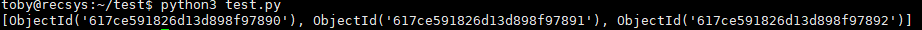
在命令行看一下是否插入成功
> use pydb
switched to db pydb
> db.col_set.find()
{ "_id" : ObjectId("617ce42cbc6011eaf1529012"), "name" : "Toby", "url" : "https://juejin.cn/user/3403743731649863", "age" : "23" }
{ "_id" : ObjectId("617ce591826d13d898f97890"), "name" : "Tom", "url" : "https://juejin.cn/user/3403743731649863", "age" : "100" }
{ "_id" : ObjectId("617ce591826d13d898f97891"), "name" : "Mary", "url" : "https://juejin.cn/user/3403743731649863", "age" : "101" }
{ "_id" : ObjectId("617ce591826d13d898f97892"), "name" : "Timi", "url" : "https://juejin.cn/user/3403743731649863", "age" : "10" }
> MongoDB 中使用了 find 和 find_one 方法来查询集合中的数据,它类似于 SQL 中的 SELECT 语句。
我们可以使用 find_one() 方法来查询集合中的一条数据。
查询 col_set 文档中的第一条数据:
import pymongo
myclient = pymongo.MongoClient("mongodb://localhost:27017/")
mydb = myclient["pydb"]
mycol = mydb["col_set"]
x = mycol.find_one()
print(x)
find() 方法可以查询集合中的所有数据,类似 SQL 中的 SELECT * 操作。
以下实例查找 col_set 集合中的所有数据:
import pymongo
myclient = pymongo.MongoClient("mongodb://localhost:27017/")
mydb = myclient["pydb"]
mycol = mydb["col_set"]
for x in mycol.find():
print(x)
我们可以使用 find() 方法来查询指定字段的数据,将要返回的字段对应值设置为 1。
import pymongo
myclient = pymongo.MongoClient("mongodb://localhost:27017/")
mydb = myclient["pydb"]
mycol = mydb["col_set"]
for x in mycol.find({},{ "_id": 0, "name": 1, "age": 1 }):
print(x)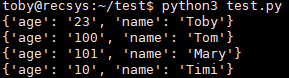
我们可以在 find() 中设置参数来过滤数据。
以下实例查找 name 字段为 "Toby" 的数据:
import pymongo
myclient = pymongo.MongoClient("mongodb://localhost:27017/")
mydb = myclient["pydb"]
mycol = mydb["col_set"]
myquery = { "name": "Toby" }
mydoc = mycol.find(myquery)
for x in mydoc:
print(x)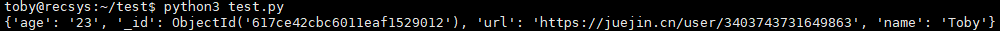
如果我们要对查询结果设置指定条数的记录可以使用 limit() 方法,该方法只接受一个数字参数。
以下实例返回 3 条文档记录:
import pymongo
myclient = pymongo.MongoClient("mongodb://localhost:27017/")
mydb = myclient["pydb"]
mycol = mydb["col_set"]
myresult = mycol.find().limit(3)
# 输出结果
for x in myresult:
print(x)
我们可以在 MongoDB 中使用 update_one() 方法修改文档中的记录。该方法第一个参数为查询的条件,第二个参数为要修改的字段。
如果查找到的匹配数据多于一条,则只会修改第一条。
以下实例将 age字段的值 23改为 12345:
import pymongo
myclient = pymongo.MongoClient("mongodb://localhost:27017/")
mydb = myclient["pydb"]
mycol = mydb["col_set"]
myquery = { "age": "23" }
newvalues = { "$set": { "age": "12345" } }
mycol.update_one(myquery, newvalues)
# 输出修改后的 "sites" 集合
for x in mycol.find():
print(x)
sort() 方法可以指定升序或降序排序。
sort() 方法第一个参数为要排序的字段,第二个字段指定排序规则,1 为升序,-1 为降序,默认为升序。
对字段 age 按升序排序:
import pymongo
myclient = pymongo.MongoClient("mongodb://localhost:27017/")
mydb = myclient["pydb"]
mycol = mydb["col_set"]
mydoc = mycol.find().sort("age")
for x in mydoc:
print(x)
对字段 age按降序排序:
import pymongo
myclient = pymongo.MongoClient("mongodb://localhost:27017/")
mydb = myclient["pydb"]
mycol = mydb["col_set"]
mydoc = mycol.find().sort("alexa", -1)
for x in mydoc:
print(x)
我们可以使用 delete_one() 方法来删除一个文档,该方法第一个参数为查询对象,指定要删除哪些数据。
以下实例删除 name 字段值为 "Timi" 的文档:
import pymongo
myclient = pymongo.MongoClient("mongodb://localhost:27017/")
mydb = myclient["pydb"]
mycol = mydb["col_set"]
myquery = { "name": "Timi" }
mycol.delete_one(myquery)
# 删除后输出
for x in mycol.find():
print(x)
delete_many() 方法如果传入的是一个空的查询对象,则会删除集合中的所有文档:
import pymongo
myclient = pymongo.MongoClient("mongodb://localhost:27017/")
mydb = myclient["pydb"]
mycol = mydb["col_set"]
x = mycol.delete_many({})
print(x.deleted_count, "个文档已删除")
我们可以使用 drop() 方法来删除一个集合。
以下实例删除了 col_set集合:
import pymongo
myclient = pymongo.MongoClient("mongodb://localhost:27017/")
mydb = myclient["pydb"]
mycol = mydb["col_set"]
mycol.drop()我们在终端查看一下
> use pydb
switched to db pydb
> show tables
system.indexes
> 本文主要介绍了MongoDB数据库的相关概念及基本操作,为了更好的了解MongoDB在新闻推荐系统中的应用,需要了解数据库的相关概念并熟练使用python操作MongoDB。