an example that shows the need for memory backpressure #2602
Comments
|
Thanks for the writeup and the motivation @rabernat . In general I agree with everything that you've written. I'll try to lay out the challenge from a scheduling perspective. The worker notices that it is running low on memory. The things that it can do are:
Probably it should run some task, but it doesn't know which tasks generate data, and which tasks allow it to eventually release data. In principle we know that operations like One option that I ran into recently is that we could slowly try to learn which tasks cause memory to arrive and which tasks cause memory to be released. This learning would happen on the worker. This isn't straightforward because there are many tasks running concurrently and their results on the system will be confused (there is no way to tie a system metric like CPU time or memory use to a particular Python function). Some simple model might give a decent idea over time though. We do something similar (though simpler) with runtime. We maintain an exponentially weighted moving average of task run time, grouped by task prefix name (like This approach would also be useful for other resource constraints, like network use (it'd be good to have a small number of network-heavy tasks like If someone wanted to try out the approach above my suggestion would be to ...
There are likely other solutions to this whole problem. But this might be one. |
but we do measure the memory usage of the inputs and outputs of functions that have run (not the internal transient memory), and also know whether running of a function ought to free the memory used by its inputs. If measurements were done on the prefix basis mentioned, there could be a reasonable guess at the memory implications of running a given task. |
|
Thanks a lot for your quick response. One quick clarification question... You say that a central challenge is that the scheduler
In my mental model, this is obvious from the input and output array shapes. If a task has an input which is 1000x1000 and an output which is 10x10, it is a net sink of memory. The initial nodes of the graph are always sources. I assumed that the graph must know about these input and output shapes, and the resulting memory footprint, even if it has no idea how long each task will take. But perhaps I misunderstand how much the scheduler knows about the tasks it is running. Wouldn't it be easier to expose this information to the scheduler than it would be to rig up an adaptive monitoring solution? |
That's a good point, and it's much easier to measure :)
The scheduler doesn't know about shapes or dtypes of your arrays. It only knows that it is running a Python function, and that that function produces some outputs. You're thinking about Dask array, not Dask. @martindurant 's suggestion is probably enough for your needs though. |
I suppose the client does, at least for arrays, so there could be another route to pass along the expected output memory size of some tasks. In the dataframe case, the client might know enough, and in the general case, there could be a way for users to specify expected output size. |
|
Hi everyone, This is a subject of interest to me too. But I thought that Dask tried already to minimize memory footprint as explained here. Obviously, this is not what @rabernat is observing, and I've seen the same behavior as him on similar use cases. Couldn't we just give an overall strategy for the Scheduler to use? Like work on the depth of the graph first? |
The scheduler does indeed run the graph depth first to the extent possible (actually, it's a bit more complex than this, but your depth-first intuition is correct). Things get odd though if
|
|
These issues also impact my use cases. One thing I've considered is rather than creating a graph purely composed of parallel reductions: is to define some degree of parallelism (2 in this example) and then create two "linked lists", where the results of a previous operation are aggregated with those of the current. I haven't tried this out yet, so not sure to what extent it would actually help, but its on my todo list to mock the above up with dummy ops.
In this context it's probably worth re-raising Task Annotations again: dask/dask#3783, which in a complete form would allow annotating a task with an estimate of it's memory output. I started on it in #2180 but haven't found time to push it forward. |
|
This also affects my work-flow so I would be curious to see progress on it. On our end, writing out to disk doesn't help since disk is also a finite resource. We have a few workarounds such as adding artificial dependencies into a graph or submitting a large graph in pieces. |
|
Thanks everyone for the helpful discussion. It sounds like @mrocklin and @martindurant have identified a concrete idea to try which could improve the situation. This issue is a pretty high priority for us in Pangeo, so we would be very happy to test any prototype implementation of this idea. |
|
I’ll be on paternity leave for at least the next two weeks (maybe longer, depending on how things are going). If this is still open then I’ll tackle it then. |
|
Hi folks...I'm just pinging this issue to remind us that it remains a crucial priority for Pangeo. |
|
👍 it's on my list for tomorrow :) |
|
https://nbviewer.jupyter.org/gist/TomAugspurger/2df7828c22882d336ad5a0722fbec842 has a few initial thoughts. The first problem is that the rechunking from along just axis 0 to just axis 1 cause a tough, global communication pattern. The output of
So for this specific problem it may be an option to preserve the chunks along axis 0, and only add additional chunks along axis 1. This leads to a better communication pattern.
But, a few issues with that
I'll keep looking into this, assuming that a different chunking pattern isn't feasible. (FYI @mrocklin the HTML array repr came in handy). |


|
@TomAugspurger , the general problem remains interesting, though, of using the expected output size and known set of things that could be dropped of a given tasks as an additional heuristic in determining when/where to schedule that task. |
|
Yep. I notice now that my notebook oversimplified things. The original example still has chunks along the first and second axis before the map_blocks (which means the communication shouldn't be entirely global). I'll update things. |
|
This is a "real world" example that can be run from ocean.pangeo.io which I believe illustrates the core issue. It is challenging because the chunks are big, leading to lots of memory pressure. import intake
cat = intake.Catalog('https://raw.githubusercontent.com/pangeo-data/pangeo-datastore/master/intake-catalogs/ocean.yaml')
ds = cat.GODAS.to_dask()
print(ds)
salt_clim = ds.salt.groupby('time.month').mean(dim='time')
print(salt_clim)
# launch dask cluster
from dask.distributed import Client
from dask_kubernetes import KubeCluster
# using more workers might alleviate the problem, but that is not a satisfactory workaround
cluster = KubeCluster(n_workers=5)
client = Client(cluster)
# computation A
# compute just one month of the climatology
# it works fine, indicating that the computation could be done in serial
salt_clim[0].load()
# computation B
# now load the whole thing
# workers quickly run out of memory, spill to disk, and even get killed
salt_clim.load()
|
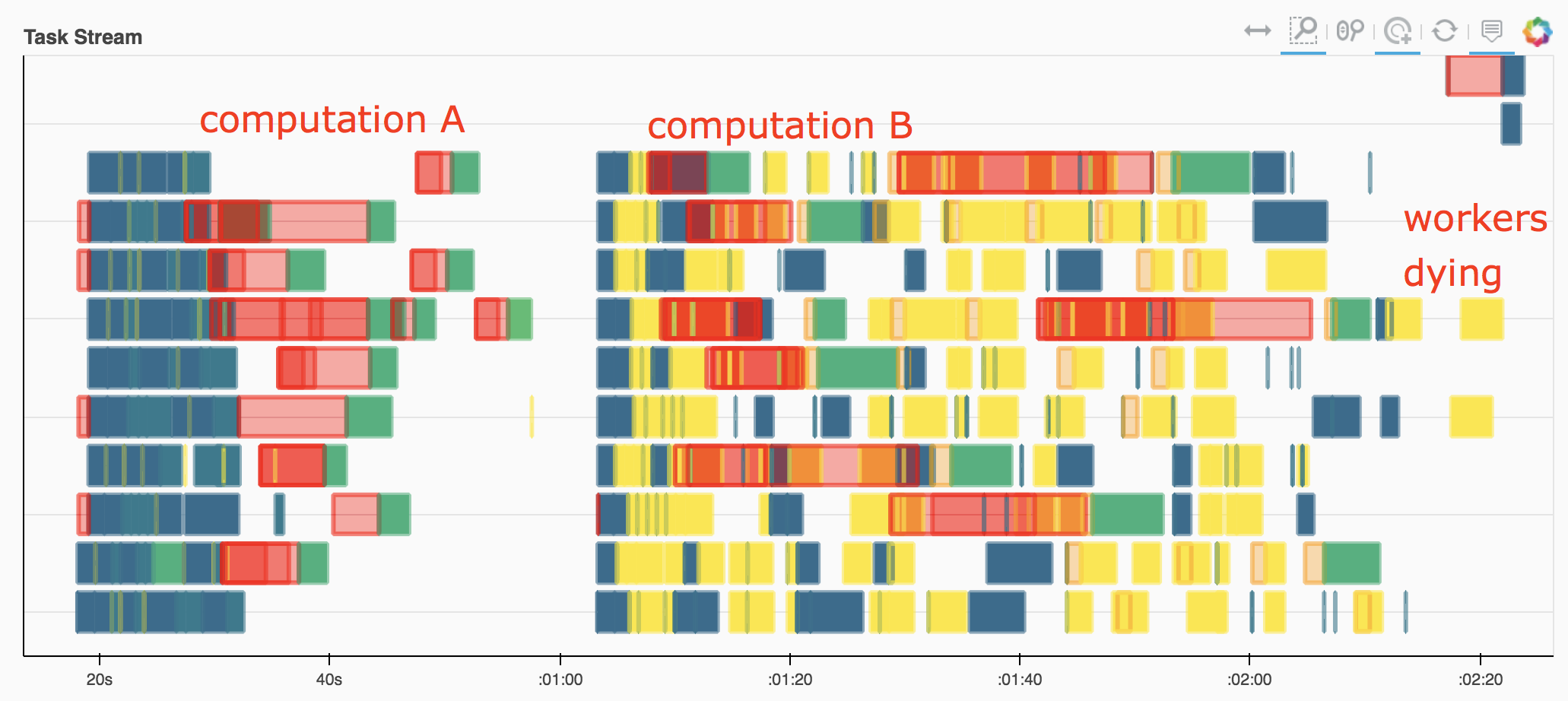
|
Thanks @rabernat. I'll try it out on the pangeo binder once I have something working locally. I think (hope) I have a workable solution. My basic plan is
So if we currently have high memory usage, and we see a set of tasks like We would (ideally) schedule |
|
@TomAugspurger , that's exactly how I was picturing things. Additionally, you may need to know whether calculating |
Yeah, I've been looking through the recommendations -> release logic now. I'm wondering if we can also keep a counter of "completing this task recommended that we release this many bytes". That seems a bit easier to track than knowing whether |
|
As a user of dask.array, it confuses me that the graph itself doesn't have this information in it already. In my mind, all of my dask.array operations know about the shape and dtype of their inputs and outputs. Consequently, the memory impact of a task is known a-priori. I do understand that this information is not encoded into the dask graph--all the graph knows about is tasks and their dependencies. But, to my naive interpretation, it seems harder to try to "learn" the memory impact of tasks based on past experience than it does to pass this information through the graph itself, in the form of task annotation. |
As you say, TaskAnnotations mentioned by @sjperkins in #2602 (comment) would let us pass that information through. I think that approach should be considered, but I have two reasons for pursing the "learning" approach within distributed for now
I will take another look at the task annotation issue though. |
|
A promising note, the additional LOC for the tracking seems to be ~3 :) I'm just keeping a
The scheduling changes will be harder, but this seems promising so far. |
|
@TomAugspurger said
Sounds reasonable. As a warning, there might be other considerations fighting for attention here. Scheduling is an interesting balancing game. @martindurant said
This is a nice point. One naive approach would be to divide the effect by the number of dependents of the dependency-to-be-released. |
|
Also, I'm very glad to have more people thinking about the internal scheduling logic! |
|
@mrocklin do you know off hand whether the changes to the scheduling logic are likely to be on the worker, scheduler, or both? I can imagine both situations occurring, so I suspect the answer is "both". |
|
I would say either. Dask has task priorities in three places:
1. As provided by the client with dask.order and user priorities
2. As modified by the scheduler, with first-in-first-out for successive
compute calls
3. As modified again by the worker, loosely preferring first-in-first
out, but largely deferring to the high priorities
What you're proposing seems like it plays at the first level, similar to
dask.order. You're going to want to be careful not to overwhelm the user
provided priorities. I think that you're going to hit some interesting
situations where bytes handling and dask.order disagree. In some ways
bytes handling is smarter on a short term basis, but might bite you by
being short sighted. It will be interesting to see what happens.
In terms of scheduler vs worker, the scheduler would be nicer because you
can learn the bytes size across the cluster as a whole, rather than having
to relearn on every worker. Learning on the worker is a bit nicer because
you'll be able to update priorities more rapidly and it's always nice to
move any potentially costly logic away from the scheduler. My sense is
that it might not matter much where you implement the logic to start.
…On Fri, May 24, 2019 at 12:00 PM Tom Augspurger ***@***.***> wrote:
@mrocklin <https://github.com/mrocklin> do you know off hand whether the
changes to the scheduling logic are likely to be on the worker, scheduler,
or both? I can imagine both situations occurring, so I suspect the answer
is "both".
—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
<#2602?email_source=notifications&email_token=AACKZTB3OWMOUTWRN6H6ZGLPXANLXA5CNFSM4HEYFY22YY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGODWF7DOI#issuecomment-495710649>,
or mute the thread
<https://github.com/notifications/unsubscribe-auth/AACKZTEDQHV77JAGZKMYR7LPXANLXANCNFSM4HEYFY2Q>
.
|
|
I could also imagine us not asking the client to run dask.order at all, and doing all task prioritization on the workers. This would allow us to integrate the byte sizes into the dask.order computation (and remove it from the single-threaded client-scheduler processing). This is probably something to explore as future work though. |
FWIW,
So this looks more like a problem with reordering / waiting to execute some tasks, if we notice that we
|

|
This does look like a huge improvement! I look forward to trying it out on my problems. |
|
EXciting!
@gjoseph92 This happens all the time! See dask/dask#3595 (especially dask/dask#3595 (comment)) @mrocklin proposed a solution here: dask/dask#3595 . I use the |
|
@dcherian thanks for the xref! dask/dask#3595 (comment) is exactly what I was thinking. (It wouldn't help with user code in |
|
From a Coiled resourcing perspective, +1 on spending time on the getitem
fix. That seems cheap to implement and medium-high value.
…On Wed, Jun 30, 2021 at 9:32 AM Gabe Joseph ***@***.***> wrote:
@dcherian <https://github.com/dcherian> thanks for the xref! dask/dask#3595
(comment)
<dask/dask#3595 (comment)> is
exactly what I was thinking. (It wouldn't help with user code in
map_blocks like this case specifically, but since that's advanced, maybe
that's okay.) I might like to take this on.
—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
<#2602 (comment)>,
or unsubscribe
<https://github.com/notifications/unsubscribe-auth/AACKZTBBHQSYYGDLSQQDCITTVNBJRANCNFSM4HEYFY2Q>
.
|
|
I'm closing this out. If folks have other issues here though then I'm happy to reopen. @rabernat , thank you for opening this originally. My apologies that it took so long to come to a good solution. |
|
Which dask release do users need to be running to get this feature? My impression is 2021.07.0, correct? |
|
I think anything 2021.07 or greater should work. We're also releasing
2021.07.2 today if you wanted to wait a day :)
…On Fri, Jul 30, 2021 at 6:12 AM Ryan Abernathey ***@***.***> wrote:
Which dask release do users need to be running to get this feature?
—
You are receiving this because you modified the open/close state.
Reply to this email directly, view it on GitHub
<#2602 (comment)>,
or unsubscribe
<https://github.com/notifications/unsubscribe-auth/AACKZTCMKTQFEGPRUEWISCTT2KCJRANCNFSM4HEYFY2Q>
.
|
|
I am working on a blog post to advertise the exciting progress we have made on this problem. As part of this, I have created an example notebook that can be run in Pangeo Binder (including with Dask Gateway) with two different versions of Dask which attempts to reproduce the issue and its resolution. Older Dask version (2020.12.1): https://binder.pangeo.io/v2/gh/pangeo-gallery/default-binder/b8d1c53?urlpath=git-pull%3Frepo%3Dhttps%253A%252F%252Fgist.github.com%252Frabernat%252F39d8b6a396e076d168c24167b8871c4b%26urlpath%3Dtree%252F39d8b6a396e076d168c24167b8871c4b%252Fanomaly_std.ipynb%26branch%3Dmaster The notebook uses the following cluster settings, which is the biggest cluster we can reasonably share publicly on Pangeo Binder: It includes both the "canonical anomaly-mean example example" with synthetic data from #2602 (comment) (referenced by @gjoseph92 in #2602 (comment)) as well as a similar real-world example that uses cloud data. I have found that the critical performance issues are largely resolved even in Dask 2020.12.1 when I use My questions for the group are:
(edit below)
I am now trying to run this example, which should presumably reproduce the issue better. |
|
Latest edit: I ran a slightly modified version of the "dougiesquire's climactic mean example" and added it to the gist. The only real change I made was to also reduce over the climactic mean example codeimport pandas as pd
size = (28, 237, 48, 21, 90, 144)
chunks = (1, 1, 48, 21, 90, 144)
arr = dsa.random.random(size, chunks=chunks)
arr
items = dict(
ensemble = np.arange(size[0]),
init_date = pd.date_range(start='1960', periods=size[1]),
lat = np.arange(size[2]).astype(float),
lead_time = np.arange(size[3]),
level = np.arange(size[4]).astype(float),
lon = np.arange(size[5]).astype(float),
)
dims, coords = zip(*list(items.items()))
array = xr.DataArray(arr, coords=coords, dims=dims)
dset = xr.Dataset({'data': array})
display(dset)
# reduce of "init_date" and "ensemble" to reduce final memory requirements.
result = dset['data'].groupby("init_date.month").mean(dim=["init_date", "ensemble"])
%time result.compute()Using So I can definitely see evidence of an incremental improvement, but I feel like I'm still missing something. |
|
Thanks Ryan. Have not tested this on anything seriously large, but hopefully will soon. |
This thread is a confusing mix of many issues. The
This example (from @dougiesquire I think) has chunksize=1 along The earlier example:
So The best way to reduce the GODAS dataset should be this strategy: https://flox.readthedocs.io/en/latest/implementation.html#method-cohorts i.e. we index out months 1-4 which always occur together and map-reduce that. Repeat for all other cohorts (months 5-8, 9-12) and then concatenate for the final result. One could test this with |
|
Though this issue is closed, I imagine that most of you following it are still interested in memory usage in dask, and might still be having problems with it. It's possible that closing this with #4967 was premature, but I'm hoping that #6614 actually addresses the core problem in this issue. If you are (or aren't) having problems with workloads running out of memory, please try out the new Information on how to set it is here. And please comment on the discussion to share how it goes: These are benchmarking results showing significant reductions in peak memory use:
We're especially interested in hearing how the runtime-vs-memory tradeoff feels to people. So please try it out and report back! Lastly, thank you all for your collaboration and persistence in working on these issues. It's frustrating when you need to get something done, and dask isn't working for you. The examples everyone has shared here have been invaluable in working towards a solution, so thanks to everyone who's taken their time to keep engaging on this. |
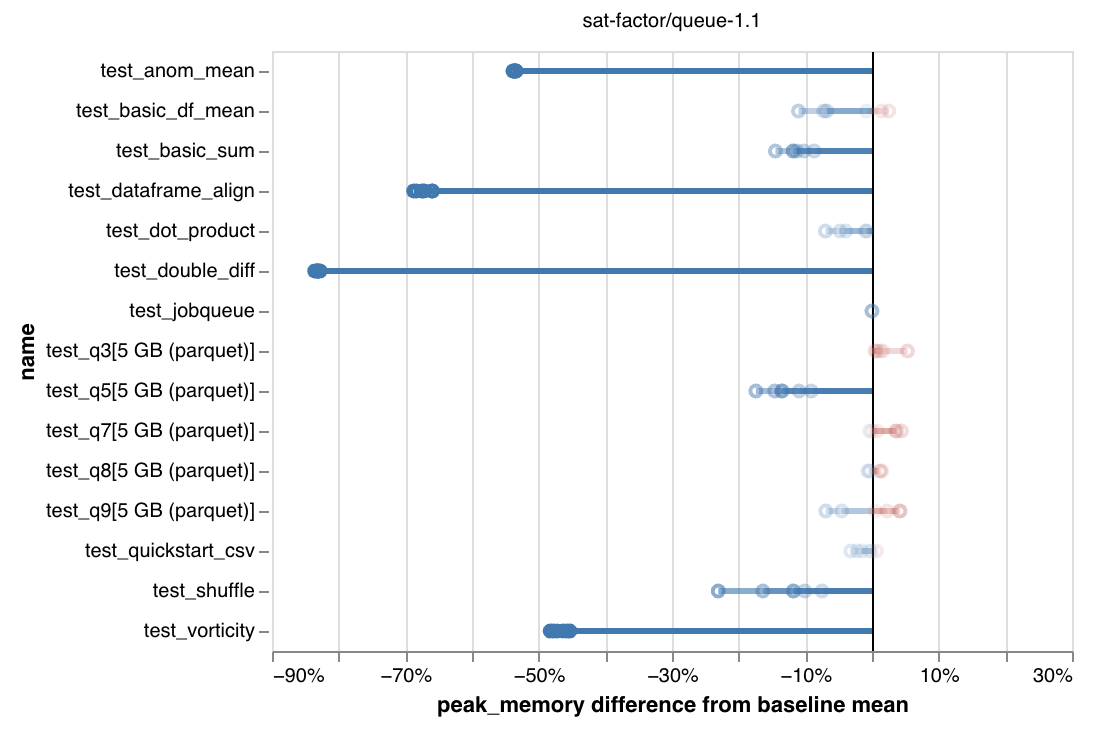
|
Thanks @gjoseph92 |
In my work with large climate datasets, I often concoct calculations that cause my dask workers to run out of memory, start dumping to disk, and eventually grind my computation to a halt. There are many ways to mitigate this by e.g. using more workers, more memory, better disk-spilling settings, simpler jobs, etc. and these have all been tried over the years with some degree of success. But in this issue, I would like to address what I believe is the root of my problems within the dask scheduler algorithms.
The core problem is that the tasks early in my graph generate data faster than it can be consumed downstream, causing data to pile up, eventually overwhelming my workers. Here is a self contained example:
(Perhaps this could be simplified further, but I have done my best to preserve the basic structure of my real problem.)
When I watch this execute on my dashboard, I see the workers just keep generating data until they reach their memory thresholds, at which point they start writing data to disk, before
my_custom_functionever gets called to relieve the memory buildup. Depending on the size of the problem and the speed of the disks where they are spilling, sometimes we can recover and manage to finish after a very long time. Usually the workers just stop working.This fail case is frustrating, because often I can achieve a reasonable result by just doing the naive thing:
and evaluating my computation in serial.
I wish the dask scheduler knew to stop generating new data before the downstream data could be consumed. I am not an expert, but I believe the term for this is backpressure. I see this term has come up in #641, and also in this blog post by @mrocklin regarding streaming data.
I have a hunch that resolving this problem would resolve many of the pervasive but hard-to-diagnose problems we have in the xarray / pangeo sphere. But I also suspect it is not easy and requires major changes to core algorithms.
Dask version 1.1.4
The text was updated successfully, but these errors were encountered: