RNN theory
layout: post date: 2018-04-12 00:01 title: "循环神经网络RNN理论剖析" categories: ML tag: - Machine Learning - deep learning - RNN comment: true
待整理。
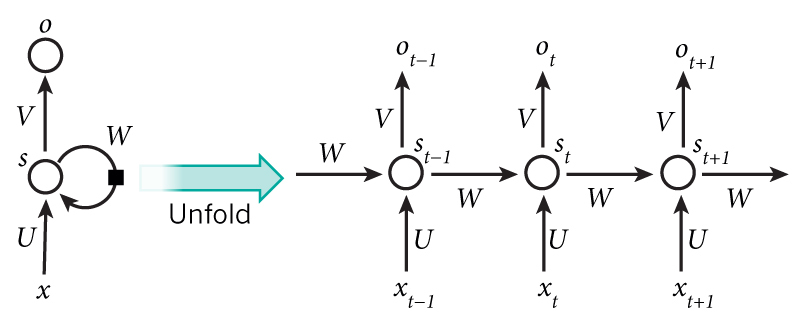
其中$x_{t}$是t时刻的输入;$s_{t}$是t时刻的隐藏状态,$f$函数通常为tanh或者ReLU函数;$o_{t}$是t时刻的输出。
- 隐藏层$s_{t}$可以认为是网络的记忆,通过$t$时刻的记忆,我们可以单独计算出它的输出$o_{t}$。
- RNN共享三大权值,分别是上述的
U、V、W。 - RNN有多种形式,比如one-to-one、one-to-many、many-to-one、many-tomany、etc,可参考资料[1]。
- vanishing gradient(梯度消失):Long Short-Term Memory (LSTM) 和 Gated Recurrent Unit (GRU)
- exploding gradient(梯度爆炸)
其中$y_{t}$是t时刻的正确输出,$o_{t}$是t时刻预测的输出。整个训练过程的误差图如下:
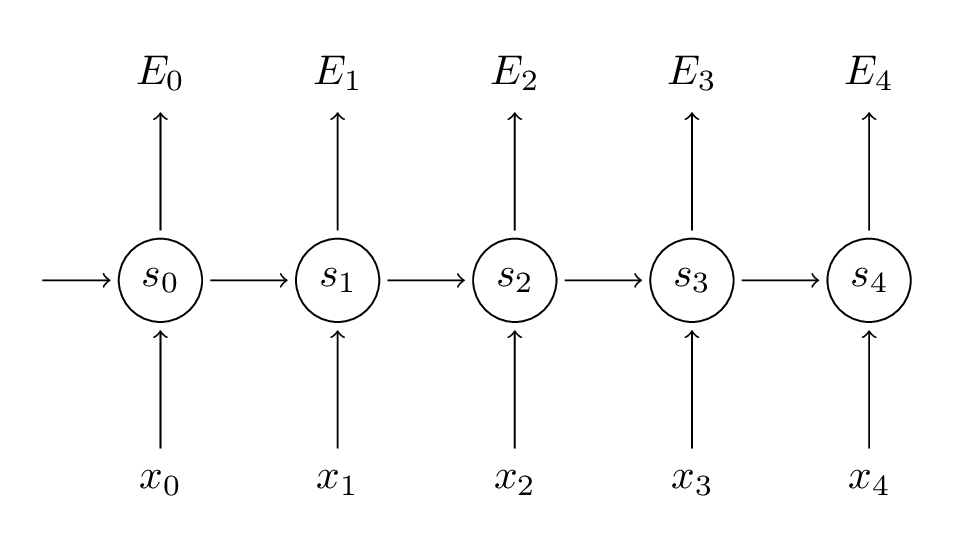
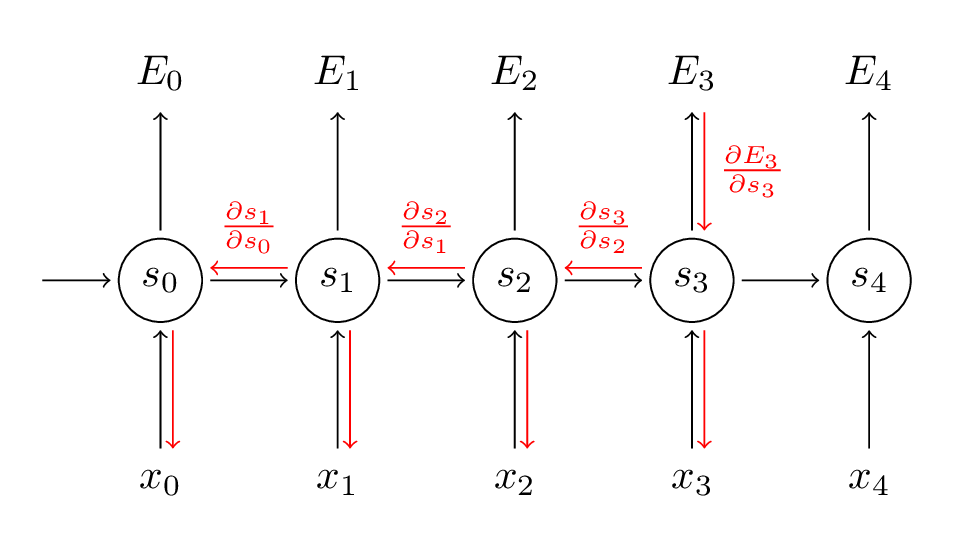
我们训练RNN的目的,是学习三大参数U、V、W,使用的方法是SGD。计算偏导数:
$$
$$
- http://cs231n.stanford.edu/slides/2016/winter1516_lecture10.pdf
- http://cs231n.stanford.edu/slides/2017/cs231n_2017_lecture10.pdf
- http://adventuresinmachinelearning.com/recurrent-neural-networks-lstm-tutorial-tensorflow/
- http://ir.hit.edu.cn/~jguo/docs/notes/bptt.pdf
- https://zhuanlan.zhihu.com/p/27485750
- http://www.wildml.com/2015/09/recurrent-neural-networks-tutorial-part-1-introduction-to-rnns/
- http://jmlr.org/proceedings/papers/v9/glorot10a/glorot10a.pdf
- http://colah.github.io/posts/2015-08-Backprop/