- 数据将以这样一种方式分布,即读写均匀地分布在tablet server上。这受到分区的影响。
- tablets将以一个均匀的、可预测的速度增长,随着时间的推移,跨tablet的负载将保持稳定,受分区影响最大
- 扫描将读取完成查询所需的最小数据量。这主要受到主键设计的影响,但是分区也通过分区修剪发挥作用。
- 大多数的表使用哈希分区,包括同时使用范围分区的时间序列的应用
- 每一列都有类型、编码方式和压缩方式。编码方式有合适的默认值,而压缩方式默认是不支持压缩
完美的架构取决于数据的特性,需要处理的数据以及集群的拓扑。 模式设计是控件中最重要的事情,它可以最大化Kudu群集的性能。
- 一个Kudu表由一个或多个列组成,每个列都有一个定义的类型,不属于主键的列可以为空。支持的列类型包括
- boolean
- 8bit signed integer(8字节有符号int类型)
- 16-bit signed integer
- 32-bit signed integer
- 64-bit signed integer
- date (32-bit days since the Unix epoch)
- unixtime_micros (64-bit microseconds since the Unix epoch)
- single-precision (32-bit) IEEE-754 floating-point number
- double-precision (64-bit) IEEE-754 floating-point number
- decimal (see Decimal Type for details)
- varchar (see Varchar Type for details)
- UTF-8 encoded string (up to 64KB uncompressed)
- binary (up to 64KB uncompressed)
- Kudu利用
强类型列和磁盘上的列存储格式提供高效的编码和序列化。为了充分利用这些特性,应该将列指定为适当的类型,而不是为数据使用字符串或二进制列来模拟“无模式”表,否则数据可能是结构化的。除了编码之外,Kudu还允许按列指定压缩。
- decimal类型对于大于int64的整数和主键中有小数值的情况也很有用。decimal类型是一种参数化类型,它接受precision和scale类型属性。
- precision表示可以由列表示的总位数,而与小数点的位置无关,该值必须在
1到38之间,并且没有缺省值。例如该值为4表示9999的整数值,或以两个小数位表示至99.99的值。范围-9999到9999仍然只要求精度为4。
- scala表示小数位数,
必须在0和precision之间,0的scala产生的是整数值,如果precision和scale相等,所有的数字都在小数点后,例如precision和scale都是4,那么可以表示为-0.9999和0.9999之间的值。
- 根据为十进制列指定的precision,kudu将每个值存储在尽可能少的字节中,因此不建议为了方便而使用更高的精度。
- Decimal值的precision为9或者小于将被存储4个bytes
- Decimal值的precision为10到18将被存储8个bytes
- Decimal值的precision为大于等于18将被存储16个bytes
varchar类型是一个UTF-8编码的字符串是一个固定的最大字符长度。这种类型在从支持varchar类型的遗留系统迁移或与之集成时特别有用。如果不需要最大字符长度,则应该使用string类型。varchar的参数是一个长度,表示字符的长度,长度在1到65535
- 可以根据列的类型使用编码创建Kudu表中的每一列。
| Column Type | Encoding | Default |
|---|---|---|
| int8, int16, int32, int64 | plain, bitshuffle, run length | bitshuffle |
| date, unixtime_micros | plain, bitshuffle, run length | bitshuffle |
| float, double, decimal | plain, bitshuffle | bitshuffle |
| bool | plain, run length | run length |
| string, varchar, binary | plain, prefix, dictionary | dictionary |
- 数据是按照原始格式存储,例如
int32存储就按照32bit固定长度的int
- 一个值块被重新安排,以存储每个值的最有效位,然后存储每个值的第二有效位,依此类推。最后,对LZ4进行压缩。对于具有
许多重复值或按主键排序时发生少量更改的值的列,Bitshuffle编码是一个很好的选择。bitshuffle项目很好地概述了性能和用例。
通过只存储值和计数,在列中压缩运行(连续重复值)。当按主键排序时,运行长度编码对于具有许多连续重复值的列是有效的。
- 将构建一个包含
惟一值的字典,并将每个列值编码为字典中对应的索引。字典编码对于基数低的列是有效的。如果一个给定行集的列值无法被压缩,因为唯一值的数量太高,Kudu将会对该行集透明地采用纯编码。这将在刷新时进行评估。
- 公共前缀被压缩成连续的列值。前缀编码对于共享公共前缀的值或主键的第一列是有效的,因为行在tablet中是按主键排序的。
- Kudu运行基于列的压缩使用
LZ4,Snappy,zlib压缩器。默认情况下,列按照BitShuffle编码使用LZ4压缩进行压缩。否则,列被存储时不会被压缩,如果减少存储空间比原始扫描性能更重要,可以考虑使用压缩。
- 每个kudu表都必须指定一个主键,主键有一列或多列组成,主键强制为一个唯一性约束,不能插入重复的主键数据。
- 主键的列不允许为空,不能为boolean、float或double类型。
- 一旦在表创建期间设置,主键中的列集就不能更改。
- kudu不支持自增的列的特性,随意应用一定要在插入的时候提供全部的主键。
- 行删除和更新操作还必须指定要更改的行的完整主键。Kudu本身不支持范围删除或更新。
- 插入行后,列的主键值可能不会更新。但是,可以使用更新后的值删除并重新插入该行。
- 与许多传统关系数据库一样,Kudu的主键位于聚集索引中。tablet中的所有行都按其主键排序。
- 当扫描kudu的行时,在主键列上使用相等或范围谓词可有效地查找行。
-
在主键是时间戳或主键的第一列是时间戳的情况下,timeseries用例中的主键设计考虑。
-
每次将一行插入到Kudu表时,Kudu都会在主键索引存储中查找主键,以检查主键是否已经存在于表中。如果主键存在于表中,则返回一个“重复键”错误。
在数据从数据源到达时插入数据的典型情况下,只有一小部分主键是“热的”。所以,每一个“存在检查”行动都非常迅速。它在内存中访问缓存的主键存储,而不需要去磁盘。 -
在从离线数据源加载历史数据(称为“backfilling”)的情况下,插入的每一行很可能会触及主键索引的
冷区,该区域不在内存中,并导致一个或多个HDD磁盘查找。例如,在正常的摄取情况下,Kudu每秒维持几百万个插入,“回填”用例可能只维持每秒几千个插入。 -
为了缓解回填过程中的性能问题,可以考虑以下选项
- 使主键更可压缩
例如,如果主键的第一列是32字节的随机ID,则缓存十亿个主键将需要至少32 GB的RAM才能保留在缓存中。 如果从几天前开始缓存回填主键,则需要有32 GB的内存几次。 通过将主键更改为更具可压缩性,可以增加主键可以放入缓存的可能性,从而减少随机磁盘I / O的数量。- 使用ssd存储,因为随机查找比旋转磁盘快几个数量级。
- 更改主键结构,使回填写命中连续范围的主键。
- 为了提供可扩展性,kudu表被划分为多个tablets单元,并且以分布式方式分布在多个tablet server上。一行通常属于一个单独的tablet。将行分配给tablet的方法由表的分区决定,分区是在表创建期间设置的。
- 选择一个分区策略必须要理解一个表的数据模型和期待的工作负载。对于写频繁的工作负载,为了防止数据
热点问题,应该将数据均匀的分布在各个tablet上。对于涉及许多短扫描的工作负载,在联系远程服务器的开销占主导地位的情况下,如果扫描的所有数据都位于同一块tablet上,则可以提高性能。
- Kudu不提供默认分区策略,建议预期具有繁重读写工作负载的新表至少拥有与tablet server相同的tablet。
- range partitioning使用
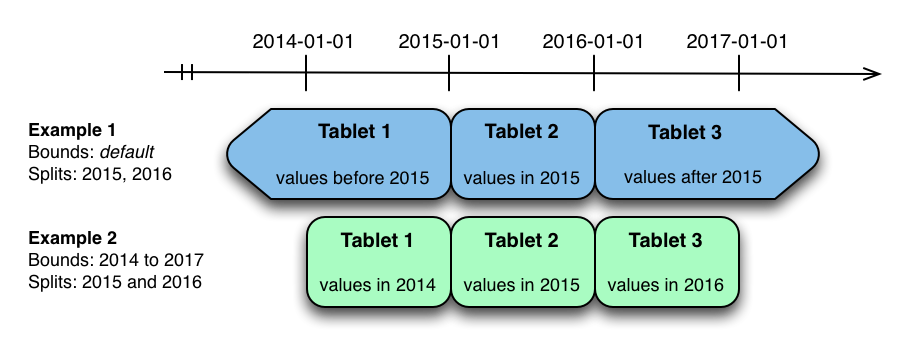
完全有序的范围分区键来分配行,每个分区被指定一个范围分区键空间的一个连续段。键必须由主键列的子集组成,如果范围分区列匹配逐渐的列,那么一行的范围分区键将等于它的主键。在没有散列分区的范围分区表中,每个范围分区将恰好对应一个tablet。 - 在表创建期间,将范围分区的初始集指定为一组分区边界和分割行。对于每个绑定,将在表中创建一个范围分区。每次分割都会将一个范围分区划分为两个。如果没有指定分区边界,那么表将默认为单个分区,覆盖整个键空间(上下不限)。范围分区必须始终不重叠,分割的行必须位于范围分区内。
- Kudu运行在
运行时添加或删除范围分区,不影响其他分区的可用性。删除一个分区将删除属于该分区的tablet以及其中包含的数据。对已删除分区的后续插入将失败。可以添加新的分区,但是它们不能与任何现有的范围分区重叠。Kudu允许在一个事务alter table操作中删除和添加任意数量的范围分区。 - 动态添加和删除范围分区对于时间序列用例特别有用。随着时间的推移,可以添加范围分区来覆盖未来的时间范围。例如,存储事件日志的表可以在每月开始之前添加一个月范围的分区,以保存即将发生的事件。可以删除旧的范围分区,以便在必要时有效地删除历史数据。
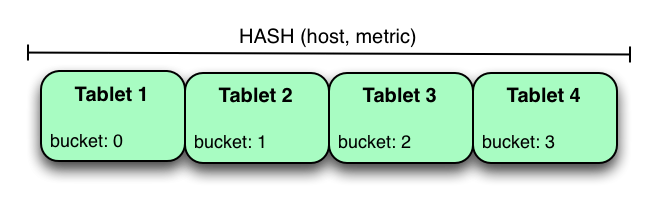
- 哈希分区按哈希值进行分布到多个桶中。在单级哈希分区表中,每个
bucket将恰好对应一个tablet。bucket的数量是在创建表时设置的。通常使用主键列作为hash值,但与范围分区一样,可以使用主键列的任何子集。 - 当不需要对表进行有序访问时,哈希分区是一种有效的策略。哈希分区对于在tablet之间随机分布写操作非常有效,这有助于缓解热定位和tablet大小不均匀。
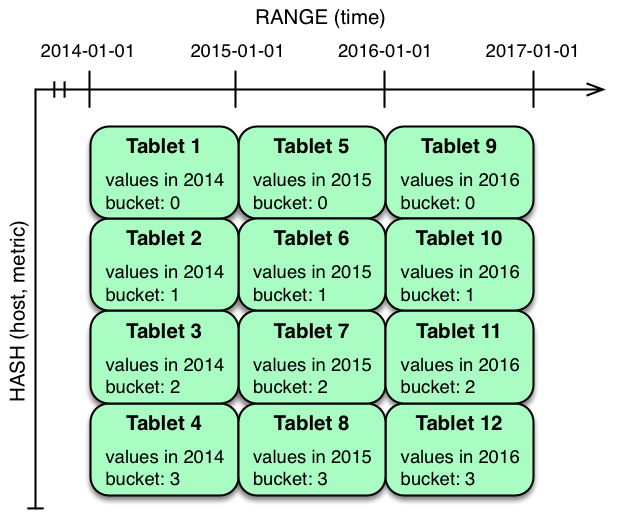
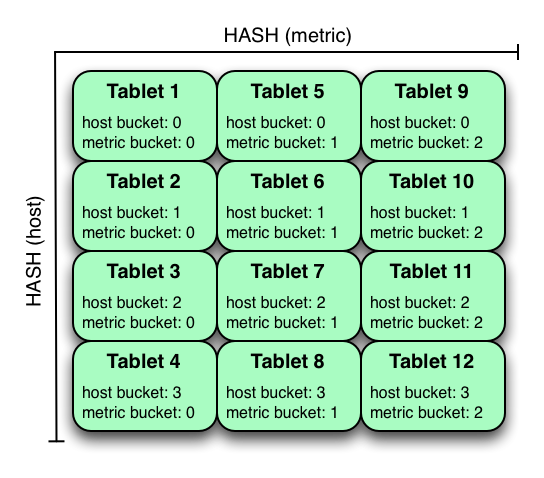
- Kudu允许在一个表上组合多个分区级别,0或多个hash分区能和一个范围分区组合。除了单个分区类型的约束外,对多层分区的唯一附加约束是
多层哈希分区不能哈希同一列。
- 当可以确定分区可以被scan谓词完全过滤时,Kudu扫描将自动跳过对整个分区的扫描。要删除hash分区,扫描必须在每个散列上包含等式谓词。要删除范围分区,扫描必须包括范围分区列上的相等谓词或范围谓词。对多层分区表的扫描可以独立地利用任何级别上的分区修剪。
CREATE TABLE metrics (
host STRING NOT NULL,
metric STRING NOT NULL,
time INT64 NOT NULL,
value DOUBLE NOT NULL,
PRIMARY KEY (host, metric, time)
);- 对度量表进行分区的一种自然方法是在时间列上进行范围分区。假设我们希望每年有一个分区,表将保存2014、2015和2016年的数据。至少有两种方法可以对表进行分区:使用无边界范围分区,或者使用有边界范围分区。
metrics根据host和metric列作为hash分区的列
- 这种分区策略将在表中的所有tablet上均匀地展开写操作,这有助于总体的写吞吐量。通过指定相等谓词,对特定
host和metrics的扫描可以利用分区修剪,从而将扫描的tablet数量减少到一个。
| Strategy | Writes | Reads | Tablet Growth |
|---|---|---|---|
range(time) |
✗ - all writes go to latest partition | ✓ - time-bounded scans can be pruned | ✓ - new tablets can be added for future time periods |
hash(host, metric) |
✓ - writes are spread evenly among tablets | ✓ - scans on specific hosts and metrics can be pruned | ✗ - tablets could grow too large |
- Kudu可以在同一个表中支持任意数量的哈希分区级别,只要这些级别没有共同的哈希列。
- 重命名表
- 重命名主键的列
- 重命名、添加或者删除非主键列
- 添加或删除范围分区
可以在单个事务操作中组合多个更改步骤。
- 列的数量
- 默认kudu不允许创建一个表超过300个列。
- cell的大小
- 在编码或压缩之前,单个单元不能大于64KB。在由Kudu完成内部组合键编码后,组成组合键的单元总数被限制为16KB。插入不符合这些限制的行将导致错误返回给客户机。
- 行的大小
- 虽然单个单元格最多可以达到64KB,并且Kudu最多支持300列,但是建议单个行不要超过几百KB。
- Valid Identifiers
- 诸如表和列名之类的标识符必须是有效的UTF-8序列,并且不超过256字节。
- 主键不可变
- kudu不允许修改修改一行的主键列
- 不可修改主键
- 在创建表之后,Kudu不允许更改主键列。
- 不可修改分区
- 除了添加或删除范围分区外,Kudu不允许更改创建后的表分区方式。
- 不可修改列的类型
- Kudu不允许更改列的类型。
- partition splitting
- 分区不能在表创建之后分开或合并
- 删除的行磁盘空间不会被回收
- 被删除的行所占用的磁盘空间只能通过
compaction机制来回收,并且只有当删除的期限超过“talet server历史记录的最大使用期限”(由--tablet_history_max_age_sec标志控制)时,才能收回。 此外,Kudu当前仅调度压缩以提高读取/写入性能。 tablet绝不会仅仅为了压缩磁盘空间而进行压缩。 这样,当预期将丢弃大量行时,应使用范围分区。 使用范围分区,可以删除各个分区以丢弃数据并回收磁盘空间。
- 被删除的行所占用的磁盘空间只能通过