无87 常灿 2018**********
该工程主要由CPU, 外设(集成在DataMemory中)和uart串口3部分组成
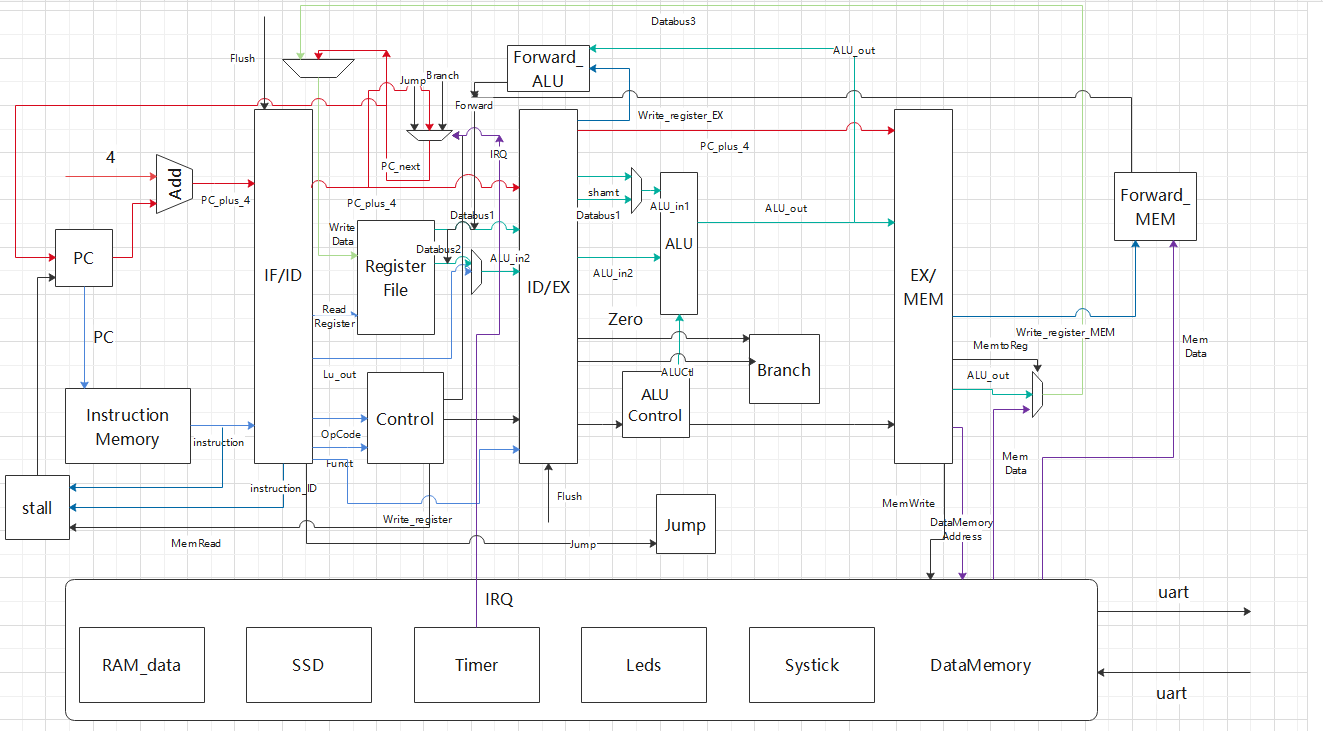
- 红色线条代表PC相关信号,主要包含计算PC_next的部分(图中Control输出到PC_next计算单元的信号包括Exception,Jump,Branch_EX等,未画出) 和 选择下一条PC的部分(是否stall)。
- 紫色线条代表数据存储器读写相关部分,值得注意的是IRQ信号由Timer发出。
- 绿色线条代表ALU计算部分,这里与通常涉及不同的是,ALU_in2在ID阶段就计算出,主要是为了优化主频,详见优化方案第2条
- 蓝色线条为Instruction直接包含的信息,包括读写寄存器地址和指令码等。对于2个Forwarding部分,通过比较当前阶段Write_register和ID阶段Write_register来决定ID阶段的Databus1和Databus2所读取数据来源
- 黑色线条为Control产生的控制信号。其中Flush信号由Jump信号与Branch信号决定,图中未画出
- 完成了实验要求中提到的所有功能
- vivado实现后的主频125.7MHz, CPI=1.27
我们采用了10ns周期的时钟进行仿真验证。为了便于观察中间变量,确保程序的正确性,我们关掉了时序优化中设置的flatten-hierarchy选项。
-
排序功能的实现
以下是testbench文件中sorted_data数组经过uart传出数据后的结果的部分截图,可以发现,数据已经成功被排好了序
-
七段数码管扫描显示 如下图所示为数码管扫描的一部分,对应到16进制为0x1197
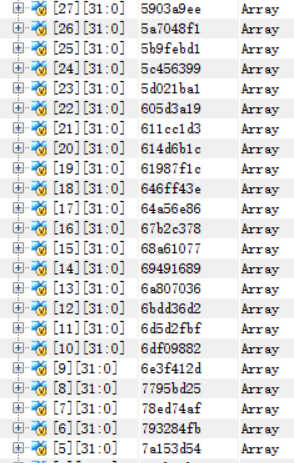

使用Mars分析得到的指令数为106647
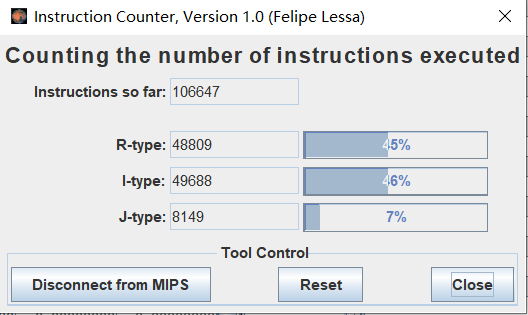
计算得到的CPI为1.27
按照要求所提示的操作方法,依次执行以下步骤
-
导入数据 (uart实现)
-
保存初始systick值
li $s5 0x40000014 lw $s4 0($s5) # $s4: initial systick
-
完成排序(使用冒泡排序)
-
读取systick新值,求得其差值
# save systick li $s5 0x40000014 lw $s7 0($s5) sub $s5 $s7 $s4 # systick diff
-
使能定时器中断
# enable timer li $t0 0x40000000 # timer address li $t1 0xffff0000 li $t2 0xffffffff addi $t3 $zero 3 sw $t1 0($t0) # TH sw $t2 4($t0) # TL sw $t3 8($t0) # TCON
-
进入中断服务程序,扫描显示systick
interrupt: #disable timer li $s0 0x40000000 # timer address sw $zero 8($s0) add $s1 $zero 516 # $s1: start address of ssd table,129*4 li $s3 0x40000010 add $s2 $zero 15 and $t0 $s5 $s2 sll $t0 $t0 2 add $t0 $t0 $s1 lw $t0 0($t0) srl $s5 $s5 4 and $t1 $s5 $s2 sll $t1 $t1 2 add $t1 $t1 $s1 lw $t1 0($t1) srl $s5 $s5 4 and $t2 $s5 $s2 sll $t2 $t2 2 add $t2 $t2 $s1 lw $t2 0($t2) srl $s5 $s5 4 and $t3 $s5 $s2 sll $t3 $t3 2 add $t3 $t3 $s1 lw $t3 0($t3) scan: add $t5 $t0 $zero sw $t5 0($s3) add $t5 $t1 $zero sw $t5 0($s3) add $t5 $t2 $zero sw $t5 0($s3) add $t5 $t3 $zero sw $t5 0($s3) j scan jr $k0
-
输出排序结果(uart控制)
我们引入了uart_on和uart_mode[1:0]两个信号来控制uart。其中,uart_on为1时代表传输数据,反之代表未传输数据。uart_mode代表以下3者之一: 传入指令,传入数据,传出排序好的数据。相关代码主要位于testbench文件和CPU.v文件最后。
PC在时钟沿上升处触发,在程序未开始时保持为32'h80000000,否则使用PC_next赋值
always @(posedge clk)
if (reset)
PC <= 32'h80000000;
else if(!(uart_on==0 && uart_mode==2'b11))
PC<=32'h80000000;
else if(~stall)
PC <= PC_next;PC_next根据控制信号决定,包括异常中断,分支跳转和载入下一条。
assign PC_next = ~BeginSortAlready?32'h80000000:
IRQ ? 32'h80000004:
Exception ?32'h80000008:
(PCSrc_EX == 2'b11&&Branch)? Branch_target: // branch at EX stage
(PCSrc == 2'b01)? Jump_target:
(PCSrc==2'b10)?Databus1: // jump register
PC_plus_4;PC_plus_4在计算过程中需要保持监督位不变
assign PC_plus_4 =(PC==32'h80000000)?32'h00000004:{PC[31],PC[30:0] + 31'd4};外设统一在DataMemory模块中实现,如果Address[30]不为1,则正常写入RAM_data中
if (MemWrite && ~Address[30])
RAM_data[Address[RAM_SIZE_BIT + 1:2]] <= Write_data;否则,根据Address的值写入相应的外设中。
- timer的实现参考了课件上给出的代码
module Timer(
input reset,
input clk,
input [1:0] addr,
input MemWrite,
input [31:0] Write_data,
output [31:0] read_data,
output IRQ
);
reg [31:0] TH;
reg [31:0] TL;
reg [31:0] TCON;
assign read_data=(addr==0)?TH:(addr==1)?TL:(addr==2)?TCON:32'b0;
assign IRQ=TCON[2]&TCON[1];
always @(posedge clk)begin
if(reset)begin // turn off timer
TH<=0;
TL<=0;
TCON<=0;
end
else begin
if(MemWrite)begin
if(addr==0) TH<=Write_data;
else if(addr==1)TL<=Write_data;
else if (addr==2)TCON<=Write_data;
end
else begin
if(TCON[0])begin // timer is enabled
if(TL==32'hffffffff)begin
TL<=TH;
if(TCON[1]) TCON[2]<=1'b1;
end
else TL<=TL+1;
end
end
end
end
endmodule-
systick实现了一个计数器
module SysTick( input reset, input clk, output reg[31:0] systick ); always @(posedge clk)begin if(reset) systick<=0; else begin systick<=systick+1; end end endmodule
-
SSD和LED的代码实现与普通存储区相同,不再赘述
我们使用上升沿触发的寄存器,实验中我发现MEM_WB寄存器可以省略,故仅仅保留文件,未在CPU模块中体现。
除了通常的控制信号外,我们在ID_EX寄存器中传入了ALU_in2信号,具体可以参考下文优化方案第2条
我们仅仅实现了非法指令导致的异常。在control中采用如下判断方式
assign Exception=(~Branch && ~RegWrite && ~MemWrite && PCSrc!=2'd1 && PCSrc!=2'd2 &&
~(Funct==0 && OpCode==0))?1:0;同时,我们考虑到在内核态不允许异常,因此在CPU中加入下面代码
assign Exception=Exception_ID && ~PC[31];在写入寄存器时判断,如果出现异常,则写入PC_next至k0寄存器。
通过timer产生IRQ信号
assign IRQ=TCON[2]&TCON[1];IRQ信号的处理与Exception信号类似,唯一区别在于跳转地址不同,此处不再赘述。
共有4种forward信号,如下所示
assign Forward_ALU_to_Databus1=(Write_register_EX==instruction_ID[25:21]
&& Write_register_EX!=0 && RegWrite_EX)?1:0;
assign Forward_ALU_to_Databus2=(Write_register_EX==instruction_ID[20:16]
&& Write_register_EX!=0 && RegWrite_EX)?1:0;
assign Forward_MEM_to_Databus1=(Write_register_MEM==instruction_ID[25:21]
&& Write_register_MEM!=0 && RegWrite_MEM)?1:0;
assign Forward_MEM_to_Databus2=(Write_register_MEM==instruction_ID[20:16]
&& Write_register_MEM!=0 && RegWrite_MEM)?1:0;需要注意的是,在forwarding时优先考虑上一级forwarding,再考虑上上一级的
assign Databus1=Forward_ALU_to_Databus1?ALU_out:Forward_MEM_to_Databus1?Databus3:Databus1_reg;
assign Databus2=Forward_ALU_to_Databus2?ALU_out:Forward_MEM_to_Databus2?Databus3:Databus2_reg;除了上述所用forwarding外,还需要引入stall信号
assign stall=((Instruction[25:21]==Write_register || Instruction[20:16]==Write_register)
&& MemRead)?1:0;对于jump和branch,需要flush掉相应流水线寄存器里面的指令
IF_ID阶段的flush
assign Flush_IF_ID=Branch || Jump || Exception;ID_EX阶段的flush
assign Flush_ID_EX=Branch;在单周期指令的基础上,我们添加了Negative信号,并结合Zero信号得到新的branch信号
assign Branch=(BranchEq_EX & Zero) || (BranchNeq_EX & !Zero) ||
(BranchLez_EX & (Zero || Negative)) || (BranchGtz_EX & !Negative & !Zero)
|| (BranchLtz_EX & Negative);整个优化过程花费了我2天左右的时间,优化的主要思路为根据关键路径调整各个单元所处的位置,使得整体较为均衡。
-
将Branch判断部分从ALU中分离出来
对于涉及到Branch判断的Zero和Negative两个信号,我们无需等待ALU计算出Out后再进行判断,而是可以直接对ALU_in1和ALU_in2进行异或和减法运算进行判断。
-
将ALU_in的计算过程提到ID阶段
我们发现ID阶段相比于EX阶段时间丰裕得多,因此我们将能够提前计算的ALU_in再ID阶段进行计算,再通过流水线寄存器传给EX阶段
-
精简存储空间的使用
我们尽量开辟与所需存储空间相近大小的存储空间,使得布线阶段对所用空间进行优化,能够对主频有所提升
-
删去无用的变量
开始时我在流水线寄存器中放入了很多变量,最后优化时对无用的变量进行了手动删除,进一步提升了主频
-
对部分运算逻辑进行了等价的变形
这主要体现在两个方面
① 对if… else if类型或者多个||的并列型判断,将简单的表达式放在前面,有时可以有一定的提升
② 使用德摩根定律进行等价逻辑转换
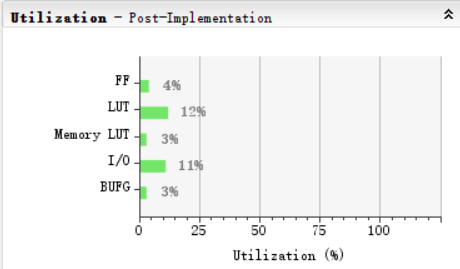
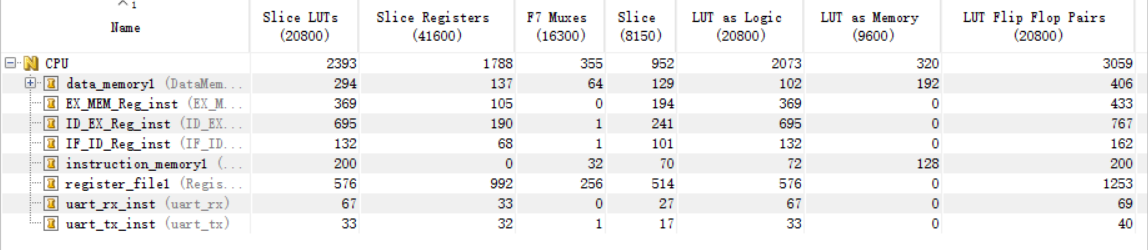
采用flatten-hierarchy=rebuilt的综合设置,8ns时钟激励,其余均使用默认选项。实现结果如下所示

WNS=0.048ns,计算得到主频为1/(8-0.048)=125.7MHz. 对比单周期CPU的50MHz,流水线CPU有着较大的改善。
最长延迟路径如下
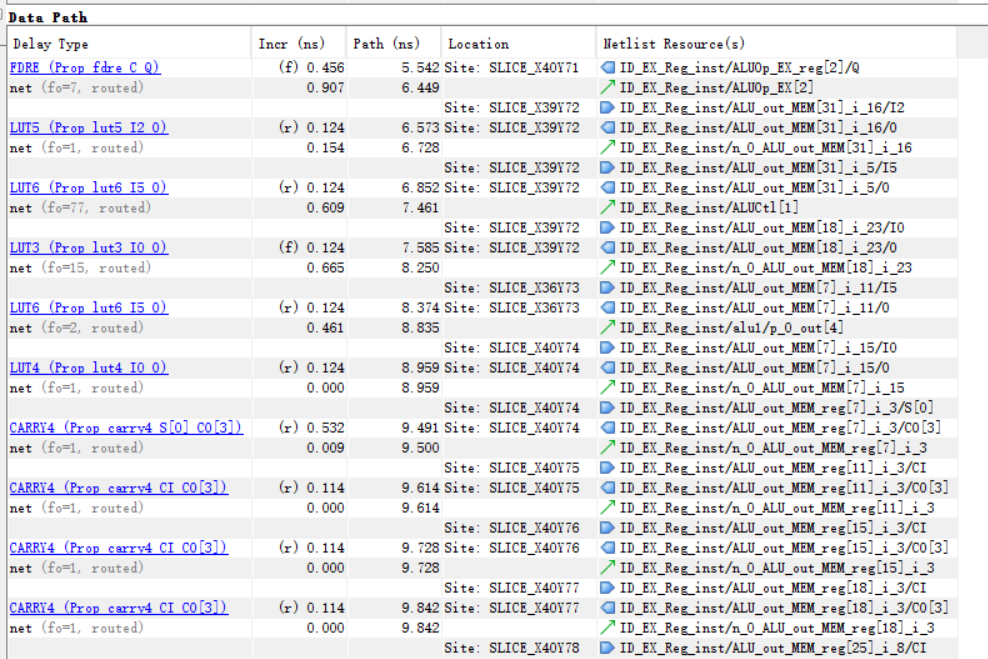
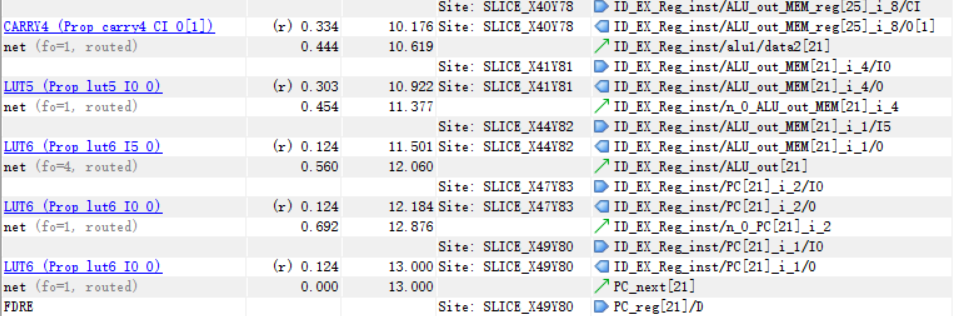
可以分析得到,该最坏路径为branch对应计算跳转地址后写入PC_next的路径。
- 良好的工程规划对大工程的实现有着极为重要的帮助。本次实验中我循着完善单周期CPU,完成uart和外设,初步实现流水线CPU并进行单指令调试,完善forwarding和异常处理,流水线优化这一步骤,确保了bug的可控性。
- 对软硬件的协同作用有了进一步的理解。开始时我为了方便,使用硬件方法实现了七段数码管的显示,后来经过孙老师的提示,我明白了这一做法的不合理性。外设经过内存映射后映射为了RAM的一部分,从硬件的角度考虑,其就应该与其他存储空间的地位相同,这类似于操作系统中的设备管理,需要依靠驱动程序这一软件方法来实现。
- 对Vivado的实现方式有待进一步的提高。在优化过程中,我也曾经尝试了一些看似可行的办法,但实现后的主频却有所下降。事实上Vivado的布线对主频有着较大的影响,例如当我对InstructionMemory进行一定精简时,主频反而变慢了,且InstructionMemory从原来的不在关键路径到进入了关键路径。此外,一些参数的设置(如存储器大小)的微调也对主频有3~5MHz的影响。这些恐怕只有在我深入学习其布线原理后才能理解。
bbsort.asm 用于仿真的冒泡排序汇编代码
bbsort2.asm 用于计算指令数的汇编代码
data.txt 用于排序的数据和ssd的查找表,通过 generate_data.py生成
inst.txt bbsort.asm通过Mars直接生成的机器码
instruction.txt 用于仿真的机器码,由generate_instruction.py生成
pipeline.srcs\sources_1\ 存放设计文件的文件夹
pipeline.srcs\constrs_1 存放约束文件的文件夹
pipeline.srcs\sim_1 存放仿真文件的文件夹
pipeline.xpr 工程文件