-
Notifications
You must be signed in to change notification settings - Fork 0
/
01-part1-overview.Rmd
82 lines (60 loc) · 4.71 KB
/
01-part1-overview.Rmd
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
---
title: "Overview and Introduction"
output:
html_document:
toc: false
---
```{r setup, include=FALSE}
knitr::opts_chunk$set(echo = TRUE)
```
# Set up your computer
## Installation
- Download and install R 3.5.1 from https://ftp.osuosl.org/pub/cran/ . (Requires administrator/root privellege)
- Install the latest RStudio Desktop free version from https://www.rstudio.com/products/rstudio/download/
- Follow [these steps](03-git.html#install-git) to install Git. (Requires administrator/root privellege)
If you already have R and RStudio installed on your laptop, it'd be a good idea to check their version and upgrade them to the latest (if they are not).
## Installation Verification
1. Launch RStudio and you should see a program window like this: <center><img src="http://swcarpentry.github.io/r-novice-gapminder/fig/01-rstudio.png"></center>
1. Click the **File** menu, select **New Project...**, then **Version Control** and **Git**;
1. Copy & paste this URL: https://github.com/cities/datascience2018.git into the the Repository URL textbox;
1. Click **Create Project**.
If you see a popup box that says "Clone Repsitory" with a progress bar and then RStudio refreshes, then your installation is working.
# What is Data Science?
According to Wikipedia:
> Data science is an interdisciplinary field that uses scientific methods, processes, algorithms and systems to extract knowledge and insights from data in various forms, both structured and unstructured, similar to data mining.
>
> Data science is a "concept to unify statistics, data analysis, machine learning and their related methods" in order to "understand and analyze actual phenomena" with data. It employs techniques and theories drawn from many fields within the context of mathematics, statistics, information science, and computer science.
[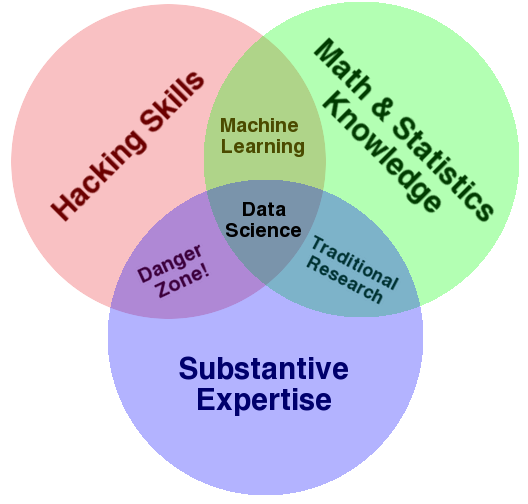](http://drewconway.com/zia/2013/3/26/the-data-science-venn-diagram)
Data Science Venn Diagram by Drew Conway
## Resources
- [What is Data Science?](https://datascience.berkeley.edu/about/what-is-data-science/) by datascience@Berkeley
- [A Taxonomy of Data Science](http://www.dataists.com/2010/09/a-taxonomy-of-data-science/) by Hilary Mason and Chris Wiggins
- ["You can't do data science in a GUI"](https://www.youtube.com/watch?v=cpbtcsGE0OA) by Hadley Wickham
- [Why Do We Need Data Science When We’ve Had Statistics for Centuries?](https://blogs.wsj.com/cio/2014/05/02/why-do-we-need-data-science-when-weve-had-statistics-for-centuries/) by Irving Wladawsky-Berger
# Why R
- [Free, as in beer & speech](https://www.r-project.org/about.html)
- Large and growing community, with [More than 15,000 packages and counting](https://www.rdocumentation.org/trends)
- Powerful and flexible
- [Graphics Gallery](http://www.r-graph-gallery.com/)
- [Interactive Web Apps: Interactive Plots, Dashboard, Widget ...](https://shiny.rstudio.com/gallery/)
- Packages for doing statistics & machine learning, creating documents, grabbing/processing data ...
# Class project
For the class project, you are expected to create a re-usable R script with the following requirements and commit it to GitHub:
1. Part I
1. Contains at least one self-contained function;
1. Follows a consistent style guide;
1. Completed with necessary documentation;
1. Has at least one test that passes;
1. [Advanced] Organizes the function(s) into a package that passes the checks
2. Part II
1. Utilzes tidyverse functions as much as possible
1. [Advanced] Includes a vignette that demonstrates the usage of the package
You can take and/or re-organize code from your current work or start from scratch. Take the feasibility of completing in a week into consideration when selecting project ideas.
If you don't have a feasible project idea at the moment, consider writing a R package that reads and visualizes the bike counts on Steel Bridge, Hawthorne Bridge, and Tilikum Crossing. Daily traffic counts data for these bridges can be found [here](https://github.com/cities/datascience2018/tree/master/data). At the minimum, your package should be able to:
- Read the data in the excel file;
- Process (tidy) the data as necessary;
- Visualize bike counts crossing a bridge based on a data frame passed in;
- Plot daily bike counts for any specified period;
- [Advanced] Plot daily, weekly, or monthly bike counts based on a frequency argument;
- [Advanced] Overlay weather data for Portland and study (visualize and/or model) the effect of weather on bike traffic;
- [Advanced] Study (visualize and/or model) the effect of Tilikum Crossing (opened in September 2015) on bike counts crossing other bridges.