We test two models: VGG16 (communication-intensive) and Resnet50 (computation-intensive) on a popular public cloud. Both models are trained using fp32.
We use Tesla V100 16GB GPUs and set batch size equal to 64 per GPU. The machines are VMs on the cloud. Each machine has 8 V100 GPUs with NVLink-enabled. Machines are inter-connected with 20 Gbps TCP/IP network.
BytePS outperforms Horovod (NCCL) by 44% for Resnet50, and 100% for VGG16.
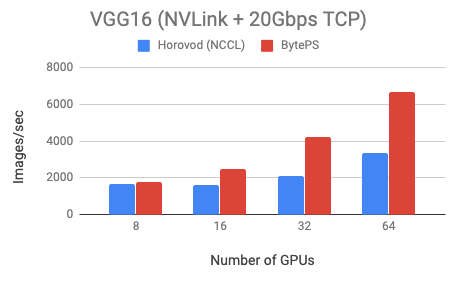
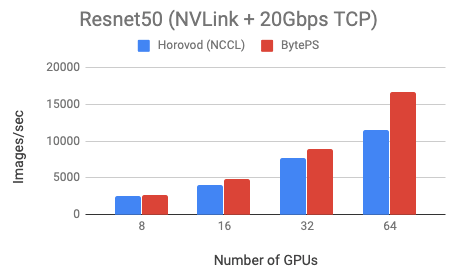
You can reproduce the results using the Dockerfiles and example scripts we provide.
Note: here we present the worse case scenario of BytePS, i.e., 100Gbps RDMA + no NVLinks.
We get below results on machines that are based on PCIe-switch architecture -- 4 GPUs under one PCIe switch, and each machine contains two PCIe switches. The machines are inter-connected by 100 Gbps RoCEv2 networks. In this case, BytePS outperforms Horovod (NCCL) by 7% for Resnet50, and 17% for VGG16.


To have BytePS outperform NCCL by so little, you have to have 100Gbps RDMA network and no NVLinks. In this case, the communication is actually bottlenecked by internal PCI-e switches, not the network. BytePS has done some optimization so that it still outperforms NCCL. However, the performance gain is not as large as other cases where the network is the bottleneck.