This repo contains demo application, which can load different networks, create pipelines, record video, etc.
Click on the GIF below to see a full example run

Documentation is available at https://docs.luxonis.com/en/latest/pages/tutorials/first_steps/.
There are two installation steps that need to be performed to make sure the demo works:
-
One-time installation that will add all necessary packages to your OS.
$ sudo curl -fL https://docs.luxonis.com/install_dependencies.sh | bashPlease follow this installation page to see instructions for other platforms
-
Python dependencies installation that makes sure your Python interpreter has all required packages installed. This script is safe to be run multiple times and should be ran after every demo update
$ python3 install_requirements.py
This repository and the demo script itself can be used in various independent cases:
- As a tool to try out different DepthAI features, explorable either with command line arguments (with
--guiType cv) or in clickable QT interface (with--guiType qt) - As a quick prototyping backbone, either utilising callbacks mechanism or by extending the
Democlass itself - As a way to write code for DepthAI devices faster, using depthai-sdk managers and helper functions, on top of which the demo script is built
See instuctions here
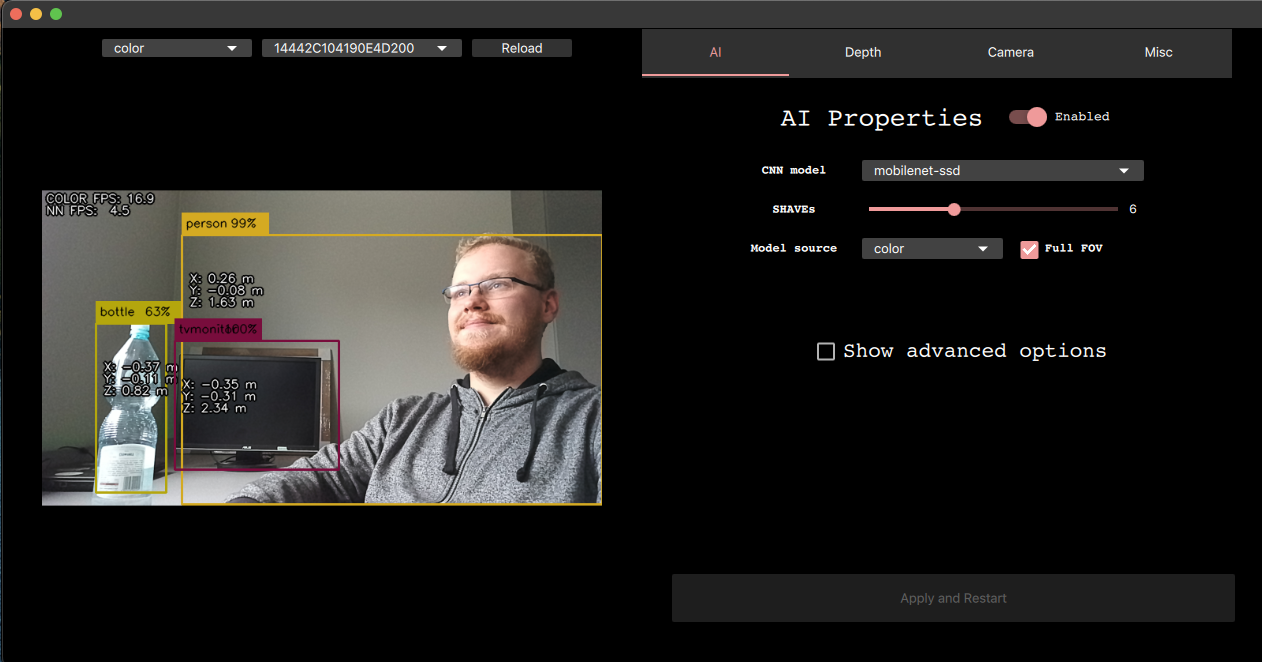
Examples
python3 depthai_demo.py -gt cv - RGB & CNN inference example
python3 depthai_demo.py -gt cv -vid <path_to_video_or_yt_link> - CNN inference on video example
python3 depthai_demo.py -gt cv -cnn person-detection-retail-0013 - Run person-detection-retail-0013 model from resources/nn directory
python3 depthai_demo.py -gt cv -cnn tiny-yolo-v3 -sh 8 - Run tiny-yolo-v3 model from resources/nn directory and compile for 8 shaves
Demo

Full reference
$ depthai_demo.py --help
usage: depthai_demo.py [-h] [-cam {left,right,color}] [-vid VIDEO] [-dd] [-dnn] [-cnnp CNNPATH] [-cnn CNNMODEL] [-sh SHAVES] [-cnnsize CNNINPUTSIZE] [-rgbr {1080,2160,3040}] [-rgbf RGBFPS] [-dct DISPARITYCONFIDENCETHRESHOLD] [-lrct LRCTHRESHOLD] [-sig SIGMA] [-med {0,3,5,7}] [-lrc] [-ext] [-sub] [-dff]
[-scale SCALE [SCALE ...]] [-cm {AUTUMN,BONE,CIVIDIS,COOL,DEEPGREEN,HOT,HSV,INFERNO,JET,MAGMA,OCEAN,PARULA,PINK,PLASMA,RAINBOW,SPRING,SUMMER,TURBO,TWILIGHT,TWILIGHT_SHIFTED,VIRIDIS,WINTER}] [-maxd MAXDEPTH] [-mind MINDEPTH] [-sbb] [-sbbsf SBBSCALEFACTOR]
[-s {nnInput,color,left,right,depth,depthRaw,disparity,disparityColor,rectifiedLeft,rectifiedRight} [{nnInput,color,left,right,depth,depthRaw,disparity,disparityColor,rectifiedLeft,rectifiedRight} ...]] [--report {temp,cpu,memory} [{temp,cpu,memory} ...]] [--reportFile REPORTFILE]
[-monor {400,720,800}] [-monof MONOFPS] [-cb CALLBACK] [--openvinoVersion {2020_3,2020_4,2021_1,2021_2,2021_3,2021_4}] [--app APP] [--count COUNTLABEL] [-dev DEVICEID] [-bandw {auto,low,high}] [-gt {auto,qt,cv}] [-usbs {usb2,usb3}] [-enc ENCODE [ENCODE ...]] [-encout ENCODEOUTPUT]
[-xls XLINKCHUNKSIZE] [-poeq POEQUALITY] [-camo CAMERAORIENTATION [CAMERAORIENTATION ...]] [--cameraControlls] [--cameraExposure CAMERAEXPOSURE [CAMERAEXPOSURE ...]] [--cameraSensitivity CAMERASENSITIVITY [CAMERASENSITIVITY ...]]
[--cameraSaturation CAMERASATURATION [CAMERASATURATION ...]] [--cameraContrast CAMERACONTRAST [CAMERACONTRAST ...]] [--cameraBrightness CAMERABRIGHTNESS [CAMERABRIGHTNESS ...]] [--cameraSharpness CAMERASHARPNESS [CAMERASHARPNESS ...]] [--skipVersionCheck] [--noSupervisor] [--sync]
optional arguments:
-h, --help show this help message and exit
-cam {left,right,color}, --camera {left,right,color}
Use one of DepthAI cameras for inference (conflicts with -vid)
-vid VIDEO, --video VIDEO
Path to video file (or YouTube link) to be used for inference (conflicts with -cam)
-dd, --disableDepth Disable depth information
-dnn, --disableNeuralNetwork
Disable neural network inference
-cnnp CNNPATH, --cnnPath CNNPATH
Path to cnn model directory to be run
-cnn CNNMODEL, --cnnModel CNNMODEL
Cnn model to run on DepthAI
-sh SHAVES, --shaves SHAVES
Number of MyriadX SHAVEs to use for neural network blob compilation
-cnnsize CNNINPUTSIZE, --cnnInputSize CNNINPUTSIZE
Neural network input dimensions, in "WxH" format, e.g. "544x320"
-rgbr {1080,2160,3040}, --rgbResolution {1080,2160,3040}
RGB cam res height: (1920x)1080, (3840x)2160 or (4056x)3040. Default: 1080
-rgbf RGBFPS, --rgbFps RGBFPS
RGB cam fps: max 118.0 for H:1080, max 42.0 for H:2160. Default: 30.0
-dct DISPARITYCONFIDENCETHRESHOLD, --disparityConfidenceThreshold DISPARITYCONFIDENCETHRESHOLD
Disparity confidence threshold, used for depth measurement. Default: 245
-lrct LRCTHRESHOLD, --lrcThreshold LRCTHRESHOLD
Left right check threshold, used for depth measurement. Default: 4
-sig SIGMA, --sigma SIGMA
Sigma value for Bilateral Filter applied on depth. Default: 0
-med {0,3,5,7}, --stereoMedianSize {0,3,5,7}
Disparity / depth median filter kernel size (N x N) . 0 = filtering disabled. Default: 7
-lrc, --stereoLrCheck
Enable stereo 'Left-Right check' feature.
-ext, --extendedDisparity
Enable stereo 'Extended Disparity' feature.
-sub, --subpixel Enable stereo 'Subpixel' feature.
-dff, --disableFullFovNn
Disable full RGB FOV for NN, keeping the nn aspect ratio
-scale SCALE [SCALE ...], --scale SCALE [SCALE ...]
Define which preview windows to scale (grow/shrink). If scale_factor is not provided, it will default to 0.5
Format: preview_name or preview_name,scale_factor
Example: -scale color
Example: -scale color,0.7 right,2 left,2
-cm {AUTUMN,BONE,CIVIDIS,COOL,DEEPGREEN,HOT,HSV,INFERNO,JET,MAGMA,OCEAN,PARULA,PINK,PLASMA,RAINBOW,SPRING,SUMMER,TURBO,TWILIGHT,TWILIGHT_SHIFTED,VIRIDIS,WINTER}, --colorMap {AUTUMN,BONE,CIVIDIS,COOL,DEEPGREEN,HOT,HSV,INFERNO,JET,MAGMA,OCEAN,PARULA,PINK,PLASMA,RAINBOW,SPRING,SUMMER,TURBO,TWILIGHT,TWILIGHT_SHIFTED,VIRIDIS,WINTER}
Change color map used to apply colors to depth/disparity frames. Default: JET
-maxd MAXDEPTH, --maxDepth MAXDEPTH
Maximum depth distance for spatial coordinates in mm. Default: 10000
-mind MINDEPTH, --minDepth MINDEPTH
Minimum depth distance for spatial coordinates in mm. Default: 100
-sbb, --spatialBoundingBox
Display spatial bounding box (ROI) when displaying spatial information. The Z coordinate get's calculated from the ROI (average)
-sbbsf SBBSCALEFACTOR, --sbbScaleFactor SBBSCALEFACTOR
Spatial bounding box scale factor. Sometimes lower scale factor can give better depth (Z) result. Default: 0.3
-s {nnInput,color,left,right,depth,depthRaw,disparity,disparityColor,rectifiedLeft,rectifiedRight} [{nnInput,color,left,right,depth,depthRaw,disparity,disparityColor,rectifiedLeft,rectifiedRight} ...], --show {nnInput,color,left,right,depth,depthRaw,disparity,disparityColor,rectifiedLeft,rectifiedRight} [{nnInput,color,left,right,depth,depthRaw,disparity,disparityColor,rectifiedLeft,rectifiedRight} ...]
Choose which previews to show. Default: []
--report {temp,cpu,memory} [{temp,cpu,memory} ...]
Display device utilization data
--reportFile REPORTFILE
Save report data to specified target file in CSV format
-monor {400,720,800}, --monoResolution {400,720,800}
Mono cam res height: (1280x)720, (1280x)800 or (640x)400. Default: 400
-monof MONOFPS, --monoFps MONOFPS
Mono cam fps: max 60.0 for H:720 or H:800, max 120.0 for H:400. Default: 30.0
-cb CALLBACK, --callback CALLBACK
Path to callbacks file to be used. Default: <project_root>/callbacks.py
--openvinoVersion {2020_3,2020_4,2021_1,2021_2,2021_3,2021_4}
Specify which OpenVINO version to use in the pipeline
--app APP Specify which app to run instead of the demo
--count COUNTLABEL Count and display the number of specified objects on the frame. You can enter either the name of the object or its label id (number).
-dev DEVICEID, --deviceId DEVICEID
DepthAI MX id of the device to connect to. Use the word 'list' to show all devices and exit.
-bandw {auto,low,high}, --bandwidth {auto,low,high}
Force bandwidth mode.
If set to "high", the output streams will stay uncompressed
If set to "low", the output streams will be MJPEG-encoded
If set to "auto" (default), the optimal bandwidth will be selected based on your connection type and speed
-gt {auto,qt,cv}, --guiType {auto,qt,cv}
Specify GUI type of the demo. "cv" uses built-in OpenCV display methods, "qt" uses Qt to display interactive GUI. "auto" will use OpenCV for Raspberry Pi and Qt for other platforms
-usbs {usb2,usb3}, --usbSpeed {usb2,usb3}
Force USB communication speed. Default: usb3
-enc ENCODE [ENCODE ...], --encode ENCODE [ENCODE ...]
Define which cameras to encode (record)
Format: cameraName or cameraName,encFps
Example: -enc left color
Example: -enc color right,10 left,10
-encout ENCODEOUTPUT, --encodeOutput ENCODEOUTPUT
Path to directory where to store encoded files. Default: /Users/vandavv/dev/depthai
-xls XLINKCHUNKSIZE, --xlinkChunkSize XLINKCHUNKSIZE
Specify XLink chunk size
-poeq POEQUALITY, --poeQuality POEQUALITY
Specify PoE encoding video quality (1-100)
-camo CAMERAORIENTATION [CAMERAORIENTATION ...], --cameraOrientation CAMERAORIENTATION [CAMERAORIENTATION ...]
Define cameras orientation (available: AUTO, NORMAL, HORIZONTAL_MIRROR, VERTICAL_FLIP, ROTATE_180_DEG)
Format: camera_name,camera_orientation
Example: -camo color,ROTATE_180_DEG right,ROTATE_180_DEG left,ROTATE_180_DEG
--cameraControlls Show camera configuration options in GUI and control them using keyboard
--cameraExposure CAMERAEXPOSURE [CAMERAEXPOSURE ...]
Specify camera saturation
--cameraSensitivity CAMERASENSITIVITY [CAMERASENSITIVITY ...]
Specify camera sensitivity
--cameraSaturation CAMERASATURATION [CAMERASATURATION ...]
Specify image saturation
--cameraContrast CAMERACONTRAST [CAMERACONTRAST ...]
Specify image contrast
--cameraBrightness CAMERABRIGHTNESS [CAMERABRIGHTNESS ...]
Specify image brightness
--cameraSharpness CAMERASHARPNESS [CAMERASHARPNESS ...]
Specify image sharpness
--skipVersionCheck Disable libraries version check
--noSupervisor Disable supervisor check
--sync Enable frame and NN synchronization. If enabled, all frames and NN results will be synced before preview (same sequence number)
We have added support for a number of different AI models that work (decoding and visualization) out-of-the-box with the demo. You can specify which model to run with -cnn argument, as shown above. Currently supported models:
- deeplabv3p_person
- face-detection-adas-0001
- face-detection-retail-0004
- human-pose-estimation-0001
- mobilenet-ssd
- openpose2
- pedestrian-detection-adas-0002
- person-detection-retail-0013
- person-vehicle-bike-detection-crossroad-1016
- road-segmentation-adas-0001
- tiny-yolo-v3
- vehicle-detection-adas-0002
- vehicle-license-plate-detection-barrier-0106
- yolo-v3
If you would like to use a custom AI model, see documentation here.
By default, the demo script will collect anonymous usage statistics during runtime. These include:
- Device-specific information (like mxid, connected cameras, device state and connection type)
- Environment-specific information (like OS type, python version, package versions)
We gather this data to better understand what environemnts are our users using, as well as assist better in support questions.
All of the data we collect is anonymous and you can disable it at any time. To do so, click on the "Misc" tab and disable sending the statistics or create a .consent file in repository root with the following content
{"statistics": false}
We are actively developing the DepthAI framework, and it's crucial for us to know what kind of problems you are facing. If you run into a problem, please follow the steps below and email [email protected]:
- Run
log_system_information.shand share the output from (log_system_information.txt). - Take a photo of a device you are using (or provide us a device model)
- Describe the expected results;
- Describe the actual running results (what you see after started your script with DepthAI)
- How you are using the DepthAI python API (code snippet, for example)
- Console output