简体中文 | English
Arcface-Paddle是基于PaddlePaddle实现的,开源深度人脸检测、识别工具。Arcface-Paddle目前提供了三个预训练模型,包括用于人脸检测的 BlazeFace、用于人脸识别的 ArcFace 和 MobileFace。
- 本部分内容为人脸识别部分。
- 人脸检测相关内容可以参考:基于BlazeFace的人脸检测。
- 基于PaddleInference的Whl包预测部署内容可以参考:Whl包预测部署。
注: 在此非常感谢 GuoQuanhao 基于PaddlePaddle复现了 Arcface的基线模型。
请参照 Installation 配置实验所需环境。
数据集可以从 insightface datasets 下载.
- MS1M_v2: MS1M-ArcFace
- MS1M_v3: MS1M-RetinaFace
python tools/mx_recordio_2_images.py --root_dir ms1m-retinaface-t1/ --output_dir MS1M_v3/当数据集抽取完后,输出的图像数据集目录结构如下:
MS1M_v3
|_ images
| |_ 00000001.jpg
| |_ ...
| |_ 05179510.jpg
|_ label.txt
|_ agedb_30.bin
|_ cfp_ff.bin
|_ cfp_fp.bin
|_ lfw.bin
标签文件格式如下:
# 图像路径与标签的分隔符: "\t"
# 以下是 label.txt 每行的格式
images/00000001.jpg 0
...
如果你想使用自定义数据集训练,可以根据以上目录结构和标签文件格式组织数据。
export CUDA_VISIBLE_DEVICES=1
python tools/train.py \
--config_file configs/ms1mv2_mobileface.py \
--embedding_size 128 \
--sample_ratio 1.0 \
--loss ArcFace \
--batch_size 512 \
--dataset MS1M_v2 \
--num_classes 85742 \
--data_dir MS1M_v2/ \
--label_file MS1M_v2/label.txt \
--fp16 False为了方便训练,已经为用户准备好训练启动脚本。
sh scripts/train_static.shsh scripts/train_dynamic.sh注:多机器多卡训练参见 paddle.distributed.launch API 文档。单机与多机训练不同之处在于多机需要设置 --ips 参数。
在训练过程中,你可以实时通过 VisualDL 可视化查看 loss 的变化,更多信息可以参考 VisualDL。
模型评价可以通过以下脚本启动
sh scripts/validation_static.shsh scripts/validation_dynamic.shPaddlePaddle 支持用预测引擎直接推理,首先,需要导出推理模型,通过以下脚本进行导出
sh scripts/export_static.shsh scripts/export_dynamic.sh模型推理过程支持 paddle 格式的 save inference model 和 onnx 格式。
sh scripts/inference.sh配置:
- CPU: Intel(R) Xeon(R) Gold 6184 CPU @ 2.40GHz
- GPU: a single NVIDIA Tesla V100
- Precison: FP32
- BatchSize: 64/512
- SampleRatio: 1.0
- Embedding Size: 128
- MS1MV2
| Model structure | lfw | cfp_fp | agedb30 | CPU time cost | GPU time cost | Inference model |
|---|---|---|---|---|---|---|
| MobileFace-Paddle | 0.9952 | 0.9280 | 0.9612 | 4.3ms | 2.3ms | download link |
| MobileFace-mxnet | 0.9950 | 0.8894 | 0.9591 | 7.3ms | 4.7ms | - |
- 注: MobileFace-Paddle 是使用 MobileFaceNet_128 backbone 训练出的模型
配置:
- GPU: 8 NVIDIA Tesla V100 32G
- Precison: Pure FP16
- BatchSize: 128/1024
| Mode | Datasets | backbone | Ratio | agedb30 | cfp_fp | lfw | log | checkpoint |
|---|---|---|---|---|---|---|---|---|
| Static | MS1MV3 | r50 | 0.1 | 0.98317 | 0.98943 | 0.99850 | log | checkpoint |
| Static | MS1MV3 | r50 | 1.0 | 0.98283 | 0.98843 | 0.99850 | log | checkpoint |
| Dynamic | MS1MV3 | r50 | 0.1 | 0.98333 | 0.98900 | 0.99833 | log | checkpoint |
| Dynamic | MS1MV3 | r50 | 1.0 | 0.98317 | 0.98900 | 0.99833 | log | checkpoint |
配置:
- GPU: 8 NVIDIA Tesla V100 32G (32510MiB)
- BatchSize: 64/512
- SampleRatio: 0.1
| Mode | Precision | Res50 | Res100 |
|---|---|---|---|
| Framework1 (static) | AMP | 42000000 (31792MiB) | 39000000 (31938MiB) |
| Framework2 (dynamic) | AMP | 30000000 (31702MiB) | 29000000 (32286MiB) |
| Paddle (static) | Pure FP16 | 60000000 (32018MiB) | 60000000 (32018MiB) |
| Paddle (dynamic) | Pure FP16 | 59000000 (31970MiB) | 59000000 (31970MiB) |
- 注:在跑实验前配置环境变量
export FLAGS_allocator_strategy=naive_best_fit
配置:
- BatchSize: 128/1024
- SampleRatio: 0.1
- Datasets: MS1MV3
- V100: Driver Version: 450.80.02, CUDA Version: 11.0
- A100: Driver Version: 460.32.03, CUDA Version: 11.2

更多实验结果可以参考 PLSC,PLSC (Paddle Large Scale Classification) 是 Paddle 官方开源的大规模分类库,支持单机 8 卡 NVIDIA V100 (32G) 训练 6000 千万类,目前还在持续更新中,请关注。
首先下载索引库、待识别图像与字体文件。
# 下载用于人脸识别的索引库,这里因为示例图像是老友记中的图像,所以使用老友记中角色的人脸图像构建的底库。
wget https://raw.githubusercontent.com/littletomatodonkey/insight-face-paddle/main/demo/friends/index.bin
# 下载用于人脸识别的示例图像
wget https://raw.githubusercontent.com/littletomatodonkey/insight-face-paddle/main/demo/friends/query/friends2.jpg
# 下载字体,用于可视化
wget https://raw.githubusercontent.com/littletomatodonkey/insight-face-paddle/main/SourceHanSansCN-Medium.otf检测+识别 串联预测的示例脚本如下。
# 同时使用检测+识别
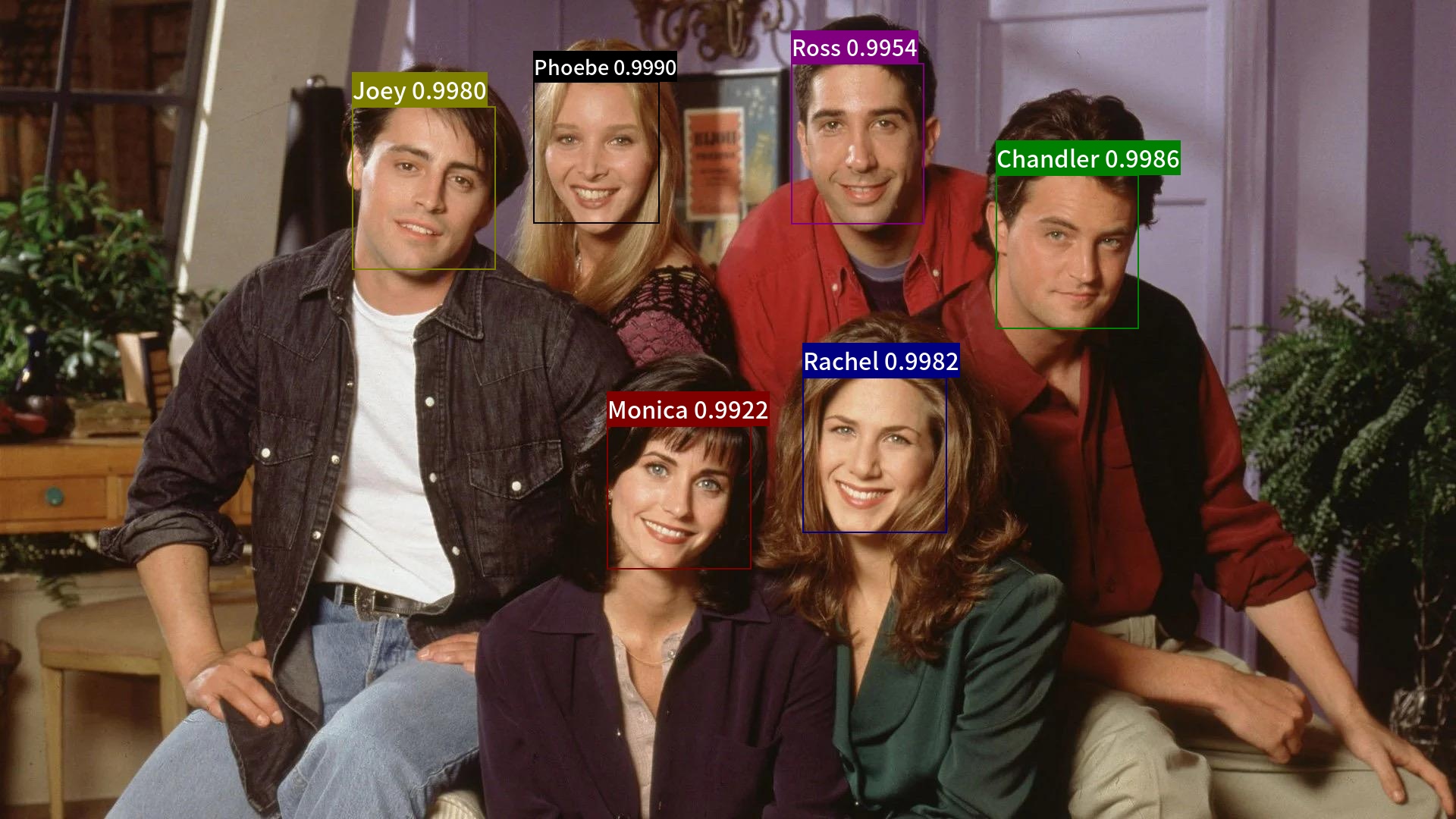
python3.7 tools/test_recognition.py --det --rec --index=index.bin --input=friends2.jpg --output="./output"最终可视化结果保存在output目录下,可视化结果如下所示。
更多关于参数解释,索引库构建、whl包预测部署和Paddle Serving预测部署的内容可以参考: