人工智能主要包括感知智能(比如图像识别、语言识别和手势识别等)和认知智能(主要是语言理解知识和推理)。它的核心是数据驱动来提升生产力、提升生产效率。
机器学习相关技术属于人工智能的一个分支。其理论主要分为如下三个方面:
- 传统的机器学习:包括线性回归、逻辑回归、决策树、SVM、贝叶斯模型、神经网络等等。
- 深度学习(Deep Learning):基于对数据进行表征学习的算法。好处是用非监督式或半监督式的特征学习和分层特征提取高效算法来替代手工获取特征。
- 强化学习(Reinforcement Learning):强调如何基于环境而行动,以取得最大化的预期利益。其灵感来源于心理学中的行为主义理论,即有机体如何在环境给予的奖励或惩罚的刺激下,逐步形成对刺激的预期,产生能获得最大利益的习惯性行为。和标准的监督式学习之间的区别在于,它并不需要出现正确的输入/输出对,也不需要精确校正次优化的行为。强化学习更加专注于在线规划,需要在探索(在未知的领域)和遵从(现有知识)之间找到平衡。
在现实生活中,机器学习技术主要体现在以下几个部分:
- 数据挖掘(Data Mining):发现数据间的关系
- 计算机视觉(CV - Computer Vision):让机器看懂世界
- 自然语言处理(NLP):让机器读懂文字
- 语音识别(Speech Recognition):让机器听懂
- 机器决策(Decision Making):让机器做决定,比如无人驾驶中的汽车控制决策
- 监督学习:训练数据中有我们想要预测的属性,也就是说对每一组 输入 数据,都有对应的 输出。问题可以分为两类:
- 分类问题:数据属于有限多个类别,希望从已标记数据中学习如何预测未标记数据的类别。
- 例子:手写数字的识别(0-9共10个类别)。
- 回归问题:每组数据对应的输出是一个或多个连续变量。
- 例子:是根据鲑鱼长度作为其年龄和体重。
- 分类问题:数据属于有限多个类别,希望从已标记数据中学习如何预测未标记数据的类别。
- 无监督学习:训练数据无对应的输出值。
- 例子:数据聚类、降维。
- 弱监督学习/半监督学习:
- 弱监督:标签里的数据存在质量低的情况;目的是将数据标签映射会更强的标签。
- 半监督:训练数据有部分没有标签。基本思想是利用数据分布上的模型假设, 建立学习器对未标签样本进行标签。比如样本存在聚类结构,同一个聚类中的标签应该相同;相邻样本的标签应该相同。
科学家们的定义:
- 机器学习是不显示编程地赋予计算机能力的研究领域。—— Arthur Samuel
- 机器学习研究的是从数据中产生模型(model)的算法。—— 周志华《西瓜书》
更通俗的理解:
- 根据已知的数据,学习一个数学函数(决策函数),使其可以对未知的数据做出响应(预测或判断)。
- 数据集(data set):为机器学习准备一组记录集合
- 样本(sample)或示例(instance):数据集中记录的关于一个事件或对象的记录
- 模型(model)
- 特征(feature)或属性(attribute)
- 样本空间(sample space)或属性空间(attribute space):属性张成的空间
- 特征向量(feature vector)
- 维数(dimensionality)
- 训练数据(training data)
- 训练集(training set)
- 训练样本(training sample)
- 假设(hypothesis)
- 真相(ground-truth)
- 标记(label)
- 分类(classification)
- 回归(regression)
- 正类(positive class)
- 反类(negative class)
- 多分类(multi-class classification)
- 测试(testing)
- 测试样本(testing sample)
- 监督学习(supervised learning):训练数据有标记信息
- 无监督学习(unsupervised learning):训练数据无标记信息
- 泛化(generalization):学得模型适用于新样本的能力称为泛化能力
- 分布(distribution)
- 独立同分布(independent and indentically distributed):每个样本都是独立地从一个分布上个采样获得的
- 归纳(induction):从具体事实归纳出一般规律
- 演绎(deduction):从一般到特化
- 血糖值预测:根据性别、年龄、血液各种参数(血小板、白蛋白等等)预测血糖值
- 有无糖料病预测:根据性别、年龄、血液各种参数预测有无糖尿病
- 图像分类
- 根据输入的手写数字图片,预测数字。或者我们数据库中有很多种动物,训练一种模型,能根据不同动物的图片预测其所属种类。
- 一个应用场景是手写支票的文字识别。
原始图像 --> 机器学习模型 --> 类别 - 目标检测
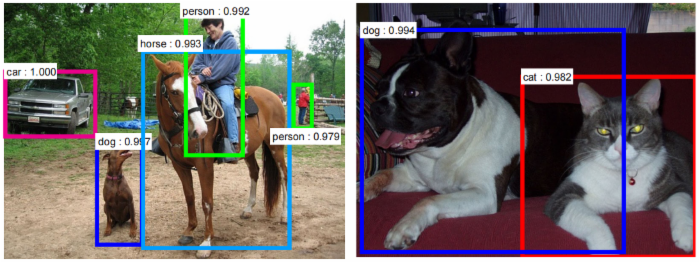
- 目标检测比图像分类更进一步,模型的输入是一副图像,输出是物体(Object)在图中的区域和类型。
- 比较典型的应用场景是无人驾驶领域。
原始图像 --> 机器学习模型 --> 标签(包括区域信息和类别) - 语义分割
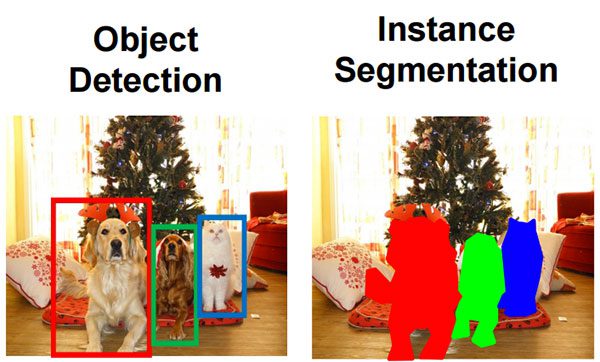
- 可以理解为是一个分类问题,从检测到的目标图像中,分割出和检测物体相关的像素点信息。
原始图像 --> 机器学习模型 --> 标签(包括区域信息、类别和物体包括的像素信息) - 场景理解
- 将图片中不同区域的图像分解为不同的区域和场景。
- 典型的案例还是无人驾驶,根据识别的场景,从而规划可行的路线。
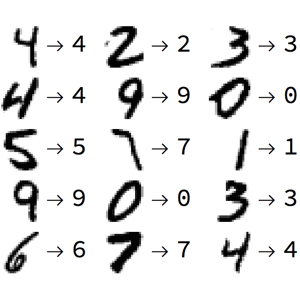

- 文本分类
- 输入新闻稿件,得到新闻所属的类别。
- 典型的案例是Google或百度的新闻自动聚合。
- 机器翻译
- 从一种语言文字翻译为另外一种语言文字。例如常用的Google翻译。
- 生成文章摘要
- 输入文章,生成文字摘要(abstract)
- 情感分析 (sentiment analysis)
- 包括情感分类(sentiment classification)、观点抽取(opinion extraction)、观点问答和观点摘要等。
- 应用案例:通过对微博文字的情感分析,获取客户对企业品牌的评价、分析营销活动的影响、民意调查等
- 问答系统
- 问答系统能够准确地理解以自然语言形式描述的用户提问,并通过检索异构语料库或问答知识库返回简洁、精确的匹配答案。当然除了NLP的技术外还涉及知识图谱等相关技术。
- 例如Apple Siri也是先将文字转换为文本,然后输入到问答系统。
- 人机系统
- 类似问答系统,不同的是人机系统不以获取答案为目的,甚至可以闲聊。例如微软小冰。
- 图像描述(image captioning)
- 输入图像,输出图像对应的文字描述。需要计算机视觉里的场景理解作为前提。
- 输入是语音数据,输出文本数据
- 比较常见应用的是语音输入法,现在几乎所有的手机都有类似功能。
- 自动驾驶(Autopilot):有一种端到端学习(End-to-End Learning)的技术。输入为图像和雷达数据,输出为车辆控制信号。
- 游戏AI:比如AlphaStar可以根据游戏屏幕数据操作键盘和鼠标,控制游戏里的角色。最新的消息是AlphaStar已经可以打败星际争霸2顶级职业玩家。
- 机器人:循环输入摄像头数据,输出机械臂等控制信号,以协助机械臂执行相应操作。可以应用在比如家用服务机器人、救援机器人、工业机器人手臂等。
上述几类问题大多需要深度学习+强化学习来解决。
传统机器学习算法 -> 深度学习 -> LLM(语言大模型) -> VLM(视觉和语言多模态)
循序渐进、系统掌握、有所专长