Chore/broswerfs deprecated issue 127 #93
Draft
Conversation
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
feat(bloom-filter): add support Add ability to create bloom filters on columns according to the apache [specs](https://github.com/apache/parquet-format/blob/master/BloomFilter.md). Co-authored-by: shannonwells <[email protected]> Co-authored-by: Wil Wade <[email protected]>
* Remove travis * Fix tiny syntax bug * Add org to name in package.json * Add templates for PRs and issues * Add GitHub Actions for testing and publishing * Linting not yet implemented * Commit the package-lock file for consistent builds
…uding directly (#6)
chore(README): update to include bloom filter Update README file to include bloom filter feature. Co-authored-by: Shannon Wells <[email protected]>
* use xxhash-wasm * updates after rebase * update tests due to new xxhash-wasm package * remove reference to old xxhash
* Cleanup package.json packages * Fix readme up * Thrift types * Update parquet thrift * Class requires new * Export Parquetjs Types
Add browser/node support for fetching http request.
* Configuration for bundling parquetjs that works in browser, via esbuild * Add to build targets * Fix all the things that got broken * Example server showing how it can be used * Updates to README * Disable LZO and Brotli in browser * Disable LZO in Node as a consequence of this attempt (see notes) * Use wasm-brotli: * Use async import to load wasm before loading compression.js * requires async loading to get the wasm instanc * bubble up all the asyncs * make the tests pass again * Webpack config file for possibly later * check in example parquet files Co-authored-by: enddy <[email protected]>
…ck (#19) * Add parquet.js explicitly to the "include" list in tsconfig. * Also regenerated package-lock.json to bump some patch versions.
Update bson package from 2.0.8 to 4.4.0 due to a vulnerability in v2. The interface changed, so update the files that use the package. Remove an unused TypeArray import. Remove a stray comment.
Co-authored-by: acruikshank <[email protected]>
* Added test cases for types and fixed bigint precision * missed one check on if statement * Added more test cases for invalid values to throw * Added test cases for real this time * Reorganized test cases and added helper function for readability and try catch for better error message * Fixed spacing on function * Added final tests to int64 and 96 * changed throw error code and fixed type on tests Co-authored-by: Wayland Li <[email protected]>
* Converted Independent files into typescript Co-authored-by: Wayland Li <[email protected]> Co-authored-by: Sidney Keese <[email protected]>
Co-authored-by: Wayland Li <[email protected]>
* Converted schema.js into typescript without using type any Co-authored-by: Wayland Li <[email protected]> Co-authored-by: Wayland Li <[email protected]>
* Converted shred.js into typescript without using type any Co-authored-by: Wayland Li <[email protected]> Co-authored-by: Wayland Li <[email protected]>
Converted util.js into typescript Co-authored-by: Wayland Li <[email protected]> Co-authored-by: Wayland Li <[email protected]>
* Converted reader file to typescript and made fixes dependent on it Co-authored-by: Wayland Li <[email protected]>
* Removed fixedTTransport class This may not be necessary, since we have upgraded Thrift to a version above 0.9.2. See https://github.com/apache/thrift/blob/master/CHANGES.md\#092 * Re-adding TFrameTransport patch so is supported.
* Blackbox tests for buffer reader * Sinon plugins for testing order * Integration tests + fixture
* Use parquet.ts not js * require -> import * Remove module.exports * Export default and types from parquet.ts
* Switch to import * Better optional types * Remove duplicated types * types/types -> declare for less confusion between types and types/types * Make sure thrift types pass through * Minimal WriteStream Interface * Fix an unknown type * Better openUrl Interface
* Clean up TIMESTAMP issues ZJONSSON#65 ZJONSSON#45 * Use MAX_SAFE_INTEGER for testing toPrimitive_TIME_MILLIS
Problem ======= This PR is intended to implement 2 enhancements to schema error reporting. * When a parquet schema includes an invalid type, encoding or compression the current error does not indicate which column has the the problem * When a parquet schema has multiple issues, the code currently fails on the first, making multiple errors quite cumbersome Solution ======== Modified the schema.ts and added tests to: * Change error messages from the original `invalid parquet type: UNKNOWN` to `invalid parquet type: UNKNOWN, for Column: quantity` * Keep track of schema errors as we loop through each column in the schema, and at the end, if there are any errors report them all as below: `invalid parquet type: UNKNOWN, for Column: quantity` `invalid parquet type: UNKNOWN, for Column: value` Change summary: --------------- * adding tests and code to ensure multiple field errors are logged, as well as indicating which column had the error * also adding code to handle multiple encoding and compression schema issues Steps to Verify: ---------------- 1. Download this [parquet file](https://usaz02prismdevmlaas01.blob.core.windows.net/ml-job-config/dataSets/multiple-unsupported-columns.parquet?sv=2020-10-02&st=2023-01-09T15%3A28%3A09Z&se=2025-01-10T15%3A28%3A00Z&sr=b&sp=r&sig=GS0Skk93DCn5CnC64DbnIH2U7JhzHM2nnhq1U%2B2HwPs%3D) 2. attempt to open this parquet with this library `const reader = await parquet.ParquetReader.openFile(<path to parquet file>)` 3. You should receive errors for more than one column, which also includes the column name for each error --------- Co-authored-by: Wil Wade <[email protected]>
Problem
=======
Often parquet files have a column of type `decimal`. Currently `decimal`
column types are not supported for reading.
Solution
========
I implemented the required code to allow properly reading(only) of
decimal columns without any external libraries.
Change summary:
---------------
* I made a lot of commits as this required some serious trial and error
* modified `lib/codec/types.ts` to allow precision and scale properties
on the `Options` interface for use when decoding column data
* modified `lib/declare.ts` to allow `Decimal` in `OriginalType`, also
modified `FieldDefinition` and `ParquetField` to include precision and
scale.
* In `plain.ts` I modified the `decodeValues_INT32` and
`decodeValues_INT64` to take options so I can determine the column type
and if `DECIMAL`, call the `decodeValues_DECIMAL` function which uses
the options object's precision and scale configured to decode the column
* modified `lib/reader.ts` to set the `originalType`, `precision`,
`scale` and name while in `decodePage` as well as `precision` and
`scale` in `decodeSchema` to retrieve that data from the parquet file to
be used while decoding data for a Decimal column
* modified `lib/schema.ts` to indicate what is required from a parquet
file for a decimal column in order to process it properly, as well as
passing along the `precision` and `scale` if those options exist on a
column
* adding `DECIMAL` configuration to `PARQUET_LOGICAL_TYPES`
* updating `test/decodeSchema.js` to set precision and scale to null as
they are now set to for non decimal types
* added some Decimal specific tests in `test/reader.js` and
`test/schema.js`
Steps to Verify:
----------------
1. Take this code, and paste it into a file at the root of the repo with
the `.js` extenstion:
```
const parquet = require('./dist/parquet')
async function main () {
const file = './test/test-files/valid-decimal-columns.parquet'
await _readParquetFile(file)
}
async function _readParquetFile (filePath) {
const reader = await parquet.ParquetReader.openFile(filePath)
console.log(reader.schema)
let cursor = reader.getCursor()
const columnListFromFile = []
cursor.schema.fieldList.forEach((rec, i) => {
columnListFromFile.push({
name: rec.name,
type: rec.originalType
})
})
let record = null
let count = 0
const previewData = []
const columnsToRead = columnListFromFile.map(col => col.name)
cursor = reader.getCursor(columnsToRead)
console.log('-------------------- data --------------------')
while (record = await cursor.next()) {
previewData.push(record)
console.log(`Row: ${count}`)
console.log(record)
count++
}
await reader.close()
}
main()
.catch(error => {
console.error(error)
process.exit(1)
})
```
2. run the code in a terminal using `node <your file name>.js`
3. Verify that the schema indicates 4 columns, including `over_9_digits`
with scale: 7, and precision 10. As well as a column `under_9_digits`
with scale: 4, precision: 6.
4. The values of those columns should match this table:
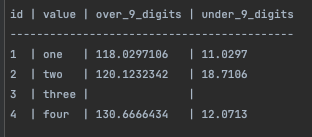
{kind=link}
Problem ======= We want it to be easier to build Parquet files (and thus the schema for those files) from existing schemas. In this case JSON Schemas Solution ======== Change summary: --------------- * Added field creation helper functions * Added static function `ParquetSchema.fromJsonSchema` that takes in a Json Schema Steps to Verify: ---------------- 1. Examples are in the tests, but take a JSON schema and call `ParquetSchema.fromJsonSchema` with it and see what it does --------- Co-authored-by: Shannon Wells <[email protected]> With assistance from @noxify
Problem ======= We need to update to Node16+ as 15.* is @ end-of-life. Closes #62, Fixes #85, a hasher bug Solution ======== Update to nodejs 16.15.1, update some packages and fix anything broken. **Important:** This revealed a bug in the Xxhasher code that was not converting to hex-encoded strings as the [bloom filter expects](https://github.com/LibertyDSNP/parquetjs/blob/2c733b5c7a647b9a8ebe9a13d300f41537ef60e2/lib/bloom/sbbf.ts#L357)
Problem ======= compression functions' return values are assumed to be Buffer objects. However, in reality they could be non-Buffer objects and will results in exceptions during reading/writing. #72 Solution ======== Detect the data type of the value from various compression libraries and convert the value to Buffer object if necessary before returning. Change summary: --------------- Ensure Buffer objects are returned by compression functions Steps to Verify: ---------------- As pointed out in the original issue, the problem can be reproduced using the browser build of parquetjs to read a file with snappy compression.
Problem ======= Need to support writing decimal types Also closes: #87 Solution ======== Add basic encoding support for decimals Change summary: --------------- * Added better decimal field errors * Default scale to 0 per spec * Cleanup types on RLE so it only asks for what is needed * Support decimal encoding * Add test for write / read of decimal Steps to Verify: ---------------- 1. Generate a schema with decimal field 2. Use it!
Problem ======= Parquet file column indexes are required to have `null_pages` and `boundary_order`, but they were missing from Parquetjs generated files. https://github.com/apache/parquet-format/blob/1603152f8991809e8ad29659dffa224b4284f31b/src/main/thrift/parquet.thrift#L955 Closes #92 Solution ======== Note: While required, the requirement is not always a hard requirement depending on the library. Steps to Verify: ---------------- 1. Checkout the branch 2. `npm i && npm run build && npm pack ` 3. Install parquet cli tools (macOS brew: `brew install parquet-cli`) 4. Checkout the bug repo from #92 https://github.com/noxify/parquetjs_bug/ 5. `cd parquetjs_bug/parquetjs && npm i` 6. `node index.js && parquet column-index ../generated_files/parquetjs/change.parque` will FAIL 7. npm i ../parquetjs/dsnp-parquetjs-0.0.0.tgz 8 `node index.js && parquet column-index ../generated_files/parquetjs/change.parque` will PASS!
Problem ======= Closes: #93 Solution ======== Add checks for `format == 'date-time`` inside the string type check for`string` and `array of string` Change summary: --------------- * Added format check for string fields ( and string arrays ) * Check for JSONSchema property `format` with value `date-time` * Updated jsonschema tests and updated the snapshots Steps to Verify: ---------------- 1. Generate a JSON Schema or use an existing one 2. Add `"format":"date-time"` to the field which should have a Date/Time value 3. Ensure that the value is a valid `Date` object 4. Enjoy
Problem ======= Address #91 Solution ======== When encountering such byte array represented "Decimal" fields, parse them into raw buffers. Change summary: --------------- - Added code to parse "Decimal" type fields represented by byte arrays (fixed length or non-fixed length) into raw buffer values for further client side processing. - Added two test cases verifying the added code. - Loosen the precision check to allow values greater than 18 for byte array represented "Decimal" fields. Steps to Verify: ---------------- - Use the library to open a parquet file which contains a "Decimal" field represented by a byte array whose precision is greater than 18. - Before the change, library will throw an error saying precision cannot be greater than 18. - After the change, library will parse those fields to their raw buffer values and return records normally. --------- Co-authored-by: Wil Wade <[email protected]>
Upgrade to nodejs 18+. Closes #83
For bloom filters, treat column names as the full path and not just the first part of the path in the schema. Closes #98 with @rlaferla Co-authored-by: Wil Wade <[email protected]>
Problem ======= Docs were wrong from a long time ago per ironSource#100 Solution ======== Updated the docs and added a simple test Closes #106
Problem ======= The JSON Schema stipulates that [a "number" type can be an integer, floating point, or exponential notation](https://json-schema.org/understanding-json-schema/reference/numeric). Currently, the "number" type is treated the same as an integer when instantiating `fromJSONSchema`. In those cases, providing a float value of e.g. `2.5` will fail because it can't be converted into a BigInt. Solution ======== I changed the primitive to Double for "number" types when creating a schema from JSON. Co-authored-by: Wil Wade <[email protected]>
Problem ======= problem statement - when trying to read a parquet file that was generated using V2 parquet and had RLE_DICTIONARY, got an error: invalid encoding: RLE_DICTIONARY #96 Reported issue: #96 Solution ======== What I/we did to solve this problem added: export * as RLE_DICTIONARY from './plain_dictionary'; ---------------- I added this line to an existing project in the node modules and it works. without this line I get an an error with this line added - it passed --------- Co-authored-by: Wil Wade <[email protected]>
… null instead of undefined (#114) Problem ======= We wanted to add tests for all the tests in https://github.com/apache/parquet-testing ### Discovered Bugs - We treated nulls as undefined, but others don't - We incorrectly processed dictionary_page_offset >= 0 instead of only > 0 Solution ======== - Added new test that automatically tests all files: `test/reference-test/read-all.test.ts` - Fixed found bugs with @shannonwells Steps to Verify: ---------------- 1. Run the tests 1. Comment out the bug fixes and see reference test files fail
…E_ARRAY (#108) Problem ======= typeLength is present in column options but decoding is throwing an error. `thrown: "missing option: typeLength (required for FIXED_LEN_BYTE_ARRAY)"` options object for reference: ``` { type: 'FIXED_LEN_BYTE_ARRAY', rLevelMax: 0, dLevelMax: 1, compression: 'SNAPPY', column: { name: 'BLOCK_NUMBER', primitiveType: 'FIXED_LEN_BYTE_ARRAY', originalType: 'DECIMAL', path: [ 'BLOCK_NUMBER' ], repetitionType: 'OPTIONAL', encoding: 'PLAIN', statistics: undefined, compression: 'UNCOMPRESSED', precision: 38, scale: 0, typeLength: 16, rLevelMax: 0, dLevelMax: 1 }, num_values: { buffer: <Buffer 00 00 00 00 00 00 27 10>, offset: 0 } } ``` using `parquet-tools schema` here is the schema for this column: ``` optional fixed_len_byte_array(16) BLOCK_NUMBER (DECIMAL(38,0)) ``` The parquet file is a direct export from snowflake and the data type of the column is `NUMBER(38,0)`. Solution ======== I traced through the code to find where the decode was erroring and added the ability to take the `typeLength` from `column` in the column options when it is not present at the top level. Change summary: --------------- see above Steps to Verify: ---------------- decode a parquet file with this type of field. --------- Co-authored-by: Wil Wade <[email protected]> Co-authored-by: Wil Wade <[email protected]>
Problem ======= Support AWS S3 V3 streams while retaining support for V2. V2 may be removed later. Closes #32 with @wilwade , @pfrank13 Change summary: --------------- * support V3 in reader.ts * add tests * use `it.skip` instead of commenting out test code. --------- Co-authored-by: Wil Wade <[email protected]>
- Buffer.slice -> Buffer.subarray (and correct test that wasn't using buffers) - new Buffer(array) -> Buffer.from(array) - Fix issue with `npm run serve` Via looking into #117 As `subarray` is slightly faster in the browser shim.
Problem ======= `typeLength`, and potentially `precision`, with value "null" causes incorrect primitive type detection result. Solution ======== We should handle the null values such that when the `typeLength` or `precisions` field is of value "null", its primitive type are detected as "INT64". Steps to Verify: The bug reproduces when the parquet file consists of a Dictionary_Page with a INT64 field whose typeLength is null upon read. Unfortunately, I don't have such a test file for now. My debugging was based on a piece of privately shared data from our customer. When the bug reproduces, the primitive type parsed from the schema (Fixed_Length_Byte_Array) won't match the primitive type discovered from the column data (Int64). Due to a discrepancy on how the library decodes data pages, when the data is in a Dictionary_Page, the decoding logic will hit the check for `typeLength` and fail. For Data_Page and Data_Page_V2, decoding ignores the schema and privileges the primitive type inferred from the column data. However, for Dictionary_Page, decoding uses the primitive type specified in the schema. decodeDataPageV2 https://github.com/LibertyDSNP/parquetjs/blob/91fc71f262c699fdb5be50df2e0b18da8acf8e19/lib/reader.ts#L1104 decodeDictionaryPage https://github.com/LibertyDSNP/parquetjs/blob/91fc71f262c699fdb5be50df2e0b18da8acf8e19/lib/reader.ts#L947 Notice that one uses "opts.type" while the other uses "opts.column.primitiveType".
Per @ MaTiAtSIE via #120 (comment) Switch from the older, non-maintained [wasm-brotli](https://github.com/dfrankland/wasm-brotli) to the newer and maintained [brotli-wasm](https://github.com/httptoolkit/brotli-wasm). Drop in swap, all tests still pass. Closes #120
Updated _almost_ all of the dependencies to the latest version.
- Bson updates required a few small changes due to es module updates in
bson
- Did *not* update chai past v4. Looks like moving past chai v4 would
require many changes and not all the chai plugins we are using support
it yet. Perhaps we should just move away from chai instead.
- Moved from ts-node to tsx
- Updates for `msw` breaking changes, but nothing special for our use
cases.
- Github actions with node no longer needs a separate cache step
## Suggested Tests
- Locally build and run tests
- Try it out with:
- `npm i && npm run build && npm run serve`
- `cd examples/server && npm i && node app.js`
- Then go to `http://localhost:3000`, open up the console and hit some
buttons.
Review Note: I split this into different commits so it would be easy to review that which wasn't automatically applied. I suggest reviewing those commits instead of every line. Problem ======= Styles and potential issues were all over without enforcing linting and formatting. Closes: #34 Solution ======== Added linting and formatting. Change summary: --------------- * Added eslint * Added Prettier * Checked to make sure it was setup in CI Steps to Verify: ---------------- 1. npm i 2. npm run lint 3. npm run format 4. npm run lint:fix
Update the project to use ZenFs instead of BrowserFs, as BrowserFs is now deprecated. issue-127
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
Add this suggestion to a batch that can be applied as a single commit.
This suggestion is invalid because no changes were made to the code.
Suggestions cannot be applied while the pull request is closed.
Suggestions cannot be applied while viewing a subset of changes.
Only one suggestion per line can be applied in a batch.
Add this suggestion to a batch that can be applied as a single commit.
Applying suggestions on deleted lines is not supported.
You must change the existing code in this line in order to create a valid suggestion.
Outdated suggestions cannot be applied.
This suggestion has been applied or marked resolved.
Suggestions cannot be applied from pending reviews.
Suggestions cannot be applied on multi-line comments.
Suggestions cannot be applied while the pull request is queued to merge.
Suggestion cannot be applied right now. Please check back later.
No description provided.