클러스터: 쿠버네티스를 배포하면 클러스터를 얻는다. 실행 중인 쿠버네티스라고 보아도 된다.
- 다양한 배포 방식
Deployment,StatefulSets,DaemonSet,Job,CronJob
- Ingress(입장) 설정
- 클라우드 지원
- 컨트롤 플레인 컴포넌트의 cloud-controller-manager를 통해 여러 클라우드와 상호작용할 수 있다.
- Namespace & Label
- RBAC (role-based access control)
- 접근 권한 시스템, AWS의 IAM처럼 클라우드 서비스와 연동해서도 사용 가능
- CRD (Custom Resource Definitaion)
- 쿠버네티스가 제공하지 않는 기능을 기본 기능과 동일한 방식으로 적용하고 사용할 수 있다.
- (내 생각: 확장성이 좋다는 이야기로 보임)
- Auto Scaling
- 리소스 사용량 뿐만 아니라 현재 접속자 수와 같은 다양한 조건 사용 가능, 컨테이너의 개수, 리소스 할당량 등을 조정 가능
- Federation, Multi Cluster
- 클라우드에 설치한 쿠버네티스 클러스터와 자체 서버에 설치한 쿠버네티스를 묶어서 하나로 사용할 수 있다.
-
- 원하는 상태를 정의
- 현재 상태를 지속적으로 모니터링하며 현재 상태와 원하는 상태가 다르면 원하는 상태와 현재 상태가 일치하도록 작업하고, 이러한 모니터링과 처리를 반복한다.
- 명령(imperative)대신 선언(declarative) - (내 생각: 약간 테라폼처럼 IaC같은 느낌의 사용법인듯)
-
- 쿠버네티스는 상태를 관리하기 위한 대상을 오브젝트로 정의한다. 수십 종류가 있고, 확장 가능하다.
-
- 쿠버네티스에서 배포할 수 있는 가장 작은 단위
- 한 개 이상의 컨테이너와 스토리지, 네트워크 속성을 가진다.
- Pod에 속한 컨테이너는 스토리지와 네트워크를 공유하고 서로 localhost로 접근할 수 있습니다.
- 있다는거지 항상 그렇다는건 아님 (아마도?)
-
- Pod을 한 개 이상 복제하여 관리하는 오브젝트
- 복제할 개수, 개수를 체크할 라벨 선택자, 생성할 Pod의 설정값(템플릿)등을 가지고 있다.
- 직접 다루기보단 다른 오브젝트에 의해 사용됨
-
- 네트워크와 관련된 오브젝트
- Pod을 외부 네트워크와 연결해주고 여러 개의 Pod을 바라보는 내부 로드 밸런서를 생성할 때 사용한다.
- 내부 DNS에 서비스 이름을 도메인으로 등록하기 때문에 서비스 디스커버리 역할도 한다.
-
- 저장소와 관련된 오브젝트
- 호스트 디렉토리, AWS EBS 클라우드 스토리지를 동적으로 생성하여 사용할 수도 있다
- 많은 저장 방식 지원
-
- 오브젝트의 명세는 YAML 파일(JSON도 가능하다고 하지만 잘 안 씀)로 정의하고 여기에 오브젝트의 종류와 원하는 상태를 입력한다.
- 종류 - 참고
- apiVersion: 사용할 k8s 버전
- kind: 어떤 오브젝트인지
- metadata: 메타 정보, 이름이나 레이블
- spec: 오브젝트를 생성할 때 리소스에 원하는 특징(의도한 상태)에 대한 설명. 오브젝트마다 많이 다름
-
- 애플리케이션을 배포하기 위해 원하는 상태(desired state)를 다양한 오브젝트(object)에 라벨Label을 붙여 정의(yaml)하고 API 서버에 전달하는 방식을 사용한다.
쿠버네티스 클러스터 구성 요소

-
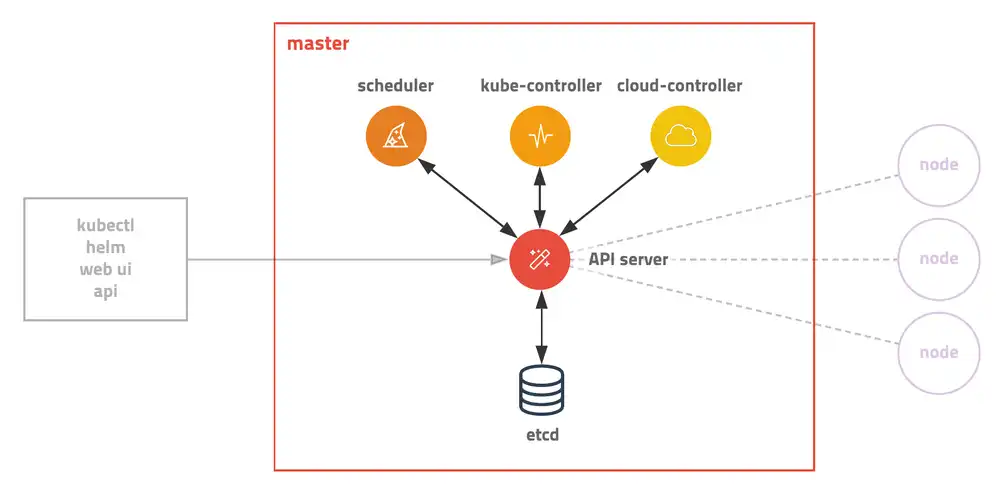
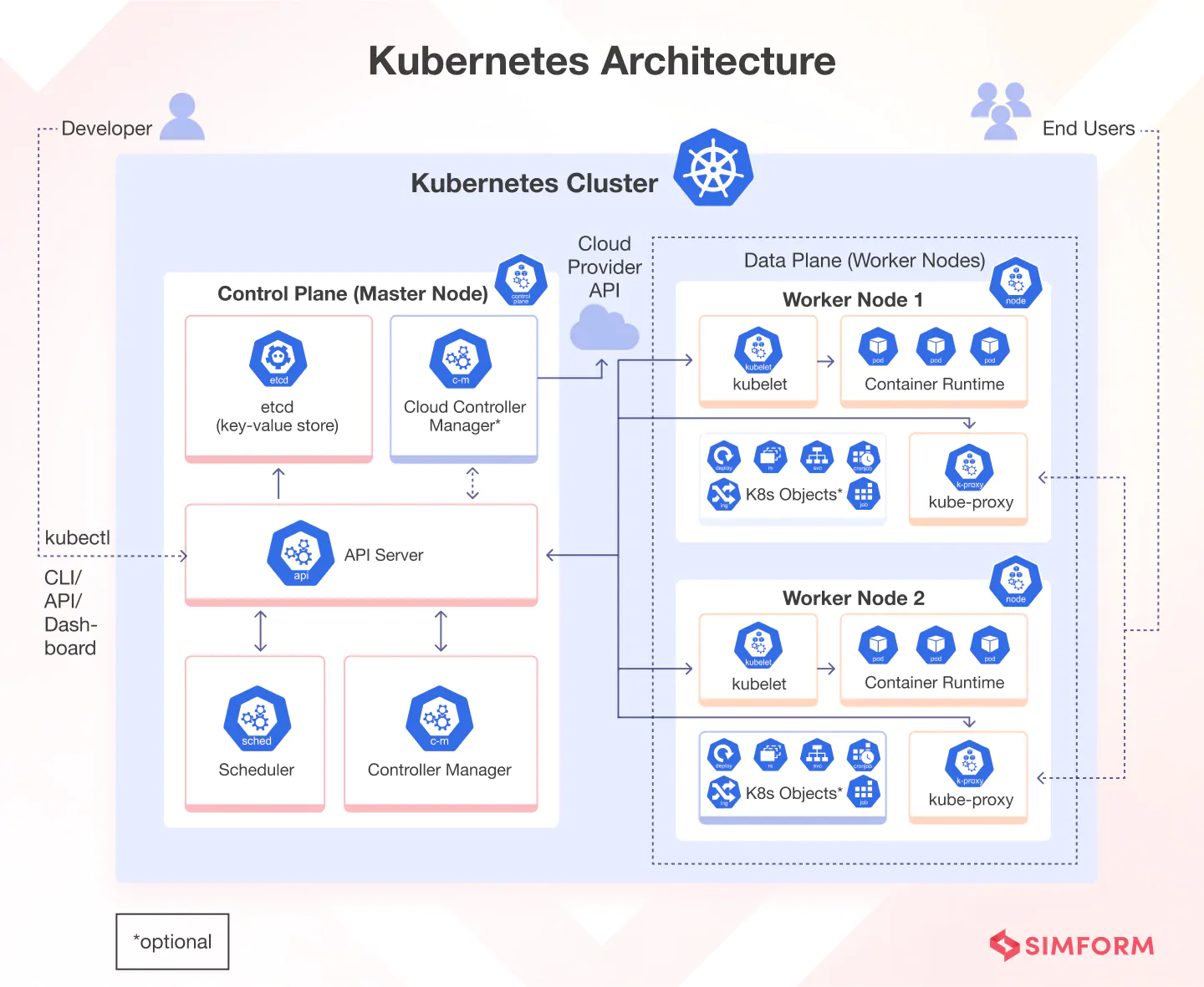
- 전체 클러스터를 관리하는 마스터와 컨테이너가 배포되는 노드로 구성되어 있다.
- 모든 명령은 마스터의 API서버를 호출하고, 노드는 마스터와 통신하면서 필요한 작업을 수행한다.
-
- 마스터는 다양한 모듈이 기능별로 쪼개져 있다.
- 마스터가 살아있어야 클러스터를 관리할 수 있으므로 보통 3대를 구성하여 안전성을 높인다.
- 보통 Node와 분리된 위치에서 관리
-
- 마스터 서버와 통신하면서 필요한 Pod을 생성하고 네트워크와 볼륨을 설정한다.
- 실제 컨테이너들이 생성되는 곳으로 수백, 수천대로 확장할 수 있다.
-
- API와 통신하기 위한 명령행 도구
- 공식적으로 큐브컨트롤이라고 읽지만, 큐브씨티엘, 쿱컨트롤, 쿱씨티엘 등으로도 부른다.
-
- 쿠버네티스 API를 노출하는 쿠버네티스 컨트롤 플레인의 프론트 엔드이다.
- 모든 요청을 받는다.
- 수평 확장(scale out)이 가능하게 설계되었다.
-
- 모든 클러스터 데이터를 담는 쿠버네티스 뒷단의 저장소로 사용되는 일관성·고가용성 키-값 저장소.
- 모든 클러스터 데이터를 담는 만큼 백업은 필수이다.
-
- 노드가 배정되지 않은 새로 생성된 파드 를 감지하고, 실행할 노드를 선택하는 컨트롤 플레인 컴포넌트.
- 적절한 노드를 선택하기 위해 수많은 요소를 고려한다.
-
- 컨트롤러 프로세스를 실행하는 컨트롤 플레인 컴포넌트.
- 컨트롤러 프로세스: kube-apiserver를 통해 클러스터의 공유된 상태를 감시하고, 현재 상태를 원하는 상태로 이행시키는 피드백 루프.
- Node, EndpointSlice, Job 등 여러 컨트롤러가 있다.
- 컨트롤러 프로세스: kube-apiserver를 통해 클러스터의 공유된 상태를 감시하고, 현재 상태를 원하는 상태로 이행시키는 피드백 루프.
- 논리적으로 분리된 여러 개의 프로세스지만, 복잡성을 낮추기 위해 모두 단일 바이너리로 컴파일되고 단일 프로세스 내에서 실행된다.
- 컨트롤러 프로세스를 실행하는 컨트롤 플레인 컴포넌트.
-
- 클라우드별 컨트롤 로직을 포함하는 쿠버네티스 컨트롤 플레인 컴포넌트이다.
- 클러스터를 클라우드 공급자의 API에 연결하고, 해당 클라우드 플랫폼과 상호 작용하는 컴포넌트와 클러스터와만 상호 작용하는 컴포넌트를 구분할 수 있게 해 준다.
- 클라우드 제공자 전용 컨트롤러만 실행한다. local이나 직접 관리하는 쿠버네티스는 cloud-controller-manager가 없다.
- kube-controller-manager와 동일하게 논리적인 여러 프로세스를 단일 프로세스로 실행한다.
- 노드 컨트롤러, 라우트 컨트롤러, 서비스 컨트롤러는 CSP의 의존성을 가질 수 있다.
- 동작 중인 파드를 유지시키고 쿠버네티스 런타임 환경을 제공하며, 모든 노드 상에서 동작한다.
-
- 노드에 할당된 Pod의 생명주기를 관리한다.
- Pod을 생성하고 Pod 안의 컨테이너에 이상이 없는지 확인하면서 주기적으로 마스터에 상태를 전달한다.
- API 서버의 요청을 받아 컨테이너의 로그를 전달하거나 특정 명령을 대신 수행하기도 한다.
-
- 클러스터의 각 노드에서 실행되는 네트워크 프록시로, 쿠버네티스의 서비스 개념의 구현부이다.
- 노드의 네트워크 규칙을 유지 관리한다. 이 네트워크 규칙이 내부 네트워크 세션이나 클러스터 바깥에서 파드로 네트워크 통신을 할 수 있도록 해준다.
- 초기에는 직접 프록시 서버로서 요청을 받았지만 요즘에는 성능상의 이슈로 iptables, IPVS를 사용한다.
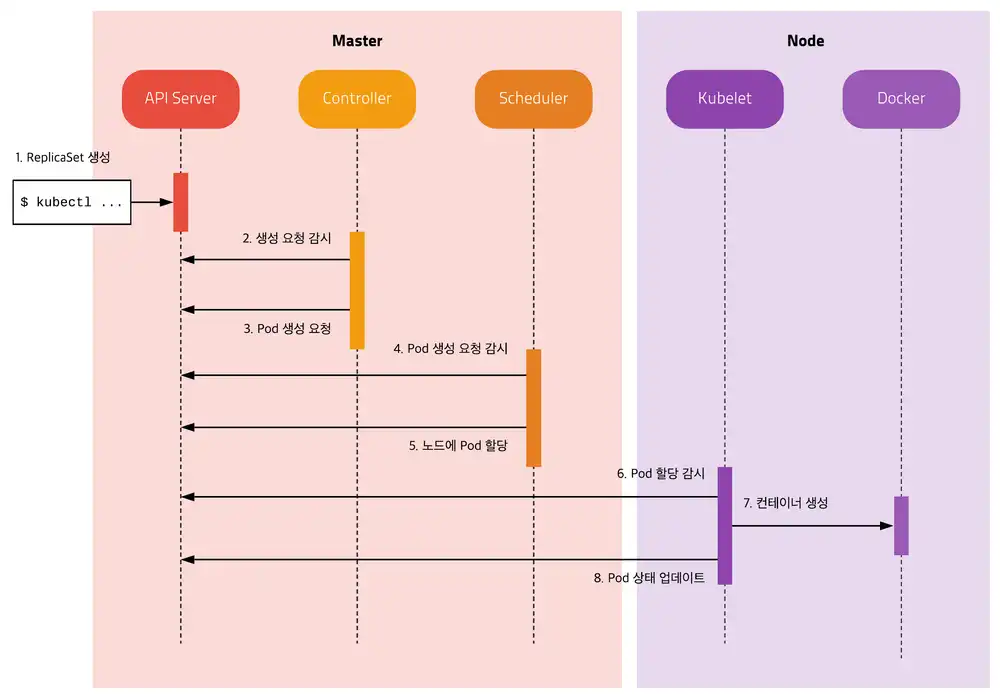
- (내 생각: 위 이미지에는 End Users가 kube-proxy를 의존하지만, 논리적으로는 서비스를 의존해야 할 듯)
-
- 컨테이너 실행을 담당하는 소프트웨어이다.
- CRI를 구현한 다양한 컨테이너 런타임을 지원한다. (containerd, rkt, CRI-O)
- 쿠버네티스 시작하기 - Kubernetes란 무엇인가?
- 쿠버네티스 컴포넌트 - 이 외의 공식문서도 일부 참고