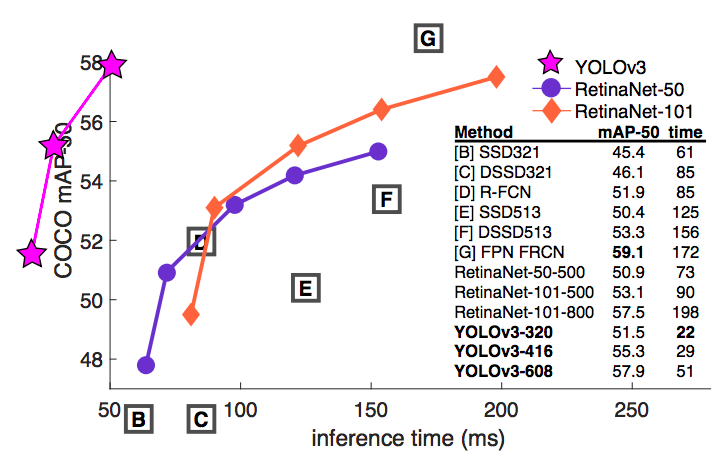
You only look once (YOLO) is a state-of-the-art, real-time object detection system. On a Pascal Titan X it processes images at 30 FPS and has a mAP of 57.9% on COCO test-dev.
- Paper: YOLOv3: An Incremental Improvement (2018)
- Framework: Darknet
- Input resolution: 320x320, 416x416 (and other multiple of 32)
- Pretrained: COCO
- Weights size: ~250 mb
- Work modes: train, inference, deploy
- Usage example: Multi-class object detection using YOLO V3

General train configuration available in model presets.
Also you can read common training configurations documentation.
lr- Learning rate.epochs- the count of training epochs.batch_size- batch sizes for training (train) stage.input_size- input images dimensionwidthandheightin pixels.bn_momentum- batch normalization momentum parameter.gpu_devices- list of selected GPU devices indexes.data_workers- how many subprocesses to use for data loading.dataset_tags- mapping for split data to train (train) and validation (val) parts by images tags. Images must be tagged bytrainorvaltags.subdivisions- split batch on subbatches (if big batch size does not fit to GPU memory).special_classes- objects with specified classes will be interpreted in a specific way. Default class name forbackgroundisbg, default class name forneutralisneutral. All pixels fromneutralobjects will be ignored in loss function.print_every_iter- allow to output training information everyNiterations.weights_init_type- can be in one of 2 modes. Intransfer_learningmode all possible weights will be transfered except last layer. Incontinue_trainingmode all weights will be transfered and validation for classes number and classes names order will be performed.enable_augmentations- current implementation contains strong augmentation system. If you want to use it selecttrueorfalseotherwise.
Full training configuration example:
{
"lr": 0.0001,
"epochs": 10,
"batch_size": {
"train": 8
},
"input_size": {
"width": 416,
"height": 416
},
"bn_momentum": 0.01,
"gpu_devices": [0],
"data_workers": {
"train": 3
},
"dataset_tags": {
"train": "train"
},
"subdivisions": {
"train": 1
},
"print_every_iter": 10,
"weights_init_type": "continue_training",
"enable_augmentations": true
}For full explanation see documentation.
model - group contains unique settings for each model:
-
gpu_device- device to use for inference. Right now we support only single GPU. -
confidence_tag_name- name of confidence tag for predicted bound boxes.
mode - group contains all mode settings:
-
name- mode name defines how to apply NN to image (e.g.full_image- apply NN to full image) -
model_classes- which classes will be used, e.g. NN produces 80 classes and you are going to use only few and ignore other. In that case you should setsave_classesfield with the list of interested class names.add_suffixstring will be added to new class to prevent similar class names with exisiting classes in project. If you are going to use all model classes just set"save_classes": "__all__".
Full image inference configuration example:
{
"model": {
"gpu_device": 0,
"confidence_tag_name": "confidence"
},
"mode": {
"name": "full_image",
"model_classes": {
"save_classes": "__all__",
"add_suffix": "_yolo"
}
}
}