Autoři výsledku: Marie Haškovcová, Zdenko Vozár, Jan Škvrňák, Tomáš Foltýn, Michaela Bežová, Jaroslav Kvasnica, Jan Lehečka, Pavel Ircing, Jan Švec, Luboš Šmídl, Vlasta Radová, Josef Michálek, Matouš Pilnáček, Paulína Tabery
WACloud: Centralizované rozhraní pro vytěžování velkých dat z webového archivu je nástroj, který umožňuje badatelům práci s archivními webovými daty. Pro generování a kategorizaci textových výstupů využívá pokročilé postupy strojového zpracování a pomocí fulltextového a fasetového vyhledávání nabízí široké možnosti definice datových setů. Badatelé tak mohou na základě svých požadavků získávat relevantní data pro svůj další výzkum. Analýza témat a jejich automatická detekce je založena na základě hlubokých neuronových sítí, používány jsou i postupy rozpoznávání informací z video nebo audio souborů. Rozhraní umožňuje získávání datasetů napříč daty webového archivu, což otevírá nové možnosti pro jejich analýzu.
WACloud se skládá z následujících částí dodávaných Západočeskou univerzitou v Plzni (ZČU) a společností inQool a.s.:
- nástroj na zpracování vstupních dat (dále jen ArchiveProcessor, dodavatel ZČU),
- backend aplikace s HTTP REST aplikačním rozhraním (WACloud API, dodavatel inQool),
- frontend aplikace s uživatelským prostředím (WACloud UI, dodavatel inQool),
- exportér do WARC archivů (WARC ExportApp, dodavatel inQool).
Níže je uveden stručný popis jednotlivých komponent a informace o tom, na jaké technologii jsou postaveny.
Nástroj ArchiveProcesor zpracovává záznamy z Webarchivu pomocí metod strojového učení a zpracovaná data obohacená o vytěžená metadata ukládá v definovaném formátu buď do souborů nebo do databáze HBase.
Pro paralelizaci výpočtů se používá PySpark. Na základě konfigurace Sparku, která je součástí nástroje ArchiveProcessor, je možné nástroj spustit lokálně na jednom stroji nebo na celém Hadoop clusteru.
Nástroj je implementován v jazyce Python, který nabízí velké množství balíčků pro strojové učení (např. algoritmy pro data mining, klasifikátory, hluboké neuronové sítě atd.). Tyto algoritmy lze pak snadno zapojit do procesu zpracování dat při zachování MapReduce filozofie celého procesu. Podporované vstupní formáty:
- Kolekce WARCů – záznamy jsou načítány pomocí balíku warcio a zkonvertovány do formátu PySpark dataframe. Každý WARC soubor je zpracován jako jedna úloha (task) jedním exekutorem.
- Hlavní HBase tabulka, ze které jsou záznamy načteny do formátu PySpark dataframe.
Podporované typy záznamů:
- response – odpověď serveru obsahující tělo webové stránky
- revisit – záznamy označující, že webová stránka byla znovu navštívena, ale od poslední návštěvy se nezměnila
Po načtení vstupních dat do formátu PySpark dataframe prochází záznamy jednotlivými algoritmy, které mohou záznam obohacovat o další metadata. Sekvenci algoritmů, která se na záznamy aplikuje, lze nastavit vstupním parametrem nástroje. Po zpracování je každý záznam konvertován do požadovaného formátu a uložen.
Podporované výstupní formáty:
- Hlavní HBase tabulka, kde je každý záznam uložen jako jeden řádek s jeho UUID jakožto unikátním klíčem. Jednotlivé sloupce, které jsou pro každý řádek ukládány, lze nastavit v konfiguraci nástroje.
- Textový soubor se záznamy rozloženými do sloupců stejně jako v případě výstupu do hlavní HBase tabulky. Soubor může být uložen do HDFS nebo na lokální FileSystem jednotlivých výpočetních uzlů.
- Speciální ad-hoc textový soubor pro jednorázové výstupy ve formátech, které nejsou přímo podporovány exportní aplikací.
Protože archiv obsahuje různé typy dat, je možné pro každý podporovaný multimediální typ (MIME typ) definovat specifickou sekvenci algoritmů, kterými budou záznamy tohoto typu postupně zpracovány. Typicky používáme jiné algoritmy pro zpracování textu, obrázků a audio/video záznamů.
Podporované skupiny MIME typů záznamů (lze nastavit v konfiguraci nástroje):
- HTML – webové stránky (MIME typy text/html + aapplication/xhtml+xml)
- PDF – dokumenty pdf (MIME typ application/pdf)
- IMG – obrázky (MIME typy images/*)
- AV – audio, video (MIME typy audio/* + video/*)
Hardwarové nároky tohoto nástroje závisí na náročnosti modelů, které se při zpracování v jednotlivých algoritmech používají. Minimální požadavky na každý exekutor: 1 CPU, 8 GB RAM.
Aplikace napsaná v programovacím jazyce Java verze 8 s využitím frameworku Spring Boot, která vytváří aplikační rozhraní HTTP REST. Získává data z ArchiveProcessoru, indexuje je a poskytuje rozhraní pro vytváření dotazů nad nimi. Zahrnuje ověřování a autorizaci spolu se správou uživatelských účtů. Minimální systémové požadavky aplikace jsou:
- 2 CPU
- 4 GB RAM
- 20 GB disk
V případě disku je třeba mít na paměti, že většina dat je uložena v podpůrných komponentách, jako jsou HadoopFS, HBase, Solr a PostgreSQL. Velikost prvních tří závisí na počtu a velikosti zpracovávaných archivů WARC. Velikost PostgreSQL závisí na počtu a velikosti exportů (ať už výsledků dotazů nebo exportů archivů WARC). Podobně je třeba počítat s tím, že podpůrné komponenty budou vyžadovat vyšší nároky na CPU a RAM.
Zdrojový kód aplikace lze nalézt na adrese: https://github.com/WebarchivCZ/WACloud ve složce api.
Webová aplikace napsaná v jazyce JavaScript pomocí knihovny React JS. Připojí se k rozhraní API, vůči kterému se autentizuje, a zobrazí data, která z něj obdrží. Obsahuje formulář pro zadávání uživatelských dotazů, zobrazení historie dotazů a také administrační část se správou uživatelů, sklizní a dotazů. Rozhraní UI je podrobněji popsáno v části Uživatelská dokumentace.
Aplikace není náročná na systémové prostředky, takže si vystačí s 1 CPU a asi 250 MB RAM. Zdrojový kód aplikace lze nalézt na adrese: https://github.com/WebarchivCZ/WACloud ve složce client.
Aplikace napsaná v jazyce Python pomocí knihovny Flask k vytvoření rozhraní REST API. Slouží k vytvoření WARC archivu ze zadaných dat zpracovaných ArchiveProcessorem. Zdrojový kód aplikace lze nalézt na adrese: https://github.com/WebarchivCZ/WACloud_ExportApp.
Aplikace není náročná na systémové prostředky, takže si vystačí s 1 CPU a asi 250 MB RAM.
Komponenty, které jsou vyžadovány hlavními komponentami:
- cluster se službami Hadoop a Spark (dále jen Cluster),
- HBase databáze (HBase),
- indexovací nástroj Solr pro základ dotazu (Solr BaseCore),
- indexovací nástroj Solr pro analytické dotazy (Solr QueryCore),
- PostgreSQL databáze (PostgreSQL).
Každá podpůrná komponenta má svůj vlastní účel a je využívána jednou nebo více hlavními komponentami.
Slouží k ukládání vstupních dat ve formátu WARC v distribuovaném souborovém systému HadoopFS a ke spouštění dotazů ve službě Spark nad těmito distribuovanými daty. Cluster je provozován v prostředí NKP. Je implementován v struktuře:
- 1x Aplikační node využívající zdroje clusteru pro Solr a zejména HBase a provozující frontendovou aplikaci WACloud v dockeru
- 1x Name node: provozující koordinační služby HDFS klastru (hlídání a přidělování prostředků, mapování a redukce dat, pouštění a plánování úkolů) a koordinace HBASE databáze. Name node obsahuje dále instalaci WACloud exportéra a jeho běžící službu pro koordinaci s frontendovou aplikací
- 4x Data node: provozující datové úložiště na discích organizovaných pomocí přístupu JBOD a orchestrovaných name nodem. Data node dále podporuje datové a výpočetní operace HDFS a SPARK
Implementace všech řešení stacku je realizována primárně prostřednictvím Bigtop 3.11 a nástroje Puppet pro orchestraci konfigurace a automatizaci nasazování. Obsahuje kromě velkého množství knihoven tyto prvky v následujících verzích:
- (ambari 2.7.5 client)
- bigtop-utils 3.1.1
- hadoop 3.2.4
- hbase 2.4.11
- solr 8.11.1
- spark 3.1.2
- zookeeper 3.5.9
Name node provozuje daemony dostupné z výpisu Java Virtual Machine Process Status Tool (JPS): Master, HMaster, QorumPeer, ResourceMaster, Jps, NameNode, HRegionServer, ThriftServer, JobHistoryServer, WebAppProxyServer, NodeManager
Data node provozuje daemony: Jps, NodeManager,QuorumPeerMain, DataNode
Provozní cluster momentálně poskytuje kapacitu o velikosti 164 TB, tj. 41 TB per DataNode. Data jsou ukládána při nastavení trojnásobného replikačního faktoru, tj. nacházejí se vždy ve třech instancích, tak aby byla zajištěna resilience clusteru jako celku i při výpadku jeho jednotlivých nodů. Datová komunikace mezi všemi nody podporuje dedikovaná linka na metalickém 10 GBit Huawei switch.
Řešení bylo původně implementováno pomocí Ambari 2.7.5, ale změna (zpoplatnění) přístupu k repozitářum znemožnilo dále používat tuto konfigurační, orchestrační a monitorovací platformu, a proto původní testovací prostředí není již dále podporováno.
Pro samotný provoz výpočetních úkolů na clusteru je pomocí Anacondy nainstalován Python s dalšími závislostmi analytického skriptu ArchiveProcessor (viz. níže) a na každém data nodu rozdistribuován model pro identifikaci témat, tak aby ho nebylo nutné přenášet vždy při novém výpočetním úkolu. Cluster neobsahuje model pro analýzu zvuku, který je udržován v prostředí ZČU.
Pro každý node v clusteru je požadovaný Python verze 3.7 a vyšší (všechny nody musí mít stejnou verzi). Vyžadované jsou i nasledující balíčky: jsonschema, justext v3.0, NLTK s Punkt corpusem, scikit-learn, pyspark, lxml, happybase, keras, tensorflow, keras-bert.
Databáze NoSQL, která uchovává informace o spuštění a výsledcích ArchiveProcessoru. V samostatné tabulce vede seznam všech zpracovaných sklizní a v další tabulce seznam všech zpracovaných záznamů. Obsahuje také konfigurační tabulku, ve které je uložen například číselník témat a typů stránek. Podrobnější popis tabulek naleznete v dokumentu Popis tabulek HBase databáze.
Index obsahující základní metadata jednotlivých záznamů z databáze HBase bez jejich plaintextu. Slouží k vytvoření základu dotazu, kdy dotaz omezuje rozsah zpracovávaných záznamů. Proto obsahuje a indexuje ta pole, která lze vložit do základu dotazu, jako jsou url, datum sklizně, id a typ sklizně, typ stránky, jazyk stránky, seznam témat a sentiment.
Index obsahující data potřebná ke zpracování analytických dotazů, jako je rok, úplná url, doména, doména nejvyšší úrovně, název stránky, seznam nadpisů, odkazy a plaintext. Pravidelně se promazává pro každou sadu analytických dotazů. Vždy je vyplněn záznamy, které byly určeny základem dotazu. Zahrnuje také možnost upravovat stop slova, která se používají při indexování.
Relační databáze sloužící k ukládání dotazů, uživatelských účtů a vygenerovaných exportů. Uchovává také informace o sklizních, které již byly indexovány, a o tom, kolik záznamů v nich bylo při indexaci nalezeno.
Jednotlivé tabulky v databázi jsou generovány pomocí frameworku Hibernate, který umožňuje objektově orientované generování tabulek z entit. Entity jsou umístěny ve složce https://github.com/WebarchivCZ/WACloud/tree/main/api/src/main/java/cz/inqool/nkp/api/model. Podle jejich atributů je možné odvodit strukturu tabulek.
Základní tok dat lze popsat následujícím diagramem:

Diagram toku dat
- Na začátku je sklizeň ve formátu WARC.
- Sklizně jsou zpracovány v kroku 1) nástrojem ArchiveProcessor do databáze HBase.
- V kroku 2) se provede indexace základních parametrů dat do Solr BaseCore.
- Při zadání uživatelského dotazu jsou následně vyhledané záznamy základem dotazu (krok 3a), kdy se získá jejich identifikace v HBase, odkud se podle identifikace načtou a indexují v kroku 3b) do Solr QueryCore.
- Aplikace pak v kroku 4) provádí jednotlivé analytické dotazy (kolokace, fulltextové vyhledávání, frekvenční analýzu slov, sítě odkazů), čímž získá výsledky, které jsou uživateli poskytnuty v posledním kroku 5).
Jednotlivé procesy z diagramu toku dat jsou podrobněji zakresleny v následujícím diagramu:
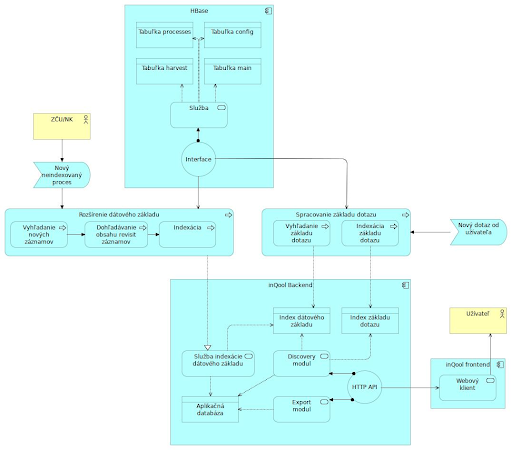
Diagram procesů
Základní události v diagramu jsou:
- Nový neindexovaný proces
- v HBase tabulce processes sa objeví ukončený proces zpracování nové sklizně
- WACloud API tak ví, že do HBase byla přidána nová data, která může zpracovat
- Nový dotaz od uživatele
- uživatel zadal nový dotaz prostřednictvím uživatelského rozhraní služby WACloud, které vytvoří základ dotazu.
- podle něj se načítají a zaindexují data z HBase (discovery modul)
- ze základu dotazu se zpracují jednotlivé analytické dotazy (export modul)
- Poskytnutí výsledků uživateli
- uživatel přihlášený přes WACloud UI si stáhne výsledky
Instalace se provádí pomocí nástrojů pro správu Ambari nebo Bigtop a není součástí této dokumentace. Potřebné návody jsou dostupné na adrese https://ambari.apache.org/ a https://bigtop.apache.org/.
Hbase tabulky není potřeba vytvářet ručně, vytvoří se automaticky při prvním spuštění nástroje ArchiveProcessor.
Aplikace vyžaduje minimálně verzi 7 systému Solr. Byla testována na Solr 7, ale měla by být schopna běžet i na Solr verzi 8.
Obě instance Solr indexů (BaseCore a QueryCore) lze v rámci clusteru nainstalovat jako službu. Po instalaci nástroje Solr je třeba definovat oba indexy podle konfigurace, která se nachází na adrese https://github.com/WebarchivCZ/WACloud/tree/main/solr ve složkách config-base a config-query.
Službu Solr je také možné spustit v docker kontejneru pomocí konfigurace souboru Dockerfile umístěné na stejné adrese. Docker kontejner automaticky vkládá obě jádra podle připojené konfigurace. V tomto případě je třeba nastavit volume pro složky /var/solr a /opt/solr/server/solr/mycores, ve kterých se ukládají data indexů, o která nechcete přijít v případě restartu kontejneru. Kontejner publikuje port 8983, což je standardní port Solr.
Inspiraci, jak nakonfigurovat a spustit službu Solr s oběma jádry SOLR cores pomocí nástroje docker compose, najdete na adrese https://github.com/WebarchivCZ/WACloud/blob/main/docker-compose.yml.
Aplikace byla testována s databází PostgreSQL, verze 12. Nevyžaduje však žádnou zvláštní funkcionalitu a měla by být schopna pracovat nad novějšími verzemi databázového systému.
Databázi PostgreSQL lze spustit jako samostatnou službu v operačním systému nebo jako docker kontejner. V prvním případě se jedná o instalaci podle oficiální dokumentace dostupné na webu https://www.postgresql.org/docs/current/install-binaries.html a postup instalace není součástí této dokumentace. Po instalaci je nutné vytvořit jeden uživatelský účet s jednou databází, ke které bude mít účet plná práva.
V druhém případě je možné se inspirovat konfigurací nástroje docker compose na adrese https://github.com/WebarchivCZ/WACloud/blob/main/docker-compose.yml. Aplikace používá oficiální docker image postgres:12-alpine, který zveřejňuje databázový systém na standardním portu 5432. Kontejner vyžaduje, aby byly definovány dvě proměnné prostředí:
- POSTGRES_USER – přihlašovací jméno uživatele
- POSTGRES_PASSWORD – přihlašovací heslo uživatele
Je také možné zadat proměnnou prostředí POSTGRES_DB, která definuje název vytvářené databáze. Pokud není definována, vytvoří se databáze se stejným názvem, jako je přihlašovací jméno uživatele. Tyto proměnné prostředí jsou definovány v ukázkové konfiguraci docker compose v souboru .env, který v úložišti z bezpečnostních důvodů neexistuje, ale lze jej vytvořit zkopírováním obsahu ze souboru .env.example.
Instalace se provádí na všechny stroje v Clusteru. Předpokládají se stroje s operačním systémem Linux a uživatel s administrátorskými právy. Nástroj byl testován pro Hadoop Cluster s Ambari 2.7.4.0 (s HDP-3.1.4.0) na CentOS Linux release 7.6.
Příprava všech strojů v Clusteru Nástroj ArchiveProcessor a všechny modely, které bude používat pro zpracování dat, je nutné nainstalovat na všechny stroje Clusteru. Díky tomu není nutné tyto (obvykle velké) modely mezi stroji kopírovat během zpracování dat. Prvním krokem je instalace potřebných systémových balíků:
[CentOS]: sudo yum install -y git wget gcc-c++ java-1.8.0-openjdk-devel
[Debian, Ubuntu]: sudo apt-get install git wget gcc openjdk-8-jdk
Instalace nástroje Anaconda (virtuální prostředí obsahující programovací jazyk Python 3.7.6):
cd ~
wget https://repo.anaconda.com/archive/Anaconda3-2020.02-Linux-x86_64.sh -O ./anaconda.sh
chmod +x ./anaconda.sh
sudo ./anaconda.sh -b -p /opt/anaconda3
rm -f ./anaconda.sh
Instalace nástroje ArchiveProcessor z GitHubu a potřebných Python balíků:
cd ~
git clone https://github.com/WebarchivCZ/WACloud_ArchiveProcessor
sudo /opt/anaconda3/bin/pip install -r ./archiveprocessor/requirements.txt
Příprava lokálních adresářů (pro logy a modely):
sudo mkdir -p /opt/archiveprocessor
sudo setfacl -R -m u:spark:rwx,d:u:spark:rwx /opt/archiveprocessor
sudo setfacl -R -m u:yarn:rwx,d:u:yarn:rwx /opt/archiveprocessor
Stažení natrénovaných modelů umělé inteligence. Jedná se o velké soubory, proto nejsou součástí gitu, ale stahují se z jednorázově vygenerovaných odkazů
Příprava na vybraném stroji, ze kterého se budou úlohy spouštět (obvykle NameNode) Přesunutí nástroje ArchiveProcessor do složky /opt a nastavení práv uživateli Spark, který bude nástroj spouštět:
sudo cp -R ~/archiveprocessor /opt
sudo setfacl -R -m u:spark:rwx,d:u:spark:rwx /opt/archiveprocessor
Aplikace potřebuje ke svému fungování Python verze 3 a musí se umět připojit k HBase. Postup instalace aplikace spolu se službou Systemd je popsán v souboru README.md v repozitáři https://github.com/WebarchivCZ/WACloud_ExportApp. Předpokládá se tedy, že bude spuštěna na stroji s operačním systémem Linux a Systemd démonem, ale je možné ji spustit i jinak jako službu Systemd. V obou případech je třeba definovat dvě proměnné prostředí:
- HBASE_HOST – IP adresa nebo hostname, kde běží HBase Thrift server
- HBASE_PORT – port na HBase Thrift server
Aplikace sa defaultně spustí a poslouchá na portu 8000 jako HTTP REST API.
Aplikace je připravena jako docker kontejner. Během vytváření docker image probíhá build aplikace, kde se stahují všechny závislosti, proto je tato fáze poměrně dlouhá. Poté po spuštění docker image jako kontejneru se spustí HTTP API na portu 8080. Ukázková konfigurace pro nástroj docker compose je opět k dispozici na adrese https://github.com/WebarchivCZ/WACloud/blob/main/docker-compose.yml. Konfigurace odkazuje na soubor .env, který je třeba vytvořit podle vzoru .env.example. Pro WACloud API lze nastavit následující proměnné prostředí:
| Název proměnné prostředí | Popis proměnné prostředí |
|---|---|
| SPRING_DATASOURCE_URL | JDBC url pro připojení do databáze i s identifikátorem databáze default hodnota: jdbc:postgresql://db:5432/nkp |
| SPRING_DATASOURCE_USERNAME | Přihlašovací jméno do databáze default hodnota: nkp |
| SPRING_DATASOURCE_PASSWORD | Přihlašovací heslo do databáze |
| HBASE_ZOOKEEPER_QUORUM | IP adresa, kde beží HBase Zookeeper |
| ZOOKEEPER_ZNODE_PARENT | Klíč, pod kterým je HBase registrovaná v Zookeeperu |
| SOLR_BASE_HOST_QUERY | Url, kde je dostupný Solr BaseCore příklad: http://solr:8983/solr/nkpbase |
| SOLR_QUERY_HOST_QUERY | Url, kde je dostupný Solr QueryCore příklad: http://solr:8983/solr/nkpquery |
| WARC_RECORDS-PER-ARCHIVE | Počet záznamů, které mají být uložené do jednoho WARC balíčku při exportu default hodnota: 10000 |
| WARC_EXPORTER_URL | Url, kde beží WARC ExportApp default hodnota: http://127.0.0.1:5000/ |
Z nastavení proměnných prostředí je zřejmé, že aplikace musí vidět na WARC ExportApp, Solr BaseCore, SolrQueryCore a HBase (spolu se Zookeeperem a Thrift serverem).
Aplikace je připravena jako docker kontejner. Během vytváření docker image probíhá stahování všech závislostí aplikace a po jejím spuštění v kontejneru probíhá samotný build aplikace. Proto se může stát, že aplikace bude reagovat až po několika sekundách po nasazení. Následně po spuštění docker image jako kontejneru se spustí HTTP server na portu 80.
Pro správný běh musí mít kontejner definovanou proměnnou prostředí API_HOST na IP adrese nebo hostname stroje, na kterém běží rozhraní WACloud API na portu 8080 (podmínkou je, že rozhraní API nesmí běžet na jiném portu, jinak je třeba upravit konfiguraci serveru Apache HTTPD v souboru https://github.com/WebarchivCZ/WACloud/blob/main/client/run.sh). Pokud tato proměnná prostředí není nastavena, uživatelské rozhraní předpokládá, že rozhraní API je spuštěno na serveru localhost.
Při použití nástroje docker compose musí být v poli API_HOST nastaveno hostname kontejneru a API. Ukázka konfigurace pro docker compose je opět k dispozici na adrese https://github.com/WebarchivCZ/WACloud/blob/main/docker-compose.yml.
Aplikace neřeší šifrovanou komunikaci, a proto je pro produkční provoz doporučeno postavit API i UI za reverzní proxy, která řeší HTTPS komunikaci. API není třeba publikovat mimo UI, k API nemusí mít přístup žádná další aplikace nebo uživatel. Stačí, aby se na API umělo připojit UI a UI vytváří reverzní proxy pro API na adrese /api/.
Také UI dělá reverzní proxy nad nástrojem Swagger UI, který publikuje API, slouží na samotný popis endpointů API. Swagger UI je dostupné na adrese /swagger-ui.
Aplikace WACloud API vytváří po spuštění tabulky v databázi PostgreSQL. V rámci těchto tabulek je tabulka users. Do této tabulky je potřeba vložit první záznam, kterým se vytvoří administrátorský účet. To lze provést pomocí následujícího příkazu:
insert into users (id, access_token, enabled, last_login, name, password, role, username) values (1, null, true, '2022-11-25 09:02:03.202000', 'Admin', '$2y$11$eEUReCv.WHs9YuBqK/4jW.B8rtPhbUvJ446FXXuQwRWBvSaTqE4T6', 1, 'admin');
Příkaz vloží do databáze uživatele s názvem admin a se stejným heslem s rolí administratora. Pod tímto uživatelem se pak můžeme přihlásit do uživatelského rozhraní služby WACloud, v pravém horním rohu vybrat možnost Uživatel – Administrace a v administraci můžeme spravovat/vytvářet další uživatelské účty. Pokud se při vytváření nového uživatele prostřednictvím uživatelského rozhraní vrátí chyba, je nutné příkaz zopakovat. Jedná se o problém, kdy jsme do databáze vložili uživatele s ID 1, ale neaktualizovali generátor čísel ID, který se při prvním dotazu snaží vytvořit uživatele s ID 1, který však již existuje.
Administrace sklizně se rovněž nachází v rámci uživatelského rozhraní a jeho administrační části. V této části je potřeba zkontrolovat, zda aplikace vidí zpracované sklizně z HBase, a pokud je nezačala importovat sama, musíme stisknout tlačítko Importovat. Po importu některé ze sklizní mohou běžní uživatelé začít zadávat dotazy. K importu sklizní se používá jediné vlákno, takže pokud je dotazováno více sklizní současně, budou importovány jedna po druhé.
Tato část dokumentace popisuje jednotlivé tabulky v databázi HBase. HBase slouží jako úložiště záznamů WARC v intermediary formátu a pro generování SOLR indexu pro fulltextové vyhledávání. Každý záznam má vždy časové razítko (timestamp), podle kterého lze v databázi vyhledávat. Aby bylo možné snadno vyhledávat nová data podle časových značek, je celý archiv uložen v jedné velké tabulce HBase. Data v tabulce HBase jsou uložena trvale (smazání starších dat se nezohledňuje), v případě nedostatku místa se použije pouze část archivu.
Jedná se o hlavní datovou tabulku, kde jeden záznam odpovídá jedné sklizené stránce.
klíč: WARC-Record-ID bez úvodního „urn:uuid:“
- příklad: 078777f5-4f22-4f74-8053-11d1cfce9eb7
sloupečky:
- urlkey (utf-8 string)
- refers-to (utf-8 string|empty)
- uuid vytáhnuté z WARC-Refers-To
- tento sloupec mají vyplněné jen revisit záznamy
- harvest-id (utf-8 string)
- identifikátor sklizně (odkaz na tabulku sklizní)
- title (utf-8 string)
- plain-text (utf-8 string)
- language (utf-8 string)
- sentiment (float uložený jako string)
- headlines (pole stringů serializované do formátu JSON)
- topics (pole stringů serializované do formátu JSON)
- links (pole stringů serializované do formátu JSON)
- web-page-type (utf-8 string|empty)
- IF (intermediary format serializovaný do formátu BSON)
- neobsahuje již data ze samostatných sloupečků
- neobsahuje objemné položky* content, plain-text-tokens, plain-text-sentences* (další možné dodefinovat v konfiguraci ZČU softwaru)
Tabulka obsahující seznam zpracovaných sklizní.
klíč: identifikátor sklizně
sloupečky:
- date
- type
Tabulka definuje číselníky témat a typů stránek. HBase obsahuje možnost verzování jednotlivých záznamů, proto jsou k dispozici i starší verze číselníků. Je také možné uložit nastavení jednotlivých modulů, např. které sloupce budou generovány z IF do tabulky main.
klíč: jméno číselníku
příklady: topics, webtypes
sloupečky:
- value (dictionary {hodnota:id} serializovaný do formátu JSON)
- verzování číselníků realizováno pomocí HBase verzí sloupečku
- max_versions=100
Tabulka slouží k ukládání informací o průběhu zpracování dat.
klíč: id procesu (operation_name) - jméno programu + čas spuštění
sloupečky:
- operation_status (string) - možné hodnoty jsou "running", "finished", "failed"
- t_started (HBase timestamp)
- t_finished (HBase timestamp)
- records_processed (int)
- records_failed (int)
- cmd_args (string)
- harvests (pole stringů serializované do formátu JSON) - identifikátory sklizní změněných v průběhu procesu
- application_id (string) - YARN ID aplikace spuštěné v tomto procesu
Sloupec t_started a t_finished používá stejný formát jako jako HBase timestamp (tj. čas od 1.1.1970 v milisekundách, např. 1592951258431), pouhým scanem tabulky se dá zjistit, které operace a kdy proběhly a je možné on-demand spouštět například přenos dat z HBase do SOLR na základě timestampu v t_finished.
Přihlášení je možné pomocí uživatelského jména a hesla na adrese https://www.wacloud.nkp.cz.
Na úvodní stránce lze přepnout do anglické jazykové verze nebo si přečíst v sekci FAQ nejčastější dotazy a odpovědi na ně. Po přihlášení se uživatel dostane na první část dotazu.

Dotaz je rozdělen do dvou částí s vlastním rozhraním. Rozhraní první části dotazu se skládá z několika sekcí. Nahoře je umístěna hlavička aplikace, v levém sloupci se nastavují parametry vyhledávání (Filtry a Nastavení limitů), vpravo pod hlavičkou je umístěno pole dotazu (Dotaz) s Logickými operátory (AND, OR, NOT, levá a pravá závorka), pod nímž je umístěna tabulka sklizní (Sklizně). Pod tabulkou Sklizně je tlačítko Pokračovat, které umožňuje přejít k analytickým dotazům v druhé části dotazu.
V hlavičce se nachází dvě skupiny odkazů. Nalevo je umožněn návrat na hlavní stránku rozhraní (symbol domečku), odkaz na webové stránky Národní knihovny ČR a Webarchivu. Vpravo jsou odkazy na kategorie Nový dotaz, Oblíbené, předchozí dotazy (Moje dotazy), FAQ, která zahrnuje i odkaz na dokumentaci, a na uživatelské nastavení (Uživatel), v němž je možné se z aplikace odhlásit, případně změnit jazykovou verzi (českou nebo anglickou). Aktuální režim kategorie (stránky) má modrou barvu.

Filtry zahrnují pět kategorií - Téma, Typ stránky, Datum sklizně, URL a Sentiment.
Filtry Téma, Typ stránky a Datum sklizně se nastavují výběrem z možností. Pro Téma to je několik desítek abecedně seřazených předmětových hesel (ta lze vybírat buď rolováním, nebo je lze psát). U kategorie Typ stránky lze zvolit e-shop (internetové obchody), forum (diskusní fóra), news (zpravodajství) a others (ostatní weby, které nezapadají do výše uvedených kategorií). Po vybrání požadovaného parametru je nutné stisknout jedno ze dvou tlačítek/logických operátorů, buď = (rovná se, vyhledává) nebo ≠ (nerovná se, vyjímá z hledání), které přidají parametr do pole Dotaz vpravo.

Datum sklizně se volí výběrem z kalendáře, datum lze manuálně přepsat. Pro vložení do dotazu je nutné použít operátor přidat (+).
URL- Webovou stránku, ve které probíhá vyhledávání, lze přidat 4 způsoby: obsahuje, neobsahuje, rovná se, nerovná se. Rovná se vyhledá přesně zadaný řetězec, nebo nevyhledá v případě možnosti Nerovná se. V příkazech obsahuje a neobsahuje stačí zadat jen část hledané adresy. Pro vložení do dotazu je nutné použít operátor přidat (+).
Sentiment- sentiment sleduje citové zabarvení obsahu webu. Sentiment nabývá hodnot od -1 (zcela negativní) přes 0 (neutrální) po +1 (zcela pozitivní). Nastavit lze určité rozmezí. I zde je možné přidat do dotazu operátor rovná se nebo nerovná se a pracovat s různým vymezením. Více k sentimentu: Analýza sentimentu – Wikipedie (wikipedia.org)
Pomocí těchto filtrů lze vytvořit složitější dotaz, protože všechny parametry lze zadávat opakovaně.
Nastavení limitů umožňuje omezit a zpřesnit výsledky vyhledávání.

Stop slova Stop slova jsou slova, která nebudou zohledněna při dalším vyhledávání - většinou jde o předložky, spojky, částice nebo zájmena. Uživateli je nabídnuta sada stop slov. Stop slova lze přidávat (kolonka vlevo nahoře po napsání a stisknutí +) nebo ubírat (x za každým slovem). Seznam stop slov lze také exportovat nebo importovat do/z vlastní databáze ve formě souboru .txt. Červené tlačítko koš umožňuje vymazat všechna zadaná slova. K použití změněných stop slov je nutné stisknout modré tlačítko Uložit.

Počet záznamů umožňuje omezit počet výsledků. Standardně je nastaveno omezení na 100 záznamů. Lze tu také zvolit Náhodné záznamy. Semínko pro náhodnost je řetězec čísel, díky němuž je možné získat opakovaně stejné náhodné záznamy, které jsou seřazeny chronologicky.
V poli dotaz se zobrazuje syntax dotazu. Ten je sestavován pomocí nastavení jednotlivých parametrů v sloupci nalevo. Dotaz lze upravovat i psaním přímo do pole dotazu. Dotaz lze exportovat i importovat - stáhnout si ho do textového souboru (formát .txt) a později nahrát. Pod dotazem se nacházejí logické operátory - AND (a), OR (nebo), NOT (ne) a pravá a levá závorka. Tyto operátory umožňují společně se zadáním parametrů filtrů vytvořit složitější dotaz.
Logické operátory: AND vyhledá průnik obou částí dotazu (syntax: topics:"Afghánistán" AND topics:"Ázerbájdžán" vyhledává na stránkách, kde jsou zmíněny oba asijské státy) OR sloučí obě části dotazu (topics:"Afghánistán" OR topics:"Ázerbájdžán" vyhledává na stránkách, kde je zmíněn alespoň jeden asijský stát) NOT vyloučí jednu část dotazu (topics:"Afghánistán" NOT topics:"Ázerbájdžán" vyhledává na stránkách, kde je zmíněn Afghánistán, ale není tam Ázerbájdžán)
Příklad:
topics:"Afghánistán" OR topics:"Ázerbájdžán"webType:"news" NOT webType:"forum"date:[2022-03-01T00:00:00Z TO 2022-03-31T00:00:00Z]url:/.nkp.cz./sentiment:[0 TO 1]
Výše uvedená syntax vyhledává v tematických kolekcích Afghánistán nebo Ázerbájdžán, ve zprávách, nikoliv ve fórech, na stránkách nkp.cz během druhé poloviny března. Nalezené výsledky musí mít pozitivní sentiment.
Většinu stránky zabírá tabulka sklizní, které lze použít pro vyhledání dotazu. V případě nezvolení žádné sklizně se vyhledává ve všech sklizních. Jednotlivá pole sklizní obsahují jejich názvy, údaje o velikosti, datu spuštění sklizně, o počtu WARCů (což je specializovaný kontejnerový formát určený k uložení archivních webových dat). Sklizně, ve kterých se vyhledává, se zaškrtávají v pravém horním rohu. Tato informace se v poli Dotaz nezobrazí, prohledávané sklizně jsou vidět až v druhé stránce dotazu, která se zobrazí po kliknutí na tlačítko Pokračovat.

Sklizně V názvech sklizní je obsažen i jejich stručný popis. První slovo názvu označuje typ sklizně, následuje datum zahájení sklizně a frekvence sklizní:
Typy sklizní Topics (zkratka To) - tematická sklizeň Serials (zkratka Se) - pravidelná sklizeň (kombinace výběrových sklizní s různou frekvencí sklízení) Continuous (zkratka Co) - pravidelná sklizeň s denní nebo nižší frekvencí Totals - celoplošná sklizeň domény .cz Tests (zkratka Te) - testovací sklizeň Requests (zkratka Rq) - sklizeň vyžádaná jinou institucí
Popis a frekvence sklizní V - výběrová sklizeň, T - tematická sklizeň, 1M - měsíční frekvence, 2M - dvouměsíční frekvence, 3M - čtvrtletní frekvence, 6M - šestiměsíční frekvence, 12M - roční frekvence, V-1 - jednorázová sklizeň, CZ - celoplošná sklizeň, ArchiveIt - jednorázová sklizeň nových semínek, OneShot - další přidaná jednorázová semínka (seedy, url adresy).
Podrobné informace o technických a administrativních metadatech archivních dat Webarchivu viz: Metodika pro tvorbu, uložení a zpřístupnění technických a administrativních metadat z webového archivu.
Po stisknutí tlačítka Pokračovat se uživatel dostane na druhou stránku dotazu.
Na předchozí stránce byly nastaveny filtry pro následné vyhledání analytických dotazů, které lze zadat na druhé straně dotazu. Zde se v poli Dotaz zobrazuje dotaz zvolený v předchozí části, zobrazeny jsou tu i sklizně, pokud byly zvoleny, v nichž probíhá vyhledávání. Pokud uživatel chce změnit některý z filtrů, na předchozí stránku (první část dotazu) se lze vrátit pomocí černého tlačítka Upravit.
Pod dotazem je indikátor validity (správnosti) zadaného dotazu (Dotaz je ne/validní). Je zde také informace o tom, v kolika záznamech bude vyhledáváno. Maximální počet záznamů lze nastavit na předchozí stránce - parametr Počet záznamů. Pokud je dotaz nevalidní, tak nelze ve vyhledávání pokračovat. Pokud validátor ukáže, že se zpracuje 0 záznamů, tak dotaz nic nenajde, uživatel může dotaz vymezit jiným způsobem.

V části Analytické dotazy je automaticky připraven jeden nevyplněný dotaz, přidávat lze i další dotazy a to modrým tlačítkem +Přidat další dotaz. Každý dotaz má několik parametrů. Typ dotazu má varianty Frequency, Collocation, Network a Fulltext. Následuje políčko pro hledaný text (Zadejte text pro vyhledávání). Hledaný výraz se přidává modrým tlačítkem + a po přidání je vidět v kolonce Seznam výrazů. I zde lze přidat více vyhledávaných výrazů. Celý dotaz lze odstranit červeným tlačítkem.

Fulltext: Tento analytický dotaz zobrazuje data v originální podobě (plain text). Kromě samotného textu je výsledkem exportu také URL adresa webu, titulek stránky (název stránky, obsah html tagu <title>), jazyk, rok vydání, nadpisy, odkazy na jiné stránky, témata a sentiment. V dotazu je možné nastavit počet záznamů, což je počet nalezených a exportovaných stránek.
Kromě toho je možné nastavit řazení výsledků a formát exportu.
Výsledky lze řadit chronologicky (rok), podle jazyka, nadpisu webu, url adresy a hodnoty sentimentu. Každá tato možnost má ještě dvě varianty řazení: ASC (vzestupně) a DESC (sestupně).
Formát exportu u všech dotazů nabízí dvě možnosti - JSON a CSV.
Frekvence: Frekvence zobrazí nejčastější slova na stránkách, které splňují zadané parametry - obsahují slovo nebo slova hledaná tímto dotazem. V dotazu je opět možné nastavit počet záznamů - počet nalezených a exportovaných záznamů.
Kolokace: zjišťuje slovní spojení týkající se hledaného výrazu - slovo před a za hledaným výrazem. V tomto typu dotazu lze hledat pomocí zaškrtávacího políčka Přidat kontext a nastavit počet slov kontextu, tj. další slova před a za vyhledávanými kolokacemi. Slova kontextu se ve výstupu dotazu zobrazují samostatně. Další vysvětlení kolokací: Kolokace – Wikipedie (wikipedia.org)
Příklad: Zadaný dotaz vyhledá kolokace slova „válka“ z témat Afghánistán a Ázerbájdžán ze zpráv, nikoliv z fór, a to s pozitivní konotací za využití 3 určených sklizní.

Network: Zobrazuje a počítá vzájemné hypertextové odkazy mezi doménami - tedy která stránka (zdrojový uzel) odkazuje na jinou stránku (cílový uzel). Dotaz umožňuje také seskupit uzly pouze domén, nikoliv jednotlivých stránek (url adres). Zde stačí zadat i jen část url adresy bez přípony .cz, rozhraní pak bude vyhledávat v celé url adrese. Příkladové heslo „robot“ vrátí i výsledky typu „www.nkp.cz/robotizace“

Stisknutím tlačítka Vyhledat začne vyhledávání, které je vidět níže (STAV PROCESU), po jeho ukončení je možné výsledky přímo stáhnout nebo přidat dotaz mezi oblíbené.

Tlačítko Stáhnout umožní stáhnout do počítače zazipovaný soubor .zip. Ten obsahuje soubory .json nebo .csv (pro fulltext), pro každý ze zadaných analytických dotazů jeden soubor.
Po vykonání dotazu ho lze přidat do Oblíbených a pojmenovat.
Centralizované rozhraní kromě vyhledání dotazů a jejich stažení umožňuje i správu dotazů - pomocí stránek Oblíbené a **Moje dotazy **v hlavičce napravo.
Stránka Moje dotazy zobrazí historii vyhledávaných dotazů.

Tabulka ukazuje dotazy - syntax dotazu, datum vytvoření, stav a také poskytuje možnost dataset znovu stáhnout. Kliknutí na tři tečky umožňuje další manipulaci:

Pokyn Zobrazit detail umožňuje zobrazit znovu celý dotaz: Kromě toho je možné přidat dotaz do Oblíbených (na liště vpravo), Zopakovat dotaz a také ho Stáhnout.

WARC Archivy Stáhnout lze také data v formátu WARC, kliknutím na možnost WARC Archivy je možné požádat o export.

O možnosti stažení, vzhledem k právním omezením, rozhoduje administrátor. Po schválení je ho pak možné stáhnout.


WARC vypadá takto:
WARC/1.0
WARC-Type: response
WARC-Target-URI: https://okamura.blog.idnes.cz/diskuse.aspx?iddiskuse=A130101_313625_blogidnes&vlakno=59488097
WARC-Date: 2021-02-27T02:12:15Z
WARC-IP-Address: 185.17.117.47
WARC-Record-ID: <urn:uuid:ac7ef3e6-2fe3-43ea-9beb-fc13b6c2112d>
Content-Length: 26274
WARC-Payload-Digest: sha1:VQY5C7QM6SUTZNHVXV36RZLQFHJQUGAY
WARC-Block-Digest: sha1:D7I4PEHCKUR4QEGMHI2IMWIE47U7K4QZ
Content-Type: application/http; msgtype=response
HTTP/1.0 200 OK
Oblíbené dotazy lze přidávat a odebírat pomocí hvězdičky nalevo od textu dotazu v tabulce Mých dotazů. Oblíbený dotaz je možné i označit vlastním jménem.

Na stránce Moje dotazy je také možné se vrátit a zadat nový dotaz (vpravo nahoře)
Stránka Oblíbené zobrazuje oblíbené dotazy a umožňuje s nimi manipulovat podobně jako v případě pole Moje dotazy. Oblíbené dotazy lze pro snadnější orientaci pojmenovat.

Administrace umožňuje spravovat uživatelské účty, dotazy a vkládat a odebírat sklizně.

Centralizované rozhraní umožňuje export výsledků, většinou ve formátu .json
Export fulltextu (Fulltext)
Fulltext exportuje nejrozsáhlejší informace o webové stránce - internetovou adresu, titulek stránky, jazyk stránky, samotný text, nadpisy, odkazy, rok publikace. Kromě toho export ukazuje téma stránky a sentiment.
Příklad:
"id" : "a51eb9a4-96d6-4c24-8254-f8eba6f6a9b8",
"url" : "dobry-spanek.cz/napsali-o-nas/audio/napsali-o-nas/v-noci-budite-a-nemuzete-spat-pozor-na-zavislost-na-lecich-327",
"urlDomain" : "dobry-spanek.cz",
"urlDomainTopLevel" : "dobry-spanek.cz",
"title" : "Napsali o nás - Poruchy spánku a nespavost, příčiny a léčba, poradna lékaře",
"language" : "cs",
"plainText" : "Tajemný hormon melatonin si poradí s rozhozenými spánkovými biorytmy Novinky.cz, 21. 3. 2012 Od té doby, co užívám melatonin, spím jak miminko…",
"year" : 2021,
"headlines" : [ "Napsali o nás", "ARCHIV" ],
"links" : [ "https://www.dobry-spanek.cz/home", "https://www.dobry-spanek.cz/napsali-o-nas/audio/napsali-o-nas/v-noci-budite-a-nemuzete-spat-pozor-na-zavislost-na-lecich-327#skipmenu", "https://www.dobry-spanek.cz/home", ],
"topics" : [ "zdraví" ],
"sentiment" : 0.8552388687966159
Export frekvence (Frequency):
Frekvence zobrazí url stránky a výskyt nejčastejších slov na této stránce
{ "dobry-spanek.cz/napsali-o-nas/audio/napsali-o-nas/v-noci-budite-a-nemuzete-spat-pozor-na-zavislost-na-lecich-327" : {
"spanku" : 59,
"spanek" : 52,
"muze" : 45,
"chytrazena.cz" : 34,
"noci" : 34,
"casu" : 31,
"dobre" : 22,
"nas" : 21,
"nespavosti" : 21,
"ceske" : 20
}
}
Export kolokací (Collocation):
Kolokace zobrazují slova, které se pojí s vyhledávaným slovem
Příklad
{
"baseball.cz/soutez-161/extraliga-u18/zakladni-cast" : {
"používáním" : [ "tohoto" ],
"souhlasíte" : [ "souhlasíte." ]
},
"deti-noci.cz/2012/01/filmoteka/anime/underworld-endless-war" : {
"každém" : [ "každém" ],
"načítání" : [ "načítání" ],
"používá" : [ "používá" ],
"používáním" : [ "tohoto" ],
"reklamou" : [ "reklamou" ],
"souhlasíte" : [ "souhlasíte." ],
"war" : [ "Tento" ],
"započítání" : [ "započítání" ]
},
Export sítí (Network): Soubor ve formátu .json ukazuje rok, zdrojovou a cílovou url adresu
Příklad:
"year" : 2021,
"nodes" : {
"name" : "abclinuxu.cz/zpravicky/pred-osmi-lety-navzdy-odesel-aaron-swartz",
"links" : {
"name" : "http://bugzilla.abclinuxu.cz",
"count" : 1
}, {
"name" : "http://czech-server.cz",
"count" : 1
}, {
"name" : "http://en.wikipedia.org/wiki/Image:H96566k.jpg",
"count" : 1
}, {
"name" : "http://jiri.one",
"count" : 1
},