Hunyuan-DiT : A Powerful Multi-Resolution Diffusion Transformer with Fine-Grained Chinese Understanding
This repo contains Paddle model definitions, pre-trained weights and inference/sampling code for Hunyuan-DiT.
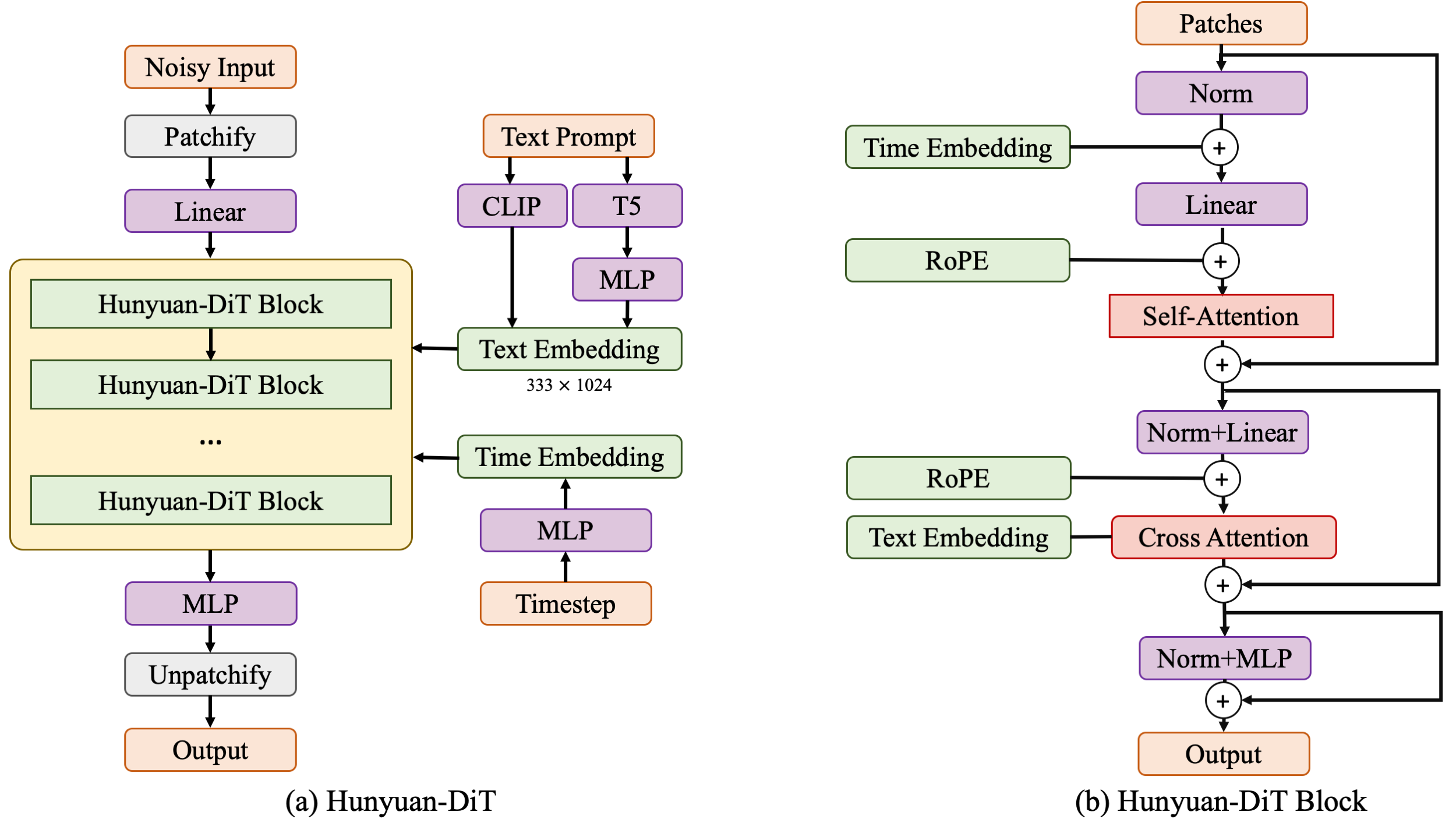
Hunyuan-DiT is a diffusion model in the latent space, as depicted in figure below. Following the Latent Diffusion Model, we use a pre-trained Variational Autoencoder (VAE) to compress the images into low-dimensional latent spaces and train a diffusion model to learn the data distribution with diffusion models. Our diffusion model is parameterized with a transformer. To encode the text prompts, we leverage a combination of pre-trained bilingual (English and Chinese) CLIP and multilingual T5 encoder.
comprehensive comparison of Hunyuan-DiT with other models.
| Model | Open Source | Text-Image Consistency (%) | Excluding AI Artifacts (%) | Subject Clarity (%) | Aesthetics (%) | Overall (%) |
|---|---|---|---|---|---|---|
| SDXL | ✔ | 64.3 | 60.6 | 91.1 | 76.3 | 42.7 |
| PixArt-α | ✔ | 68.3 | 60.9 | 93.2 | 77.5 | 45.5 |
| Playground 2.5 | ✔ | 71.9 | 70.8 | 94.9 | 83.3 | 54.3 |
| SD 3 | ✘ | 77.1 | 69.3 | 94.6 | 82.5 | 56.7 |
| MidJourney v6 | ✘ | 73.5 | 80.2 | 93.5 | 87.2 | 63.3 |
| DALL-E 3 | ✘ | 83.9 | 80.3 | 96.5 | 89.4 | 71.0 |
| Hunyuan-DiT | ✔ | 74.2 | 74.3 | 95.4 | 86.6 | 59.0 |
We provide several commands to quick start:
# Prompt Enhancement + Text-to-Image. Paddle mode
python sample_t2i.py --prompt "渔舟唱晚"
# Only Text-to-Image. Paddle mode
python sample_t2i.py --prompt "渔舟唱晚" --no-enhance
# Only Text-to-Image. Flash Attention mode
python sample_t2i.py --infer-mode fa --prompt "渔舟唱晚"
# Generate an image with other image sizes.
python sample_t2i.py --prompt "渔舟唱晚" --image-size 1280 768
More example prompts can be found in example_prompts.txt
We list some more useful configurations for easy usage:
| Argument | Default | Description |
|---|---|---|
--prompt |
None | The text prompt for image generation |
--image-size |
1024 1024 | The size of the generated image |
--seed |
42 | The random seed for generating images |
--infer-steps |
100 | The number of steps for sampling |
--negative |
- | The negative prompt for image generation |
--infer-mode |
paddle | The inference mode (paddle, fa, or trt) |
--sampler |
ddpm | The diffusion sampler (ddpm, ddim, or dpmms) |
--no-enhance |
False | Disable the prompt enhancement model |
--model-root |
ckpts | The root directory of the model checkpoints |
--load-key |
ema | Load the student model or EMA model (ema or module) |