 -
- -
- -
-image source: Data Science: A First Introduction by Timbers, Campbell & Lee
- -Sampling distribution vs bootstrap distribution¶
True population mean = 154.51. The mean of our sample is 155.8.
- -
-image source: Data Science: A First Introduction by Timbers, Campbell & Lee
- -Using the bootstrap to calculate a plausible range¶
-
-
- Take a bootstrap sample -
- Calculate the bootstrap point estimate (e.g., mean, median, proportion, etc.) from that bootstrap sample -
- Repeat steps (1) and (2) many times to create a bootstrap sampling distribution - the distribution of bootstrap point estimates -
- Calculate the plausible range of values around our observed point estimate (we will call this a confidence interval and learn how to do this in the worksheet) -
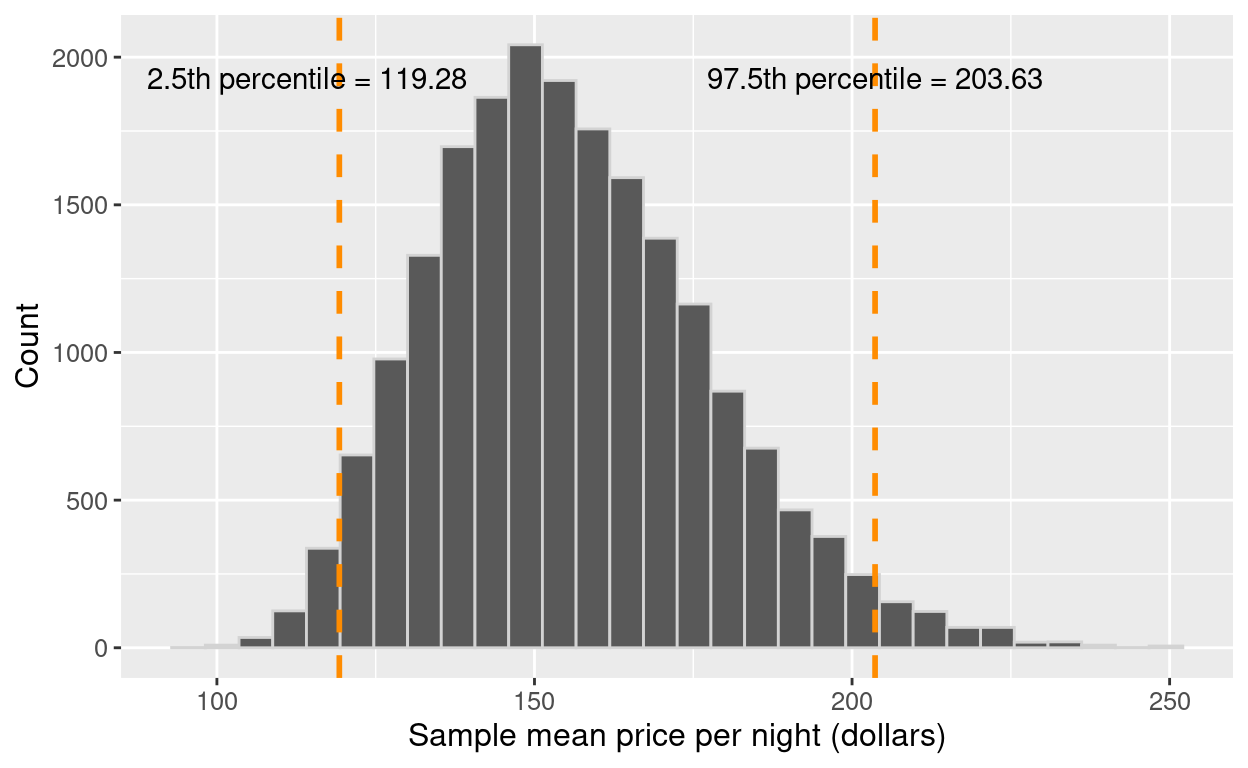 -
-We can use our bootstrap distribution to calculate the plausible range of values for the population parameter:
--
-
- $a$ is the 2.5% percentile (the value such that 2.5% of the bootstrap point estimates fall below) -
- $b$ is the 97.5% percentile (the value such that 97.5% of the bootstrap point estimates fall below) -
- the (approximate) confidence interval we report is the range from $a$ to $b$ -
We can report both our sample point estimate and the plausible range where we expect our true population quantity to fall.
-image source: Data Science: A First Introduction by Timbers, Campbell & Lee
- -Q. If we want to calculate a 90% confidence interval we should find the..¶
A. 2.5th percentile and 97.5th percentile
-B. 5th percentile and 95th percentile
-C. 10th percentile and 90th percentile
- -infer package workflow for bootstrapping¶
-
-
inferpackage is an R: used for statistical inference
-- provides functions with intuitive verb-like names to perform statistical inference -
-
-
specify(): choose which variables will be the focus of the statistical inference
-generate(): here our main argument isreps(how many different repetitions we would like)
-calculate(): return observed statistic specified withstatargument
-
set.seed(201)
-library(infer)
-library(tidyverse)
-#install.packages("vctrs")
-#install.packages("readr")
-library(vctrs)
-library(readr)
-
-set.seed(1)
-student_population <- tibble(student = 1:10000, grade = rnorm(n = 10000, mean = 70, sd = 5))
-
-student_sample <- rep_sample_n(student_population, size = 50, replace = FALSE, reps = 1) %>%
- ungroup() %>%
- select(-replicate)
-
-head(student_sample)
-## Bootstrapping with old method
-bootstrap_dist <- rep_sample_n(student_sample, size = 50, replace = T, reps = 10000) %>%
- group_by(replicate) %>%
- summarize(sample_mean = mean(grade))
-
-# bootstrap_dist
-# 90% confidence interval
-ci <- bootstrap_dist %>%
- summarize(ci_lower = quantile(sample_mean, 0.05),
- ci_upper = quantile(sample_mean, 0.95))
-
-
-bootstrap_dist %>%
- ggplot(aes(sample_mean)) +
- geom_histogram() +
- geom_vline(xintercept = ci$ci_lower) +
- geom_vline(xintercept = ci$ci_upper)
-# bootstrapping using infer package
-bootstrap_dist2 <- student_sample %>%
- specify(response = grade) %>%
- generate(type = "bootstrap", reps = 10000) %>%
- calculate(stat = "mean")
-
-#bootstrap_dist; bootstrap_dist2
-
-ci2 <- bootstrap_dist2 %>%
- get_confidence_interval(level = 0.90, type = "percentile")
-
-ci2
-bootstrap_dist2 %>%
- visualize() +
- shade_confidence_interval(endpoints = ci2)
-Confidence Interval interpretation¶
-
-
- Did our 90% confidence interval for the true mean based on our sample contain the true value of the population mean (i.e. 70)? -
- Will every 90% confidence interval for the true mean capture this value (i.e. 70)? In other words, if we had a different sample of 50 students and constructed a different confidence interval, would it necessarily contain the true population mean? -
-
-
- Interpretation: If we repeated our sampling procedure a large number of times, we expect about $C$% (where $C$ is the confidence level) of the resulting confidence intervals to capture the value of the population parameter. -
Impact of sample size¶
Suppose we take a sample of size 100 instead of 50. We then construct a 90% percentile-based confidence interval for our sample. Which interval would you expect to be wider?
-A. the interval with $n = 50$
-B. the interval with $n = 100$
-C. the two intervals will be the same
- -Impact of confidence level¶
Suppose we keep the sample size at 50. We then construct a 90% percentile-based confidence interval and a 95% percentile-based confidence interval. Which interval would you expect to be wider?
-A. the 95% confidence interval
-B. the 90% confidence interval
-C. the two intervals will be the same
- -Deliverable 1: Team Contract¶
A group contract is a document to help you formalize the expectations you have for your group members and what they can expect of you. It will help you think about what you need from each other to work effectively as a team! You will create and agree on this contract as a team. Each member should “sign” (you can just type out your name) at the bottom of the submission. At a minimum, your group contract must address the following:
-Goals¶
-
-
- What are our team goals for this project? -
- What do we want to accomplish? -
- What skills do we want to develop or refine? -
Expectations¶
What do we expect of one another regarding attendance at meetings, participation, frequency of communication, quality of work, etc.? What are our internal deadlines? (Warning: if working on separate parts, do not aim to put all the parts together on the last day – it takes time to integrate multiple parts.)
-Policies & Procedures¶
What rules can we agree on to help us meet our goals and expectations?
-Consequences:¶
How will we address non-performance regarding these goals, expectations, policies and procedures?
- -Teamwork contract¶
Teamwork contracts are due Jul 16
--
-
- In your groups, work on your teamwork contracts -
When you are done you can work on worksheet_04¶
-What did you learn today?¶
-
-
-
-
-
