npm run buildwill reprocess the files and output warnings- Resolve warnings - show me
- Remove generic names - show me
- Add
brand:wikidataandbrand:wikipediatags - show me - Add missing brands - show me
- Edit Wikidata - show me
Tip: You can browse the index at https://nsi.guide/ to see which brands are missing Wikidata links, or have incomplete Wikipedia pages.
dist/names_all.json- all the frequent names and tags collected from OpenStreetMapdist/names_discard.json- subset ofnames_allwe are discardingdist/names_keep.json- subset ofnames_allwe are keepingdist/wikidata.json- cached brand data retrieved from Wikidata
config/*config/filters.json- Regular expressions used to filternames_allintonames_keep/names_discardconfig/match_groups.json- Groups of tag pairs that are considered equal when matching
brands/*- Config files for each kind of branded business, organized by OpenStreetMap tagbrands/amenity/*.jsonbrands/leisure/*.jsonbrands/shop/*.jsonbrands/tourism/*.json
features/*- Source files for custom locations where brands are active
OpenStreetMap is a free, editable map of the whole world that
is being built by volunteers.
Features on the map are defined using tags. Each tag is a key=value pair of text strings.
For example, a McDonald's restaurant might have these tags:
"amenity": "fast_food"
"cuisine": "burger"
"name": "McDonald's"
... and more tags to record its address, opening hours, and so on.
The goal of this project is to define the most correct tags to assign to each common brand name. This helps people contribute to OpenStreetMap, because they can pick "McDonald's" from a list and not need to worry about the tags being added.
The brands/* folder contains many files, which together define the most correct OpenStreetMap names and tags.
These files are created by a several step process:
- Process the OpenStreetMap "planet" data to extract common names ->
dist/names_all.json - Filter all the names into ->
dist/names_keep.jsonanddist/names_discard.json - Merge the names we are keeping into ->
brands/**/*.jsonfiles for us to decide what to do with them
The files are organized by OpenStreetMap tag:
brands/*- Config files for each kind of branded business, organized by OpenStreetMap tagbrands/amenity/*.jsonbrands/leisure/*.jsonbrands/shop/*.jsonbrands/tourism/*.json
Each brand entry looks like this (comments added for clarity):
In brands/amenity/fast_food.json:
{
"displayName": "McDonald's", // "displayName" - Name to display in summary screens and lists
"id": "mcdonalds-658eea", // "id" - a unique identifier generated automatically
"locationSet": {"include": ["001"]}, // "locationSet" - defines where this brand is valid ("001" = worldwide)
"tags": { // "tags" - OpenStreetMap tags that every McDonald's should have
"amenity": "fast_food", // The OpenStreetMap tag for a "fast food" restaurant
"brand": "McDonald's", // `brand` - Brand name in the local language (English)
"brand:wikidata": "Q38076", // `brand:wikidata` - Universal Wikidata identifier
"brand:wikipedia": "en:McDonald's", // `brand:wikipedia` - Reference to English Wikipedia
"cuisine": "burger", // `cuisine` - What kind of fast food is served here
"name": "McDonald's" // `name` - Display name, also in the local language (English)
}
},There may also be entries for McDonald's in other languages!
{
"displayName": "マクドナルド", // "displayName" - Name to display in summary screens and lists
"id": "マクドナルド-3e7699", // "id" - a unique identifier generated automatically
"locationSet": { "include": ["jp"] }, // "locationSet" - defines where this brand is valid ("jp" = Japan)
"tags": {
"amenity": "fast_food",
"brand": "マクドナルド", // `brand` - Brand name in the local language (Japanese)
"brand:en": "McDonald's", // `brand:en` - For non-English brands, tag the English version too
"brand:ja": "マクドナルド", // `brand:ja` - Add at least one `brand:xx` tag that matches `brand`
"brand:wikidata": "Q38076", // `brand:wikidata` - Same Universal wikidata identifier
"brand:wikipedia": "ja:マクドナルド", // `brand:wikipedia` - Reference to Japanese Wikipedia
"cuisine": "burger",
"name": "マクドナルド", // `name` - Display name, also in the local language (Japanese)
"name:en": "McDonald's" // `name:en` - For non-English names, tag the English version too
"name:ja": "マクドナルド", // `name:ja` - Add at least one `name:xx` tag that matches `name`
}
},
Each entry requires a locationSet to define where the entry is available. You can define the locationSet as an Object with include and exclude properties:
"locationSet": {
"include": [ Array of locations ],
"exclude": [ Array of locations ]
}The "locations" can be any of the following:
- Strings recognized by the country-coder library. These should be ISO 3166-1 2 or 3 letter country codes or UN M.49 numeric codes.
Example:"de"
Tip: The M49 code for the whole world is"001". - Filenames for custom
.geojsonfeatures. If you want to use a custom feature, you'll need to add these under thefeatures/folder (see "Features" below for more details). EachFeaturemust have anidproperty that ends in.geojson.
Example:"de-hamburg.geojson"
Tip: You can use geojson.io or other tools to create these.
You can view examples and learn more about working with locationSets in the @ideditor/location-conflation project.
⚡️ You can test locationSets on this interactive map: https://ideditor.github.io/location-conflation/
Each entry requires a tags value. This is just an Object containing all the OpenStreetMap tags that should be set on the feature.
Brands are often tagged inconsistently in OpenStreetMap. For example, some mappers write "International House of Pancakes" and others write "IHOP".
This project includes a "fuzzy" matcher that can match alternate names and tags to a single entry in the name-suggestion-index. The matcher keeps duplicate entries out of the index and is used in the iD editor to help suggest tag improvements.
matchNames and matchTags properties can be used to list the less-preferred alternatives.
"brands/amenity/fast_food": [ // all items in this file will match the tag `amenity=fast_food`
…
{
"displayName": "Honey Baked Ham",
"id": "honeybakedham-4d2ff4",
"locationSet": { "include": ["us"] },
"matchNames": ["honey baked ham company"], // also match these less-preferred names
"matchTags": ["shop/butcher", "shop/deli"], // also match these less-preferred tags
"tags": {
"alt_name": "HoneyBaked Ham", // match `alt_name`
"amenity": "fast_food",
"brand": "Honey Baked Ham", // match `brand`
"brand:wikidata": "Q5893363",
"brand:wikipedia": "en:The Honey Baked Ham Company",
"cuisine": "american",
"name": "Honey Baked Ham", // match `name`
"official_name": "The Honey Baked Ham Company" // match `official_name`
}
},
…👉 The matcher code also has some useful automatic behaviors...
You don't need to add matchNames for:
- Name variations in capitalization, punctuation, spacing (the middots common in Japanese names count as punctuation, so "V・ドラッグ" already matches "vドラッグ")
- Name variations that already appear in the
name,brand,alt_name,short_name,official_nametags - Name variations in diacritic marks (e.g. "Häagen-Dazs" already matches "Haagen-Dazs")
- Name variations in
&vs.and
You don't need to add matchTags for:
- Tags assigned to match groups (defined in
config/match_groups.json). For example, you don't need addmatchTags: ["shop/doityourself"]to every "shop/hardware" and vice versa. Tags in a match group will automatically match any other tags in the same match group.
Sometimes multiple brands use the same name - this is okay!
Make sure each entry has a distinct locationSet, and the index will generate unique identifiers for each one.
You should also give each entry a unique displayName, so you everyone can tell them apart.
"brands/shop/supermarket": [
…
{
"displayName": "Price Chopper (Kansas City)",
"id": "pricechopper-9554e9",
"locationSet": { "include": ["price_chopper_ks_mo.geojson"] },
"tags": {
"brand": "Price Chopper",
"brand:wikidata": "Q7242572",
"brand:wikipedia": "en:Price Chopper (supermarket)",
"name": "Price Chopper",
"shop": "supermarket"
}
},
{
"displayName": "Price Chopper (New York)",
"id": "pricechopper-f86a3e",
"locationSet": { "include": ["price_chopper_ny.geojson"] },
"tags": {
"brand": "Price Chopper",
"brand:wikidata": "Q7242574",
"brand:wikipedia": "en:Price Chopper Supermarkets",
"name": "Price Chopper",
"shop": "supermarket"
}
},
These are optional .geojson files found under the features/ folder. Each feature file must contain a single GeoJSON Feature for a region where a brand is active. Only Polygon and MultiPolygon geometries are supported.
Feature files look like this:
{
"type": "Feature",
"id": "scotland.geojson",
"properties": {},
"geometry": {
"type": "Polygon",
"coordinates": [...]
}
}Note: A FeatureCollection containing a single Feature is ok too - the build script can handle this.
The build script will automatically generate an id property to match the filename.
👉 GeoJSON Protips:
- There are many online tools to create or modify
.geojsonfiles. - You can draw and edit GeoJSON polygons with geojson.io - (Editing MultiPolygons does not work in drawing mode, but you can edit the code directly).
- You can simplify GeoJSON files with mapshaper.org
- More than you ever wanted to know about GeoJSON
To rebuild the index, run:
npm run build
This will output a lot of warnings, which you can help fix!
Warnings mean that you need to edit files under brands/*.
The warning output gives a clue about how to fix or suppress the warning.
If you aren't sure, just ask on GitHub!
Warning - Potential duplicate:
------------------------------------------------------------------------------------------------------
If the items are two different businesses,
make sure they both have accurate locationSets (e.g. "us"/"ca") and wikidata identifiers.
If the items are duplicates of the same business,
add `matchTags`/`matchNames` properties to the item that you want to keep, and delete the unwanted item.
If the duplicate item is a generic word,
add a filter to config/filters.json and delete the unwanted item.
------------------------------------------------------------------------------------------------------
"shop/supermarket|Carrefour" -> duplicates? -> "amenity/fuel|Carrefour"
"shop/supermarket|VinMart" -> duplicates? -> "shop/department_store|VinMart"
What it means: These names are commonly tagged differently in OpenStreetMap. This might be ok, but it might be a mistake.
For "VinMart" we really prefer for it to be tagged as a supermarket. It's a single brand frequently mistagged.
- Add
"matchTags": ["shop/department_store"]to the (preferred)"shop/supermarket|VinMart"entry - Delete the (not preferred) entry for
"shop/department_store|VinMart"
For "Carrefour" we know that can be both a supermarket and a fuel station. It's two different things.
- Make sure both entries have a
brand:wikidatatag and appropriatelocationSet.
Existing tagging (you can compare counts in dist/names_keep.json), information at the relevant Wikipedia page or the company's website, and OpenStreetMap Wiki tag documentation all help in deciding how to address duplicate warnings.
If the situation is unclear, one may contact the local community and ask for help.
Some of the common names in the index might not actually be brand names. We want to remove these generic words from the index, so they are not suggested to mappers.
For example, "Универмаг" is just a Russian word for "Department store":
"brands/shop/department_store": [
…
{
"displayName": "Универмаг",
"id": "универмаг-d5eaac",
"locationSet": { "include": ["ru"] },
"tags": {
"brand": "Универмаг",
"name": "Универмаг",
"shop": "department_store"
}
},
},To remove this generic name:
- Delete the item from the appropriate file, in this case
brands/shop/department_store.json - Edit
config/filters.json. Add a regular expression matching the generic name in either thediscardKeysordiscardNameslist. - Run
npm run build- if the filter is working, the name will not be put back intobrands/shop/department_store.json git diff- to make sure that the entries you wanted to discard are gone (and no others are affected)- If all looks ok, submit a pull request with your changes.
Adding brand:wikipedia and brand:wikidata tags is a very useful task that anybody can help with.
- Find an entry in a brand file that is missing these tags:
In brands/amenity/fast_food.json:
"brands/amenity/fast_food": [
…
{
"displayName": "Chipotle",
"id": "chipotle-658eea",
"locationSet": { "include": ["us"] }
"matchNames": ["chipotle mexican grill"],
"tags": {
"amenity": "fast_food",
"brand": "Chipotle",
"cuisine": "mexican",
"name": "Chipotle"
}
},- Google for that brand - if you are lucky, you might find the Wikipedia page right away.
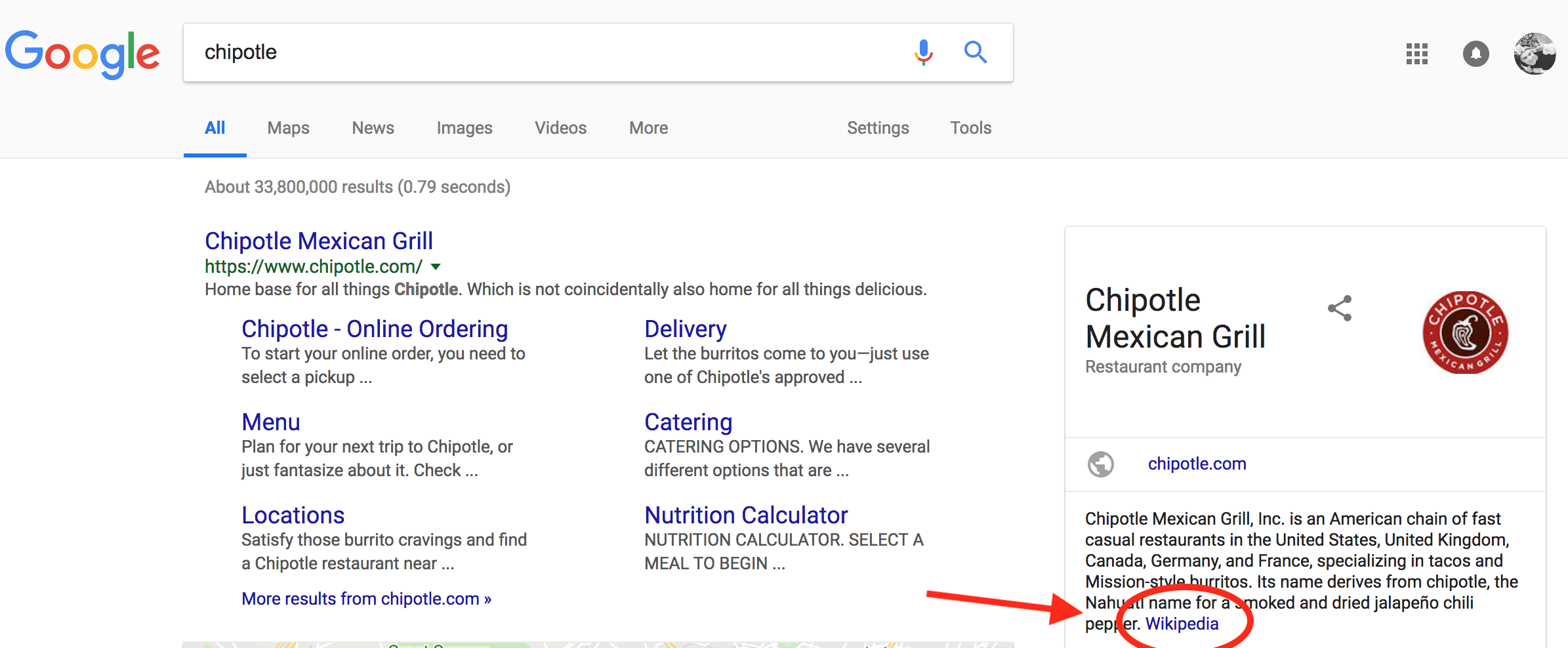
- From the Wikipedia page URL, you can identify the
brand:wikipediavalue.
OpenStreetMap expects this tag to be formatted like "en:Chipotle Mexican Grill".
- Copy the page name from the URL.
- Add the language prefix - "en:" for the English Wikipedia.
- Replace the underscores '_' with spaces.
On the brand's Wikipedia page, you can also find its "Wikidata item" link. This appears under the "tools" menu in the sidebar.
👉 protip: @maxerickson has created a user script to make copying these values even easier - see #1881
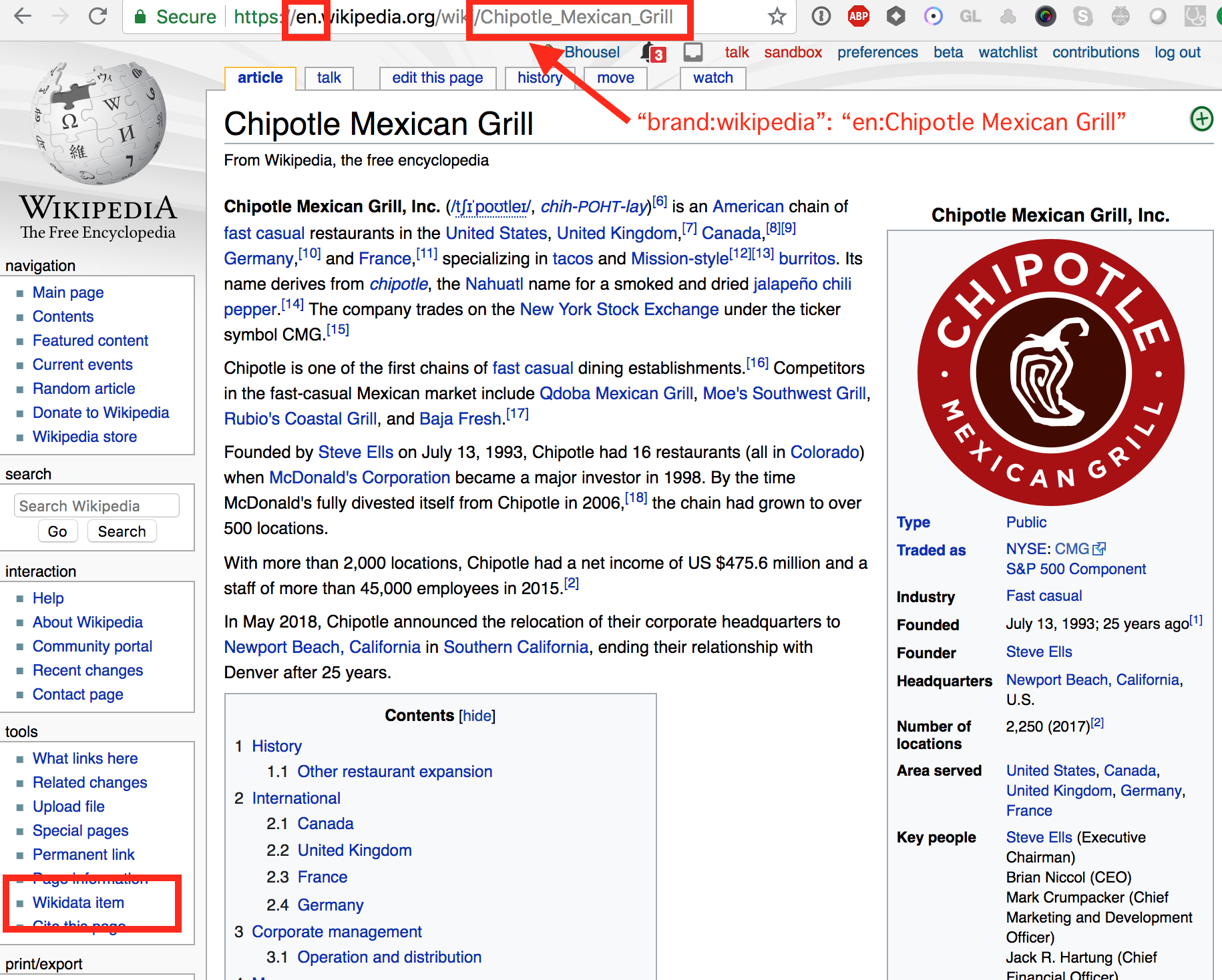
- On the brand's Wikidata page, you can identify the
brand:wikidatavalue. It is a code starting with 'Q' and several numbers.
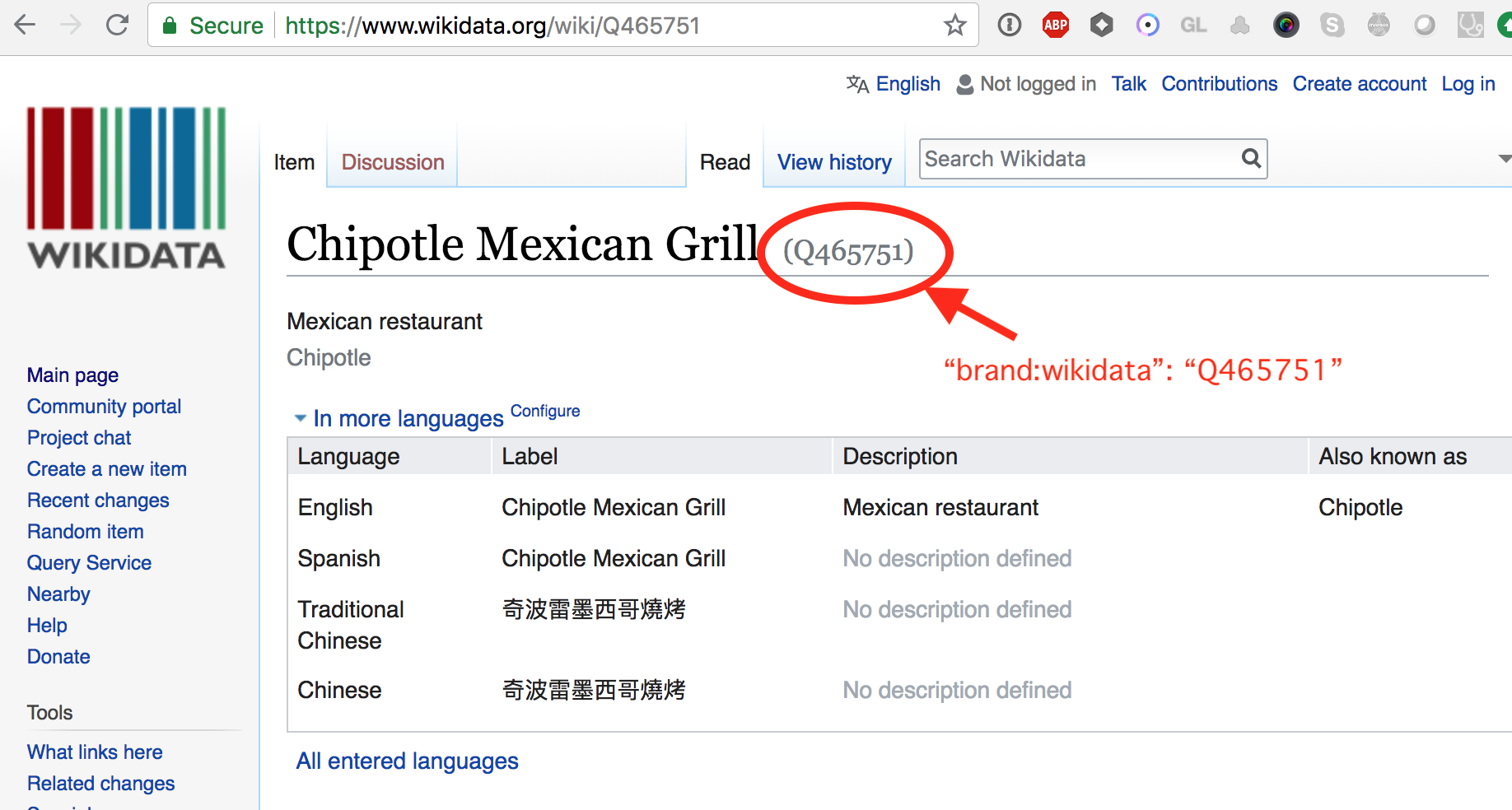
- Update the brand file, in this case
brands/amenity/fast_food.json:
We can add the "brand:wikipedia" and "brand:wikidata" tags.
"brands/amenity/fast_food": [
…
{
"displayName": "Chipotle",
"id": "chipotle-658eea",
"locationSet": { "include": ["us"] }
"matchNames": ["chipotle mexican grill"],
"tags": {
"amenity": "fast_food",
"brand": "Chipotle",
"brand:wikidata": "Q465751", // added
"brand:wikipedia": "en:Chipotle Mexican Grill", // added
"cuisine": "mexican",
"name": "Chipotle"
}
},(comments added for clarity)
- Rebuild and submit a pull request.
- Run
npm run build - If it does not fail with an error, you can submit a pull request with your changes (warnings are OK).
This example uses a brand "かっぱ寿司". I don't know what that is, so I will do some research.
- Find an entry in a brand file that is missing these tags:
In brands/amenity/fast_food.json:
"brands/amenity/fast_food": [
…
{
"displayName": "かっぱ寿司",
"id": "かっぱ寿司-3e7699",
"locationSet": {"include": ["jp"]},
"tags": {
"amenity": "fast_food",
"brand": "かっぱ寿司",
"name": "かっぱ寿司"
}
},
},- Google for that brand - if you are lucky, you might find the Wikipedia page right away.
Tip: You might want to narrow you search by Googling with a site: filter: "かっぱ寿司 site:ja.wikipedia.org"
From these results, we can know that the brand is "Kappazushi", owned by a Japanese company called "Kappa Create". We can also find the Wikipedia page.
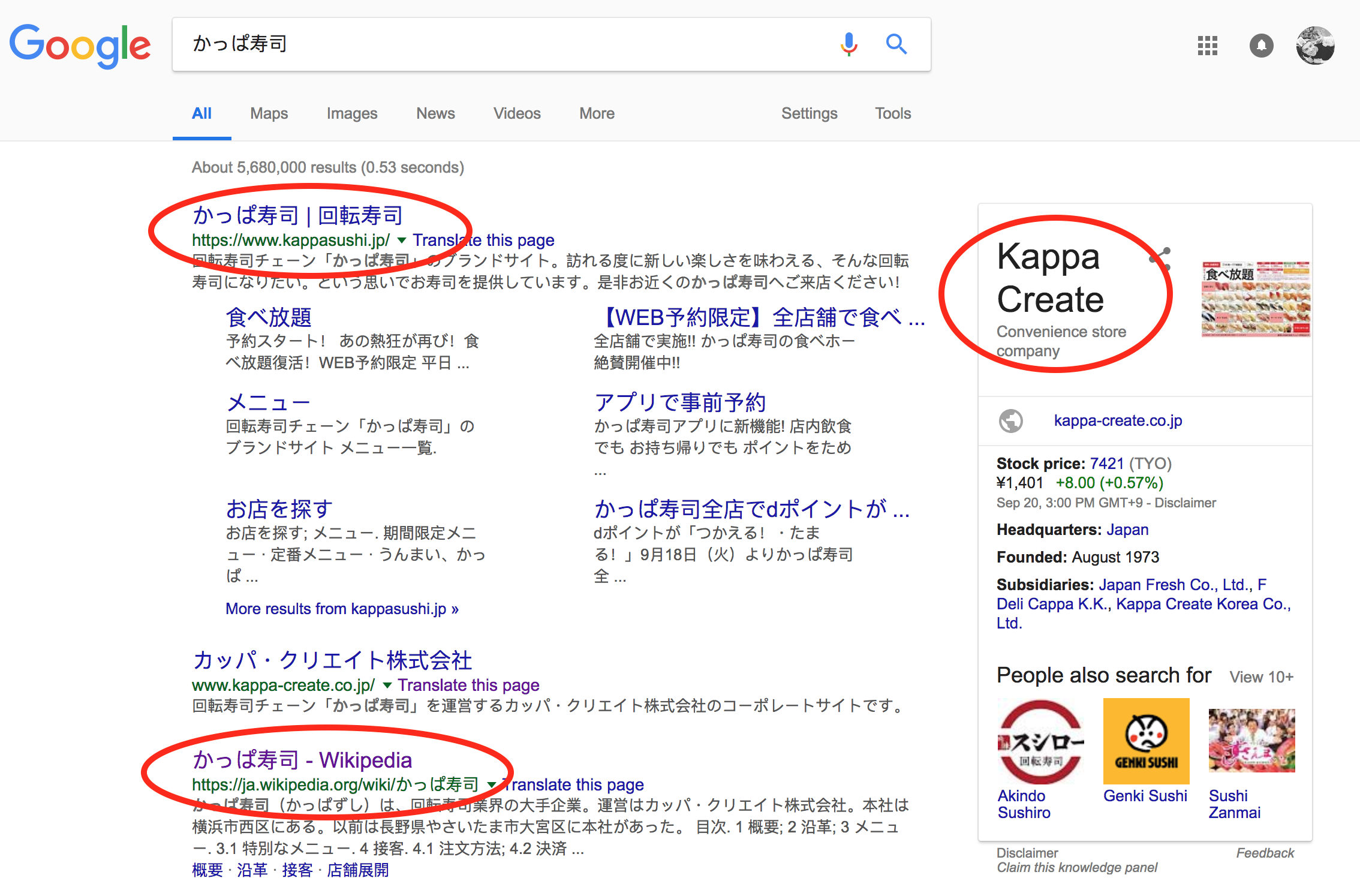
- As with English brands, you can identify the
brand:wikipediavalue from the URL. Because this is a Japanese brand, we will link to the Japanese Wikipedia page.
OpenStreetMap expects this tag to be formatted like "ja:かっぱ寿司".
- Copy the page name from the URL.
- Add the language prefix "ja:".
- Replace the underscores '_' with spaces.
Although I can not read Japanese, I can identify the "Wikidata item" link because it always appears in the sidebar and mouseover will show the Wikidata 'Q' code in the URL.
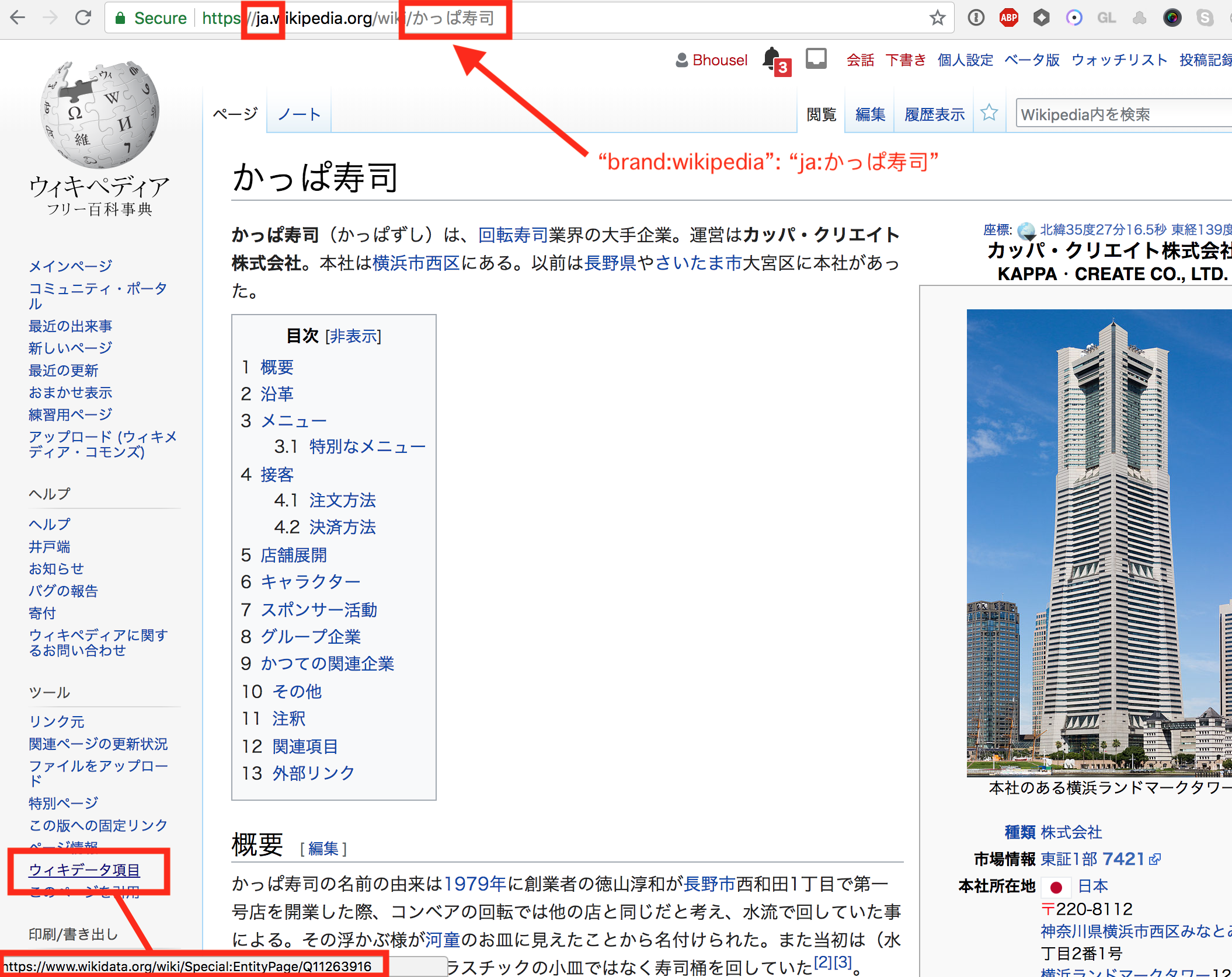
- On the brand's Wikidata page, you can identify the
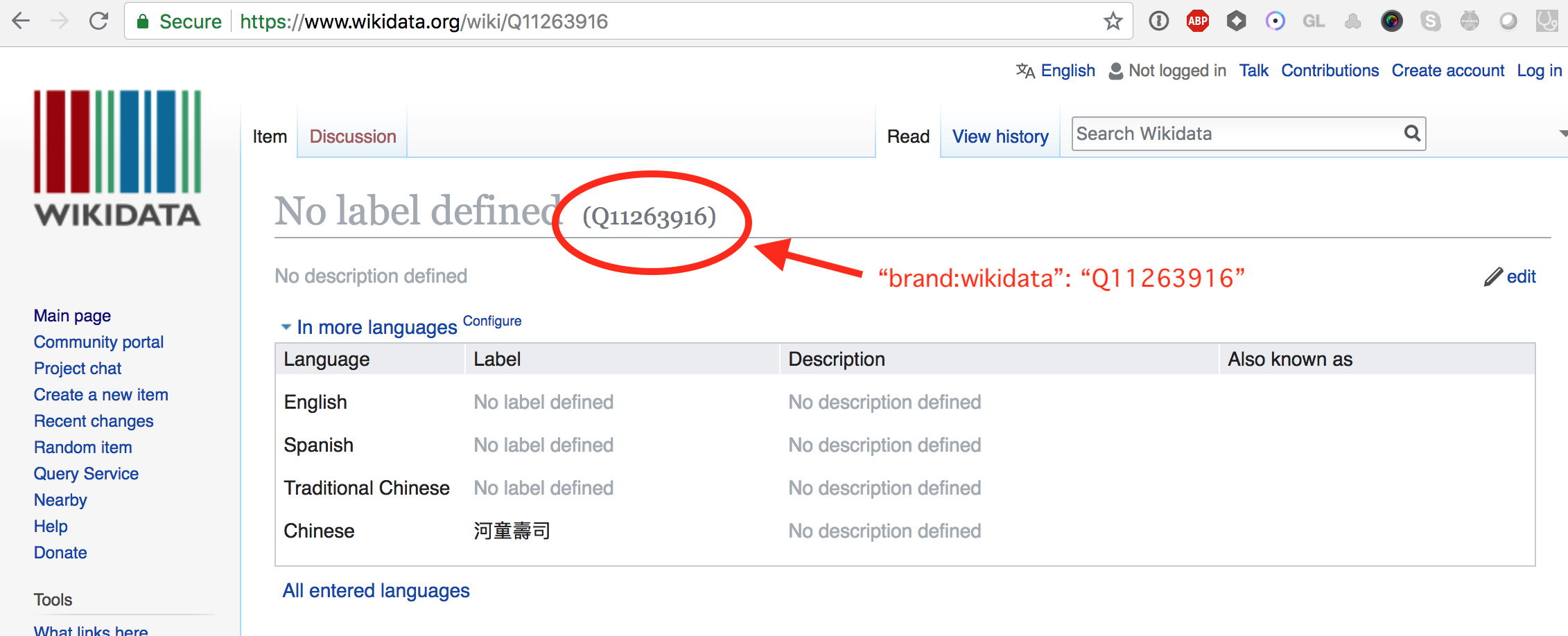
brand:wikidatavalue. It is a code starting with 'Q' and several numbers.
Note: The Wikidata page looks a bit sparse - you can edit this too if you want to help!
- Update the brand file, in this case
brands/amenity/fast_food.json:
We can add:
"brand:en"and"name:en"tags to contain the English name "Kappazushi""name:ja"and"brand:ja"tags to contain the local name "かっぱ寿司""brand:wikipedia"and"brand:wikidata"tags"cuisine": "sushi"OpenStreetMap tag- Also check the
"locationSet"property to make sure it is accurate.
"brands/amenity/fast_food": [
…
{
"displayName": "かっぱ寿司",
"id": "かっぱ寿司-3e7699",
"locationSet": {"include": ["jp"]},
"tags": {
"amenity": "fast_food",
"brand": "かっぱ寿司",
"brand:en": "Kappazushi", // added
"brand:ja": "かっぱ寿司", // added
"brand:wikipedia": "ja:かっぱ寿司", // added
"brand:wikidata": "Q11263916", // added
"cuisine": "sushi", // added
"name": "かっぱ寿司",
"name:en": "Kappazushi", // added
"name:ja": "かっぱ寿司" // added
}
},(comments added for clarity)
- Rebuild and submit a pull request.
- Run
npm run build - If it does not fail with an error, you can submit a pull request with your changes (warnings are OK).
If it exists, we want to know about it!
Some brands aren't mapped enough (50+ times) to automatically be added to the index so this is a valuable way to get ahead of incorrect tagging.
-
Before adding a new brand, the minimum information you should know is the correct tagging required for instances of the brand (
name,brandand what it is - e.g.shop=food). Ideally you also havebrand:wikidataandbrand:wikipediatags for the brand and any other appropriate tags - e.g.cuisine. -
Add your new entry anywhere into the appropriate file under
brands/*(the files will be sorted alphabetically later) and using the"tags"key add all appropriate OSM tags. Refer to here if you're not familiar with the syntax. -
If the brand only has locations in a known set of countries add them to the
"locationSet"property. This takes an array of ISO 3166-1 alpha-2 country codes in lowercase (e.g.["de", "at", "nl"]). -
If instances of this brand are commonly mistagged add the
"matchNames": []key to list these. Again, refer to here for syntax. -
Run
npm run buildand resolve any duplicate name warnings.
Sometimes you might want to know the locations where a brand name exists in OpenStreetMap. Overpass Turbo can show them on a map:
-
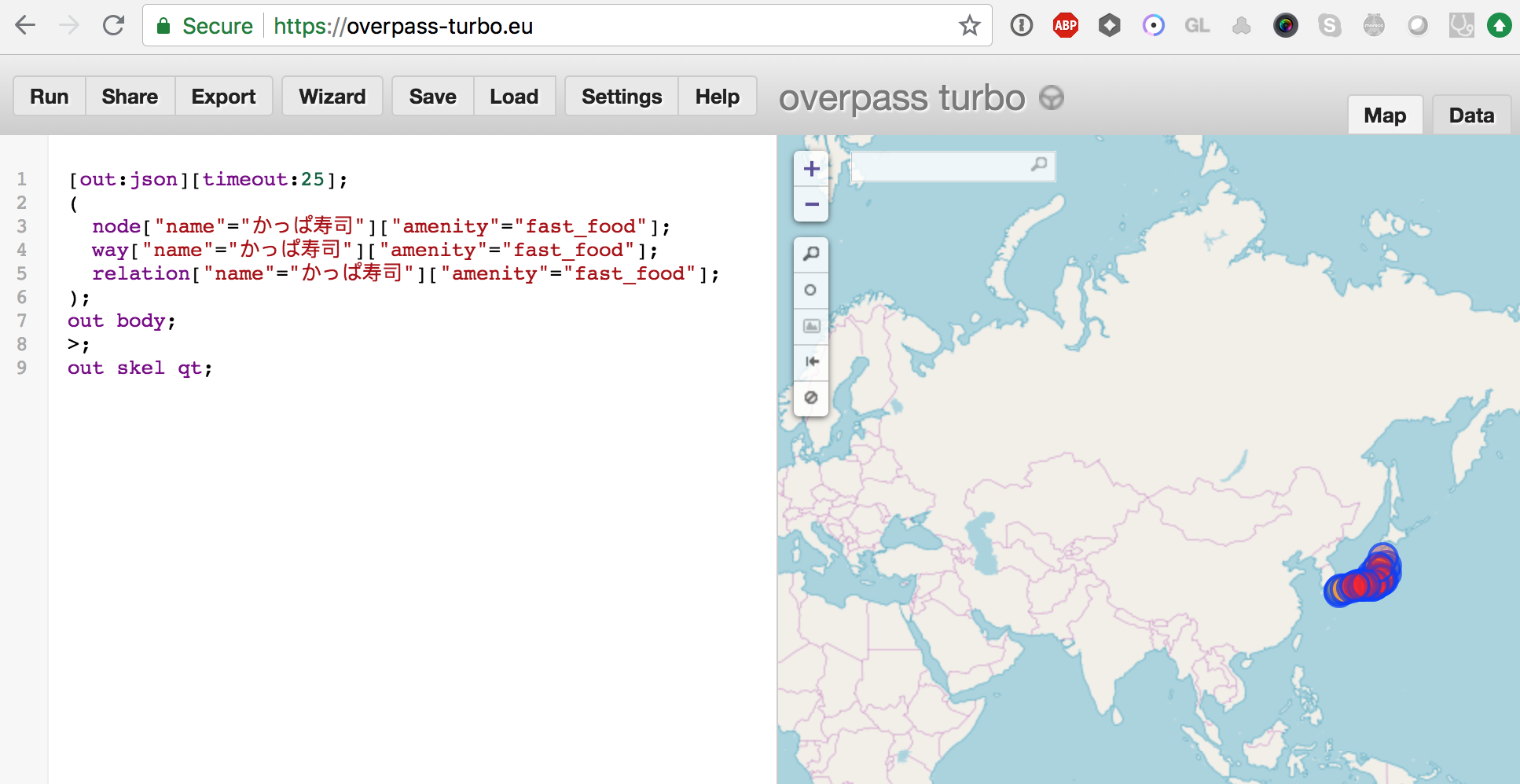
Enter your query like this, replacing the
nameand other OpenStreetMap tags. Because we don't specify a bounding box, this will perform a global query.
nwr["name"="かっぱ寿司"]["amenity"="fast_food"];
out center;
Tip: The browsable index at https://nsi.guide/ can open Overpass Turbo with the query already set up for you.
- Click run to view the results.
As expected, the "かっぱ寿司" (Kappazushi) locations are all concentrated in Japan.
Editing brand pages on Wikidata is something that anybody can do. It helps not just our project, but anybody who uses this data for other purposes too! You can read more about contributing to Wikidata here.
- Add Wikidata entries for brands that don't yet have them.
- Improve the labels and descriptions on the Wikidata entries.
- Translate the labels and descriptions to more languages.
- Add social media accounts under the "Identifiers" section. If a brand has a Facebook, Instagram, or Twitter account, we can fetch its logo automatically.
Tip: The browsable index at https://nsi.guide/ can show you where the Wikidata information is missing or incomplete.
Social media accounts may be used to automatically fetch logos, which are used by the iD Editor.
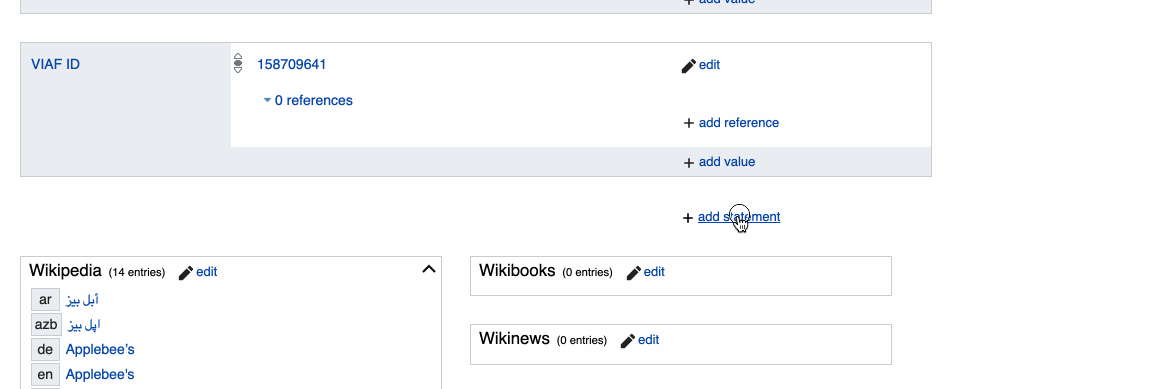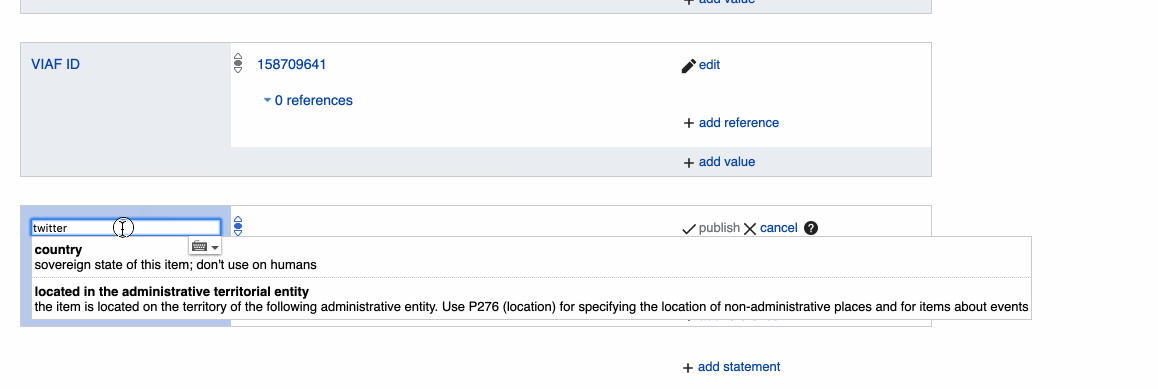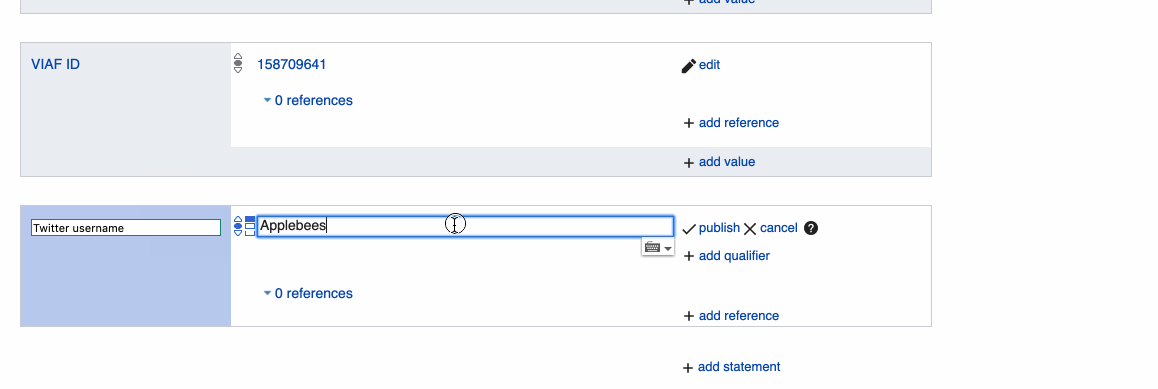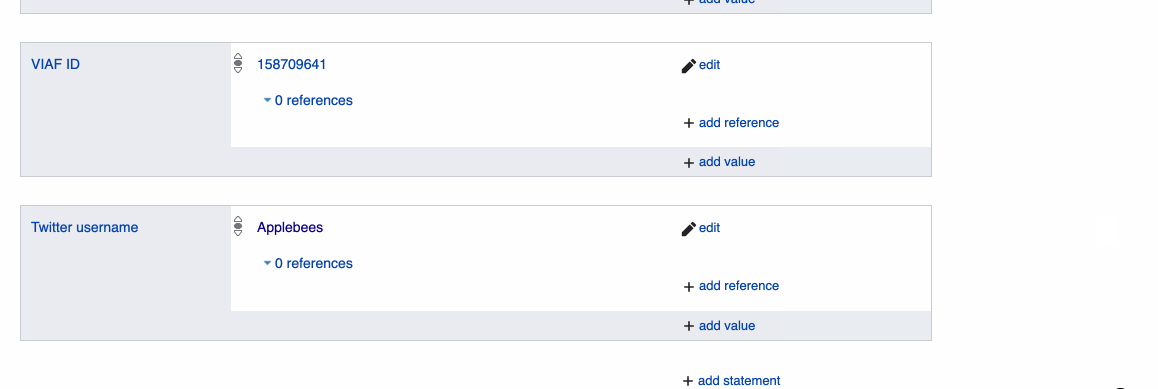
Social media links are often displayed on the official web site of a brand, making them easy to find. When adding an entry for a social media account, it might be worth checking if that account has a "verified badge" which indicates a verified social media account, and if it does, this can be added via the "add qualifier" option, using "has quality" along with either "verified account" or "verified badge".
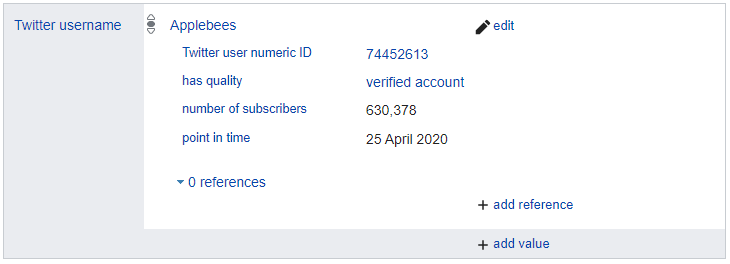
Entries without matching Wikipedia article must have some references by independent sources. For our entries usually the easiest one to add is something in form of "this shop brand had N shops on some specific date".

For minor brands there may be no Wikipedia article and it may be impossible to create one. In such cases one may still go to Wikidata and select "Create a new item" in menu. For such entries it is mandatory to add some external identifier or references (see section above with animation showing how it can be done).