- KDD Biotrain Dataset
- Worms Dataset
- KDD Biotrain Dataset
- Worms Dataset
- KDD Biotrain Dataset
- Worms Dataset
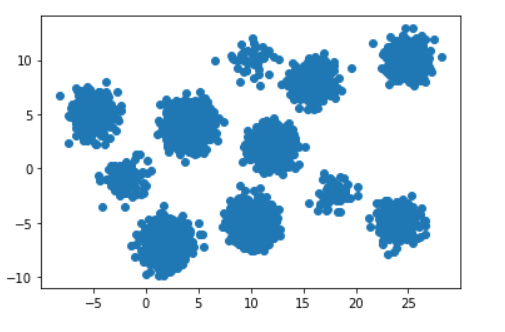
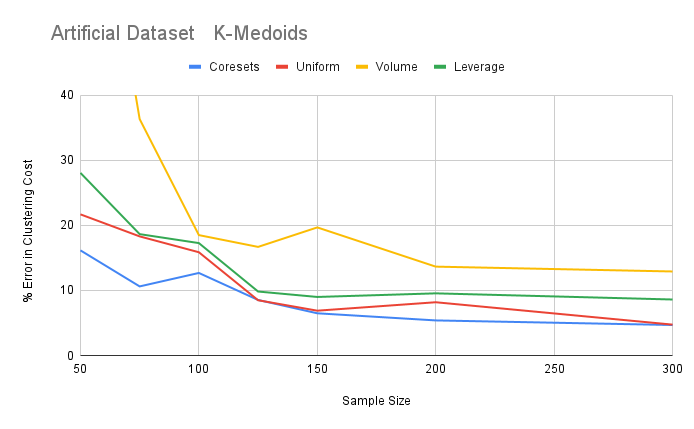
- K-medoids clustering is performed on artificial dataset because of its expensive runtime
- Artificial Dataset (dataset visualization)
- All sampling methods
- The directory structure is as follows -
- There are 4 directories for each clustering algorithm
│ Averaged_Data_collection.xlsx
│ README.md
│
├───bisecting
│ kdd_coresets.py
│ kdd_leverage.py
│ kdd_uniform.py
│ kdd_volume.py
│ worms_coresets.py
│ worms_leverage.py
│ worms_uniform.py
│ worms_volume.py
│
├───images
│ │ artificial.png
│ │ kmedoids.png
│ │
│ ├───kdd
│ │ bisectingcoresets.png
│ │ bisectingvol_lev.png
│ │ kcenterall.png
│ │ kmeanscoresets.png
│ │ kmeansvol_lev.png
│ │
│ └───worms
│ bisectingall.png
│ kcenterall.png
│ kmeansall.png
│
├───kcenter
│ kdd_coresets.py
│ kdd_leverage.py
│ kdd_uniform.py
│ kdd_volume.py
│ worms_coresets.py
│ worms_leverage.py
│ worms_uniform.py
│ worms_volume.py
│
├───kdd
│ bio_train.dat
│ kdd_reduced.pickle
│ kdd_reduced_1k.pickle
│ kdd_reduced_20k.pickle
│ kdd_reduced_30k.pickle
│ kdd_reduced_40k.pickle
│
├───kmeans
│ kdd_coresets.py
│ kdd_leverage.py
│ kdd_uniform.py
│ kdd_volume.py
│ worms_coresets.py
│ worms_leverage.py
│ worms_uniform.py
│ worms_volume.py
│
├───kmedoid
│ artificial_all.py
│
└───worms
README.txt
worms_2d.png
worms_2d.txt
worms_64d.txt
worms_reduced.pickle
worms_reduced_20k.pickle
worms_reduced_30k.pickle
worms_reduced_40k.pickle
-
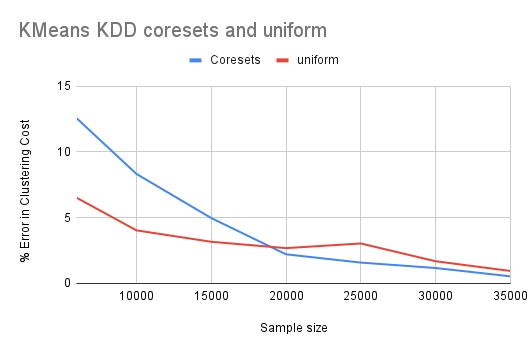
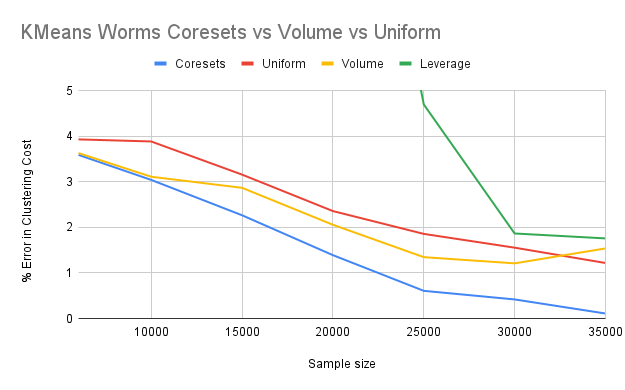
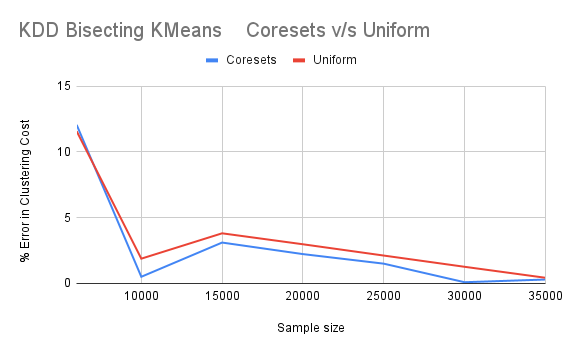
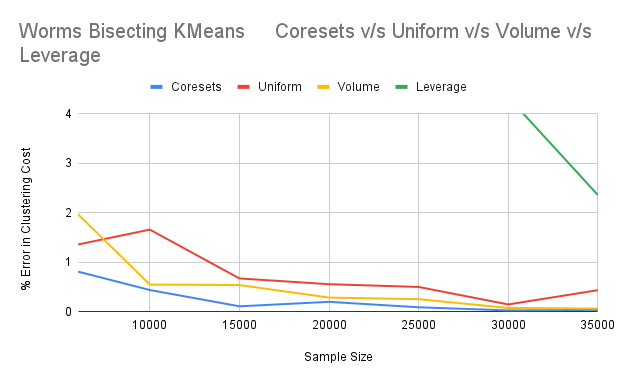
Lightweight coresets outperform all other sampling techniques in each combination ofdatasets and clustering algorithms.
-
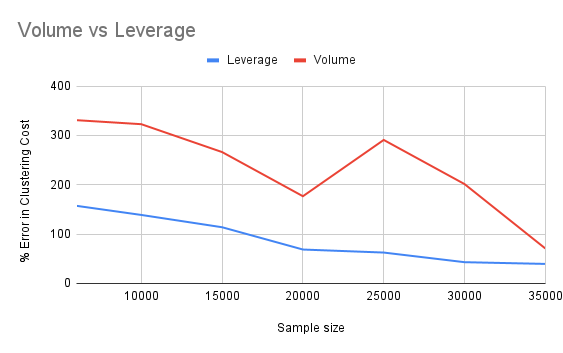
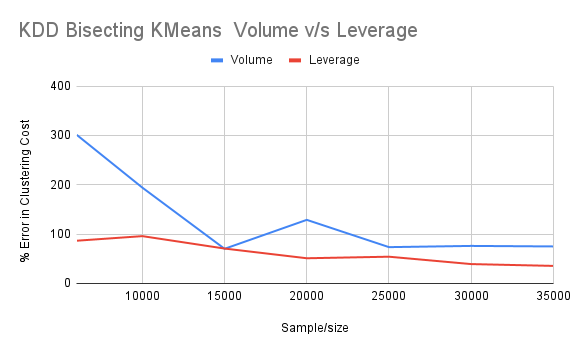
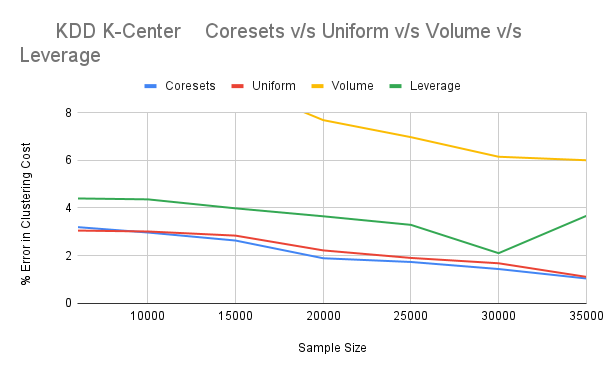
For the KDD dataset, Leverage sampling performs better than Volume sampling, in eachcombination of KDD dataset and clustering algorithms.
-
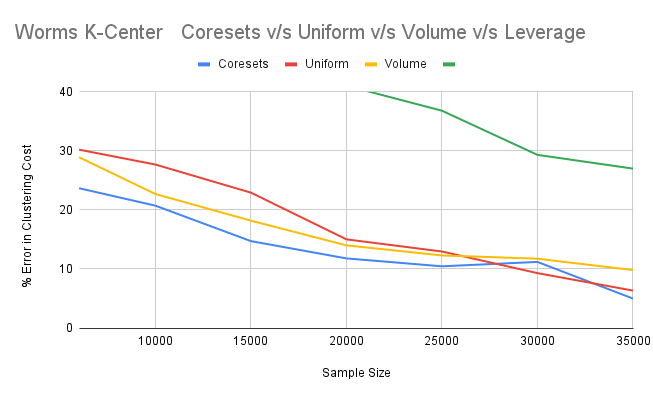
For the Worms dataset, Volume sampling performs better than Leverage sampling, in eachcombination of Worms dataset and clustering algorithms.
-
Although lightweight coresets were designed for kmeans, they show a good performance onthe kcenters algorithm as well, beating rest of the sampling techniques.