In addition to this README there is a (not yet finished) streamlit-based website with visualizations and more detailed explanations:
This tutorial describes the optimization strategies and parameters from the Hyperactive and Gradient-Free-Optimizers python-packages. All optimizer- and parameter-names correspond to version 1.0 of Gradient-Free-Optimizers.
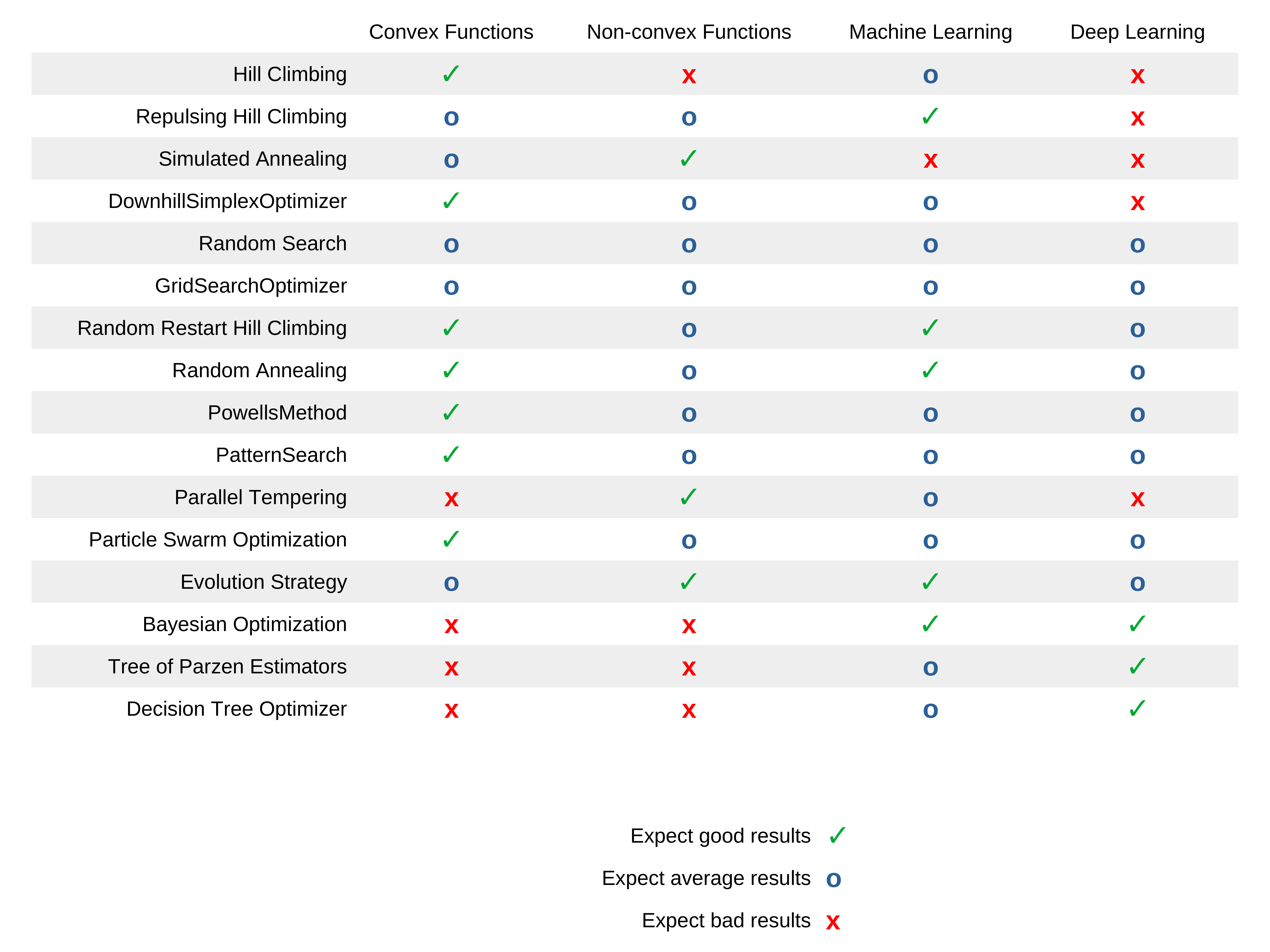
The following table shows the expected results for each optimization strategy for the given type of problems:
- Convex function with fast evaluation time (<0.1s)
- Non-convex function with fast evaluation time (<0.1s)
- Machine learning model hyperparameter optimization
- Deep learning model hyperparameter optimization
HillClimbingOptimizer
Hill climbing is a very basic optimization technique, that explores the search space only localy. It starts at an initial point, which is often chosen randomly and continues to move to positions with a better solution. It has no method against getting stuck in local optima.
Available parameters:
- epsilon=0.05
- distribution="normal"
- n_neighbours=3
- rand_rest_p=0
Use cases/properties:
- Never as a first method of optimization
- When you have a very good initial point to start from
- If the search space is very simple and has few local optima or saddle points
RepulsingHillClimbingOptimizer
Available parameters:
- epsilon=0.05
- distribution="normal"
- n_neighbours=3
- rand_rest_p=0
- repulsion_factor=3
Use cases/properties:
- When you have a good initial point to start from
SimulatedAnnealingOptimizer
Simulated annealing chooses its next possible position similar to hill climbing, but it accepts worse results with a probability that decreases with time:
It simulates a temperature that decreases with each iteration, similar to a material cooling down. The following normalization is used to calculate the probability independent of the metric:
Available parameters:
- epsilon=0.05
- distribution="normal"
- n_neighbours=3
- rand_rest_p=0
- annealing_rate=0.975
- start_temp=1
Use cases/properties:
- When you have a good initial point to start from, but expect the surrounding search space to be very complex
- Good as a second method of optimization
DownhillSimplexOptimizer
The downhill simplex optimization works by creating a polytope from n + 1 positions in the search space of n dimensions. This polytope is called a simplex, which can alter its shape with the following steps:
- reflecting
- expanding
- contracting
- shrinking
Available parameters:
- alpha=1,
- gamma=2,
- beta=0.5
- sigma=0.5
RandomSearchOptimizer
The random search explores by choosing a new position at random after each iteration. Some random search implementations choose a new position within a large hypersphere around the current position. The implementation in hyperactive is purely random across the search space in each step.
Use cases/properties:
- Very good as a first method of optimization or to start exploring the search space
- For a short optimization run to get an acceptable solution
GridSearchOptimizer
The grid-search explores the search space one step at a time following a diagonal grid like structure. It does not take the score from the objective function into account, but follows the grid until the entire search space is explored.
Available parameters:
- step_size=1
Use cases/properties:
- Very good as a first method of optimization or to start exploring the search space
RandomRestartHillClimbingOptimizer
Random restart hill climbing works by starting a hill climbing search and jumping to a random new position after a number of iterations.
Available parameters:
- epsilon=0.05
- distribution="normal"
- n_neighbours=3
- rand_rest_p=0
- n_iter_restart=10
Use cases/properties:
- Good as a first method of optimization
- For a short optimization run to get an acceptable solution
RandomAnnealingOptimizer
An algorithm that chooses a new position within a large hypersphere around the current position. This hypersphere gets smaller over time.
Available parameters:
- epsilon=0.05
- distribution="normal"
- n_neighbours=3
- rand_rest_p=0.03
- annealing_rate=0.975
- start_temp=1
Use cases/properties:
- Disclaimer: I have not seen this algorithm before, but invented it myself. It seems to be a good alternative to the other random algorithms
- Good as a first method of optimization
- For a short optimization run to get an acceptable solution
PowellsMethod
This powell's method implementation works by optimizing each search space dimension at a time with a hill climbing algorithm.
Available parameters:
- iters_p_dim=10
PatternSearch
The pattern search creates a cross-like pattern that moves its center position to the best surrounding position or shrinks if no better position is available.
Available parameters:
- n_positions=4
- pattern_size=0.25
- reduction=0.9
ParallelTemperingOptimizer
Parallel Tempering initializes multiple simulated annealing searches with different temperatures and chooses to swap those temperatures with the following probability:
Available parameters:
- population=10
- n_iter_swap=10
- rand_rest_p=0
Use cases/properties:
- Not as dependend of a good initial position as simulated annealing
- If you have enough time for many model evaluations
ParticleSwarmOptimizer
Particle swarm optimization works by initializing a number of positions at the same time and moving all of those closer to the best one after each iteration.
Available parameters:
- population=10
- inertia=0.5
- cognitive_weight=0.5
- social_weight=0.5
- rand_rest_p=0
Use cases/properties:
- If the search space is complex and large
- If you have enough time for many model evaluations
EvolutionStrategyOptimizer
Evolution strategy mutates and combines the best individuals of a population across a number of generations without transforming them into an array of bits (like genetic algorithms) but uses the real values of the positions.
Available parameters:
- population=10
- mutation_rate=0.7
- crossover_rate=0.3
- rand_rest_p=0
Use cases/properties:
- If the search space is very complex and large
- If you have enough time for many model evaluations
BayesianOptimizer
Bayesian optimization chooses new positions by calculating the expected improvement of every position in the search space based on a gaussian process that trains on already evaluated positions.
Available parameters:
- gpr=gaussian_process["gp_nonlinear"]
- xi=0.03
- warm_start_smbo=None
- rand_rest_p=0
Use cases/properties:
- If model evaluations take a long time
- If you do not want to do many iterations
- If your search space is not to big
TreeStructuredParzenEstimators
Tree of Parzen Estimators also chooses new positions by calculating the expected improvement. It does so by calculating the ratio of probability being among the best positions and the worst positions. Those probabilities are determined with a kernel density estimator, that is trained on alrady evaluated positions.
Available parameters:
- gamma_tpe=0.5
- warm_start_smbo=None
- rand_rest_p=0
Use cases/properties:
- If model evaluations take a long time
- If you do not want to do many iterations
- If your search space is not to big
ForestOptimizer
Available parameters:
- tree_regressor="extra_tree"
- xi=0.01
- warm_start_smbo=None
- rand_rest_p=0
epsilon
When climbing to new positions epsilon determines how far the hill climbing based algorithm jumps from one position to the next points. Higher epsilon leads to longer jumps.
available values: float
Used by:
- HillClimbingOptimizer
- RepulsingHillClimbingOptimizer
- SimulatedAnnealingOptimizer
- RandomRestartHillClimbingOptimizer
- RandomAnnealingOptimizer
- ParallelTemperingOptimizer
- ParticleSwarmOptimizer
- EvolutionStrategyOptimizer
distribution
The mathematical distribution the algorithm draws samples from.
available values: str; "normal", "laplace", "logistic", "gumbel"
Used by:
- HillClimbingOptimizer
- RepulsingHillClimbingOptimizer
- SimulatedAnnealingOptimizer
- RandomRestartHillClimbingOptimizer
- RandomAnnealingOptimizer
- ParallelTemperingOptimizer
- ParticleSwarmOptimizer
- EvolutionStrategyOptimizer
n_neighbours
The number of positions the algorithm explores from its current postion before jumping to the best one.
available values: int
Used by:
- HillClimbingOptimizer
- RepulsingHillClimbingOptimizer
- SimulatedAnnealingOptimizer
- RandomRestartHillClimbingOptimizer
- RandomAnnealingOptimizer
- ParallelTemperingOptimizer
- ParticleSwarmOptimizer
- EvolutionStrategyOptimizer
rand_rest_p
Probability for the optimization algorithm to jump to a random position in an iteration step.
available values: float; [0.0, ... ,0.5, ... ,1]
Used by:
- HillClimbingOptimizer
- RepulsingHillClimbingOptimizer
- SimulatedAnnealingOptimizer
- RandomRestartHillClimbingOptimizer
- RandomAnnealingOptimizer
- ParallelTemperingOptimizer
- ParticleSwarmOptimizer
- EvolutionStrategyOptimizer
- BayesianOptimizer
- TreeStructuredParzenEstimators
- ForestOptimizer
repulsion_factor
If the algorithm does not find a better position the repulsion factor increases epsilon for the next jump.
available values: float
Used by:
- RepulsingHillClimbingOptimizer
annealing_rate
Rate at which the temperatur-value of the algorithm decreases. An annealing rate above 1 increases the temperature over time.
available values: float; [0.0, ... ,0.5, ... ,1]
Used by:
- SimulatedAnnealingOptimizer
- RandomAnnealingOptimizer
- ParallelTemperingOptimizer
start_temp
The start temperatur determines the probability for the algorithm to jump to a worse position.
available values: float
Used by:
- SimulatedAnnealingOptimizer
- RandomAnnealingOptimizer
- ParallelTemperingOptimizer
alpha
Reflection parameter of the simplex algorithm.
available values: float
Used by:
- DownhillSimplexOptimizer
gamma
Expansion parameter of the simplex algorithm.
available values: float
Used by:
- DownhillSimplexOptimizer
beta
Contraction parameter of the simplex algorithm.
available values: float
Used by:
- DownhillSimplexOptimizer
sigma
Shrinking parameter of the simplex algorithm.
available values: float
Used by:
- DownhillSimplexOptimizer
step_size
The number of steps the grid search takes after each iteration. If this parameter is set to 3 the grid search won't select the next position, but the one it would normally select after 3 iterations. This way we get a sparse grid after the first pass through the search space. After the first pass is done the grid search starts at the beginning and does a second pass with the same step size. And a third pass after that.
available values: int
Used by:
- GridSearchOptimizer
n_iter_restart
The number of iterations the algorithm performs before jumping to a random position.
available values: int
Used by:
- RandomRestartHillClimbingOptimizer
iters_p_dim
Number of iterations per dimension of the search space.
available values: int
Used by:
- PowellsMethod
n_positions
Number of positions that the pattern contains.
available values: int
Used by:
- PatternSearch
pattern_size
Size of the patterns in percentage of the size of the search space in the corresponding dimension.
available values: int
Used by:
- PatternSearch
reduction
Factor to change the size of the pattern when no better position is found.
available values: int
Used by:
- PatternSearch
n_iter_swap
The number of iterations the algorithm performs before switching temperatures of the individual optimizers in the population.
available values: int
Used by:
- ParallelTemperingOptimizer
population
Size of the population for population-based optimization algorithms.
available values: float
Used by:
- ParallelTemperingOptimizer
- ParticleSwarmOptimizer
- EvolutionStrategyOptimizer
inertia
The inertia of the movement of the individual optimizers in the population.
available values: float
Used by:
- ParticleSwarmOptimizer
cognitive_weight
A factor of the movement towards the personal best position of the individual optimizers in the population.
available values: float
Used by:
- ParticleSwarmOptimizer
social_weight
A factor of the movement towards the global best position of the individual optimizers in the population.
available values: float
Used by:
- ParticleSwarmOptimizer
mutation_rate
Probability of an individual in the population to perform an hill climbing step.
available values: float
Used by:
- EvolutionStrategyOptimizer
crossover_rate
Probability of an individual to perform a crossover with the best individual in the population.
available values: float
Used by:
- EvolutionStrategyOptimizer
gpr
The access to the surrogate model class. Example surrogate model classes can be found in a separate repository.
available values: class
Used by:
- BayesianOptimizer
xi
Parameter for the expected uncertainty of the estimation.
available values: float
Used by:
- BayesianOptimizer
- ForestOptimizer
warm_start_smbo
Dataframe that contains the search data of a previous optimization run.
available values: dataframe
Used by:
- BayesianOptimizer
- TreeStructuredParzenEstimators
- ForestOptimizer
gamma_tpe
Separates the explored positions into good and bad.
available values: float; [0.0, ... ,0.5, ... ,1]
Used by:
- TreeStructuredParzenEstimators
tree_regressor
The access to the surrogate model class. Example surrogate model classes can be found in a separate repository.
available values: class
Used by:
- ForestOptimizer