Using BERT model as a sentence encoding service, i.e. mapping a variable-length sentence to a fixed-length vector.






Highlights • What is it • Install • Getting Started • API • Tutorials • FAQ • Benchmark • Blog
Made by Han Xiao • 🌐 https://hanxiao.github.io
BERT is a NLP model developed by Google for pre-training language representations. It leverages an enormous amount of plain text data publicly available on the web and is trained in an unsupervised manner. Pre-training a BERT model is a fairly expensive yet one-time procedure for each language. Fortunately, Google released several pre-trained models where you can download from here.
Sentence Encoding/Embedding is a upstream task required in many NLP applications, e.g. sentiment analysis, text classification. The goal is to represent a variable length sentence into a fixed length vector, e.g. hello world to [0.1, 0.3, 0.9]. Each element of the vector should "encode" some semantics of the original sentence.
Finally, bert-as-service uses BERT as a sentence encoder and hosts it as a service via ZeroMQ, allowing you to map sentences into fixed-length representations in just two lines of code.
- 🔭 State-of-the-art: build on pretrained 12/24-layer BERT models released by Google AI, which is considered as a milestone in the NLP community.
- 🐣 Easy-to-use: require only two lines of code to get sentence/token-level encodes.
- ⚡ Fast: 900 sentences/s on a single Tesla M40 24GB. Low latency, optimized for speed. See benchmark.
- 🐙 Scalable: scale nicely and smoothly on multiple GPUs and multiple clients without worrying about concurrency. See benchmark.
- 💎 Reliable: tested on multi-billion sentences; days of running without a break or OOM or any nasty exceptions.
More features: XLA & FP16 support; mix GPU-CPU workloads; optimized graph; tf.data friendly; customized tokenizer; flexible pooling strategy; build-in HTTP server and dashboard; async encoding; multicasting; etc.
Install the server and client via pip. They can be installed separately or even on different machines:
pip install bert-serving-server # server
pip install bert-serving-client # client, independent of `bert-serving-server`Note that the server MUST be running on Python >= 3.5 with Tensorflow >= 1.10 (one-point-ten). Again, the server does not support Python 2!
☝️ The client can be running on both Python 2 and 3 for the following consideration.
Download a model listed below, then uncompress the zip file into some folder, say /tmp/english_L-12_H-768_A-12/
List of released pretrained BERT models (click to expand...)
| BERT-Base, Uncased | 12-layer, 768-hidden, 12-heads, 110M parameters |
| BERT-Large, Uncased | 24-layer, 1024-hidden, 16-heads, 340M parameters |
| BERT-Base, Cased | 12-layer, 768-hidden, 12-heads , 110M parameters |
| BERT-Large, Cased | 24-layer, 1024-hidden, 16-heads, 340M parameters |
| BERT-Base, Multilingual Cased (New) | 104 languages, 12-layer, 768-hidden, 12-heads, 110M parameters |
| BERT-Base, Multilingual Cased (Old) | 102 languages, 12-layer, 768-hidden, 12-heads, 110M parameters |
| BERT-Base, Chinese | Chinese Simplified and Traditional, 12-layer, 768-hidden, 12-heads, 110M parameters |
Optional: fine-tuning the model on your downstream task. Why is it optional?
After installing the server, you should be able to use bert-serving-start CLI as follows:
bert-serving-start -model_dir /tmp/english_L-12_H-768_A-12/ -num_worker=4 This will start a service with four workers, meaning that it can handle up to four concurrent requests. More concurrent requests will be queued in a load balancer. Details can be found in our FAQ and the benchmark on number of clients.
Below shows what the server looks like when starting correctly:

Alternatively, one can start the BERT Service in a Docker Container (click to expand...)
docker build -t bert-as-service -f ./docker/Dockerfile .
NUM_WORKER=1
PATH_MODEL=/PATH_TO/_YOUR_MODEL/
docker run --runtime nvidia -dit -p 5555:5555 -p 5556:5556 -v $PATH_MODEL:/model -t bert-as-service $NUM_WORKERNow you can encode sentences simply as follows:
from bert_serving.client import BertClient
bc = BertClient()
bc.encode(['First do it', 'then do it right', 'then do it better'])It will return a ndarray (or List[List[float]] if you wish), in which each row is a fixed-length vector representing a sentence. Having thousands of sentences? Just encode! Don't even bother to batch, the server will take care of it.
As a feature of BERT, you may get encodes of a pair of sentences by concatenating them with ||| (with whitespace before and after), e.g.
bc.encode(['First do it ||| then do it right'])Below shows what the server looks like while encoding:

One may also start the service on one (GPU) machine and call it from another (CPU) machine as follows:
# on another CPU machine
from bert_serving.client import BertClient
bc = BertClient(ip='xx.xx.xx.xx') # ip address of the GPU machine
bc.encode(['First do it', 'then do it right', 'then do it better'])Note that you only need pip install -U bert-serving-client in this case, the server side is not required. You may also call the service via HTTP requests.
💡 Want to learn more? Checkout our tutorials:
- Building a QA semantic search engine in 3 min.
- Serving a fine-tuned BERT model
- Getting ELMo-like contextual word embedding
- Using your own tokenizer
- Using
BertClientwithtf.dataAPI- Training a text classifier using BERT features and tf.estimator API
- Saving and loading with TFRecord data
- Asynchronous encoding
- Broadcasting to multiple clients
- Monitoring the service status in a dashboard
- Using
bert-as-serviceto serve HTTP requests in JSON- Starting
BertServerfrom Python
The best way to learn bert-as-service latest API is reading the documentation.
Please always refer to the latest server-side API documented here., you may get the latest usage via:
bert-serving-start --help
bert-serving-terminate --help
bert-serving-benchmark --help| Argument | Type | Default | Description |
|---|---|---|---|
model_dir |
str | Required | folder path of the pre-trained BERT model. |
tuned_model_dir |
str | (Optional) | folder path of a fine-tuned BERT model. |
ckpt_name |
str | bert_model.ckpt |
filename of the checkpoint file. |
config_name |
str | bert_config.json |
filename of the JSON config file for BERT model. |
graph_tmp_dir |
str | None | path to graph temp file |
max_seq_len |
int | 25 |
maximum length of sequence, longer sequence will be trimmed on the right side. Set it to NONE for dynamically using the longest sequence in a (mini)batch. |
cased_tokenization |
bool | False | Whether tokenizer should skip the default lowercasing and accent removal. Should be used for e.g. the multilingual cased pretrained BERT model. |
mask_cls_sep |
bool | False | masking the embedding on [CLS] and [SEP] with zero. |
num_worker |
int | 1 |
number of (GPU/CPU) worker runs BERT model, each works in a separate process. |
max_batch_size |
int | 256 |
maximum number of sequences handled by each worker, larger batch will be partitioned into small batches. |
priority_batch_size |
int | 16 |
batch smaller than this size will be labeled as high priority, and jumps forward in the job queue to get result faster |
port |
int | 5555 |
port for pushing data from client to server |
port_out |
int | 5556 |
port for publishing results from server to client |
http_port |
int | None | server port for receiving HTTP requests |
cors |
str | * |
setting "Access-Control-Allow-Origin" for HTTP requests |
pooling_strategy |
str | REDUCE_MEAN |
the pooling strategy for generating encoding vectors, valid values are NONE, REDUCE_MEAN, REDUCE_MAX, REDUCE_MEAN_MAX, CLS_TOKEN, FIRST_TOKEN, SEP_TOKEN, LAST_TOKEN. Explanation of these strategies can be found here. To get encoding for each token in the sequence, please set this to NONE. |
pooling_layer |
list | [-2] |
the encoding layer that pooling operates on, where -1 means the last layer, -2 means the second-to-last, [-1, -2] means concatenating the result of last two layers, etc. |
gpu_memory_fraction |
float | 0.5 |
the fraction of the overall amount of memory that each GPU should be allocated per worker |
cpu |
bool | False | run on CPU instead of GPU |
xla |
bool | False | enable XLA compiler for graph optimization (experimental!) |
fp16 |
bool | False | use float16 precision (experimental) |
device_map |
list | [] |
specify the list of GPU device ids that will be used (id starts from 0) |
show_tokens_to_client |
bool | False | sending tokenization results to client |
Please always refer to the latest client-side API documented here. Client-side provides a Python class called BertClient, which accepts arguments as follows:
| Argument | Type | Default | Description |
|---|---|---|---|
ip |
str | localhost |
IP address of the server |
port |
int | 5555 |
port for pushing data from client to server, must be consistent with the server side config |
port_out |
int | 5556 |
port for publishing results from server to client, must be consistent with the server side config |
output_fmt |
str | ndarray |
the output format of the sentence encodes, either in numpy array or python List[List[float]] (ndarray/list) |
show_server_config |
bool | False |
whether to show server configs when first connected |
check_version |
bool | True |
whether to force client and server to have the same version |
identity |
str | None |
a UUID that identifies the client, useful in multi-casting |
timeout |
int | -1 |
set the timeout (milliseconds) for receive operation on the client |
A BertClient implements the following methods and properties:
| Method | Description |
|---|---|
.encode() |
Encode a list of strings to a list of vectors |
.encode_async() |
Asynchronous encode batches from a generator |
.fetch() |
Fetch all encoded vectors from server and return them in a generator, use it with .encode_async() or .encode(blocking=False). Sending order is NOT preserved. |
.fetch_all() |
Fetch all encoded vectors from server and return them in a list, use it with .encode_async() or .encode(blocking=False). Sending order is preserved. |
.close() |
Gracefully close the connection between the client and the server |
.status |
Get the client status in JSON format |
.server_status |
Get the server status in JSON format |
The full list of examples can be found in example/. You can run each via python example/example-k.py. Most of examples require you to start a BertServer first, please follow the instruction here. Note that although BertClient works universally on both Python 2.x and 3.x, examples are only tested on Python 3.6.
Table of contents (click to expand...)
- Building a QA semantic search engine in 3 min.
- Serving a fine-tuned BERT model
- Getting ELMo-like contextual word embedding
- Using your own tokenizer
- Using
BertClientwithtf.dataAPI- Training a text classifier using BERT features and tf.estimator API
- Saving and loading with TFRecord data
- Asynchronous encoding
- Broadcasting to multiple clients
- Monitoring the service status in a dashboard
- Using
bert-as-serviceto serve HTTP requests in JSON- Starting
BertServerfrom Python
The complete example can be found example8.py.
As the first example, we will implement a simple QA search engine using bert-as-service in just three minutes. No kidding! The goal is to find similar questions to user's input and return the corresponding answer. To start, we need a list of question-answer pairs. Fortunately, this README file already contains a list of FAQ, so I will just use that to make this example perfectly self-contained. Let's first load all questions and show some statistics.
prefix_q = '##### **Q:** '
with open('README.md') as fp:
questions = [v.replace(prefix_q, '').strip() for v in fp if v.strip() and v.startswith(prefix_q)]
print('%d questions loaded, avg. len of %d' % (len(questions), np.mean([len(d.split()) for d in questions])))This gives 33 questions loaded, avg. len of 9. So looks like we have enough questions. Now start a BertServer with uncased_L-12_H-768_A-12 pretrained BERT model:
bert-serving-start -num_worker=1 -model_dir=/data/cips/data/lab/data/model/uncased_L-12_H-768_A-12Next, we need to encode our questions into vectors:
bc = BertClient(port=4000, port_out=4001)
doc_vecs = bc.encode(questions)Finally, we are ready to receive new query and perform a simple "fuzzy" search against the existing questions. To do that, every time a new query is coming, we encode it as a vector and compute its dot product with doc_vecs; sort the result descendingly; and return the top-k similar questions as follows:
while True:
query = input('your question: ')
query_vec = bc.encode([query])[0]
# compute normalized dot product as score
score = np.sum(query_vec * doc_vecs, axis=1) / np.linalg.norm(doc_vecs, axis=1)
topk_idx = np.argsort(score)[::-1][:topk]
for idx in topk_idx:
print('> %s\t%s' % (score[idx], questions[idx]))That's it! Now run the code and type your query, see how this search engine handles fuzzy match:

Pretrained BERT models often show quite "okayish" performance on many tasks. However, to release the true power of BERT a fine-tuning on the downstream task (or on domain-specific data) is necessary. In this example, I will show you how to serve a fine-tuned BERT model.
We follow the instruction in "Sentence (and sentence-pair) classification tasks" and use run_classifier.py to fine tune uncased_L-12_H-768_A-12 model on MRPC task. The fine-tuned model is stored at /tmp/mrpc_output/, which can be changed by specifying --output_dir of run_classifier.py.
If you look into /tmp/mrpc_output/, it contains something like:
checkpoint 128
eval 4.0K
eval_results.txt 86
eval.tf_record 219K
events.out.tfevents.1545202214.TENCENT64.site 6.1M
events.out.tfevents.1545203242.TENCENT64.site 14M
graph.pbtxt 9.0M
model.ckpt-0.data-00000-of-00001 1.3G
model.ckpt-0.index 23K
model.ckpt-0.meta 3.9M
model.ckpt-343.data-00000-of-00001 1.3G
model.ckpt-343.index 23K
model.ckpt-343.meta 3.9M
train.tf_record 2.0MDon't be afraid of those mysterious files, as the only important one to us is model.ckpt-343.data-00000-of-00001 (looks like my training stops at the 343 step. One may get model.ckpt-123.data-00000-of-00001 or model.ckpt-9876.data-00000-of-00001 depending on the total training steps). Now we have collected all three pieces of information that are needed for serving this fine-tuned model:
- The pretrained model is downloaded to
/path/to/bert/uncased_L-12_H-768_A-12 - Our fine-tuned model is stored at
/tmp/mrpc_output/; - Our fine-tuned model checkpoint is named as
model.ckpt-343something something.
Now start a BertServer by putting three pieces together:
bert-serving-start -model_dir=/pretrained/uncased_L-12_H-768_A-12 -tuned_model_dir=/tmp/mrpc_output/ -ckpt_name=model.ckpt-343After the server started, you should find this line in the log:
I:GRAPHOPT:[gra:opt: 50]:checkpoint (override by fine-tuned model): /tmp/mrpc_output/model.ckpt-343
Which means the BERT parameters is overrode and successfully loaded from our fine-tuned /tmp/mrpc_output/model.ckpt-343. Done!
In short, find your fine-tuned model path and checkpoint name, then feed them to -tuned_model_dir and -ckpt_name, respectively.
Start the server with pooling_strategy set to NONE.
bert-serving-start -pooling_strategy NONE -model_dir /tmp/english_L-12_H-768_A-12/To get the word embedding corresponds to every token, you can simply use slice index as follows:
# max_seq_len = 25
# pooling_strategy = NONE
bc = BertClient()
vec = bc.encode(['hey you', 'whats up?'])
vec # [2, 25, 768]
vec[0] # [1, 25, 768], sentence embeddings for `hey you`
vec[0][0] # [1, 1, 768], word embedding for `[CLS]`
vec[0][1] # [1, 1, 768], word embedding for `hey`
vec[0][2] # [1, 1, 768], word embedding for `you`
vec[0][3] # [1, 1, 768], word embedding for `[SEP]`
vec[0][4] # [1, 1, 768], word embedding for padding symbol
vec[0][25] # error, out of index!Note that no matter how long your original sequence is, the service will always return a [max_seq_len, 768] matrix for every sequence. When using slice index to get the word embedding, beware of the special tokens padded to the sequence, i.e. [CLS], [SEP], 0_PAD.
Often you want to use your own tokenizer to segment sentences instead of the default one from BERT. Simply call encode(is_tokenized=True) on the client slide as follows:
texts = ['hello world!', 'good day']
# a naive whitespace tokenizer
texts2 = [s.split() for s in texts]
vecs = bc.encode(texts2, is_tokenized=True)This gives [2, 25, 768] tensor where the first [1, 25, 768] corresponds to the token-level encoding of "hello world!". If you look into its values, you will find that only the first four elements, i.e. [1, 0:3, 768] have values, all the others are zeros. This is due to the fact that BERT considers "hello world!" as four tokens: [CLS] hello world! [SEP], the rest are padding symbols and are masked out before output.
Note that there is no need to start a separate server for handling tokenized/untokenized sentences. The server can tell and handle both cases automatically.
Sometimes you want to know explicitly the tokenization performed on the server side to have better understanding of the embedding result. One such case is asking word embedding from the server (with -pooling_strategy NONE), one wants to tell which word is tokenized and which is unrecognized. You can get such information with the following steps:
- enabling
-show_tokens_to_clienton the server side; - calling the server via
encode(..., show_tokens=True).
For example, a basic usage like
bc.encode(['hello world!', 'thisis it'], show_tokens=True)returns a tuple, where the first element is the embedding and the second is the tokenization result from the server:
(array([[[ 0. , -0. , 0. , ..., 0. , -0. , -0. ],
[ 1.1100919 , -0.20474958, 0.9895898 , ..., 0.3873255 , -1.4093989 , -0.47620595],
..., -0. , -0. ]],
[[ 0. , -0. , 0. , ..., 0. , 0. , 0. ],
[ 0.6293478 , -0.4088499 , 0.6022662 , ..., 0.41740108, 1.214456 , 1.2532915 ],
..., 0. , 0. ]]], dtype=float32),
[['[CLS]', 'hello', 'world', '!', '[SEP]'], ['[CLS]', 'this', '##is', 'it', '[SEP]']])
When using your own tokenization, you may still want to check if the server respects your tokens. For example,
bc.encode([['hello', 'world!'], ['thisis', 'it']], show_tokens=True, is_tokenized=True)returns:
(array([[[ 0. , -0. , 0. , ..., 0. , -0. , 0. ],
[ 1.1111546 , -0.56572634, 0.37183186, ..., 0.02397121, -0.5445367 , 1.1009651 ],
..., -0. , 0. ]],
[[ 0. , 0. , 0. , ..., 0. , -0. , 0. ],
[ 0.39262453, 0.3782491 , 0.27096173, ..., 0.7122045 , -0.9874849 , 0.9318679 ],
..., -0. , 0. ]]], dtype=float32),
[['[CLS]', 'hello', '[UNK]', '[SEP]'], ['[CLS]', '[UNK]', 'it', '[SEP]']])
One can observe that world! and thisis are not recognized on the server, hence they are set to [UNK].
Finally, beware that the pretrained BERT Chinese from Google is character-based, i.e. its vocabulary is made of single Chinese characters. Therefore it makes no sense if you use word-level segmentation algorithm to pre-process the data and feed to such model.
Extremely curious readers may notice that the first row in the above example is all-zero even though the tokenization result includes [CLS] (well done, detective!). The reason is that the tokenization result will always includes [CLS] and [UNK] regardless the setting of -mask_cls_sep. This could be useful when you want to align the tokens afterwards. Remember, -mask_cls_sep only masks [CLS] and [SEP] out of the computation. It doesn't affect the tokenization algorithm.
The complete example can be found example4.py. There is also an example in Keras.
The tf.data API enables you to build complex input pipelines from simple, reusable pieces. One can also use BertClient to encode sentences on-the-fly and use the vectors in a downstream model. Here is an example:
batch_size = 256
num_parallel_calls = 4
num_clients = num_parallel_calls * 2 # should be at least greater than `num_parallel_calls`
# start a pool of clients
bc_clients = [BertClient(show_server_config=False) for _ in range(num_clients)]
def get_encodes(x):
# x is `batch_size` of lines, each of which is a json object
samples = [json.loads(l) for l in x]
text = [s['raw_text'] for s in samples] # List[List[str]]
labels = [s['label'] for s in samples] # List[str]
# get a client from available clients
bc_client = bc_clients.pop()
features = bc_client.encode(text)
# after use, put it back
bc_clients.append(bc_client)
return features, labels
ds = (tf.data.TextLineDataset(train_fp).batch(batch_size)
.map(lambda x: tf.py_func(get_encodes, [x], [tf.float32, tf.string]), num_parallel_calls=num_parallel_calls)
.map(lambda x, y: {'feature': x, 'label': y})
.make_one_shot_iterator().get_next())The trick here is to start a pool of BertClient and reuse them one by one. In this way, we can fully harness the power of num_parallel_calls of Dataset.map() API.
The complete example can be found example5.py.
Following the last example, we can easily extend it to a full classifier using tf.estimator API. One only need minor change on the input function as follows:
estimator = DNNClassifier(
hidden_units=[512],
feature_columns=[tf.feature_column.numeric_column('feature', shape=(768,))],
n_classes=len(laws),
config=run_config,
label_vocabulary=laws_str,
dropout=0.1)
input_fn = lambda fp: (tf.data.TextLineDataset(fp)
.apply(tf.contrib.data.shuffle_and_repeat(buffer_size=10000))
.batch(batch_size)
.map(lambda x: tf.py_func(get_encodes, [x], [tf.float32, tf.string]), num_parallel_calls=num_parallel_calls)
.map(lambda x, y: ({'feature': x}, y))
.prefetch(20))
train_spec = TrainSpec(input_fn=lambda: input_fn(train_fp))
eval_spec = EvalSpec(input_fn=lambda: input_fn(eval_fp), throttle_secs=0)
train_and_evaluate(estimator, train_spec, eval_spec)The complete example can be found example5.py, in which a simple MLP is built on BERT features for predicting the relevant articles according to the fact description in the law documents. The problem is a part of the Chinese AI and Law Challenge Competition.
The complete example can be found example6.py.
The TFRecord file format is a simple record-oriented binary format that many TensorFlow applications use for training data. You can also pre-encode all your sequences and store their encodings to a TFRecord file, then later load it to build a tf.Dataset. For example, to write encoding into a TFRecord file:
bc = BertClient()
list_vec = bc.encode(lst_str)
list_label = [0 for _ in lst_str] # a dummy list of all-zero labels
# write to tfrecord
with tf.python_io.TFRecordWriter('tmp.tfrecord') as writer:
def create_float_feature(values):
return tf.train.Feature(float_list=tf.train.FloatList(value=values))
def create_int_feature(values):
return tf.train.Feature(int64_list=tf.train.Int64List(value=list(values)))
for (vec, label) in zip(list_vec, list_label):
features = {'features': create_float_feature(vec), 'labels': create_int_feature([label])}
tf_example = tf.train.Example(features=tf.train.Features(feature=features))
writer.write(tf_example.SerializeToString())Now we can load from it and build a tf.Dataset:
def _decode_record(record):
"""Decodes a record to a TensorFlow example."""
return tf.parse_single_example(record, {
'features': tf.FixedLenFeature([768], tf.float32),
'labels': tf.FixedLenFeature([], tf.int64),
})
ds = (tf.data.TFRecordDataset('tmp.tfrecord').repeat().shuffle(buffer_size=100).apply(
tf.contrib.data.map_and_batch(lambda record: _decode_record(record), batch_size=64))
.make_one_shot_iterator().get_next())To save word/token-level embedding to TFRecord, one needs to first flatten [max_seq_len, num_hidden] tensor into an 1D array as follows:
def create_float_feature(values):
return tf.train.Feature(float_list=tf.train.FloatList(value=values.reshape(-1)))And later reconstruct the shape when loading it:
name_to_features = {
"feature": tf.FixedLenFeature([max_seq_length * num_hidden], tf.float32),
"label_ids": tf.FixedLenFeature([], tf.int64),
}
def _decode_record(record, name_to_features):
"""Decodes a record to a TensorFlow example."""
example = tf.parse_single_example(record, name_to_features)
example['feature'] = tf.reshape(example['feature'], [max_seq_length, -1])
return exampleBe careful, this will generate a huge TFRecord file.
The complete example can be found example2.py.
BertClient.encode() offers a nice synchronous way to get sentence encodes. However, sometimes we want to do it in an asynchronous manner by feeding all textual data to the server first, fetching the encoded results later. This can be easily done by:
# an endless data stream, generating data in an extremely fast speed
def text_gen():
while True:
yield lst_str # yield a batch of text lines
bc = BertClient()
# get encoded vectors
for j in bc.encode_async(text_gen(), max_num_batch=10):
print('received %d x %d' % (j.shape[0], j.shape[1]))The complete example can be found in example3.py.
The encoded result is routed to the client according to its identity. If you have multiple clients with same identity, then they all receive the results! You can use this multicast feature to do some cool things, e.g. training multiple different models (some using scikit-learn some using tensorflow) in multiple separated processes while only call BertServer once. In the example below, bc and its two clones will all receive encoded vector.
# clone a client by reusing the identity
def client_clone(id, idx):
bc = BertClient(identity=id)
for j in bc.listen():
print('clone-client-%d: received %d x %d' % (idx, j.shape[0], j.shape[1]))
bc = BertClient()
# start two cloned clients sharing the same identity as bc
for j in range(2):
threading.Thread(target=client_clone, args=(bc.identity, j)).start()
for _ in range(3):
bc.encode(lst_str)The complete example can be found in plugin/dashboard/.
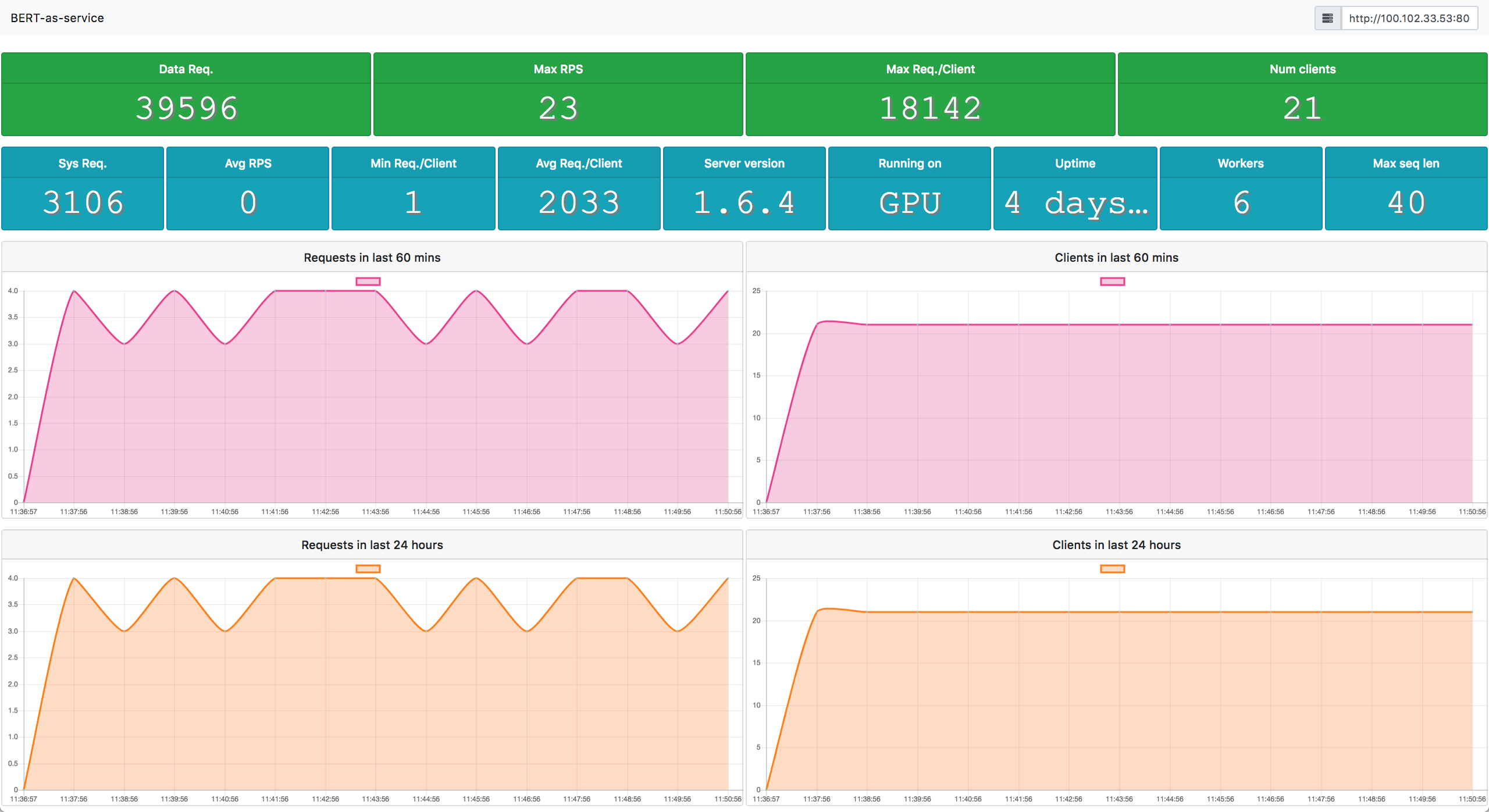
As a part of the infrastructure, one may also want to monitor the service status and show it in a dashboard. To do that, we can use:
bc = BertClient(ip='server_ip')
json.dumps(bc.server_status, ensure_ascii=False)This gives the current status of the server including number of requests, number of clients etc. in JSON format. The only thing remained is to start a HTTP server for returning this JSON to the frontend that renders it.
Alternatively, one may simply expose an HTTP port when starting a server via:
bert-serving-start -http_port 8001 -model_dir ...This will allow one to use javascript or curl to fetch the server status at port 8001.
plugin/dashboard/index.html shows a simple dashboard based on Bootstrap and Vue.js.
Besides calling bert-as-service from Python, one can also call it via HTTP request in JSON. It is quite useful especially when low transport layer is prohibited. Behind the scene, bert-as-service spawns a Flask server in a separate process and then reuse a BertClient instance as a proxy to communicate with the ventilator.
To enable the build-in HTTP server, we need to first (re)install the server with some extra Python dependencies:
pip install -U bert-serving-server[http]Then simply start the server with:
bert-serving-start -model_dir=/YOUR_MODEL -http_port 8125Done! Your server is now listening HTTP and TCP requests at port 8125 simultaneously!
To send a HTTP request, first prepare the payload in JSON as following:
{
"id": 123,
"texts": ["hello world", "good day!"],
"is_tokenized": false
}, where id is a unique identifier helping you to synchronize the results; is_tokenized follows the meaning in BertClient API and false by default.
Then simply call the server at /encode via HTTP POST request. You can use javascript or whatever, here is an example using curl:
curl -X POST http://xx.xx.xx.xx:8125/encode \
-H 'content-type: application/json' \
-d '{"id": 123,"texts": ["hello world"], "is_tokenized": false}', which returns a JSON:
{
"id": 123,
"results": [[768 float-list], [768 float-list]],
"status": 200
}To get the server's status and client's status, you can send GET requests at /status/server and /status/client, respectively.
Finally, one may also config CORS to restrict the public access of the server by specifying -cors when starting bert-serving-start. By default -cors=*, meaning the server is public accessible.
Besides shell, one can also start a BertServer from python. Simply do
from bert_serving.server.helper import get_args_parser
from bert_serving.server import BertServer
args = get_args_parser().parse_args(['-model_dir', 'YOUR_MODEL_PATH_HERE',
'-port', '5555',
'-port_out', '5556',
'-max_seq_len', 'NONE',
'-mask_cls_sep',
'-cpu'])
server = BertServer(args)
server.start()Note that it's basically mirroring the arg-parsing behavior in CLI, so everything in that .parse_args([]) list should be string, e.g. ['-port', '5555'] not ['-port', 5555].
To shutdown the server, you may call the static method in BertServer class via:
BertServer.shutdown(port=5555)Or via shell CLI:
bert-serving-terminate -port 5555This will terminate the server running on localhost at port 5555. You may also use it to terminate a remote server, see bert-serving-terminate --help for details.
The design philosophy and technical details can be found in my blog post.
A: BERT code of this repo is forked from the original BERT repo with necessary modification, especially in extract_features.py.
In general, each sentence is translated to a 768-dimensional vector. Depending on the pretrained BERT you are using, pooling_strategy and pooling_layer the dimensions of the output vector could be different.
A: Yes, pooling is required to get a fixed representation of a sentence. In the default strategy REDUCE_MEAN, I take the second-to-last hidden layer of all of the tokens in the sentence and do average pooling.
A: Yes and no. On the one hand, Google pretrained BERT on Wikipedia data, thus should encode enough prior knowledge of the language into the model. Having such feature is not a bad idea. On the other hand, these prior knowledge is not specific to any particular domain. It should be totally reasonable if the performance is not ideal if you are using it on, for example, classifying legal cases. Nonetheless, you can always first fine-tune your own BERT on the downstream task and then use bert-as-service to extract the feature vectors efficiently. Keep in mind that bert-as-service is just a feature extraction service based on BERT. Nothing stops you from using a fine-tuned BERT.
A: Sure! Just use a list of the layer you want to concatenate when calling the server. Example:
bert-serving-start -pooling_layer -4 -3 -2 -1 -model_dir /tmp/english_L-12_H-768_A-12/A: Here is a table summarizes all pooling strategies I implemented. Choose your favorite one by specifying bert-serving-start -pooling_strategy.
| Strategy | Description |
|---|---|
NONE |
no pooling at all, useful when you want to use word embedding instead of sentence embedding. This will results in a [max_seq_len, 768] encode matrix for a sequence. |
REDUCE_MEAN |
take the average of the hidden state of encoding layer on the time axis |
REDUCE_MAX |
take the maximum of the hidden state of encoding layer on the time axis |
REDUCE_MEAN_MAX |
do REDUCE_MEAN and REDUCE_MAX separately and then concat them together on the last axis, resulting in 1536-dim sentence encodes |
CLS_TOKEN or FIRST_TOKEN |
get the hidden state corresponding to [CLS], i.e. the first token |
SEP_TOKEN or LAST_TOKEN |
get the hidden state corresponding to [SEP], i.e. the last token |
Q: Why not use the hidden state of the first token as default strategy, i.e. the [CLS]?
A: Because a pre-trained model is not fine-tuned on any downstream tasks yet. In this case, the hidden state of [CLS] is not a good sentence representation. If later you fine-tune the model, you may use [CLS] as well.
A: By default this service works on the second last layer, i.e. pooling_layer=-2. You can change it by setting pooling_layer to other negative values, e.g. -1 corresponds to the last layer.
Q: Why not the last hidden layer? Why second-to-last?
A: The last layer is too closed to the target functions (i.e. masked language model and next sentence prediction) during pre-training, therefore may be biased to those targets. If you question about this argument and want to use the last hidden layer anyway, please feel free to set pooling_layer=-1.
A: It depends. Keep in mind that different BERT layers capture different information. To see that more clearly, here is a visualization on UCI-News Aggregator Dataset, where I randomly sample 20K news titles; get sentence encodes from different layers and with different pooling strategies, finally reduce it to 2D via PCA (one can of course do t-SNE as well, but that's not my point). There are only four classes of the data, illustrated in red, blue, yellow and green. To reproduce the result, please run example7.py.

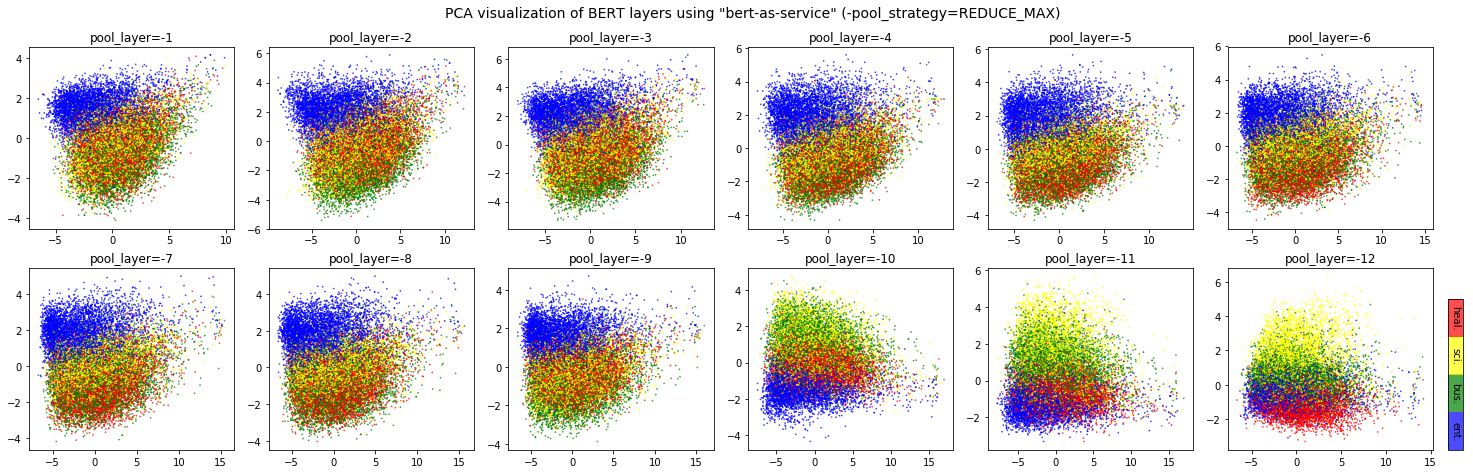
Intuitively, pooling_layer=-1 is close to the training output, so it may be biased to the training targets. If you don't fine tune the model, then this could lead to a bad representation. pooling_layer=-12 is close to the word embedding, may preserve the very original word information (with no fancy self-attention etc.). On the other hand, you may achieve the very same performance by simply using a word-embedding only. That said, anything in-between [-1, -12] is then a trade-off.
A: For sure. But if you introduce new tf.variables to the graph, then you need to train those variables before using the model. You may also want to check some pooling techniques I mentioned in my blog post.
No, not at all. Just do encode and let the server handles the rest. If the batch is too large, the server will do batching automatically and it is more efficient than doing it by yourself. No matter how many sentences you have, 10K or 100K, as long as you can hold it in client's memory, just send it to the server. Please also read the benchmark on the client batch size.
A: Yes! That's the purpose of this repo. In fact you can start as many clients as you want. One server can handle all of them (given enough time).
A: The maximum number of concurrent requests is determined by num_worker in bert-serving-start. If you a sending more than num_worker requests concurrently, the new requests will be temporally stored in a queue until a free worker becomes available.
A: No. One request means a list of sentences sent from a client. Think the size of a request as the batch size. A request may contain 256, 512 or 1024 sentences. The optimal size of a request is often determined empirically. One large request can certainly improve the GPU utilization, yet it also increases the overhead of transmission. You may run python example/example1.py for a simple benchmark.
A: It highly depends on the max_seq_len and the size of a request. On a single Tesla M40 24GB with max_seq_len=40, you should get about 470 samples per second using a 12-layer BERT. In general, I'd suggest smaller max_seq_len (25) and larger request size (512/1024).
A: Yes. See Benchmark.
To reproduce the results, please run bert-serving-benchmark.
A: ZeroMQ.
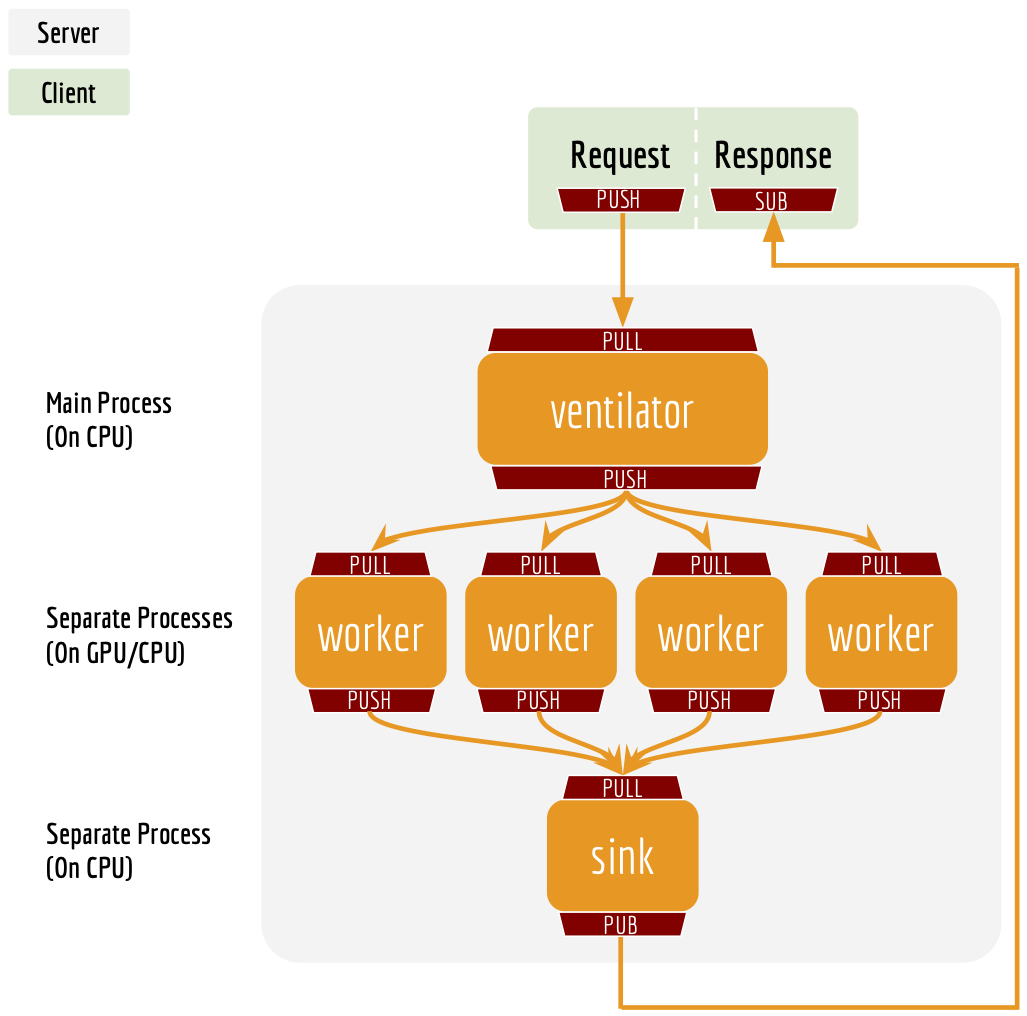
One port is for pushing text data into the server, the other port is for publishing the encoded result to the client(s). In this way, we get rid of back-chatter, meaning that at every level recipients never talk back to senders. The overall message flow is strictly one-way, as depicted in the above figure. Killing back-chatter is essential to real scalability, allowing us to use BertClient in an asynchronous way.
A: No. Think of BertClient as a general feature extractor, whose output can be fed to any ML models, e.g. scikit-learn, pytorch, tensorflow. The only file that client need is client.py. Copy this file to your project and import it, then you are ready to go.
A: Yes.
A: Yes. In fact, this is suggested. Make sure you have the following three items in model_dir:
- A TensorFlow checkpoint (
bert_model.ckpt) containing the pre-trained weights (which is actually 3 files). - A vocab file (
vocab.txt) to map WordPiece to word id. - A config file (
bert_config.json) which specifies the hyperparameters of the model.
A: Server side no, client side yes. This is based on the consideration that python 2.x might still be a major piece in some tech stack. Migrating the whole downstream stack to python 3 for supporting bert-as-service can take quite some effort. On the other hand, setting up BertServer is just a one-time thing, which can be even run in a docker container. To ease the integration, we support python 2 on the client side so that you can directly use BertClient as a part of your python 2 project, whereas the server side should always be hosted with python 3.
No, if you are using the pretrained Chinese BERT released by Google you don't need word segmentation. As this Chinese BERT is character-based model. It won't recognize word/phrase even if you intentionally add space in-between. To see that more clearly, this is what the BERT model actually receives after tokenization:
bc.encode(['hey you', 'whats up?', '你好么?', '我 还 可以'])tokens: [CLS] hey you [SEP]
input_ids: 101 13153 8357 102 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
input_mask: 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
tokens: [CLS] what ##s up ? [SEP]
input_ids: 101 9100 8118 8644 136 102 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
input_mask: 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
tokens: [CLS] 你 好 么 ? [SEP]
input_ids: 101 872 1962 720 8043 102 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
input_mask: 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
tokens: [CLS] 我 还 可 以 [SEP]
input_ids: 101 2769 6820 1377 809 102 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
input_mask: 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
That means the word embedding is actually the character embedding for Chinese-BERT.
Because your word is out-of-vocabulary (OOV). The tokenizer from Google uses a greedy longest-match-first algorithm to perform tokenization using the given vocabulary.
For example:
input = "unaffable"
tokenizer_output = ["un", "##aff", "##able"]Yes. If you already tokenize the sentence on your own, simply send use encode with List[List[Str]] as input and turn on is_tokenized, i.e. bc.encode(texts, is_tokenized=True).
Q: I encounter zmq.error.ZMQError: Operation cannot be accomplished in current state when using BertClient, what should I do?
A: This is often due to the misuse of BertClient in multi-thread/process environment. Note that you can’t reuse one BertClient among multiple threads/processes, you have to make a separate instance for each thread/process. For example, the following won't work at all:
# BAD example
bc = BertClient()
# in Proc1/Thread1 scope:
bc.encode(lst_str)
# in Proc2/Thread2 scope:
bc.encode(lst_str)Instead, please do:
# in Proc1/Thread1 scope:
bc1 = BertClient()
bc1.encode(lst_str)
# in Proc2/Thread2 scope:
bc2 = BertClient()
bc2.encode(lst_str)Q: After running the server, I have several garbage tmpXXXX folders. How can I change this behavior ?
A: These folders are used by ZeroMQ to store sockets. You can choose a different location by setting the environment variable ZEROMQ_SOCK_TMP_DIR :
export ZEROMQ_SOCK_TMP_DIR=/tmp/
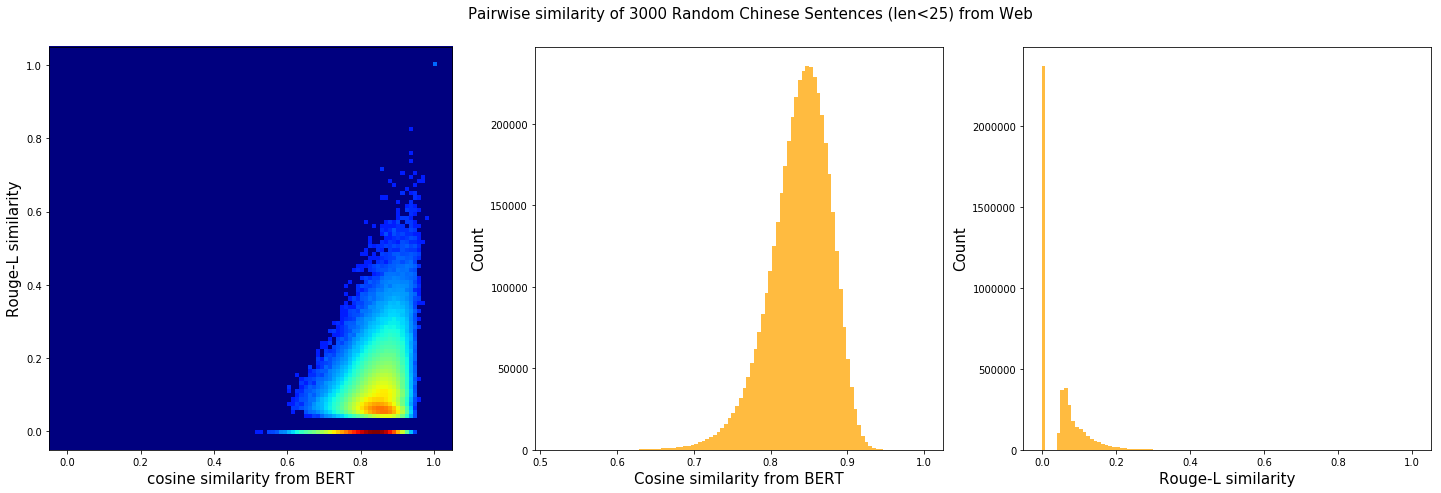
Q: The cosine similarity of two sentence vectors is unreasonably high (e.g. always > 0.8), what's wrong?
A: A decent representation for a downstream task doesn't mean that it will be meaningful in terms of cosine distance. Since cosine distance is a linear space where all dimensions are weighted equally. if you want to use cosine distance anyway, then please focus on the rank not the absolute value. Namely, do not use:
if cosine(A, B) > 0.9, then A and B are similar
Please consider the following instead:
if cosine(A, B) > cosine(A, C), then A is more similar to B than C.
The graph below illustrates the pairwise similarity of 3000 Chinese sentences randomly sampled from web (char. length < 25). We compute cosine similarity based on the sentence vectors and Rouge-L based on the raw text. The diagonal (self-correlation) is removed for the sake of clarity. As one can see, there is some positive correlation between these two metrics.
A: This often suggests that the pretrained BERT could not generate a decent representation of your downstream task. Thus, you can fine-tune the model on the downstream task and then use bert-as-service to serve the fine-tuned BERT. Note that, bert-as-service is just a feature extraction service based on BERT. Nothing stops you from using a fine-tuned BERT.
A: Yes, please run bert-serving-start -cpu -max_batch_size 16. Note that, CPUs do not scale as well as GPUs to large batches, therefore the max_batch_size on the server side needs to be smaller, e.g. 16 or 32.
A: Generally, the number of workers should be less than or equal to the number of GPUs or CPUs that you have. Otherwise, multiple workers will be allocated to one GPU/CPU, which may not scale well (and may cause out-of-memory on GPU).
A: Yes, you can specifying -device_map as follows:
bert-serving-start -device_map 0 1 4 -num_worker 4 -model_dir ...This will start four workers and allocate them to GPU0, GPU1, GPU4 and again GPU0, respectively. In general, if num_worker > device_map, then devices will be reused and shared by the workers (may scale suboptimally or cause OOM); if num_worker < device_map, only device_map[:num_worker] will be used.
Note, device_map is ignored when running on CPU.
The primary goal of benchmarking is to test the scalability and the speed of this service, which is crucial for using it in a dev/prod environment. Benchmark was done on Tesla M40 24GB, experiments were repeated 10 times and the average value is reported.
To reproduce the results, please run
bert-serving-benchmark --helpCommon arguments across all experiments are:
| Parameter | Value |
|---|---|
| num_worker | 1,2,4 |
| max_seq_len | 40 |
| client_batch_size | 2048 |
| max_batch_size | 256 |
| num_client | 1 |
max_seq_len is a parameter on the server side, which controls the maximum length of a sequence that a BERT model can handle. Sequences larger than max_seq_len will be truncated on the left side. Thus, if your client want to send long sequences to the model, please make sure the server can handle them correctly.
Performance-wise, longer sequences means slower speed and more chance of OOM, as the multi-head self-attention (the core unit of BERT) needs to do dot products and matrix multiplications between every two symbols in the sequence.
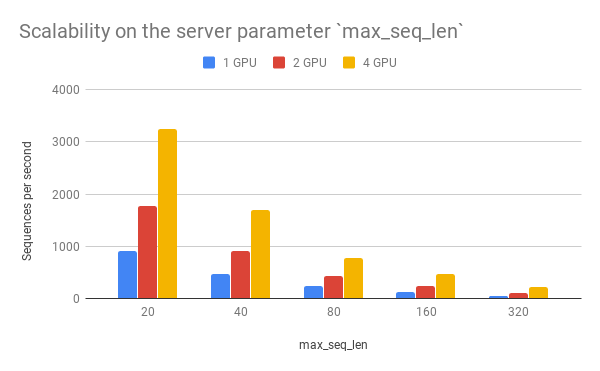
max_seq_len |
1 GPU | 2 GPU | 4 GPU |
|---|---|---|---|
| 20 | 903 | 1774 | 3254 |
| 40 | 473 | 919 | 1687 |
| 80 | 231 | 435 | 768 |
| 160 | 119 | 237 | 464 |
| 320 | 54 | 108 | 212 |
client_batch_size is the number of sequences from a client when invoking encode(). For performance reason, please consider encoding sequences in batch rather than encoding them one by one.
For example, do:
# prepare your sent in advance
bc = BertClient()
my_sentences = [s for s in my_corpus.iter()]
# doing encoding in one-shot
vec = bc.encode(my_sentences)DON'T:
bc = BertClient()
vec = []
for s in my_corpus.iter():
vec.append(bc.encode(s))It's even worse if you put BertClient() inside the loop. Don't do that.
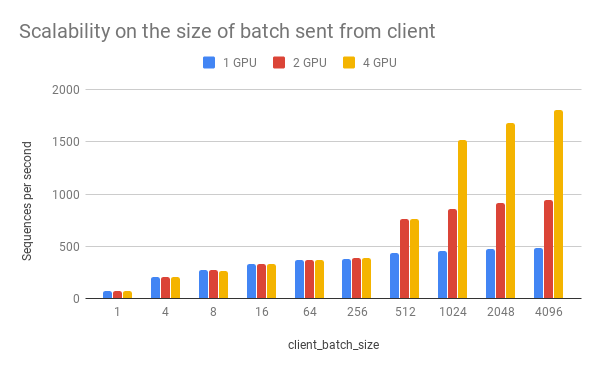
client_batch_size |
1 GPU | 2 GPU | 4 GPU |
|---|---|---|---|
| 1 | 75 | 74 | 72 |
| 4 | 206 | 205 | 201 |
| 8 | 274 | 270 | 267 |
| 16 | 332 | 329 | 330 |
| 64 | 365 | 365 | 365 |
| 256 | 382 | 383 | 383 |
| 512 | 432 | 766 | 762 |
| 1024 | 459 | 862 | 1517 |
| 2048 | 473 | 917 | 1681 |
| 4096 | 481 | 943 | 1809 |
num_client represents the number of concurrent clients connected to the server at the same time.
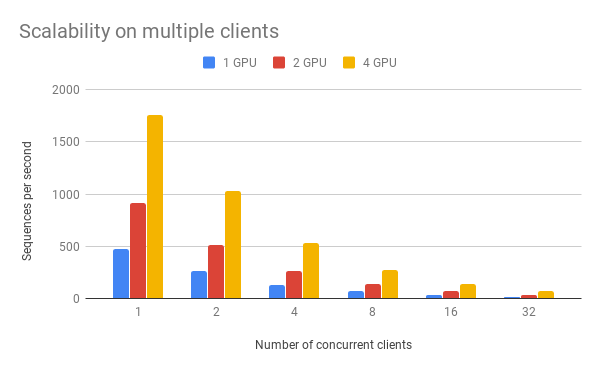
num_client |
1 GPU | 2 GPU | 4 GPU |
|---|---|---|---|
| 1 | 473 | 919 | 1759 |
| 2 | 261 | 512 | 1028 |
| 4 | 133 | 267 | 533 |
| 8 | 67 | 136 | 270 |
| 16 | 34 | 68 | 136 |
| 32 | 17 | 34 | 68 |
As one can observe, 1 clients 1 GPU = 381 seqs/s, 2 clients 2 GPU 402 seqs/s, 4 clients 4 GPU 413 seqs/s. This shows the efficiency of our parallel pipeline and job scheduling, as the service can leverage the GPU time more exhaustively as concurrent requests increase.
max_batch_size is a parameter on the server side, which controls the maximum number of samples per batch per worker. If a incoming batch from client is larger than max_batch_size, the server will split it into small batches so that each of them is less or equal than max_batch_size before sending it to workers.

max_batch_size |
1 GPU | 2 GPU | 4 GPU |
|---|---|---|---|
| 32 | 450 | 887 | 1726 |
| 64 | 459 | 897 | 1759 |
| 128 | 473 | 931 | 1816 |
| 256 | 473 | 919 | 1688 |
| 512 | 464 | 866 | 1483 |
pooling_layer determines the encoding layer that pooling operates on. For example, in a 12-layer BERT model, -1 represents the layer closed to the output, -12 represents the layer closed to the embedding layer. As one can observe below, the depth of the pooling layer affects the speed.
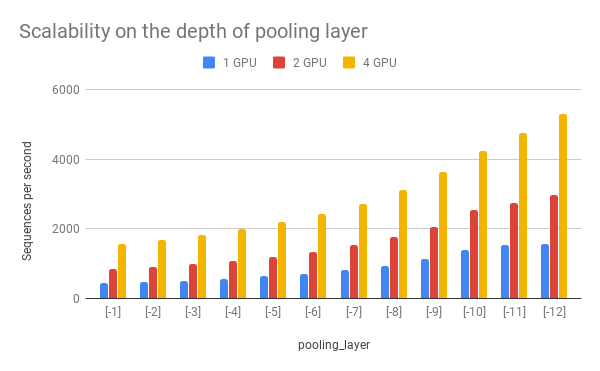
pooling_layer |
1 GPU | 2 GPU | 4 GPU |
|---|---|---|---|
| [-1] | 438 | 844 | 1568 |
| [-2] | 475 | 916 | 1686 |
| [-3] | 516 | 995 | 1823 |
| [-4] | 569 | 1076 | 1986 |
| [-5] | 633 | 1193 | 2184 |
| [-6] | 711 | 1340 | 2430 |
| [-7] | 820 | 1528 | 2729 |
| [-8] | 945 | 1772 | 3104 |
| [-9] | 1128 | 2047 | 3622 |
| [-10] | 1392 | 2542 | 4241 |
| [-11] | 1523 | 2737 | 4752 |
| [-12] | 1568 | 2985 | 5303 |
bert-as-service supports two additional optimizations: half-precision and XLA, which can be turned on by adding -fp16 and -xla to bert-serving-start, respectively. To enable these two options, you have to meet the following requirements:
- your GPU supports FP16 instructions;
- your Tensorflow is self-compiled with XLA and
-march=native; - your CUDA and cudnn are not too old.
On Tesla V100 with tensorflow=1.13.0-rc0 it gives:

FP16 achieves ~1.4x speedup (round-trip) comparing to the FP32 counterpart. To reproduce the result, please run python example/example1.py.
If you use bert-as-service in a scientific publication, we would appreciate references to the following BibTex entry:
@misc{xiao2018bertservice,
title={bert-as-service},
author={Xiao, Han},
howpublished={\url{https://github.com/hanxiao/bert-as-service}},
year={2018}
}