This report summarizes the results of a series of tests published in Oct 2020.
All tests were performed on 4 Nodes with 8x Tesla V100-SXM2-16GB GPUs, the following is the main hardware and software configuration for each:
- Tesla V100-SXM2-16GB x 8
- InfiniBand 100 Gb/sec (4X EDR), Mellanox Technologies MT27700 Family
- Intel(R) Xeon(R) Gold 5118 CPU @ 2.30GHz
- Memory 384G
- Ubuntu 16.04.4 LTS (GNU/Linux 4.4.0-116-generic x86_64)
- CUDA Version: 10.2, Driver Version: 440.33.01
nvidia-smi topo -m
GPU0 GPU1 GPU2 GPU3 GPU4 GPU5 GPU6 GPU7 mlx5_0 CPU Affinity
GPU0 X NV1 NV1 NV2 NV2 SYS SYS SYS NODE 0-11,24-35
GPU1 NV1 X NV2 NV1 SYS NV2 SYS SYS NODE 0-11,24-35
GPU2 NV1 NV2 X NV2 SYS SYS NV1 SYS PIX 0-11,24-35
GPU3 NV2 NV1 NV2 X SYS SYS SYS NV1 PIX 0-11,24-35
GPU4 NV2 SYS SYS SYS X NV1 NV1 NV2 SYS 12-23,36-47
GPU5 SYS NV2 SYS SYS NV1 X NV2 NV1 SYS 12-23,36-47
GPU6 SYS SYS NV1 SYS NV1 NV2 X NV2 SYS 12-23,36-47
GPU7 SYS SYS SYS NV1 NV2 NV1 NV2 X SYS 12-23,36-47
mlx5_0 NODE NODE PIX PIX SYS SYS SYS SYS X
Legend:
X = Self
SYS = Connection traversing PCIe as well as the SMP interconnect between NUMA nodes (e.g., QPI/UPI)
NODE = Connection traversing PCIe as well as the interconnect between PCIe Host Bridges within a NUMA node
PHB = Connection traversing PCIe as well as a PCIe Host Bridge (typically the CPU)
PXB = Connection traversing multiple PCIe bridges (without traversing the PCIe Host Bridge)
PIX = Connection traversing at most a single PCIe bridge
NV# = Connection traversing a bonded set of # NVLinks
| Framework | Version | Docker From | DNN Model Sources | Features |
|---|---|---|---|---|
| OneFlow | 0.2.0 | - | OneFlow-Benchmark | - |
| NGC MXNet | 1.6.0 | nvcr.io/nvidia/mxnet:20.03-py3 | DeepLearningExamples/MxNet | DALI+Horovod |
| NGC TensorFlow 1.x | 1.15.2 | nvcr.io/nvidia/tensorflow:20.03-tf1-py3 | DeepLearningExamples/TensorFLow | DALI+Horovod+XLA |
| NGC PyTorch | 1.5.0a0+8f84ded | nvcr.io/nvidia/pytorch:20.03-py3 | DeepLearningExamples/PyTorch | DALI+APEX |
| MXNet | 1.6.0 | - | gluon-cv | Horovod |
| TensorFlow 2.x | 2.3.0 | - | TensorFlow-models | - |
| PyTorch | 1.6.0 | - | pytorch/examples | - |
| PaddlePaddle | 1.8.3.post107 | - | PaddleCV | DALI |
| Framework | Version | Docker From | DNN Model Sources | Features |
|---|---|---|---|---|
| OneFlow | 0.2.0 | - | OneFlow-Benchmark | - |
| NGC TensorFlow 1.x | 1.15.2 | nvcr.io/nvidia/tensorflow:20.03-tf1-py3 | DeepLearningExamples/TensorFlow | Horovod |
| NGC PyTorch | 1.5.0a0+8f84ded | nvcr.io/nvidia/pytorch:20.03-py3 | DeepLearningExamples/PyTorch | APEX |
| MXNet | 1.6.0 | - | gluon-nlp | Horovod |
| PaddlePaddle | 1.8.3.post107 | - | PaddleNLP | - |
P.S. In features:
- APEX is a PyTorch extension with NVIDIA-maintained utilities to streamline mixed precision and distributed training.
- NVIDIA DALI - NVIDIA Data Loading Library (DALI) is a collection of highly optimized building blocks, and an execution engine, to accelerate the pre-processing of the input data for deep learning applications.
- Horovod is a distributed training framework for TensorFlow, Keras, PyTorch, and MXNet.
- XLA (Accelerated Linear Algebra) is a domain-specific compiler for linear algebra that can accelerate TensorFlow models with potentially no source code changes.
- Devices Config: 1 node 1 device, 1 node 8 devices, 2 nodes 16 devices, 4 nodes 32 devices
- DataType: Float32, AMP (Automatic Mixed Precision)
- XLA for TensorFlow with AMP
| node num | device num | OneFlow | NGC MXNet |
NGC TensorFlow 1.x |
NGC PyTorch |
MXNet | TensorFlow 2.x | PyTorch | PaddlePaddle |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 397.64 | 392.24 | 362.44 | 367.29 | 384.19 | 321.80 | 348.62 | 352.72 |
| 1 | 8 | 3130.34 | 3006.98 | 2721.98 | 2887.65 | 2556.03 | 2458.74 | 2632.93 | 2625.38 |
| 2 | 16 | 6260.30 | 5758.49 | 5099.42 | 5716.79 | 4855.34 | 4849.68 | 5115.40 | 4895.27 |
| 4 | 32 | 12411.97 | 11331.93 | 9514.64 | 10917.09 | 9579.74 | 9418.44 | 10021.29 | 9348.17 |
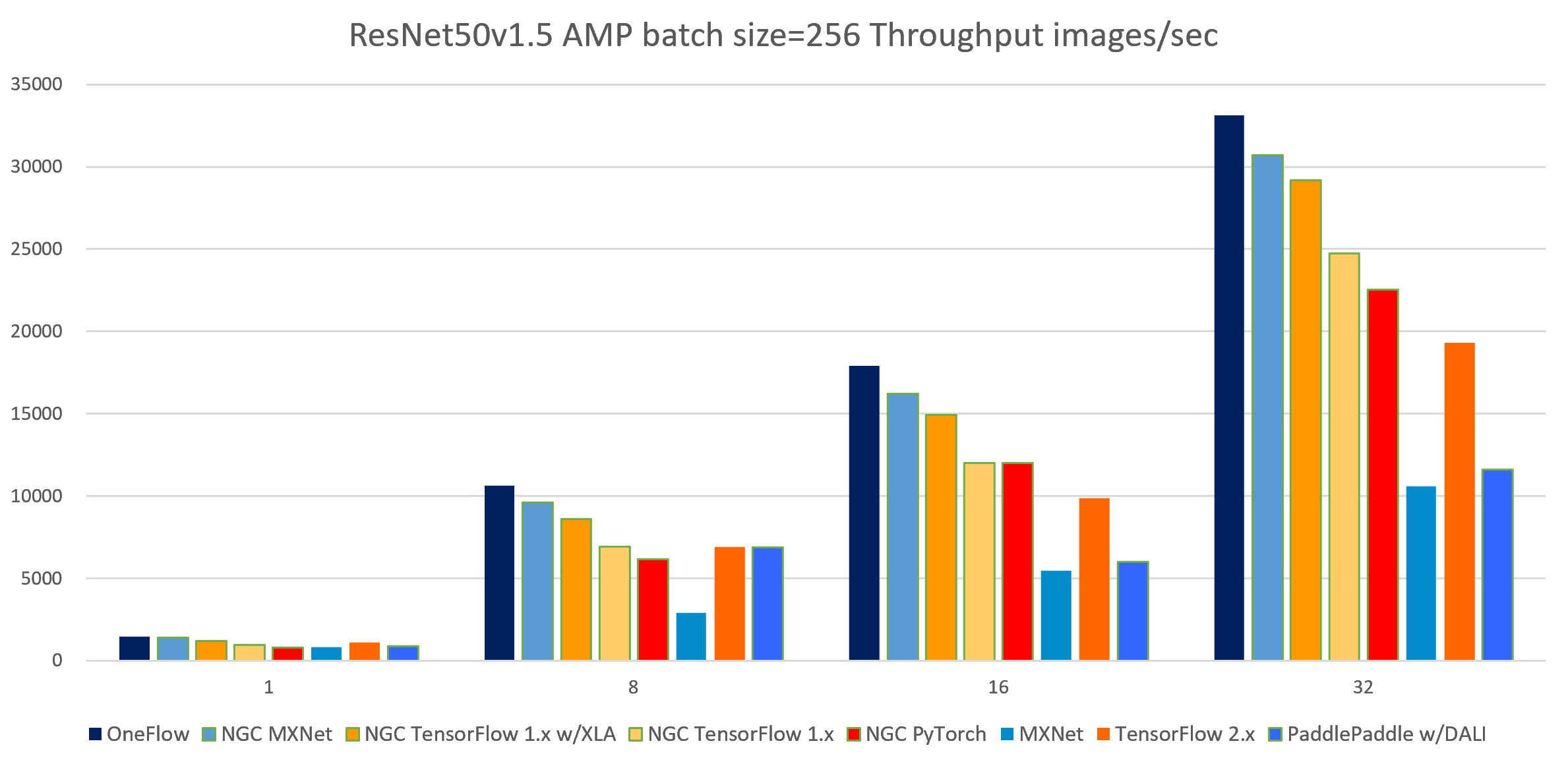
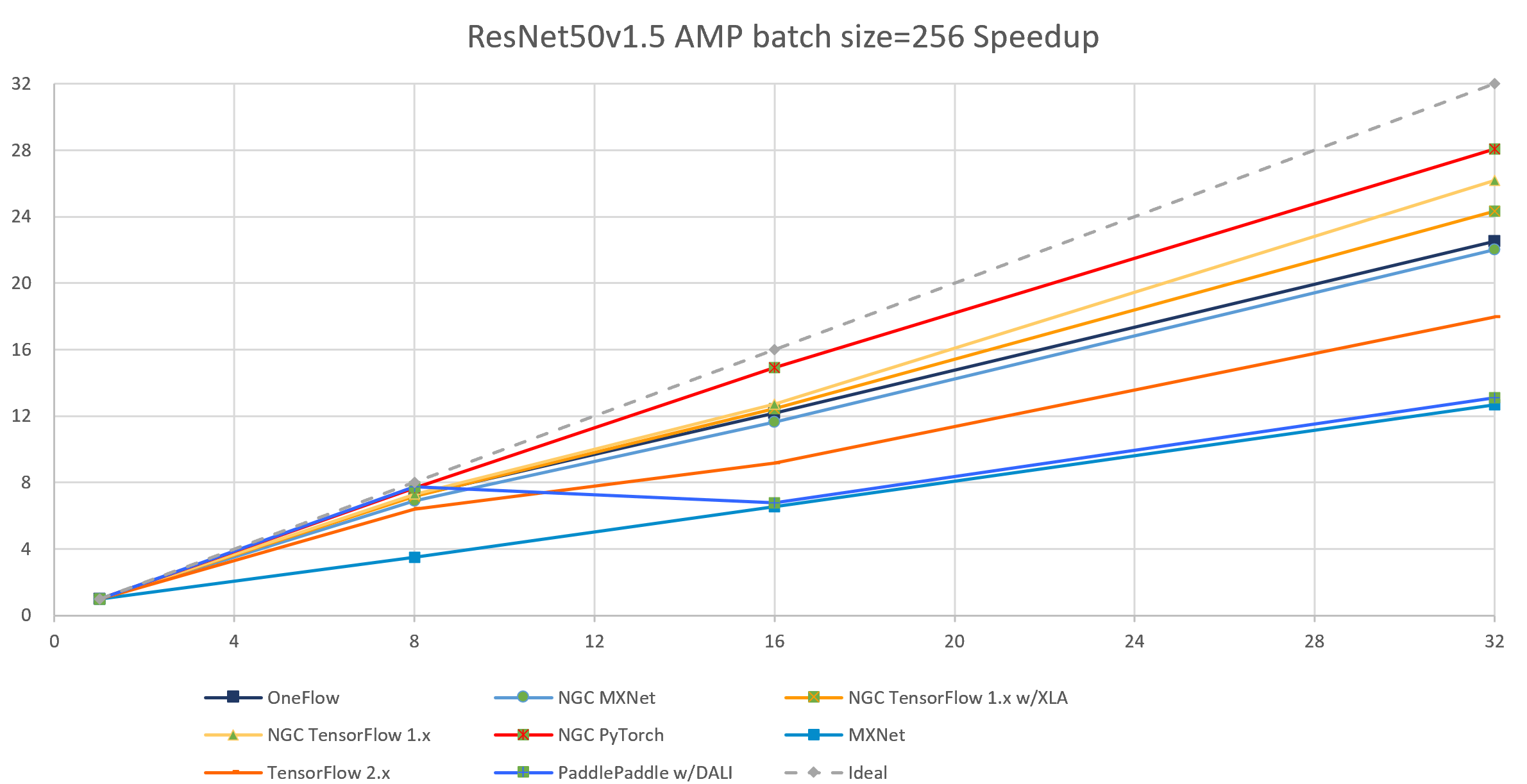
The following images show throughput and speedup of 8 implementations of ResNet50 V1.5.
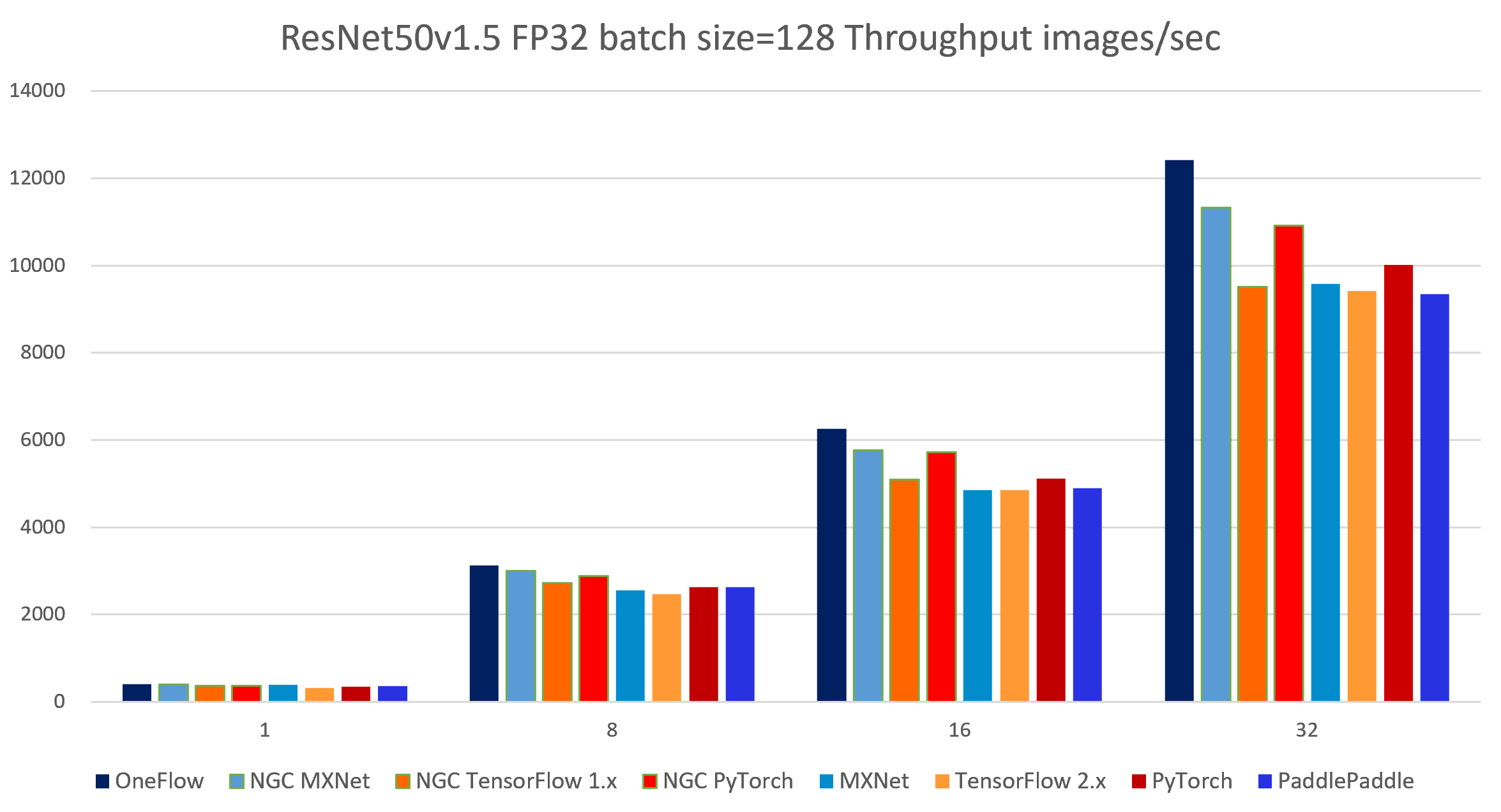
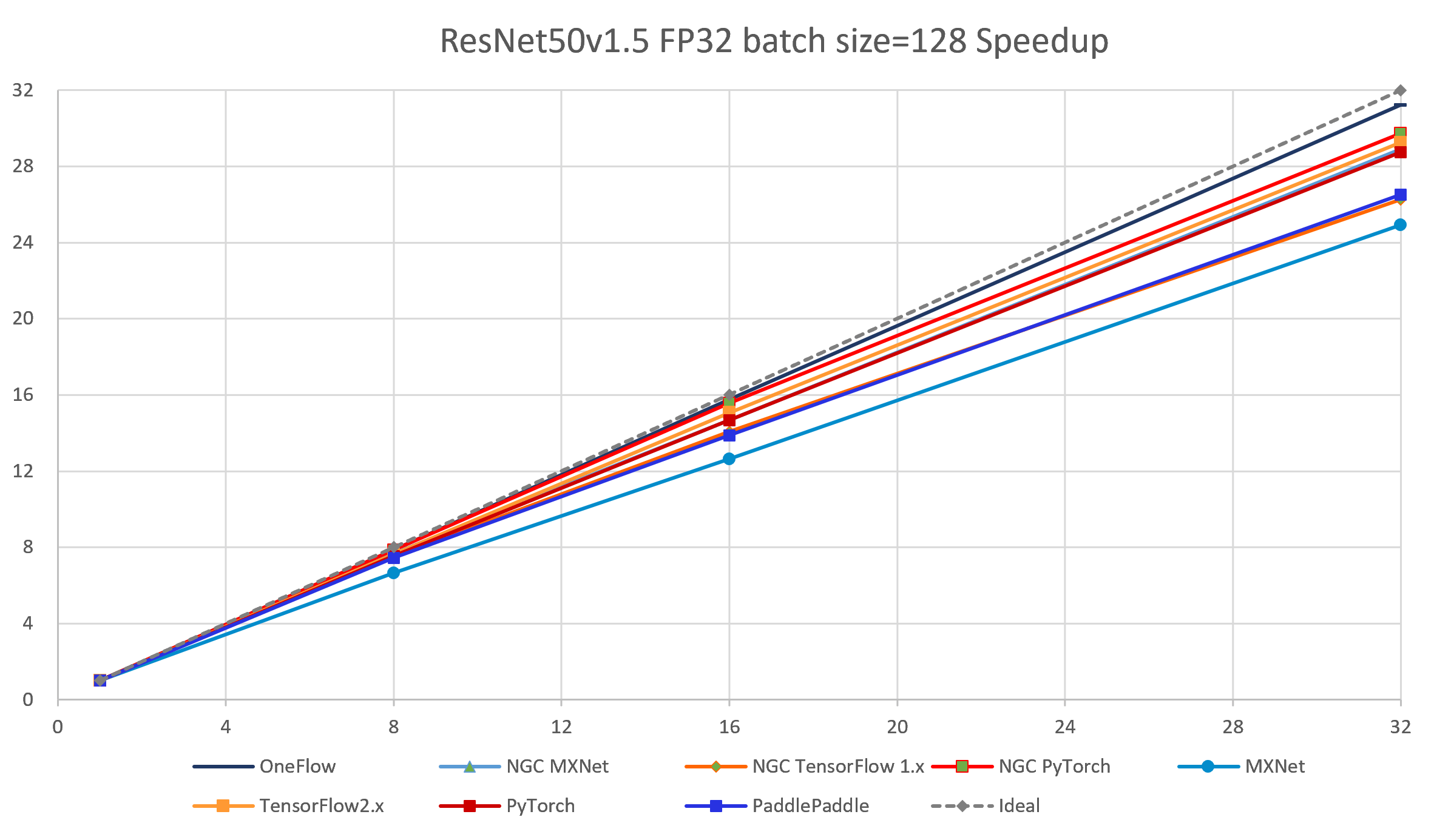
| node num | device num | OneFlow | NGC MXNet |
NGC TensorFlow 1.x w/XLA bsz=224 |
NGC TensorFlow 1.x bsz=224 |
NGC PyTorch |
MXNet | TensorFlow 2.x | PaddlePaddle w/DALI bsz=196[1] |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 1472.72 | 1393.87 | 1198.55 | 945.18 | 802.9 | 833.65 | 1075.27 | 887.17 |
| 1 | 8 | 10629.32 | 9621.31 | 8588.45 | 6903.42 | 6154.66 | 2908.88 | 6898.00 | 6862.17 |
| 2 | 16 | 17920.40 | 16219.03 | 14931.03 | 12021.09 | 11991.94 | 5451.27 | 9870.15 | 6018.46 |
| 4 | 32 | 33141.02 | 30713.68 | 29171.69 | 24734.22 | 22551.16 | 10565.55 | 19314.31 | 11617.57 |
[1]: The throughput 11617.57 img/s is obtained with bsz = 196 and with DALI-paddle plug-in because using DALI will occupy more GPU device memory, so bsz = 224 or 256 both encounters OOM. The official data 28594 img/s provided by PaddlePaddle is tested on V100 32G and the PaddlePaddle docker image with DALI not released, so we cannot replicate this result. If anyone can help us improve PaddlePaddle test results, please contact us by issue.
| node num | device num | OneFlow | NGC TensorFlow 1.x |
NGC PyTorch |
PaddlePaddle | [2]OneFlow W/O clip |
[2]MXNet W/O clip |
|---|---|---|---|---|---|---|---|
| 1 | 1 | 152.89 | 107.33 | 119.60 | 132.64 | 153.94 | 150.11 |
| 1 | 8 | 1105.55 | 790.03 | 921.32 | 615.12 | 1194.48 | 1058.60 |
| 2 | 16 | 2015.78 | 1404.04 | 1499.40 | 1116.02 | 2181.51 | 1845.65 |
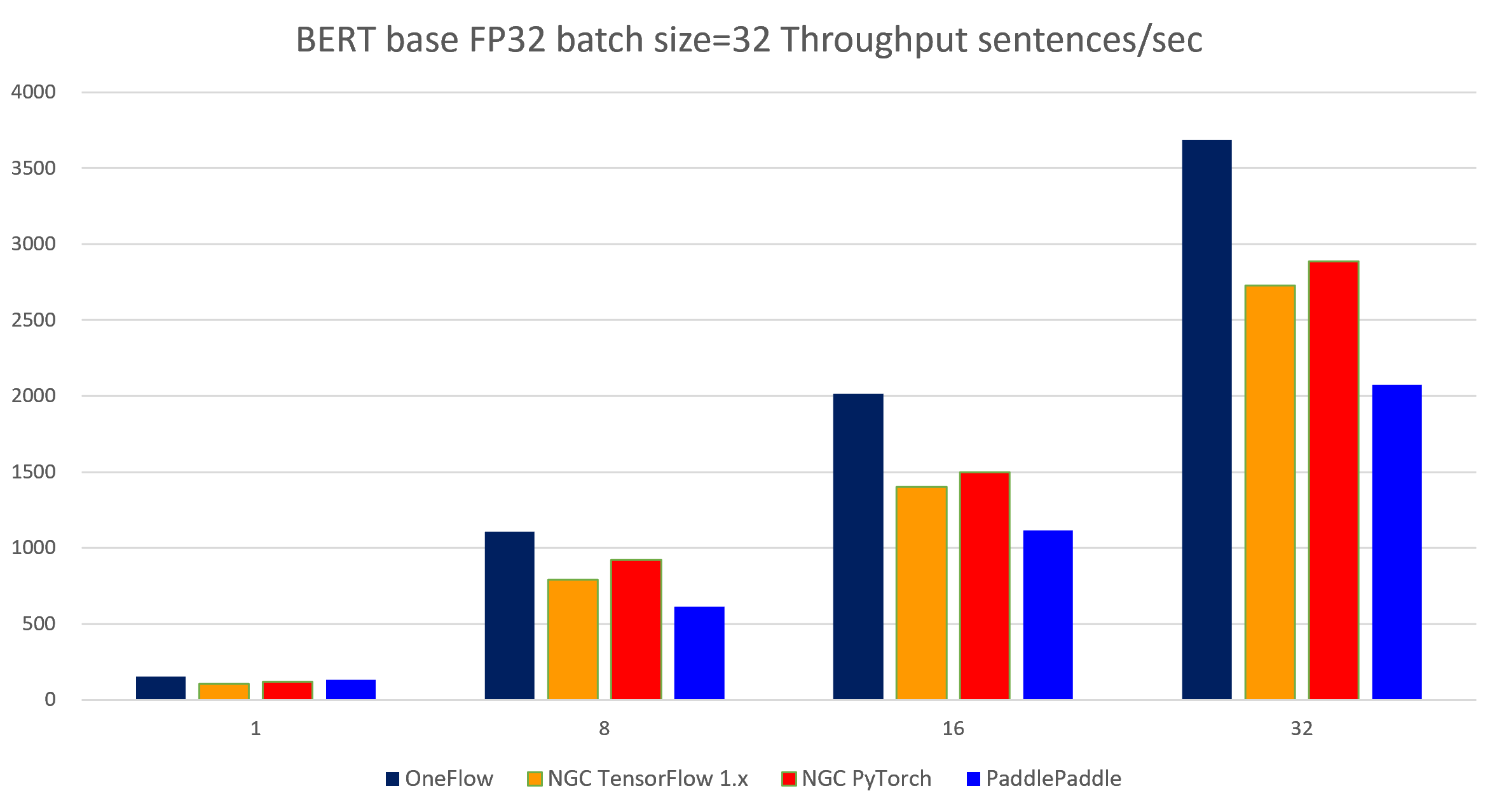
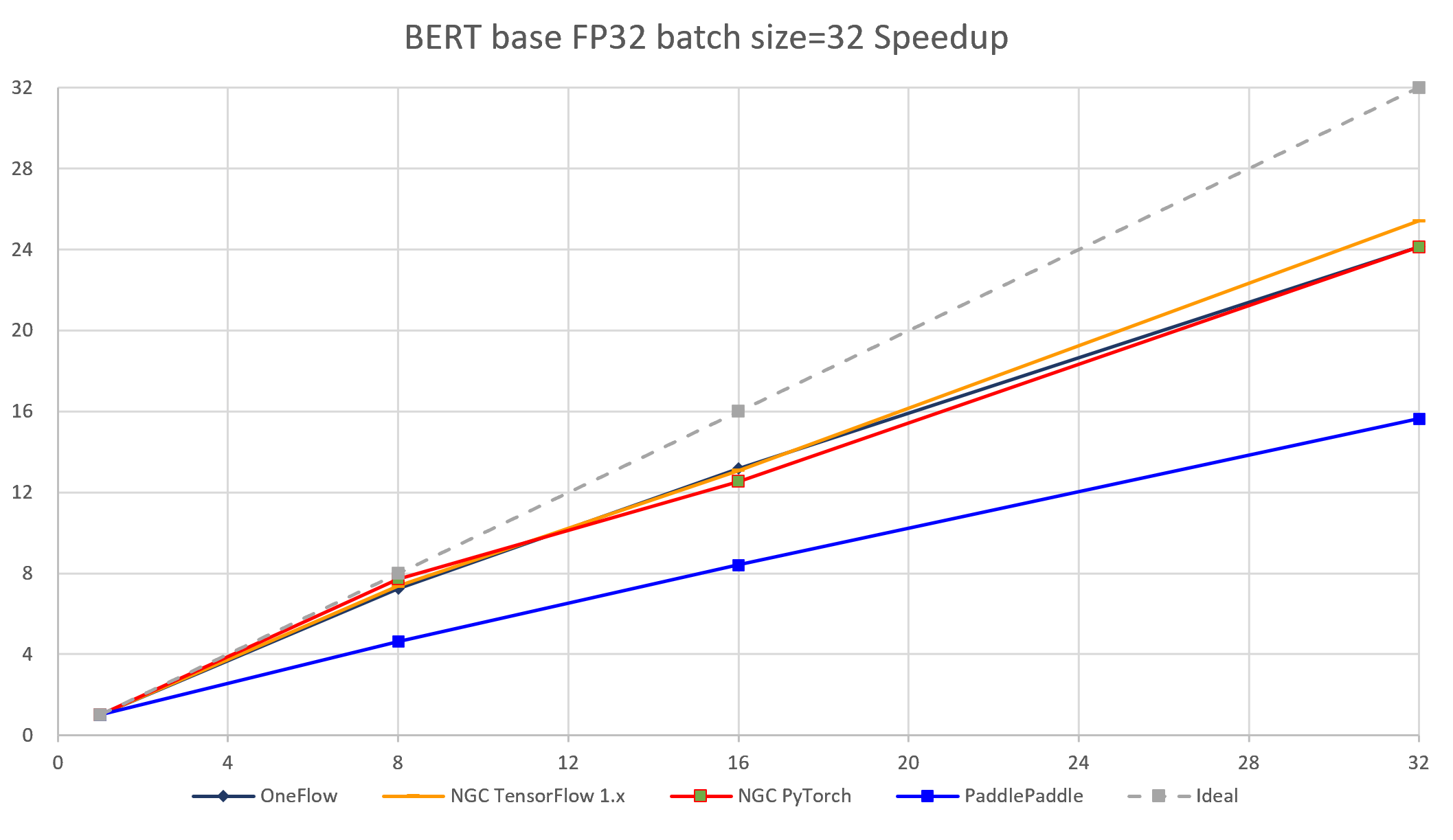
| 4 | 32 | 3689.80 | 2727.90 | 2885.81 | 2073.60 | 4019.45 | 3671.45 |
[2]: The MXNet BERT script of the gluon-nlp repository does NOT support clip_by_ global_norm operation in Adam optimizer. W/O clip_by_global_norm operation, the throughput will be larger and the the fine-tuning accuracy may be lower. So we also tested OneFlow data W/O clip operation for comparison.
The following images show throughput and speedup of 4 implementations (without MXNet) of BERT base with data type float32 and batch size per device = 32.
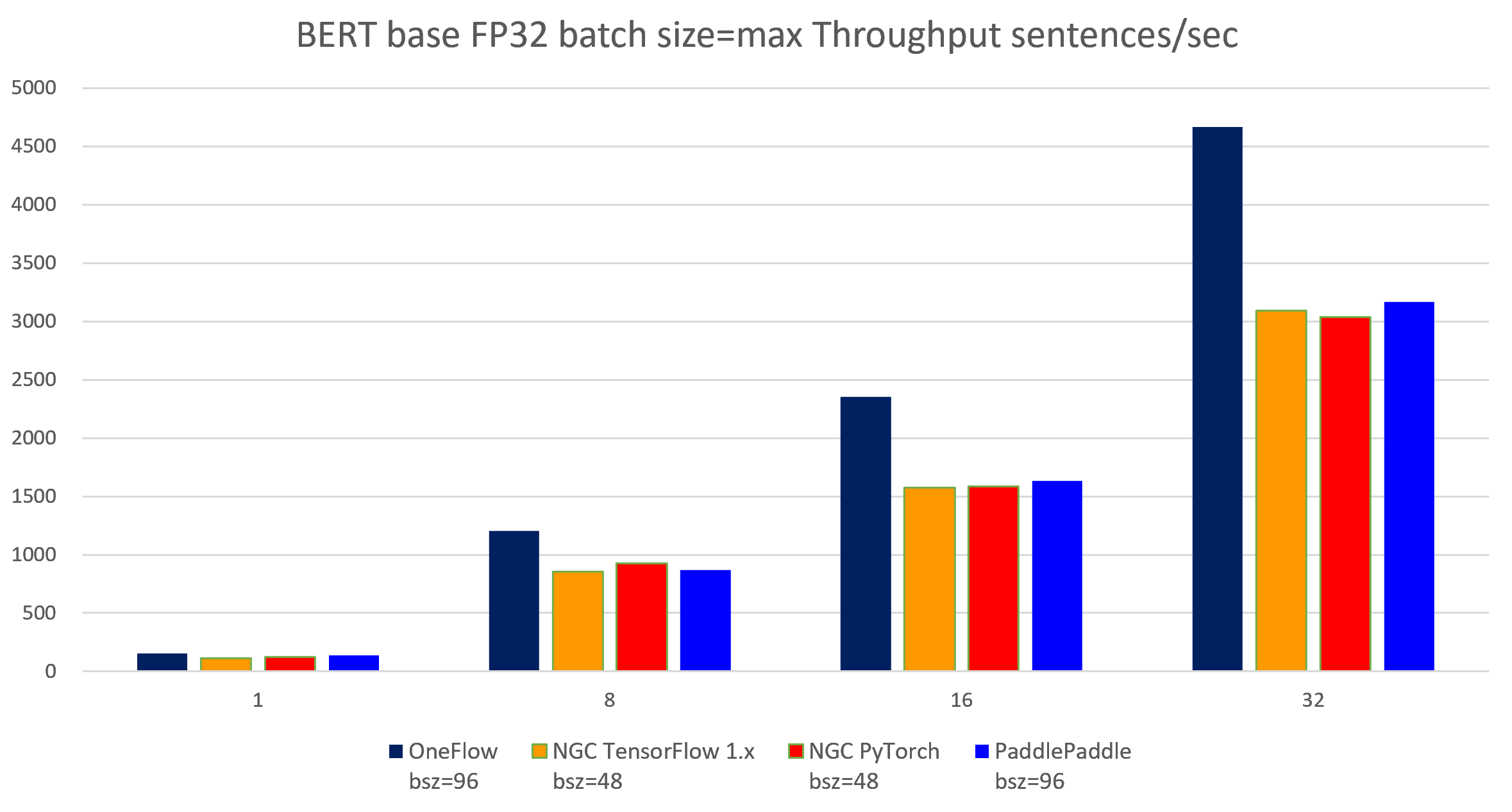
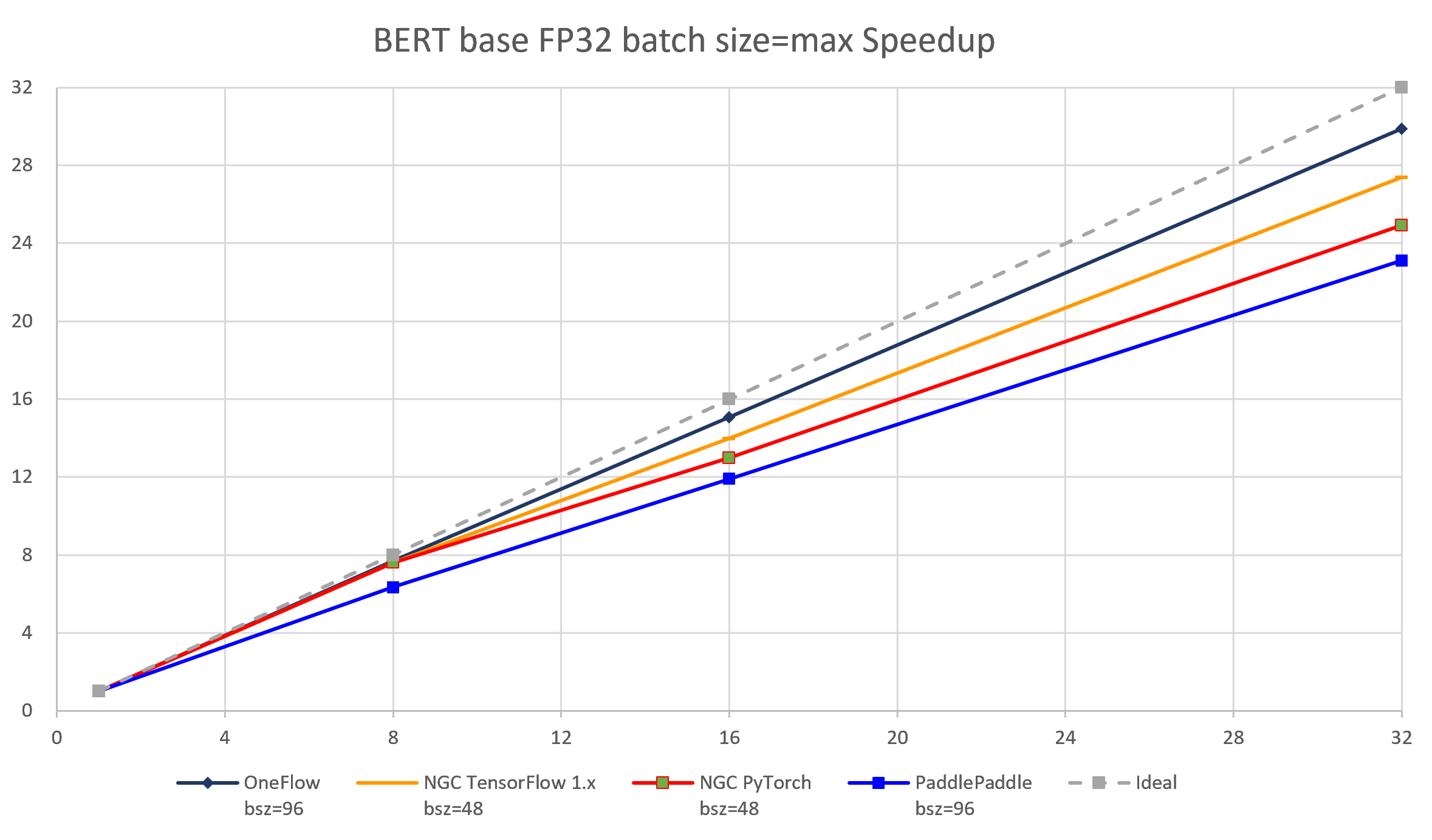
| node num | device num | OneFlow bsz=96 |
NGC TensorFlow 1.x bsz=48 |
NGC PyTorch bsz=48 |
PaddlePaddle bsz=96 |
OneFlow W/O clip bsz=96 |
MXNet W/O clip bsz=64 |
|---|---|---|---|---|---|---|---|
| 1 | 1 | 156.02 | 112.76 | 121.94 | 136.97 | 156.25 | 156.76 |
| 1 | 8 | 1201.70 | 855.45 | 928.01 | 868.60 | 1234.65 | 1153.08 |
| 2 | 16 | 2352.92 | 1576.88 | 1584.32 | 1631.36 | 2425.97 | 2172.62 |
| 4 | 32 | 4664.10 | 3089.74 | 3039.30 | 3167.68 | 4799.64 | 4340.89 |
The following images show throughput and speedup of 4 implementations of BERT base with data type float32 and batch size per device = max.
| node num | device num | OneFlow | NGC TensorFlow 1.x |
NGC TensorFlow 1.x w/XLA |
NGC PyTorch |
PaddlePaddle | OneFlow W/O clip |
MXNet W/O clip |
|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 534.72 | 183.25 | 422.53 | 444.51 | 289.23 | 552.48 | 473.76 |
| 1 | 8 | 3399.43 | 1452.59 | 3112.73 | 3251.7 | 1298.96 | 3897.19 | 3107.1 |
| 2 | 16 | 5745.56 | 2653.74 | 5050.86 | 4936.92 | 1999.38 | 6669.93 | 5723.26 |
| 4 | 32 | 9911.78 | 5189.07 | 9409.20 | 9331.72 | 3406.36 | 11195.72 | 11269.14 |
The following images show throughput and speedup of 4 implementations (with TensorFlow 1.x XLA and without MXNet) of BERT base with auto mixed precision and batch size per device = 64.
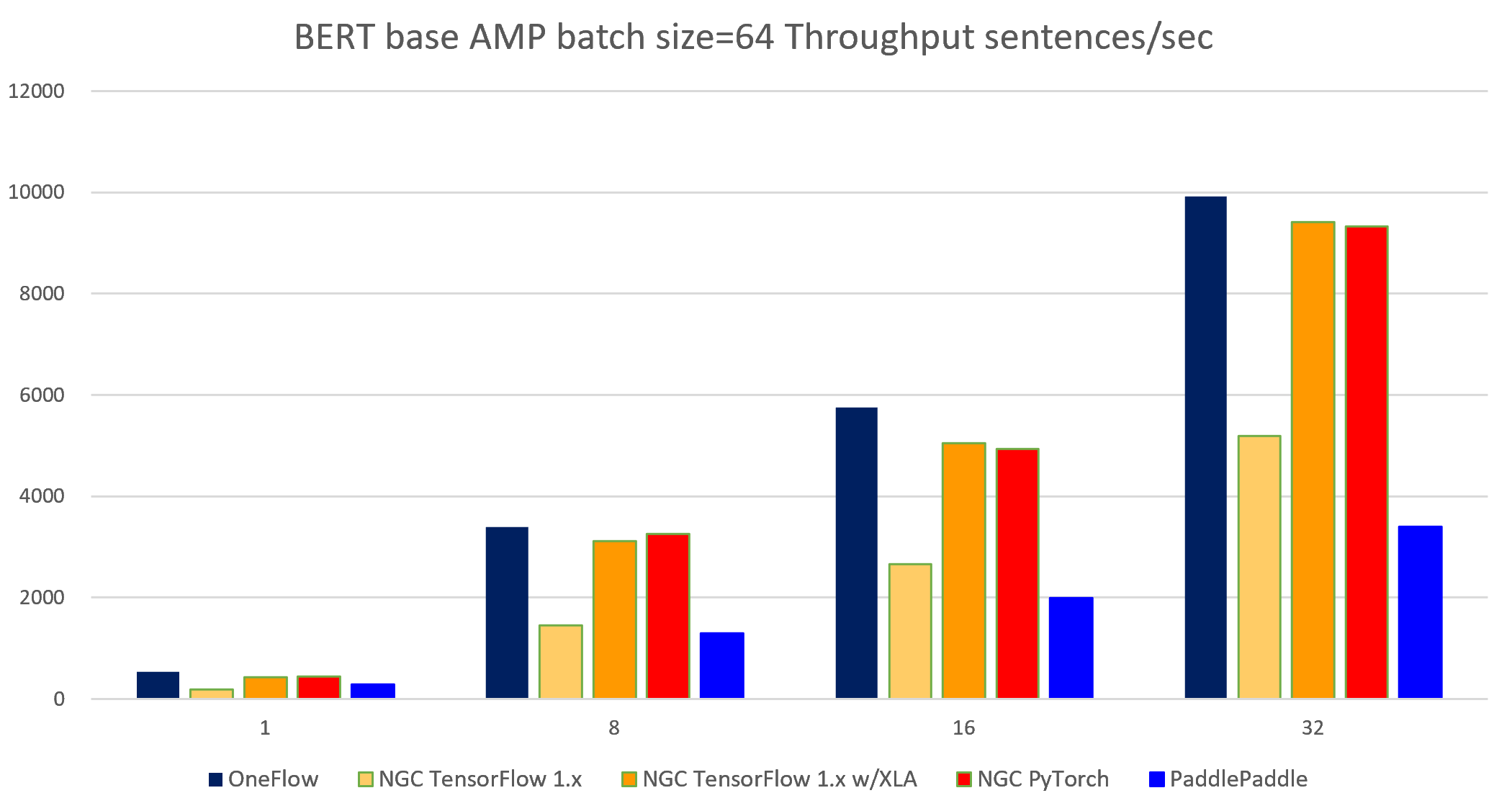
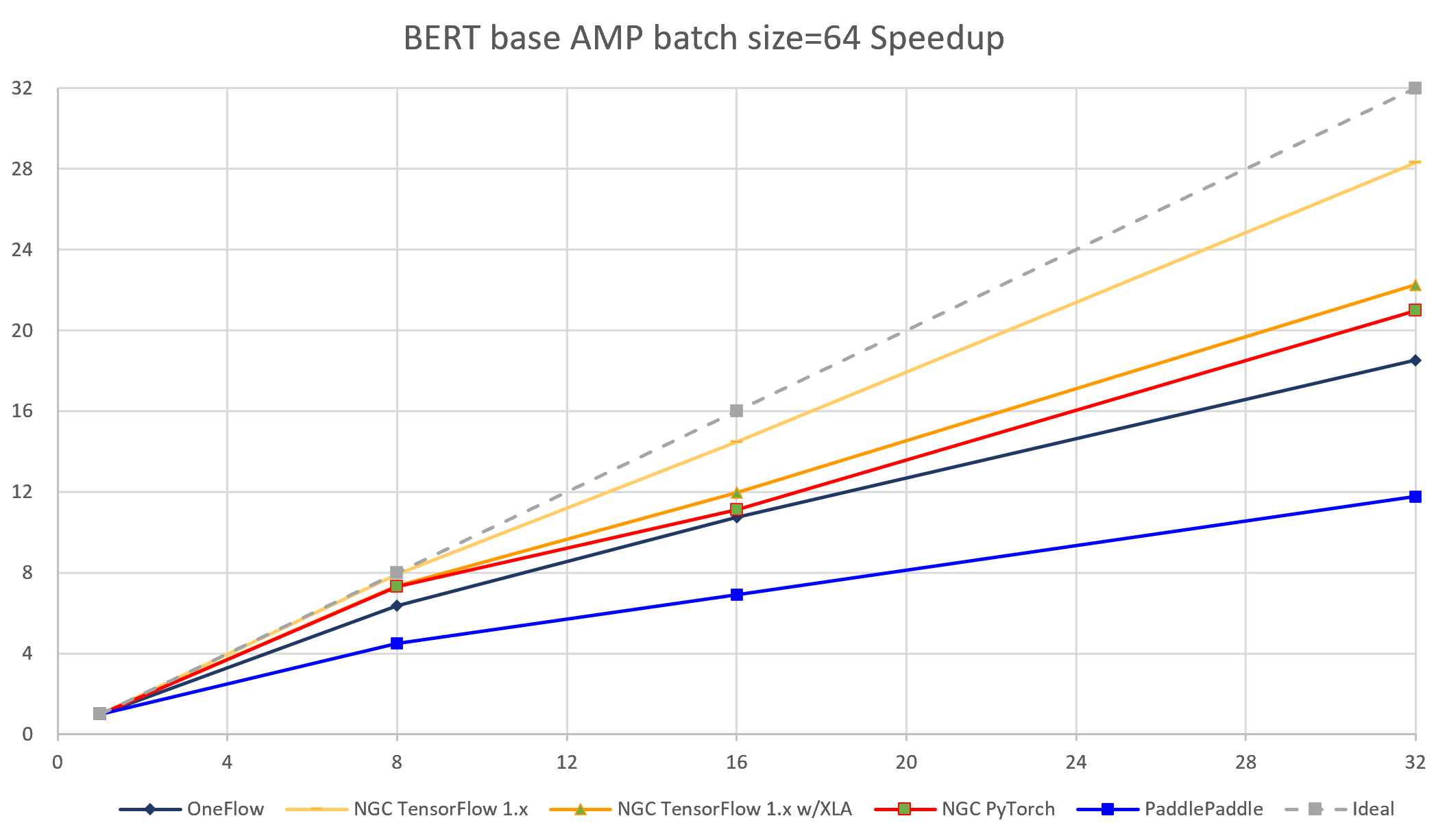
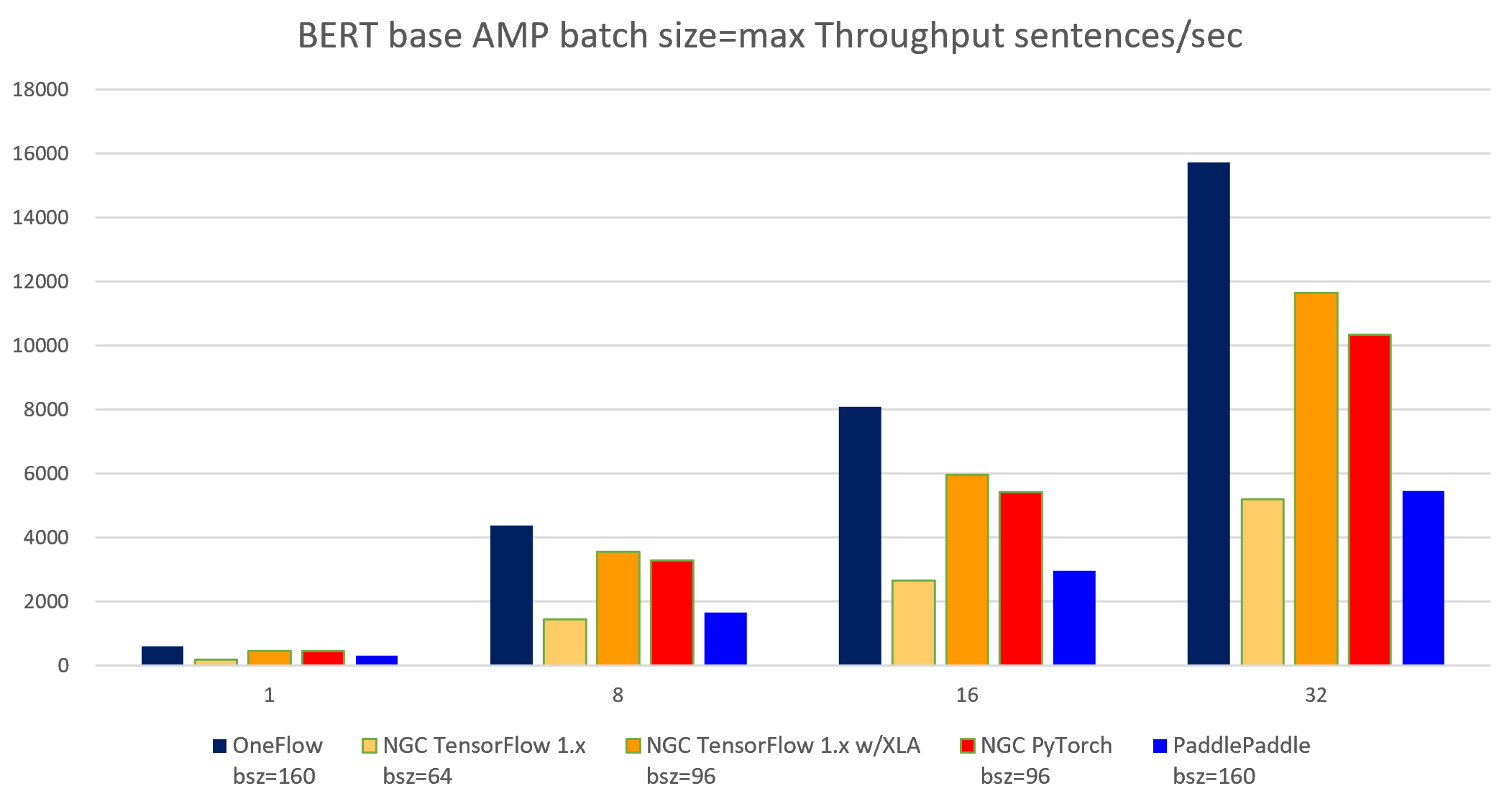
| node num | device num | OneFlow bsz=160 |
NGC TensorFlow 1.x bsz=64 |
NGC TensorFlow 1.x w/XLA bsz=96 |
NGC PyTorch bsz=96 |
PaddlePaddle bsz=160 |
OneFlow W/O clip bsz=160 |
MXNet W/O clip bsz=128 |
|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 605.11 | 183.25 | 468.10 | 462.35 | 309.68 | 613.93 | 544.31 |
| 1 | 8 | 4381.66 | 1452.59 | 3559.8 | 3287.12 | 1666.54 | 4683.36 | 3825.21 |
| 2 | 16 | 8075.16 | 2653.74 | 5960.14 | 5426.07 | 2969.85 | 8777.57 | 7327.50 |
| 4 | 32 | 15724.70 | 5189.07 | 11650.0 | 10349.12 | 5452.35 | 17210.63 | 14822.31 |
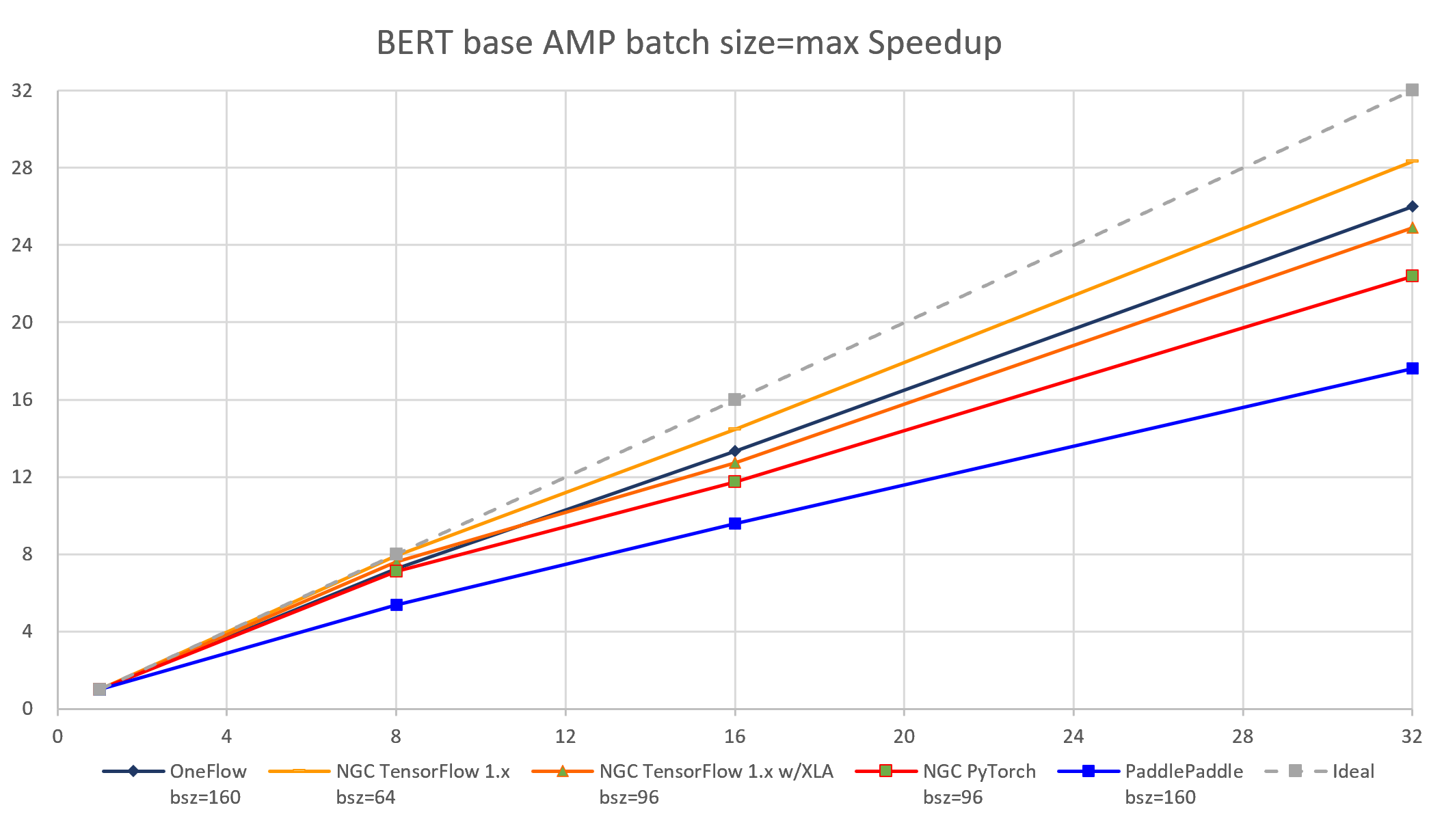
The following images show throughput and speedup of 4 implementations of BERT base with auto mixed precision and batch size per device = max.