Ce projet implémente un modèle de prédiction des prix des biens immobiliers en utilisant Python et des techniques de machine learning.
Les données d'entraînement sont extraites du jeu de données public de Data.gouv.fr qui contient des informations sur les demandes de valeurs foncières pour les années 2018, 2019, 2020 et 2021.
- Prédiction de Prix : Le modèle utilise des caractéristiques telles que la superficie, l'emplacement, le nombre de pièces, etc... pour prédire le prix des biens immobiliers.
-
Téléchargement des Données : Téléchargez les données à partir du lien Data.gouv.fr et placez le fichier CSV à la racine du projet.
-
Installation des Dépendances : Assurez-vous d'avoir installé Python sur votre système. Installez les dépendances en utilisant le fichier
requirements.txt: -
Prétraitement des données : Pour prétraiter les données, utilisez le script
preprocessing_deploiement.pyou alors le notebookpreprocessing.ipynb. -
Classifcation de code type local : Une fois les données nettoyées, vous pouvez prédire le code type local des biens (variable extremement utile pour prédire la valeur foncière d'un bien), mais les informations manquent grandement. C'est pour cela que nous utilisons un modèle de classification, c'est le notebook
classification.ipynbqui s'occupe d'entrainer et de générer le modèle de classification, il se trouvera dans le dossiermodel/. -
Régression : Une fois les code type local prédit, vous pouvez entrainer le modèle de régression en utilisant le script
regression.ipynb, cela va créer les modèles de régression pour chaque code type local, dans le dossiermodel/. -
Prédiction : Le script
make_predictions.py, vous permets prédire la valeur foncière des données en entrée, il vous retournera la valeur foncière de chaque bien.
Un dashboard est accessible à l'adresse suivante : Dashboard
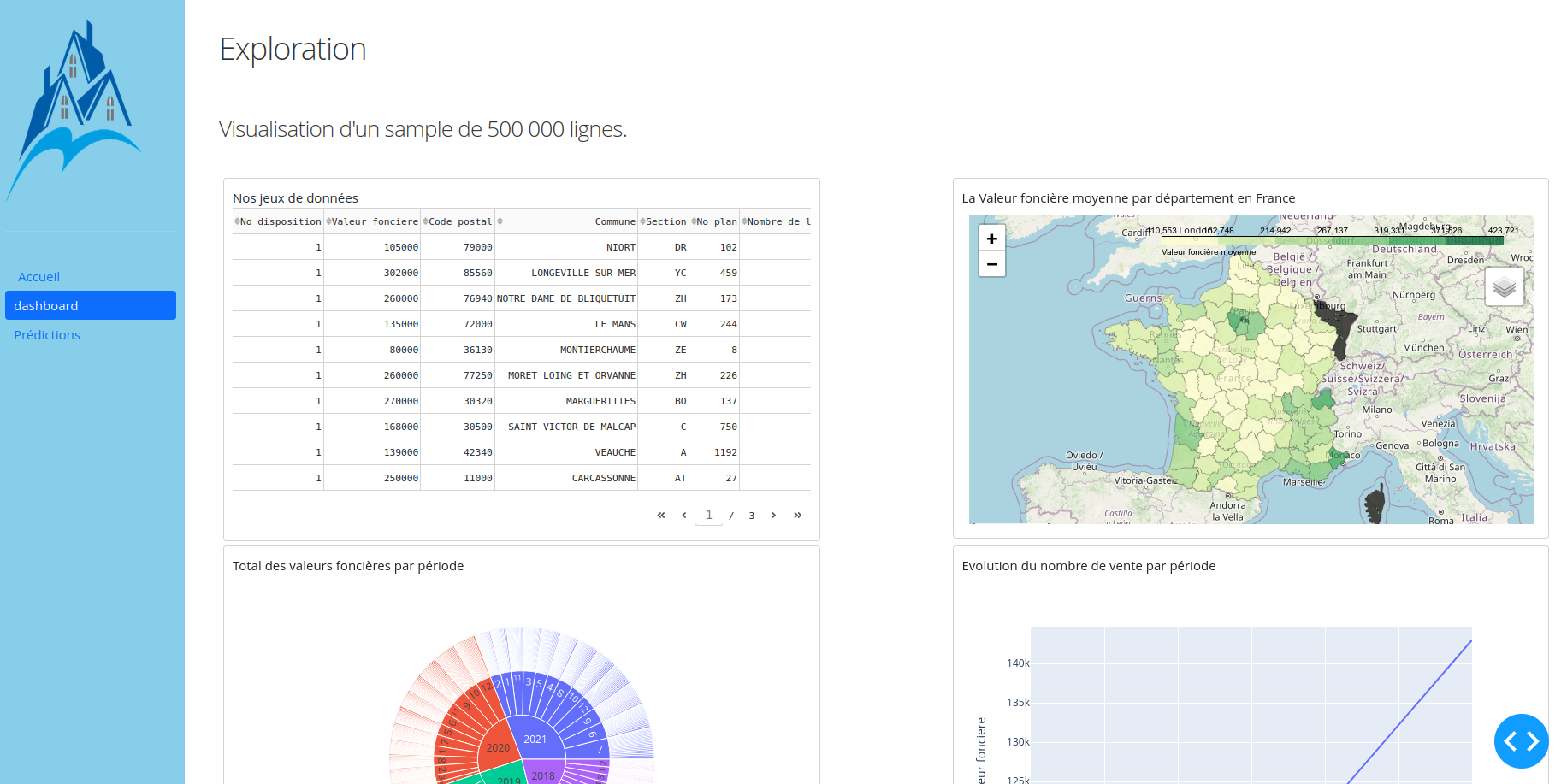
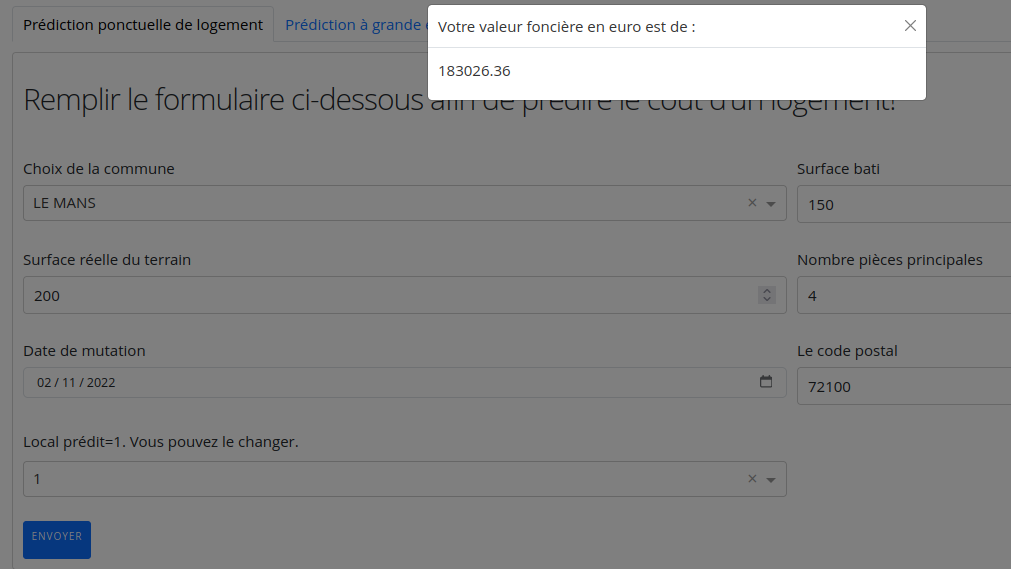
Le code du dashboard se trouve sur le depôt : git dashboard
NB : le dashboard ne fonctionne pas sur Google Chrome, utilisez Mozilla Firefox
Pour directement utilisez l'API du projet, vous pouvez vous rendre à l'adresse qui suit : fast API
data/: Ce dossier contient des données additionnelles aux fichiers CSV utilisés.src/: Ce dossier contient le code source du projet, y compris les scripts d'entraînement et de prédiction.model/: Ce dossier contient les modèles entraînés.requirements.txt: Ce fichier contient la liste des dépendances requises pour le projet.
- Nathan GRIMAULT
- Wendyam YAMEOGO
- Cyrielle BARAILLER
- Joseph PELHMAN