This repository contains the code (in PyTorch) for "Pyramid Stereo Matching Network" paper (CVPR 2018) by Jia-Ren Chang and Yong-Sheng Chen.
2020/12/20: Update PSMNet: now support torch 1.6.0 / torchvision 0.5.0 and python 3.7, Removed inconsistent indentation.
2020/12/20: Our proposed Real-Time Stereo can be found here Real-time Stereo.
@inproceedings{chang2018pyramid,
title={Pyramid Stereo Matching Network},
author={Chang, Jia-Ren and Chen, Yong-Sheng},
booktitle={Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition},
pages={5410--5418},
year={2018}
}
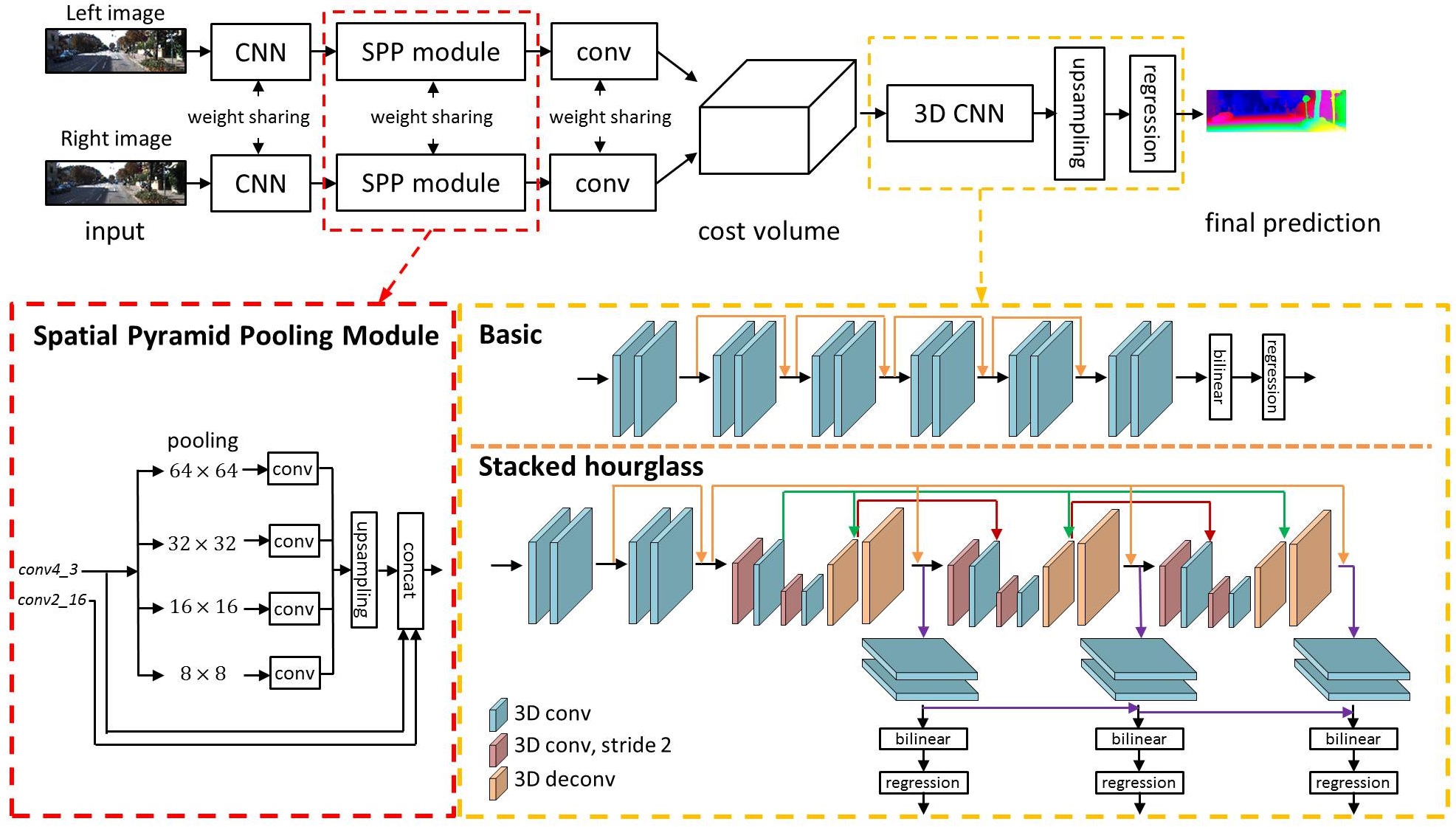
Recent work has shown that depth estimation from a stereo pair of images can be formulated as a supervised learning task to be resolved with convolutional neural networks (CNNs). However, current architectures rely on patch-based Siamese networks, lacking the means to exploit context information for finding correspondence in illposed regions. To tackle this problem, we propose PSMNet, a pyramid stereo matching network consisting of two main modules: spatial pyramid pooling and 3D CNN. The spatial pyramid pooling module takes advantage of the capacity of global context information by aggregating context in different scales and locations to form a cost volume. The 3D CNN learns to regularize cost volume using stacked multiple hourglass networks in conjunction with intermediate supervision.
- Python 3.7
- PyTorch(1.6.0+)
- torchvision 0.5.0
- KITTI Stereo
- Scene Flow
Usage of Scene Flow dataset
Download RGB cleanpass images and its disparity for three subset: FlyingThings3D, Driving, and Monkaa.
Put them in the same folder.
And rename the folder as: "driving_frames_cleanpass", "driving_disparity", "monkaa_frames_cleanpass", "monkaa_disparity", "frames_cleanpass", "frames_disparity".
- Warning of upsample function in PyTorch 0.4.1+: add "align_corners=True" to upsample functions.
- Output disparity may be better with multipling by 1.17. Reported from issues #135 and #113.
As an example, use the following command to train a PSMNet on Scene Flow
python main.py --maxdisp 192 \
--model stackhourglass \
--datapath (your scene flow data folder)\
--epochs 10 \
--loadmodel (optional)\
--savemodel (path for saving model)
As another example, use the following command to finetune a PSMNet on KITTI 2015
python finetune.py --maxdisp 192 \
--model stackhourglass \
--datatype 2015 \
--datapath (KITTI 2015 training data folder) \
--epochs 300 \
--loadmodel (pretrained PSMNet) \
--savemodel (path for saving model)
You can also see those examples in run.sh.
Use the following command to evaluate the trained PSMNet on KITTI 2015 test data
python submission.py --maxdisp 192 \
--model stackhourglass \
--KITTI 2015 \
--datapath (KITTI 2015 test data folder) \
--loadmodel (finetuned PSMNet) \
※NOTE: The pretrained model were saved in .tar; however, you don't need to untar it. Use torch.load() to load it.
Update: 2018/9/6 We released the pre-trained KITTI 2012 model.
Update: 2021/9/22 a pretrained model using torch 1.8.1 (the previous model weight are trained torch 0.4.1)
| KITTI 2015 | Scene Flow | KITTI 2012 | Scene Flow (torch 1.8.1) |
|---|---|---|---|
| Google Drive | Google Drive | Google Drive | Google Drive |
python Test_img.py --loadmodel (finetuned PSMNet) --leftimg ./left.png --rightimg ./right.png

※Note that the reported 3-px validation errors were calculated using KITTI's official matlab code, not our code.
| Method | D1-all (All) | D1-all (Noc) | Runtime (s) |
|---|---|---|---|
| PSMNet | 2.32 % | 2.14 % | 0.41 |
| iResNet-i2 | 2.44 % | 2.19 % | 0.12 |
| GC-Net | 2.87 % | 2.61 % | 0.90 |
| MC-CNN | 3.89 % | 3.33 % | 67 |



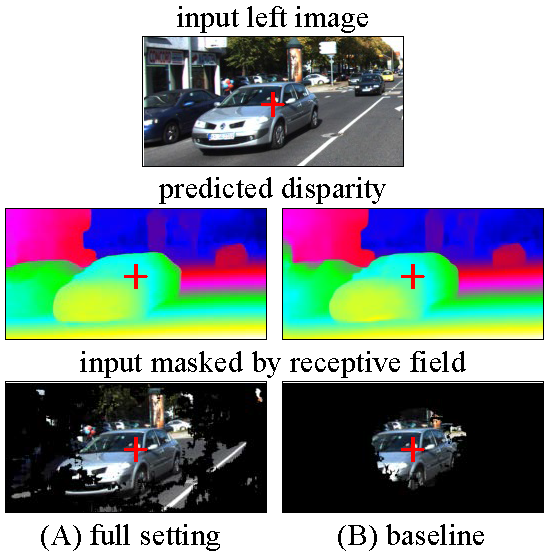
We visualize the receptive fields of different settings of PSMNet, full setting and baseline.
Full setting: dilated conv, SPP, stacked hourglass
Baseline: no dilated conv, no SPP, no stacked hourglass
The receptive fields were calculated for the pixel at image center, indicated by the red cross.
Any discussions or concerns are welcomed!