欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
https://leetcode-cn.com/problems/find-common-characters/
给定仅有小写字母组成的字符串数组 A,返回列表中的每个字符串中都显示的全部字符(包括重复字符)组成的列表。例如,如果一个字符在每个字符串中出现 3 次,但不是 4 次,则需要在最终答案中包含该字符 3 次。
你可以按任意顺序返回答案。
【示例一】 输入:["bella","label","roller"] 输出:["e","l","l"]
【示例二】 输入:["cool","lock","cook"] 输出:["c","o"]
这道题意一起就有点绕,不是那么容易懂,其实就是26个小写字符中有字符 在所有字符串里都出现的话,就输出,重复的也算。
例如:
输入:["ll","ll","ll"] 输出:["l","l"]
这道题目一眼看上去,就是用哈希法,“小写字符”,“出现频率”, 这些关键字都是为哈希法量身定做的啊
首先可以想到的是暴力解法,一个字符串一个字符串去搜,时间复杂度是O(n^m),n是字符串长度,m是有几个字符串。
可以看出这是指数级别的时间复杂度,非常高,而且代码实现也不容易,因为要统计 重复的字符,还要适当的替换或者去重。
那我们还是哈希法吧。如果对哈希法不了解,可以看这篇:关于哈希表,你该了解这些!。
如果对用数组来做哈希法不了解的话,可以看这篇:把数组当做哈希表来用,很巧妙!。
了解了哈希法,理解了数组在哈希法中的应用之后,可以来看解题思路了。
整体思路就是统计出搜索字符串里26个字符的出现的频率,然后取每个字符频率最小值,最后转成输出格式就可以了。
如图:
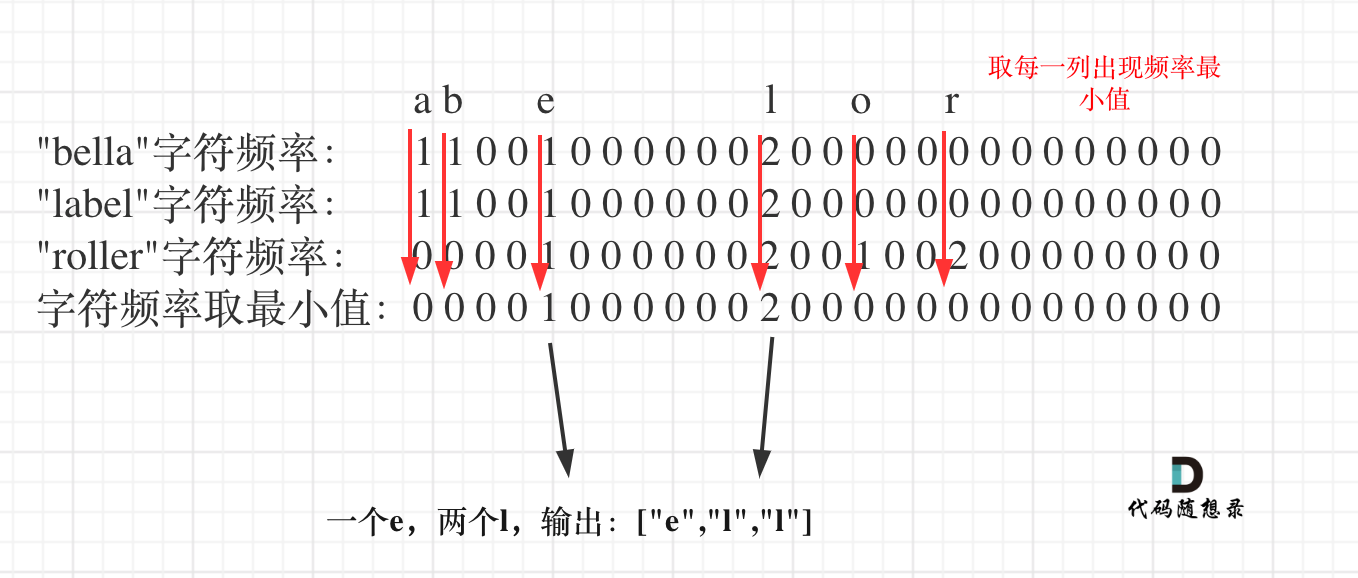
先统计第一个字符串所有字符出现的次数,代码如下:
int hash[26] = {0}; // 用来统计所有字符串里字符出现的最小频率
for (int i = 0; i < A[0].size(); i++) { // 用第一个字符串给hash初始化
hash[A[0][i] - 'a']++;
}
接下来,把其他字符串里字符的出现次数也统计出来一次放在hashOtherStr中。
然后hash 和 hashOtherStr 取最小值,这是本题关键所在,此时取最小值,就是 一个字符在所有字符串里出现的最小次数了。
代码如下:
int hashOtherStr[26] = {0}; // 统计除第一个字符串外字符的出现频率
for (int i = 1; i < A.size(); i++) {
memset(hashOtherStr, 0, 26 * sizeof(int));
for (int j = 0; j < A[i].size(); j++) {
hashOtherStr[A[i][j] - 'a']++;
}
// 这是关键所在
for (int k = 0; k < 26; k++) { // 更新hash,保证hash里统计26个字符在所有字符串里出现的最小次数
hash[k] = min(hash[k], hashOtherStr[k]);
}
}
此时hash里统计着字符在所有字符串里出现的最小次数,那么把hash转正题目要求的输出格式就可以了。
代码如下:
// 将hash统计的字符次数,转成输出形式
for (int i = 0; i < 26; i++) {
while (hash[i] != 0) { // 注意这里是while,多个重复的字符
string s(1, i + 'a'); // char -> string
result.push_back(s);
hash[i]--;
}
}
整体C++代码如下:
class Solution {
public:
vector<string> commonChars(vector<string>& A) {
vector<string> result;
if (A.size() == 0) return result;
int hash[26] = {0}; // 用来统计所有字符串里字符出现的最小频率
for (int i = 0; i < A[0].size(); i++) { // 用第一个字符串给hash初始化
hash[A[0][i] - 'a']++;
}
int hashOtherStr[26] = {0}; // 统计除第一个字符串外字符的出现频率
for (int i = 1; i < A.size(); i++) {
memset(hashOtherStr, 0, 26 * sizeof(int));
for (int j = 0; j < A[i].size(); j++) {
hashOtherStr[A[i][j] - 'a']++;
}
// 更新hash,保证hash里统计26个字符在所有字符串里出现的最小次数
for (int k = 0; k < 26; k++) {
hash[k] = min(hash[k], hashOtherStr[k]);
}
}
// 将hash统计的字符次数,转成输出形式
for (int i = 0; i < 26; i++) {
while (hash[i] != 0) { // 注意这里是while,多个重复的字符
string s(1, i + 'a'); // char -> string
result.push_back(s);
hash[i]--;
}
}
return result;
}
};Java:
class Solution {
public List<String> commonChars(String[] A) {
List<String> result = new ArrayList<>();
if (A.length == 0) return result;
int[] hash= new int[26]; // 用来统计所有字符串里字符出现的最小频率
for (int i = 0; i < A[0].length(); i++) { // 用第一个字符串给hash初始化
hash[A[0].charAt(i)- 'a']++;
}
// 统计除第一个字符串外字符的出现频率
for (int i = 1; i < A.length; i++) {
int[] hashOtherStr= new int[26];
for (int j = 0; j < A[i].length(); j++) {
hashOtherStr[A[i].charAt(j)- 'a']++;
}
// 更新hash,保证hash里统计26个字符在所有字符串里出现的最小次数
for (int k = 0; k < 26; k++) {
hash[k] = Math.min(hash[k], hashOtherStr[k]);
}
}
// 将hash统计的字符次数,转成输出形式
for (int i = 0; i < 26; i++) {
while (hash[i] != 0) { // 注意这里是while,多个重复的字符
char c= (char) (i+'a');
result.add(String.valueOf(c));
hash[i]--;
}
}
return result;
}
}