팀 이름 : 팀명뭘로하조

박범수 |

한건우 |

홍요한 |

박준혁 |

조혜원 |
최근 사람들의 운동에 대한 관심도가 높아지면서 SNS에 눈바디 사진을 촬영하는 사람이 늘고 있습니다. 하지만, 우리의 눈을 얼마나 믿을 수 있을까요? 이를 AI가 보완해 줄 수는 없을까요? 이번 챌린지에서 제공된 데이터로 정교한 AI 모델을 개발한다면, 이미지 안에서 사람의 body parts별 면적을 구할 수 있습니다. 이를 통해서 눈바디 사진을 촬영하는 사람들이 내 몸의 어느 부분이 변화하고 있는지 알려주는 알고리즘을 얻고자 합니다.
촬영된 사진에서 사람의 각 신체부위(body parts) 별로 semantic segmentation AI 모델 개발
-
train dataset - Dense COCO 2014 Dataset (https://cocodataset.org/#home)
-
test dataset - 다양한 포즈를 취하고 있는 취하고 있는 남여의 전신 사진 (annotation을 포함한 image 800장)
-
[배경(background) - 0 / 몸통(body) - 1 / 오른손(R-hand) - 2 / 왼손(L-hand) - 3 / 왼발(L-foot) - 4 / 오른발(R-foot) - 5 / 오른쪽 허벅지(R-thigh) - 6 / 왼쪽 허벅지(L-thigh) - 7 / 오른쪽 종아리(R-calf) - 8 / 왼쪽 종아리(L-calf) - 9 / 왼쪽 팔(L-arm) - 10 / 오른쪽 팔(R-arm) - 11 / 왼쪽 전완(L-forearm) - 12 / 오른쪽 전완(R-forearm) - 13 / 머리(head) - 14]
-
labeling 정보들 중 머리(14)는 학습에 사용하는 것은 관계없으나 평가에는 사용하지 않습니다.
사람의 Body Parts 별 Segmentation을 진행하여 변화되는 몸 상태를 확인하고 관리
-
Validation Data 해상도가 train에 비해 상대적으로 큼
- Validation Data 해상도가 1920x1440, 2560x1440으로 train dataset 평균보다 4~8배 정도 큰 이미지들이었음
- 원해상도에서 inference 자체가 불가능했기 때문에 512x512로 일괄 resize 하여 사용함
-
모델 파일 100MB 제한
- 모델 파일의 크기가 100MB 제한이라는 대회 규정 때문에, 100MB를 넘지 않는 한도 내에서 최대한 큰 모델을 사용하려고 함
- 최종적으로 Efficientnet-B4 + DeepLabV3+ 조합으로 실험을 진행하였음
-
Validation Data Annotation 확인 (좌우 바뀜 + 발 잘못됨)

- 주최측에서 제공한 Validation Data의 좌우가 반대로 Annotation되어 수정
- 주최측에서 제공한 Validation Data의 발 부분에 noise가 존재하여 수정
-
COCO dataset에 대한 잘못된 mask 형식
- 주최측에서 제공한 COCO train dataset 변환 코드에 객체별 mask가 지워지는 문제가 있어서 이 부분을 수정함
-
바뀐 Validation Data에 대해 목 부분이 잘못 annotation
- Validation Data에 Head가 Right thigh로 annotation된 데이터가 있어 수정함
-
데이터 추가 제작

- Validation Dataset과 COCO Dataset은 데이터의 분포가 크게 달라 COCO Dataset 만으로는 성능 향상이 어렵다고 판단함
- Validation Dataset을 확인하여 Google, Pinterest, Naver에서 관련 키워드를 통해 Image Crawling 을 활용하여 추가 데이터를 수집함
- 수집한 데이터로 annotation 작업하여 Train 데이터로 활용함
- 작업들 간의 충돌을 방지하기 위해 룰을 정하고 이에 맞게 annotation을 진행하려 노력함.
- 그래픽 이미지 제거
- 얼굴만 있는 이미지 제거
- Text Occulusion이 있는 데이터 제거
- 옷만 있는 이미지 제거
- 머리카락 숱많은 부분은 head에 포함
- 신발은 발에 포함
- 오버핏 (코트 기타 등등) 옷 입은 대상 제거
- 총 331장의 데이터를 생성함 😤
-
zoom out Augmentation / random gamma Augmentation
- Validation Dataset에 있는 이미지 들 중에 전체 이미지 크기에서 객체가 차지하는 범위가 작은 이미지들이 존재함
- Private Dataset에 유사한 데이터가 있다고 판단되어 Val mIoU에서 성능향상이 보이지 않더라도 추가함
- Random Gamma Augmentation 적용시 ShiftScaleRotate만 적용시켰을 때 보다 성능이 향상 됨을 확인함
-
TTA
- 여러 옵션으로 테스트 하였으나 TTA 종류나 강도를 추가할 경우, 왼쪽, 오른쪽 구별 성능이 오히려 떨어지는 것을 확인함
- 기본적인 noise만 제거하기 위해 Gamma와 시너지를 낼 수 있도록 pixel 값에 multiply(0.9, 1.0, 1.1)만 적용함
-
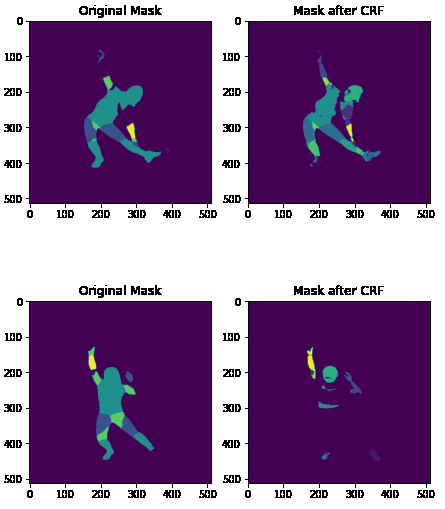
CRF
- CRF 적용을 시도했으나 annotation이 background와 color가 유사해 CRF의 영향을 받아 삭제되는 현상이 발생했고, 삭제되지 않은 부분에 대해서는 디테일하게 annotation이 적용되는 점을 확인할 수 있었음. 하지만 이번 대회에서는 적용시켰을 때에 손실량이 컸기 때문에 적용하지 않았음.




- 각 Class별로 IoU를 모두 구합니다.
- 이미지에 모든 class가 존재하지 않을 것을 고려, ground truth에 존재하는 class와 prediction 결과에 존재하는 class의 합집합을 구해서 합집합 class에 속하는 class의 IoU에 대해서 평균값을 구합니다.
- 2.에서 이미지 별로 구한 mIoU의 평균 값을 구하여 최종 순위를 결정합니다.

LB Score : 0.708717 🥈

{kind=link}
과정 외의 첫 segmentation 대회여서 긴장도 많이 되고, 다양한 기법을 활용하려고 했던 것 같습니다. 그래도 많은 것을 시도해보려고 segmentation 관련 공부를 이어 나갔고 많은 것들을 적용시키기엔 모델 용량 제한 등 제약이 있었기 때문에 아쉬운 점이 있었지만, 그래도 주어진 환경 내에 맞추기 위해서 공부들을 할 수 있어서 좋았던 것 같습니다.