forked from Elvin-Ma/pytorch_guide
-
Notifications
You must be signed in to change notification settings - Fork 0
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
- Loading branch information
elvin
committed
Jun 29, 2023
1 parent
105015e
commit abee4e8
Showing
20 changed files
with
179 additions
and
1 deletion.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
{kind=link}
Binary file not shown.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,22 @@ | ||
| # pytorch model parallel summary | ||
|
|
||
|  | ||
|
|
||
|
|
||
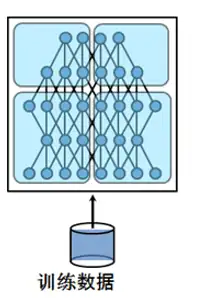
| ## 数据并行的优缺点 | ||
| - 优点:将相同的模型复制到所有GPU,其中每个GPU消耗输入数据的不同分区,可以极大地加快训练过程。 | ||
| - 缺点:不适用于某些模型太大而无法容纳单个GPU的用例。 | ||
|
|
||
| ## 模型并行介绍 | ||
| *模型并行的高级思想是将模型的不同子网放置到不同的设备上,并相应地实现该 forward方法以在设备之间移动中间输出。* | ||
| *由于模型的一部分只能在任何单个设备上运行,因此一组设备可以共同为更大的模型服务。* | ||
| *在本文中,我们不会尝试构建庞大的模型并将其压缩到有限数量的GPU中。* | ||
| *取而代之的是,本文着重展示模型并行的思想。读者可以将这些想法应用到实际应用中。* | ||
|
|
||
|
|
||
| # [references] | ||
| [参考文献1-pytorch](https://pytorch.org/tutorials/intermediate/model_parallel_tutorial.html) | ||
| [参考文献2-pytorchRPC](https://pytorch.org/tutorials/intermediate/rpc_tutorial.html) | ||
| [参考文献3](https://pytorch.org/tutorials/intermediate/rpc_param_server_tutorial.html) | ||
| [参考文献4](https://juejin.cn/post/7043601075307282462) | ||
| [参考文献5](https://pytorch.org/tutorials/intermediate/dist_pipeline_parallel_tutorial.html) |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,16 @@ | ||
| # PyTorch Tensor Parallelism for distributed training | ||
|
|
||
| This example demonstrates SPMD Megatron-LM style tensor parallel by using | ||
| PyTorch native Tensor Parallelism APIs, which include: | ||
|
|
||
| 1. High-level APIs for module-level parallelism with a dummy MLP model. | ||
| 2. Model agnostic ops for `DistributedTensor`, such as `Linear` and `RELU`. | ||
| 3. A E2E demo of tensor parallel for a given toy model (Forward/backward + optimization). | ||
|
|
||
| More details about the design can be found: | ||
| https://github.com/pytorch/pytorch/issues/89884 | ||
|
|
||
| ``` | ||
| pip install -r requirements.txt | ||
| python example.py | ||
| ``` |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,133 @@ | ||
| import argparse | ||
| import os | ||
| import torch | ||
| import torch.distributed as dist | ||
| import torch.multiprocessing as mp | ||
| import torch.nn as nn | ||
|
|
||
| TP_AVAILABLE = False | ||
| try: | ||
| from torch.distributed._tensor import ( | ||
| DeviceMesh, | ||
| ) | ||
| from torch.distributed.tensor.parallel import ( | ||
| PairwiseParallel, | ||
| parallelize_module, | ||
| ) | ||
| TP_AVAILABLE = True | ||
| except BaseException as e: | ||
| pass | ||
|
|
||
|
|
||
| """ | ||
| This is the script to test Tensor Parallel(TP) on a toy model in a | ||
| Megetron-LM SPMD style. We show an E2E working flow from forward, | ||
| backward and optimization. | ||
| More context about API designs can be found in the design: | ||
| https://github.com/pytorch/pytorch/issues/89884. | ||
| And it is built on top of Distributed Tensor which is proposed in: | ||
| https://github.com/pytorch/pytorch/issues/88838. | ||
| We use the example of two `nn.Linear` layers with an element-wise `nn.RELU` | ||
| in between to show an example of Megatron-LM, which was proposed in paper: | ||
| https://arxiv.org/abs/1909.08053. | ||
| The basic idea is that we parallelize the first linear layer by column | ||
| and also parallelize the second linear layer by row so that we only need | ||
| one all reduce in the end of the second linear layer. | ||
| We can speed up the model training by avoiding communications between | ||
| two layers. | ||
| To parallelize a nn module, we need to specify what parallel style we want | ||
| to use and our `parallelize_module` API will parse and parallelize the modules | ||
| based on the given `ParallelStyle`. We are using this PyTorch native Tensor | ||
| Parallelism APIs in this example to show users how to use them. | ||
| """ | ||
|
|
||
|
|
||
| def setup(rank, world_size): | ||
| os.environ['MASTER_ADDR'] = 'localhost' | ||
| os.environ['MASTER_PORT'] = '12355' | ||
|
|
||
| # initialize the process group | ||
| dist.init_process_group("nccl", rank=rank, world_size=world_size) | ||
| torch.cuda.set_device(rank) | ||
|
|
||
| def cleanup(): | ||
| dist.destroy_process_group() | ||
|
|
||
|
|
||
| class ToyModel(nn.Module): | ||
| def __init__(self): | ||
| super(ToyModel, self).__init__() | ||
| self.net1 = nn.Linear(10, 32) | ||
| self.relu = nn.ReLU() | ||
| self.net2 = nn.Linear(32, 5) | ||
|
|
||
| def forward(self, x): | ||
| return self.net2(self.relu(self.net1(x))) | ||
|
|
||
|
|
||
| def demo_tp(rank, args): | ||
| """ | ||
| Main body of the demo of a basic version of tensor parallel by using | ||
| PyTorch native APIs. | ||
| """ | ||
| print(f"Running basic Megatron style TP example on rank {rank}.") | ||
| setup(rank, args.world_size) | ||
| # create a sharding plan based on the given world_size. | ||
| device_mesh = DeviceMesh( | ||
| "cuda", | ||
| torch.arange(args.world_size), | ||
| ) | ||
|
|
||
| # create model and move it to GPU with id rank | ||
| model = ToyModel().cuda(rank) | ||
| # Create a optimizer for the parallelized module. | ||
| LR = 0.25 | ||
| optimizer = torch.optim.SGD(model.parameters(), lr=LR) | ||
| # Parallelize the module based on the given Parallel Style. | ||
| model = parallelize_module(model, device_mesh, PairwiseParallel()) | ||
|
|
||
| # Perform a num of iterations of forward/backward | ||
| # and optimizations for the sharded module. | ||
| for _ in range(args.iter_nums): | ||
| inp = torch.rand(20, 10).cuda(rank) | ||
| output = model(inp) | ||
| output.sum().backward() | ||
| optimizer.step() | ||
|
|
||
| cleanup() | ||
|
|
||
|
|
||
| def run_demo(demo_fn, args): | ||
| mp.spawn(demo_fn, | ||
| args=(args,), | ||
| nprocs=args.world_size, | ||
| join=True) | ||
|
|
||
|
|
||
| if __name__ == "__main__": | ||
| n_gpus = torch.cuda.device_count() | ||
| parser = argparse.ArgumentParser() | ||
| # This is passed in via cmd | ||
| parser.add_argument("--world_size", type=int, default=n_gpus) | ||
| parser.add_argument("--iter_nums", type=int, default=10) | ||
| args = parser.parse_args() | ||
| # The main entry point is called directly without using subprocess | ||
| if n_gpus < 2: | ||
| print("Requires at least 2 GPUs to run.") | ||
| elif not TP_AVAILABLE: | ||
| print( | ||
| "PyTorch doesn't have Tensor Parallelism available," | ||
| " need nightly build." | ||
| ) | ||
| else: | ||
| run_demo(demo_tp, args) | ||
|
|
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,6 @@ | ||
| # Python dependencies required for running the example | ||
|
|
||
| --pre | ||
| --extra-index-url https://download.pytorch.org/whl/nightly/cu113 | ||
| --extra-index-url https://download.pytorch.org/whl/nightly/cu116 | ||
| torch >= 1.14.0.dev0; sys_platform == "linux" |
File renamed without changes.
File renamed without changes.
File renamed without changes.
File renamed without changes.
File renamed without changes.
File renamed without changes.
File renamed without changes.
File renamed without changes.
File renamed without changes.
File renamed without changes.
File renamed without changes.
File renamed without changes.
File renamed without changes.
File renamed without changes.