English | 中文



- 基于
PyMuPDF提取文本、图片、矢量等原始数据 - 基于规则解析章节、段落、表格、图片、文本等布局及样式
- 基于
python-docx创建Word文档
-
解析和创建页面布局
- 页边距
- 章节和分栏 (目前最多支持两栏布局)
- 页眉和页脚 [TODO]
-
解析和创建段落
- OCR 文本 [TODO]
- 水平(从左到右)或竖直(自底向上)方向文本
- 字体样式例如字体、字号、粗/斜体、颜色
- 文本样式例如高亮、下划线和删除线
- 列表样式 [TODO]
- 外部超链接
- 段落水平对齐方式 (左/右/居中/分散对齐)及前后间距
-
解析和创建图片
- 内联图片
- 灰度/RGB/CMYK等颜色空间图片
- 带有透明通道图片
- 浮动图片(衬于文字下方)
-
解析和创建表格
- 边框样式例如宽度和颜色
- 单元格背景色
- 合并单元格
- 单元格垂直文本
- 隐藏部分边框线的表格
- 嵌套表格
-
支持多进程转换
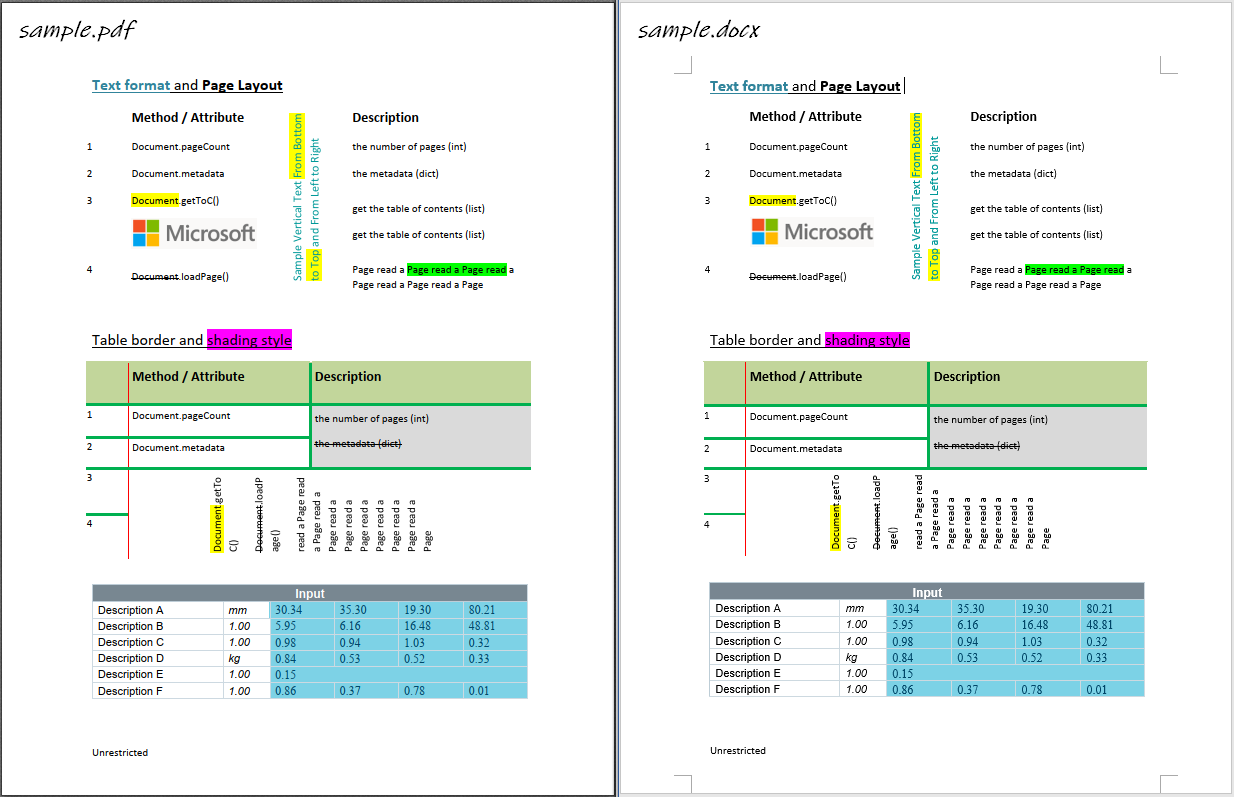
pdf2docx同时解析出了表格内容和样式,因此也可以作为一个表格内容提取工具。
- 目前暂不支持扫描PDF文字识别
- 仅支持从左向右书写的语言(因此不支持阿拉伯语)
- 不支持旋转的文字
- 基于规则的解析无法保证100%还原PDF样式