Have you ever lost data due to hard drive failure? This work is meant to bring the science of data to bear on this kind of misfortune. The use of hard drives has been growing exponentially, as they are used on computers (which are increasingly ubiquitous), to store data. Drive hard failures can indeed be costly and painful, especially as more voluminous, and frequently valuable, data is stored on them. The causes of hard drive failures are varied. Let us run through some of them. Some may be due to mishaps, such as: Water Damage, Human Error, Extreme Thermal or Magnetic Energy e.t.c. Some, which are possibly preventable are: Virus-infected or Faulty Software, Unallocated Space Issues, Hardware Issues, Mechanical Flaws, Power Issues, and Firmware Corruption . As you can see, not all causes are easily preventable. Nevertheless, this study will examine the details for those failure causes which are. Some years ago, a Google paper reported that up to 40% of units being studied, which failed, did not have any associated SMART flags.
SMART. One might be asking - 'What is that?' According to Wikipedia, S.M.A.R.T. (often written as SMART) is a monitoring system included in computer hard disk drives - to detect, and report various indicators of drive reliability with the intent of anticipating imminent hardware failures, so that software running on the host system may alert the user, to prevent data loss. Thus the failing drive could be replaced -with the ultimate goal of data integrity being maintained.
![hard drive failure] (http://samplesite.com/somesample.jpg)

The Data Source. Every month, since 2013, Backblaze (Backblaze.com) has been generating 1 comma-separated values spreadsheet, containing one observation entry per day for each of the hundreds of thousands of drives in its data center. Each spreadsheet entry stores more than 50 of the 255 SMART hard drive monitoring metrics published by hard drive manufacturers. After extensive review of the data, the data subset from Seagate model STD4000DM000, if they failed in 2019, was selected for further analysis, because that model’s units seemed to have a fairly consistent performance profile. In order to determine how to predict lifespans with SMART health monitoring attributes, at first a regression analysis was performed. The remaining useful days was calculated for each observation by subtracting the observation date from the failure date.
[Causes of hard drive failure]
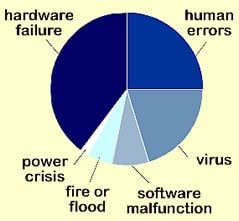
This was then used as a target while the monitored attributes were used as features.

The accuracy of this model was low. I then tried a different approach. This time, the observed lifespans for the units were grouped into 12 sets. These group labels were fed into a tree classification model as targets, again with monitored features as inputs. A tree classification algorithm seeks to branch through decisions, as a means of categorizing its outputs.
The end-points for a series of decision branches are called nodes, and should ideally match a category of outputs. In this case, an ensemble of such trees was employed in order to enhance accuracy. The extra-trees ensemble algorithm was used. The extra-trees ensemble randomly chooses the thresholds for determining gini impurity. On the other hand, random forests, another ensemble of decision tree classifiers, uses a fixed level for the gini impurity threshold. Both algorithms expose random subsets of the data to each of the sub-estimators. [Tree classification ensemble methods]

{kind=link}
This time, with the extra-trees algorithm, the average accuracy (0.81) was much higher. Furthermore, the top feature, when weighted by importance, was the Load Cycle Count. Some other features in descending order, were: 2. Total Logical block addresses Written to, 3. Spin-Up Time, 4. Power Cycle Count, 5. Start/Stop Count, 6. Total Logical block addresses read from, 7. Power-On Hours, 8. Head Flying Hours, 9. Seek Error Rate, 10. Reported Uncorrectable Errors, 11. SATA Downshift Error Count or Runtime Bad Block, and 12. Temperature Difference or Airflow Temperature.
Observing the accuracy rate, we can say that for each unit, the algorithm predicts with a greater than 60% success rate, whether it will suffer very early death, or operate closer to the typical lifespan of greater than 40000 hours.