本项目目的是把自然语言的文本转换成Neo4j的 Cypher 查询语句。和另一个大家可能已经比较熟悉的场景 Text2SQL:文本转换 SQL 在形式上没有什么区别。但是知识图谱查询的发展非常缓慢,RAG目前是主流,通过文本转换为向量进行相似度查询得到最优Prompt
项目地址:https://github.com/langchain-ai/langchain/tree/master/templates/neo4j-cypher
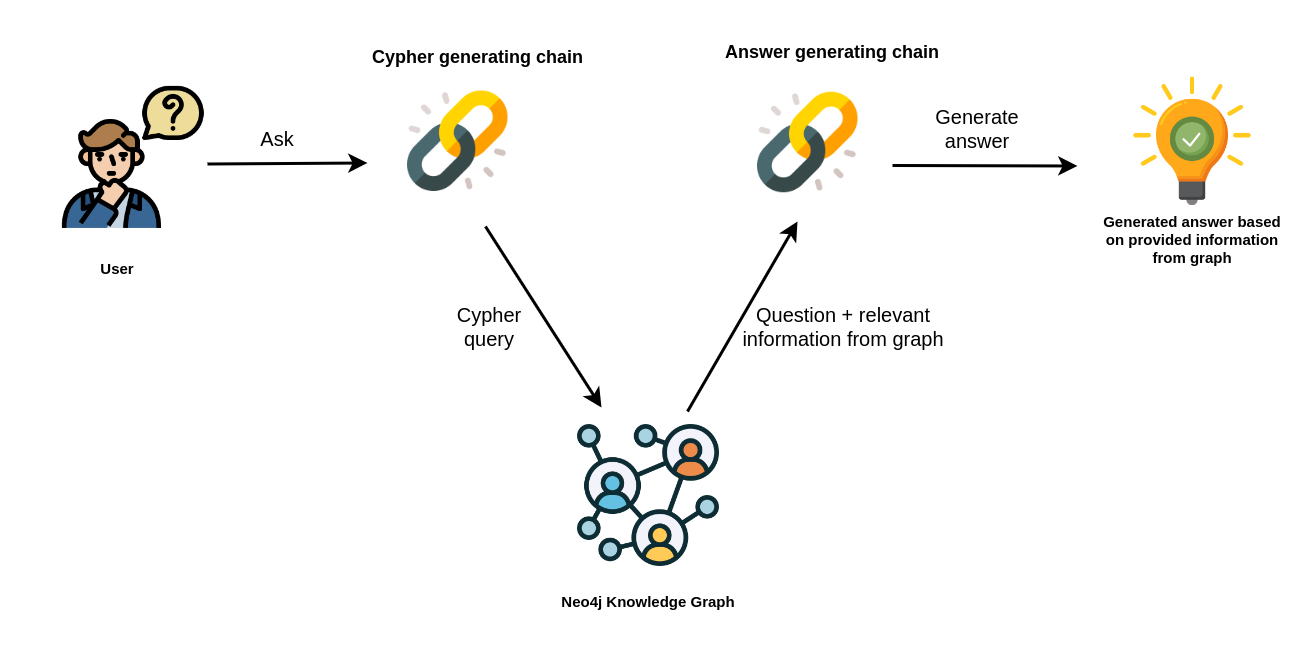
langchain已经对接了Neo4j,可以从代码中看到neo4j_cypher/chain.py 的第19~21行文件中可以看出
# LLMs
cypher_llm = ChatOpenAI(model_name="gpt-4", temperature=0.0)
qa_llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0.0)
gpt-4用来生成查询语句,gpt-3.5-turbo用查询到的结果作为Prompt然后回答用户提出的问题
项目地址:https://github.com/varunshenoy/GraphGPT
这里用的也是gpt-4
依然用的是gpt-4
Nebula数据库,和neo4j类似
项目地址:https://github.com/wey-gu/NebulaGraph-GPT
这里使用gpt-3生成查询语句
经过在https://huggingface.co/的搜索,并没有找到相关模型,似乎只又chatgtp-4可做到生成查询语句
另外也没有在huggingface上搜索到比较好的数据集
但是费点时间总能出结果,找到了一个质量很好的数据集放到了huggingface:text-to-neo4j-cypher-chinese
来源于论文 SpCQL: A Semantic Parsing Dataset for Converting Natural Language into Cypher
微调模型必须选择中文指令模型,例如:llama-3-chinese-8b-instruct-v2
现在知识图谱标签、关系没有统一,模型训练出来后只能针对训练集的知识图谱进行text-to-neo4j-cypher 设想过对这些标签、关系向量化以达到统一的目的