Replace the existing solver API end point. #32
Comments
|
I'm actually second-guessing the tact here...90% of the solver usage, I reckon, will come from the online editor and/or the VSCode plugin. How about this (CC @nirlipo @jan-dolejsi)...
That would likely minimize the impact, no? |
|
Looks like we have the go-ahead. @YIDING-CODER : What's the status of the new plugin? @jan-dolejsi : Do you want any help in re-working the plugin call to the planner? @nirlipo : Can you check to make sure the right ports are open for public access? E.g., I'd expect http://45.113.232.43/docs/lama or http://45.113.232.43/package to work |
|
Yes, we are ready for deployment! Port 80 should be open but currently we are using port 5001. The links http://45.113.232.43:5001/docs/lama and http://45.113.232.43:5001/package are working correctly. See https://github.com/AI-Planning/planning-as-a-service#api regarding the ports we are using. We would need to change all these files https://github.com/AI-Planning/planning-as-a-service/search?q=5001 to change to port 80 |
|
@nirlipo Perfect, thanks! I missed that port 5001 bit of info. I was able to take it across the finish line with AI-Planning/planutils#72 on the current server (will swap out the base URL once we re-map to solver.PD). |
|
@haz do you have a description somewhere for what the client interaction with the service(s) will be? Something like this: http://solver.planning.domains/ description. |
|
Would be a wonderful future for it! Open socket, that is. For now, I've just looked through this to get a sense of the API, and this is an example of how I turned it synchronous. The initial call returns a URL extension with a big code to check on the status. That code just pings it every 0.5s until the result is ready. You can see another example of the call structure here. The reason it isn't rigid and written somewhere is because packages in |
|
Ok, pretty cool. I managed to pull the manifest from the URL above, constructed a URL to call a selected solver, got back the URL to poll for results. Do you have a schema or something for what the manifest may contain when it comes to other arguments and switches passable to the solver? Like for example this list of options (and ideally valid values for the options that I am hardcoding for the planners that I got my hands on: Btw, any chance we could implement a long-polling style endpoint for fetching the plan(s)? That would mean that the client passes a header with number of seconds it is willing to wait for the plan. If a plan is found within that timeout, the solver returns the plan. If the timeout is about to expire, the solver returns the call with a "call again" status. That way we would not need to poll the poor service and we would get the plan(s) to the client as soon as they are found. I have an Openapi spec for that. Along with restful api for fetching and pruning the requests and associated plans. |
Since we have deploy the latest paas to server, I have to test the plugin. I will try to do the testing tomorrow. I feel like the VS Code plugin could use the same API endpoits I used for Planing Editor plugin. I will provide the API detailed as well. |
@YIDING-CODER , yes please. Is it going to be exposed at an address like |
@jan-dolejsi Below are the APIs that may relevant to you:
You can find the python example on this notebook. You can also find the js example here. Please have a look at lines 52,154 and 217. |
|
Thanks @YIDING-CODER ! Just wanted to add a few more concrete endpoints (for now, port
The beautiful thing about this setup is that it's service/package defined. So it may be custom to any newly added planutils package. Though, we do have templates for common planner usage (domain/problem parameters, etc).
Yep, plans are now possible. You can see it in the two more complicated examples above.
This sounds pretty awesome! Any chance you could elaborate in a new issue? Definitely feels like we should move to a model like this, and potentially also allow for partial data to be return (plans as they're generated, search updates, etc). I can imagine it mirroring the command-line output as the problem is solved. |
|
I occasionally get this error: But when it works, it starts looking cool: I wish the manifest listed the PDDL :requirements that the given planner supports, so I could filter it by the set of requirements declared in the domain/problem that is being sent to the planner. |

|
Great to see it working in Vscode @jan-dolejsi ! In terms of requirements, in the long term, we may want to auto populate the requirements in the manifests by testing planners with PDDL files designed specifically to test support of different features. |
|
This looks awesome, @jan-dolejsi!
I think that's precisely the plan, yep! This could do the trick: https://github.com/nergmada/eviscerator
Not sure where this one is coming from. When does it crop up? |
This is happening right now. It comes back as a plain ASCII (not JSON) HTTP response body, when I send |
|
Next, during the last couple of days I did not manage to get all the way to a plan. Instead I get 'PENDING' and then in the next poll just seconds later I get this: {
"result": {
"call": "optic domain problem >> plan",
"output": {},
"output_type": "log",
"stderr": "",
"stdout": "Request Time Out"
},
"status": "ok"
}It is a simple blocksworld problem that I am sending. And I am getting the same |
|
@nirlipo @YIDING-CODER : There an ongoing issue with the solver? @jan-dolejsi : Can you share the token for one of the failed calls so they can dig into the db on it? |
/check/4c0f6ce7-6f7d-41f2-b4c5-bb948d14e556?external=True |
|
Hrmz...looks like a timeout on it:
Have one for optic? |

@jan-dolejsi Is it easy for you to create a postman request that can trigger this error message? Can you please share the postman file, and I can invesigate why it is happens. |
@jan-dolejsi @haz The default time out is 20seconds. If the solver is not finshed in 20s, it will returns the timeout. Paas is using celery to manage the task. If the server is busy, the task will be in the waiting list. I don't think it's caused by the server issue. I will run a test soon. |
|
The server (flower interfaces) is extremely slow, so there may be something up... |
|
I tried to ssh and couldn't, so I started digging through the logs. This is the first thing I get while trying to connect through a virtual console through the management system:
It seems we are not enforcing the mem-outs correctly, or we are not killing the process. See mem-out Optic-clp messages. |

|
@YIDING-CODER, I manage to ssh, and |

|
Ouch! If we're going to put this in front of hundreds of students, the failsafe will need to be rock solid :P. Individual planner resource limits obviously need a check, but I reckon two further things should be in play:
|
|
@haz @nirlipo Below is the documentation for max-memory-per-child: I think the child here is refering to worker. Currently we have one celery worker runing on the server(Nir has asked me to add more, but I havn't make the changes). If the single task(like Optic domain problem) exceed the 12MB memory usage, the task will be completed and the worker will be replaced afterwards. For somehow, it is end up with the out of memory issue. Also, I found an example to prove this behavior - celery - will --max-memory-per-child restart workers instantly or allow them to finish the task?. Actions |
|
I'm unclear with the celery queue stuff. But from the SO post you link to, it sounds like we need something more aggressive at stopping processes that exceed the memory. They shouldn't be allowed to complete (some planners are good at staying within their memory limits or stopping if they can't, but not all of them). I think the memory we allow for a single thread/worker comes down to the resources we have available. @nirlipo , what are the limits looking like? For the record, 12MB is way too low. Probably 1Gb or 2Gb will be the sweet spot. |
|
It seems that it is freeing the worker to process the next job, but not killing the process. The processes left running not only exceed the memory limit, but they also exceeded the time limit: 20s. It seems that if the max-memory limit is reached before the 20s, then the process is not being killed. I say this because I tested bfws over a hard sokoban instance that takes >> 20s, without reaching mem limit, and it was killed correctly. In terms of specs, we currently have RAM: 64GB I'll manually do a hard reboot so we can investigate further how to avoid this issue. It is currently too slow to work with ssh. The system is up again (see Flower service) but now we have 12 workers and 4GB of mem-limit, The pending action item is:
|
|
Can we wrap things in extra command-line limits? |
|
Certainly! As an example of simple code that can be reused, we can use the benchmark.py file to wrap all the system calls. We just need to use the It's the code we use in LAPKT: https://github.com/LAPKT-dev/LAPKT-public/tree/master/examples/agnostic-examples, and I believe it was inspired by how FD used to limit their processes. See how the run function is used by looking at the |
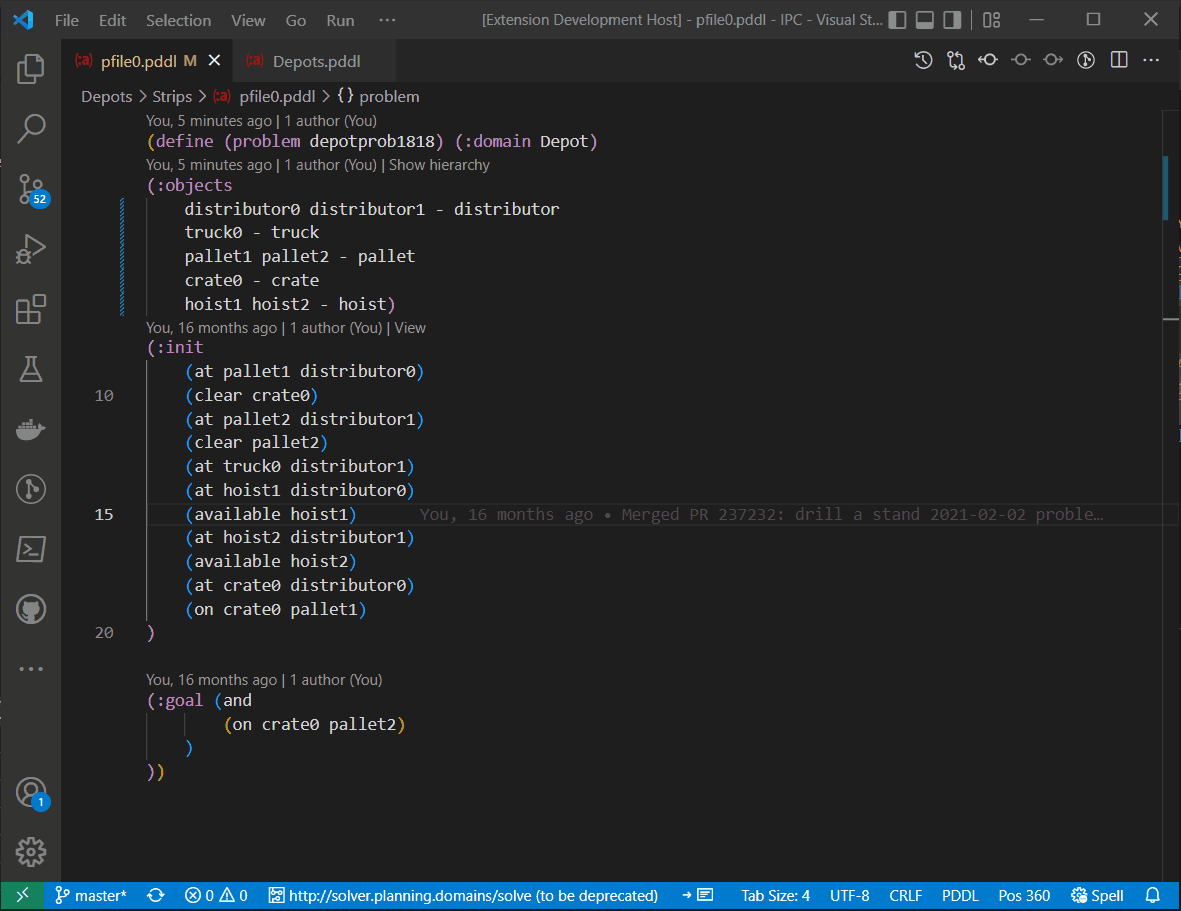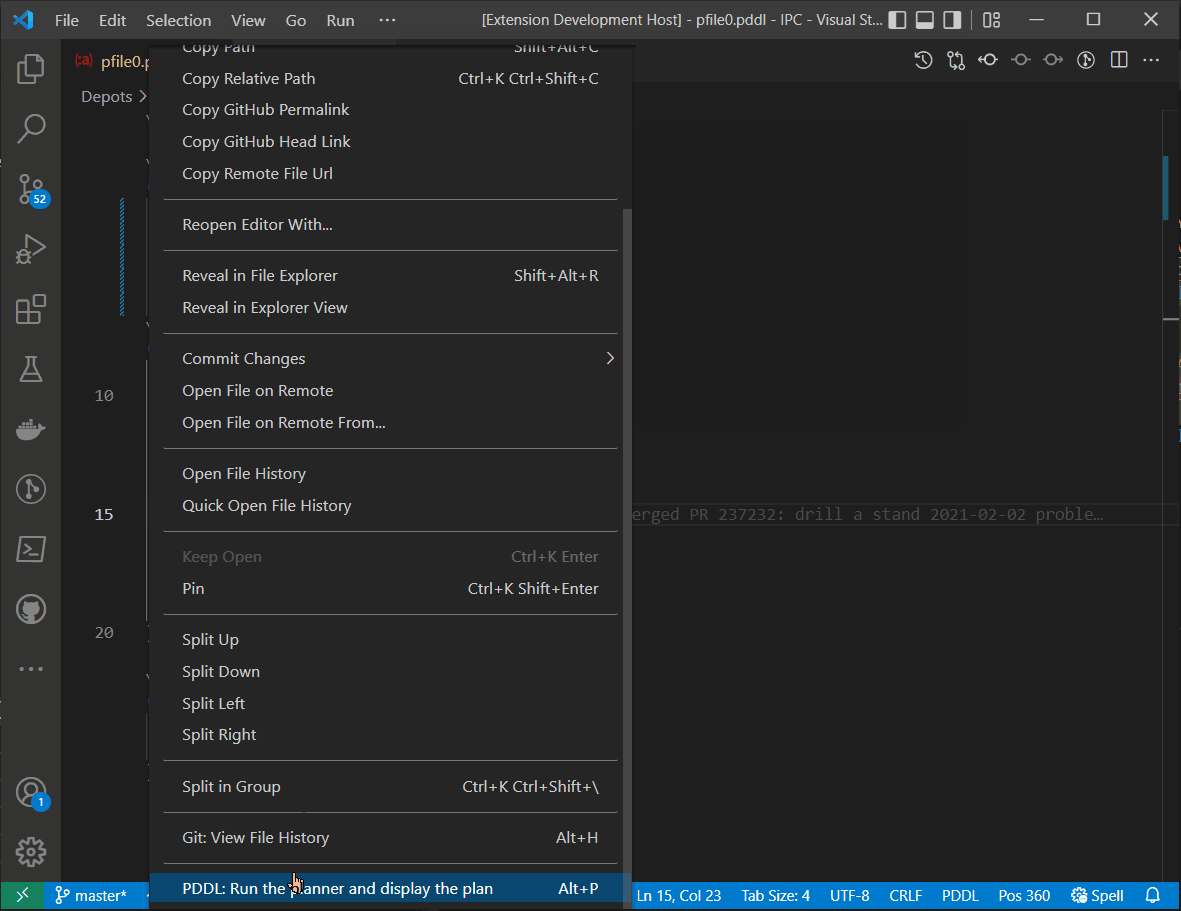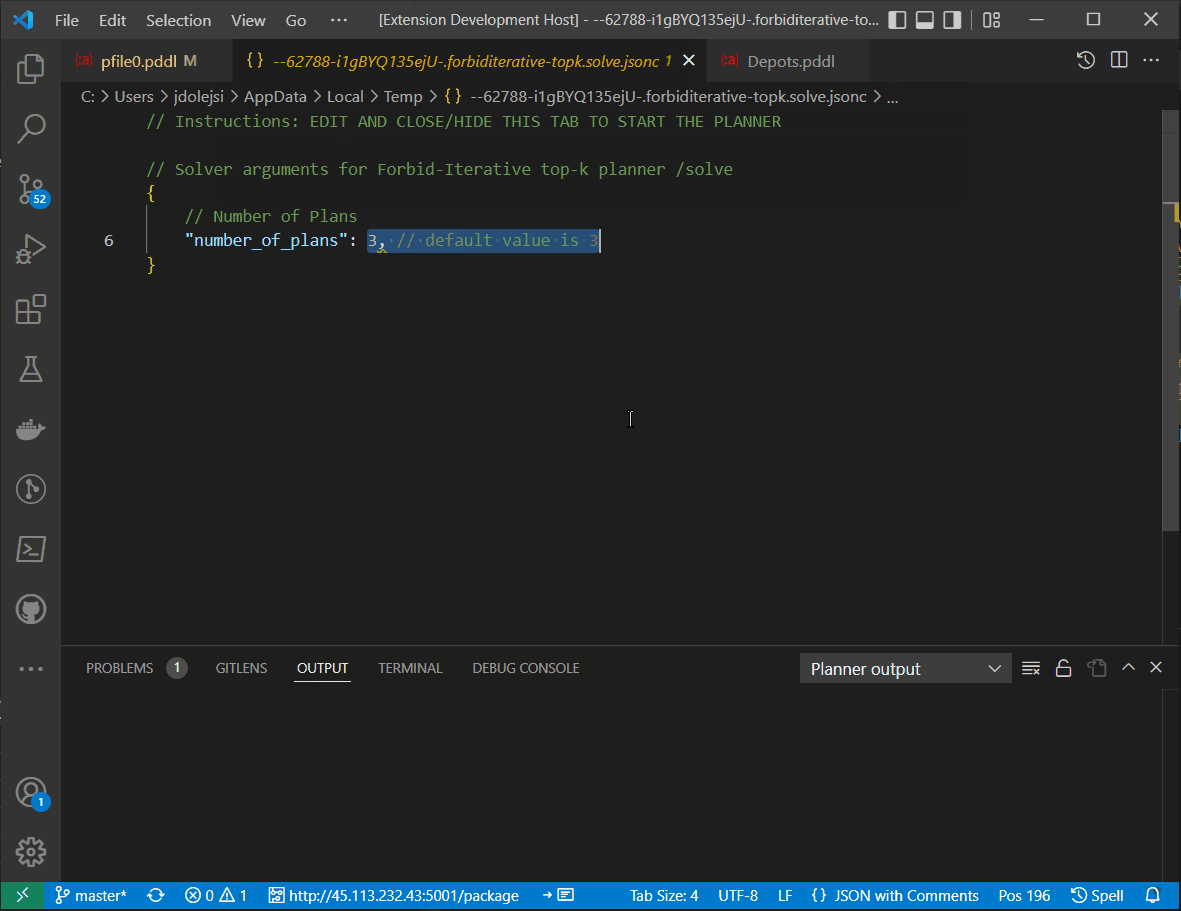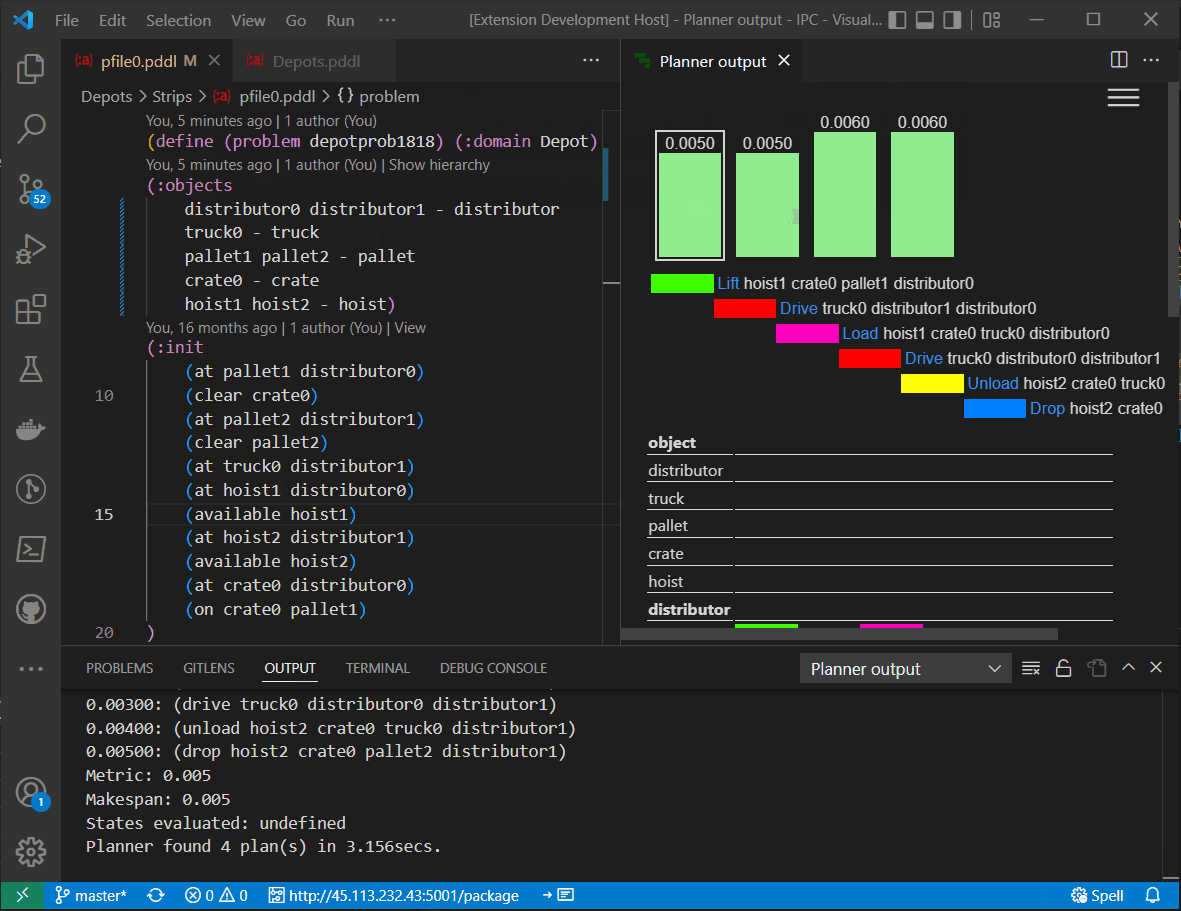
Planning-as-a-service client - previewFor now the packaged planning-as-a-service url needs to be added as an additional planner.
This is now getting released in the VS Code extension for PDDL version 2.23.2. There are number of issues that I can see in the planner responses and in the interface. Do you want me to submit them as separate issues in this repo, so we can decide about each of them? |
|
That's great @jan-dolejsi, I'll aim to test the new version of the vscode plugin embedding it in an assignment around September, then we'll truly see if the server manages a high load :) It would be great if you can add all the issues so we can include them in future development plans. |
|
Very awesome indeed! The idea with the new online editor plugin was to use the arguments in the payload to dynamically build the input form. Maybe eventually vscode could do the same? I.e., create the right dialog elements depending on the arguments and their types. Would echo @nirlipo 's advice -- individual issues would be great to keep track of things. |
Yes. Eventually. A panel with the auto-generated UI is also possible. I will submit the issues I can see. Mainly it is about the semantic of the planner input and output. Plus some weird errors. |
@haz @nirlipo I have tried to apply the Resource limit on the subprocess call,here is the code. (I found this example online), but it never succeeded. If I set the memory too low, the subprocess won't return anything. If I set it to 30MB, I got fatal error: failed to reserve page summary memory\n message. Not sure what's going on here and I can't find any useful information on Google. I feel like this is a little bit complex now, as it involves docker, cluster, API decorator, and subprocess. |

|
Setting it too low likely breaks in weird ways because it can't even get off the ground. What happens when you throw large problems at a 500Mb limit? It's a problem we need to solve, since anyone could bring down the entire system by just trying to solve a few complicated problems. This not only is a theoretical risk, but happens all the time with the deployed solver. |
As for the solver, I couldn't find the stuff Cam did to make it backwards compatible...maybe that got removed at some point? We can leave the existing one up, but I'd rather not make something look official if we're just going to eventually shift to hosting it at solver.PD (which I think makes sense). This isn't meant to be a "sibling project", but rather a complete rewrite of the existing one. So, for now, just go with hard-coded IP's to keep it looking unofficial, and create an issue assigned to me to have it folded into the current setup (requires a fair bit of server setup wrangling, so best to just let Nir & I take care of it).
The text was updated successfully, but these errors were encountered: